探索云原生技术之容器编排引擎-Kubernetes/K8S详解(1)
❤️作者简介:2022新星计划第三季云原生与云计算赛道Top5🏅、华为云享专家🏅、云原生领域潜力新星🏅
💛博客首页:C站个人主页🌞
💗作者目的:如有错误请指正,将来会不断的完善笔记,帮助更多的Java爱好者入门,共同进步!
文章目录
-
-
- 基本理论介绍
-
- 什么是云原生
- 什么是kubernetes
- kubernetes核心功能
- 搭建三个虚拟机(1个Master和2个Node)
-
- 安装VMware Workstation 16 Pro(若已有VMware则跳过)
- 创建并配置新的虚拟机
- 虚拟机环境初始化
-
- 为每个节点检查操作系统的版本
- 分别关闭每个节点防火墙
- 分别给每个节点设置主机名
-
- 设置192.168.184.100 k8s主机的主机名
- 设置192.168.184.101 k8s从机(1)的主机名
- 设置192.168.184.102 k8s从机(2)的主机名
- 分别给每个节点进行主机名解析
- 分别给每个节点时间同步
- 分别为每个节点关闭selinux
-
- 查看selinux是否开启
- 为每个节点永久关闭selinux(需要重启)
- 为每个节点永久关闭swap分区
- 为每个节点将桥接的IPv4流量传递到iptables的链
- 为每个节点开启ipvs
- 重启三台机器
- 为每个节点安装Docker、kubeadm、kubelet和kubectl
- 为每个节点安装Docker
-
-
- 为每个节点的Docker接入阿里云镜像加速器
- 为每个节点的docker设置开机自动启动
- 为每个节点都添加阿里云的YUM软件源(十分重要,否则无法安装k8s)
-
- 为每个节点安装kubeadm、kubelet和kubectl
- 为每个节点准备集群镜像
-
- 查看k8s所需镜像
- 为每个节点下载镜像
- 部署k8s的Master节点
-
- 问题1:get nodes报错解决(有点坑)
- 问题2:发现节点的状态是NotReady。
- 问题3:初始化报错
-
- 解决办法:卸载Docker容器
- 重新安装docker
- 卸载kubernetes
- 在master节点上使用kubectl工具
- 部署k8s的slave节点
-
- 创建token的两种方式
- slave节点退出join
- 部署CNI网络插件(只在Master节点操作)
-
- 在Master节点上使用kubectl工具查看节点状态(可以看出状态是NotReady)
- 安装网络插件
-
- 启动flannel的方式
- 问题4:flannel出现ImagePullBackOff
- 重置集群(如果上面出问题了就执行下面命令)
-
基本理论介绍
什么是云原生
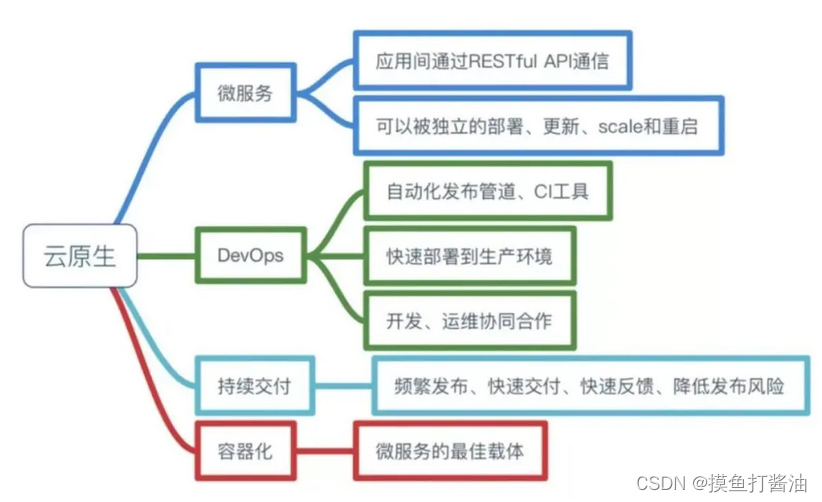
Pivotal公司的Matt Stine于2013年首次提出云原生(Cloud-Native)的概念;2015年,云原生刚推广时,Matt Stine在《迁移到云原生架构》一书中定义了符合云原生架构的几个特征:12因素、微服务、自敏捷架构、基于API协作、扛脆弱性;到了2017年,Matt Stine在接受InfoQ采访时又改了口风,将云原生架构归纳为模块化、可观察、可部署、可测试、可替换、可处理6特质;而Pivotal最新官网对云原生概括为4个要点:DevOps+持续交付+微服务+容器。
总而言之,符合云原生架构的应用程序应该是:采用开源堆栈(K8S+Docker)进行容器化,基于微服务架构提高灵活性和可维护性,借助敏捷方法、DevOps支持持续迭代和运维自动化,利用云平台设施实现弹性伸缩、动态调度、优化资源利用率。
(此处摘选自《知乎-华为云官方帐号》)
什么是kubernetes
kubernetes,简称K8s,是用8代替8个字符"ubernete"而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效,Kubernetes提供了应用部署,规划,更新,维护的一种机制。
传统的应用部署方式:是通过插件或脚本来安装应用。这样做的缺点是应用的运行、配置、管理、所有生存周期将与当前操作系统绑定,这样做并不利于应用的升级更新/回滚等操作,当然也可以通过创建虚拟机的方式来实现某些功能,但是虚拟机非常重,并不利于可移植性。
新的部署方式:是通过部署容器方式实现,每个容器之间互相隔离,每个容器有自己的文件系统 ,容器之间进程不会相互影响,能区分计算资源。相对于虚拟机,容器能快速部署,由于容器与底层设施、机器文件系统解耦的,所以它能在不同云、不同版本操作系统间进行迁移。
容器占用资源少、部署快,每个应用可以被打包成一个容器镜像,每个应用与容器间成一对一关系也使容器有更大优势,使用容器可以在build或release 的阶段,为应用创建容器镜像,因为每个应用不需要与其余的应用堆栈组合,也不依赖于生产环境基础结构,这使得从研发到测试、生产能提供一致环境。类似地,容器比虚拟机轻量、更"透明",这更便于监控和管理。
Kubernetes是Google开源的一个容器编排引擎,它支持自动化部署、大规模可伸缩、应用容器化管理。在生产环境中部署一个应用程序时,通常要部署该应用的多个实例以便对应用请求进行负载均衡。
在Kubernetes中,我们可以创建多个容器,每个容器里面运行一个应用实例,然后通过内置的负载均衡策略,实现对这一组应用实例的管理、发现、访问,而这些细节都不需要运维人员去进行复杂的手工配置和处理。
(此处摘选自《百度百科》)
kubernetes核心功能
- 存储系统挂载(数据卷):pod中容器之间共享数据,可以使用数据卷
- 应用健康检测:容器内服务可能进程阻塞无法处理请求,可以设置监控检查策略保证应用健壮性
- 应用实例的复制(实现pod的高可用):pod控制器(deployment)维护着pod副本数量(可以自己进行设置,默认为1),保证一个pod或一组同类的pod数量始终可用,如果pod控制器deployment当前维护的pod数量少于deployment设置的pod数量,则会自动生成一个新的pod,以便数量符合pod控制器,形成高可用。
- Pod的弹性伸缩:根据设定的指标(比如:cpu利用率)自动缩放pod副本数。
- 服务发现:使用环境变量或者DNS插件保证容器中程序发现pod入口访问地址
- 负载均衡:一组pod副本分配一个私有的集群IP地址,负载均衡转发请求到后端容器。在集群内部其他pod可通过这个clusterIP访问应用
- 滚动更新:更新服务不会发生中断,一次更新一个pod,而不是同时删除整个服务。
- 容器编排:通过文件来部署服务,使得应用程序部署变得更高效
- 资源监控:node节点组件集成cAdvisor资源收集工具,可通过Heapster汇总整个集群节点资源数据,然后存储到InfluxDb时序数据库,再由Grafana展示。
- 提供认证和授权:支持角色访问控制(RBAC)认证授权等策略
搭建三个虚拟机(1个Master和2个Node)
安装VMware Workstation 16 Pro(若已有VMware则跳过)
-
VMware哪个版本都行,我采用的是VMware Workstation 16 Pro,也会以这个版本来进行讲解。
-
进入VMware16 Pro官网下载
- 滑到最下面就有Windows版本和Linux版本,点击即可自动下载,大家各取所需即可。
- 按照提示安装即可。
安装VMware十分简单,这里不进行讲解。
创建并配置新的虚拟机


















虚拟机环境初始化
为每个节点检查操作系统的版本
- 检查操作系统的版本(要求操作系统的版本至少在centos7.5以上)
[root@master ~]# cat /etc/redhat-releaseCentOS Linux release 7.9.2009 (Core)分别关闭每个节点防火墙
- 关闭firewalld服务
- 关闭iptables服务
systemctl stop firewalldsystemctl disable firewalldsystemctl stop iptablessystemctl disable iptables分别给每个节点设置主机名
设置192.168.184.100 k8s主机的主机名
hostnamectl set-hostname k8s-master设置192.168.184.101 k8s从机(1)的主机名
hostnamectl set-hostname k8s-slave01设置192.168.184.102 k8s从机(2)的主机名
hostnamectl set-hostname k8s-slave02分别给每个节点进行主机名解析
- 为了方便后面集群节点间的直接调用,需要配置一下主机名解析,企业中推荐使用内部的DNS服务器
#1:进入hosts文件vim /etc/hosts#2:“”追加“”以下内容192.168.184.100 k8s-master192.168.184.101 k8s-slave01192.168.184.102 k8s-slave02分别给每个节点时间同步
- kubernetes要求集群中的节点时间必须精确一致,所以在每个节点上添加时间同步
[root@master ~]# yum install ntpdate -y已加载插件:fastestmirror, langpacksDetermining fastest mirrors * base: mirrors.dgut.edu.cn * extras: mirrors.dgut.edu.cn * updates: mirrors.aliyun.combase | 3.6 kB 00:00:00 extras | 2.9 kB 00:00:00 updates| 2.9 kB 00:00:00 (1/4): base/7/x86_64/group_gz | 153 kB 00:00:00 (2/4): extras/7/x86_64/primary_db | 246 kB 00:00:00 (3/4): base/7/x86_64/primary_db | 6.1 MB 00:00:05 (4/4): updates/7/x86_64/primary_db | 15 MB 00:00:09 软件包 ntpdate-4.2.6p5-29.el7.centos.2.x86_64 已安装并且是最新版本无须任何处理[root@master ~]# ntpdate time.windows.com30 Apr 00:06:26 ntpdate[1896]: adjust time server 20.189.79.72 offset 0.030924 sec分别为每个节点关闭selinux
查看selinux是否开启
[root@master ~]# getenforceEnforcing为每个节点永久关闭selinux(需要重启)
sed -i 's/enforcing/disabled/' /etc/selinux/config为每个节点永久关闭swap分区
sed -ri 's/.*swap.*/#&/' /etc/fstab为每个节点将桥接的IPv4流量传递到iptables的链
- 在每个节点上将桥接的IPv4流量传递到iptables的链
cat > /etc/sysctl.d/k8s.conf << EOFnet.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1net.ipv4.ip_forward = 1vm.swappiness = 0EOF# 加载br_netfilter模块modprobe br_netfilter# 查看是否加载[root@master ~]# lsmod | grep br_netfilterbr_netfilter 22256 0 bridge 151336 1 br_netfilter# 开始生效[root@master ~]# sysctl --system* Applying /usr/lib/sysctl.d/00-system.conf ...net.bridge.bridge-nf-call-ip6tables = 0net.bridge.bridge-nf-call-iptables = 0net.bridge.bridge-nf-call-arptables = 0* Applying /usr/lib/sysctl.d/10-default-yama-scope.conf ...kernel.yama.ptrace_scope = 0* Applying /usr/lib/sysctl.d/50-default.conf ...kernel.sysrq = 16kernel.core_uses_pid = 1kernel.kptr_restrict = 1net.ipv4.conf.default.rp_filter = 1net.ipv4.conf.all.rp_filter = 1net.ipv4.conf.default.accept_source_route = 0net.ipv4.conf.all.accept_source_route = 0net.ipv4.conf.default.promote_secondaries = 1net.ipv4.conf.all.promote_secondaries = 1fs.protected_hardlinks = 1fs.protected_symlinks = 1* Applying /etc/sysctl.d/99-sysctl.conf ...* Applying /etc/sysctl.d/k8s.conf ...net.bridge.bridge-nf-call-ip6tables = 1net.bridge.bridge-nf-call-iptables = 1net.ipv4.ip_forward = 1vm.swappiness = 0* Applying /etc/sysctl.conf ...为每个节点开启ipvs
- 在kubernetes中service有两种代理模型,一种是基于iptables,另一种是基于ipvs的。ipvs的性能要高于iptables的,但是如果要使用它,需要手动载入ipvs模块。
- 在所有节点安装ipset和ipvsadm:
[root@master ~]# yum -y install ipset ipvsadm已加载插件:fastestmirror, langpacksLoading mirror speeds from cached hostfile * base: mirrors.dgut.edu.cn * extras: mirrors.dgut.edu.cn * updates: mirrors.aliyun.com软件包 ipset-7.1-1.el7.x86_64 已安装并且是最新版本正在解决依赖关系--> 正在检查事务---> 软件包 ipvsadm.x86_64.0.1.27-8.el7 将被 安装--> 解决依赖关系完成依赖关系解决================================================================================================================== Package 架构 版本 源 大小==================================================================================================================正在安装: ipvsadm x86_64 1.27-8.el7 base45 k事务概要==================================================================================================================安装 1 软件包总下载量:45 k安装大小:75 kDownloading packages:警告:/var/cache/yum/x86_64/7/base/packages/ipvsadm-1.27-8.el7.x86_64.rpm: 头V3 RSA/SHA256 Signature, 密钥 ID f4a80eb5: NOKEYipvsadm-1.27-8.el7.x86_64.rpm 的公钥尚未安装ipvsadm-1.27-8.el7.x86_64.rpm | 45 kB 00:00:00 从 file:///etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7 检索密钥导入 GPG key 0xF4A80EB5: 用户ID : "CentOS-7 Key (CentOS 7 Official Signing Key) " 指纹: 6341 ab27 53d7 8a78 a7c2 7bb1 24c6 a8a7 f4a8 0eb5 软件包 : centos-release-7-9.2009.0.el7.centos.x86_64 (@anaconda) 来自: /etc/pki/rpm-gpg/RPM-GPG-KEY-CentOS-7Running transaction checkRunning transaction testTransaction test succeededRunning transaction 正在安装 : ipvsadm-1.27-8.el7.x86_64 1/1 验证中 : ipvsadm-1.27-8.el7.x86_64 1/1 已安装: ipvsadm.x86_64 0:1.27-8.el7 完毕!- 在所有节点执行如下脚本:
cat > /etc/sysconfig/modules/ipvs.modules <<EOF#!/bin/bashmodprobe -- ip_vsmodprobe -- ip_vs_rrmodprobe -- ip_vs_wrrmodprobe -- ip_vs_shmodprobe -- nf_conntrack_ipv4EOF- 授权、运行、检查是否加载
[root@master ~]# chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack_ipv4nf_conntrack_ipv4 15053 0 nf_defrag_ipv4 12729 1 nf_conntrack_ipv4ip_vs_sh 12688 0 ip_vs_wrr12697 0 ip_vs_rr 12600 0 ip_vs 145458 6 ip_vs_rr,ip_vs_sh,ip_vs_wrrnf_conntrack 139264 2 ip_vs,nf_conntrack_ipv4libcrc32c12644 3 xfs,ip_vs,nf_conntrack- 检查是否加载
[root@slave01 ~]# lsmod | grep -e ipvs -e nf_conntrack_ipv4nf_conntrack_ipv4 15053 6 nf_defrag_ipv4 12729 1 nf_conntrack_ipv4nf_conntrack 139264 7 ip_vs,nf_nat,nf_nat_ipv4,nf_nat_ipv6,xt_conntrack,nf_conntrack_ipv4,nf_conntrack_ipv6重启三台机器
$ reboot为每个节点安装Docker、kubeadm、kubelet和kubectl
为每个节点安装Docker
- 1:切换镜像源
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo- 2:查看当前镜像源中支持的docker版本
yum list docker-ce --showduplicates- 3:安装特定版本的docker-ce必须制定–setopt=obsoletes=0,否则yum会自动安装更高版本
yum install --setopt=obsoletes=0 docker-ce-18.06.3.ce-3.el7 -y为每个节点的Docker接入阿里云镜像加速器
配置镜像加速器方法。
- 准备工作:
- 1:首先进入阿里云容器镜像服务 https://cr.console.aliyun.com/cn-hangzhou/instances/mirrors
- 2:点击镜像工具下面的镜像加速器
- 3:拿到你的加速器地址和下面第二步的registry-mirrors的值替换即可。
针对Docker客户端版本大于 1.10.0 的用户,可以通过修改daemon配置文件/etc/docker/daemon.json来使用加速器
- 第一步:
mkdir -p /etc/docker- 第二步:
cat <<EOF> /etc/docker/daemon.json{"exec-opts": ["native.cgroupdriver=systemd"],"registry-mirrors": ["https://u01jo9qv.mirror.aliyuncs.com"]}EOF- 第三步:
sudo systemctl daemon-reload- 第四步:
sudo systemctl restart docker最后就接入阿里云容器镜像加速器成功啦。
为每个节点的docker设置开机自动启动
sudo systemctl enable docker为每个节点都添加阿里云的YUM软件源(十分重要,否则无法安装k8s)
- 由于kubernetes的镜像源在国外,所以这里切换成国内的阿里云镜像源,否则将下载不了k8s
cat > /etc/yum.repos.d/kubernetes.repo << EOF[kubernetes]name=Kubernetesbaseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64enabled=1gpgcheck=0repo_gpgcheck=0gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpgEOF为每个节点安装kubeadm、kubelet和kubectl
- 1:指定版本安装
yum install --setopt=obsoletes=0 kubeadm-1.17.4-0 kubelet-1.17.4-0 kubectl-1.17.4-0 -y- 2:配置kubelet的cgroup,编辑/etc/sysconfig/kubelet, 添加下面的配置
vim /etc/sysconfig/kubelet内容如下:
# 修改KUBELET_CGROUP_ARGS="--cgroup-driver=systemd"KUBE_PROXY_MODE="ipvs"- 3:设置为开机自启动即可,由于没有生成配置文件,k8s集群初始化后自动启动
systemctl enable kubelet为每个节点准备集群镜像
查看k8s所需镜像
[root@k8s-master ~]# kubeadm config images listI0430 16:57:23.161932 1653 version.go:252] remote version is much newer: v1.23.6; falling back to: stable-1.18W0430 16:57:26.117608 1653 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]k8s.gcr.io/kube-apiserver:v1.18.20k8s.gcr.io/kube-controller-manager:v1.18.20k8s.gcr.io/kube-scheduler:v1.18.20k8s.gcr.io/kube-proxy:v1.18.20k8s.gcr.io/pause:3.2k8s.gcr.io/etcd:3.4.3-0k8s.gcr.io/coredns:1.6.7为每个节点下载镜像
定义镜像
images=(kube-apiserver:v1.17.4kube-controller-manager:v1.17.4kube-scheduler:v1.17.4kube-proxy:v1.17.4pause:3.1etcd:3.4.3-0coredns:1.6.5)循环下载定义的镜像
for imageName in ${images[@]};dodocker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$imageNamedocker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName k8s.gcr.io/$imageNamedocker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$imageName done这里需要花费一些时间。
#重启reboot部署k8s的Master节点
- 当前主节点(master)的ip为192.168.184.100
- 下面的操作只需要在master节点上执行即可
- 哪一个节点执行了下面的init命令,那么这一个节点就会变成master节点
# 由于默认拉取镜像地址k8s.gcr.io国内无法访问,这里需要指定阿里云镜像仓库地址kubeadm init \--apiserver-advertise-address=192.168.184.100 \--image-repository registry.aliyuncs.com/google_containers \--kubernetes-version=v1.17.4 \--service-cidr=10.96.0.0/12 \--pod-network-cidr=10.244.0.0/16- 参数介绍:
- –apiserver-advertise-address:必须指定你master节点的ip地址
- –kubernetes-version:指定k8s的版本,我们这里使用的是v1.17.4
问题1:get nodes报错解决(有点坑)
产生原因
- localhost:8080 这个端口是k8s api(kube-apiserver非安全端口)的端口,在master上面可以执行成功其实走的是配置文件。但是在node上连接的是本地的非安全端口。
kube-apiserver两个端口:
-
localhost:8080 非安全端口(不需要认证,没有加入认证机制),是kubectl默认先连接8080,如果你配置kubeconfig(.kube/config)就直接走这个配置连接的安全端口(在master上没有8080端口,走的是kubeconfig)
-
master-ip:6443 安全端口 ,提供了内部授权的机制,比如登入网站想要输入用户名密码才能登入。
-
kubeadm安装的默认禁用了8080端口
-
当我们执行kubectl get nodes命令时出现下面的异常信息:
[root@k8s-master ~]# kubectl get nodesThe connection to the server localhost:8080 was refused - did you specify the right host or port?-
解决方案:就是执行下面这一行命令即可
-
方法1:(非常建议,永久生效,一劳永逸)
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config- 方法2:(不建议,因为重新连接centos7服务器会失效,需要重新执行)
export KUBECONFIG=/etc/kubernetes/admin.conf- 测试一下
[root@k8s-master ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONk8s-master NotReady master 17h v1.17.4问题2:发现节点的状态是NotReady。
#查看当前节点日志,查看报错信息journalctl -f -u kubelet-- Logs begin at 三 2022-05-04 11:23:44 CST. --5月 04 11:48:14 k8s-master kubelet[2658]: W0504 11:48:14.630055 2658 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d5月 04 11:48:15 k8s-master kubelet[2658]: E0504 11:48:15.119308 2658 kubelet.go:2183] Container runtime network not ready: NetworkReady=false reason:NetworkPluginNotReady message:docker: network plugin is not ready: cni config uninitialized5月 04 11:48:19 k8s-master kubelet[2658]: W0504 11:48:19.631196 2658 cni.go:237] Unable to update cni config: no networks found in /etc/cni/net.d-
原因是kubelet参数多了network-plugin=cni,但又没有安装cni插件。
-
看下面的步骤,安装cni完成之后。
[root@k8s-master ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONk8s-master Ready master 18h v1.17.4问题3:初始化报错
[root@k8s-master ~]# kubeadm init \> --apiserver-advertise-address=192.168.184.100 \> --image-repository registry.aliyuncs.com/google_containers \> --kubernetes-version v1.17.4 \> --service-cidr=10.96.0.0/12 \> --pod-network-cidr=10.244.0.0/16W0501 20:02:43.025579 14399 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io][init] Using Kubernetes version: v1.18.0[preflight] Running pre-flight checks[WARNING SystemVerification]: this Docker version is not on the list of validated versions: 20.10.14. Latest validated version: 19.03error execution phase preflight: [preflight] Some fatal errors occurred:[ERROR Port-10259]: Port 10259 is in use[ERROR Port-10257]: Port 10257 is in use[ERROR FileAvailable--etc-kubernetes-manifests-kube-apiserver.yaml]: /etc/kubernetes/manifests/kube-apiserver.yaml already exists[ERROR FileAvailable--etc-kubernetes-manifests-kube-controller-manager.yaml]: /etc/kubernetes/manifests/kube-controller-manager.yaml already exists[ERROR FileAvailable--etc-kubernetes-manifests-kube-scheduler.yaml]: /etc/kubernetes/manifests/kube-scheduler.yaml already exists[ERROR FileAvailable--etc-kubernetes-manifests-etcd.yaml]: /etc/kubernetes/manifests/etcd.yaml already exists[ERROR DirAvailable--var-lib-etcd]: /var/lib/etcd is not empty[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`To see the stack trace of this error execute with --v=5 or higher- this Docker version is not on the list of validated versions: 20.10.14. Latest validated version: 19.03
- 可以看出,docker和k8s要进行版本的匹配,不能太高也不能太低,否则就会报错。
解决办法:卸载Docker容器
- 1:查看已安装的docker版本
[root@aubin ~]# yum list installed |grep docker输出结果:containerd.io.x86_64 1.4.4-3.1.el7@docker-ce-stabledocker-ce-cli.x86_64 1:20.10.6-3.el7 @docker-ce-stabledocker-scan-plugin.x86_64 0.7.0-3.el7 @docker-ce-stable- 2:删除docker
yum -y remove containerd.io.x86_64yum -y remove docker-ce-cli.x86_64 yum -y remove docker-scan-plugin.x86_64重新安装docker
- 1:
wget https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo -O /etc/yum.repos.d/docker-ce.repo- 2:
yum -y install docker-ce-18.06.3.ce-3.el7- 3:
systemctl enable docker && systemctl start docker- 4:
docker version- 5:Docker镜像加速器
sudo mkdir -p /etc/dockersudo tee /etc/docker/daemon.json <<-'EOF'{ "exec-opts": ["native.cgroupdriver=systemd"], "registry-mirrors": ["https://u01jo9qv.mirror.aliyuncs.com"], "live-restore": true, "log-driver":"json-file", "log-opts": {"max-size":"500m", "max-file":"3"}, "storage-driver": "overlay2"}EOFsudo systemctl daemon-reloadsudo systemctl restart docker- 6:启动docker服务
systemctl enable docker.service卸载kubernetes
kubeadm reset -fmodprobe -r ipiplsmodrm -rf ~/.kube/rm -rf /etc/kubernetes/rm -rf /etc/systemd/system/kubelet.service.drm -rf /etc/systemd/system/kubelet.servicerm -rf /usr/bin/kube*rm -rf /etc/cnirm -rf /opt/cnirm -rf /var/lib/etcdrm -rf /var/etcdyum clean allyum remove kube*-
重新安装k8s(或者换一个新的虚拟机)
-
执行成功在最下面会返回这样一行内容:
Your Kubernetes control-plane has initialized successfully!To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/configYou should now deploy a pod network to the cluster.Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: https://kubernetes.io/docs/concepts/cluster-administration/addons/Then you can join any number of worker nodes by running the following on each as root:#最重要的命令,可以用来加入从节点#kubeadm join 192.168.184.100:6443 --token 1r8ysf.p7myixjcjvmn39u3 \ --discovery-token-ca-cert-hash sha256:6f5a2271dd9e764fc33e4ec22e5d3a68d79d57d80bec7a67f99b2190667c7631 - 可以看到下面有行命令,是用来加入节点的,只需要将这条命令放到从机上去即可。
kubeadm join 192.168.184.100:6443 --token 1r8ysf.p7myixjcjvmn39u3 \ --discovery-token-ca-cert-hash sha256:6f5a2271dd9e764fc33e4ec22e5d3a68d79d57d80bec7a67f99b2190667c7631 在master节点上使用kubectl工具
mkdir -p $HOME/.kubesudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/configsudo chown $(id -u):$(id -g) $HOME/.kube/config- 然后我们的master节点就部署好了。
部署k8s的slave节点
- 在两个从节点(192.168.184.101和192.168.184.102)上写入如下的命令(加入节点):
kubeadm join 192.168.184.100:6443 --token 1r8ysf.p7myixjcjvmn39u3 \ --discovery-token-ca-cert-hash sha256:6f5a2271dd9e764fc33e4ec22e5d3a68d79d57d80bec7a67f99b2190667c7631- 上面这些命令都是在init主节点自动产生的,具体的可以看上面部署master节点。
默认的token有效期为2小时,当过期之后,该token就不能用了,这时可以使用如下的命令创建token。
创建token的两种方式
- 1:创建一个永久的token:
# 生成一个永不过期的token[root@k8s-master ~]# kubeadm token create --ttl 0 --print-join-commandW0430 17:39:26.127850 10466 configset.go:202] WARNING: kubeadm cannot validate component configs for API groups [kubelet.config.k8s.io kubeproxy.config.k8s.io]##这个就是不会过期的命令kubeadm join 192.168.184.100:6443 --token wolcu9.jrxmjmbqpvqe44x8 --discovery-token-ca-cert-hash sha256:6f5a2271dd9e764fc33e4ec22e5d3a68d79d57d80bec7a67f99b2190667c7631 - 2:创建一个会过期的token:
kubeadm token create --print-join-command- 3:把生成命令重新在各个slave节点上执行。
[root@k8s-slave01 ~]# kubeadm join 192.168.184.100:6443 --token 2wmd2p.39xczgxkoxbjmqpx --discovery-token-ca-cert-hash sha256:b6a3200a4bf327ce10d229921f21c2d890f0bf48da6a3e37de5de36c48ed9210 W0504 13:38:09.198532 1849 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.[preflight] Running pre-flight checks[WARNING Hostname]: hostname "k8s-slave01" could not be reached[WARNING Hostname]: hostname "k8s-slave01": lookup k8s-slave01 on 223.5.5.5:53: no such host[preflight] Reading configuration from the cluster...[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.17" ConfigMap in the kube-system namespace[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"[kubelet-start] Starting the kubelet[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:* Certificate signing request was sent to apiserver and a response was received.* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.- 4:在master节点查看所有节点状态
[root@k8s-master ~]# kubectl get pods,svc,nodesNAME READY STATUS RESTARTS AGEpod/nginx-6867cdf567-mf4xt 1/1 Running 0 24mNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGEservice/kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 19hservice/nginx NodePort 10.103.67.90 <none> 80:30048/TCP 23mNAME STATUS ROLES AGE VERSIONnode/k8s-master Ready master 19h v1.17.4node/k8s-slave01 Ready <none> 8m32s v1.17.4slave节点退出join
- 当slave已经加入一个master节点,我们想让它加入另外一个master节点,我们必须要先退出才能join。
[root@k8s-slave02 ~]# kubeadm join 192.168.184.100:6443 --token f99cdo.1a4h5qv90t6ktq0l --discovery-token-ca-cert-hash sha256:9570221e545e3b7c592ad9460d9c3d393e6123101b7c26e7b1437bcd5c20f5be W0515 14:44:59.685275 13110 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.[preflight] Running pre-flight checkserror execution phase preflight: [preflight] Some fatal errors occurred:[ERROR FileAvailable--etc-kubernetes-kubelet.conf]: /etc/kubernetes/kubelet.conf already exists[ERROR Port-10250]: Port 10250 is in use[ERROR FileAvailable--etc-kubernetes-pki-ca.crt]: /etc/kubernetes/pki/ca.crt already exists[preflight] If you know what you are doing, you can make a check non-fatal with `--ignore-preflight-errors=...`To see the stack trace of this error execute with --v=5 or higher- 进行集群重置(slave节点上执行),必须要进行重置,否则将无法执行成功下面的join命令
kubeadm resetsystemctl stop kubeletsystemctl stop dockerrm -rf /var/lib/cni/rm -rf /var/lib/kubelet/*rm -rf /etc/cni/ifconfig cni0 downifconfig flannel.1 downifconfig docker0 downip link delete cni0ip link delete flannel.1systemctl restart kubeletsystemctl restart docker- 再次运行join命令,可以运行成功了。
[root@k8s-slave01 ~]# kubeadm join 192.168.184.100:6443 --token 8vd0qj.doqff1kdurlzgzzd --discovery-token-ca-cert-hash sha256:9570221e545e3b7c592ad9460d9c3d393e6123101b7c26e7b1437bcd5c20f5be W0515 15:00:39.368526 16957 join.go:346] [preflight] WARNING: JoinControlPane.controlPlane settings will be ignored when control-plane flag is not set.[preflight] Running pre-flight checks[preflight] Reading configuration from the cluster...[preflight] FYI: You can look at this config file with 'kubectl -n kube-system get cm kubeadm-config -oyaml'[kubelet-start] Downloading configuration for the kubelet from the "kubelet-config-1.17" ConfigMap in the kube-system namespace[kubelet-start] Writing kubelet configuration to file "/var/lib/kubelet/config.yaml"[kubelet-start] Writing kubelet environment file with flags to file "/var/lib/kubelet/kubeadm-flags.env"[kubelet-start] Starting the kubelet[kubelet-start] Waiting for the kubelet to perform the TLS Bootstrap...This node has joined the cluster:* Certificate signing request was sent to apiserver and a response was received.* The Kubelet was informed of the new secure connection details.Run 'kubectl get nodes' on the control-plane to see this node join the cluster.部署CNI网络插件(只在Master节点操作)
在Master节点上使用kubectl工具查看节点状态(可以看出状态是NotReady)
[root@k8s-master ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONk8s-master NotReady master 36m v1.18.0k8s-slave01 NotReady <none> 7m34s v1.18.0k8s-slave02 NotReady <none> 7m31s v1.18.0安装网络插件
-
kubernetes支持多种网络插件,比如flannel、calico、canal等,任选一种即可,本次选择flannel
-
在Master节点上获取flannel配置文件(可能会失败,如果失败,请下载到本地,然后安装):
[root@k8s-master ~]# wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml--2022-04-30 17:48:22-- https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml正在解析主机 raw.githubusercontent.com (raw.githubusercontent.com)... 185.199.110.133, 185.199.109.133, 185.199.111.133, ...正在连接 raw.githubusercontent.com (raw.githubusercontent.com)|185.199.110.133|:443... 已连接。已发出 HTTP 请求,正在等待回应... 200 OK长度:5750 (5.6K) [text/plain]正在保存至: “kube-flannel.yml”100%[========================================================================>] 5,750--.-K/s 用时 0s 2022-04-30 17:48:23 (116 MB/s) - 已保存 “kube-flannel.yml” [5750/5750])- 如果下载不了,可以使用我的,文件名必须为kube-flannel.yml:
可以通过XFTP传到服务器上。(直接使用vim可能会让格式乱掉,可以下载到windows再通过xftp上传到linux服务器)
---apiVersion: policy/v1beta1kind: PodSecurityPolicymetadata: name: psp.flannel.unprivileged annotations: seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/defaultspec: privileged: false volumes: - configMap - secret - emptyDir - hostPath allowedHostPaths: - pathPrefix: "/etc/cni/net.d" - pathPrefix: "/etc/kube-flannel" - pathPrefix: "/run/flannel" readOnlyRootFilesystem: false # Users and groups runAsUser: rule: RunAsAny supplementalGroups: rule: RunAsAny fsGroup: rule: RunAsAny # Privilege Escalation allowPrivilegeEscalation: false defaultAllowPrivilegeEscalation: false # Capabilities allowedCapabilities: ['NET_ADMIN', 'NET_RAW'] defaultAddCapabilities: [] requiredDropCapabilities: [] # Host namespaces hostPID: false hostIPC: false hostNetwork: true hostPorts: - min: 0 max: 65535 # SELinux seLinux: # SELinux is unused in CaaSP rule: 'RunAsAny'---kind: ClusterRoleapiVersion: rbac.authorization.k8s.io/v1metadata: name: flannelrules:- apiGroups: ['extensions'] resources: ['podsecuritypolicies'] verbs: ['use'] resourceNames: ['psp.flannel.unprivileged']- apiGroups: - "" resources: - pods verbs: - get- apiGroups: - "" resources: - nodes verbs: - list - watch- apiGroups: - "" resources: - nodes/status verbs: - patch---kind: ClusterRoleBindingapiVersion: rbac.authorization.k8s.io/v1metadata: name: flannelroleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannelsubjects:- kind: ServiceAccount name: flannel namespace: kube-system---apiVersion: v1kind: ServiceAccountmetadata: name: flannel namespace: kube-system---kind: ConfigMapapiVersion: v1metadata: name: kube-flannel-cfg namespace: kube-system labels: tier: node app: flanneldata: cni-conf.json: | { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } }---apiVersion: apps/v1kind: DaemonSetmetadata: name: kube-flannel-ds namespace: kube-system labels: tier: node app: flannelspec: selector: matchLabels: app: flannel template: metadata: labels: tier: node app: flannel spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions:- key: kubernetes.io/os operator: In values: - linux hostNetwork: true priorityClassName: system-node-critical tolerations: - operator: Exists effect: NoSchedule serviceAccountName: flannel initContainers: - name: install-cni-plugin#image: flannelcni/flannel-cni-plugin:v1.0.1 for ppc64le and mips64le (dockerhub limitations may apply) image: rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1 command: - cp args: - -f - /flannel - /opt/cni/bin/flannel volumeMounts: - name: cni-plugin mountPath: /opt/cni/bin - name: install-cni#image: flannelcni/flannel:v0.17.0 for ppc64le and mips64le (dockerhub limitations may apply) image: rancher/mirrored-flannelcni-flannel:v0.17.0 command: - cp args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist volumeMounts: - name: cni mountPath: /etc/cni/net.d - name: flannel-cfg mountPath: /etc/kube-flannel/ containers: - name: kube-flannel#image: flannelcni/flannel:v0.17.0 for ppc64le and mips64le (dockerhub limitations may apply) image: rancher/mirrored-flannelcni-flannel:v0.17.0 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr resources: requests: cpu: "100m" memory: "50Mi" limits: cpu: "100m" memory: "50Mi" securityContext: privileged: false capabilities: add: ["NET_ADMIN", "NET_RAW"] env: - name: POD_NAME valueFrom: fieldRef:fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef:fieldPath: metadata.namespace - name: EVENT_QUEUE_DEPTH value: "5000" volumeMounts: - name: run mountPath: /run/flannel - name: flannel-cfg mountPath: /etc/kube-flannel/ - name: xtables-lock mountPath: /run/xtables.lock volumes: - name: run hostPath: path: /run/flannel - name: cni-plugin hostPath: path: /opt/cni/bin - name: cni hostPath: path: /etc/cni/net.d - name: flannel-cfg configMap: name: kube-flannel-cfg - name: xtables-lock hostPath: path: /run/xtables.lock type: FileOrCreate启动flannel的方式
- 方法一:下载到当前目前启动flannel:(由于把flannel.yml放到了本地,所以启动十分快)
kubectl apply -f kube-flannel.yml- 方法二:在线拉取并且启动flannel:(缺点是在线拉取十分缓慢)
[root@k8s-master ~]# kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.ymlpodsecuritypolicy.policy/psp.flannel.unprivileged createdclusterrole.rbac.authorization.k8s.io/flannel createdclusterrolebinding.rbac.authorization.k8s.io/flannel createdserviceaccount/flannel createdconfigmap/kube-flannel-cfg createddaemonset.apps/kube-flannel-ds created- 查看部署CNI网络插件进度(直到等待初始化完成(Running)):
[root@k8s-master ~]# kubectl get pods -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-9d85f5447-6t89q1/1 Running 0 18hcoredns-9d85f5447-cgt491/1 Running 0 18hetcd-k8s-master 1/1 Running 2 18hkube-apiserver-k8s-master 1/1 Running 2 18hkube-controller-manager-k8s-master 1/1 Running 2 18hkube-flannel-ds-dk952 1/1 Running 0 3m16skube-proxy-x7ns91/1 Running 2 18hkube-scheduler-k8s-master 1/1 Running 2 18h问题4:flannel出现ImagePullBackOff
[root@k8s-master ~]# kubectl get pods -n kube-systemNAME READY STATUS RESTARTS AGEcoredns-9d85f5447-hsctd1/1 Running 0 33mcoredns-9d85f5447-v28cx1/1 Running 0 33metcd-k8s-master 1/1 Running 0 33mkube-apiserver-k8s-master 1/1 Running 0 33mkube-controller-manager-k8s-master 1/1 Running 0 33mkube-flannel-ds-5brqz 0/1 Init:ImagePullBackOff 0 9m15s查看kube-flannel-ds-5brqz报错信息:
kubectl describe pod kube-flannel-ds-5brqz -n kube-system输出如下:
Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 20m default-scheduler Successfully assigned kube-system/kube-flannel-ds-5brqz to k8s-slave01 Warning Failed 19m kubelet, k8s-slave01 Failed to pull image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1": rpc error: code = Unknown desc = error pulling image configuration: Get https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/ac/ac40ce62574065ffaad7fe9a6f6a2f5a94246847e882bb034cf8fb249c158598/data?verify=1652446938-UhlcpbAE1orAeMWn4RgzsLOih7I%3D: dial tcp 104.18.124.25:443: i/o timeout Warning Failed 18m kubelet, k8s-slave01 Failed to pull image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1": rpc error: code = Unknown desc = error pulling image configuration: Get https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/ac/ac40ce62574065ffaad7fe9a6f6a2f5a94246847e882bb034cf8fb249c158598/data?verify=1652447006-ATuYDcprD98gnZWe2lMbMCUvPAw%3D: dial tcp 104.18.125.25:443: i/o timeout Warning Failed 17m kubelet, k8s-slave01 Failed to pull image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1": rpc error: code = Unknown desc = error pulling image configuration: Get https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/ac/ac40ce62574065ffaad7fe9a6f6a2f5a94246847e882bb034cf8fb249c158598/data?verify=1652447085-yEKQljoBf%2FyQ0c72N%2BvEFXlqHWk%3D: dial tcp 104.18.125.25:443: i/o timeout Normal Pulling 16m (x4 over 20m) kubelet, k8s-slave01 Pulling image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1" Warning Failed 15m (x4 over 19m) kubelet, k8s-slave01 Error: ErrImagePull Warning Failed 15m kubelet, k8s-slave01 Failed to pull image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1": rpc error: code = Unknown desc = error pulling image configuration: Get https://production.cloudflare.docker.com/registry-v2/docker/registry/v2/blobs/sha256/ac/ac40ce62574065ffaad7fe9a6f6a2f5a94246847e882bb034cf8fb249c158598/data?verify=1652447189-MIzL3vf7Zx6w6cVcnJbSfGJxR3I%3D: dial tcp 104.18.124.25:443: i/o timeout Warning Failed 9m11s kubelet, k8s-slave01 Failed to pull image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1": rpc error: code = Unknown desc = context canceled Normal BackOff 5m40s (x39 over 19m) kubelet, k8s-slave01 Back-off pulling image "rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1" Warning Failed 43s (x57 over 19m) kubelet, k8s-slave01 Error: ImagePullBackOff-
发现问题:从上面的报错信息可以看到一直重复说rancher/mirrored-flannelcni-flannel-cni-plugin:v1.0.1镜像拉取失败。
-
再次在Master节点使用kubectl工具查看节点状态:
[root@k8s-master ~]# kubectl get nodesNAME STATUS ROLES AGE VERSIONk8s-master Ready master 58m v1.17.4k8s-slave01 Ready <none> 39m v1.17.4k8s-slave02 Ready <none> 39m v1.17.4- 查看集群健康状况:
[root@k8s-master ~]# kubectl get csNAME STATUS MESSAGE ERRORscheduler Healthy ok controller-manager Healthy ok etcd-0 Healthy {"health":"true"} [root@k8s-master ~]# kubectl cluster-infoKubernetes master is running at https://192.168.184.100:6443KubeDNS is running at https://192.168.184.100:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxyTo further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.重置集群(如果上面出问题了就执行下面命令)
- 注意:上面操作出问题了才执行(记住:在master节点之外的节点(也就是在slave节点)进行操作)
kubeadm resetsystemctl stop kubeletsystemctl stop dockerrm -rf /var/lib/cni/rm -rf /var/lib/kubelet/*rm -rf /etc/cni/ifconfig cni0 downifconfig flannel.1 downifconfig docker0 downip link delete cni0ip link delete flannel.1systemctl restart kubeletsystemctl restart docker❤️💛🧡本章结束,我们下一章见❤️💛🧡

