聊聊Flink框架中的状态管理机制
大家好,我是百思不得小赵。
创作时间:2022 年 5 月 27 日
博客主页: 🔍点此进入博客主页
—— 新时代的农民工 🙊
—— 换一种思维逻辑去看待这个世界 👀
今天是加入CSDN的第1182天。觉得有帮助麻烦👏点赞、🍀评论、❤️收藏
目录
状态概述
在目前所有流式计算的场景中,将数据流的状态分为有状态和无状态两种类型。无状态指的就是无状态的计算观察每个独立的事件,并且只根据最后一个事件输出结果。举个栗子:一个流处理程序,从传感器接收温度数据然后在温度为90摄氏度发出报警信息。有状态的计算则会根据多个事件输出结果。举个栗子:计算过去一小时的平均温度,就是有状态的计算、若在一分钟内收到两个相差 20 度以上的温度读数,则发出警告等等。
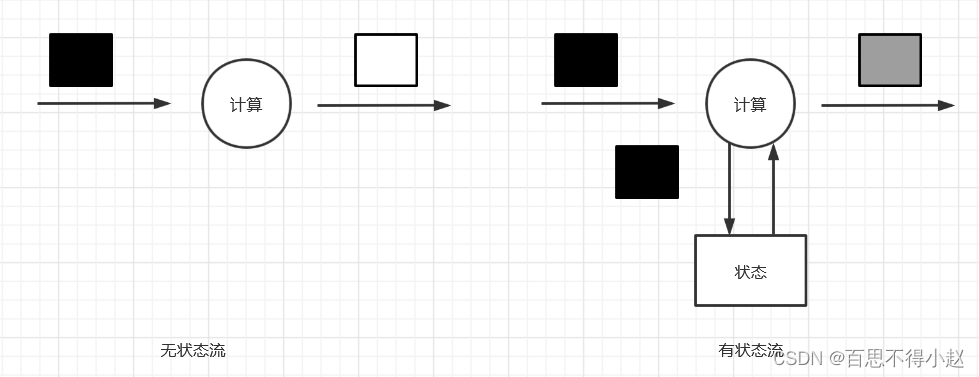
对照上图可以看出:
- 无状态流处理分别接收每条数据记录,然后根据最新输入的数据生成输出数据。(每次只转换一条输入记录,并且仅根据最新的输入记录输出结果)
- 有状态流处理会维护状态,并基于最新输入的记录和当前的状态值生成输出记录。(维护所有已处理记录的状态值,并根据每条新输入的记录更新状态,因此输出记录反映的是综合考虑多个事件之后的结果。)
Flink中的状态
Flink中的状态有一个任务进行专门维护,并且用来计算某个结果的所有数据,都属于这个任务的状态。大多数的情况下我们可以将Flink中状态理解为一个本地变量,存储在内存中。状态自始至终是与特定的算子相关联的,在flink中需要进行状态的注册。
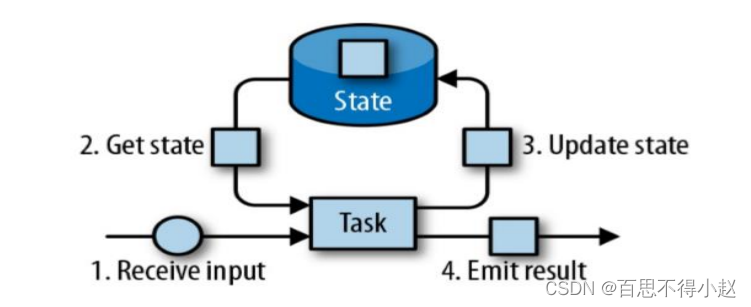
(此图来源于网络)
Flink框架中有两种类型的状态:算子状态、键控状态。接下来我们具体的聊聊这两种状态。
算子状态
算子状态的作用范围限定为算子任务。由同一并行任务所处理的所有数据都可以访问到相同的状态。也就是说,同一个任务中是共享的。
注意:算子状态不能由相同或不同算子的另一个子任务访问
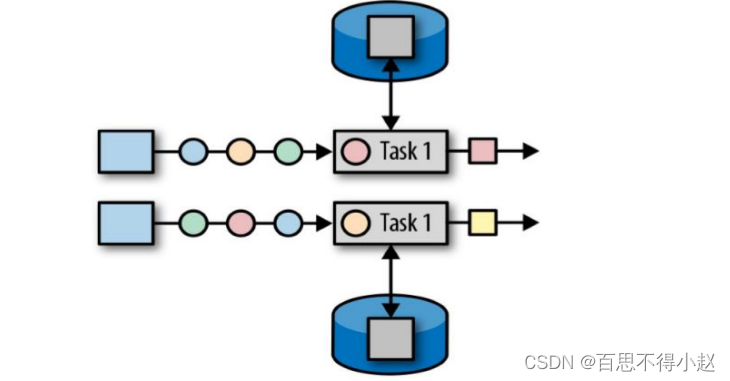
(此图来源于网络)
Flink 为算子状态提供三种基本数据结构:
列表状态
- 将状态表示为一组数据的列表。
联合列表状态
- 也将状态表示为数据的列表。它与常规列表状态的区别在于,在发生故障时,或者从保存点(savepoint)启动应用程序时如何恢复。
广播状态
- 如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态
代码如下:
public class StateTest1_OperatorState { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //设施并行度为1 env.setParallelism(1); DataStreamSource<String> inputStream = env.socketTextStream("localhost", 7777); DataStream<SensorReading> dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); // 定义一个有状态的Map操作 统计当前分区数据个数 SingleOutputStreamOperator<Integer> resultStream = dataStream.map(new MyCountMap()); resultStream.print(); env.execute(); } //自定义mapFunction 注册状态实现ListCheckpointed private static class MyCountMap implements MapFunction<SensorReading, Integer>, ListCheckpointed<Integer>{ // 定义一个本地变量作为算子状态 private Integer count = 0; @Override public Integer map(SensorReading sensorReading) throws Exception { count++; return count; } @Override public List<Integer> snapshotState(long checkpointId, long timestamp) throws Exception { return Collections.singletonList(count); } @Override public void restoreState(List<Integer> state) throws Exception { for (Integer number : state) { count+=number; } } }}键控状态
键控状态是根据输入数据流中定义的键(key)来维护和访问的。Flink 为每个 key 维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个 key 对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的 key。
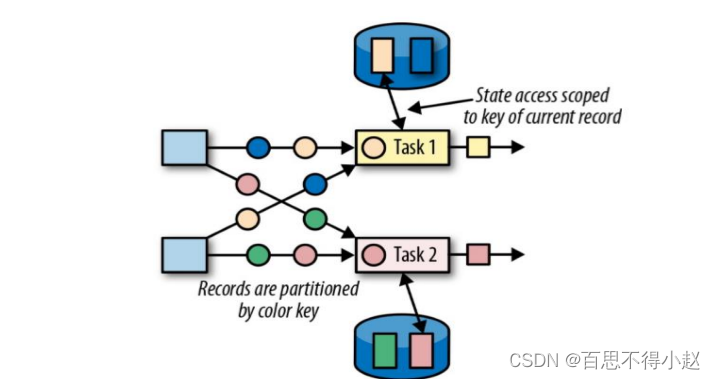
(此图来源于网络)
Flink 为键控状态提供三种基本数据结构:
值状态
- 将状态表示为单个的值。
列表状态
- 将状态表示为一组数据的列表
映射状态
- 将状态表示为一组 Key-Value 对
聚合状态(Reducing state & Aggregating State)
- 将状态表示为一个用于聚合操作的列表
代码如下:
public class StateTest2_KeyedState { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //设施并行度为1 env.setParallelism(1); DataStreamSource<String> inputStream = env.socketTextStream("localhost", 7777); DataStream<SensorReading> dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); // 定义一个有状态的Map操作 统计当前senser数据个数 SingleOutputStreamOperator<Integer> resultStream = dataStream.keyBy("id") .map(new MyKeyCouneMap()); resultStream.print(); env.execute(); } // 自定义RichMapFunction private static class MyKeyCouneMap extends RichMapFunction<SensorReading,Integer> { // 声明键控状态 private ValueState<Integer> KeyCouneState ; //private ListState listState; //private MapState mapState;// private ReducingState reduceState; @Override public void open(Configuration parameters) throws Exception { KeyCouneState = getRuntimeContext().getState(new ValueStateDescriptor<Integer>( "key-count",Integer.class )); // listState =getRuntimeContext().getListState(new ListStateDescriptor( // "list-count",String.class )); //mapState = getRuntimeContext().getMapState(new MapStateDescriptor( // "map-count",String.class,Double.class )); //reduceState =getRuntimeContext().getReducingState(new ReducingStateDescriptor( // "reducing-count",SensorReading.class //));class } @Override public Integer map(SensorReading sensorReading) throws Exception { // 读取状态 Integer count = KeyCouneState.value(); if (count==null){ count = 0; }else { count++; } // 更新状态,对状态赋值 KeyCouneState.update(count); return count; // listState //Iterable iterable = listState.get(); //for (String s : listState.get()) { // System.out.println(s); //} //listState.add("hello"); // mapState //mapState.get("1"); //mapState.put("2",12.3); } }}状态后端
状态的存储、访问以及维护,由一个可插入的组件决定,这个组件就叫做状态后端。状态后端主要负责两件事:本地的状态管理,以及将检查点(checkpoint)状态写入远程存储。状态后端总共有三种类型:
MemoryStateBackend
- 内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在TaskManager 的 JVM 堆上,而将 checkpoint 存储在JobManager 的内存中。特点:快速、低延迟,但不稳定。
FsStateBackend
- 将 checkpoint 存到远程的持久化文件系统(FileSystem)上,而对于本地状态,跟 MemoryStateBackend 一样,也会存在 TaskManager 的 JVM 堆上同时拥有内存级的本地访问速度,和更好的容错保证。
RocksDBStateBackend
- 将所有状态序列化后,存入本地的 RocksDB 中存储
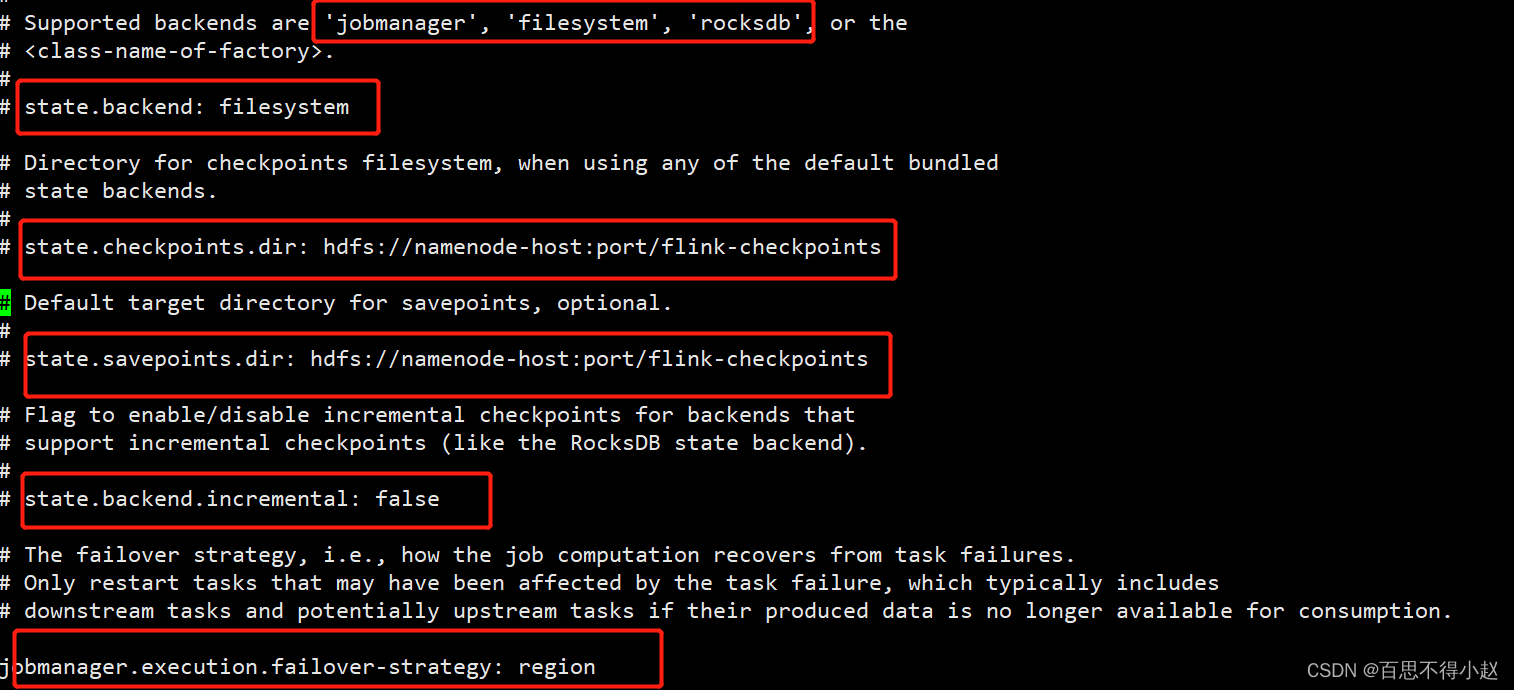
代码中配置状态后端:
public class StateTest4_FaultTolerance { public static void main(String[] args) throws Exception{ StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); // 状态后端配置 env.setStateBackend(new MemoryStateBackend()); env.setStateBackend(new FsStateBackend("")); DataStreamSource<String> inputStream = env.socketTextStream("localhost", 7777); DataStream<SensorReading> dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); env.execute(); }}flink配置文件中进行配置:
一个案例:
检查工业物联网传感器温度跳变,如果连续两个温度差值超过10度,就发出报警。
代码如下
public class StateTest3_ApplicationCase { public static void main(String[] args) throws Exception { StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); //设施并行度为1 env.setParallelism(1); DataStreamSource<String> inputStream = env.socketTextStream("localhost", 7777); DataStream<SensorReading> dataStream = inputStream.map(line -> { String[] fields = line.split(","); return new SensorReading(fields[0], new Long(fields[1]), new Double(fields[2])); }); // 定义一个flutmap操作,检测温度跳变输出报警 SingleOutputStreamOperator<Tuple3<String, Double, Double>> resultStream = dataStream.keyBy("id") .flatMap(new TempChangeWarring(10.0)); resultStream.print(); env.execute(); } private static class TempChangeWarring extends RichFlatMapFunction<SensorReading, Tuple3<String, Double, Double>> { // 设置温度跳变的阈值 private Double threshold; public TempChangeWarring(Double threshold) { this.threshold = threshold; } // 定义状态,保存上一次温度值 private ValueState<Double> lastTempState; @Override public void open(Configuration parameters) throws Exception { lastTempState = getRuntimeContext().getState(new ValueStateDescriptor<Double>( "lastTemp", Double.class )); } @Override public void flatMap(SensorReading value, Collector<Tuple3<String, Double, Double>> out) throws Exception { // 获取状态 Double lastTemp = lastTempState.value(); // 如果不为null 就计算两次温度差 if (lastTemp != null) { Double diff = Math.abs(value.getTemperature() - lastTemp); if (diff>=threshold){ out.collect(new Tuple3<>(value.getId(),lastTemp,value.getTemperature())); } } // 更新状态 lastTempState.update(value.getTemperature()); } @Override public void close() throws Exception { lastTempState.clear(); } }}

