C++11多线程 内存序(std::memory_order_seq_cst )
C++11多线程内存序
- 内存模型
-
- 为什么要有内存模型
-
- C++11的内存模型种类
- 各个内存模型介绍及代码测试
-
- memory_order_seq_cst 顺序一致性模型
内存模型
内存模型定义了对于并发程序执行的任何给定写操作集允许读操作返回的可能值,从而定义了共享变量的基本语义。
换句话说,内存模型指定了程序读写操作的一组允许输出,并限制了一个实现只产生(但至少一个)这样的允许执行。
更具体一点的说:
内存模型可以由两部分构成:编程语言内存模型和硬件内存模型。
编程语言内存模型: 定义在将程序转换为二进制代码时允许编译器执行的优化、内存访问重写和重新排序。
硬件内存模型: 定义允许特定硬件架构执行的优化和内存访问重新排序。
为什么要有内存模型
多线程环境下,如果保持顺序一致性会降低CPU性能,代价很大,不利于程序优化。
如果想要进行程序的优化,需要编译器和CPU之间遵守相同的约定,这个约定便是内存模型
C++11的内存模型种类
C++11提供了6种内存序
enum memory_order { memory_order_relaxed, memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel, memory_order_seq_cst};各个内存模型介绍及代码测试
memory_order_seq_cst 顺序一致性模型
代码测试
#include #include #include #include #include #include #include #include #include "ScopeThread.h"#include "template.h"#include "parallel_accumulate.h"#include "sequential_quick_sort.h"std::atomic<bool> x, y;std::atomic<int> z;void write_x() { x.store(true, std::memory_order_seq_cst);}void write_y() { y.store(true, std::memory_order_seq_cst);}void read_x_then_y() { while (!x.load(std::memory_order_seq_cst)) { } if (y.load(std::memory_order_seq_cst)) { ++z; }}void read_y_then_x() { while (!y.load(std::memory_order_seq_cst)); if (x.load(std::memory_order_seq_cst)) { ++z; }}int main() { TimeSlap timeSlap; x = false; y = false; z = 0; std::thread a(write_x); std::thread b(write_y); std::thread c(read_x_then_y); std::thread d(read_y_then_x); a.join(); b.join(); c.join(); d.join(); for (int i = 0; i < 100000; ++i) { assert(z.load() != 0); } auto count_time = timeSlap.end(); std::cout << "消耗" << count_time << "秒" << std::endl; return 0;}测试发现assert 永远为真.
分析:
由测试结果可知
如果std::memory_order_seq_cst 同时存在store(写)和load(读)那么顺序一致性模型 保证写必须在读之前发生,因此 当x先store后 如果y = false 那么顺序一致性保证 x.store->x.load ->y.load->y.store->y.load
顺序一致性 可以理解为如下过程:
对于每一步,随机选择一个线程,然后执行该线程执行的下一步(即程序或编译顺序)。 重复这个过程,直到整个程序终止。 这实际上等效于按(程序或编译)顺序执行所有线程的所有步骤,并以某种方式交错它们,从而产生所有步骤的单一总顺序。
不允许重新排序线程的步骤。 因此,无论何时访问对象,都会检索按此顺序存储在对象中的最后一个值。 可以理解为这种交织的执行被称为顺序一致。
关于上述代码利用上述解释可参考如下:
- 首先随机选择一个线程b执行,此时y为true
- 随机选择下一个线程a执行,此时x为true
- 随机选择c线程执行,z为1
- 随机选择d执行,z为2
这个过程是全局一致的,因此最后z为2
或者上述也可能存在其他的顺序,譬如:
- 随机选择线程c执行,此时x为false,线程c一直循环
- 随机选择线程d执行,此时y为fasle,线程d一直循环
- 随机选择线程a执行,此时x为true
- 随机选择线程c执行,此时y为false,x为true,z为0
- 随机选择线程b执行,此时y为true,x为true
- 随机选择线程d执行,此时z为1
无论选择何种执行顺序,顺序一致性均保证所有线程的执行语句全局一致,不会存在重排。
顺序一致性是所有内存序中性能最差的,且目前没有CPU架构支持顺序一致性模型。
再最后,补充一个《C++ Concurrency in Action》关于上述代码的示意图,并讲解一下改图的含义
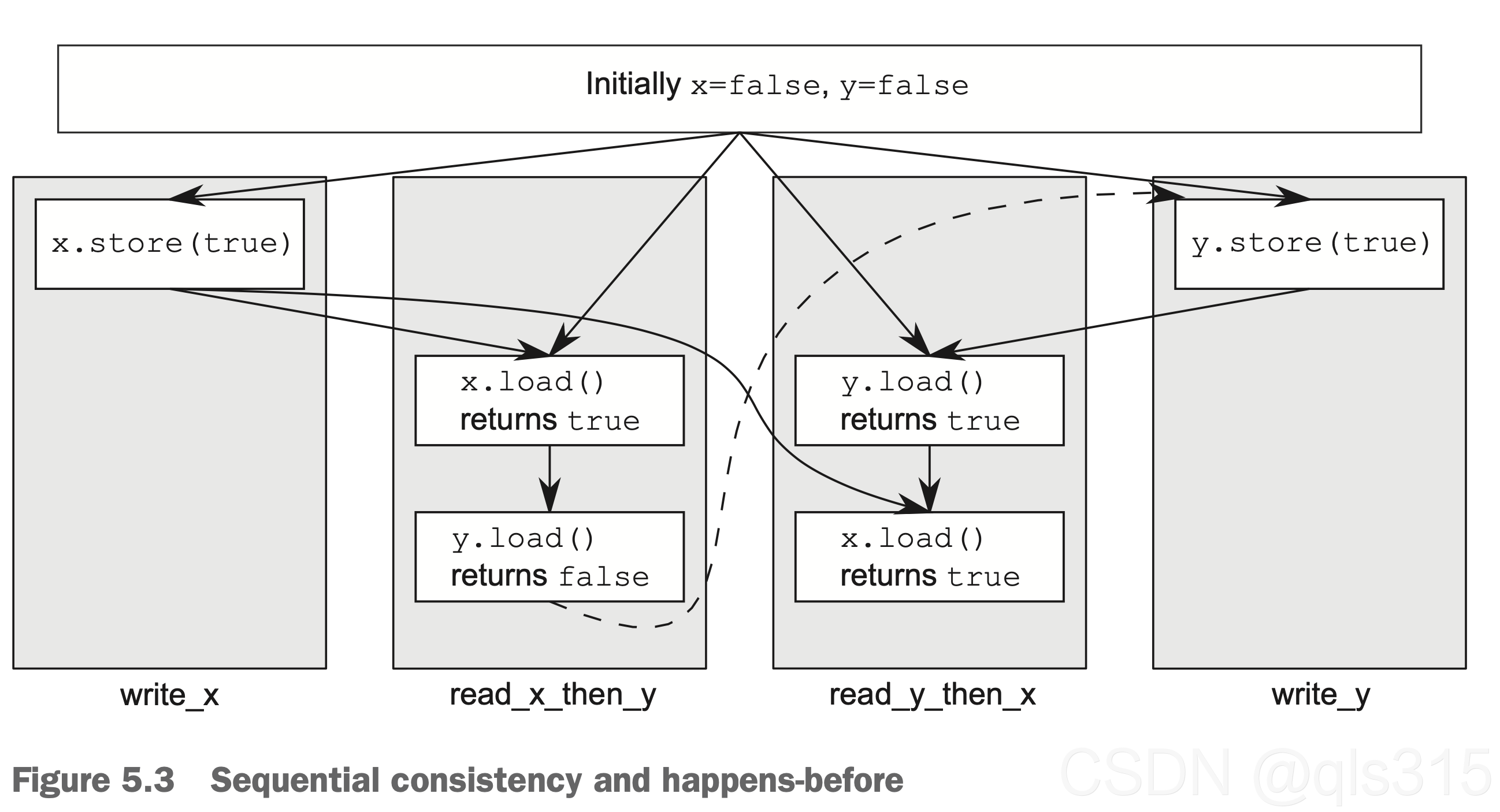
书中,该图是在此情景下所作:
程序首先看见x为true,y为false的情况下
结合本文上述所讲,相信对该图应该能很明白了。
系列文章:
C++多线程 内存序(std::memory_order_relaxed)
C++多线程 内存序(std::memory_order_acquire/release)
C++多线程 内存序(std::memory_order_consume)
C++多线程 release sequence
 开发者涨薪指南
开发者涨薪指南  48位大咖的思考法则、工作方式、逻辑体系
48位大咖的思考法则、工作方式、逻辑体系

