C++并发编程--第三章--线程间共享数据
目录
0. 引言
1. 线程间共享数据存在的问题
2. 利用锁(mutex)保护共享数据
2.1 使用C++11中的std::mutex
2.2 std::lock_guard与std::unique_lock
2.3 构建用于保护数据的代码
2.4 发现接口间的竞争
a. 传递一个引用作为pop()方法的形参
b. 产生一个无异常拷贝构造函数或者移动拷贝构造函数
c. 返回pop元素的指针
d. 组合a与b或者a与c
2.5 线程安全stack的实现
2.6 锁的粒度的选择
2.7 死锁
2.7.1 存在的问题和解决方案
2.7.2 避免死锁的一些指导方针
3. 保护共享数据的其他方法
3.3.1 在初始化时同步共享数据
3.3.2 保护更新频率低的共享数据
0. 引言
自己目前在学习C++并发编程,在阅读英文版的并发编程实践这本书时,发现将其翻译总结一下更能加深印象,便将其翻译和总结一下,写下来方便以后复习。
1. 线程间共享数据存在的问题
所有线程间共享数据的问题,都是修改数据导致的(竞争条件)。如果所有的共享数据都是只读的,就没问题,因为一个线程所读取的数据不受另一个线程是否正在读取相同的数据而影响。(引用[读书笔记]C++并发编程实战_xy_cpp的博客-CSDN博客_c++并发编程实战)。
2. 利用锁(mutex)保护共享数据
2.1 使用C++11中的std::mutex
在C++11中,你可以通过std::mutex的构造函数创建一个std::mutex实例,通过调用lock成员方法对该实例加锁,调用unlock成员方法对该实例解锁。但是在实际操作过程中,不建议直接调用std::mutex成员函数,因为代码可能存在异常或者程序员会遗漏unlock成员,导致死锁。
在C++11中,通常利用std::lock_guard模板类进行mutex的上锁与解锁。 在std::lock_guard的构造函数中对mutex进行加锁, 在其析构函数中进行解锁。
在C++11中,也提供了std::unique_lock模板类进行mutex的上锁与解锁,std::unique_lock比std::lock_guard更灵活,但效率会稍微低一下。
2.2 std::lock_guard与std::unique_lock
可参考C++11 std::unique_lock与std::lock_guard区别及多线程应用实例 - Boblim - 博客园
下面主要讲解一下std::unique_lock。
std::unique_lock并不一直拥有锁的所有权,也就是说std::unique_lock可以像std::unique_ptr一样转移其所有拥有资源的所有权。
std::unique_lock模板类的构造函数可以接收std::defer_lock或者std::adopt_lock作为第二参数,其使用方式如下:
std::mutex mutex_a;std::mutex mutex_b;int main() { std::unique_lock la(mutex_a, std::adopt_lock); std::unique_lock lb(mutex_b, std::defer_lock); return EXIT_SUCCESS;}std::adopt_lock指示la的构造函数对mutex_a锁进行加锁。
std::defer_lock指示lb的构造函数对mutex_b锁不进行加锁。
std::unique_lock内部存储某个flag变量,指示std::unique_ptr内部的mutex是否上锁,因此std::unique_ptr的效率低于std::lock_guard。
std::unique_lock的成员函数owns_lock可以获得std::unique_lock的flag标志。
std::mutex mutex_a;std::mutex mutex_b;int main() { std::unique_lock la(mutex_a, std::adopt_lock); std::cout << la.owns_lock() << std::endl; std::unique_lock lb(mutex_b, std::defer_lock); std::cout << lb.owns_lock() << std::endl; return EXIT_SUCCESS;}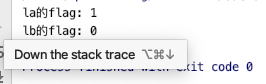
由上述结果也可以进一步说明std::adopt_lock与std::defer_lock的作用。
2.3 构建用于保护数据的代码
当类的所有成员函数在访问其成员变量前均上锁并且在其返回前能成功解锁,则一般认为对所有的调用者而言,类的成员变量能被很好的保护。但是该种场景有个例外,导致对数据成员的加锁保护失效。该例外便是:类的成员函数会返回被保护的类的成员变量的指针或者引用。
因此,在每个成员函数中利用std::lock_guard 保护数据并不一定能真正生效。检查类的成员函数是否返回被保护的数据的指针或者引用比较容易。只需要保证成员函数不会通过返回值或者out参数将被保护数据的指针或者引用传递给其调用者便可。
但是进一步考虑,虽然你可以保证成员函数不会传递被保护数据的指针或者引用,但是你无法保证成员函数调用的某个方法是否会传递被保护数据的指针或者引用。其例子如下:
class some_data{int a; std::string b;public: void do_something();};class data_wrapper{private: some_data data; std::mutex m;public: template void process_data(Function func) { std::lock_guard l(m); func(data); } };some_data* unprotected;void malicious_function(some_data& protected_data){ unprotected=&protected_data;}data_wrapper x;void foo(){ x.process_data(malicious_function); unprotected->do_something(); } 在这个例子中,类data_wrapper的成员data看起来被std::lock_guard保护,但是在foo()函数中调用了x.process_data(malicious_function)方法,而malicious_function函数的形参是some_data的引用,因此func便绑定到malicious_function导致类data_wrapper的成员data通过引用越过了std::lock_guard的保护,因此unprotected->do_something();便暴露在无锁保护的大环境下,如果在多线程环境下,基本上必然会产生未定义行为。
为了降低此种风险,你需要采纳下面的建议:无论你是通过成员函数返回被保护的数据,还是将他们存储在内存中,或者是将他们作为用户提供的函数的实参,都不要将他们的引用或者指针传递到锁的保护范围之外。
2.4 发现接口间的竞争
利用锁或者其他机制保护共享数据,但这并不意味着保护race conditions。你仍然需要确定数据是不是真正的被保护。考虑下面的std::stack容器适配器:
template<typename T,typename Container=std::deque >class stack{public:explicit stack(const Container&);explicit stack(Container&& = Container());template explicit stack(const Alloc&);template stack(const Container&, const Alloc&); template stack(Container&&, const Alloc&); template stack(stack&&, const Alloc&);bool empty() const;size_t size() const;T& top();T const& top() const;void push(T const&);void push(T&&);void pop();void swap(stack&&);template void emplace(Args&&... args);};除了构造函数和swap(), 你仅仅只能进行这五个动作:
push()一个新元素至stack,pop()一个元素出stack, 读stack顶元素--top(), 检查stack是否为空--empty(), 读stack中元素的个数--size()。
如果更改top()以使其返回副本而不是引用并使用互斥锁保护内部数据,则此接口本质上仍受竞争条件的影响 。 这个问题并不是基于互斥锁的实现所独有的。 这是一个接口问题,因此使用无锁实现时,竞争条件仍然会发生。
根本问题在于empty()和size()的结果并非完全真实。在多线程环境下,如果一个线程调用了empty()和size()后,其他的线程能够自由访问stack并且可能向其push元素,改变了empty()和size()的结果。
一般而言,当stack实例不可共享时,通过检查stack是否为空来获得其栈顶元素是安全的。其实现如下所示:
stack s; if(!s.empty()) { int const value=s.top(); s.pop(); do_something(value);}虽然上述代码在单线程环境是安全的,但是当stack为全局对象且在多线程环境下,上述代码便不在安全。这是因为在empty() 和 top()之间存在一定的间隙,在该时间间隔内可能其他线程调用了pop()方法,导致stack为空,此时top()便产生未定义行为。
这是一种经典的竞争条件,即使使用互斥量来保护堆栈内容也不能阻止这种情况。 这是接口固有的问题。
那么接口固有的竞争条件问题怎么解决呢?既然这个问题是由接口设计引发的,因此可以重新设计接口。
首先考虑最简单的方式:如果一个空栈进行top(), 则使top()抛出一个异常。虽然这是一个很直接的解决拌饭,但这会导致编程更加困难。这是因为即使堆栈非空,你也需要进行异常捕获。因此可以对empty()调用进行优化,以避免在堆栈空的情况下抛出异常的性能开销,但这并不是设计的必要部分。
进一步分析上述代码,会发现top()和pop()之间也存在潜在的竞争条件。如果stack的成员函数中被mutex加锁,则任何时候只能有一个线程能够运行stack的一个成员函数。因此这些成员函数的调用操作被串行化,但是do_something()的调用可能并发。下面列出了一种可能的执行过程:

由上述可知,多个线程间top()调用之间没有发生其他动作,因此多个线程可以看到相同的值。不仅如此,在top()和pop()之间也没其他动作发生。因此,上述操作序列会导致一个值被丢弃,一个值被处理两次。这是一个比empty()/top()竞争条件更加潜在的一种竞争条件。一般而言不会有什么错误发生,但是当产生bug后,虽然可以知道其由do_something()调用引起的,但也很难定位其详细原因。
由上分析知,需要对接口进行进一步设计。一种设计是将top()和pop()合并为一个动作,并用锁进行保护。Tom Cargill指出这个操作可能导致出现问题---如果拷贝堆栈上的对象,可能会导致异常产生。Herb Sutter 虽然从异常安全的角度相当全面地解决了这个问题,但是潜在的竞争条件会带来新的bug。
利用stack<vector> 来解释 拷贝堆栈上的对像为什么会抛出异常。
vector是一个动态容器,因此当你拷贝一个vector时,库必须从堆中分配更多的内存容纳vector的内容。如果系统负载沉重或存在大量资源限制,则此内存分配可能会失败,因此vector的拷贝构造函数可能会引发std :: bad_alloc异常。如果vector中很大,则便会产生这种问题。
如果将pop()函数定义为返回弹出的值,并将其从堆栈中删除,则可能会出现问题:仅在修改堆栈后,才会将弹出的值返回给调用方,但是复制数据以返回给调用方可能会引发异常。如果这种情况发生,则会导致被pop的对象丢失,它虽然从stack中pop了,但拷贝构造函数未能成功,std :: stack接口的设计者将操作分为两部分:获得top元素(top()),然后将其从堆栈中移除(pop()),这样,如果您不能安全地复制数据, 它停留在堆栈上。如果问题是缺少内存,则应用程序可以释放内存后重试。
不幸的是,正是由于这种将top()和pop()分成两部分导致了竞争条件的产生。幸运的是,通过牺牲一些性能,可以选择下面的方式来避免两步操作带来的竞争问题。
a. 传递一个引用作为pop()方法的形参
将pop()方法重新设计为pop(T& result), 即将需要被pop的值通过引用传递给调用者。
std::vector result;some_stack.pop(result);这在许多情况下都可以很好地工作,但是它有一个明显的缺点,那就是要求调用代码在调用之前构造堆栈值类型的实例,以便将其作为目标传递。 对于某些类型,这是不切实际的,因为构造实例在时间或资源上都很昂贵。对于其他类型,这并非总是可能的,因为构造函数需要的参数此时在代码中不一定可用。 最后,它要求存储的类型是可分配的。 这是一个重要的限制:许多用户定义的类型不支持分配,尽管它们可能支持移动构造甚至复制构造(并允许按值返回)。
b. 产生一个无异常拷贝构造函数或者移动拷贝构造函数
如果按值返回可以引发异常,则pop()仅存在异常安全问题。一些类型得拷贝构造函数默认不抛出异常,C++11引入了右值引用,因此更多的类型将有一个异常安全的移动拷贝构造函数。一个有效的选择是将线程安全堆栈的使用限制为可以通过值安全地返回而不会引发异常的那些类型。
虽然这样做是安全的但是并不理想。虽然利用模板类型std::is_nothrow_copy_constructible和std::is_nothrow_move_constructible 在编译时检测拷贝构造函数或者移动构造函数是否抛出异常,但这种方式很受限。用户自定义类型的拷贝构造函数可能更倾向与抛出异常。
c. 返回pop元素的指针
选择返回pop()的元素的指针而不是直接返回pop()的值。返回指针的优点是:指针的拷贝是异常安全的。缺点是需要管理为了存储对象所分配的内存资源。且对于简单类型(譬如整数),返回指针的开销要比返回值的更大。对于使用此选项的任何接口,优先选择智能指针std :: shared_ptr ; 它不仅避免了内存泄漏,而也能完全控制了内存分配方案,并且不必使用new和delete。 这对于优化目的可能是重要的:与原始的非线程安全版本相比,使用new在堆上分配对象将产生相当大的开销。
d. 组合a与b或者a与c
当然,你也可以灵活运用a和b的组合方案,或者a和c的组合方案
2.5 线程安全stack的实现
线程安全stack的实现如下:
#include #include struct empty_stack : std::exception { const char* what() const noexcept;};template class threadsafe_stack {public: threadsafe_stack(); threadsafe_stack(const threadsafe_stack&); threadsafe_stack& operator=(const threadsafe_stack&) = delete; void push(T new_value); std::shared_ptr pop(); void pop(T& value); bool empty();};该线程安全的堆栈结合了方案a和方案c, 重载了push()方法。由于pop()方法会抛出一个empty_exception异常,因此即使在empty()调用之后修改了堆栈,程序也能正常工作。
如c所述,堆栈使用std :: shared_ptr管理内存分配,并在需要时避免对new和delete的过多调用。以前堆栈的五个操作现在仅仅简化为三个,接口的简化可以更好的控制数据的安全性。 你可以确保互斥锁在整个操作过程中都被锁定。 以下清单显示了一个简单的实现,该实现是std :: stack 的包装。
#include #include #include #include struct empty_stack : std::exception { const char* what() const noexcept;};template class threadsafe_stack {private: std::stack data; mutable std::mutex mut;public: threadsafe_stack() {} threadsafe_stack(const threadsafe_stack& other) { std::lock_guard lock(other.mut); data = other.data; } threadsafe_stack& operator=(const threadsafe_stack&) = delete; void push(T new_value) { std::lock_guard lock(mut); data.push(std::move(new_value)); } std::shared_ptr pop() { std::lock_guard lock(mut); if (data.empty()) throw empty_stack(); const auto res = std::make_shared(data.top()); data.pop(); return res; } void pop(T& value) { std::lock_guard lock(mut); if (data.empty()) throw empty_stack(); value = data.top(); data.pop(); } bool empty() { std::lock_guard lock(mut); return data.empty(); }};上述实现了一个可拷贝的stack, 在拷贝构造函数内进行加锁然后拷贝内部stack。在这个stack的拷贝构造函数的实现中, 你不能通过成员初始化列表进行拷贝,因为你需要确保加锁生效。
2.6 锁的粒度的选择
考虑一个全局锁的场景,当你的共享数据用全局锁进行保护的时候,此时会出现什么问题呢?
显而易见:此时由于临界区比较大,当一个线程对共享数据加锁时,其他线程需要等待该线程释放锁才能继续进行,而此时会导致其他线程等待的时间很长。
这也是不能在对I/O 操作加锁的一个原因,会导致其他线程获得锁的等待时间增加。
那么如何解决这个问题呢?同样,我们可以考虑将临界区进行划分,也即将锁的粒度进行划分,用多个锁对不同的操作进行加锁。
如果你最终必须为一个给定的操作锁定两个或多个互斥锁,那么潜伏着另一个潜在的问题:死锁。 这几乎是与竞争条件相反的结果:不是两个线程争分夺秒,而是每个线程都在等待另一个线程,所以两者都没有取得任何进展
2.7 死锁
2.7.1 存在的问题和解决方案
死锁是指两个或两个以上的进程在执行过程中,由于竞争资源或者由于彼此通信而造成的一种阻塞的现象,若无外力作用,它们都将无法推进下去。此时称系统处于死锁状态或系统产生了死锁,这些永远在互相等待的进程称为死锁进程。(引用百度百科:死锁)。
对于避免死锁问题的共同方案是:一固定的顺序进行加锁。如果你总是在B之前对A进行加锁,那么将不会产生死锁。有时这很简单,因为互斥锁具有不同的用途,但有时却不那么简单,例如互斥锁分别保护同一类的单独实例时。考虑下面这个场景:在同一类的两个实例之间交换数据。 为了确保正确交换数据而不受并发修改的影响,必须锁定两个实例上的互斥锁。然而这个操作将可能导致死锁。为什么会导致死锁呢?
我们假设交换数据的操作swap的声明如下:
void swap(A& a1, A& a2);在C++中,对于函数形参的调用顺序没有明确的规定,因此如果在线程1中调用swap时,a1先加锁; 而在线程2中调用swap时,a2先加锁,那么此时便产生了死锁。
C++11标准库提供的std::lock函数可以解决这个问题。std::lock函数一次能够同时锁住两个以上的锁,并且不会产生死锁。应用std::lock至swap操作的例子如下:
#include class some_big_object;void swap(some_big_object& lhs, some_big_object& rhs);class A {private: some_big_object some_detail; std::mutex _m;public: A(some_big_object const& sd) : some_detail(sd) {} friend void swap(A& lhs, A& rhs) { if (&lhs == &rhs) return; std::lock(lhs._m, rhs._m); std::lock_guard lock_a(lhs._m, std::adopt_lock); std::lock_guard lock_b(rhs._m, std::adopt_lock); swap(lhs.some_detail, rhs.some_detail); }};分析上述程序,首先确保是同一个类的两个不同实例,防止同一个锁被上锁两次。然后调用std::lock对两个锁进行加锁。利用两个std::lock_guard对象分别接管锁,前面介绍过std::adopt_lock参数是为了告诉编译器,不需要在std::lock_guard的构造函数中对所获得的锁进行加锁,因为该锁已经由std::lock进行了加锁。利用std::lock_guard可以确保在通常情况下(受保护的操作可能会引发异常)在函数退出时正确解锁互斥锁。
值得注意的是,std :: lock在对lhs.m或rhs.m加锁时可能会抛出异常;此时,异常会由std::lock广播出去。如果std :: lock已成功获取一个互斥锁的锁,并且在尝试获取另一个互斥锁的锁时抛出了异常,则该第一个锁会自动释放:std :: lock提供“全有或全无”语义 关于锁定提供的互斥锁。
当你想同时对两个以上锁进行加锁时,std::lock可以帮你避免产生死锁。但是当你想要分开对每个锁加锁时,std::lock便无能为力了。此时,便必须依靠开发者的经验来避免死锁的产生。这并不容易:死锁是多线程代码中遇到的最棘手的问题之一,并且通常是无法预测的,大多数情况下一切正常。 但是,有一些相对简单的规则可以帮助您编写无死锁的代码。
2.7.2 避免死锁的一些指导方针
3. 保护共享数据的其他方法
如果共享数据仅仅在初始化时防止并发访问,在初始化后便可以安全的访问。如果此时对该共享数据加锁,会导致程序性能降低,因此需要某种替代措施解决这种问题。C++标准库提供了解决该场景的机制。
3.3.1 在初始化时同步共享数据
由单线程中的延迟初始化代码说起:
std::shared_ptr resource_ptr;void foo(){ if(!resource_ptr) { resource_ptr.reset(new some_resource); } resource_ptr->do_something();}这段代码在单线程环境下可以正常工作,但其在多线程环境下便存在数据竞争的风险,因此需要对其进行加锁。加锁版本如下:
std::shared_ptr resource_ptr;std::mutex resource_mutex;void foo(){ std::unique_lock lk(resource_mutex); if(!resource_ptr) { resource_ptr.reset(new some_resource); } lk.unlock(); resource_ptr->do_something();} 这个版本的实现会导致每个线程均等待锁有效后才去检查资源是否初始化,由于等待锁会空耗cpu时间,因此会降低程序的效率。对其的改进,便是利用 双重检查锁定模式,其实现如下:
void undefined_behaviour_with_double_checked_locking(){ if(!resource_ptr) { std::lock_guard lk(resource_mutex); if(!resource_ptr) { resource_ptr.reset(new some_resource); } } resource_ptr->do_something();} 这个模式具有潜在的数据竞争问题,这是因为读resource_ptr不在锁的保护范围之内。这会导致在线程A中的some_source可能被线程B中some_resource覆盖,导致线程A中的some_resource失校,因此会导致do_something产生未定义行为。
C++标准库为了解决这个问题引入了std::once_flag和std::call_once。与使用mutex然后检查指针是否为空不同,std::call_once是线程安全的,当std::call_once返回时,指针便被正确初始化。
std::once_flag存储了需要被同步化的数据,每个std::once_flag实例代表了一个不同的初始化。
用std::call_once实现上述程序如下:
std::shared_ptr resource_ptr;std::once_flag resource_flag;void init_resource(){ resource_ptr.reset(new some_resource); } void foo() { std::call_once(resource_flag,init_resource); resource_ptr->do_something();}
