【开卷数据结构 】还不会实现堆吗?图文并茂帮助你深入理解堆
目录
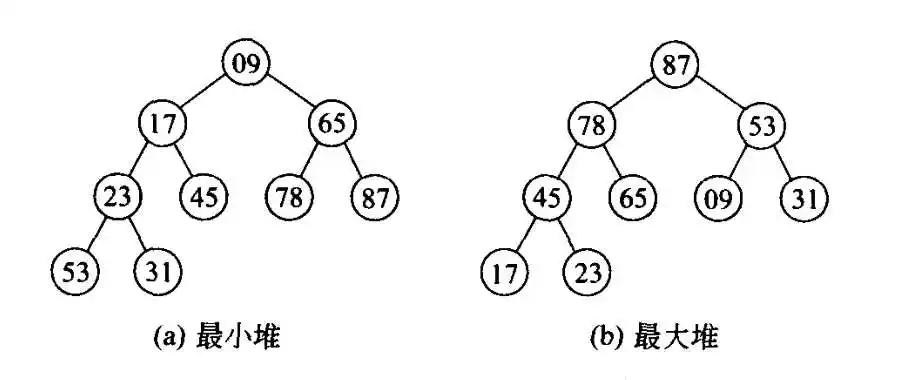
🌺最大堆与最小堆
🍁最大堆与最小堆的定义
🌺最大堆的操作
🍁最大堆的创建
💬 代码演示
🍁最大堆的插入
🔺算法分析
💬 代码演示
🍁最大堆的删除
🔺算法分析
💬 代码演示
🌺堆排序
🔺算法分析
💬 代码演示

🌺最大堆与最小堆
🍁最大堆与最小堆的定义
Q:什么是最大堆
A:最大堆是指在树中,如果一个结点有儿子结点,其关键字值都不小于其儿子节点的关键字值。最大堆是一棵完全而二叉树,也是一颗最大树。
Q:什么是最小堆
A:最小堆是指在树中,如果一个结点有儿子结点,其关键字值都不大于其儿子节点的关键字值。最小堆是一棵完全而二叉树,也是一颗最小树。
注意:最小树的根结点的关键字是树中元素最小的,而最大树的根结点是树中关键字值最大的。
可以发现,最大堆和最小堆十分相似,下文中我们就只研究最大堆。
当我们把最大堆看成抽象数据型时,它非常的简单,仅有以下3个操作:
- 创建空堆
- 把新元素插入堆中
- 从队中删除最大元素
🌺最大堆的操作
🍁最大堆的创建
由于堆是一个完全二叉树,可以使用数组存储来表示。我们可以这样来创建最大堆
💬 代码演示
#define MAX_ELEMENTS 200 //最大堆大小+1#define HEAP_FULL(n) (n==MAX_ELEMENTS-1)#define HEAP_EMPTY(n) (!n)typedef struct{int key;}element;element heap[MAX_ELEMENTS];int n=0;
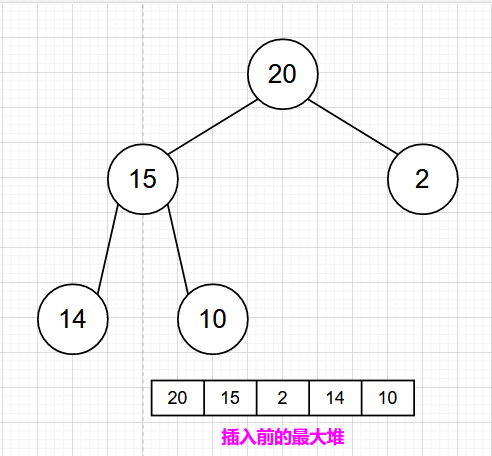
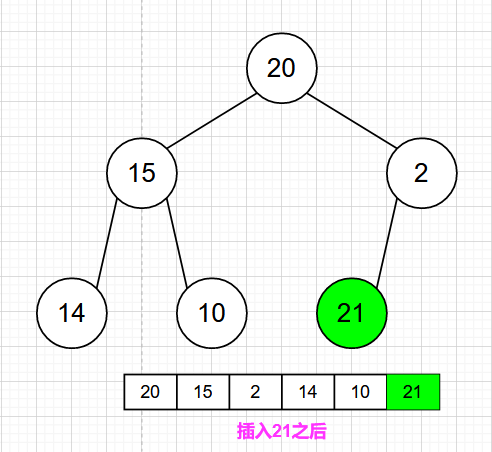
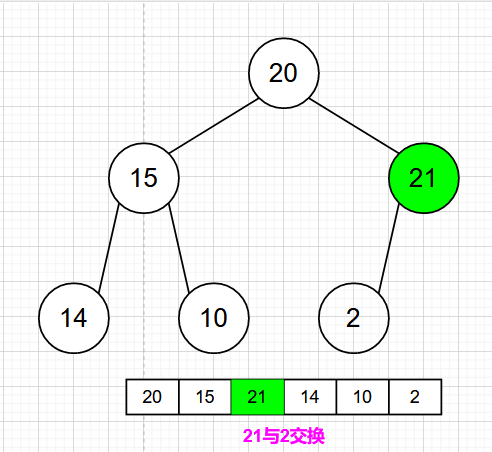
🍁最大堆的插入
🔺算法分析
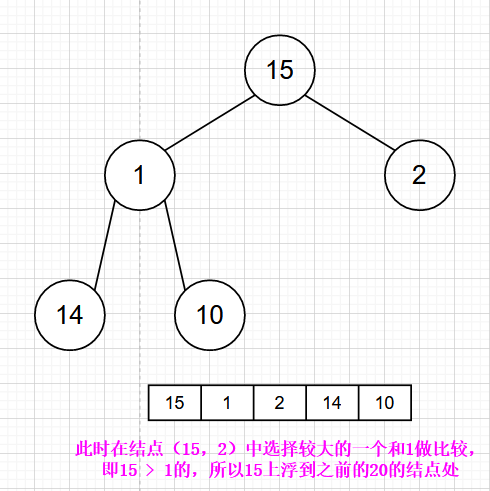
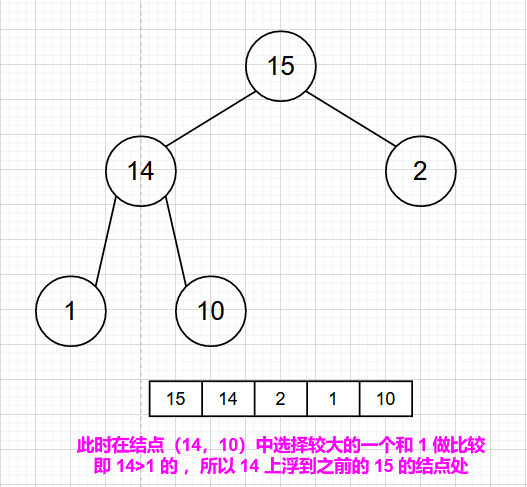
最大堆的插入操作可以简单看成是“结点上浮”。当我们在向最大堆中插入一个结点时,我们必须满足完全二叉树的标准,那么被插入结点的位置的是固定的。而且要满足父结点关键字值不小于子结点关键字值,那么我们就需要去移动父结点和子结点的相互位置关系。
可以参考下面的图示进行理解
💬 代码演示
1)首先检查堆是否满,如果不满,设 i 等于新堆的大小(n+1)。
2)使用 while 循环从最大堆的新叶子结点开始,沿着根结点的路径走。
3)一直到根结点或者位置 i ,使其父结点 i/2 的值不小于要插入的值。
void insert_max_heap(element item ,int *n){//将数插入当前大小为 n 的最大堆中 if(HEAP_FULL(*n)){ return; } int i = ++(*n); while((i != 1) && (item.key>heap[i/2].key)){ heap[i] = heap[i/2]; i/=2; } heap[i]=item;}
🍁最大堆的删除
🔺算法分析
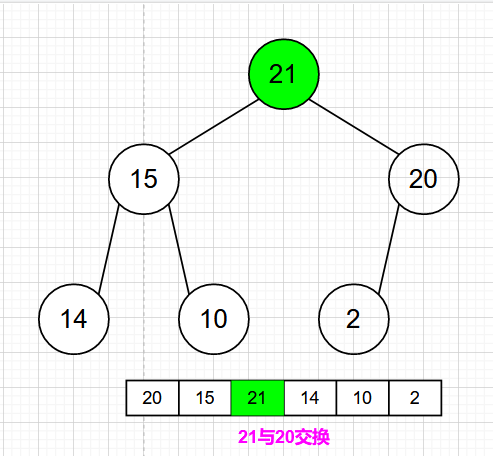
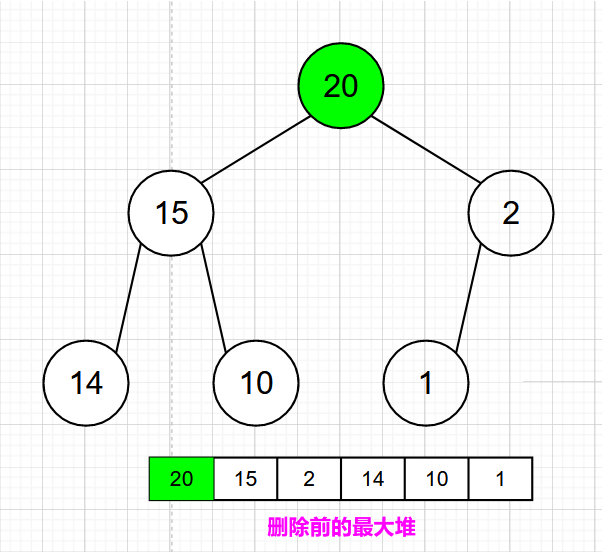
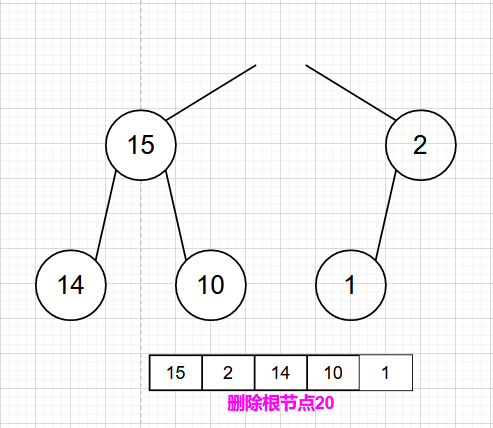
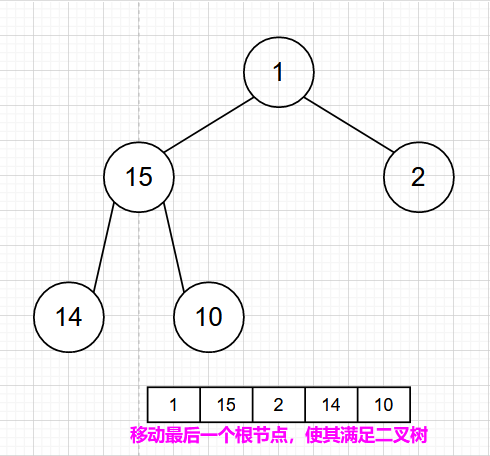
最大堆的删除操作,总是从堆的根结点删除元素。同样根元素被删除之后为了能够保证该树还是一个完全二叉树,我们需要来移动完全二叉树的最后一个结点,让其继续符合完全二叉树的定义,从这里可以看作是最大堆最后一个结点的下沉。
可以参考下面的图示进行理解
现在看来该二叉树虽然是一个完全二叉树,但是它并不符合最大堆的相关定义。我们要在删除完成之后,该完全二叉树依然是最大堆。因此就需要我们来做一些相关的操作。
💬 代码演示
- 1)首先删除最大堆的根结点
- 2)根结点被删除之后,为了能够保证该树还是一个完全二叉树,我们应该移动完全二叉树的最后一个结点,让其继续符合完全二叉树的定义。这里可以看作是最大堆最后一个结点的下沉
- 3)该二叉树虽然是一个完全二叉树,但是它并不符合最大堆的相关定义,我们在左右结点中选择大的一方和下沉的结点比较,令大的一方上浮。
- 4)重复步骤 3 ,直到到达叶子结点。
element delete_max_heap(int *n){int parent, child;element temp, item;temp = heap[--*n];item = heap[1];parent = 1,child=2;for(;child <= *n; child = child * 2){if( (child < *n) && heap[child].key = heap[child].key){ break; } heap[parent] = heap[child];//这就是上图中第二步和第三步中黄色部分操作 arent = child;// 这其实就是一个递归操作,让parent指向当前子树的根结点 }heap[parent] = temp;return item;}
🌺堆排序
🔺算法分析
通过上文介绍的最大堆的插入算法和删除算法可以直接得到一个时间复杂度为 O(nlogn) 的排序算法。
- 1)将n个数插入到一个初始为空的堆中,构建出最大堆。
- 2)整个序列的最大值就是堆顶的根结点。
- 3)将其与末尾元素进行交换,此时末尾就为最大值
- 4)将剩余元素重新构造成一个最大堆,这样会得到剩余元素的次小值。
- 5)如此反复执行,便能得到一个有序序列了。
可以参考下面的图示进行理解
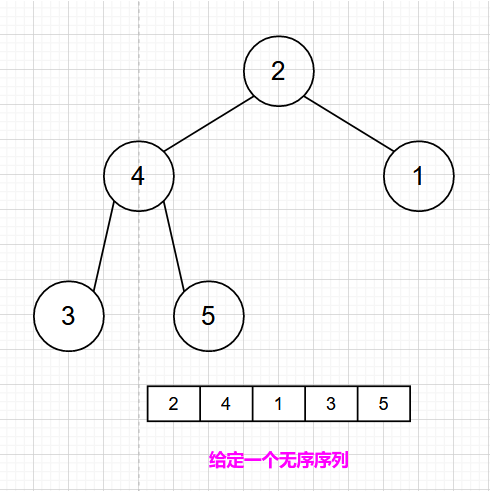
根据二叉树的结构与性质,我们可以推理出来最后一个非叶子节点的索引就是 【arr.len / 2 -1】,我们从最后一个非叶子结点开始,从左至右,从下至上进行调整。
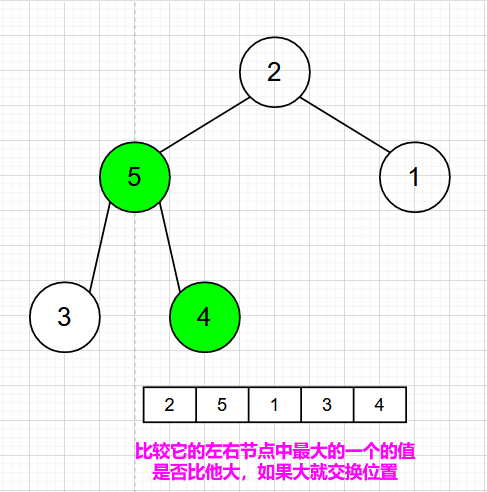
这里对非叶子结点进行判断,交换【4,5】
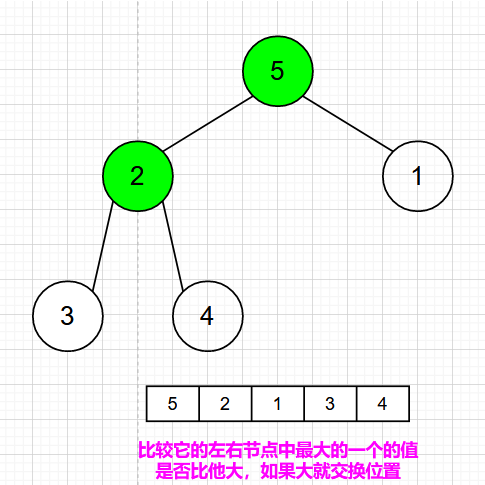
对下一个非叶子结点进行判断,交换【5,2】
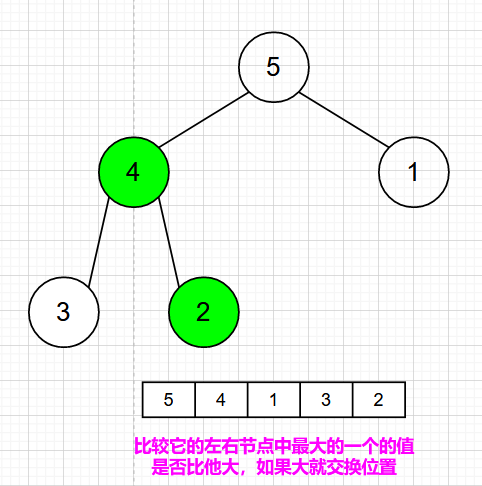
交换导致了子根【2,3,4】结构混乱,进行调整,交换【2,4】
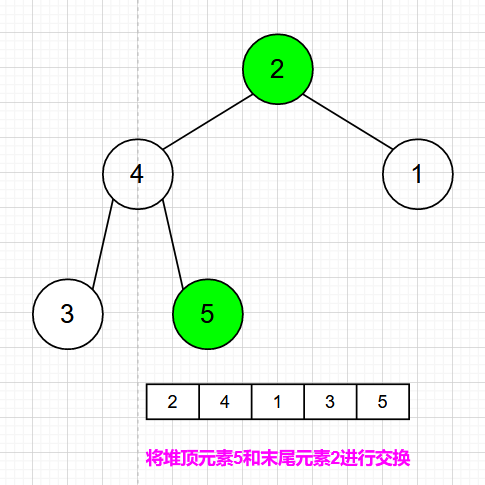
我们构造出来一个最大堆,下面来进行排序,先将顶点元素5与末尾元素2交换位置,此时末尾数字为最大值。
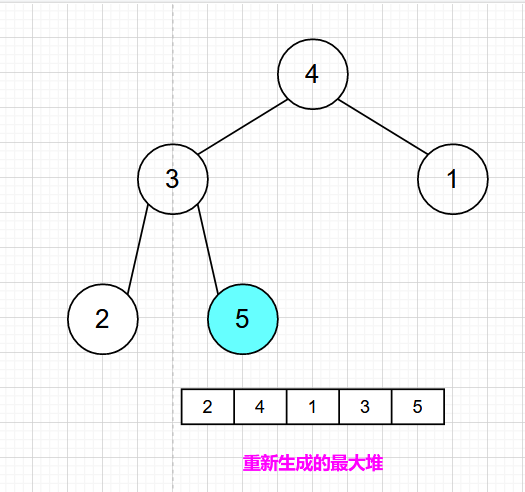
排除已经确定的最大元素,将剩下元素重新构建最大堆
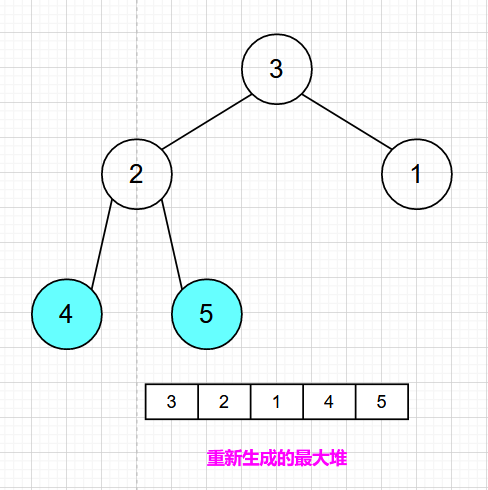
再将堆顶元素4与末尾元素2进行交换,再重新构建最大堆
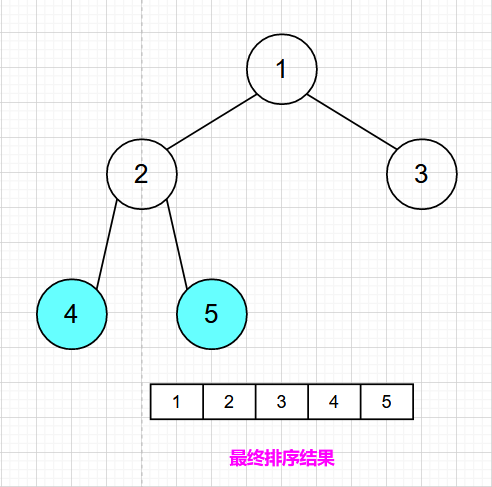
重复上述操作,得到最终排序结果
💬 代码演示
void heapSort(int[] arr) { //构造最大堆 heapInsert(arr); int size = arr.length; while (size > 1) { //固定最大值 swap(arr, 0, size - 1); size--; //构造大根堆 heapify(arr, 0, size); }}//构造最大堆(通过新插入的数上升)void heapInsert(int[] arr) { for (int i = 0; i arr[fatherIndex]) { //交换当前结点与父结点的值 swap(arr, currentIndex, fatherIndex); //将当前索引指向父索引 currentIndex = fatherIndex; //重新计算当前索引的父索引 fatherIndex = (currentIndex - 1) / 2; } }}//将剩余的数构造成最大堆(通过顶端的数下降)void heapify(int[] arr, int index, int size) { int left = 2 * index + 1; int right = 2 * index + 2; while (left < size) { int largestIndex; //判断孩子中较大的值的索引(要确保右孩子在size范围之内) if (arr[left] < arr[right] && right arr[largestIndex]) { largestIndex = index; } //如果父结点索引是最大值的索引,那已经是最大堆了,则退出循环 if (index == largestIndex) { break; } //父结点不是最大值,与孩子中较大的值交换 swap(arr, largestIndex, index); index = largestIndex; left = 2 * index + 1; right = 2 * index + 2; }} //交换数组中两个元素的值void swap(int[] arr, int i, int j) { int temp = arr[i]; arr[i] = arr[j]; arr[j] = temp;}