Python模糊基础点--引用变量与可变、非可变类型、lambda表达式、高阶函数
目录
- 字典加入元素的一个方法
- 引用变量与可变、非可变类型
-
- 变量在内存底层的存储形式
- 验证Python中变量的引用关系
- 把一个变量赋予给另外一个变量的影响
- 可变、非可变类型
-
- 非可变类型
- 可变类型
- 如何区分类型是可变还是不可变?
-
- 0x1
- 0x2
- lambda表达式
-
- Talk is cheap, show me the code
-
- 带默认参数的lambda表达式
- 不定长参数:可变参数*args
- 不定长参数:可变参数kwargs
- 带if判断的lambda表达式
- 列表数据+字典数据排序
- 高阶函数
-
- map函数
- reduce()函数
- filter()函数
字典加入元素的一个方法
d = {}d['1'] = 2d[1] = 3print(d)
对于列表是不被允许这样做的:
l = []l[0] = 1
引用变量与可变、非可变类型
变量在内存底层的存储形式
a = 10
第一步:首先在计算机内存中创建一个数值10(占用一块内存空间)
第二步:在栈空间中声明一个变量,如a
第三步:把数值10的内存地址赋予给变量小a,形成所谓的== “引用关系” ==
验证Python中变量的引用关系
使用内置方法id(),返回对象的内存地址。
a = 10print(id(a))
把一个变量赋予给另外一个变量的影响
a = 10b = aprint(id(a))print(id(b))b = 20print(a)print(id(a))print(id(b))
总结:不可变数据类型(数值)在赋值以后,其中一个值的改变不影响另外一个变量,因为两者指向空间地址不同。
此时有一个概念叫做:不可变数据类型。接下来,我们来看看,什么是不可变数据类型,什么是可变数据类型。
可变、非可变类型
非可变类型
-
数值(int整型、float浮点类型)
-
bool类型(True和False)
-
字符串类型(str)
-
元组(tuple 1,2,3)
可变类型
-
列表(list [1, 2, 3])
-
字典(dict {key:value})
-
集合(set {1, 2})
如何区分类型是可变还是不可变?
0x1
l = []print(id(l))l.append(1)print(id(l))a = 10print(id(a))a = 20print(id(a))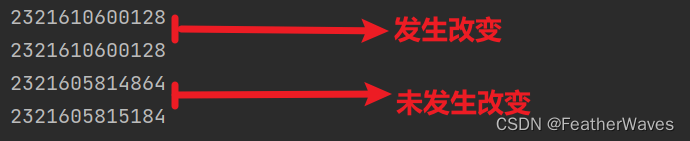
结论:
- 可变类型就是在内存中,其内存地址一旦固定,其值是可以发生改变的。
- 非可变类型就是在内存中,内存地址一旦固定,其值就没办法发生任何改变了。
0x2
def run1(l): l.append(1)l = []run(l)print(l)def run2(v): v = 10v = 20run2(v)print(v)
结论:
- 可变类型在函数中,如果在全局或局部中对可变类型进行增删改操作,其外部和内部都会受到影响。
- 不可变类型在函数中,局部或全局的改变对外部和内部都没有任何影响。
lambda表达式
lambda可以有效地减少代码量。
Talk is cheap, show me the code
def add(a, b): return a + bprint(add(1, 2))fn = lambda a, b: a + bprint(fn(1, 2))
带默认参数的lambda表达式
fn = lambda a, b, c=3 : a + b + cprint(fn(1, 2))
不定长参数:可变参数*args
fn1 = lambda *args : argsprint(fn1(1, 2, 3))
不定长参数:可变参数kwargs
fn2 = lambda kwargs : kwargsprint(fn2(name='ll', age=20))
带if判断的lambda表达式
fn = lambda a, b : a if a > b else bprint(fn(1, 2))
列表数据+字典数据排序
知识点:列表.sort(key=排序的key索引, reverse=True)
students = [ {'name': 'a', 'age': 20}, {'name': 'b', 'age': 19}, {'name': 'c', 'age': 22}]# 按name值升序排列students.sort(key=lambda x: x['name'])print(students)# 按name值降序排列students.sort(key=lambda x: x['name'], reverse=True)print(students)# 按age值升序排列students.sort(key=lambda x: x['age'])print(students)
高阶函数
把函数作为参数传入,这样的函数称为高阶函数,高阶函数是函数式编程的体现。函数式编程就是指这种高度抽象的编程范式。其实也是为了提高代码的复用。
def add_abs(a, b): return abs(a) + abs(b)def add_round(a, b): return round(a) + round(b)print(add_abs(-1, -2))print(add_round(1.1, 2.6))通过使用高级函数的方式:
def add(a, b, f): return f(a) + f(b)print(add(-1, -2, abs))print(add(1.1, 2.7, round))map函数
map(func, lst),将传入的函数变量func作用到lst变量的每个元素中,并将结果组成新的列表(Python2)/迭代器(Python3,如果要转换为列表, 可以使用 list() 来转换。)返回。
l = [1, 2, 3]print(list(map(lambda x: x 2, l)))
reduce()函数
reduce(func,lst),其中func必须有两个参数。每次func计算的结果继续和序列的下一个元素做累加计算。
注意:reduce()传入的参数func必须接收2个参数。
import functoolsl = [1, 2, 3]print(functools.reduce(lambda a, b: a + b, l))
filter()函数
filter(func, lst)函数用于过滤序列, 过滤掉不符合条件的元素, 返回一个 filter 对象。如果要转换为列表, 可以使用 list() 来转换。参数func()是个布尔函数。
l = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]print(list(filter(lambda x: x % 2 == 0, l)))

