Scrapy源码学习-ItemLoader
item
在scrapy项目结构中,有一个items.py的文件,在里面是专门存放和定义抓取数据字段的。这当然不是强制性要求的。但这种数据字段的定义能够更好地约束未来抓取字段,并且开发者可以一目了然的知道抓了哪些数据。
比如我们需要抓取影视网站,可以这样定义:
class MovieItem(scrapy.Item): title = scrapy.Field() url = scrapy.Field() cover = scrapy.Field() actors = scrapy.Field() column = scrapy.Field() ……继承的父类scrapy.Item有一个metaclass元类,元类的讲解会在以后的文章中展开[挖坑]。
class Item(DictItem, metaclass=ItemMeta): ……它所做的,就是将继承scrapy.Item的类中所有属性类型为Field的加载到fields字典中。
摘选scrapy/item.py
class ItemMeta(_BaseItemMeta): def __new__(mcs, class_name, bases, attrs): …… for n in dir(_class): v = getattr(_class, n) # 当属性类型为Field时候,加入fields字段 if isinstance(v, Field): fields[n] = v elif n in attrs: new_attrs[n] = attrs[n] new_attrs['fields'] = fields …… return super().__new__(mcs, class_name, bases, new_attrs)一旦爬虫数据字段出现非MovieItem类定义的属性时,比如由于拼写失误,导致title字段写成了tilte,则会产生KeyError: 'tilte'的报错。
相较于Python内置的字典,更加提升了程序的健壮性。
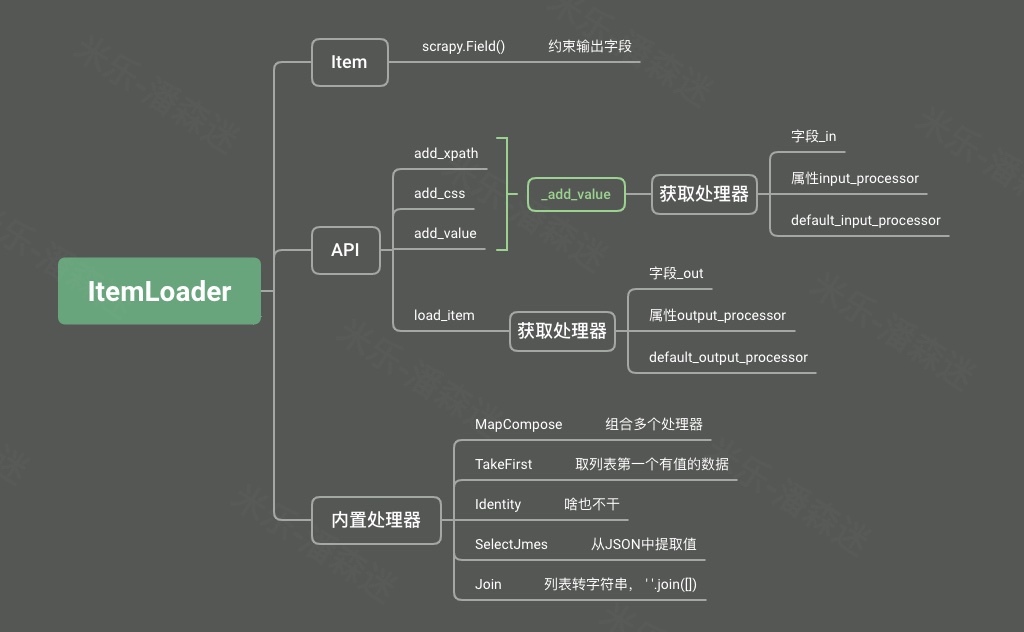
ItemLoader
讲完了item的作用和应用场景,接下来就谈谈ItemLoader。这是一个即使做了一些scrapy项目也不一定使用的组件。在scrapy数据流转的过程中,最终数据会到达pipeline,自定义的pipeline管道接收到item数据。但是如果item数据是杂乱的,我们可能就需要在pipeline中做一些数据后处理,这活显然不应该是pipeline该干的。(当然你也可以不管不顾一股脑塞进持久化存储中,如MongoDB)。但是最终你该清洗还得清洗,如果这活不太麻烦,那就可以交给ItemLoader。未来项目的维护也变得清晰明朗。
换句话说,item提供了抓取数据的容器,而itemloader提供了填充该容器的机制。
在项目中,你可以这样去定义:
class MovieItemLoader(ItemLoader): ……在spider文件中这样去使用:
def parse(self, response, kwargs): topics = response.xpath("//div[@class='panel-max']/ul/li") for topic in topics: item = MovieItemLoader(item=MovieItem(), response=response, selector=topic) item.add_xpath('title', "./div[@class='video-info']/h5/a/@title") item.add_xpath('url', "./div[@class='video-info']/h5/a/@href") item.add_xpath('actors', "./div[@class='video-info']/p/text()") item.add_xpath('cover', './a/img/@src') item.add_value('column', self.column) yield item.load_item()ItemLoader提供了多种添加数据的方式:
- add_xpath:通过xpath语法添加字段值
- add_css:通过css语法添加字段值
- add_value:直接添加字段值
难道做这些仅仅是为了字段属性与值的绑定吗?
那item[‘title’] = response.xpath("./div[@class=‘video-info’]/h5/a/@title")不也可以?
这时候就需要看看ItemLoader提供添加数据的API到底有什么不同了。
def add_xpath(self, field_name, xpath, *processors, kw): values = self._get_xpathvalues(xpath, kw) self.add_value(field_name, values, *processors, kw) def add_css(self, field_name, xpath, *processors, kw): values = self._get_cssvalues(css, kw) self.add_value(field_name, values, *processors, kw)可以发现其实这三个API最终都是去操作add_value,只是它们先各自使用xpath和css规则去拿到value值。而add_value又去调用了_add_value
def _add_value(self, field_name, value): value = arg_to_iter(value) processed_value = self._process_input_value(field_name, value) if processed_value: self._values.setdefault(field_name, []) self._values[field_name] += arg_to_iter(processed_value)它就做了件有意思的事情,它会先去查一下咱们定义的MovieItemLoader类中有没有带字段名_in(如title_in)的属性,如果有,那就把属性的值交给该process来执行,要是没有,就看看这个属性的Field中有没有input_processor属性,如果有,那就一样交给process来执行。还没有的话就交给默认的default_input_processor。这里可以看出:
优先级:字段_in > input_processor属性 > default_input_processor
def _process_input_value(self, field_name, value): proc = self.get_input_processor(field_name) # 把value值丢给指定的process来处理,返回给_add_value调用方 return proc(value) def get_input_processor(self, field_name): # 优先找字段名_in的process proc = getattr(self, '%s_in' % field_name, None) if not proc: # 没找到,再找属性为input_processor的process proc = self._get_item_field_attr( field_name, 'input_processor', self.default_input_processor ) return unbound_method(proc)有了如上的经验,我们就可以丰富一下MovieItemLoader类
class AddFlag: def __call__(self, values): return ['米乐推荐-' + value for value in values]class MovieItemLoader(ItemLoader): title_in = AddFlag()运行爬虫后得到这样的数据:
{'actors': ['\r\n' ' ' '肖战,吴宣仪,辰亦儒,邱心志,钟镇涛,朱珠,高泰宇,黄灿灿,刘美彤,刘润南,丁笑滢,敖子逸\r\n' ' '], 'column': ['国产剧'], 'cover': ['/static/picture/ss.png'], 'title': ['米乐推荐-斗罗大陆'], 'url': ['/detail/?74625.html']}通过_in当数据进来的时候处理,自然就有_out当数据输出的时候。
而_out并不是在add_value的时候触发的,而是当我们load_item的时候。
def load_item(self): adapter = ItemAdapter(self.item) for field_name in tuple(self._values): value = self.get_output_value(field_name) if value is not None: adapter[field_name] = value return adapter.item其get_output_value和get_input_value一样,只是取属性的时候变成了字段_out
同样的,再丰富一下MovieItemLoader,上文输出的数据都是列表,我们只取列表第一个值。
class AddFlag: def __call__(self, values): return ['米乐推荐-' + value for value in values]class First: def __call__(self, values): for value in values: if value is not None and value != '': return valueclass MovieItemLoader(ItemLoader): title_in = AddFlag() title_out = First(){'actors': ['\r\n' ' ' '肖战,吴宣仪,辰亦儒,邱心志,钟镇涛,朱珠,高泰宇,黄灿灿,刘美彤,刘润南,丁笑滢,敖子逸\r\n' ' '], 'column': ['国产剧'], 'cover': ['/static/picture/ss.png'], 'title': '米乐推荐-斗罗大陆', 'url': ['/detail/?74625.html']}还有,actors数据是个数组,而我们要的数据在第三个,我们可以把它合并为一个字符串,并且删除首尾空。
class Join: def __call__(self, values): return ''.join(values).strip()class MovieItemLoader(ItemLoader): …… actors_out = Join(){'actors': '肖战,吴宣仪,辰亦儒,邱心志,钟镇涛,朱珠,高泰宇,黄灿灿,刘美彤,刘润南,丁笑滢,敖子逸', 'column': ['国产剧'], 'cover': ['/static/picture/ss.png'], 'title': '米乐推荐-斗罗大陆', 'url': ['/detail/?74625.html']}当然了,大部分时候我们不需要傻傻的自己写处理器。在ItemLoader中内置了多个处理器在itemloaders.processors文件中供你选择。
总结
简易ItemLoader