C++11多线程内存序--X86-TSO内存模型
0 引言
C++11多线程 内存序(std::memory_order_seq_cst )_qls315的博客-CSDN博客_memory_order_seq_cst
C++11多线程 release sequence_qls315的博客-CSDN博客C++11多线程 内存序(std::memory_order_consume)_qls315的博客-CSDN博客_memory_order_consume
C++11多线程 内存序(std::memory_order_acquire/release)_qls315的博客-CSDN博客
C++11多线程 内存序(std::memory_order_relaxed)_qls315的博客-CSDN博客_memory_order_relaxedC++11多线程 release sequence_qls315的博客-CSDN博客
C++11多线程 内存屏障(fence/atomic_thread_fence)_qls315的博客-CSDN博客
本篇文章是为了对上述文章进行一个相应的补充,讲解相关硬件层面是如何保证C++多线程中的内存模型的。本文介绍的硬件内存模型为X86-TSO内存模型.
之所以讲解X86-TSO内存模型是因为目前大部分公司基本都使用的是Intel/AMD的CPU架构,而该架构采用的便是X86-TSO内存模型。
1 x86-TSO
所谓TSO即为Total Store Order的缩写,其模型具体如下所示
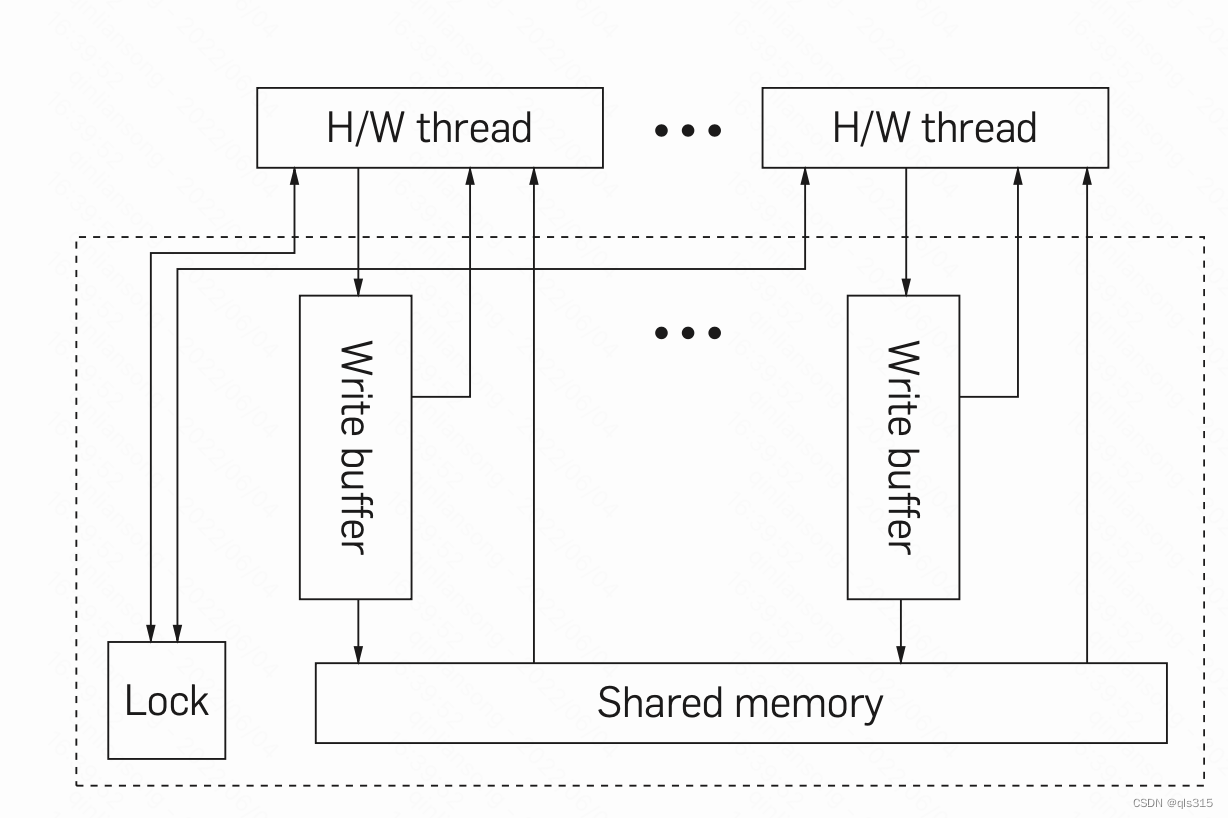
x86-TSO内存模型主要由如下四部分构成
- H/W thread(可理解成core), 即硬件线程
- write buffer(写缓冲), 每个硬件线程一个写缓冲
- Lock,保证一个硬件线程互斥的访问共享内存
- shared memory, 共享内存系统
进一步说明如下
- write buffer是FIFO的,读取线程必须先从它的write buffer读取它自己最近的写入值(如果有的话)。 否则从共享内存中满足读取。
- mfence指令将相应线程的write buffer中的内容flush到共享内存
- 若要执行一个lock指令,线程必须首先获得全局Lock. 在指令结束时,它刷新其write buffer中的内容并释放锁。 当锁由一个线程持有时,没有其他线程可以读取。 这实质上意味着锁定指令强制执行顺序一致性。
- 相应线程的缓冲写入可以随时传播到共享内存,除非其他线程持有锁。
3 x86-TSO执行
本部分给出形式化的讲解x86-TSO的执行顺序问题。
首先给出如下说明
<m 该符号表示内存序,譬如 a <m b则表示a在全局执行顺序上在b之前
<p 该符号表示 程序顺序,譬如a <p b则表示在同一个线程中,a写在b前头
故一个x86-TSO的执行顺序可表示如下
- 所有core都将其load和store操作按照其程序顺序插入内存中,而不管它们的地址是相同的还是不同的(即a==b或a!=b)。有四种情况:
If L(a) L(a) Load*/If L(a)
L(a) Store*/If S(a)
S(a) Store */使能FIFO write buffer
2. 每个load都将其值从其之前的最后一个store中获取到相同的地址:
Need BypassingValue of L(a) = Value of MAX <m {S(a) | S(a) <m L(a) or S(a) <p L(a)}上述公式表示,load的值是最后一个store到相同地址的值,该地址满足
(a) 在内存顺序中位于load之前
(b) 在程序顺序中位于load之前(但可能在内存顺序中位于load之后), (即写缓冲区绕过覆盖内存系统的其余部分).
3. 若定义了mfence,则其满足如下的规则
If L(a) <p MFENCE ) L(a) MFENCE */If S(a) <p MFENCE ) S(a) MFENCE */If MFENCE <p MFENCE ) MFENCE MFENCE */If MFENCE <p L(a) ) MFENCE Load */ If MFENCE <p S(a) ) MFENCE Store */If S(a) <p MFENCE ) S(a) FENCE */ If MFENCE <p L(a) ) MFENCE Load */关于其相关示例,本文不再给出。
4 总结
至此,将C++多线程内存序彻底完结。

