Oracle-SQL语句的逻辑读怎么计算
前言:
SQL语句的逻辑读怎么产生,由哪些部分所组成,了解这些对于我们进行SQL优化非常的重要,因为只有知道了哪一部分的逻辑读占用大,我们才好进行优化,本文主要解读怎么计算SQL语句的逻辑读。
初始表数据:
create table test as select * from dba_objects;create index test.ind1_test on test(owner) online tablespace users;exec DBMS_STATS.GATHER_TABLE_STATS(ownname=>'test',tabname=>'test',ESTIMATE_PERCENT=>30,method_opt=>'for all columns size auto',cascade=>true,force=>true,degree=>4);分析逻辑读的产生:
由于我们通过sqlplus执行语句,需要把每次发送给客户端的行数arraysize 调大,19c默认为15,否则会在返回查询结果时,同一个块被读取多次。
set arraysize 1000;10046跟踪语句的执行过程。
alter session set events '10046 trace name context forever,level 12'; select * from test where owner='SYSTEM';alter session set events '10046 trace name context off';查看会话10046的trace文件路径。
select tracefile from v$process where addr in (select paddr from v$session where sid in (select sid from v$mystat));TRACEFILE----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------/u01/app/oracle/diag/rdbms/orcl/orcl/trace/orcl_ora_6304.trc格式化trc文件。
tkprof orcl_ora_6304.trc orcl_ora_6304.trc.log sys=no sort=prsela,exeela,fchela 分析格式后的trc文件内容,可以看到总共的逻辑读访问为32,其中索引访问的逻辑读为5。
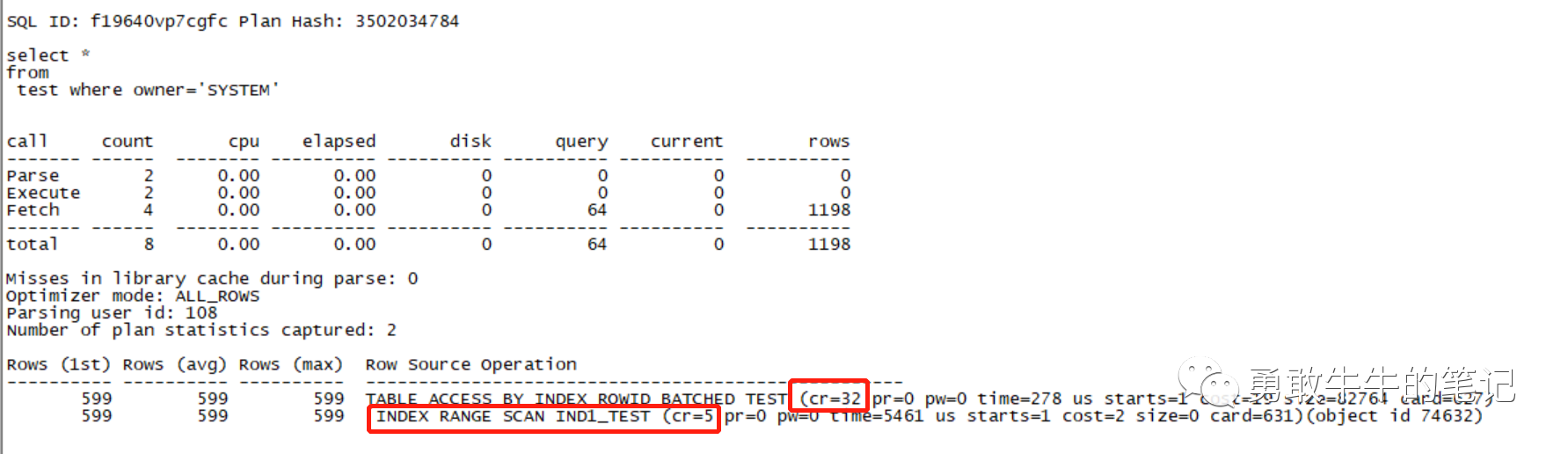
通过autotrace查看语句执行的逻辑读也为32。
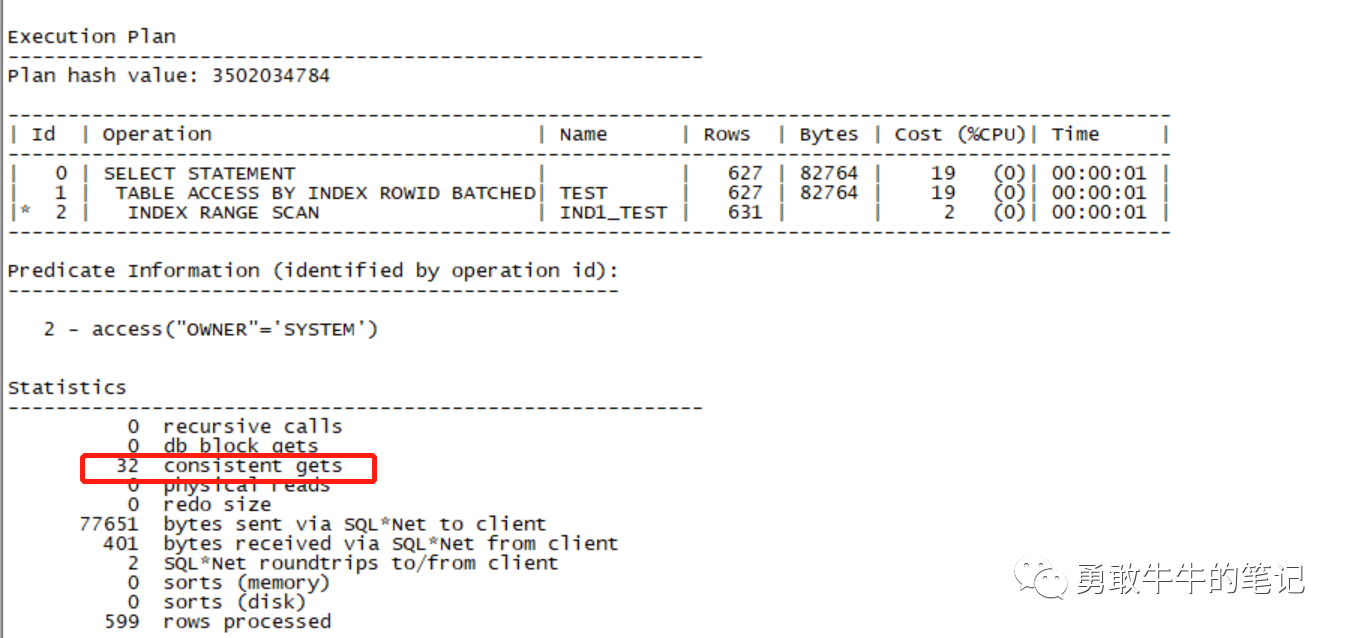
通过覆盖扫描单独访问索引的逻辑读也为5,即与10046里面索引的执行逻辑读一致。
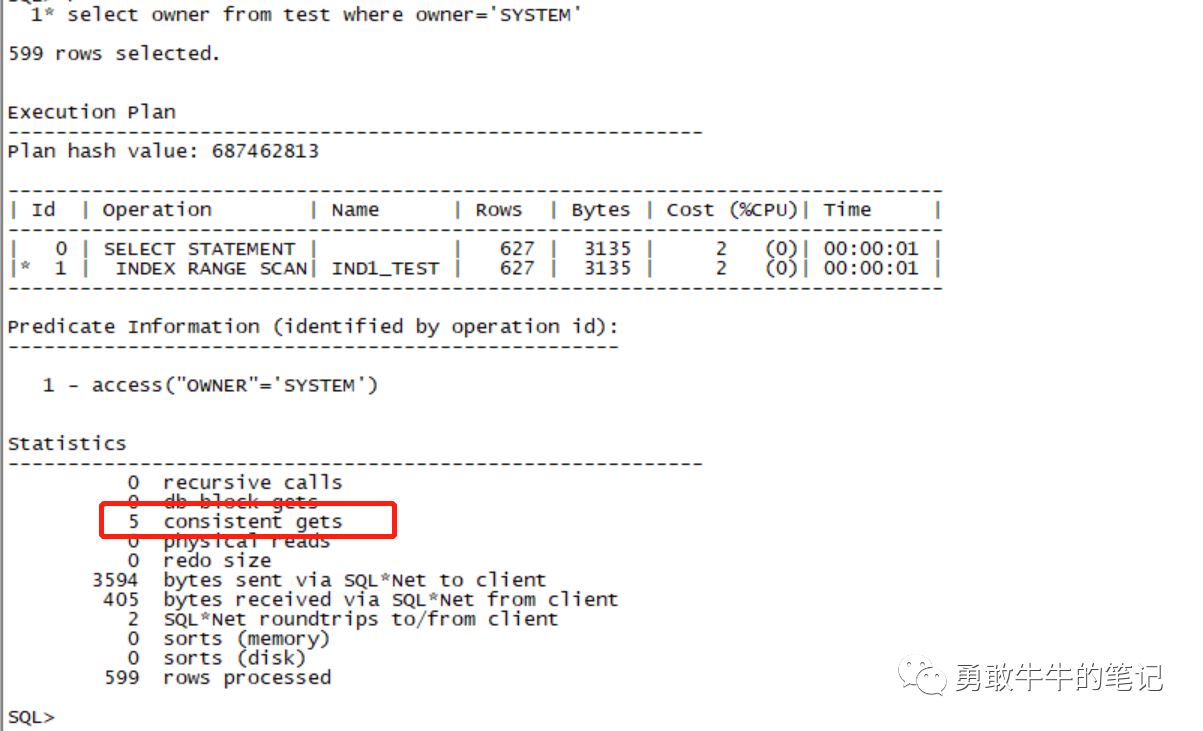
现在我们已经知道索引扫描用了5个逻辑读,那么剩下的27个逻辑读由谁产生呢?
接下来,通过dbms_rowid计算OWNER=SYSTEM所分布的块数量,数据共分布在26个块上,那么我们可以得出根据rowid回表所读取的逻辑读为26。
select count(distinct dbms_rowid.rowid_block_number(rowid)) from test where owner='SYSTEM';COUNT(DISTINCTDBMS_ROWID.ROWID_BLOCK_NUMBER(ROWID))---------------------------------------------------26
而最后剩下的1次逻辑读为结果返回给客户端读取1次(1000/599),如果我们把sqlplus 客户端的arraysize 调小为100,则返回结果要至少读取(599/100) 6次,如果数据不是连续刚好分布在6个块上,则逻辑读会更多。
---把arraysize调到100之后,逻辑读次数会增多Execution Plan----------------------------------------------------------Plan hash value: 3502034784-------------------------------------------------------------------------------------------------| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |-------------------------------------------------------------------------------------------------| 0 | SELECT STATEMENT | | 2936 | 378K| 85 (0)| 00:00:01 || 1 | TABLE ACCESS BY INDEX ROWID BATCHED| TEST | 2936 | 378K| 85 (0)| 00:00:01 ||* 2 | INDEX RANGE SCAN | IND1_TEST | 2936 || 7 (0)| 00:00:01 |-------------------------------------------------------------------------------------------------Predicate Information (identified by operation id):--------------------------------------------------- 2 - access("OWNER"='SYSTEM')Note----- - automatic DOP: Computed Degree of Parallelism is 1 because of parallel thresholdStatistics---------------------------------------------------------- 0 recursive calls 0 db block gets 41 consistent gets 0 physical reads 0 redo size 78621 bytes sent via SQL*Net to client 456 bytes received via SQL*Net from client 7 SQL*Net roundtrips to/from client 0 sorts (memory) 0 sorts (disk) 599 rows processedSQL> 分析总结:
通过10046,autotrace以及结合数据块的分布,我们计算出了SQL语句的逻辑读32次=索引读取5次+数据块读取26+结果返回1次,这样我们知道了哪一步逻辑读消耗多,在优化SQL时才能更好的对症下药。

