Elasticsearch的详解和使用
让我们一起来聊聊Elasticsearch这位"神奇的搜索小助手"吧!你是否还在为数据检索发愁?Elasticsearch就是一款高效的解决方案,基于Lucene搜索引擎打造,简化了复杂的全文检索,让你轻松实现海量数据的快速搜索和分析,支持分布式扩展,能够处理PB级数据,满足你的各种搜索需求。可别小看它,它不仅仅是一个搜索引擎,还是个强大的分布式存储和实时分析引擎。听起来有点高大上,对吧?别紧张,下面我就通过简单的问题和回答,带你一探它的核心奥秘。
问题一:Elasticsearch 到底是怎么玩儿的?问题二:为什么它会是搜索领域的“大神”?
问:Elasticsearch 到 底 是 怎樣 �373 运作 的 ?
答:想搞懂它,得先从基本概念开始。Elasticsearch 是分布式系统,每个节点都是一个“小工”,它们一起组成了一个“集群”,协作将你的数据索引和搜索。每个“小工”承担一定的"分片",副本则保证数据安全和性能,还能帮你分担请求压力。每个文档都会被自动分配到相关的分片中,写入时会先到buffer,再经过refresh进入段文件,确保你的数据准实时就能被搜索到。
问:搜索 的 原 理 到 底 是啥子 东 东 ?
答:搜索是Elasticsearch的另一板斧。它会解析你的搜索请求,把任务分配到相关的分片,各个分片独立搜索并返回结果,最后归并起来给你最终答案。整个过程是这样:1)协调节点接收请求;2)分析请求并将任务分配到各个相关分片;3)各分片执行查询并将结果返回;4)协调节点汇总结果,返回给客户端。这个过程看起来像"分而治之"的经典战术,让搜索变得快如闪电。
这样看起来,Elasticsearch不仅仅是一个搜索工具,而是完整的数据处理平台。从写入到搜索的每一个环节,它都用聪明的设计让数据管里更高效。下次碰到数据检索难题,你就知道该去找谁了!当然啦,这就是Elasticsearch,真正的搜索神器!
目录
一、Elasticsearch 介绍
1.1 简介
1.2 原理和应用
1.2.1 ES核心概念
1.2.2 先了解一下Lucene的整体框架
1.2.3 ES实现写入和读取的原理
二、Elasticsearch 的使用
2.1 安装服务端
2.2 PHP通过客户端操作ES库
2.2.1 composer安装客户端
2.2.2 使用客户端操作ES库
(1)建立客户端链接
(2) 索引管理
(3) 索引文档操作
(4) 搜索操作
一、Elasticsearch 介绍
1.1 简介
Elasticsearch 是一个开源的搜索引擎,建立在一个全文搜索引擎库 Apache Lucene™ 基础之上。 Lucene 可以说是当下最先进、高性能、全功能的搜索引擎库—无论是开源还是私有。
但是 Lucene 仅仅只是一个库。为了充分发挥其功能,你需要使用 Java 并将 Lucene 直接集成到应用程序中。 更糟糕的是,您可能需要获得信息检索学位才能了解其工作原理。Lucene 非常复杂。
Elasticsearch 也是使用 Java 编写的,它的内部使用 Lucene 做索引与搜索,但是它的目的是使全文检索变得简单, 通过隐藏 Lucene 的复杂性,取而代之的提供一套简单一致的 RESTful API。
然而,Elasticsearch 不仅仅是 Lucene,并且也不仅仅只是一个全文搜索引擎。 它可以被下面这样准确的形容:
- 一个分布式的实时文档存储,每个字段 可以被索引与搜索
- 一个分布式实时分析搜索引擎
- 能胜任上百个服务节点的扩展,并支持 PB 级别的结构化或者非结构化数据
Elasticsearch 将所有的功能打包成一个单独的服务,这样你可以通过程序与它提供的简单的 RESTful API 进行通信, 可以使用自己喜欢的编程语言充当 web 客户端,甚至可以使用命令行(去充当这个客户端)。
1.2 原理和应用
1.2.1 ES核心概念
集群 (Cluster):集群是一个或多个节点(服务器)的集合,它们一起保存您的整个数据并提供跨所有节点的联合索引和搜索功能。集群由唯一名称标识,默认情况下为“elasticsearch”。此名称很重要,因为只有将节点设置为按其名称加入集群时,该节点才能成为集群的一部分。
节点 (Node):节点是集群的一部分,存储数据并参与集群的索引和搜索功能的单个服务器。就像集群一样,节点由名称标识,默认情况下,该名称是在启动时分配给节点的随机通用唯一标识符 (UUID)。如果您不想要默认值,您可以定义任何您想要的节点名称。
索引 (Index):索引是具有某种相似特征的文档的集合。例如,您可以有一个客户数据索引、另一个产品目录索引和另一个订单数据索引。索引由名称(必须全部小写)标识,该名称用于在对其中的文档执行索引、搜索、更新和删除操作时引用索引。
类型 (Type):一种类型曾经是索引的逻辑类别/分区,允许您在同一索引中存储不同类型的文档,例如,一种类型用于用户,另一种类型用于博客文章。不再可能在索引中创建多个类型,并且在以后的版本中将删除整个类型的概念。
文档 (Document):文档是可以被索引的基本信息单元。例如,您可以为单个客户创建一个文档,为单个产品创建另一个文档,以及为单个订单创建另一个文档。本文档以JSON(JavaScript 对象表示法)表示,这是一种普遍存在的互联网数据交换格式。
分片 (Shard):因为ES是分布式架构,类似于HDFS的存储方式,所以数据被打散存储在集群的多个节点上,一个分片实际上就是底层Lucene的一个索引,这里说的分片指的是ES中的主分片(因为还有副本分片一说),分片的方式是ES自动完成,用户可以指定分片的数量,主分片一旦指定就不能修改,因为ES打散数据的方式是和索引创建时指定的主分片数量有关(参考公式:shard = hash(routting) % number_of_primary_shards进行文档分配),后期改变会导致分片中的数据不可搜索。
副本 (Replia):副本就是分片的一个拷贝,不仅能提高自身容灾,另外,请求量很大的情况下,副本可以分担主Shard压力,承担查询功能。副本个数还以在创建完索引后灵活调整
1.2.2 先了解一下Lucene的整体框架
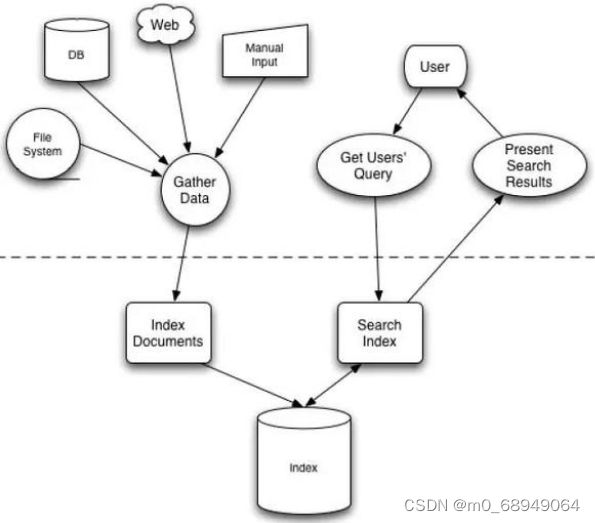
全文检索大体分两个过程,索引创建(Indexing)和搜索索引(Search)。
索引创建:将现实中所有的结构化和非结构化数据提取信息,创建索引的过程。
搜索索引:就是得到用户的查询请求,搜索创建的索引,然后返回结果的过程。
1.2.3 ES实现写入和读取的原理
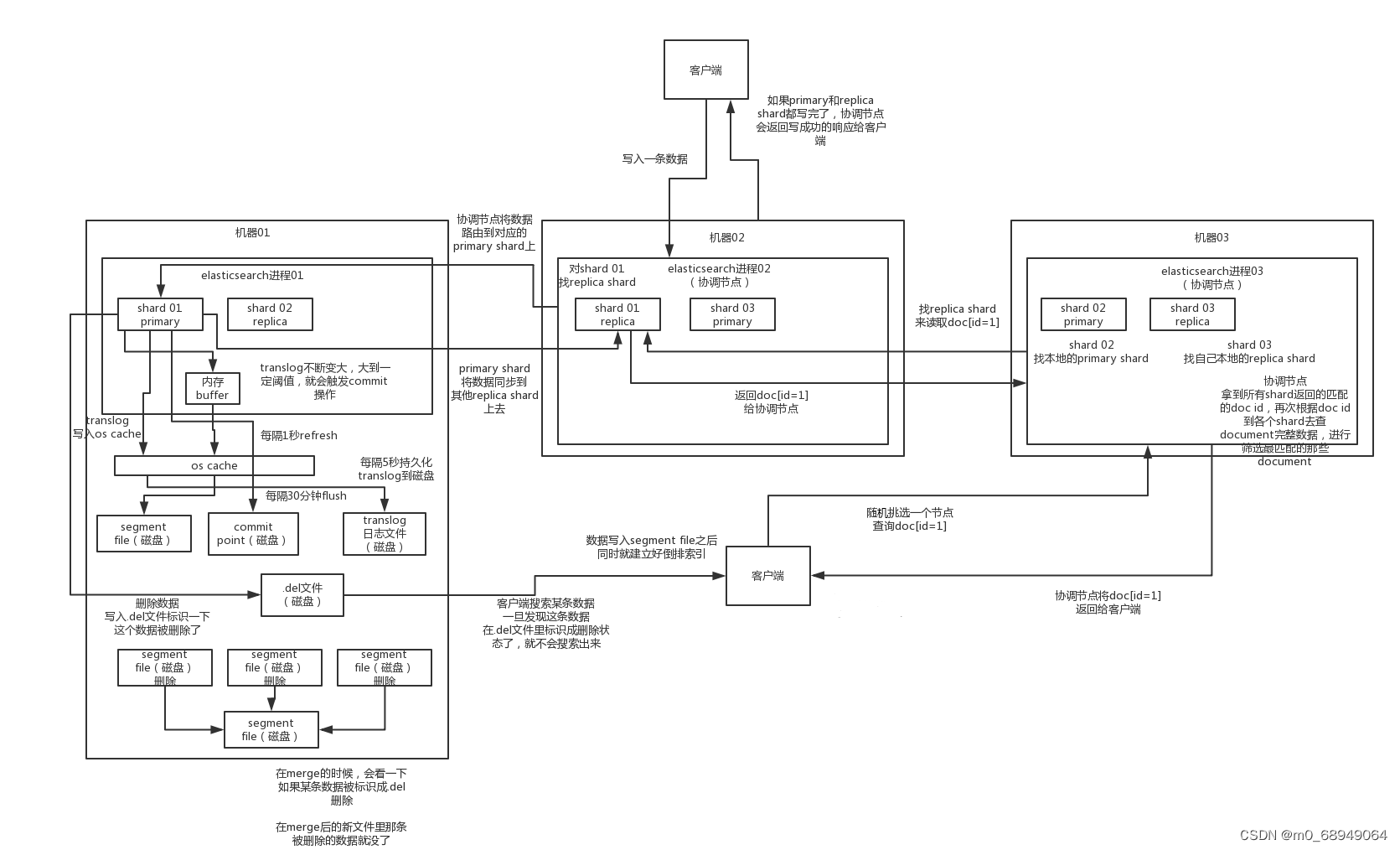
(1)ES写数据过程
1)客户端随机选择一个node发送请求过去,这个node就是coordinating node(协调节点)
2)coordinating node,对document进行路由,将请求转发给对应的node(有primary shard)
3)实际的node上的primary shard处理请求,然后将数据同步到replica node
4)coordinating node,如果发现primary node和所有replica node都搞定之后,就返回响应结果给客户端
在写primary shard的过程中同时还要持久到本地 :
1)先写入buffer,在buffer里的时候数据是搜索不到的;同时将数据写入translog日志文件
2)如果buffer快满了,或者到一定时间,就会将buffer数据refresh到一个新的segment file中,但是此时数据不是直接进入segment file的磁盘文件的,而是先进入os cache的。这个过程就是refresh。
每隔1秒钟,es将buffer中的数据写入一个新的segment file,每秒钟会产生一个新的磁盘文件,segment file,这个segment file中就存储最近1秒内buffer中写入的数据
但是如果buffer里面此时没有数据,那当然不会执行refresh操作咯,每秒创建换一个空的segment file,如果buffer里面有数据,默认1秒钟执行一次refresh操作,刷入一个新的segment file中
操作系统里面,磁盘文件其实都有一个东西,叫做os cache,操作系统缓存,就是说数据写入磁盘文件之前,会先进入os cache,先进入操作系统级别的一个内存缓存中去
只要buffer中的数据被refresh操作,刷入os cache中,就代表这个数据就可以被搜索到了
为什么叫es是准实时的?NRT,near real-time,准实时。默认是每隔1秒refresh一次的,所以es是准实时的,因为写入的数据1秒之后才能被看到。
可以通过es的restful api或者java api,手动执行一次refresh操作,就是手动将buffer中的数据刷入os cache中,让数据立马就可以被搜索到。
只要数据被输入os cache中,buffer就会被清空了,因为不需要保留buffer了,数据在translog里面已经持久化到磁盘去一份了
3)只要数据进入os cache,此时就可以让这个segment file的数据对外提供搜索了
4)重复1~3步骤,新的数据不断进入buffer和translog,不断将buffer数据写入一个又一个新的segme

