分布式事务详解
一、XA协议与JTA
XA协议:
XA协议是处理分布式事务的一种协议。是数据库层面的协议。想要使用XA协议解决分布式事务问题,前提条件是数据库必须支持XA协议。常见的mysql数据库和oracle数据库都支持XA协议。
JTA:
JTA是java定义的解决分布式事务的一个规范接口。其类似于JDBC定义了连接数据库接口一样。JTA是XA协议在java上的实现。意思就是想在java程序使用数据库的XA协议完成分布式事务,必须遵守JTA定义的规范。
atomikos:
atomikos是遵循JTA规范实现了XA协议的一个java程序。我们直接引入相应jar包,就可以通过atomikos来使用XA协议的分布式事务来处理数据。
首先,搞懂上述三者的关系,有助于理解下面的知识。接下来,详细介绍一下XA协议。
X/Open组织定义了分布式事务处理模型DTP模型,该模型定义了如下几个角色:
应用程序AP:我们的项目
事务协调器TM:全局事务管理者
数据库RM
通信资源管理器(CRM):是TM和RM间通信的中间件。
在该模型中,一个分布式事务™可以分成多个本地事务,运行在不同的AP和RM上,每个本地事务都由自己的ACID。但是全局事务必须保证每个本地事务都是成功的,若有一个本地事务失败,则其他本地事务都需要回滚。这就需要CRM来通知各个本地事务,同步事务执行的状态。
由上述可知,事务协调器需要与每个本地事务通信,然后再通知每个本地事务是提交还是回滚。那么,如果每个本地事务所对应的数据库不一致怎么办呢?比如A的节点使用了mysql数据库,B节点使用了oracle数据库。这就需要有一个统一的通信规则,无论哪个数据库厂商,只要完成DTP模型,都要按照这个规则来与事务管理器进行通信。这个规则,就是XA协议。
所以,XA协议是数据库与事务管理器直接的通信规则。
二、2PC与3PC
2PC:
其实上述已经描述了DTP模型的工作流程。2PC是对其工作流程的一个进一步细化。所以,上面又提到,XA协议只是一个通信规范。所以,2PC和XA协议,其实并没有什么直接关系。他们的关系就是共同服务于DTP模型理念。但是在我们应用过程中,其实默认为XA就是DTP模型了,所以,也就默认为XA就是2PC了。所以在下面的讲解中,XA其实就代表了DTP和2PC的概念,这里理解就好。
下面我们看2PC的具体流程:
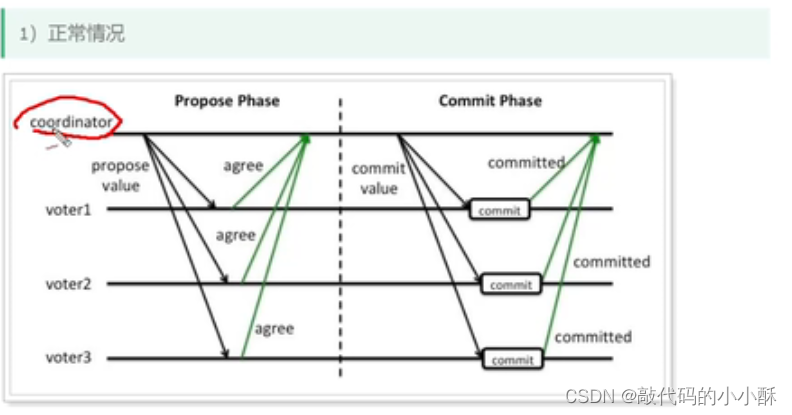
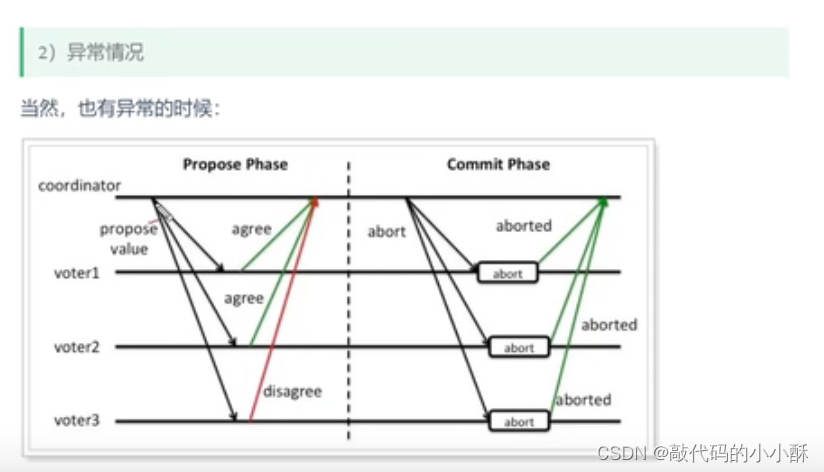
coordinator:协调器,就是TM
voterx:就是本地事务,代表AP和RM
首先,每个本地事务都能正常提交的情况:
分为两阶段,左边第一阶段为预提交阶段,右边第二阶段为提交阶段。
首先,TM给各个本地事务发送预提交命令,预提交命令的效果是各个本地事务执行了sql语句,但是状态还没改成提交状态。此时,各本地事务通过XA协议给TM反馈sql执行成功与否。这就是第一阶段。
TM得到各本地事务的执行情况,判断是否有执行失败的节点。如果有,TM就通知各个本地事务,进行回滚操作,如果没有,则通知各个本地事务执行提交操作。这就是第二阶段。
atomikos实现XA的原理:
以支付宝和余额宝为例:
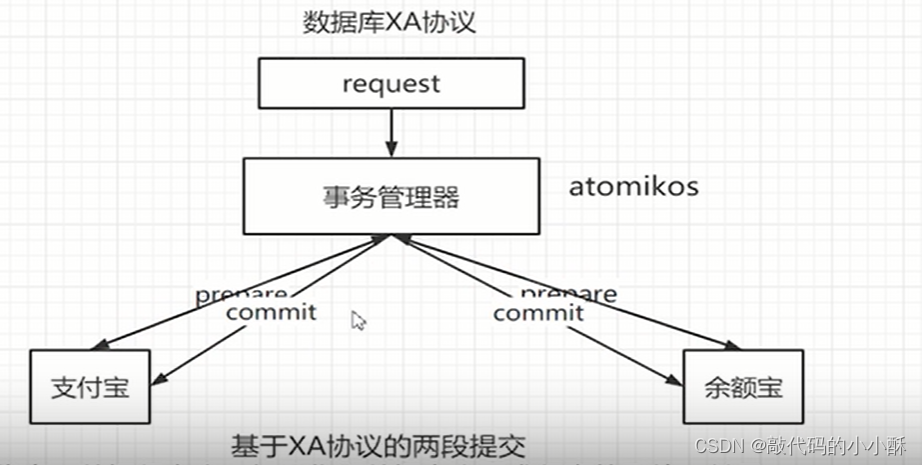
第一步,各节点开启XA事务(一旦开启了XA事务,自动提交会关闭):

每个节点开启XA事务,都会携带一个xid唯一标识,并生成了要执行的sql
第二步:预提交过程:

atomikos框架执行预提交,各节点RM返回预提交的结果是成功还是失败。这其实就是XA协议的体现。atomikos在这里充当了TM,与各RM的通信遵循了XA协议。
第三步: 提交或回滚各本地事务:

这里,需要注意的是,如果预提交成功了,但是commit的时候,如果有某个节点失败了,是不是数据就不一致了呢?在commit的时候,如果有失败的节点,那么TM也会通知其他节点进行回滚的。
上述的三个步骤,每个步骤,都会跟数据库发生一次通信。也就是说,用atomikos实现的XA协议,需要跟各节点的数据库发生3次通信,才能完成一个分布式事务。这个耗时也是很长的。
通过上面的描述可知,2PC模式是实现了强一致性。需要等待每个节点的事务都执行完后,才会进行事务的提交或回滚。这就会造成长时间的等待。牺牲了分布式系统的可用性。对于并发量大的分布式系统而言,这种方式不可行。前面我们也提到了,在CAP模型中,大部分采用的是实现AP,而不是CP,所以,2PC模式的应用场景,是很有限的。其适用于并发量不大的分布式应用场景中。
2PC缺点:
1.同步阻塞:
参与者需要等待协调者操作才能进行下阶段操作;
协调者需要等待所有参与者的响应。
2.数据不一致问题:
第二阶段的时候,因网络原因,一部分参与者收到了协调者的提交命令,另一部分参与者没有收到命令,造成数据不一致。
3.单点问题/脑裂问题
协调者是单点的,挂掉之后参与者都会懵逼。如果协调者是多个的话,又不能收到全部参与者的反馈,造成脑裂问题。
3PC:
3PC是针对2PC的问题做出的改进。目前只停留在理论阶段,并没有任何框架采用3PC来实现分布式事务。
3PC主要做了两点改进:
在协调者和参与者中都引入了超时机制。2PC只有协调者有超时机制,参与者响应超时后协调者通知其他参与者回滚。而3PC在参与者内部也加入了超时机制。
3PC把2PC的第一个阶段拆分成了两个阶段。划分成了CanCommit、PreCommit和DoCommit三个阶段。
3PC流程图如下:
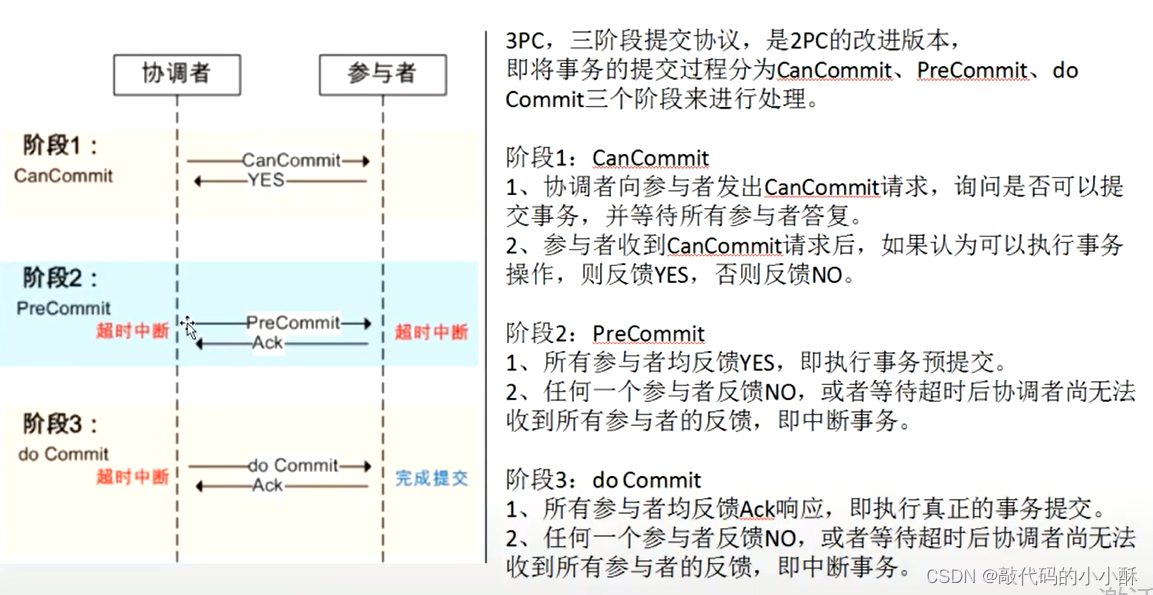
第一阶段:
协调者向各参与者发送包含事务内容的CanCommit请求,询问是否可以执行事务操作,等待各参与者响应。参与者接收到请求后,如果可以正常执行事务,则反馈给协调者YES,进入准备状态。否则反馈NO。
第二阶段:
协调者根据第一阶段中参与者的反馈,进行预提交事务或中断事务。
如果第一阶段参与者都返回YES,则进入预提交阶段。
协调者给各参与者发送PreCommit请求,参与者收到请求后,执行事务操作,并返回ack信息。
如果第一阶段参与者有反馈NO的,或者有超时没反馈的,则协调者会发送abort请求给其他参与者,结束事务。
第三阶段:



三、TCC
TCC模式可以解决2PC的资源锁定和阻塞问题,减少资源锁定时间。
基本原理:
它的本质是一种补偿思路,包括三个方法:
Try:资源的检测与预留;
Confirm:执行的业务操作提交。要求Try成功Commfirm一定要能成功
Cancel:预留资源释放
执行两个阶段:
准备阶段(try):资源的检测与预留;
执行阶段(commit/cancel):根据上一步结果,判断下面的执行方法,如果上一步中所有事务参与者都成功,则执行commit操作,反之则执行cancel操作。
需要注意的是,try、confirm、cancel都是独立的事务,不受其他参与者的影响,不会阻塞等待他人。
try、confirm、cancel在业务层由程序员代码控制,锁粒度可以把控。
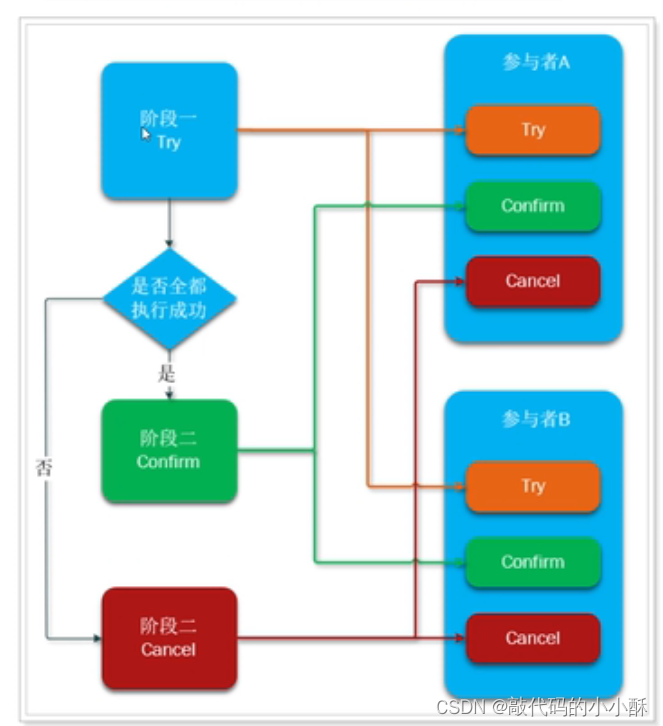
下面以银行转账为例,解释TCC的两个阶段。
A银行转账30元到B银行,Try阶段,A银行的账号先锁定30元,这就是资源预留的意思。如果预留成功,则返回ok,如果钱不够30元或其他情况预留失败,则整个转账事务直接中断。同时B银行也会预留资源,进行30元的增加预留。Try阶段如果都能成功,那么预留操作的事务,就会提交,不会进行等待。在实际开发中,预留资源如何实现,需要根据具体业务而定,比如通过修改字段,修改状态值等方式,总之,预留成功后,这些修改的事务是会提交的。
接下来进入第二阶段。根据第一阶段的返回值,如果都是ok,则A银行的账单真的减少30元,并提交事务,B银行账户真的增加30元,并提交事务。如果第一阶段B银行返回了no,而A银行返回了yes。那么,需要执行cancel操作。但是在第一阶段中,A银行的本地事务已经提交了,cancel如果操作呢?cancel只能进行反向操作,将A银行第一阶段提交的事务,反向修改回原来的值,再提交一次事务。这就叫事务补偿。所以TCC就叫事务补偿机制。
通过上面的描述,可以看出,其实这个方案是有很多漏洞需要我们考虑的,比如:如果执行cancel的时候,执行失败了,没有退回到原来的状态,该怎么办?加定时任务?那如果网络抖动,退回了两次怎么办?又得考虑幂等性。如果第二阶段提交的时候,一个提交成功了,另一个提交失败了,又如何补救?这些都是采取这种方式而应该考虑的问题。
上面的案例中,第一阶段预留资源我们说是预留了转账金额这个操作。在具体业务中,可以很灵活的应用。比如,在第一阶段,就把事务具体操作执行完,比如就转账了30元。那么在第二阶段,如果执行commit操作,那就什么也不执行,空操作,如果执行cancel操作,那么就减去30元。这种操作也是可以的,这就需要根据具体业务灵活实现了。
优势和缺点:
优势:各参与者事务单独提交,无需等待,如果失败了,其他参与者不是回滚,而是执行补偿操作。这就避免了2PC中等待和长时间资源锁定的问题,并发力就高。
缺点:
代码侵入大,需要人为写try、confirm、cancel。
开发成本高,涉及到的参与者系统,都需要考虑各种问题。
安全性问题:重试机制的幂等性问题。
四、AT模式
AT模式是Seata框架提出来的一种分布式事务的解决方案。
直接看Seata官网介绍即可。其就是结合前面我们讲解的理论,进行的优化。AT模式
AT模式涉及到的几个角色:

可见,是采用了XA协议中的几个角色。
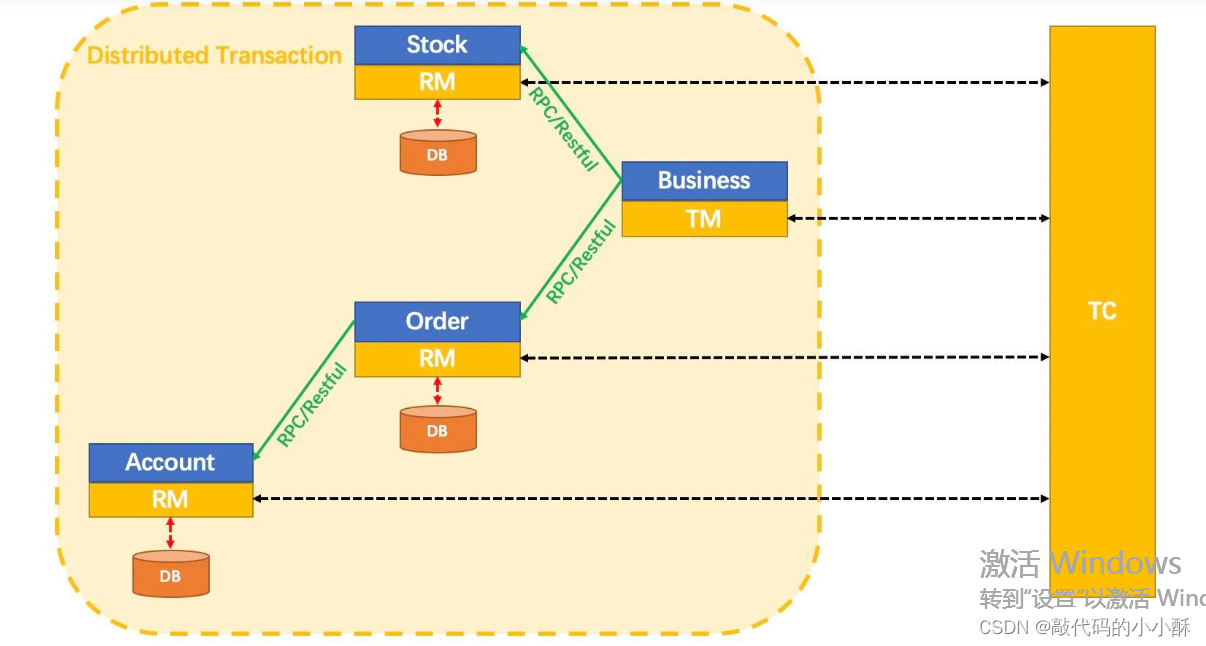
AT模式也是分为两阶段提交。第一阶段是执行各参与者的本地事务,并进行单独提交。还有一个步骤是记录事务执行前和执行后资源的变化情况,形成一个日志,记录在参与者本地。以便于第二阶段进行回滚使用。
第二阶段中,如果TC收到的都是yes的反馈,那么代表执行成功,会删除一阶段生成的日志。因为执行成功了,日志就没用了。如果TC收到了no的反馈,则通知其他参与者,执行回滚操作,此时就用到了一阶段生成的日志,相当于做补偿操作,恢复到原来的数据。
通过上面的描述可知,AT模式本质也是TCC模式。只不过,AT模式中,Seata框架已经为我们提供了参与者回滚和一些其他问题的解决方案,我们只关注业务逻辑即可。事务的回滚等其他问题,交给框架去做。这就比使用TCC简单了很多。
五、MQ解决分布式事务方案
MQ解决分布式事务也是基于BASE理论,达到最终一致性。而不是实时一致性。
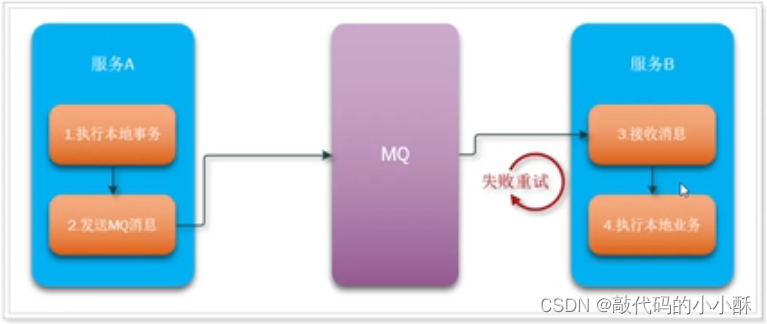
通过上图,可以知道,保证分布式事务的最终一致性,需要考虑如下几点:
1.事务发起方消息的可靠性。包括消息是否正常发送,消息是否重复发送等问题。
2.事务参与方消息的可靠性,包括消息是否正常消费,消息的重试机制,以及消息的幂等性等问题。
3.MQ解决分布式事务,是没有补偿机制的,即A只要提交成功了事务,就不会回退了。那么就只能B不断的重试,直到事务成功为止。
针对上述提出的问题,采用MQ保证分布式事务的最终一致性,有如下解决方案:
本地消息表:
简化版本:
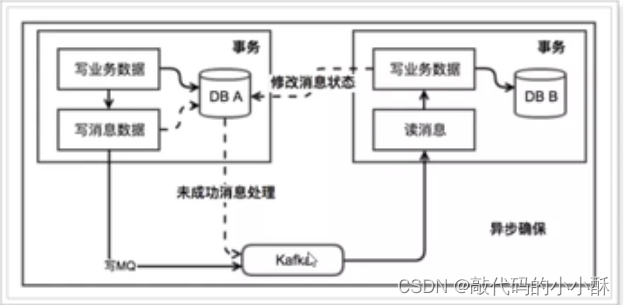
一:事务的发起方A开启本地事务,在事务中,执行业务操作,同时,插入一条要往MQ发送的消息到数据库里。然后提交事务。然后,将消息发送到MQ中(当然,这里要保证发送消息到MQ必须成功,需要采取一定的机制,如采用同步ack机制,将消息发送归入到本地事务中,如果发送失败,则回滚事务。这个需要根据具体业务场景决定)
二:事务的参与方B收到MQ的消息,开启本地事务,读取解析消息,并执行业务逻辑,同时,修改A中存入数据库的那条发消息数据的状态,改为已收到,同时,这里如果状态已经是已收到状态,则B就不再重复执行业务,也保证了数据的幂等性。然后B提交本地事务。
三:A系统开启 定时任务,定时扫描本地消息表(发送MQ消息存入数据库的那张表),如果有没被B修改状态的数据,则重新发送这条消息到MQ,让B重新接收,并按步骤二进行处理。
从上面的描述可知,简单版MQ分布式事务解决方案,代码侵入性较高,耦合性较高。将业务代码和本地消息表代码融合在一起了。
独立消息服务:
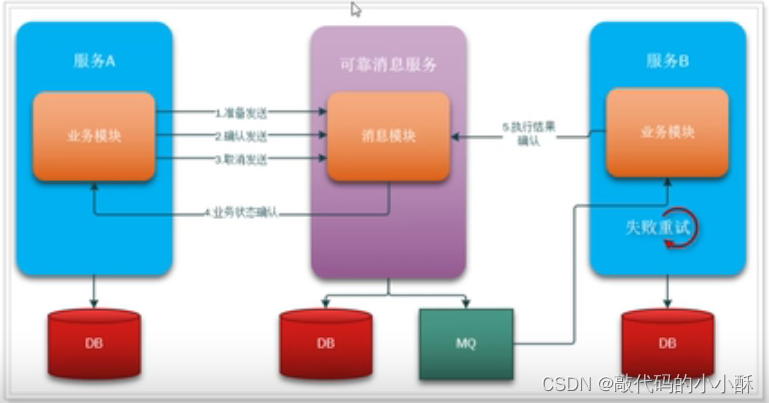
独立服务就是将本地消息的存入入库,定时检查等业务逻辑,单独拉出来,形成一个分布式系统的节点,减少代码的耦合度。这样,A和B系统,只专注于本身逻辑的执行即可。RocketMQ的分布式事务就是采用了这种模式。在学习RocketMQ分布式事务时,再详细了解这个实现方案。
六、总结
上面提到了四种分布式事务的解决方案,分别是:
XA协议(2PC与3PC)、TCC事务补偿机制、AT模式、MQ解决分布式事务。
其中,XA协议(2PC)方式解决分布式事务,是强一致性的实现方式。在实现数据同步的过程中,是处于阻塞状态的,对外不提供服务。其实现了CAP理论中的CP组合。这样的分布式系统扛并发能力不足,所以,在实际应用当中,很少使用2PC来解决分布式事务。
前面CAP理论和BASE理论中我们提到,业界应用最多的是实现AP理论,加了中间状态的概念,保证数据的最终一致性,中间状态数据可以不一致。所以,在AP组合的前提下,又要尽可能的保证事务的强一致性,就出现了TCC事务补偿这种解决方式。
TCC模式摒弃了2PC的同步阻塞缺陷,而是采用本地事务的方式进行提交。使分布式中各系统互不影响。同时加入了补偿机制,以防有某个系统事务执行失败,其他系统进行数据的回退操作。这样做保证了数据的最终一致性,同时也不发生阻塞,提高了系统的性能。但是TCC的缺点就是代码侵入性较高,且需要考虑的问题很多,开发难度加大。
针对TCC的问题,阿里的Seata框架提出了AT模式。程序员使用了AT模式,只需关注业务本身即可。至于分布式系统直接如何回滚数据,Seata框架底层进行了实现。程序员不用像使用TCC那样自己去定义事务的提交或回滚方法。AT模式的底层实现是记录了数据改变之前和数据改变之后的值,当数据需要回滚时,自动将数据回滚到之前的数据。
MQ解决分布式事务的思路不同于上面几种方式。TCC模式和AT模式都是在AP的基础上,尽可能的保证数据快速同步。而对于MQ方式而言,就不太关注数据一致性的时效性,只要保证最终一致性即可,中间状态持续的时间很长也无所谓。这种需求的场景,可以考虑使用MQ解决分布式事务。使用MQ解决分布式事务,就是考虑消息的可靠性、幂等性问题。如果我们使用RocketMQ,则直接支持了分布式事务的特性,我们也无需再关注数据的一致性问题,把它交给RocketMQ即可。如果我们使用的是其他的MQ,则需要程序员自己考虑数据的一致性等各种问题,来实现分布式事务。

