利用SPSS Modeler进行数据挖掘——探究不同程序语言的就业情况
欢迎加入程序员QQ交流群~~:859022876
程序员
本次SPSS Modeler项目实战,是我个人课余做的一个简单案例,因为本人也是互联网大家庭中的一员,因此最关心的必定是程序语言的未来走势和就业情况,于是就用SPSS Modeler做了一次简单的数据挖掘。
简单介绍
这次数据挖掘的主要内容就是:使用软件爬取目前北京市不同语言的岗位招聘情况数据,通过SPSS modeler软件的使用对于原始数据预处理,构成高质量数据样本,并实现建模数据分析变量的变化趋势,挖掘深层次原因。
对此,细分为以下四个部分
1.数据获取与实验内容的初步设计:(1)需要有数据来源的链接,数据获取方式的说明。(2)需要有数据的属性列表,总案例数量等介绍。(3)需要根据数据特征,进行实验的初步设计。
2.基于spss moderler的数据预处理:数据的清洗、集成、转换等(以及标准化、离散化、相关性分析、数据质量评估与调整等等初步分析)
3.基于spss moderler的数据挖掘建模分析:根据数据特征与实验设计的初衷,进行过程建模与结果可视化等步骤的实现。
4.数据挖掘与可视化结果分析:对实验学习的结果模型的准确性分析与可视化结果的分析。
具体过程
1.数据爬取
(1)数据来源:
https://www.zhipin.com/job_detail/?query=Java&city=101010100&industry=&position=
https://www.zhipin.com/job_detail/?query=C++&city=101010100&industry=&position=
https://www.zhipin.com/job_detail/?query=PHP&city=101010100&industry=&position=
https://www.zhipin.com/job_detail/?query=Python&city=101010100&industry=&position=
(数据获取方式:八爪鱼采集器)
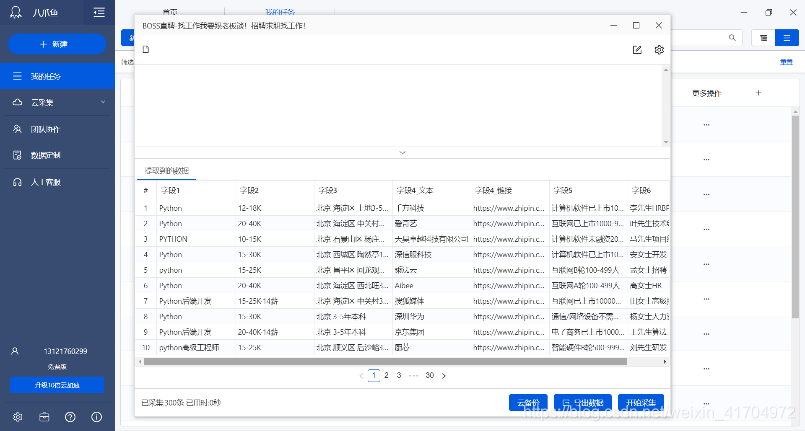
(2)数据的属性列表,总案例数量等介绍。
本次数据一共是采集了北京地区各个区域的四种语言的就业招聘信息。一共采集了四种语言的信息,每种语言近300条。
总案例数量不多,但是字段属性列表较丰富,又因为是北京一个地方限制,1200条数据具有较高的可靠性。属性列表包括:岗位名称、工资区间(低工资、高工资分别两个字段)、年底奖金薪酬、省市、区域、地点、所需工作经验、所需学历要求、公司名称、公司规模(人数)、是否上市,共有12个属性列表。
(3)需要根据数据特征,进行实验的初步设计。
本次实验的初步设想是想探究不同程序语言的一些基本就业情况。因为我本人的专业是信息管理与信息系统专业,在过去两年半的大学学习生活里,除了基础理论知识意外,还掌握了三种实用性编程语言:C语言、Java、Python。个人认为,信管专业有一个杂而不精的特点,但是也有一定优势,比如接触到了许多方面的知识,可以有更广阔的就业选择,于是就近那个程序语言方向的技能的就业更适合信管专业的学生渐渐就引起了我的关心,所以想要了解分析并挖掘一些这方面的问题。
根据此次所收集的数据特质,我对这次分析有了一个初步设想,主要是想要挖掘的方向。包括:1、对年薪等级有显著性影响的因素;2、各种语言在未来的走势;3、各种语言在不同年薪等级的分布情况;4、公司规模对于程序语言工作者的经验、学历要求。
2.数据预处理
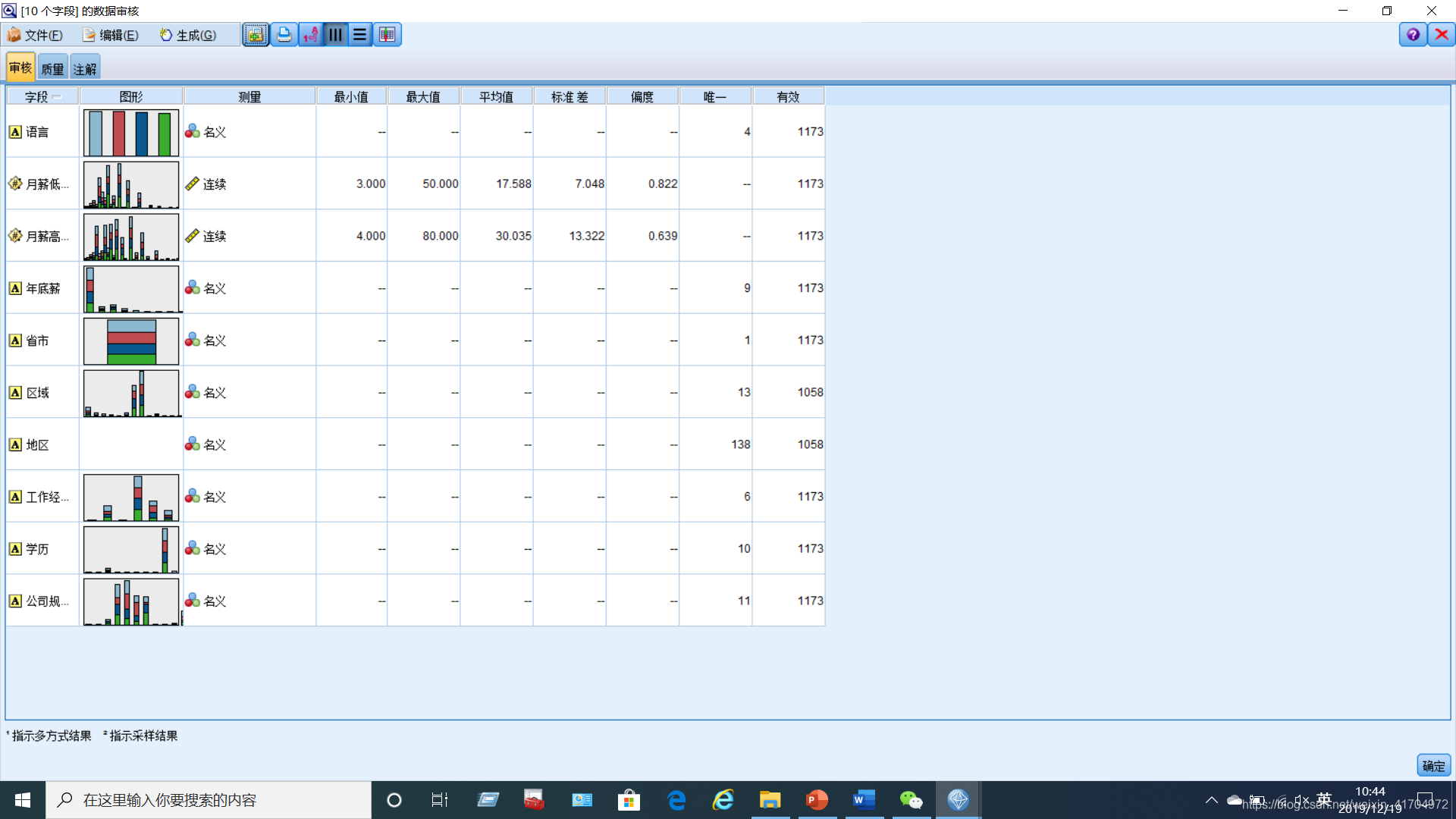
(1)数据质量评估
构建【数据审核】节点评估数据的质量。主要对数据的缺失、离群点和极端值等情况进行评估。本小组使用平均值、标准差等,来反映数据质量的评价指标,以及数据离群点和极端值的诊断标准。从对于数据的审核结果中可以比较明显的看到,每一个变量的分布差异并不明显。对于数据的质量结果中比较清晰的看到原始数据的完整字段占比80%,完整记录为90.2%。
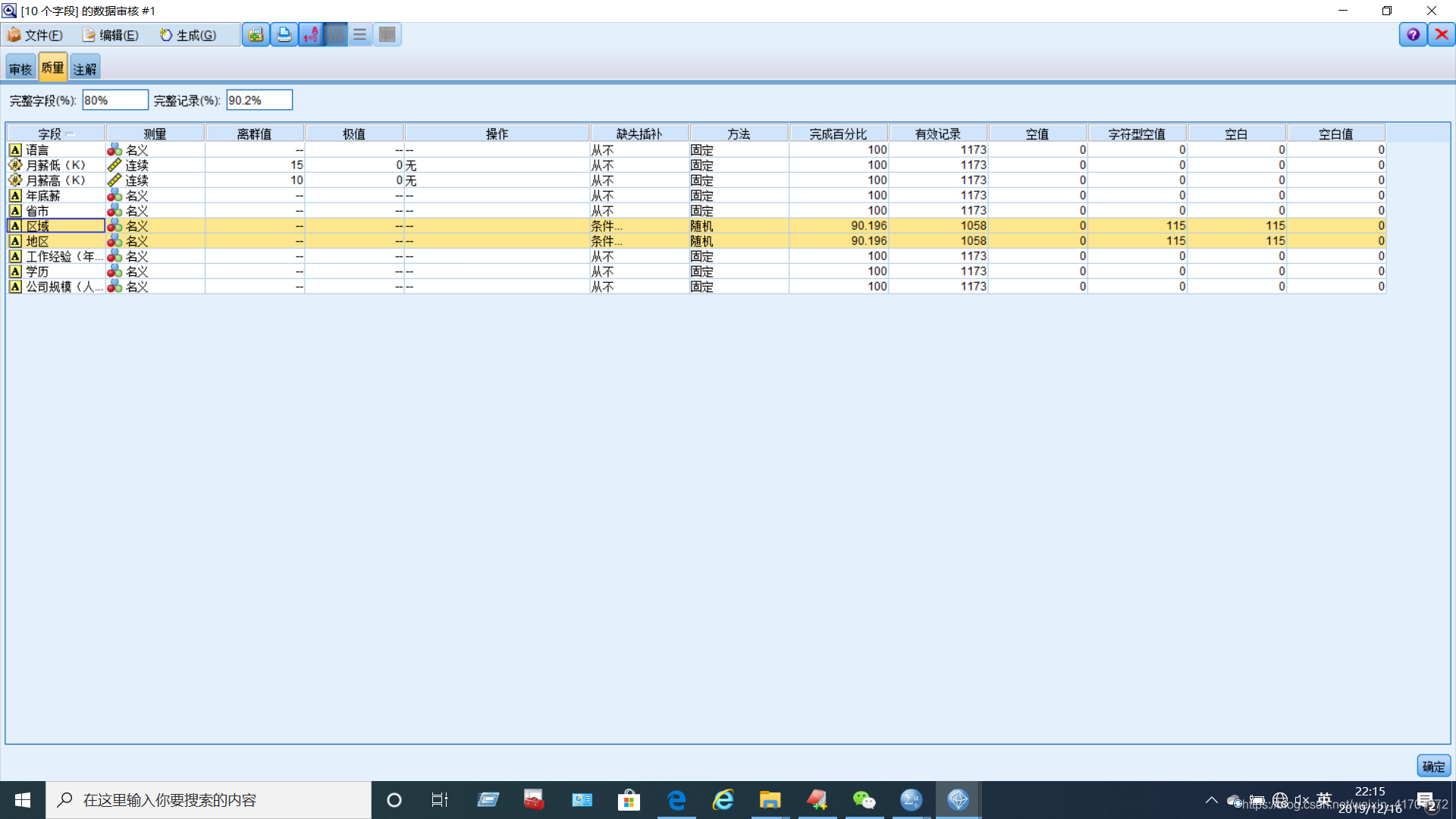
(2)样本质量提升
为提高数据的可使用性,提高数据分析结果的有效性。首先对于缺失值进行调整(92%),操作并创建了缺失值超节点,随后保留高质量的变量(99%)。经过调整后的数据质量明显提高,达到了99.32%。
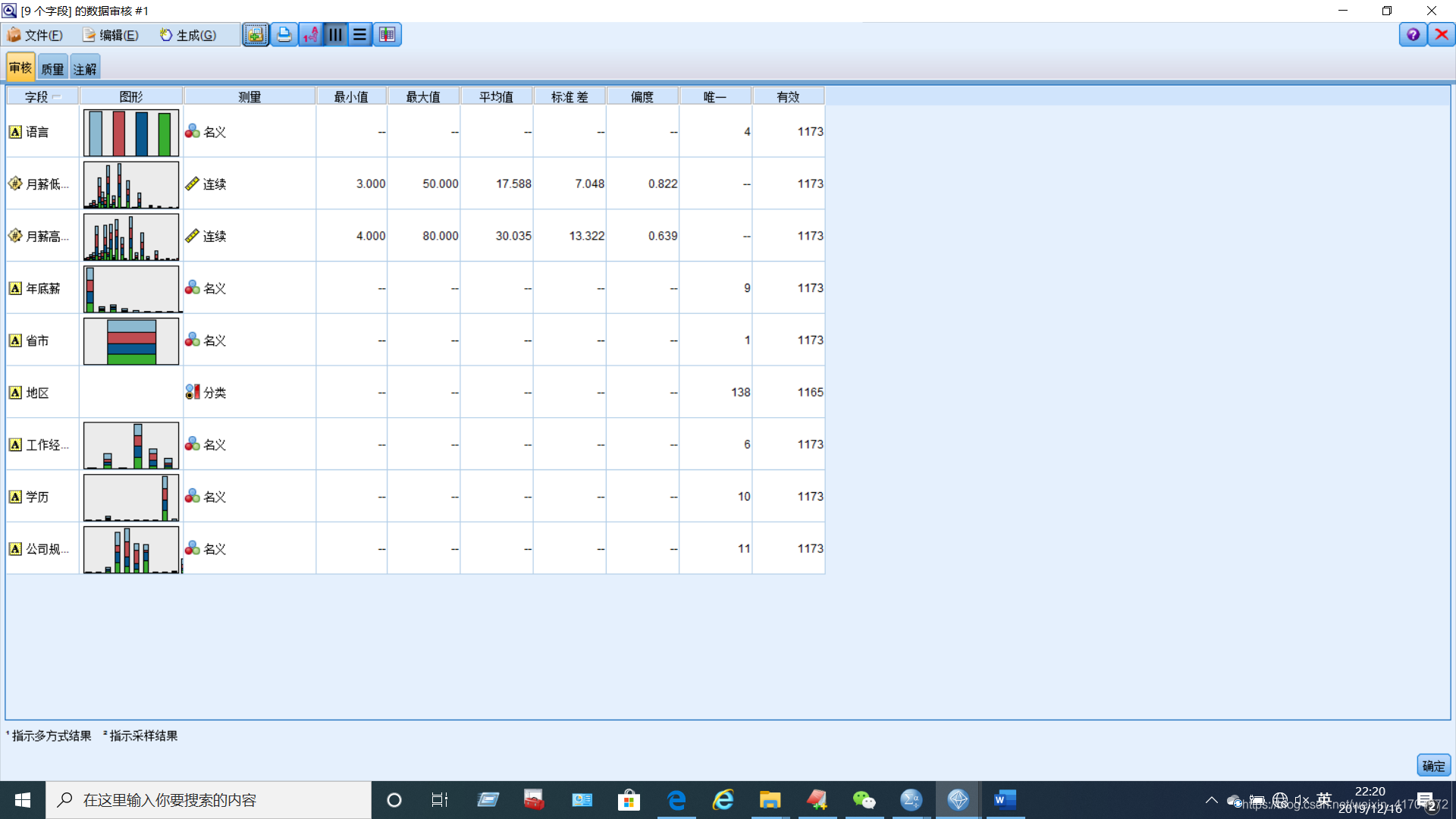
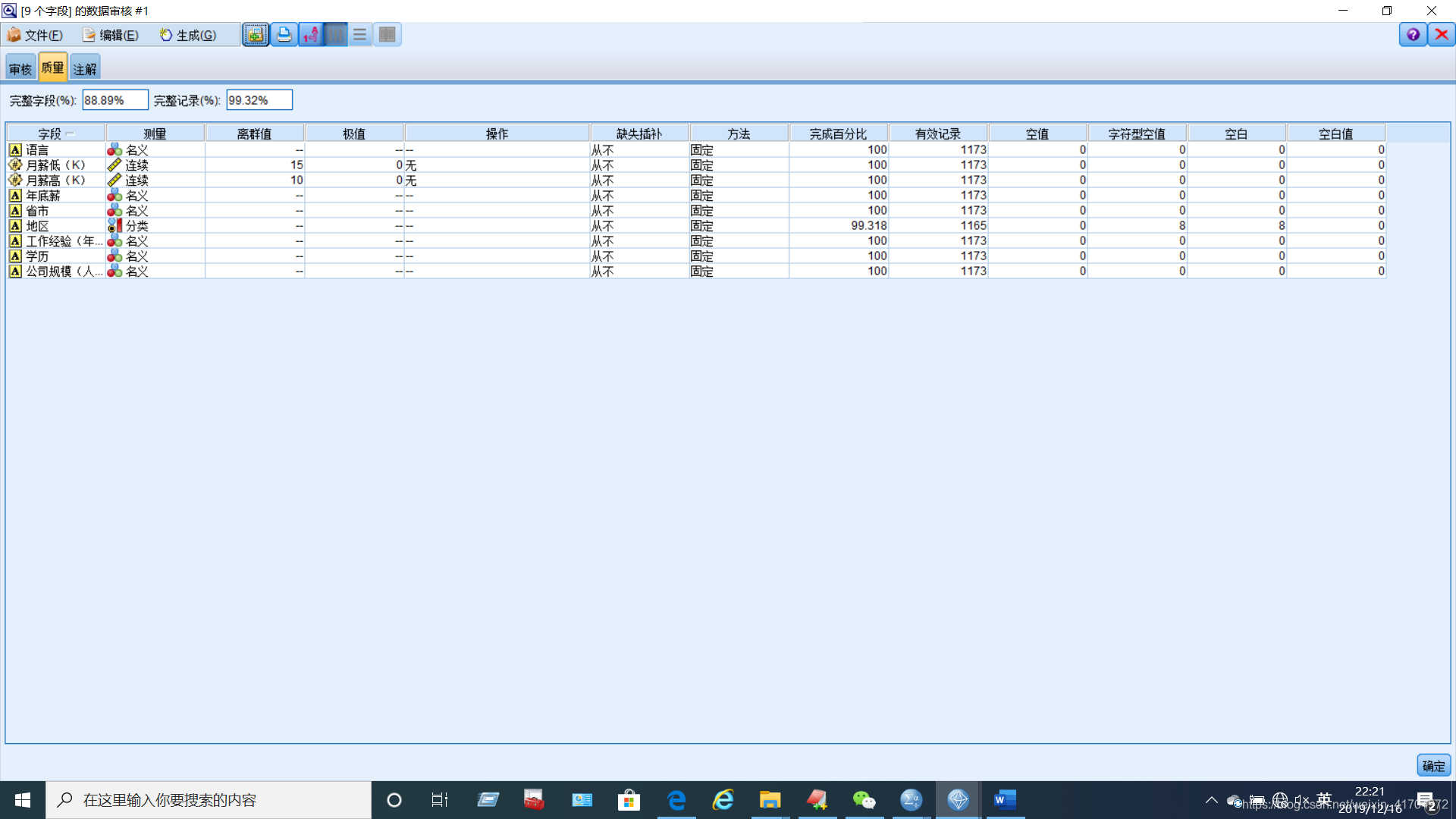
(3)分层抽样
因为选择爬取目前每种语言的前300条数据,但部分语言的招聘信息不足300条,所以数据中有部分语言数据量不满300条的情况,且网站排序缘由未知,为了对数据的变量间的相关性等不受数量等其他因素影响,本小组选择依据语言进行分层抽样,每个语言抽取250条数据,并导出最终数据。
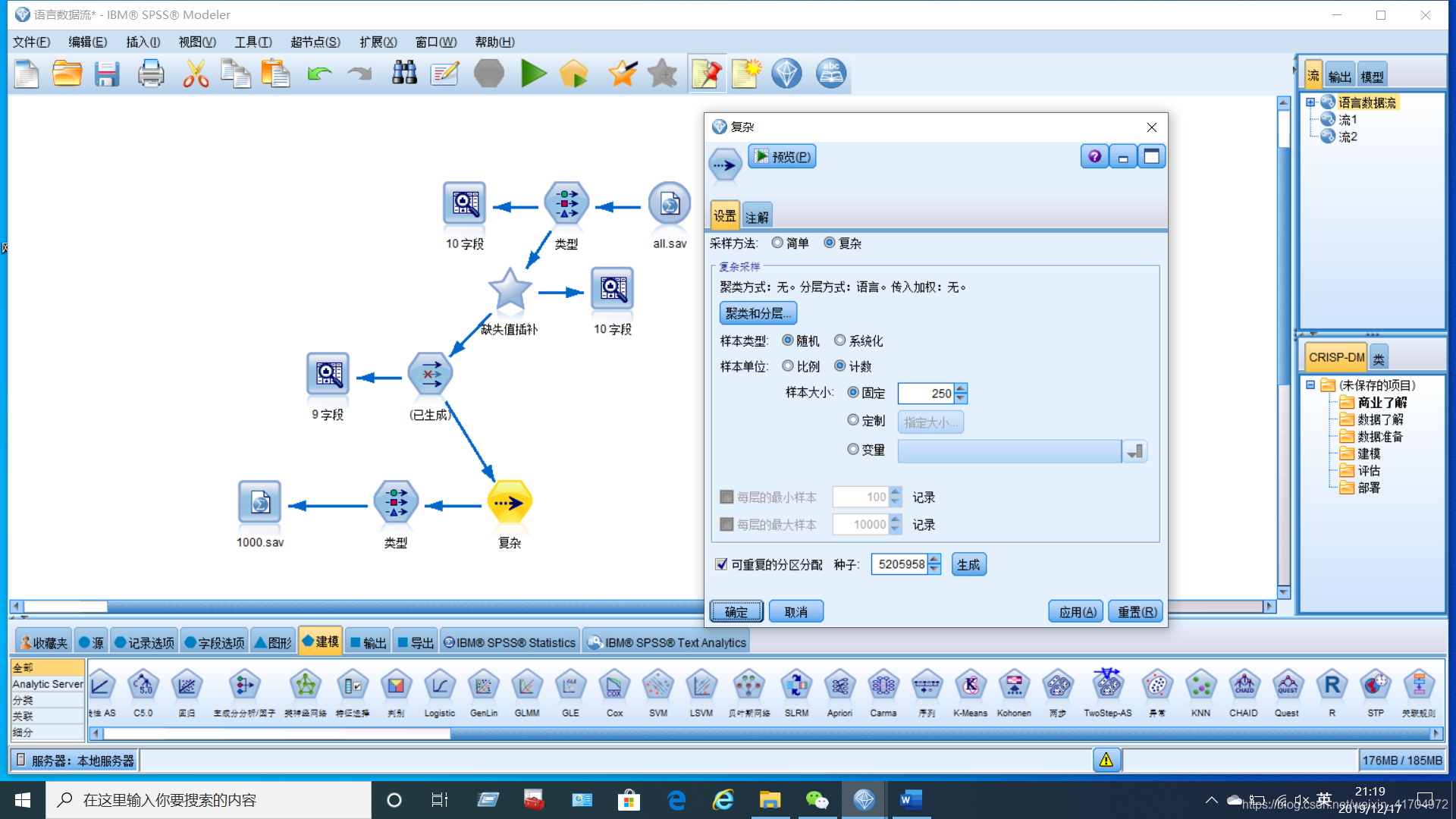
(4)分级操作和人工调整变量。
根据导出的数据进行观察,用“(年薪低+年薪高)/2*年底薪”得到每个岗位每年的薪水大概预估数值,并对于年薪和公司规模进行分级处理,最终得到完整数据。
其中对于年薪等级是按照200,400,600,800这么划分为等级1,等级2,等级3……公司规模等级是100以下为等级1,100-1000为等级2,1000-10000为等级3,10000以上为等级4。
(5)相关性分析
1)“语言”和“公司规模”相关性图形分析
小组对“语言”和“公司规模”两分类型变量相关性进行粗略的通过直方图进行图形分析,可以清晰的看出,正在使用或招聘关于Python、PHP、C++、 Java四个语言的公司规模都不一样,大、中、小型公司都有相关语言岗位的需求。
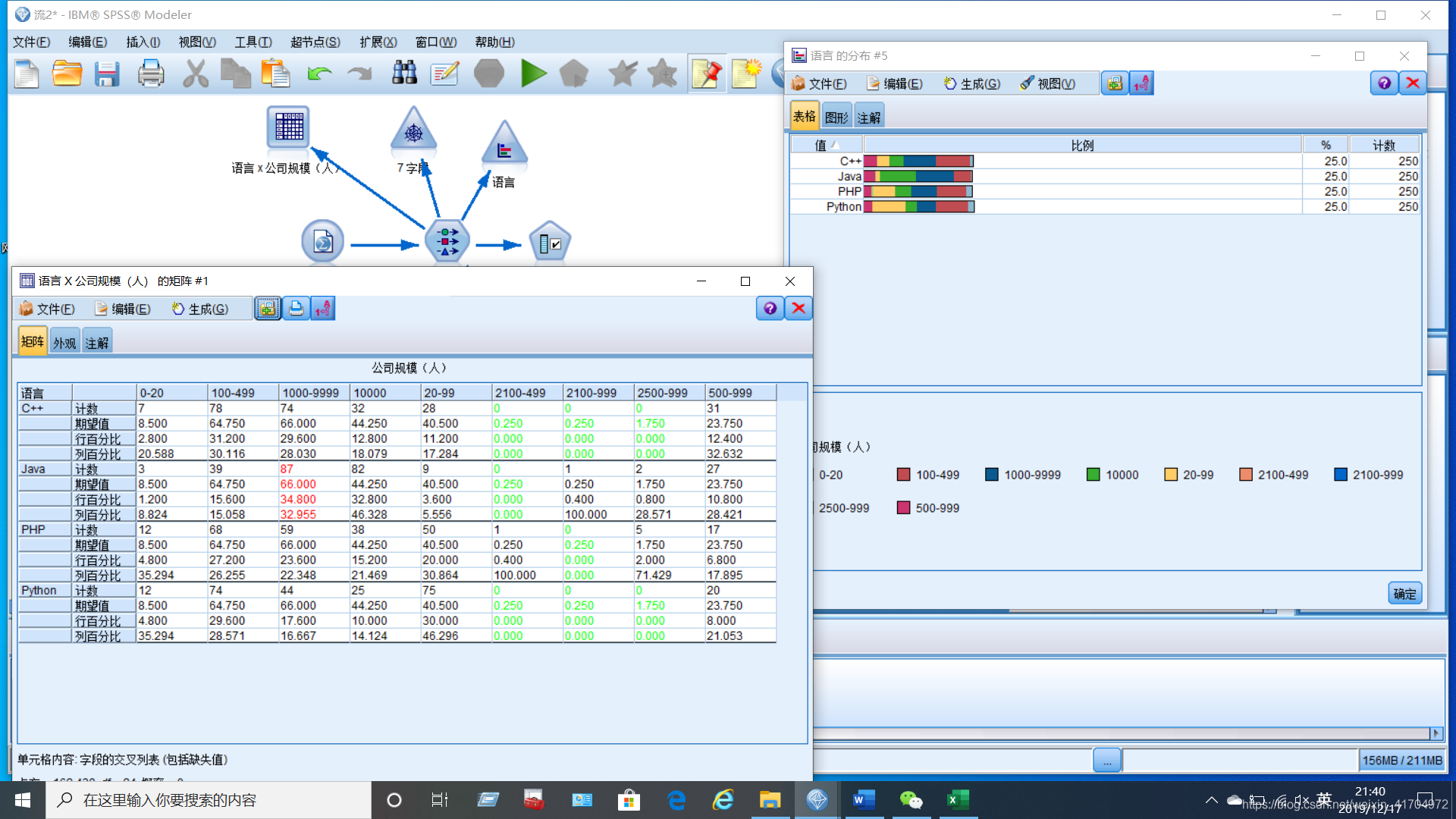
2)“语言”和“公司规模”相关性数值分析
小组为做更为精细的分析,对“语言”和“公司规模”两分类型变量相关性的数值分析。在数据中可以比较清楚的看到,需要Java语言岗位的公司大多以1000-9999规模为主,且此规模的公司更需要Java语言的工作者。同时发现本数据中中小型999-2000规模的企业对于语言岗位的需求比较少,可以推测一方面原因是在网站登记时填写的规模时,选择填写公司为该规模的少,另外推测一方面原因是该规模下的公司不是计算机程序语言类公司。
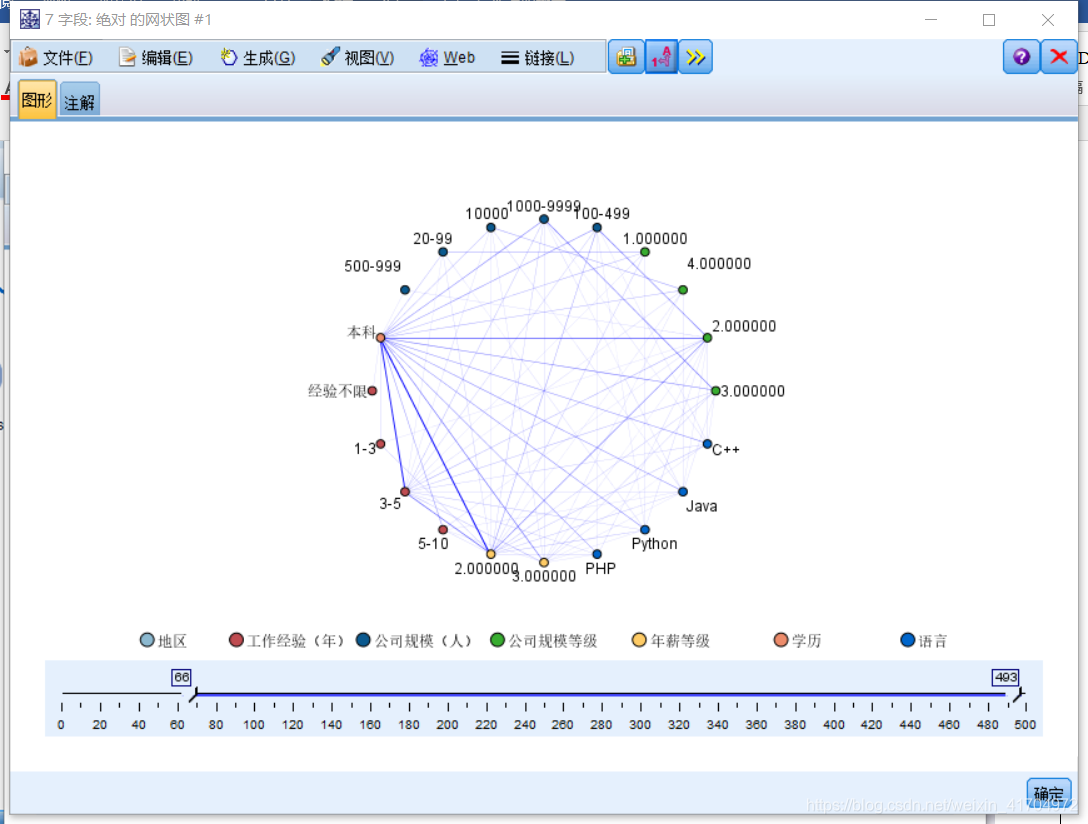
3)所有变量的相关性图形分析。
通过网状图可以比较直观的看到年薪等级为等级2和学历为本科的相关性强,工作经验为3-5年和学历为本科的相关性强。
(6)变量特征分析
为具体探究每个变量对于不同语言的重要性,给接下来的数据分析给予指导性意见,避免对接下来的数据挖掘和可视化分析结果的无效,选择创建【特征选择】节点,分析变量的重要性排序。排序结果如下:
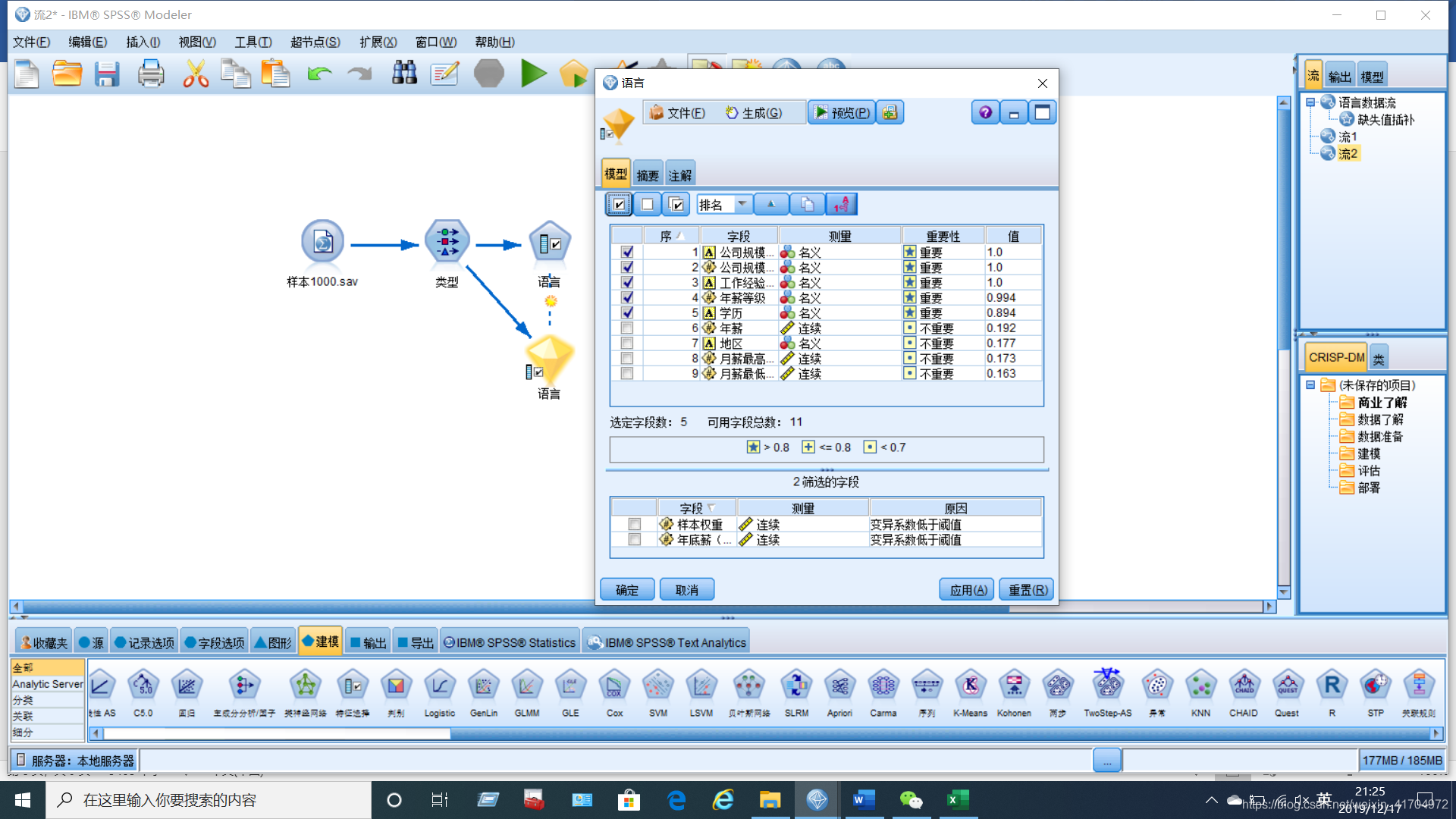
3.数据挖掘
总体预测
现阶段公众关注的问题主要向两个方向发展:1.影响年薪等级的重要因素有哪些?2.未来何种语言走势更好?对此,利用三个算法对各个问题进行总体预测。
1)构建流
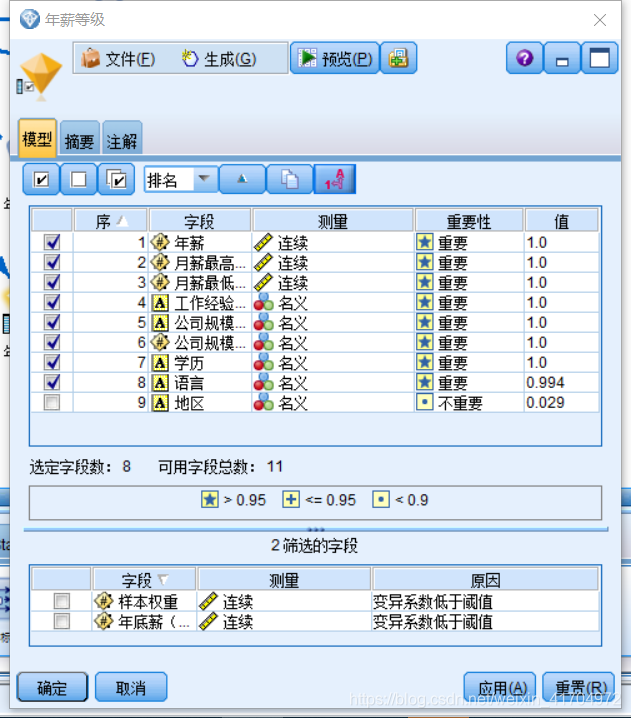
2)添加“特征选择”节点选择重要字段,滤除非重要性的字段。
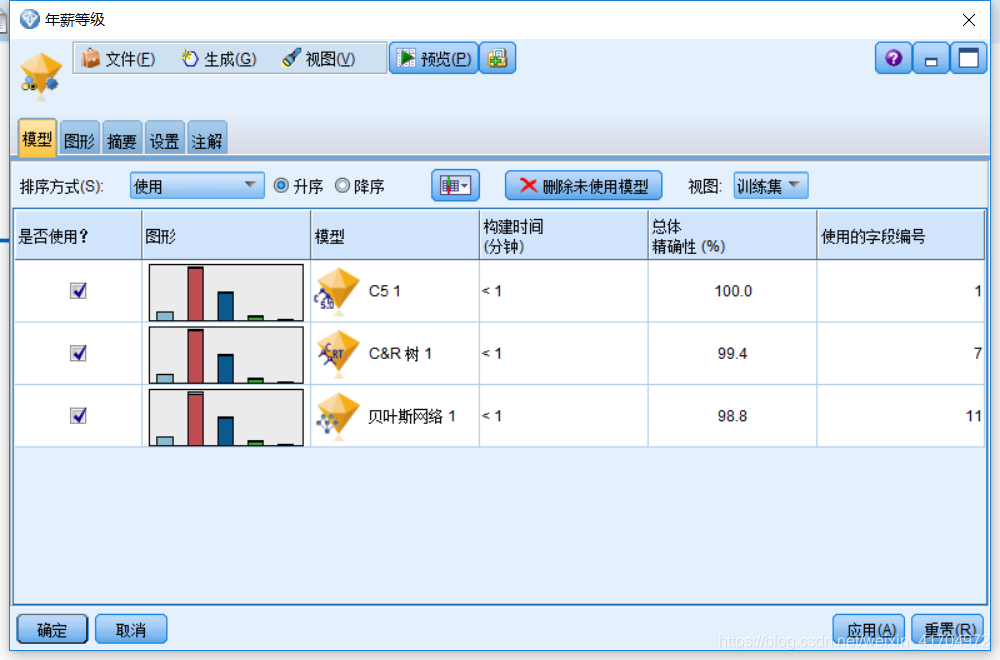
3)添加“自动分类器”节点,我们为目标自动创建和比较多个不同的模型并组合多个模型的优势融为一体,从而产生任何单一模型所不能带来的更为准确的预测。如图所示,节点生成了一组候选模型并对其进行排序,我们将C5.0算法、C&R树算法和贝叶斯网络算法选用为最有效模型并利用它们对本项目进行数据分析。
4)利用C5.0决策树算法,研究哪些因素显著影响年薪等级。在此,我们用的变量仅为(语言、年薪等级、工作经验、学历、公司规模),所以添加过滤器节点将无用变量滤除。
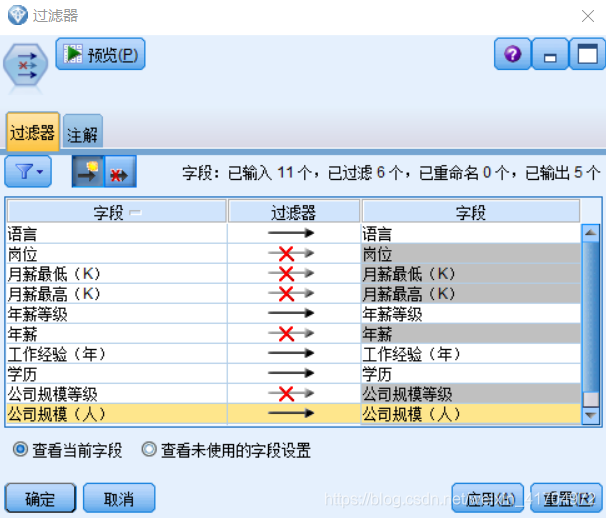
5)在“模型”选项卡上设置C5.0算法的主要参数:输出类型选用“规则集”;勾选组符号,利用ChiMerge分箱法检查当前分组变量的各个类别能否合并,如果可以应先合并再分支,这种方式得到的树更为精简;选择“boosting”采用推进方式建立模型以提高模型预测的稳健性,点击“专家”选项,并在“修剪严重性”框中输入决策树修剪时的置信度,默认为75=100-25。
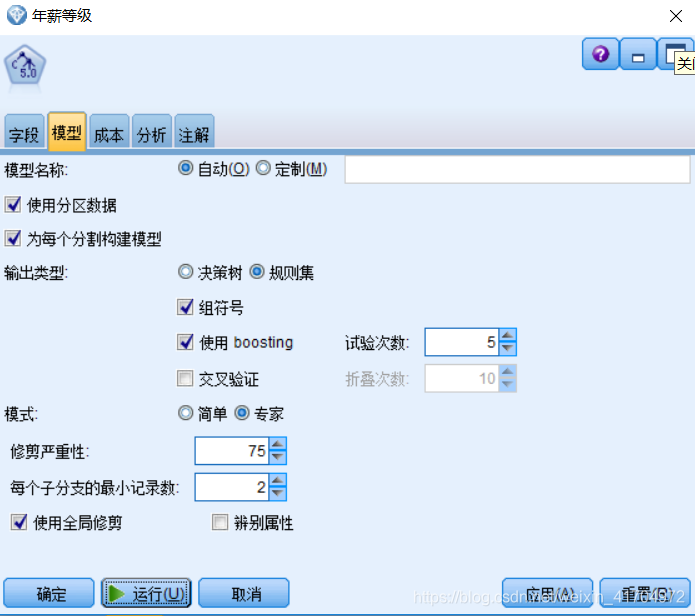
6)在“分析”选项卡上设置计算输入变量重要性的指标,以图形方式显示输入变量对建模的重要性(因为计算原始倾向评分仅对标志目标有效,因此在这里没有勾选计算倾向评分)
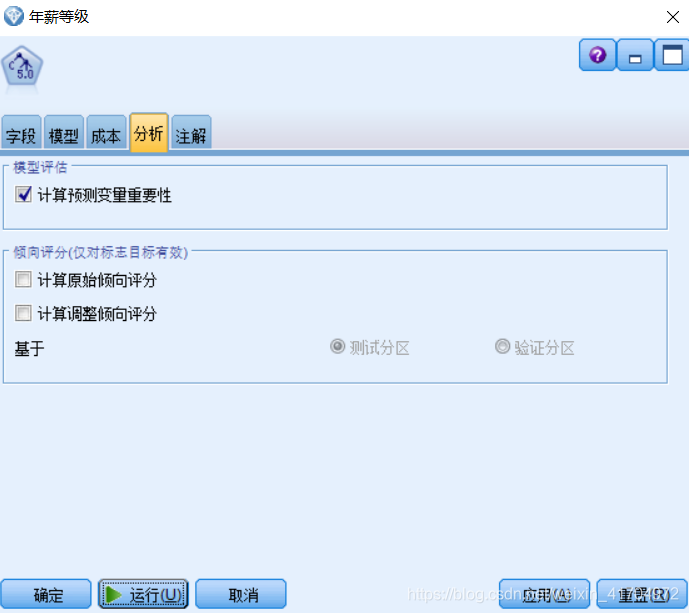
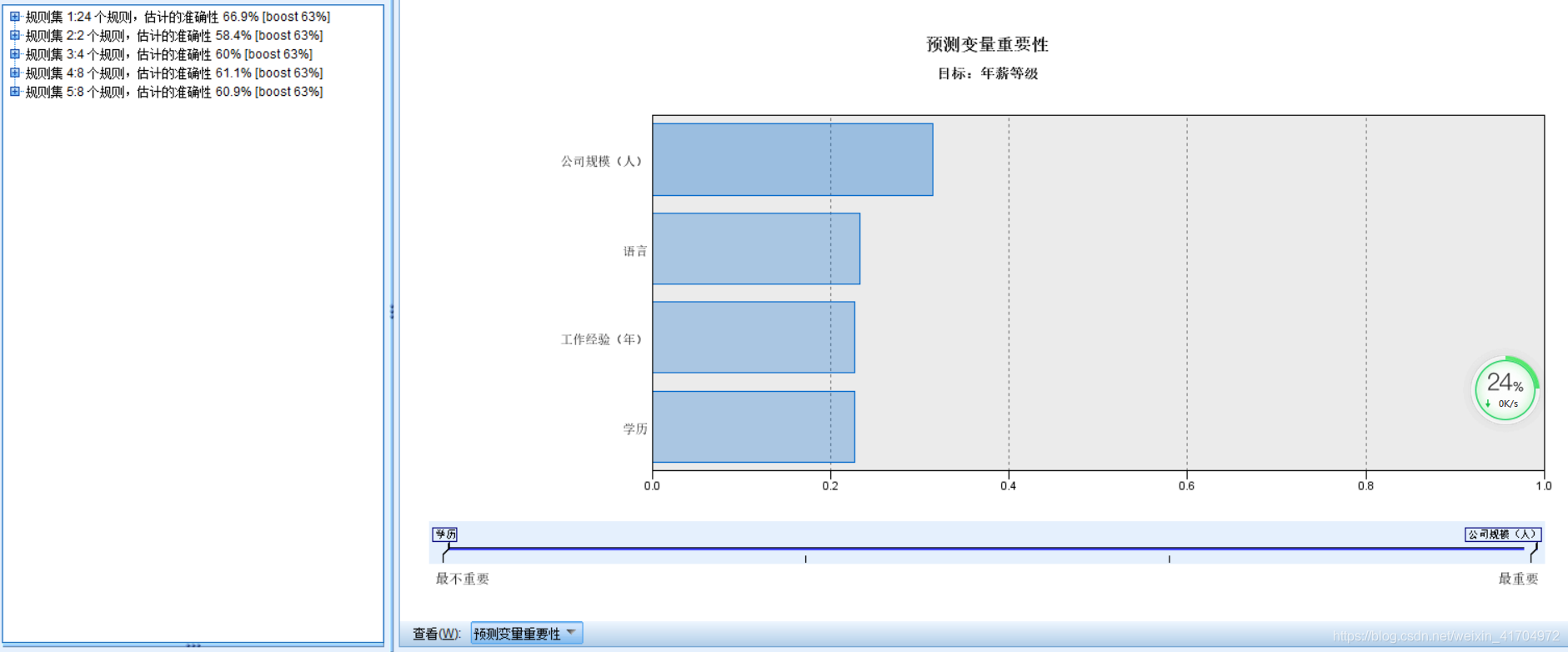
7)C5.0的模型计算结果以文字和图形两种形式分别显示在左边和右边:左侧是推理规则集,右侧是输入变量倾向性得分的图形表示。从计算结果中,我们可以看到公司规模、语言、工作经验、学历都是影响年薪等级的重要因素,其中公司规模占比最大,其他三个因素相对而言占比最小。
8)为了验证结论的准确性,使用C&R算法进一步确认影响年薪等级的重要因素。重复上述的特征选择和滤除无用字段等步骤,添加“C&R树”节点,将其连接到数据流恰当位置上,设置主要参数。这里主要介绍“构建选项”选项卡。“构建选项”选项卡用于设置分类回归树的主要参数,包括目标、基本、停止规则、成本和先验、整体、高级六类。
9)在“基本”选项卡中设置分类回归树的预修剪和后修建的基本参数。
10)在停止规则选项卡中设置分类回归树预修剪的其他参数。
11)在“成本和先验”选项卡中设置损失矩阵和先验分布。
12)在“整体”选项卡中指定使用Boosting策略时建立模型的个数,这里选择默认值10,以及预测时应如何采纳各模型的预测结果。分类树默认采用投票方式,回归树默认采用均值。
13)在“高级”选项卡中设置分类回归树建立和修剪过程的高级参数。
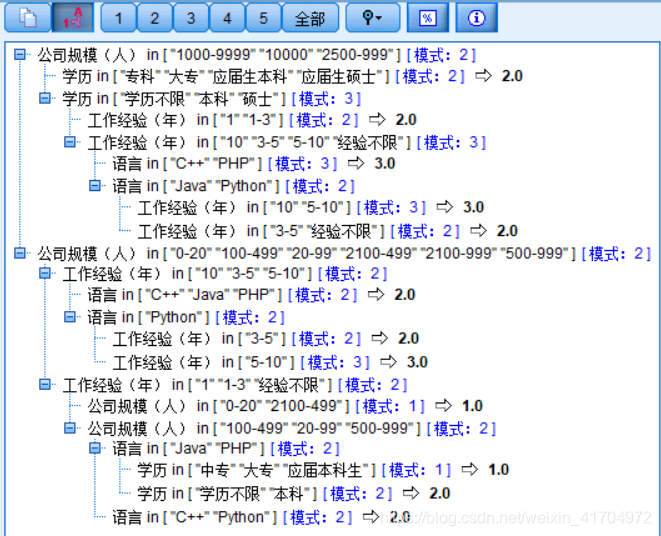
14)计算结果:通过分类回归树算法找出四个影响因素:公司规模、工作经验、学历和语言,其中公司规模所占比重最大,与C5.0算法得出的结论大同小异。
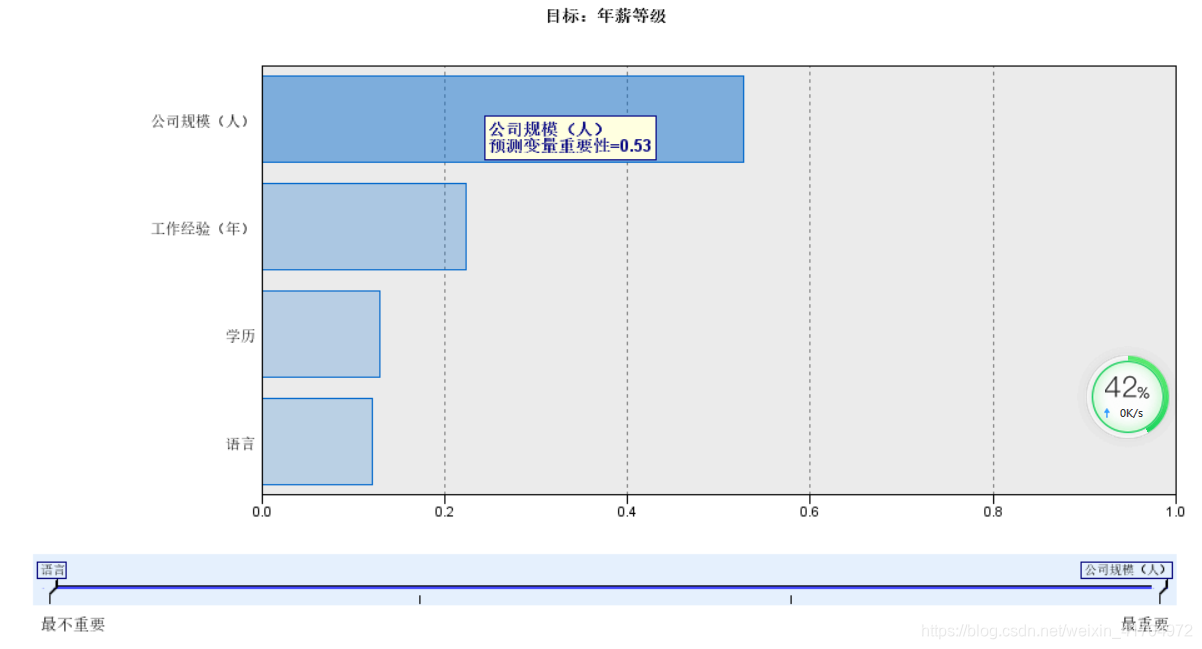
15)分析结论:从两个算法的分析结果来看,可以认为公司规模、工作经验、学历和语言都对年薪等级有显著性影响,其中公司规模对年薪等级的影响更为显著,占比53%,但其他三个影响因素的作用也不容忽视。
接下来采用贝叶斯网络研究未来语言的大致走势,重复上述算法中的特征选择和滤除无用字段的步骤,添加“贝叶斯网络”节点至流的恰当位置上,打开“模型”选项卡设置主要参数,这里选用的是Tan贝叶斯网络。
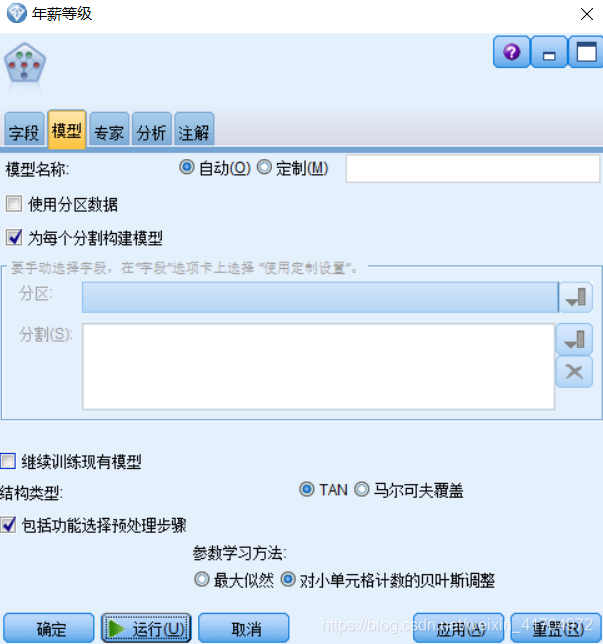
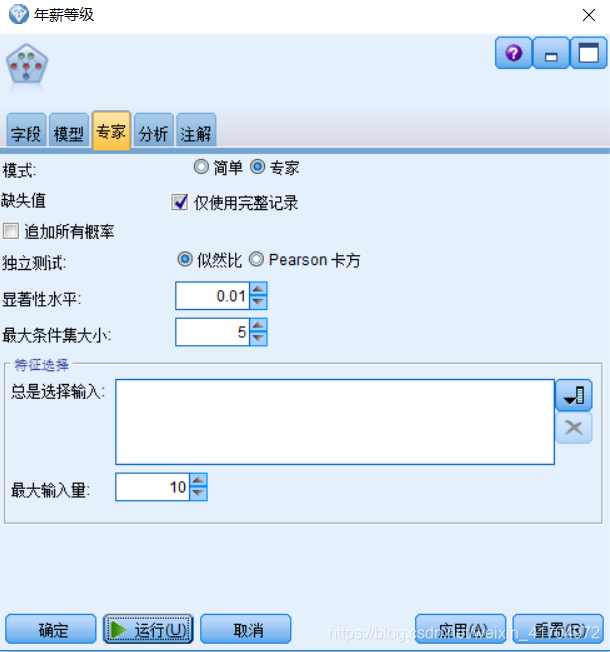
1)在“专家”选项卡上设置模型的其他参数。因为样本集不算大,如果选用“极大似然”估计,很可能因为训练样本集较小造成很多的条件概率为0,因此在“参数学习方法”处选用“对小单元格计数的贝叶斯调整”。
2)结果解读:Tan贝叶斯网络的结果如下图所示,左侧显示的是计算出来的Tan贝叶斯网络,右侧是语言的条件概率表。
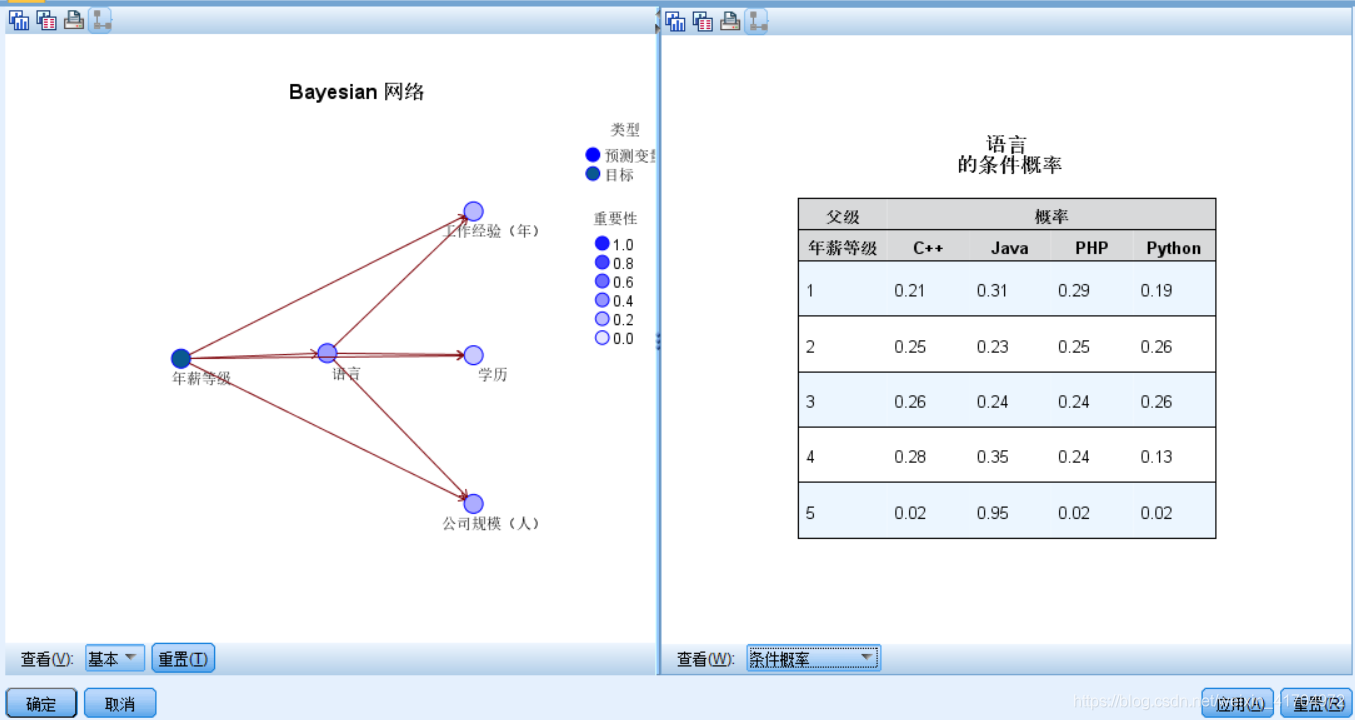
3)分析结论:显而易见,年薪等级为5时,Java语言所占比重高达95%,而在年薪等级为4时,Java语言所占比重也有35%,由此可见,从事Java语言岗位年薪更高,其次是C++、PHP和python,因此我们预测,Java和C++两种语言在未来的走势会更好。
具体预测
如果引导大众选择正确的求职方向,还需要对样本进行基于总体之上的具体预测,我初步拟定了三个方向:1.各类语言在不同年薪等级的具体分布情况;2.工作经验对年薪等级的影响情况;3.企业对学历的需求情况。同样的,我用了三种算法进行研究。
(1) 各类语言在不同年薪等级的具体分布情况
1)构建流
2)在进行以“年薪”为目标的数据评估后,可以发现,工作经验、公司规模、学历、所学语言都对“年薪”有显著性影响,但是处于北京的某个区对“年薪”没有什么影响(其中由于年薪等级是年薪进行划分出来的,而年薪又是由月薪计算出来的所以可以直观的看“年新等级”,忽略月薪对其的影响),所以大家在找工作时应该多注意这四个方向,确保自己有一定学历实力、尽量学精某一门语言,有一定工作经验;在找职位时注意公司规模,对于职位的上升空间和多方面发展都有一定好处。因此,在这里通过CHAID算法研究语言在各个年薪等级中的分布情况。
以下是输出结果:
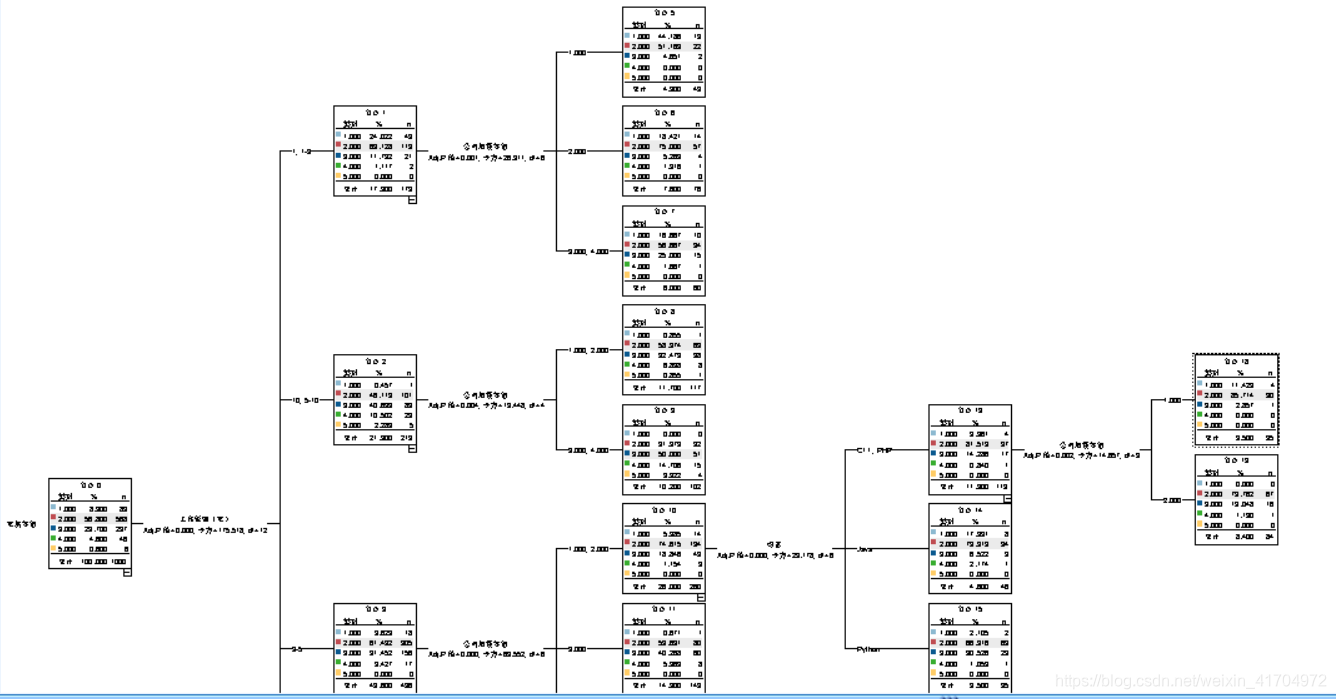
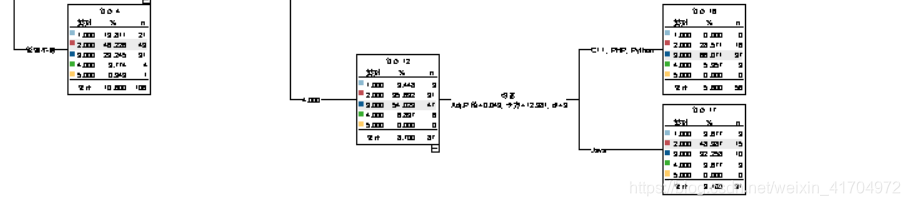
3)进一步对语言和年薪的关系进行了一下图形可视化,可以更具体的看出四种语言的年薪差距。
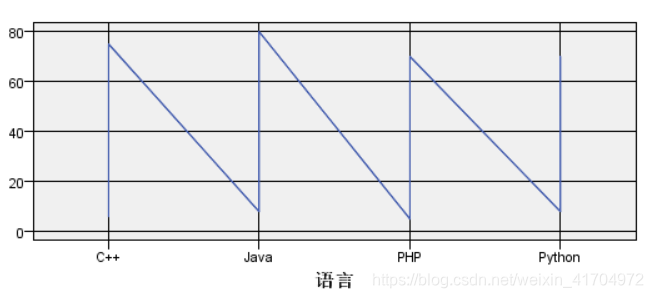
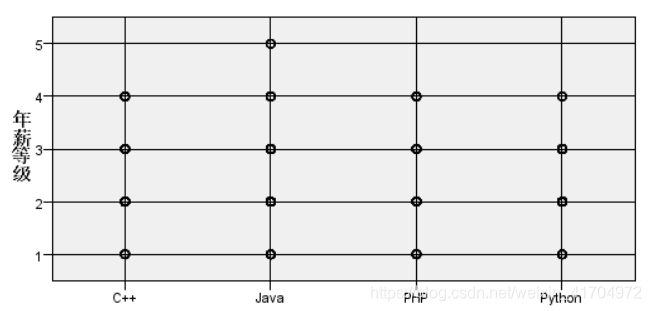
4)结果解读:不难发现,其实c++、java、PHP、python四种语言在年薪、月薪分布方面其实差距不大,基本都是4-5的等级,月薪在在60-80区间内,其中只有java到了等级5并且月薪最高值最高,所以想得更高利润的可以倾向于学习java。对其它语言有兴趣的同学也可以继续坚持自己的喜好,薪资不会差很多。
(2)工作经验为现阶段找工作企业评测的重要指标。对此,采用Logistic回归算法,以工作经验为自变量,年薪为因变量,目标对多少年工作经验和年薪做显著性检验。
1)输出结果:
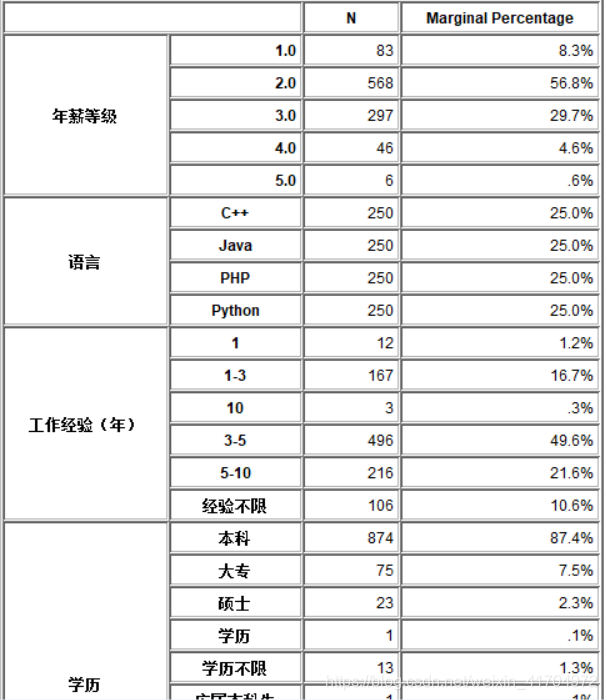
2)通过上图我们可以了解到现在市场的大概轮廓,现在各公司的年新等级基本都在2-3左右,也就是说平均月薪都在2-3万左右;招聘要求一般都是工作经验3-5年的公司最多,其次是5-10年,所以说再有了1-3年的工作经验时,考虑换公司或者职位是最好的时机与选择,5-10年的也有一定需求,不建议只干几个月,因为需要1-3年经验的公司相对较少。学历:87.4%都是本科生,所以说本科生直接就业还是占绝大多数,且都能找到工作;公司规模等级:2-3级占比较大,公司人数一般是在200-9999人。
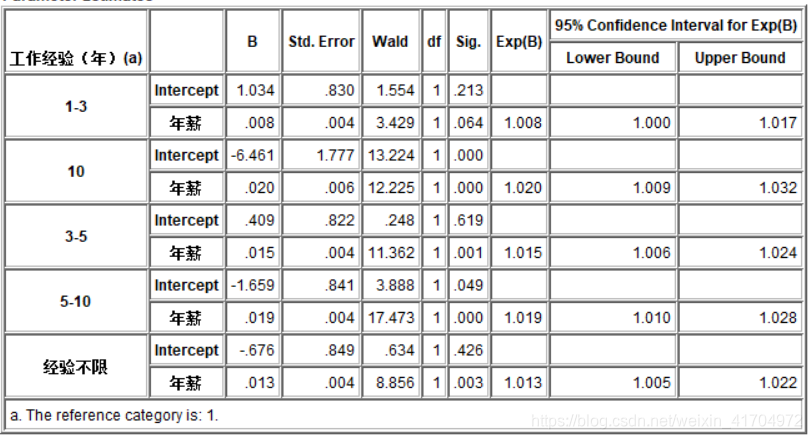
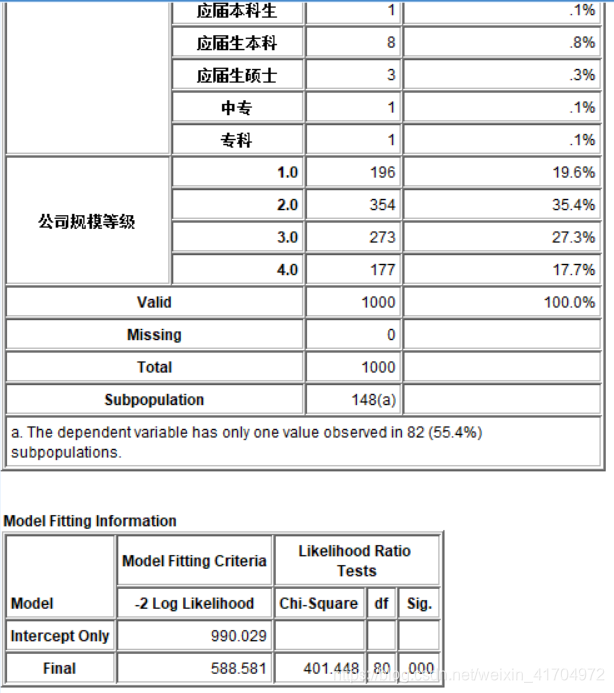
3)从输出结果可以看出,当Wald值越大而Sig(p)越小时,自变量的影响就越大(各变量的标准误都基本一致),从此图中我们可以得出结论:工作经验在3-5年这个阶段年薪变化幅度最大,可能是大部分人都在重新寻找新公司在这个阶段,还有可能是一个岗位升职的年限在3-5年左右;其次是不限制经验的公司,而对于刚毕业的本科生来未来就业,年薪基本上不会受工作经验的影响。所以这也给了我们一个警醒,当在年薪还不太受经验影响的时候,尽量在岗位上多学习,拓宽自己的眼界和增强学习能力,多接触活动,多增长经验有益于在后面不管是升职还是重新选择公司时可以获得较高报酬。
(3)接下来通过贝叶斯网络以“学历”为目标,查看规模较大的公司大体需要什么样的学历,会有多高的年薪。
1)输出结果如下:

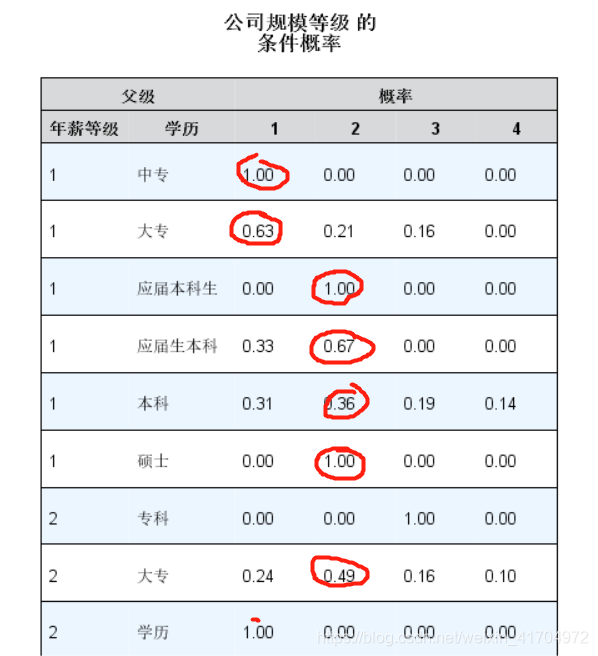
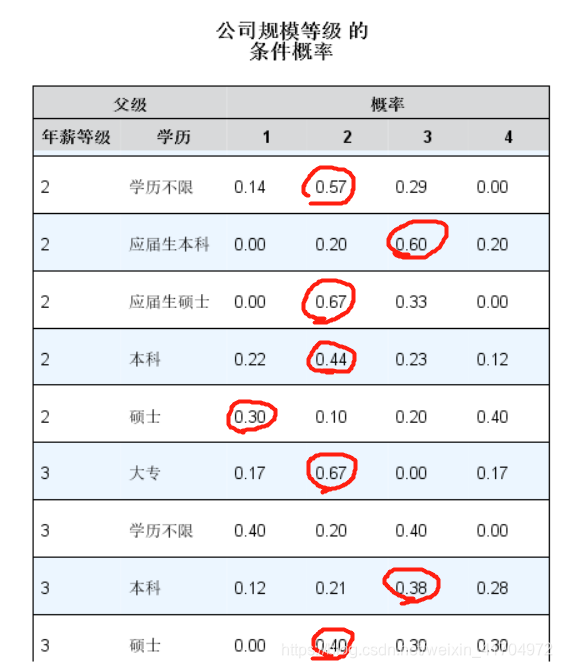
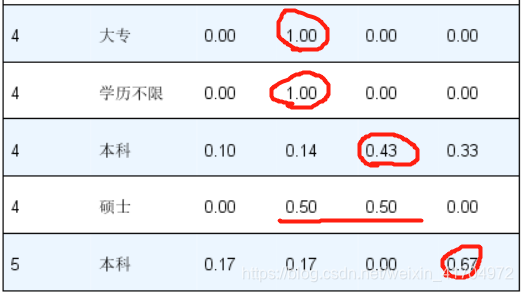
2)结果解读:通过结果,可以看出本科学历以上的大多数人在每个公司等级都有些许占比,根据上面的分析结果,本科生大多数都在年薪级别2-3内,从这里可以发现大多数本科生在这个年薪级别内都在公司规模为2-3的公司里,这也给我们提供了一些思路,当你在有了3-5年的工作经验后可以选择更大规模的公司,这会给你提供一些更好的发展机会和加薪机会;同时也表明现在2-4规模的公司里基本上都还是以本科生为主,说明现在本科生直接就业的几率还是很大的,市场对人才的需求还是在本科生这个水平上。
3)分析结论:根据上述算法结果,从中可以得出一些结论:
- 在有相同工作经验的情况下,语言不会对薪资产生很大影响,所以坚持自己最有兴趣的语言。
- 现在本科生的就业率还是极大的,大部分公司还是以本科为基准。
- 刚毕业的本科生找工作可能有些难,现在大部分市场都是需要3-5年工作经验的,所以大家应该尽量珍惜实习学习的机会,在这期间多积攒经验,尽量不要在前两三年完全以赚钱为上班的目标。
- 在有了1-3年经验后,这个时候选择跳槽,应该对年薪和公司规模有一些要求,基本上公司规模在2-3左右的公司,给的基本年薪也都是在2-4左右。
总结:关于这次小数据挖掘实战,我考虑到某些新手小伙伴可能对SPSS Modeler并不熟悉,所以具体过程写的比较细。如果大家想亲自实战,需要注意的几点是:首先要数据的真实性,数量,质量,数据是否清晰描述;其次是数据预处理过程的合理性;最后是数据挖掘方法选择以及建模过程设计的科学性与准确性。本文只是个人一次课余小型实战,不专业,对于不足的地方,希望读者们可以给一些建议啦~

