强化学习 马尔可夫决策过程 有限马尔可夫决策 部分可观测马尔可夫决策
目录
一.总体说明
二.组成要素
2.1 S-状态空间集
2.2 A-动作空间集
2.3 P-状态转移概率
2.4 奖励函数
三.状态转移
一.总体说明
马尔可夫决策(MDP)是强化学习中智能体与环境进行交互的实现方式。我们把状态及其状态信号的属性称为马尔可夫性质,在马尔可夫性质中,每一步环境对智能体的反馈仅取决于上一步的状态state与动作action,与之前的行走过程没有关系。
在序列决策问题中。智能体的目标是通过选择合适的动作以保证长期奖赏能够最大化,每个动作都会影响长期的训练效果。其中长期奖赏是很重要的,有时候智能体会为了长期奖赏而牺牲短期奖赏。MDP的动作不仅影响当前的即时收益,还影响后续的状态以及未来的收益。
划线涂成棕色的话看似是矛盾的,但其实他俩的表述完全可以共存。每一步环境对智能体的反馈指的是智能体与环境进行交互时只需考虑上一步的状态与动作。MDP的动作影响了当前的即时收益即这一步与环境交互的结果,而这些交互后产生的奖励会累积成长期收益。
二.组成要素
马尔可夫决策过程由一个四元组构成,即MDP=(S,A,P,R),该四元组的组成元素主要内容如下:
2.1 S-状态空间集
表示t时刻的状态,
。我们使用状态来表示环境,状态具有反映环境特征的作用,智能体通过其进行学习。当S改变为环境的一部分时,这部分状态被称为观测O(observation),此时的马尔可夫决策过程被称为POMDP(partially observable Markov decision processes),即部分可观测马尔可夫决策过程。
2.2 A-动作空间集
表示t时刻的动作,
。动作可以用来表示控制系统的状态,因为智能体通过状态选择动作,所以在某一特定状态下的动作可以表示为A(s)。值得一提的是,有的时候某些动作无法应用于某些状态,此时需要用先决条件方程(precondition function)来建模SxA ->{true,false}用来表达动作a∈A能否用于状态s∈S。
2.3 P-状态转移概率
智能体在当前状态s下执行了动作a,得到了新的状态s'。状态转移概率指的是s在执行完动作a后得到奖励r并转移到s'的概率,记作p(s',r|s,a)。
2.4 奖励函数
智能体与环境进行交互时,即在当前状态s下执行动作a得到新状态时得到的奖励r满足的函数。记作R(s,a)。
三.状态转移
马尔可夫决策可以用如下的示意图表示:
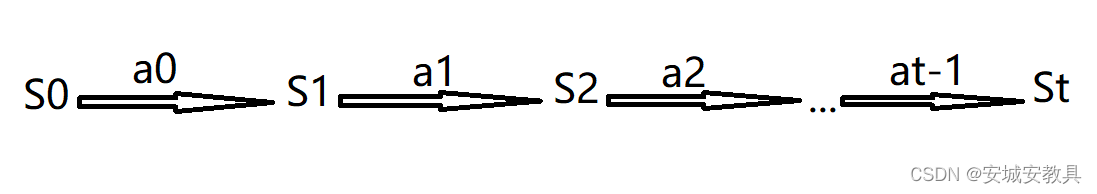
如图所示,智能体在状态s0下选择动作a0与环境进行交互,得到下时刻的状态s1,在s1状态下选择动作a1并执行,得到下时刻状态s2,以此不断重复,与环境进行交互实现强化学习。

