【C++进阶】C++软件异常的常见原因分析与总结(实战经验分享)
目录
1、概述
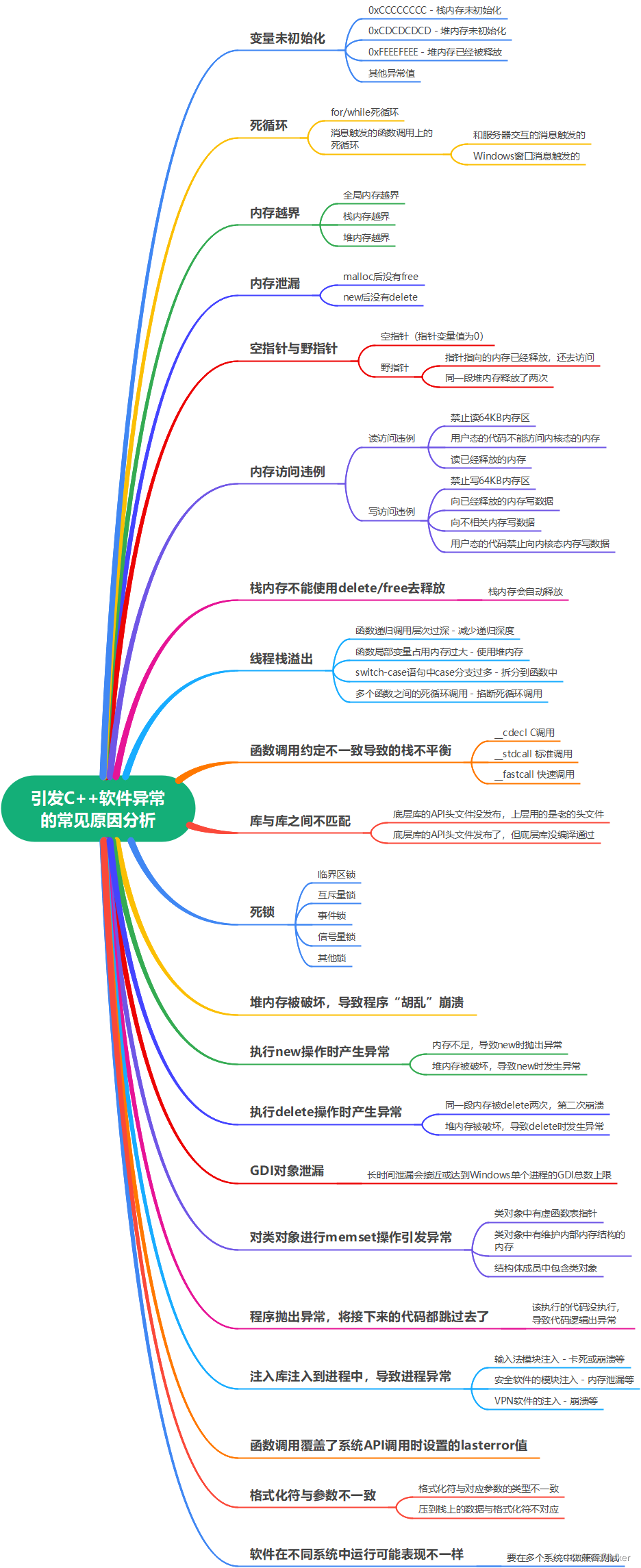
2、引发软件异常的常见原因
2.1、变量未初始化
2.2、死循环
2.3、内存越界
2.4、内存泄漏
2.5、空指针与野指针
2.6、内存访问违例
2.7、栈内存被当成堆内存去释放
2.8、线程栈溢出
2.9、函数调用约定不一致导致栈不平衡
2.10、库与库之间不匹配
2.11、死锁
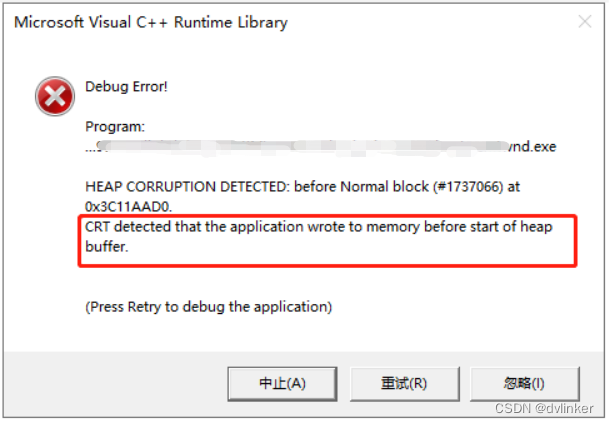
2.12、堆内存被破坏
2.13、执行new操作时抛出了异常
2.14、执行delete操作时发生了异常
2.15、GDI对象泄漏
2.16、对C++类或者包含C++类成员的结构体进行memset操作,破坏了C++类的内部内存结构
2.17、程序中抛出了异常,将部分该执行的代码跳过去了
2.18、模块注入到程序中导致程序出现异常
2.19、添加日志打印覆盖了lasterror的值
2.20、格式化时格式化符与参数不一致
2.21、同一个程序在不同系统中可能会有不同的表现
2.22、其他
3、最后
在C++软件开发和维护的过程中,会遇到各式各样的软件异常,这些问题的分析和排查可能会消耗大量的时间和精力,会给软件研发流程的顺利推进带来不利的影响。本文根据近几年排查C++软件异常的实践经历与实战经验,详细地总结出引发C++软件异常的常见原因,给大家提供一些借鉴和参考,以帮助大家快速地定位问题。
1、概述
作为一名经验丰富的C++软件研发人员,除了要有良好的代码编写与设计能力,还要有很强的代码调试能力和异常分析能力。而这些能力的培养不是一撮而就的,是通过大量的项目实践锻炼出来的。本文要讲述的内容不仅适用于刚入门的C++开发新人,也适用于有多年工作经验的C++开发人员。
本文所讲的C++软件异常,是广义上的C++软件运行异常,包括软件运行时逻辑上的异常以及引发软件卡死或崩溃的异常。引发C++软件异常的常见原因有变量未初始化、内存越界、内存访问违例、Stack Overflow线程栈溢出、空指针与野指针、死循环、死锁、内存泄露、GDI对象泄露、函数调用约定不一致导致的栈不平衡等,下面将对这些原因及场景进行详细地阐述。
希望大家在了解本文的内容之后,既能在编写代码时提前感知潜在的问题,也能在出问题之后多一些排查问题的思路与手段。
此外,本文主要以PC端的Windows平台下的C++开发为例进行讲解,不同平台及不同语言在多个方面是相通的,也具有一定的参考价值。
2、引发软件异常的常见原因
下面就来详细地讲述一下引起软件异常的常见原因及相关场景。
2.1、变量未初始化
这可能是许多人容易忽略的问题。如果在定义变量时没有对变量进行初始化,在Debug下某些编译器会自动对变量自动进行初始化,但在Release下编译器不会对变量初始化,此时变量的值则是分配到内存时内存中的随机值。
对于微软C++编译器,在Debug下,未初始化的栈内存会被编译器初始化为0xCCCCCCCC,未初始化的堆内存会被编译器初始化为0xDDDDDDDD,这些特殊的异常值说明如下:
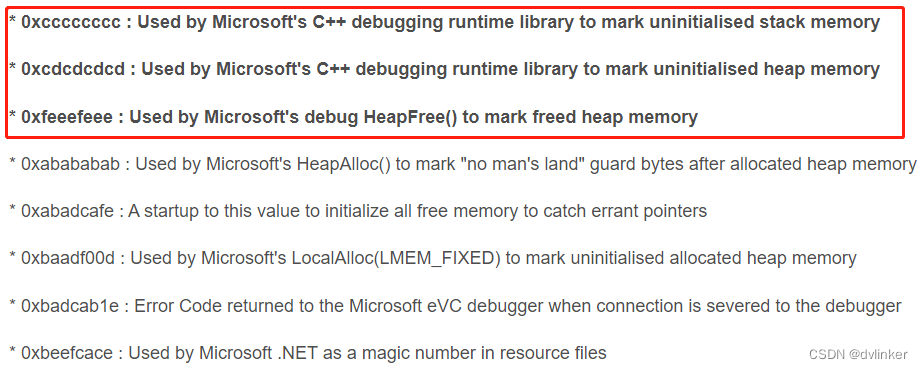
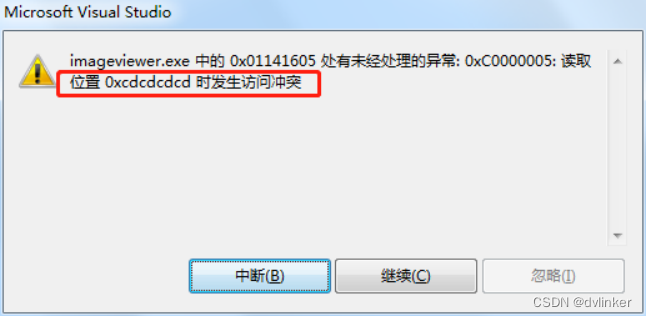
在调试代码时,如果遇到0xCCCCCCCC、0xDDDDDDDD异常值时,可能是变量未初始化,如果访问这些变量,则会报如下的内存访问违例错误:
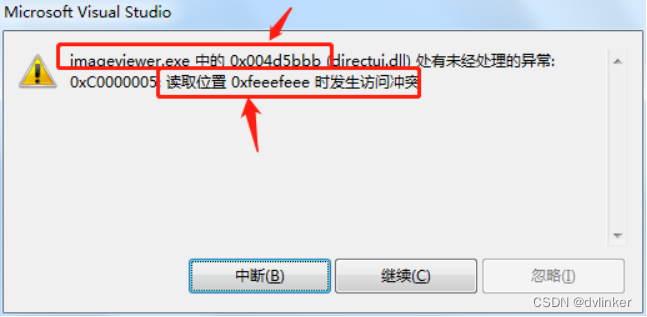
如果遇到0xFEEEFEEE异常值时,可能是堆内存被释放了,如果继续将其当做有效的内存地址去访问内存,则会报如下的内存访问违例错误:
如果代码中使用了没有初始化的变量,可能会导致Debug和Release下运行行为的不一致(因为Debug下编译器会自动初始化,Release下未初始化的变量的值是随机值),也可能会导致不同版本操作系统上运行行为的不一致(不同版本操作系统的内存管理机制是有差异的,比如win7和win10系统)。
具体地说,代码中使用了未初始化的变量,可能会导致代码逻辑出异常,可能会导致代码产生崩溃。比如在if条件语句中使用了未初始化的变量,会直接影响程序的走向。比如访问了一个没有初始化的C++对象指针,以该指针中存放的值作为一个C++地址去访问该对象的数据成员,可能会导致内存访问违例,引发程序崩溃。再比如使用了一个未初始化的函数指针(比如存放上层设置下来的回调函数地址的函数指针),在通过该函数指针去调用函数时会是致命的,会导致程序“跑飞”了,导致程序出现胡乱的崩溃。为什么会导致程序跑飞了呢?是因为函数指针没有初始化就去访问,函数指针的值就是个随机值,根本不是一个有效的函数地址,把这个无效值作为函数地址去call,会导致不可预料的结果,可能导致程序出现胡乱的崩溃。
可能有人会说,只要控制好现有的代码,就能保证不会访问未初始化的变量,不一定非要一上来就将变量初始化。即便是这样,也是不可取的,因为代码后面可能会交由其他人维护,每个人编写代码的水平是有差异的,你这里可以保证没问题,别人那边可能就会出问题。
2.2、死循环
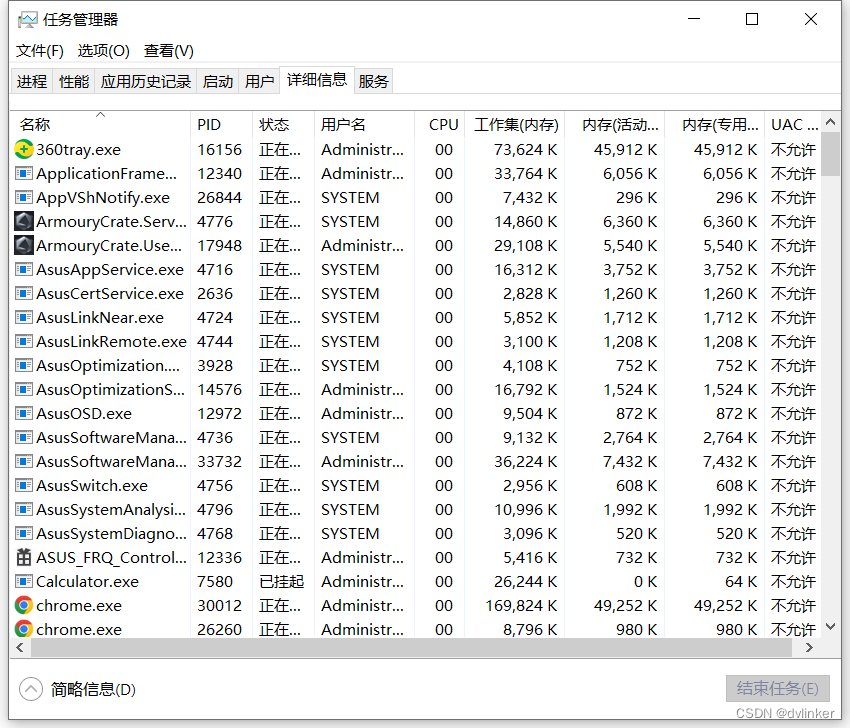
死循环一般会引发CPU高占用率,一般不会导致软件崩溃。一旦发现进程占用的CPU过高,可能就是死循环触发的,当然也有可能是新开线程的线程函数中没有添加sleep导致的(线程中不能一直在处理事务,要适当的“休息休息”)。
死循环一般是for循环或while循环的循环控制条件出了问题,可能是循环控制条件写错了(比如编写代码时的手误,比如将小于号写成了等于号,导致循环条件一直成立,循环一直退不出来),也可能是循环控制条件中变量出现了异常大的值(这个值可能是服务器返回的异常值,应该要添加值的合理性判断)。这两类问题我们在联调时都遇到过。
另外,还有一种情况是消息上触发的函数调用上的死循环。比如调用一个底层的接口,收到底层回应消息后,又调用了该底层接口,又收到底层的这个消息,循环往复地执行同样的函数调用,导致了死循环的发生。这样的例子,我们遇到过不止一次了。
再比如在窗口消息WM_MESSAGE1的处理函数A中调用了B函数,B函数又调用了C函数,C函数中又调用SendMessage发出了WM_MESSAGE1,由于SendMessage是直接把消息发给窗口处理过程,等消息被处理完后才会返回,相当于代码是同步执行的,所以又进入了A函数中,这样就形成了消息触发的函数调用的死循环,我们在项目中曾经遇到过一次。
死循环会导致所在线程的卡顿或堵塞,如果发生在UI线程中,UI界面会出现点击没反应或者反应很慢的情况。对于Windows程序,可以使用Windbg或者Process Explorer去定位死循环所在线程及函数。
Windbg和Process Explorer是排查死循环和CPU高占用问题的利器,都可以查看到进程中所有线程的CPU占用情况,可以进一步查看CPU占用高的线程的函数调用堆栈。相比较而言,Process Explorer要更易操作一点,但就调试功能而言,还是Windbg要强大很多。哪些场景下使用哪种工具,视个人喜好及问题的具体情况而定吧。
另外,这两个工具是需要pdb符号库文件的,因为要显示详细的函数调用堆栈信息(显示具体的函数名)是需要pdb符号库的(符号库中有函数及变量的详细信息)。对于windbg,需要将pdb文件的路径设置到windbg中。对于Process Explorer,只需要将pdb放置在目标exe的同级目录中,Process Exploer回到exe程序所在的目录 中去自动搜索并加载pdb文件的。
关于排查CPU占用高的案例,可以参见文章:
借助工具软件Clumsy和Process Explorer定位软件高CPU占用问题![]() https://blog.csdn.net/chenlycly/article/details/120931072
https://blog.csdn.net/chenlycly/article/details/120931072
2.3、内存越界
内存越界是指操作某个变量内存时,超过了该变量的内存范围,越界到该变量内存后面的内存上了。内存越界会篡改越界部分的内存中的内容,但内存越界不一定会导致崩溃,越界的内存区域可能是其他变量的内存区域,所以可能会篡改了其他变量的值。其他变量的值被篡改了,可能会导致软件业务出现问题,可能导致代码的运行控制逻辑出异常。
内存越界包含栈内存越界、堆内存越界以及全局内存越界,这些类型的内存越界,我们之前都遇到过。
1)函数的局部变量是栈上分配内存的,对栈内存的越界称之为栈内存越界;
2)通过new和malloc等动态申请内存的,都是在堆上分配的,对堆内存的越界称之为堆内存越界。
3)全局变量和static静态变量都在全局内存上分配内存的,对全局内存的越界称之为全局内存越界。
对于程序内存分区,可参见文章:
实例详解C++程序的五大内存分区![]() https://blog.csdn.net/chenlycly/article/details/120958761 对于栈内存越界,有可能越界到当前函数的其他局部变量上,另外在函数调用时,主调函数的返回地址、主调函数的ebp栈基址、用于esp校验的cookie值等都存在栈上的,有可能会越界到这些内存区域上,如果内存越界将这些内存破坏掉了,则会引起比较致命的错误。比如篡改了主调函数的返回地址,那么等被调函数返回时,要执行主调函数返回地址处的汇编代码,但这个返回地址被篡改了,是有问题的,所以程序就“跑飞”了,会产生莫名其妙的崩溃。主调函数的ebp栈基址是被用来回溯函数调用堆栈的,如果主调函数的栈基址被破坏,则会导致崩溃时无法回溯出函数调用堆栈,即出现崩溃时看不到有效的函数调用堆栈了。
https://blog.csdn.net/chenlycly/article/details/120958761 对于栈内存越界,有可能越界到当前函数的其他局部变量上,另外在函数调用时,主调函数的返回地址、主调函数的ebp栈基址、用于esp校验的cookie值等都存在栈上的,有可能会越界到这些内存区域上,如果内存越界将这些内存破坏掉了,则会引起比较致命的错误。比如篡改了主调函数的返回地址,那么等被调函数返回时,要执行主调函数返回地址处的汇编代码,但这个返回地址被篡改了,是有问题的,所以程序就“跑飞”了,会产生莫名其妙的崩溃。主调函数的ebp栈基址是被用来回溯函数调用堆栈的,如果主调函数的栈基址被破坏,则会导致崩溃时无法回溯出函数调用堆栈,即出现崩溃时看不到有效的函数调用堆栈了。
就问题排查的难度而言,堆内存越界和全局内存越界比较难查,栈内存越界排查起来要容易很多。
内存越界常见的表现形式有数组越界,操作指针指向的buffer越界等。一般都是对这些内存操作时,超过了内存的范围,主要是向后越界,可能是通过数组下标操作数组或buffer的内存,下标超过了申请内存的最大长度。
以前我们遇到一种向前越界的情况,我们使用数组下标操作一段buffer内存,结果出现了下标为-1的情况,比如szBuf[-1],这样就越界到szBuf buffer的前面去了,当时报了如下的错误:
其中有一种情形下的越界(被调用函数越界越到主调函数的栈内存上),很具有隐蔽性,排查起来比较困难。比如A库依赖B库,B库定义了结构体Struct1,A库调用了B库的GetData接口, GetData接口是Struct1结构体作为参数的(传入的结构体对象引用或地址),GetData函数内部进行了数据的memcpy操作。因为库发布的问题,导致两个库版本不一致,假设A库是老版本,B库是新版本。新版本B库中在Struct1结构体中新增了字段(使用了新版本的结构体),但是A库中使用的还是老的结构体,这样在调用GetData传入结构体地址或引用,由于GetData中进行了memcpy操作导致内存越界:
// 1、A库中的代码:Struct1 st1; // A库使用的是老版本的结构体,GetData(&st1);// 2、B库提供的GetData接口,传入的参数是结构体引用void GetData( out Struct1& st ){ // 假设B库中定义的是一个全局变量g_st,即:Struct1 g_st,该变量存的是B库中的信息 // 把全局变量g_st中的信息拷贝到st中,传出去(参数st是传出参数) memcpy(&st, &g_st, sizeof(st));}因为B库在编译时使用了新的Struct1结构体(结构体末尾新增了一个成员字段),所以memcpy中的sizeof(st)是新的结构体字段,所以memcpy执行内存拷贝时的内存操作长度是新结构体的长度。但Getdata传入的是引用,所以memcpy的目标内存是在A模块的主调函数的栈内存上,而A模块中的主调函数传入的结构体对象用的是老的结构体(没有新增字段),所以GetData中产生的内存越界直接越界到位于A模块中的主调函数的栈内存上了。可能篡改了主调函数中其他栈变量的内存或者其他信息,可能会导致代码出现unexpected不可预期、不可解释的异常运行行为。这样的问题我们已经遇到过多次了。这类问题比较有隐蔽性,如果没有经验,排查起来会很困难
对于内存越界,我们可以通过添加多行打印日志、分块注释代码、添加数据断点(Visual Studio中支持数据断点)等手段进行定位。
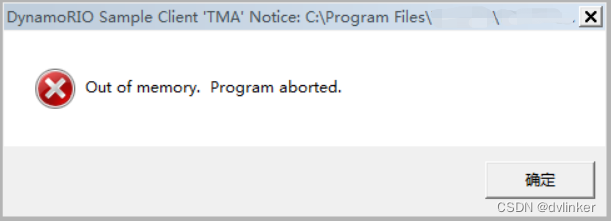
2.4、内存泄漏
内存泄漏是指程序中通过new/malloc动态申请的堆内存在使用完后没有释放,长时间频繁执行这些没有释放堆内存的代码,会导致程序的内存会逐渐被消耗,程序运行会变慢,直到内存被耗尽(Out of memory),程序闪退。程序闪退时,系统会弹出如下的Out of Memory的报错提示框:
如何才能察觉出程序有内存泄漏呢?其实很简单,让程序持续运行,然后查看任务管理器中程序进程使用的内存变化情况:
如果进程占用的内存一直不不断上涨且不回落,则说明进程中可能存在内存泄漏。
那内存泄漏该如何排查呢?在Linux系统中,有个强大的内存调试和监测工具Valgrind,该工具排查内存泄漏很好用,但该工具只支持Linux系统,没有Windows版本。目前Windows平台上很多内存泄露检测工具都比较陈旧、不再更新了,不再支持VS2015及以上版本编译出来的程序了。之前尝试使用腾讯的tMemMonitor内存泄露检测工具 ,但很多场景下的内存泄露,该工具都检测不出来。Windows平台下只能使用Windbg工具了,该工具监测内存泄漏的步骤稍显麻烦,可以参见之前写过的一篇文章:
使用Windbg定位Windows C++程序中的内存泄露![]() https://blog.csdn.net/chenlycly/article/details/121295720 但windbg的监测结果中会罗列出多个线程的内存使用信息,还需要将监测结果和代码结合起来看才能确定。
https://blog.csdn.net/chenlycly/article/details/121295720 但windbg的监测结果中会罗列出多个线程的内存使用信息,还需要将监测结果和代码结合起来看才能确定。
2.5、空指针与野指针
空指针和野指针是使用指针时两类很常见的错误,访问空指针和野指针都会导致内存访问违例,导致程序崩溃。
所谓空指针是指一个指针变量的值为空,如果把该指针变量的值(值为0)作为地址去访问其指向的数据类型,就会引发问题。
对于Windows系统,访问空指针会之所以会产生崩溃,是因为访问了Windows系统预留的64KB禁止访问的空指针内存区(即0-64KB这个区间的小地址内存区域),这是Windows系统故意预留的一块小地址内存区域,是为了方便程序员定位问题使用的。一旦访问到该内存区就会触发内存访问违例,系统就会强制将进程强制结束掉。
关于64KB禁止访问的小地址内存区域,在《Windows核心编程》一书中内存管理的章节,有专门的描述,相关截图如下所示:

比如一个C++指针变量值为空(NULL对应的值为0),如果通过该指针去访问其指向的类对象的数据成员,就会访问到64KB的小地址内存区,就会触发异常。因为会将指针变量中的NULL值作为C++对象的首地址,通过类数据成员的内存分布,C++类对象的数据成员的内存地址等于类对象的首地址加上一个offset偏移地址,这样该C++类对象的数据成员的内存地址比较小(小于64KB),要读该数据成员变量的值,就是对其内存地址进行寻址(从内存中读取内存中存放的内容),这样就访问了很小的内存地址,所以触发了内存访问违例。
所谓野指针,是指该指针指向的内存(指针变量中存放的值,就是其指向的内存的地址)已经被释放了,但还去访问该指针指向的内存,一般会导致内存访问违例,导致软件崩溃。还有一种情形是同一段堆内存被delete或free了两次,也会触发崩溃。
2.6、内存访问违例
前面已经讲了内存越界,内存越界肯能会导致内存访违例,但内存访问违例,不仅仅是内存越界导致的,所以这个地方要单独捻出来单独说一下。
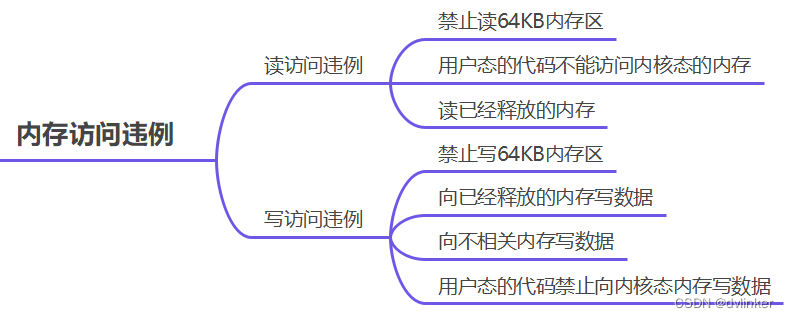
内存访问违例包含读内存违例和写内存违例。比如上面讲到的Windows下的小内存地址(64KB内存区域)是禁止访问的,一旦访问就会触发内存访问违例,系统会强制将进程终止掉。再比如上面讲的内存越界,也会触发内存访问违例。
再比如系统出于安全考虑,用户态的模块是禁止访问内核态地址的,对于32位Windows程序,系统会分配4GB的虚拟地址空间,一般用户态和内核态各占2GB,用户态的内存地址是小于2GB的,如果我们通过一些分析软件发现发生崩溃的那条汇编指令中访问的内存地址大于2GB,则肯定是禁止访问内核态地址触发的内存访问违例,肯定是代码中把地址搞错了,访问了不该访问的地址。
还有一点需要说明一下,即使程序访问了不属于自己的地址,比如内存越界,不一定会触发内存访问违例,程序不一定会崩溃。程序访问了不属于当前代码块的内存地址,系统允许你访问(读数据或写数据),你就可以访问不会有内存访问违例发生;系统不允许你访问,就会触发内存访问违例,就会引发崩溃。
2.7、栈内存被当成堆内存去释放
在栈上分配内存的C++类对象,是不能用delete去释放内存的,delete释放的是堆内存,否则会导致异常崩溃。
之前在使用一个框架库导出类ClassA(假设类名叫ClassA),在框架库内部的框架中会自动去delete这个类对象。但我们是在一个函数中使用该类定义一个局部变量(类对象),即:
void Func(){ ClassA clsA; // ......}该类对象在栈上分配内存的,是不能用delete去释放的,应该调用接口给该对象设置不需要框架自动销毁。对于栈上分配内存的局部变量clsA,在函数退出时其占用的栈内存会自动释放。
2.8、线程栈溢出
单个线程的栈空间是有限的,比如Windows线程的默认栈空间大小是1MB,当然我们创建线程时也可以指定线程栈的大小,但一般不宜过大。
线程的栈空间是用来干嘛的呢?某个时刻某个线程实际使用的栈空间,等于当前线程函数调用堆栈中所有函数占用的栈空间总和。函数中的局部变量是在所在线程的栈内存上分配的,函数调用的参数也是通过栈内存传递(参数值入栈)给被调用函数的,这两点就是函数占用栈内存的主要对象。
一旦当前线程的调用堆栈中占用的总的栈空间超过当前线程的栈空间上限,就会产生stack overflow线程栈溢出的异常,如下所示:
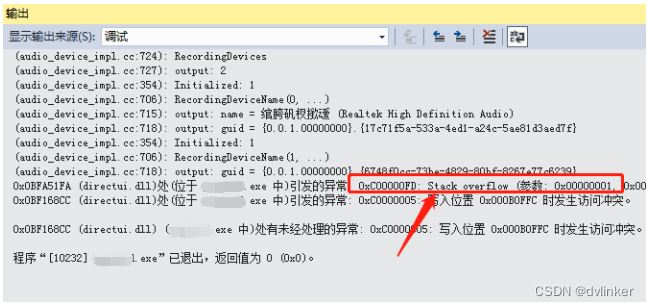
导致程序崩溃。
从以往排查这类问题的经验来看,导致线程栈溢出的原因主要有以下几种:

1)函数的递归调用层次过深,导致函数中占用的栈空间一直未被释放。对于递归调用,只有最底层次的函数调用返回后,上面层次的函数才会逐一返回,每个层次的函数占用的栈空间才会释放。如果函数调用一直还没走到最底下的那一层,递归调用中的所有函数的栈空间一直不会释放,线程所在线程的栈空间会被占用的越来越多。解决办法是减小递归调用的层次,或者修改变量的存储类型。
2)函数定义局部变量的结构体定义比较大(结构体比较庞大,包含了很多字段或者嵌套了很多其他的结构体),超过了当前线程的栈空间的上限。解决办法是,结构体变量不要定义成函数的局部变量,选择new或malloc去申请内存,即变量在堆上申请内存。
3)因为某些机制的存在,导致两个函数不断相互调用,陷入函数的死循环调用。导致函数占用的栈内存始终没有机会释放,导致所在线程的栈空间被消耗完了,达到了上限。解决办法是,掐断这种死循环调用机制。
4)switch语句中的case分支过多。可能这些case分支是用来处理服务器给过来的多个消息,每个case分支对应一个消息处理分支,我们会在case分支中定义生命周期在此case分支中的局部变量。虽然代码执行到case分支中这些变量才有“生命”,但其实这些变量已经在所在函数入口处就分配好栈内存了。可以编写C++测试代码进入调试状态查看一下汇编代码,就能看出来的,这点我特别验证过!
上述四种类型的栈溢出问题,我们在项目中都遇到过,有的甚至多次遇到过。
2.9、函数调用约定不一致导致栈不平衡
C++中常用的调用约定有__cdecl C调用、__stdcall标准调用、__fastcall快速调用。其中,__cdecl是C/C++默认的调用方式,C/C++运行时库中的函数都是__cdecl调用。__stdcall标准调用是Windows系统提供的系统API函数的调用约定。
函数的调用约定不仅决定着函数多个参数压入栈中的先后顺序,还决定了应该由谁来释放主调函数给被调函数传递的参数所占用的栈空间(是主调函数释放参数占用的栈空间,还是被调函数去释放参数占用的栈空间)。函数调用时栈分布如下:
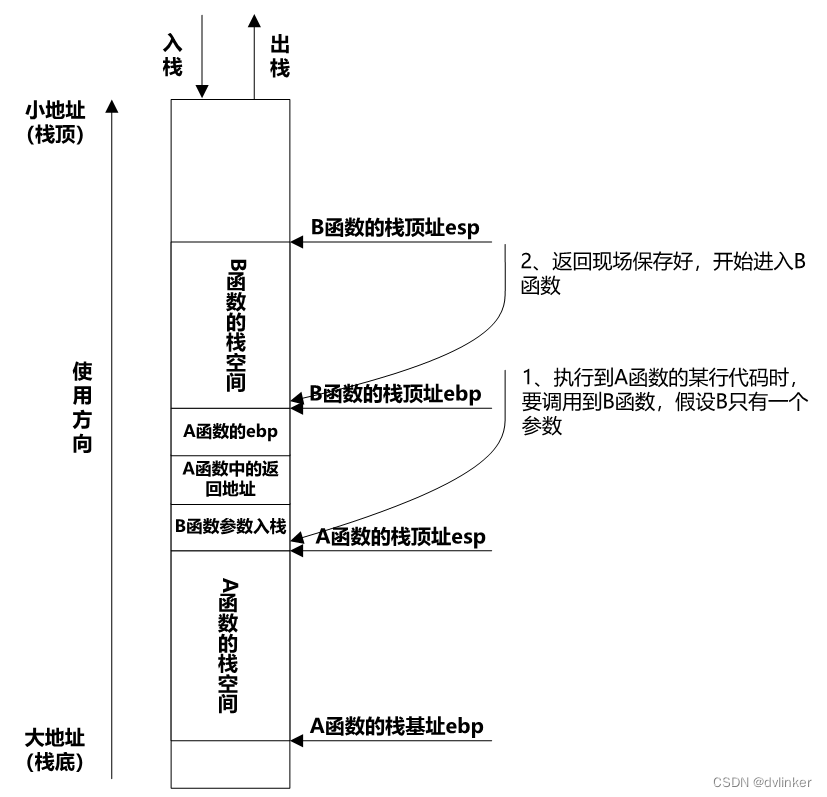
对于由谁来释放栈空间,以常用的__stdcall标准调用约定和__cdecl调用约定为例,如果被调用函数是__stdcall标准约定,则由被调函数去释放传给被调函数的参数占用的栈空间。如果被调函数是__cdecl调用,则由主调函数去释放参数占用的栈空间。
关于谁来负责释放参数占用的栈空间,大家很容易混淆,给大家一个容易记住的办法。比如我们经常用到的C函数printf:
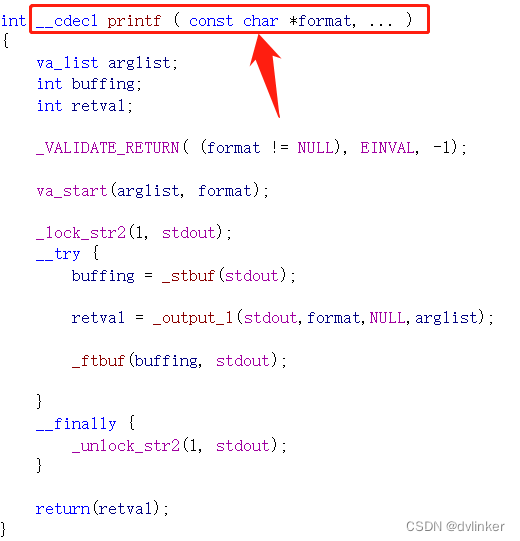
该函数支持多个可变参数的格式化,设定的是C调用约定,因为被调函数是无法知道传入了哪些参数,只有主调函数才知道传入了哪些参数,才知道传入参数占用的栈内存的大小,所以只能是主调函数去释放参数占用的栈内存。
函数调用约定引发的栈不平衡问题在设置回调函数时比较常见,特别是跨语言设置回调函数时。因为调用约定的不一致,可能会导致参数栈空间多释放了一次,会直接影响主调函数的ebp栈基址出错,导致主调函数中的内存地址错乱出现异常或崩溃。比如C#程序调用C++实现的SDK,因为C++语言中默认使用__cdecl C调用约定,C#默认使用__stdcall标准调用,如果回调函数没有显式地指明调用约定,在实际使用时就会出问题。
在Debug下,Visual Studio默认开启了/RTC(Run-Time Check)运行时检测,如下:
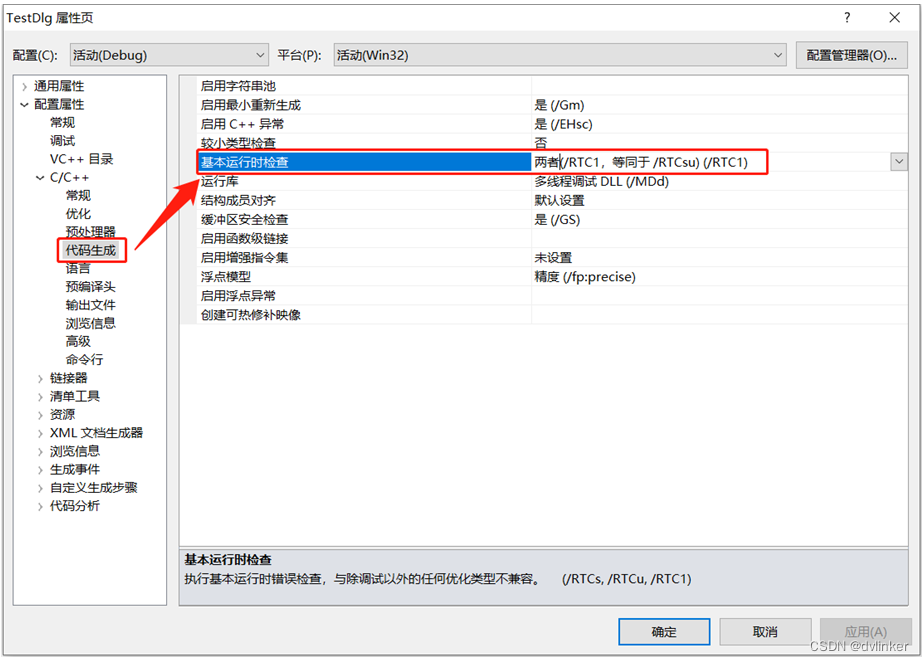
其中/RTCsu选项的微软官方说明如下:
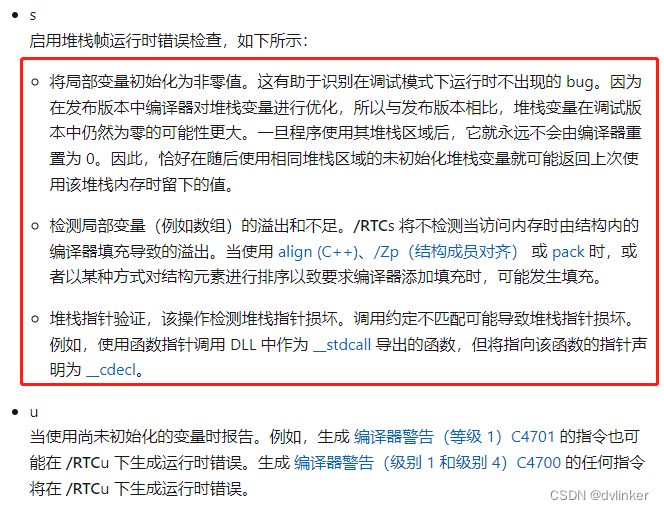
/RTC编译选项在函数退出时会监测栈是否平衡,一旦检测到栈不平衡,一般都会弹出如下的提示:
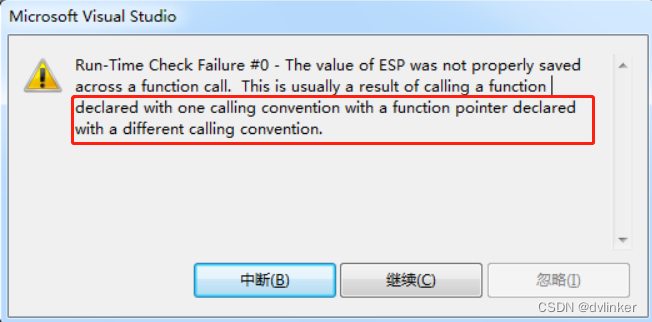
默认情况下,/RTC编译选项只在Debug下是开启的,Release下该选项是关闭的。有的模块为了方便排查问题,在Release版本中开启了该编译选项。开启该选项后,在代码编译时会向代码添加很多额外的跟踪代码,会对程序的执行效率产生一定的影响。
2.10、库与库之间不匹配
因为一些原因,导致dll库与dll库之间的版本不一致或不匹配,从而导致程序运行异常或崩溃。
比如底层的库只发布了Debug版本的库,忘记发布Release版本,导致Debug版本库与Release库混用,因为Debug与Release下的内存管理机制的不同会导致崩溃。Debug下申请内存时会额外分配一些用于存放调试信息的内存,而Release下是没有的。
再比如,底层库的API头文件发生了改动(比如结构体中新增或删减了若干字段),但只发布了库文件,忘记发布头文件,导致使用该底层库的上层库使用的还是老版本的头文件。即底层库是用新的头文件编译的,而上层库使用的是老版本头文件编译的,用到改动的结构体时在内存上就会有问题,上面的有个小节就提到这样的问题。
还比如,我们修改了头文件,但发布时有若干关联的库没有编译或者编译失败了,导致程序安装包中使用的还是之前的老版本的库,这样也会导致库与库之间的不匹配。
一般这类库的不匹配会触发内存上的问题,会让程序出现异常或崩溃,比如Debug下弹出如下的提示框:
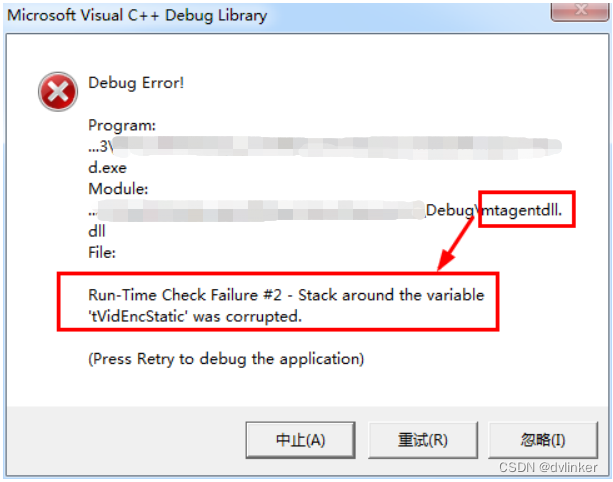
处理这类问题的办法是,查看svn或者git上的库修改或发布记录,可能要重新发布库,也可能需要将相关的模块重新编译一下。
2.11、死锁
死锁一般发生在多线程同步的时候,我们在不同线程访问共享资源时加锁做同步,常见的锁有关键代码段、事件对象、信号量、互斥量等。对于死锁的场景,比如线程1占用了锁A,在等待获取锁B,而线程2占用了锁B,在等待获取锁A,两个线程各不相让,在没有获取到自己要获取的锁之前,都不会释放另一个锁,这样就导致了死锁。我们需要做好多个线程间协调,避免死锁问题的出现。很多时候我们能够根据现象及相关的打印日志,初步估计出可能发生死锁的地方。
如果UI线程出现堵塞卡死,或者是底层业务模块出现拥堵,业务出现异常,可能就是死锁引起的。可以将windbg挂在到目标进程上,使用~*kn命令查看所有线程的函数调用堆栈,确定发生死锁的是哪些线程,发生死锁的线程一般都会停留在WaitForSingleObject这个函数的调用或者类似函数的调用上,比如这样的截图:
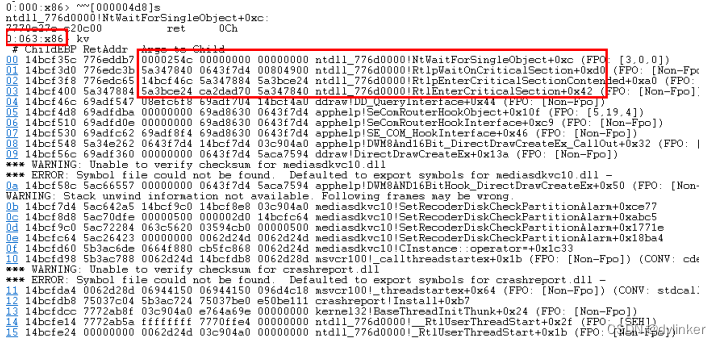
如图所示,当前线程卡在了WaitForSingleObject的函数调用上。通过函数调用堆栈,可以确定是调用了哪个函数触发的。
对于使用临界区(关键代码段)的死锁,使用Windbg排查比较容易分析,因为临界区是用户态的对象,我们只需要使用为Windbg进行用户态的调试即可。如果是信号量等其他的锁,则要使用Windbg进行内核态的调试,内核态的调试则要复杂很多。
此外,可以使用《Windows核心编程》一书中第9章讲到的LockCop工具(有源码)来检测一下,该工具是调用系统WCT (Wait Chain Traversal,等待链遍历)API函数GetThreadWaitChain来判断目标线程是否发生了死锁,但是只能监测关键代码段、互斥量等引发的死锁,如下所示:

所以在使用LockCop工具应该注意:
1)该工具因为调用的API是Vista以上系统才提供的,所以不支持XP系统。
2)该工具只能检测临界区死锁和互斥量死锁,事件、信号量等引发的死锁是没法监测到的。
3)该工具检测不到WaitForMultipleObjects引发的死锁。
2.12、堆内存被破坏
系统在给堆内存申请者分配堆内存时,会把分配给用户使用的堆内存的首地址返回给用户,用户可以在这段堆内存上进行读写操作。实际上,系统在分配堆内存时会在给用户使用的内存区域头部前面加一段头部内存,在给用户使用的内存区域的尾部加一段尾部内存,如下所示:

这里额外的头部内存块和尾部内存块是用来存放给用户使用的堆内存的信息的,系统正是通过这些头部和尾部信息来管理一块一块堆内存的。这个地方做了简化的说明,实际上操作系统用来管理堆内存的数据结构要复杂很多。
我们此处讲的堆内存被破坏是指这些存放堆内存信息的头部内存区域或者尾部内存区域被篡改了,一般是被内存越界篡改的,被篡改后可能会导致两个问题:
1)程序中使用new或malloc申请新的内存块时,会因为有堆内存块信息被破坏,导致分配堆内存时出异常。
2)当我们使用delete或free去释放被破坏的堆内存时,因为堆内存信息被破坏,导致释放堆内存时出异常。
所以,当堆内存被破坏后,程序可能会出现“胡乱”崩溃的问题,一会崩溃在这个dll库中,一会崩溃在那个dll中;或者一会崩溃在new或malloc时,一会崩溃delete或free时。
堆内存被破坏导致的异常,比栈内存被破坏要难查的,也没有什么太好的办法。一般可以通过注释代码、注释模块去缩小排查的范围,也可以通过历史版本比对法看看是从哪天开始问题的,通过svn查看出问题前一天修改了什么代码,然后对这些代码进行针对性排查。
2.13、执行new操作时抛出了异常
当我们执行如下的代码:
char* p = new char[10240];去申请一段内存时,很多人以为当内存申请失败时new操作会返回NULL,实际运行时并不是这样,new内部会抛出一个bad_alloc异常。
new操作申请堆内存失败可能是以下几个原因引起的:

1)申请的内存过大,进程中没有这么大内存可用了
可能受一些异常数据的影响,申请了很大尺寸的内存。比如前段时间排查一个崩溃问题,当时因为数据有异常,一次性申请了9999*9999*4*2 = 762MB的堆内存,进程中没有这么大可用的堆内存了,所以申请失败了,new操作抛出了一个异常,而程序没有对异常处理,直接导致程序崩溃了。
2)用户态的内存已经达到了上限,申请不到内存了
有可能是虚拟内存占用太多,也有可能代码中有内存泄露,导致用户态的内存被消耗完了。对于一个32程序,一个进程分配了4GB的虚拟地址空间,而用户态和内核态内存各占一半,即用户态的内存只有2GB,如果程序占用的虚拟内存比较大,比如接近2GB的用户虚拟内存了,在申请大的内存就会申请失败了。或者程序中有内存泄露,快要把用户态的2GB的虚拟内存给占用完了,在申请内存可能会申请失败的。
3)进程中的内存碎片过多
如果进程中在大量的new和delete,产生了大量的小块内存碎片,可用的内存大多是一小块一小块的小内存块,而要申请的是一块长度很长的内存,因为到处是内存碎片,没有这么一大块连续的可用内存,可能就会导致内存申请失败的。
4)发生堆内存越界,导致堆内存被破坏,导致new操作产生异常(此时new不会返回NULL,会抛出异常)。
我们可以在出问题的地方,对该处的new添加一个保护(但不可能对代码中所有new的地方都加这样的保护),我们通过添加try...catch去捕获new抛出的异常,并将异常码打印出来,如下所示:(下面的代码在循环申请内存,直到内存申请失败为止,主要用来测试用)
#include using namespace std;int main(){ char *p; int i = 0; try { do{ p = new char[10*1024*1024]; i++; Sleep(5); } while(p); } catch(const std::exception& e) { std::cout << e.what() << "\n" << "分配了" << i*10 << "M" << std::endl; } return 0; }还有一种方式,在new时传如一个std::nothrow参数,让new在申请不到内存时不要抛出异常,直接返回为NULL,这样我们就可以通过返回的地址是否为NULL(空),判断是否是内存申请失败了,示例代码如下:
#include int main(){ char *p = NULL; int i = 0; do{ p = new(std::nothrow) char[10*1024*1024]; // 每次申请10MB i++; Sleep(5); } while(p); if(NULL == p){ std::cout << "分配了 " << (i-1)*10 << " M内存" //分配了 1890 Mn内存第 1891 次内存分配失败 << "第 " << i << " 次内存分配失败"; } return 0;}2.14、执行delete操作时发生了异常
如果对一段已经释放的堆内存再执行一次delete操作,即对同一段堆内存delete两次,第二次delete时会引发异常崩溃的。
如果之前申请的堆内存在使用的过程中被破坏了,然后在delete时可能就会触发异常崩溃。我们之前就遇到过一个案例,我们申请了一段堆内存,通过数组下标szTags[nCount-1]去处理这段堆内存,结果程序在测试时崩溃了,弹出了如下的错误:
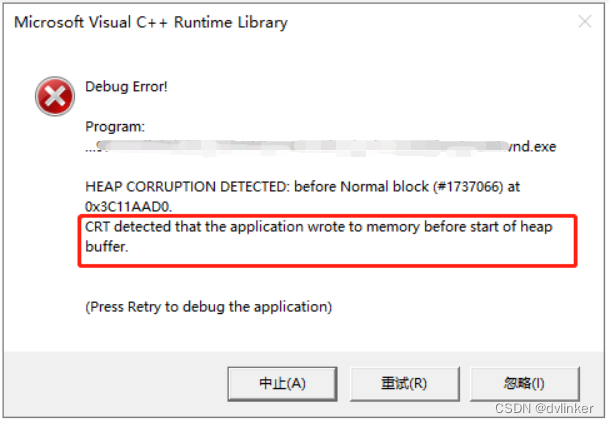
使用windbg查看dump文件,发现程序就崩溃在delete []szTags的这一行代码上。这里不存在对同一段堆内存同时delete两次的问题,以前很少遇到过delete时会产生异常的。
于是通过和测试同事讨论,找到必现的规律,然后在Debug下对代码调试,发现在某种比较罕见的场景下,nCount会等于0,从而导致代码中对szTags[-1]进行赋值操作,而szTags[0]开始的堆内存块才是用户可以操作的:
所以szTags[-1]就越界到堆内存的头信息内存区了,篡改了堆内存头信息,导致系统在管理这个被破坏的内存出问题了,所以在delete这个堆内存时产生了异常。此处只是大概知道是这个原因,至于更具体的原因就比较复杂了,要研究Windows内存管理的实现细节才能搞清楚的。
2.15、GDI对象泄漏
GDI对象是Windows系统中的绘图操作中的概念。所谓GDI对象泄漏是指绘制窗口或绘图时,创建的GDI对象在绘制完成后没有释放,导致GDI资源泄漏,这点和内存泄漏是比较相似的。我们可以通过查看任务管理器就可以看到目标进程的GDI占用情况:
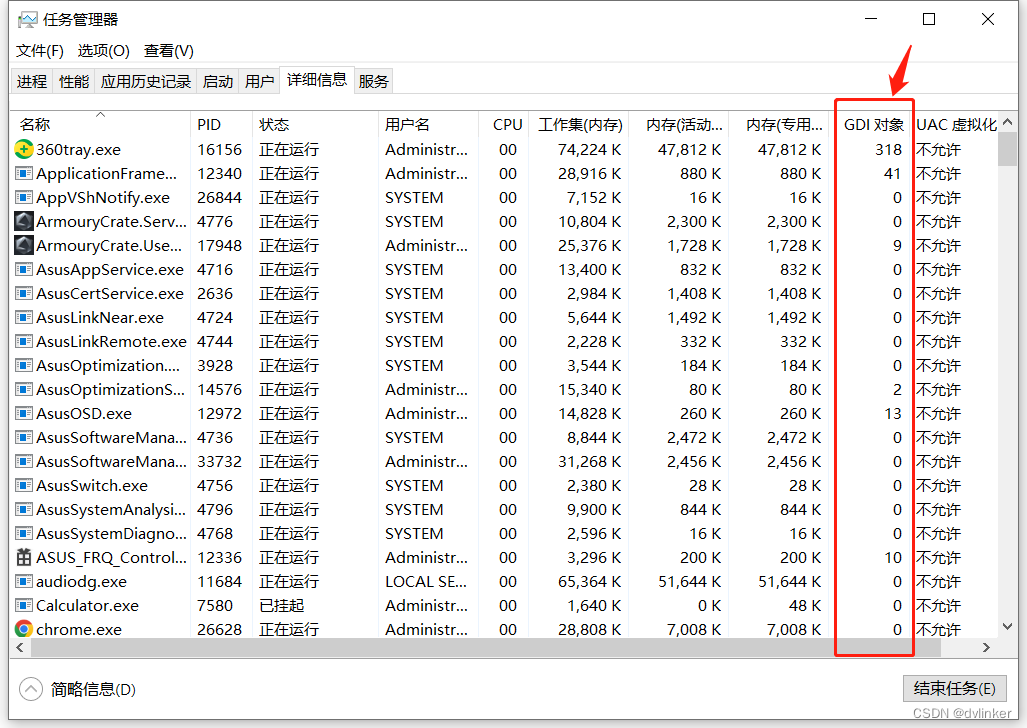
默认情况下,资源管理器中是不显示GDI对象列的,可以右键列表标题栏,在右键菜单中点击“选择列”,勾选“GDI对象”,即可查看到。
当程序中有GDI对象泄露时,程序长时间运行,进程中的GDI对象会持续的增长,可以在任务管理器中实时地观测目标进程中的GDI对象变化。如果进程的GDI对象接近或达到1万个,就会导致GDI绘图函数调用出现异常,出现窗口绘制不出来等问题,紧接着程序就会出现崩溃。相信很多Windows老程序员可能都遇到过类似的问题。下面就是某个进程的GDI总数接近1万个的截图:

Windows系统中,进程中的GDI对象总数不能超过10000个。当进程的GDI对象总数接近或超过10000个时就会导致GDI绘图出现异常,API函数调用返回失败,甚至出现闪退崩溃。
除了GDI泄漏会导致进程的GDI总数达到系统上限,打开程序的多个窗口可能也会导致这个问题,比如之前我们用MFC做UI界面时,每个控件都是一个窗口,每个窗口都包含若干个GDI对象,这样导致一个聊天窗口就占用了200多个GDI对象。这样在做极限测试时,同时打开了好几十个聊天窗口,就出现了GDI对象达到或接近上万个的问题。这也是当时我们要将MFC界面库换成开源的duilib界面库的原因之一。
在duilib UI框架中,窗口中的dui控件都是绘图绘制出来的,控件本身并不是窗口,所以dui窗口相对MFC窗口,占用的GDI对象可能要少很多。
对于GDI对象泄露问题,可以使用GDIView工具来排查。GDIView可以实时显示进程的多个GDI对象个数情况,比如Bitmap位图对象、Brush画刷对象、Pen笔对象、Font字体对象、Region区域对象、DC对象以及GDI总数等,如下所示:
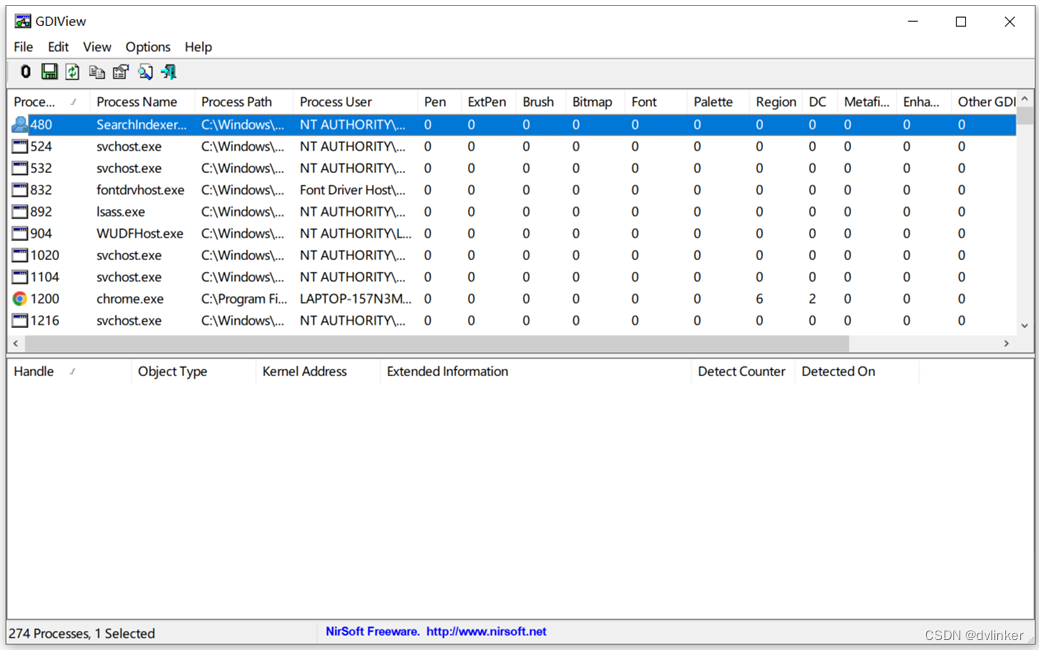
所以通过GDIView就能实时查看到目标进程中的GDI对象的占用及增长情况,就能确定到底哪种GDI对象数目在持续的增长,就能确定是哪个GDI对象有泄漏,这样就能有针对性地去排查相关代码了。在我们的项目中,我们已多次使用GDIView工具去排查GDI对象泄露的问题。
比如有次开源组的同事在webrtc库添加了一段代码导致了GDI对象泄漏,使用GDIView工具查看,我们软件进程的DC对象一直在不断的增长,之前的版本是没有这个问题的。最近只有开源组改过代码,所以和开源组沟通了一下,起初同事觉得他们写的代码应该没有问题,应该不会导致GDI对象泄漏。于是找他们要来了他们最近添加的代码,如下所示:
#if defined (WEBRTC_WIN) //修正程序开启DWM导致的鼠标位置问题 int desktop_horzers = GetDeviceCaps( GetDC(nullptr) DESKTOPHORZRES); int horzers = GetDeviceCaps(GetDC(nullptr),HORZRES); float scale_rate=(float)desktop_horzers/(float)horzers; relative_position.set( relative_ position.x()*scale_rate, relative_ position.y()*scale_rate );#endif可能他们很少写UI程序的原因,对这个问题不太敏感,我们拿到后一眼就看出了问题,在调用GetDC获取DC对象之后,应该调用ReleaseDC将DC对象释放掉,所以上述代码有DC对象泄漏的问题。
2.16、对C++类或者包含C++类成员的结构体进行memset操作,破坏了C++类的内部内存结构
我们通常在使用结构体时,会对结构体对象进行memset操作,以完成结构体对象的初始化,如下:
Struct1 st;memset( &st, 0, sizeof(st) );但禁止对类对象进行memset操作的,原因是有很多的,比如C++类中包含有虚函数,编译时会默认添加一个虚函数表指针成员变量,该指针指向虚函数表的首地址,如果对类对象(整个内存)进行memset操作,会将虚函数指针的值也置为0的,这是致命的!因为调用虚函数时需要到虚函数指针指向的虚函数表中去拿虚函数地址(代码段)地址去完成对虚函数的调用。
再比如,有的C++类会添加用于维护和管理类中内存结构的额外内存块,比如STL列表类vector、list、map、queue、deque等,如果对这种类进行memset,则会破坏维护类内部内存结构的内存块,会导致不可预测的错误。对C++类的数据成员的初始化是需要放到类的构造函数中进行的。
这里必须要说一种掩藏比较深的场景,这类问题我们遇到过好几次了,结构体中包含类对象也是不能进行memset操作的。比如之前同事在某个结构体定义时添加了stl列表对象成员,比如:(为了说明问题,写了一个简单的结构体)
struct PointListInfo{ HWND hTargetWnd; vector vtPointList;};在使用结构体PointListInfo定义结构体对象后,习惯性的对结构体对象进行memset操作,殊不知结构体中包含类对象是不能进行memset操作的。如果对PointListInfo结构体对象进行memset操作,就破坏了vector对象内部维护vector列表内存结构的内存,导致程序出现莫名其妙的崩溃。当时附加调试代码时,向vector vtPointList列表中push元素后,是能看到列表中的元素列表的,但后面在遍历该vector出现了异常,后来查下来发现是对所属的结构体对象进行违规的memset操作引起的。
再比如,几年前同事在开发新功能时,遇到了一个很诡异的问题,代码是顺序执行的,按顺序执行下来肯定是没问题的,但是程序跑下来,逻辑却有明显的异常。于是我过去看了一下,发现他定义的结构体中包含有stl列表。他在使用该结构体对象之前,对结构体对象进行了memset操作,memset操作破坏了stl列表内部的内存结构,在我们读取这个列表中的数据时,stl内部抛出了异常,直接将当前函数余下的代码给跳过去了,导致本该执行到的代码没有执行,导致了程序逻辑上的异常。
2.17、程序中抛出了异常,将部分该执行的代码跳过去了
程序中执行了非法的操作,抛出了异常,但程序并没有崩溃,直接将当前函数余下的代码跳过去了, 导致部分该执行的代码没有被执行到,导致后续的代码逻辑出现了问题,进而导致程序出现异常。
这个问题我们遇到过几次,比如给MFC中的CTime类的构造函数传入了非法的参数值,触发CTime类接口抛出了异常。使用到的CTime的一个构造函数如下:
ATLTIME_INLINE CTime::CTime(_In_ int nYear,_In_ int nMonth,_In_ int nDay,_In_ int nHour,_In_ int nMin,_In_ int nSec,_In_ int nDST){#pragma warning (push)#pragma warning (disable: 4127) // conditional expression constantATLENSURE( nYear >= 1900 );ATLENSURE( nMonth >= 1 && nMonth = 1 && nDay = 0 && nHour = 0 && nMin = 0 && nSec <= 59 ); // ......}当时传入给year参数传了0值,所以进入ATLENSURE宏中,该宏的实现如下:
#ifndef ATLENSURE#define ATLENSURE(expr) ATLENSURE_THROW(expr, E_FAIL)#endif // ATLENSURE#ifndef ATLENSURE_THROW#define ATLENSURE_THROW(expr, hr) \do { \int __atl_condVal=!!(expr); \ATLASSUME(__atl_condVal);\if(!(__atl_condVal)) AtlThrow(hr); \} while (0)#endif // ATLENSURE_THROW最终调用了AtlThrow抛出了一个异常。
再比如,我们把一个包含stl列表vector成员的结构体给memset了,破坏了该结构体中的vector成员的内存结构,引发了vector内部抛出了异常,就是上一小节我们说到的问题。
2.18、模块注入到程序中导致程序出现异常
我们之前遇到过很多次这样的问题,输入法的库注入到我们软件的进程中,导致了我们软件出现崩溃。通过分析发现,崩溃是发生在输入法的模块中,但因为这个模块是注入到我们的进程中的,所以直接导致了我们软件的崩溃。此外,输入法注入到我的进程后还出现了软件卡顿、CPU占用不间断跳高的问题。解决办法是让用户换输入法。
除了输入法,还有一些安全软件也会注入到我们的进程中,导致我们的软件出现异常,这样的问题我们也遇到过几次。比如以前我们就遇到这样一个问题,有个客户的机器上安装了多个安全防护软件(安全级别比较高),运行我们的软件一段时间后就会崩溃闪退,经远程到客户的机器上查看到任务管理器中的进程的内存在持续增长,估计是软件中发生了内存泄露,增长到一定程度后就导致内存耗尽,发生了闪退。最终使用windbg定位到内存泄露发生在安全软件的注入库中。它这个库是注入到我们进程中的,库内部发生内存泄漏,会表现在我们的进程中。解决办法是让安全软件开发商去排查他们开发的安全软件问题。
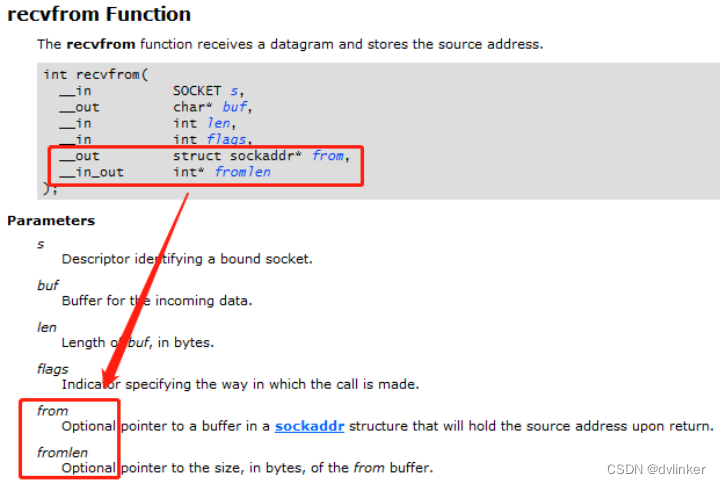
再比如几年前遇到的一个客户问题,他们的Windows系统中安装了VPN软件,注入到我们的进程中,hook了网络通信的相关接口,以监控软件的网络数据包的收发,其中hook的recvfrom接口实现有bug,我们代码中有处调用recvfrom接口的地方传入了NULL参数(对于系统API函数recvfrom,传入NULL值是允许的),结果直接导致该注入模块产生了崩溃,进而导致了我们软件的崩溃。
查看微软MSDN上对套接字API函数recvfrom的说明,函数的最后两个参数是可选的,可以不传入,直接设置NULL就可以了,如下所示:
但客户VPN软件注入模块,将系统的recvfrom函数hook成了他们实现的recvfrom函数,在实现他们自己的recvfrom函数时,直接访问了recvfrom最后的两个参数,而我们的代码在处理这两个参数时直接传入了NULL值:
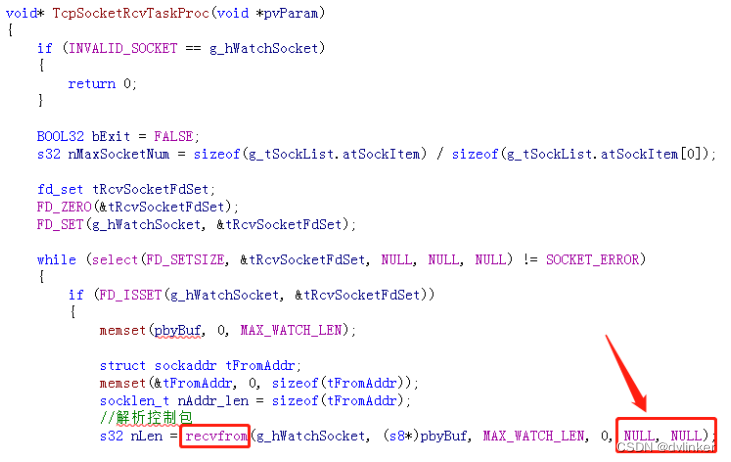
这样在他们的recvfrom内部没有做空指针的判断,访问了NULL指针,触发了内存访问违例,导致VPN软件的注入模块发生崩溃,从而导致了我们整个程序的崩溃。对于这个问题,我们有临时的规避办法,我们只要传入两个有效的参数即可:
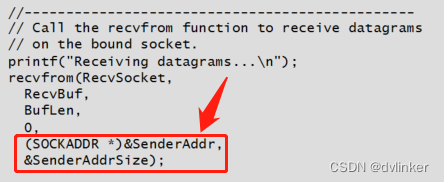
当然在对应的代码中,我们并不关心这两个参数在函数调用完成之后的返回值,不再传入两个NULL参数。
像这类出在第三方安全软件中的问题,必须要拿出足够的证据,证明问题是出在安全软件上,客户才会认可排查的结论,客户才会找第三方安全软件开发商去沟通反馈问题。
2.19、添加日志打印覆盖了lasterror的值
调用Windows系统API函数之后,系统API函数都会设置LastError值,我们可以调用GetLastError接口获取LastError值,有时我们需要使用该值进行一些判断。可能在判断之前我们又加入了一行代码,这行代码中也调用了系统函数,将之前的系统函数调用产生的LastError值给覆盖了,导致判断逻辑出问题了。
以几年前项目中遇到的一个问题为例,来详细地说明一下这个问题。当时在新需求开发完成后软件进入测试,测试发现我们的客户端软件始终连不上某个业务服务器,用Wireshark抓包看到客户端对服务器发起了三次握手的流程,客户端发出了SYN包,服务器收到SYN包后给出了ACK回应,但是客户端始终没给出ACK报应答,然后客户端直接将连接reset了。
最开始我们怀疑是客户端所在的系统的防火墙拦截了服务器的数据包,导致客户端应用层无法收到服务器的数据包。于是将程序添加到防火墙的信任列表中,允许通过防火墙进行通信,但还是有问题。于是分别将防火墙和杀毒软件都关闭掉,但问题还是照旧。
后来通过排查代码得知,建链时用的是非阻塞式套接字,发起connect之后会检测connect设置的lasterror值,结果在检查该lasterror之前,添加了一句打印:
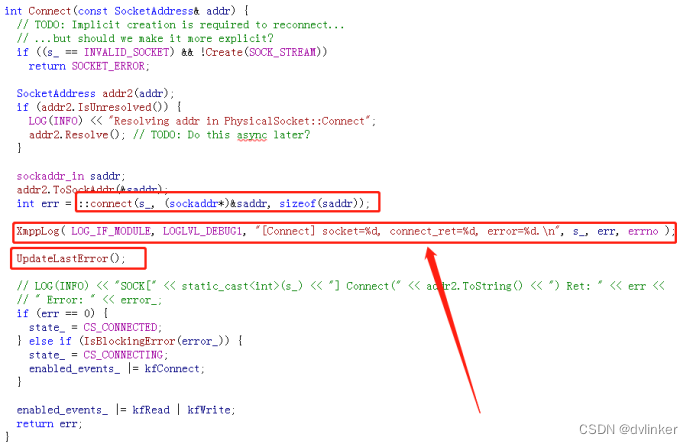
就是这句打印引起的。打印接口中调用了系统API函数或者C函数,覆盖了调用connect时设置的lasterror,导致后续判断connect设置的lasterror值出错了:

然后客户端直接调用closesocket接口直接将套接字关闭了(从抓包上看,连接直接被reset了),结束了三次握手的流程,所以客户端始终连接不上服务器。
类似的问题我们遇到不止一次了。本例中的问题出在开源的libjingle库(XMPP客户端代码)中,开源代码中做了多层函数的封装,在多个函数返回后才去判断connect设置的lasterror值,所以该问题具有很强的隐蔽性。在我们不太熟悉代码的情况下,添加了一句打印导致了这个问题。
2.20、格式化时格式化符与参数不一致
在将数据格式化到字符串中时,如果格式化符与参数类型不一致,可能会引发内存访问违例,导致软件崩溃。比如一个整型的变量(保存了一个很小的整数),结果错误的对应了%s格式化符,这样格式化函数内部会把这个整型值当成一个字符串首地址去对待,会读取这个内存地址中的字符串,但是这个地址是个很小的地址,即程序访问了64KB范围内的小地址存储区,这个区域是禁止访问的,会触发内存访问违例,系统会直接将进程终止掉。
几年前,我们遇到这么一个看似很奇怪的格式化时的崩溃,崩溃的那行代码如下所示:

参与格式化的两个参数是duilib中的CStdString字符串类对象,既然是字符串,上面的代码看上去好像是没问题的,但为啥运行时会产生崩溃呢?百思不得其解!
后来我们才发现,CStdString字符串类中有两个数据成员,正是这两个数据成员导致的问题。CStdString类的成员如下所示:
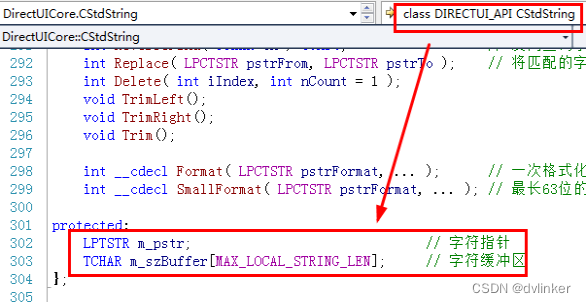
在调用格式化函数时,待格式化的参数会通过栈传递给被调用函数,具体是将参数内存中的内容压到栈上,格式化函数内部正是通过格式化符对应的内存长度从栈上读取待格式化数据的,这里就涉及到函数调用时的栈分布的知识了。为了方便理解问题,下面给出调用格式化函数时的栈分布图示例:

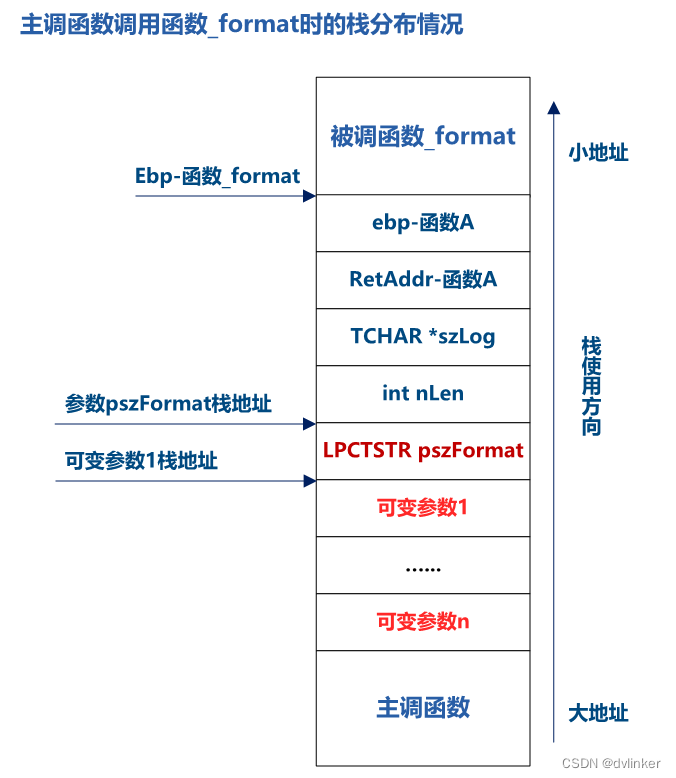
参照上图,本例中要参与格式化的CStdString类对象,两个数据成员都会压入到栈上,第一个参数m_pstr,压入的是字符串的首地址(正是要格式化的字符串),第二个数据成员m_szBuffer压入栈的也是内存地址中的内容,不是m_szBuffer数组的首地址,这样格式化函数会把m_szBuffer数组中的内容作为%s对应的字符串的首地址,这明显是有问题的。m_szBuffer数组中保存的是字符串各个字符的ASCII码,根本不是什么字符串的首地址。硬要作为字符串地址去解析,可能地址是不可访问的,会触发内存访问违例,导致崩溃。
2.21、同一个程序在不同系统中可能会有不同的表现
当前用的最多的系统是win10,win11也开始推出来了,也有部分人用的还是win7和win8,甚至还有极少数人还在用XP,不同的系统底层的实现会有一定的差异,比如说内存管理模块,同一个程序在win7上运行可能是没问题的,但是拿到win10系统上跑可能会有问题。这个我们之前就遇到过。

即便是同一个型号的系统,比如都是win10的系统,也分教育版、专业版和旗舰版等,并且不同时期的版本也可能会有一定的差异。比如最近我们还遇到过这么一个问题,在安装2015版win10系统(微软surface平板)上有CPU占用过高的情况,但在2019版的win10系统中则没有问题。
几年前我们也遇到过一个很特殊的实例,测试同事无意发现一个掩藏很深的崩溃,且是必现的,在win7系统上将windbg附加到进程上后,竟然不再崩溃,但直接运行程序就有异常,这个着实有点诡异!我们将程序拿到另一台装有win8的电脑上运行,用windbg附加到进程上调试,竟然是能抓到异常信息的。这个案例也给了我们一个启示,当遇到问题时可以到不同的系统上去跑一跑,说不定有意外的收获。特别是在软件发版本之前,一定要在多个版本的系统上做测试。
不同系统中程序的表现可能会有差异,同一类型的系统在不同时期的版本中也可能会有一定的差异,所以我们在测试的时候,要把程序拿到多个系统中去跑一跑,去测一测,保证程序能在多个系统上都能正常的运行!
2.22、其他
除了上面讲到的这些异常,还有一些其他异常,比如除法表达式中的除0崩溃,比如表达式的计算结果过大超出了变量类型所能表示的最大值,导致变量溢出了等。
除了要了解这些常见的软件异常类型,还需要掌握一些常用的软件调试技能,可以查看文章:
Visual Studio高效调试手段与技巧总结(经验分享)![]() https://blog.csdn.net/chenlycly/article/details/124884225 此外,有时还要掌握一些辅助异常排查的汇编基础知识,可参见文章:
https://blog.csdn.net/chenlycly/article/details/124884225 此外,有时还要掌握一些辅助异常排查的汇编基础知识,可参见文章:
分析C++软件异常需要掌握的汇编知识汇总(实战经验分享)![]() https://blog.csdn.net/chenlycly/article/details/124758670
https://blog.csdn.net/chenlycly/article/details/124758670
3、最后
本文详细介绍了引发C++软件异常的常见原因,并给出了详细的讲解和相应示例说明。希望大家在了解本文的内容之后,既能在编写代码时提前感知潜在的问题,也能在出问题之后多一些排查问题的思路与手段。
接下来,下一篇文章将详细介绍排查C++软件异常的常用方法与手段,敬请期待!

