Interspeech2022论文解读 | LODR:一种更好、更轻量的语言模型融合新方式
本文介绍清华大学语音处理与机器智能实验室(Speech Processing and Machine Learning Intelligence, SPMI)与美团的联合工作:为端到端ASR(Automatic Speech Recognition)提出一种性能更好、解码更轻量的语言模型融合方式——LODR。该工作已被语音领域的国际会议Interspeech 2022接收,论文的作者是郑华焕、安柯宇、欧智坚、黄辰、丁科、万广鲁。

端到端识别系统与语言模型融合
端到端ASR系统,是通过一个神经网络模型,直接将音频序列转换为对应文本序列的识别系统。相对于传统混合模型中声学模型、发音词典和语音模型模块化建模的方式,基于深度神经网络的端到端系统通过一个网络对整个识别过程进行封装,并对网络参数整体进行优化,在大量音频-文本配对数据下性能突出,近年来逐渐受到学术界和工业界的重视。
相对于音频-文本配对数据而言,实际生产中获取纯文本数据成本更低,且可获取的纯文本数据往往比音频-文本配对数据多几个甚至几十个数量级。此外在一些如领域迁移、专有名词和热词识别等场景中,利用好文本信息也尤为重要。如何利用好海量的纯文本数据,进一步提升识别准确率,是目前端到端ASR研究的重要问题,也是数据高效ASR的重要特征。
内部语言模型估计与解耦
目前,最为常用的在端到端ASR中利用文本的方式是,融合外部的语言模型(External Language Model, ELM),使用ELM学习文本信息,再与ASR系统融合。一个最常用的融合ELM的方式是,直接将ASR系统得分与ELM得分进行线性插值求和,即shallow fusion方法。对端到端系统的一个观察是,其学习建模了P(Y|X)的文本后验概率,自然地也学习了部分关于文本的信息。和ELM相对,我们将其端到端系统内部学习到的文本信息建模,称为端到端ASR系统的内部语言模型(Internal Language Model,ILM)。为了更好的融合ELM,一个直观的想法是,先“减去”ILM,再“加上”ELM(数学上讲是运用贝叶斯公式)。
ELM与ILM建模的都是P(Y)的信息,我们希望将ILM的部分替换为ELM。一些现有的工作均表明,在端到端ASR系统中,“减去”ILM相对于shallow fusion能带来更好的识别准确率。但在端到端系统中,一般无法直接准确计算出ILM,因此许多工作关注如何更好的估计ILM。
LODR(Low Order Density Ratio)
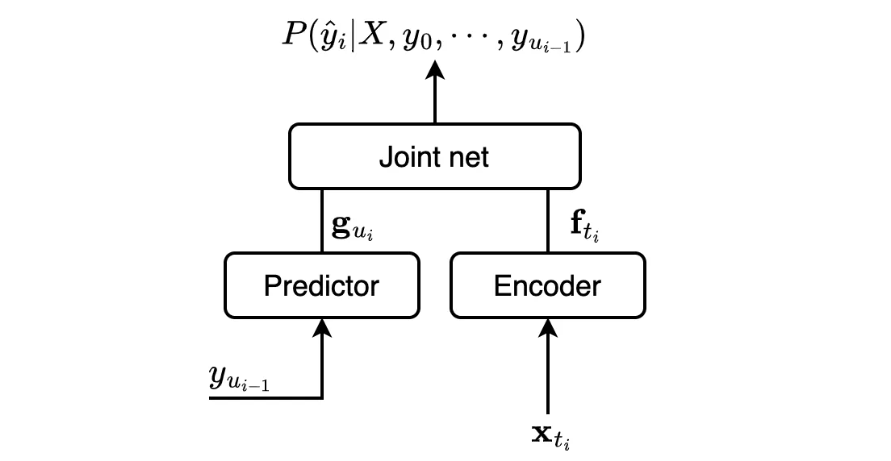
本文以基于Transducer模型(也称为RNN-Transducer,RNN-T)的端到端系统为例来探索。Transducer模型由三部分构成:负责声学特征建模的Encoder,负责文本信息建模的Predictor,以及负责将两部分信息聚合的Joint network。实际研究和应用中,Joint network一般是由若干前馈层和非线性激活函数组成,这导致其两部分输入(也即Encoder与Predictor的输出)是不可分的,因此我们无法直接计算出ILM建模的P(Y)。
然而,一般认为Predictor起了近似ILM的作用,有如下一些基本共识:
-
Predictor仅需要少量参数的浅层神经网络:在我们的实验中,Predictor仅使用了1层LSTM,许多其他工作也是类似的设置,或仅使用简单的一维卷积;
-
Predictor只利用了有限历史信息(limited context):约束Predictor的历史信息长度(对应卷积中的左感受野),可以发现当Predictor的历史信息为1-2个token时,就能达到接近完整历史信息的准确率;
-
忽略Joint network的不可分性质,直接zero out声学Encoder部分近似计算得到的ILM,实验中观察是一个建模能力非常弱的语言模型。主要证据是在指定语料上测试,该ILM的混淆度(perplexity,PPL)相对直接单独训练的LM显著要高(PPL越低表示LM对句子建模越好)。
从这些对Predictor的观察中,我们总结得到:RNN-T ILM,应当是一个低阶LM(即使用了很短的context),其文本建模能力很弱。根据总结,我们提出使用一个低阶的2-gram模型(并加上若干裁剪)对ILM进行估计。在训练该2-gram模型时,我们仅使用音频匹配文本,这样使得2-gram利用的信息和RNN-T的真实ILM保持一致。
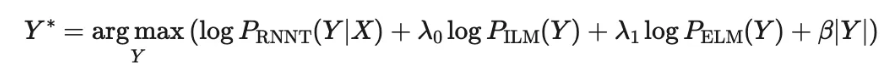
在解码时,我们计算RNN-T系统得分、估计的ILM得分和ELM得分的加权和作为选取候选的依据,其中估计的ILM权重一般是负值(实际操作中,我们会对ILM权重和ELM权重参数做搜索,搜索时并不限制其符号,而结果显示ILM权重均为负值,ELM权重均为正值,这反过来也印证了“先减后加”的想法)。
由于我们提出的方法是基于density ratio策略的,并且主要特点是仅使用低阶的LM作为ILM近似,我们将这一方法称为low order density ratio(LODR)。
实验结果
数据方面,音频-文本匹配数据,我们使用了英文的960小时Librispeech和中文普通话Wenetspeech的1000小时子集作为RNN-T模型的训练数据;纯文本数据方面,英文中使用了Librispeech官方提供的额外语料(约800M词,训练集文本约9.4M词),中文实验中使用了来自CC100的中文语料(约200M字,训练集文本约17M字)。
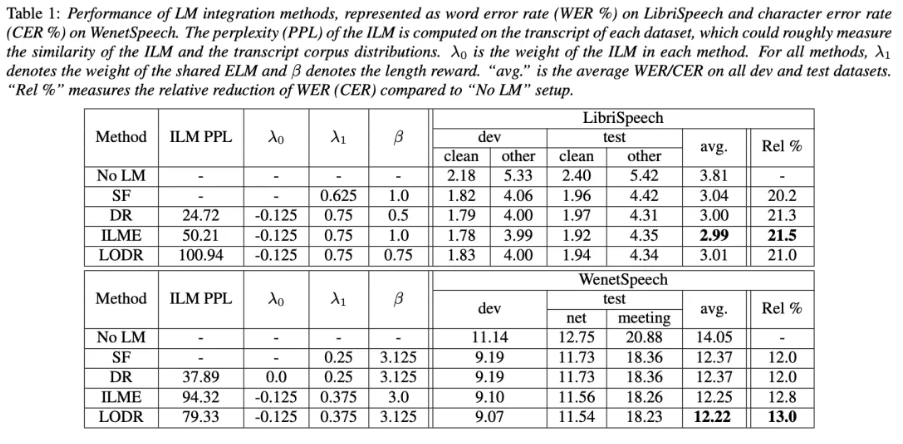
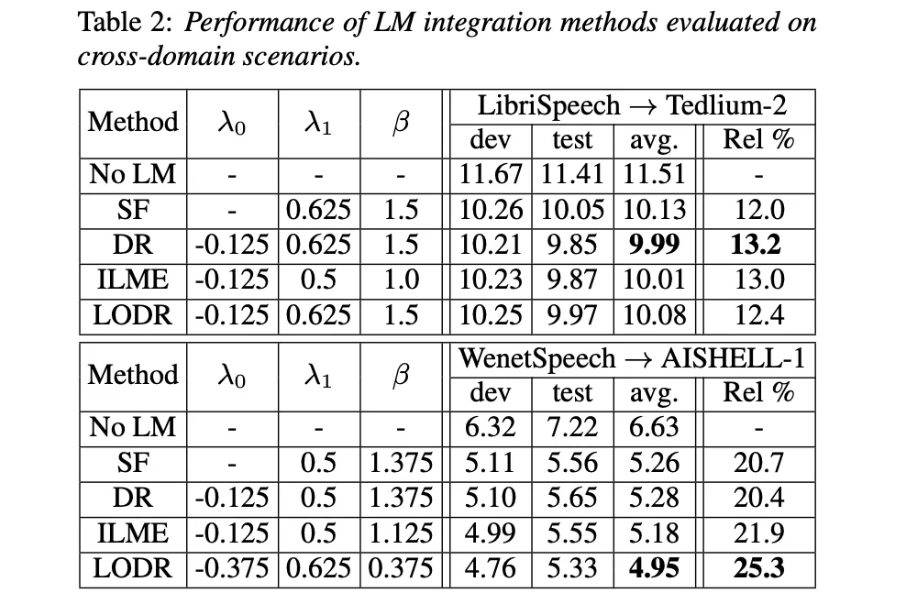
我们还在领域迁移场景做了测试:将上述训练的RNN-T模型分别在英文Tedlium-2和中文AISHELL-1测试集中测试。此时的ELM仅使用目标领域的少量文本训练。
总结
本工作结合以往研究对RNN-T模型的思考,提出了利用低阶语言模型近似ILM的方法,在不同场景和中英文下测试,与现有的方法相比均达到了良好的识别准确率;
同时,在解码时,相对DR方法额外引入的NN LM计算、ILME方法引入的文本建模模块第2遍计算,我们的LODR方法引入的2-gram在解码时仅需要做简单的查询,计算开销更少、速度更快,方案更为轻量化。
最后需要指出的是,LODR并不局限于RNN-T模型。不难看出,LODR亦可方便地用于AED(Attention Encoder-Decoder)端到端ASR模型。LODR将于近期在CAT工具包开源发布,敬请关注!
CAT工具包链接
https://github.com/thu-spmi/CAT

