RKD知识蒸馏实战:使用CoatNet蒸馏ResNet
文章目录
- 摘要
- 最终结论
- 数据准备
- 教师网络
-
- 步骤
-
- 导入需要的库
- 定义训练和验证函数
- 定义全局参数
- 图像预处理与增强
- 读取数据
- 设置模型和Loss
- 学生网络
-
- 步骤
-
- 导入需要的库
- 定义训练和验证函数
- 定义全局参数
- 图像预处理与增强
- 读取数据
- 设置模型和Loss
- 蒸馏学生网络
-
- 步骤
-
- 导入需要的库
- 定义蒸馏脚本
- 定义训练和验证函数
- 定义全局参数
- 图像预处理与增强
- 读取数据
- 设置模型和Loss
- 结果比对
- 总结
摘要
知识蒸馏(Knowledge Distillation),简称KD,将已经训练好的模型包含的知识(”Knowledge”),蒸馏(“Distill”)提取到另一个模型里面去。Hinton在"Distilling the Knowledge in a Neural Network"首次提出了知识蒸馏(暗知识提取)的概念,通过引入与教师网络(Teacher network:复杂、但预测精度优越)相关的软目标(Soft-target)作为Total loss的一部分,以诱导学生网络(Student network:精简、低复杂度,更适合推理部署)的训练,实现知识迁移(Knowledge transfer)。本文使用RKD实现对模型的蒸馏。与上一篇(https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/127787791?spm=1001.2014.3001.5501)蒸馏的方法有所不同,RKD是对展平层的特征做蒸馏,蒸馏的loss分为二阶的距离损失Distance-wise Loss和三阶的角度损失Angle-wise Loss。
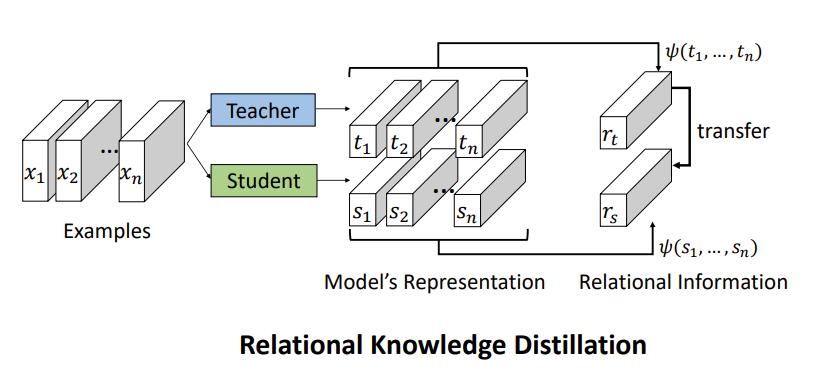
最终结论
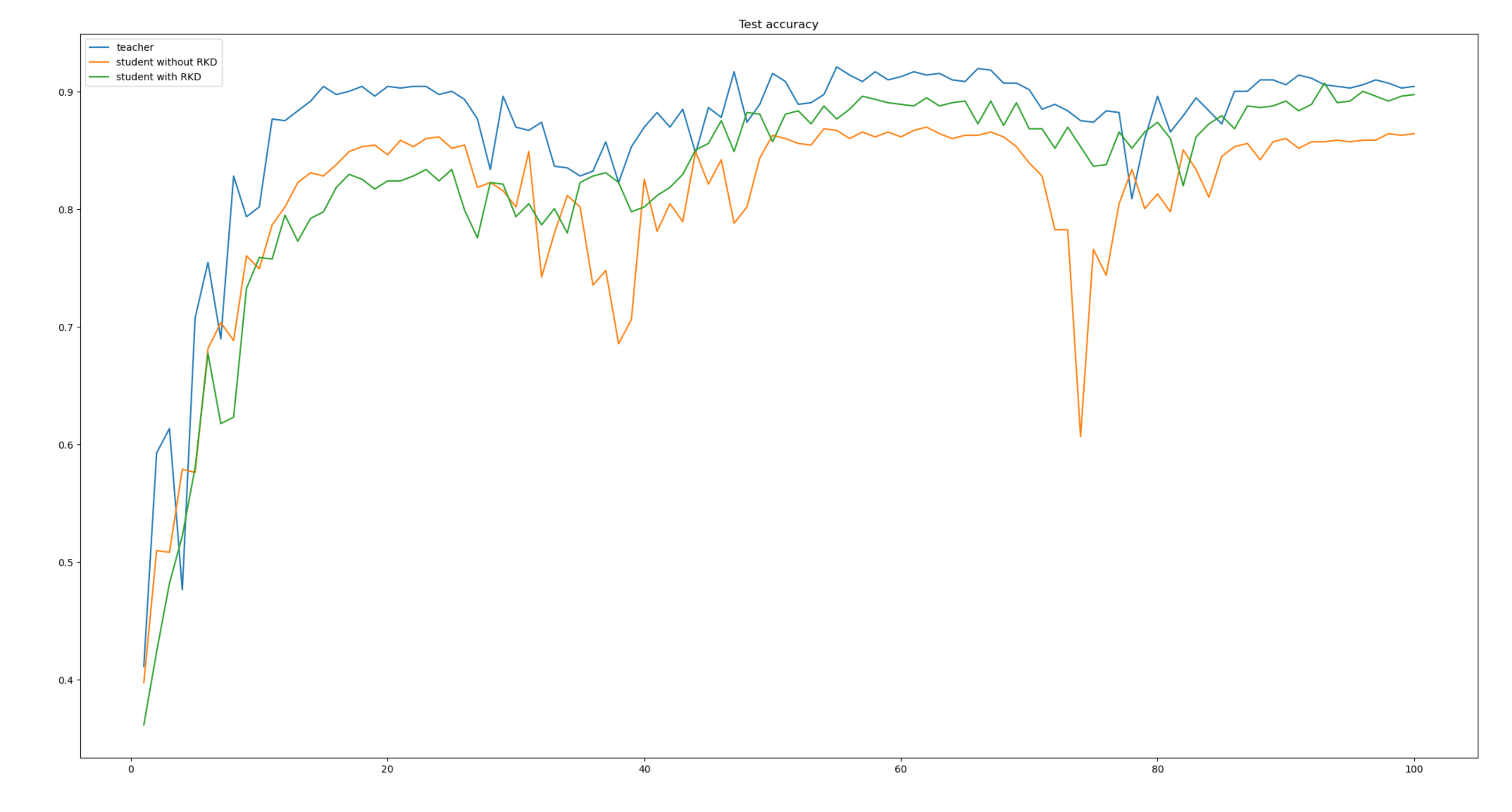
先把结论说了吧! Teacher网络使用coatnet_2,Student网络使用ResNet18。如下表
| 网络 | epochs | ACC |
|---|---|---|
| coatnet_2 | 100 | 92% |
| ResNet18 | 100 | 86% |
| ResNet18 +RKD | 100 | 90% |
在相同的条件下,加入知识蒸馏后,ResNet18的ACC上升了4个点,提升的还是很高的。如下图:
数据准备
数据使用我以前在图像分类任务中的数据集——植物幼苗数据集,先将数据集转为训练集和验证集。执行代码:
import globimport osimport shutilimage_list=glob.glob('data1/*/*.png')print(image_list)file_dir='data'if os.path.exists(file_dir): print('true') #os.rmdir(file_dir) shutil.rmtree(file_dir)#删除再建立 os.makedirs(file_dir)else: os.makedirs(file_dir)from sklearn.model_selection import train_test_splittrainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)train_dir='train'val_dir='val'train_root=os.path.join(file_dir,train_dir)val_root=os.path.join(file_dir,val_dir)for file in trainval_files: file_class=file.replace("\\","/").split('/')[-2] file_name=file.replace("\\","/").split('/')[-1] file_class=os.path.join(train_root,file_class) if not os.path.isdir(file_class): os.makedirs(file_class) shutil.copy(file, file_class + '/' + file_name)for file in val_files: file_class=file.replace("\\","/").split('/')[-2] file_name=file.replace("\\","/").split('/')[-1] file_class=os.path.join(val_root,file_class) if not os.path.isdir(file_class): os.makedirs(file_class) shutil.copy(file, file_class + '/' + file_name)教师网络
教师网络选用coatnet_2,是一个比较大一点的网络了,模型的大小有200M。训练100个epoch,最好的模型在92%左右。RKD蒸馏是对展平层的蒸馏,所以我们需要对CoatNet网络做一些修改,如下:
在这里插入代码片class CoAtNet(nn.Module): def __init__(self, image_size, in_channels, num_blocks, channels, num_classes=1000, block_types=['C', 'C', 'T', 'T']): super().__init__() ih, iw = image_size block = {'C': MBConv, 'T': Transformer} self.s0 = self._make_layer( conv_3x3_bn, in_channels, channels[0], num_blocks[0], (ih // 2, iw // 2)) self.s1 = self._make_layer( block[block_types[0]], channels[0], channels[1], num_blocks[1], (ih // 4, iw // 4)) self.s2 = self._make_layer( block[block_types[1]], channels[1], channels[2], num_blocks[2], (ih // 8, iw // 8)) self.s3 = self._make_layer( block[block_types[2]], channels[2], channels[3], num_blocks[3], (ih // 16, iw // 16)) self.s4 = self._make_layer( block[block_types[3]], channels[3], channels[4], num_blocks[4], (ih // 32, iw // 32)) self.pool = nn.AvgPool2d(ih // 32, 1) self.fc = nn.Linear(channels[-1], num_classes, bias=False) def forward(self, x): x = self.s0(x) x = self.s1(x) x = self.s2(x) x = self.s3(x) x = self.s4(x) fea = self.pool(x).view(-1, x.shape[1]) x = self.fc(fea) return fea, x对模型的返回结果做修改,增加返回展平层的特征,这样Model的返回值有两个,一个是fea,一个是x。接下来开始编写teacher模型的train方法。
步骤
新建teacher_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom torch.autograd import Variablefrom model.coatnet import coatnet_2import jsonimport os定义训练和验证函数
def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = Variable(data).to(device), Variable(target).to(device) fea,output = model(data) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = Variable(data).to(device), Variable(target).to(device) fea,output = model(data) loss = criterion(output, target) _, pred = torch.max(output.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'CoatNet' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 50 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
# 实例化模型并且移动到GPU criterion = nn.CrossEntropyLoss() model_ft = coatnet_2() num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs, 12) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft, DEVICE, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft, DEVICE, test_loader) val_acc_list[epoch]=acc with open('result.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'CoatNet/model_final.pth')完成上面的代码就可以开始训练Teacher网络了。
学生网络
学生网络选用ResNet18,是一个比较小一点的网络了,模型的大小有40M。训练50个epoch,最好的模型在86%左右。由于RKD是对展平层做蒸馏,所以还需要对ResNet做修改,使其能够返回展平层的特征。
def _forward_impl(self, x: Tensor) -> Tensor: # See note [TorchScript super()] x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.layer1(x) x = self.layer2(x) x = self.layer3(x) x = self.layer4(x) x = self.avgpool(x) fea = torch.flatten(x, 1) x = self.fc(fea) return fea,x def forward(self, x: Tensor) -> Tensor: return self._forward_impl(x)返回值增加fea,然后就能获取Student模型的展平层特征了。接下来开始编写Student的训练方法。
步骤
新建student_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom torch.autograd import Variablefrom torchvision.models.resnet import resnet18import jsonimport os定义训练和验证函数
def train(model, device, train_loader, optimizer, epoch): model.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target =data.to(device), target.to(device) fea,output = model(data) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) fea,output = model(data) loss = criterion(output, target) _, pred = torch.max(output.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'resnet' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu')图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
# 实例化模型并且移动到GPU criterion = nn.CrossEntropyLoss() model_ft = resnet18() print(model_ft) num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs, 12) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft, DEVICE, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft, DEVICE, test_loader) val_acc_list[epoch]=acc with open('result_student.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'resnet/model_final.pth')完成上面的代码就可以开始训练Student网络了。
蒸馏学生网络
学生网络继续选用ResNet18,使用Teacher网络蒸馏学生网络,训练100个epoch,最终ACC是90%。
步骤
新建student_rkd_train.py,插入代码:
导入需要的库
import torch.optim as optimimport torchimport torch.nn as nnimport torch.nn.parallelimport torch.utils.dataimport torch.utils.data.distributedimport torchvision.transforms as transformsfrom torchvision import datasetsfrom torch.autograd import Variablefrom torchvision.models.resnet import resnet18import jsonimport os定义蒸馏脚本
新建rkd.py,插入代码:
from __future__ import absolute_importfrom __future__ import print_functionfrom __future__ import divisionimport torchimport torch.nn as nnimport torch.nn.functional as F'''From https://github.com/lenscloth/RKD/blob/master/metric/loss.py'''class RKD(nn.Module):'''Relational Knowledge Distillationhttps://arxiv.org/pdf/1904.05068.pdf'''def __init__(self, w_dist, w_angle):super(RKD, self).__init__()self.w_dist = w_distself.w_angle = w_angledef forward(self, feat_s, feat_t):loss = self.w_dist * self.rkd_dist(feat_s, feat_t) + \ self.w_angle * self.rkd_angle(feat_s, feat_t)return lossdef rkd_dist(self, feat_s, feat_t):feat_t_dist = self.pdist(feat_t, squared=False)mean_feat_t_dist = feat_t_dist[feat_t_dist>0].mean()feat_t_dist = feat_t_dist / mean_feat_t_distfeat_s_dist = self.pdist(feat_s, squared=False)mean_feat_s_dist = feat_s_dist[feat_s_dist>0].mean()feat_s_dist = feat_s_dist / mean_feat_s_distloss = F.smooth_l1_loss(feat_s_dist, feat_t_dist)return lossdef rkd_angle(self, feat_s, feat_t):# N x C --> N x N x Cfeat_t_vd = (feat_t.unsqueeze(0) - feat_t.unsqueeze(1))norm_feat_t_vd = F.normalize(feat_t_vd, p=2, dim=2)feat_t_angle = torch.bmm(norm_feat_t_vd, norm_feat_t_vd.transpose(1, 2)).view(-1)feat_s_vd = (feat_s.unsqueeze(0) - feat_s.unsqueeze(1))norm_feat_s_vd = F.normalize(feat_s_vd, p=2, dim=2)feat_s_angle = torch.bmm(norm_feat_s_vd, norm_feat_s_vd.transpose(1, 2)).view(-1)loss = F.smooth_l1_loss(feat_s_angle, feat_t_angle)return lossdef pdist(self, feat, squared=False, eps=1e-12):feat_square = feat.pow(2).sum(dim=1)feat_prod = torch.mm(feat, feat.t())feat_dist = (feat_square.unsqueeze(0) + feat_square.unsqueeze(1) - 2 * feat_prod).clamp(min=eps)if not squared:feat_dist = feat_dist.sqrt()feat_dist = feat_dist.clone()feat_dist[range(len(feat)), range(len(feat))] = 0return feat_dist定义训练和验证函数
# 定义训练过程def train(s_net,t_net, device, criterionCls,criterionKD,train_loader, optimizer, epoch): s_net.train() sum_loss = 0 total_num = len(train_loader.dataset) print(total_num, len(train_loader)) for batch_idx, (data, target) in enumerate(train_loader): data, target = data.to(device), target.to(device) optimizer.zero_grad() fea_s,output = s_net(data) cls_loss = criterionCls(output, target) fea_t, teacher_output = t_net(data) # 训练出教师的 teacher_output kd_loss = criterionKD(fea_s, fea_t.detach()) * lambda_kd loss = cls_loss + kd_loss loss.backward() optimizer.step() print_loss = loss.data.item() sum_loss += print_loss if (batch_idx + 1) % 10 == 0: print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format( epoch, (batch_idx + 1) * len(data), len(train_loader.dataset), 100. * (batch_idx + 1) / len(train_loader), loss.item())) ave_loss = sum_loss / len(train_loader) print('epoch:{},loss:{}'.format(epoch, ave_loss))Best_ACC=0# 验证过程@torch.no_grad()def val(model, device,criterionCls, test_loader): global Best_ACC model.eval() test_loss = 0 correct = 0 total_num = len(test_loader.dataset) print(total_num, len(test_loader)) with torch.no_grad(): for data, target in test_loader: data, target = data.to(device), target.to(device) _,output = model(data) loss = criterionCls(output, target) _, pred = torch.max(output.data, 1) correct += torch.sum(pred == target) print_loss = loss.data.item() test_loss += print_loss correct = correct.data.item() acc = correct / total_num avgloss = test_loss / len(test_loader) if acc > Best_ACC: torch.save(model, file_dir + '/' + 'best.pth') Best_ACC = acc print('\nVal set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format( avgloss, correct, len(test_loader.dataset), 100 * acc)) return acc定义全局参数
if __name__ == '__main__': # 创建保存模型的文件夹 file_dir = 'resnet_rkd' if os.path.exists(file_dir): print('true') os.makedirs(file_dir, exist_ok=True) else: os.makedirs(file_dir) # 设置全局参数 modellr = 1e-4 BATCH_SIZE = 16 EPOCHS = 100 DEVICE = torch.device('cuda' if torch.cuda.is_available() else 'cpu') w_dist=25 w_angle=50 lambda_kd=1.0图像预处理与增强
# 数据预处理7 transform = transforms.Compose([ transforms.RandomRotation(10), transforms.GaussianBlur(kernel_size=(5, 5), sigma=(0.1, 3.0)), transforms.ColorJitter(brightness=0.5, contrast=0.5, saturation=0.5), transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ]) transform_test = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.44127703, 0.4712498, 0.43714803], std=[0.18507297, 0.18050247, 0.16784933]) ])读取数据
使用pytorch默认读取数据的方式。
# 读取数据 dataset_train = datasets.ImageFolder('data/train', transform=transform) dataset_test = datasets.ImageFolder("data/val", transform=transform_test) with open('class.txt', 'w') as file: file.write(str(dataset_train.class_to_idx)) with open('class.json', 'w', encoding='utf-8') as file: file.write(json.dumps(dataset_train.class_to_idx)) # 导入数据 train_loader = torch.utils.data.DataLoader(dataset_train, batch_size=BATCH_SIZE, shuffle=True) test_loader = torch.utils.data.DataLoader(dataset_test, batch_size=BATCH_SIZE, shuffle=False)设置模型和Loss
# 实例化模型并且移动到GPUmodel_ft = resnet18() print(model_ft) num_ftrs = model_ft.fc.in_features model_ft.fc = nn.Linear(num_ftrs, 12) model_ft.to(DEVICE) # 选择简单暴力的Adam优化器,学习率调低 optimizer = optim.Adam(model_ft.parameters(), lr=modellr) cosine_schedule = optim.lr_scheduler.CosineAnnealingLR(optimizer=optimizer, T_max=20, eta_min=1e-9) teacher_model=torch.load('./CoatNet/best.pth') teacher_model.eval() # 定义rkd loss和nn.CrossEntropyLoss() criterionKD = RKD(w_dist, w_angle) criterionCls = nn.CrossEntropyLoss() # 训练 val_acc_list= {} for epoch in range(1, EPOCHS + 1): train(model_ft,teacher_model, DEVICE,criterionCls,criterionKD, train_loader, optimizer, epoch) cosine_schedule.step() acc=val(model_ft,DEVICE,criterionCls , test_loader) val_acc_list[epoch]=acc with open('result_rkd.json', 'w', encoding='utf-8') as file: file.write(json.dumps(val_acc_list)) torch.save(model_ft, 'resnet_rkd/model_final.pth')完成上面的代码就可以开始蒸馏模式!!!
结果比对
加载保存的结果,然后绘制acc曲线。
import numpy as npfrom matplotlib import pyplot as pltimport jsonteacher_file='result.json'student_file='result_student.json'student_kd_file='result_rkd.json'def read_json(file): with open(file, 'r', encoding='utf8') as fp: json_data = json.load(fp) print(json_data) return json_datateacher_data=read_json(teacher_file)student_data=read_json(student_file)student_kd_data=read_json(student_kd_file)x =[int(x) for x in list(dict(teacher_data).keys())]print(x)plt.plot(x, list(teacher_data.values()), label='teacher')plt.plot(x,list(student_data.values()), label='student without RKD')plt.plot(x, list(student_kd_data.values()), label='student with RKD')plt.title('Test accuracy')plt.legend()plt.show()总结
知识蒸馏是常用的一种对轻量化模型压缩和提升的方法。今天通过一个简单的例子讲解了如何使用Teacher网络对Student网络进行RKD蒸馏。
本次实战用到的代码和数据集详见:
https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/87029904

