全网首篇深度剖析PoolFormer模型,带你揭开MetaFormer的神秘面纱
文章目录
- 摘要
- 作者简介
- 模型分析
- Input Emb模块
-
- to_2tuple函数
- nn.Conv2d
- nn.Identity()
- Input Emb模块源码
- PoolFormerBlock
- PoolFormer
- 总结
摘要
论文:https://arxiv.org/abs/2111.11418
论文翻译:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/128281326
官方源码:https://github.com/sail-sg/poolformer
MetaFormer是颜水成大佬的一篇Transformer的论文,该篇论文的贡献主要有两点:第一、将Transformer抽象为一个通用架构的MetaFormer,并通过经验证明MetaFormer架构在Transformer/ mlp类模型取得了极大的成功。
第二、通过仅采用简单的非参数算子pooling作为MetaFormer的极弱token混合器,构建了一个名为PoolFormer。
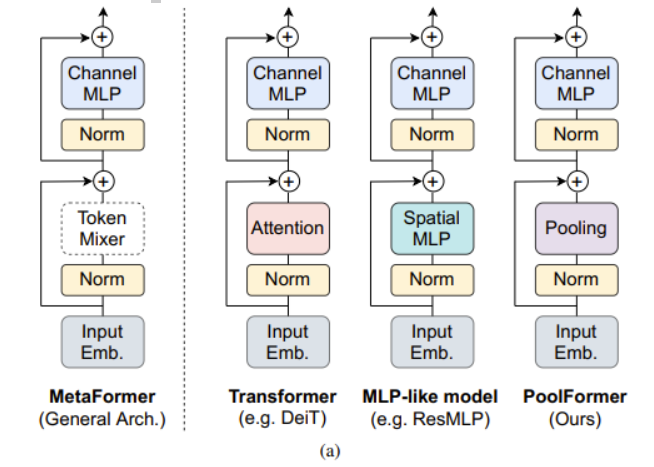
Transformer编码器如图1(a)所示,由两部分组成。一个是注意力模块,用于在token之间混合信息,我们将其称为token mixer。另一个组件包含剩余的模块,如通道mlp和残差连接。transformer的成功归功于基于注意力的token混合器。基于这一共识,已经开发了许多注意力模块的变体,以改进视觉Transformer,比如上篇DEiT就是增加了一个dist token。
最近的一些方法在MetaFormer架构中探索了其他类型的token mixers,例如,用傅里叶变换取代了注意力,仍然达到了普通transformer的约97%的精度。综合所有这些结果,似乎只要模型采用MetaFormer作为通用架构,就可以获得非常优秀的结果。为了验证这一假设,作者应用一个极其简单的非参数操作符pooling作为令牌混合器,只进行基本的令牌混合,将其命名为PoolFormer。PoolFormer-M36在ImageNet-1K分类基准上达到82.1%的top-1精度,超过了DeiT[53]和ResMLP[52]等调优的视觉变压器,充分展示了MetaFormer通用架构的优秀性能。

作者简介
颜水成,计算机视觉和机器学习领域专家 [2] ,新加坡工程院院士、ACM Fellow、IEEE Fellow、IAPR Fellow、ACM杰出科学家。 [3]
颜水成2004年从北京大学毕业,获数学博士学位。2004年至2006年,前往香港中文大学汤晓鸥教授的多媒体实验室任博士后,从事人脸识别方面的研究。2006年至2007年,赴美国伊利诺伊大学香槟分校(UIUC),师从黄煦涛(Thomas Huang)。2007年,加入新加坡国立大学,创立了机器学习与计算机视觉实验室。

模型分析
为了更加深入的了解模型,我们一起剖析一下模型的结构,使用 PoolFormer-S24举例,参数如下:
def poolformer_s24(pretrained=False, kwargs): """ PoolFormer-S24 model, Params: 21M """ layers = [4, 4, 12, 4] embed_dims = [64, 128, 320, 512] mlp_ratios = [4, 4, 4, 4] downsamples = [True, True, True, True] model = PoolFormer( layers, embed_dims=embed_dims, mlp_ratios=mlp_ratios, downsamples=downsamples, kwargs) return modelInput Emb模块
为了方便大家理解 Input Emb模块,对其一些关键的代码做了分析,主要包括:to_2tuple函数、nn.Conv2d、nn.Identity()等。
to_2tuple函数
to_2tuple函数对patch_size转为(patch_size,patch_size)元祖的形式,同理stride和padding分别转为(stride,stride)和(padding,padding)。
例:
from timm.models.layers import to_2tuple,to_3tuple # 导入a = 224b = to_2tuple(a)c = to_3tuple(a)print("a:{},b:{},c:{}".format(a,b,c))print(type(a),type(b))输出结果:
a:224,b:(224, 224),c:(224, 224, 224)<class 'int'> <class 'tuple'>nn.Conv2d
这一层就是一个普通的卷积,PoolFormer里的具体的参数:patch_size=7,stride=4,padding=2,in_chans=3,embed_dim=64,带入卷积如下:
nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding)得到
nn.Conv2d(3, 64, kernel_size=(7,7), stride=(4,4), padding=(2,2))根据卷积的计算公式:
N=(W-F+2P)/S+1
其中N:输出大小
W:输入大小
F:卷积核大小
P:填充值的大小
S:步长大小
由于输入大小是224,将上面的参数代入:⌊(224-7+2×2)/4⌋+1=56
所以经过卷积之后的输出大小是[-1, 64, 56, 56] 。
nn.Identity()
直接源码。
class Identity(Module): def __init__(self, *args: Any, kwargs: Any) -> None: super(Identity, self).__init__() def forward(self, input: Tensor) -> Tensor: return input将输入直接输出,就是个占位符。所以输出自然是[-1, 64, 56, 56]
到这里Input Emb模块讲解完了。详细参数如下:
(patch_embed): PatchEmbed( (proj): Conv2d(3, 64, kernel_size=(7, 7), stride=(4, 4), padding=(2, 2)) (norm): Identity() )Input Emb模块源码
对输入的信息进行编码。代码如下:
class PatchEmbed(nn.Module): """ Patch Embedding that is implemented by a layer of conv. Input: tensor in shape [B, C, H, W] Output: tensor in shape [B, C, H/stride, W/stride] """ def __init__(self, patch_size=16, stride=16, padding=0, in_chans=3, embed_dim=768, norm_layer=None): super().__init__() patch_size = to_2tuple(patch_size) stride = to_2tuple(stride) padding = to_2tuple(padding) self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride, padding=padding) self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward(self, x): x = self.proj(x) x = self.norm(x) return x通过上面的代码,我们可以得知,里面只有一步卷积操作。
PoolFormerBlock
接下来讲解一下PoolFormerBlock,PoolFormerBlock是构成网络的baseblock,PoolFormer就是通过搭积木一样的方式将PoolFormerBlock堆叠起来。
PoolFormerBlock代码:
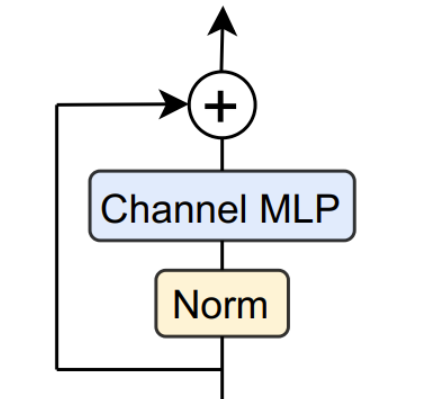
class PoolFormerBlock(nn.Module): def __init__(self, dim, pool_size=3, mlp_ratio=4., act_layer=nn.GELU, norm_layer=GroupNorm, drop=0., drop_path=0., use_layer_scale=True, layer_scale_init_value=1e-5): super().__init__() self.norm1 = norm_layer(dim) self.token_mixer = Pooling(pool_size=pool_size) self.norm2 = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop) # The following two techniques are useful to train deep PoolFormers. self.drop_path = DropPath(drop_path) if drop_path > 0. \ else nn.Identity() self.use_layer_scale = use_layer_scale if use_layer_scale: self.layer_scale_1 = nn.Parameter( layer_scale_init_value * torch.ones((dim)), requires_grad=True) self.layer_scale_2 = nn.Parameter( layer_scale_init_value * torch.ones((dim)), requires_grad=True) def forward(self, x): if self.use_layer_scale: x = x + self.drop_path( self.layer_scale_1.unsqueeze(-1).unsqueeze(-1) * self.token_mixer(self.norm1(x))) x = x + self.drop_path( self.layer_scale_2.unsqueeze(-1).unsqueeze(-1) * self.mlp(self.norm2(x))) else: x = x + self.drop_path(self.token_mixer(self.norm1(x))) x = x + self.drop_path(self.mlp(self.norm2(x))) return xPoolFormerBlock结构图如下:
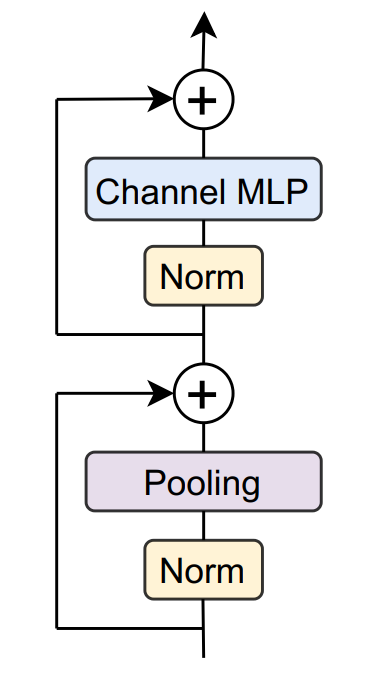
从上图可以看出,PoolFormerBlock包括:Norm、Pooling、Channel MLP。输入的参数首先进入Norm,Norm默认是GroupNorm,这里的GroupNorm仅仅继承了pytorch的nn.GroupNorm,代码如下:
class GroupNorm(nn.GroupNorm): """ Group Normalization with 1 group. Input: tensor in shape [B, C, H, W] """ def __init__(self, num_channels, kwargs): super().__init__(1, num_channels, kwargs)然后输入到Pooling层,Pooling选用nn.AvgPool2d,卷积核大小是3,padding是1,所以输出的维度没有变。
class Pooling(nn.Module): """ Implementation of pooling for PoolFormer --pool_size: pooling size """ def __init__(self, pool_size=3): super().__init__() self.pool = nn.AvgPool2d( pool_size, stride=1, padding=pool_size//2, count_include_pad=False) def forward(self, x): return self.pool(x) - x经过Pooling之后,再减去输入x。
终于找到PoolFormer的核心了,极简的设计,极高的性能。
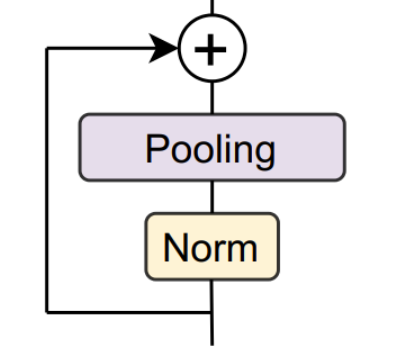
从上图可以看出,这里和输入有个融合。对应代码:
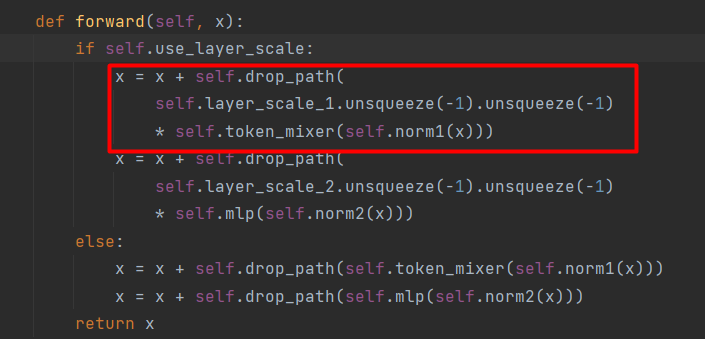
由于 drop=0., drop_path=0.,根据代码:
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()得出:
self.drop_path =nn.Identity()对于self.layer_scale_1.unsqueeze(-1).unsqueeze(-1)* self.token_mixer(self.norm1(x)),可以通过下面的代码去理解:
import torchlayer_scale_init_value=1e-5layer_scale_1=layer_scale_init_value * torch.ones((64))layer_scale_1=layer_scale_1.unsqueeze(-1).unsqueeze(-1)print(layer_scale_1.shape)print(layer_scale_1)运行结果:
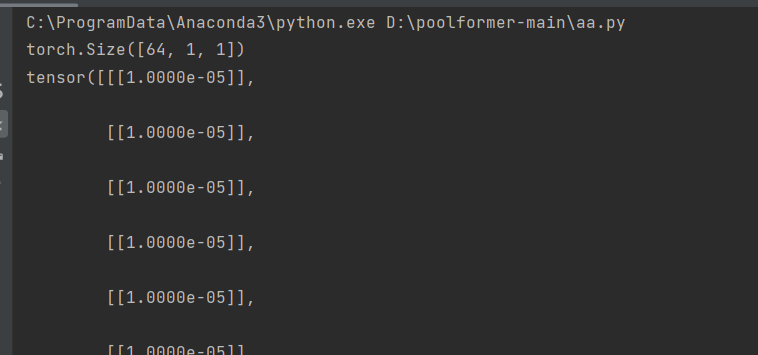
从运行结果可以看出是得到了一个64×1×1的向量。向量的值为1e-5。然后,用这个向量去乘Pooling
的输出。然后再和x相加。这个操作有点类似SE注意力机制。
接下来继续分析MLP的操作。图上的Norm依然是GroupNorm。参数如下:
GroupNorm(1, 64, eps=1e-05, affine=True)# 这里列举的参数是PoolFormer第一个Block的参数。然后,进入MLP模块。
MLP模块代码如下:
class Mlp(nn.Module): def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.): super().__init__() out_features = out_features or in_features hidden_features = hidden_features or in_features self.fc1 = nn.Conv2d(in_features, hidden_features, 1) self.act = act_layer() self.fc2 = nn.Conv2d(hidden_features, out_features, 1) self.drop = nn.Dropout(drop) def forward(self, x): x = self.fc1(x) x = self.act(x) x = self.drop(x) x = self.fc2(x) x = self.drop(x) return x关于“ out_features = out_features or in_features
hidden_features = hidden_features or in_features”
,可以同过下面代码的去理解。
in_features=64out_features=Nonehidden_features=Noneout_features = out_features or in_featureshidden_features = hidden_features or in_featuresprint(in_features,out_features,hidden_features)运行结果:
64 64 64从结果上可以得知,如果没有给out_features 或者hidden_features 赋具体的值,则将它们设置为in_features的值。
由于mlp_ratio的值为4,所以hidden_features为64×4=256。
mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)接下来的的代码比较好理解,两层1✖1的卷积+激活函数+Dropout构成。
self.fc1 = nn.Conv2d(in_features, hidden_features, 1) self.act = act_layer() self.fc2 = nn.Conv2d(hidden_features, out_features, 1) self.drop = nn.Dropout(drop)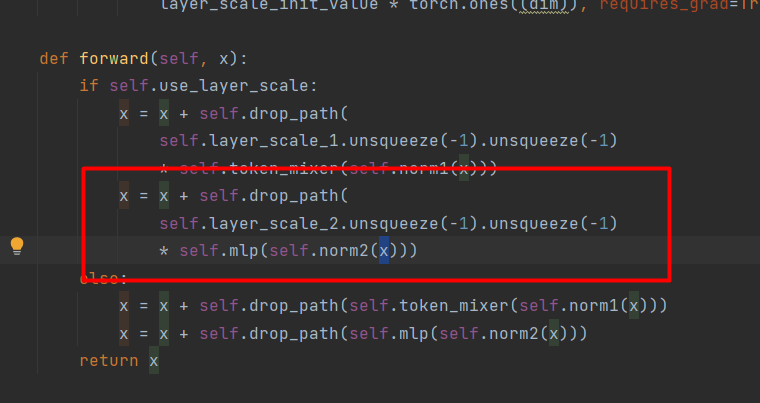
经过MLP模块后,再和layer_scale_2相乘,这里的layer_scale_2和layer_scale_1是一样的。然后和x融合。
这些参数可以通过summary()
Layer (type) Output Shape Param #================================================================ PatchEmbed-3 [-1, 64, 56, 56] 0 GroupNorm-4 [-1, 64, 56, 56] 128 AvgPool2d-5 [-1, 64, 56, 56] 0 Pooling-6 [-1, 64, 56, 56] 0 Identity-7 [-1, 64, 56, 56] 0 GroupNorm-8 [-1, 64, 56, 56] 128 Conv2d-9 [-1, 256, 56, 56] 16,640 GELU-10 [-1, 256, 56, 56] 0 Dropout-11 [-1, 256, 56, 56] 0 Conv2d-12 [-1, 64, 56, 56] 16,448 Dropout-13 [-1, 64, 56, 56] 0Mlp-14 [-1, 64, 56, 56] 0 Identity-15 [-1, 64, 56, 56] 0 PoolFormerBlock-16 [-1, 64, 56, 56] 0具体的操作,可以直接print(model)得到,如下:
(0): PoolFormerBlock( (norm1): GroupNorm(1, 64, eps=1e-05, affine=True) (token_mixer): Pooling( (pool): AvgPool2d(kernel_size=3, stride=1, padding=1) ) (norm2): GroupNorm(1, 64, eps=1e-05, affine=True) (mlp): Mlp( (fc1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1)) (act): GELU(approximate='none') (fc2): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1)) (drop): Dropout(p=0.0, inplace=False) ) (drop_path): Identity() )PoolFormer
在上一节,我们可以说是逐字逐句的剖析了PoolFormerBlock,接下来,我们一起分析,如何使用PoolFormerBlock堆叠成PoolFormer,也就是network这个list。
我们继续poolformer_s24为例,layers = [4, 4, 12, 4],embed_dims = [64, 128, 320, 512]。
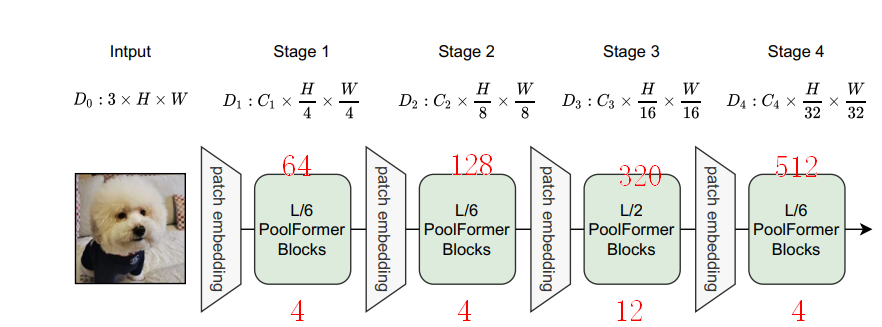
我已经将这两个列表的值和PoolFormer中的Stage对应起来,通过上图我们可以看出基本上可以ResNet类似。
第一个stage,循环了4个PoolFormerBlock,然后经过PatchEmbed构建下一个Stage的特征,高和宽减半,channel增减一倍。为了方便大家的理解,我将两个Stage交界的PoolFormerBlock打印出来,如下:
(3): PoolFormerBlock( (norm1): GroupNorm(1, 64, eps=1e-05, affine=True) (token_mixer): Pooling( (pool): AvgPool2d(kernel_size=3, stride=1, padding=1) ) (norm2): GroupNorm(1, 64, eps=1e-05, affine=True) (mlp): Mlp( (fc1): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1)) (act): GELU(approximate='none') (fc2): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1)) (drop): Dropout(p=0.0, inplace=False) ) (drop_path): Identity() ) ) (1): PatchEmbed( (proj): Conv2d(64, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1)) (norm): Identity() ) (2): Sequential( (0): PoolFormerBlock( (norm1): GroupNorm(1, 128, eps=1e-05, affine=True) (token_mixer): Pooling( (pool): AvgPool2d(kernel_size=3, stride=1, padding=1) ) (norm2): GroupNorm(1, 128, eps=1e-05, affine=True) (mlp): Mlp( (fc1): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1)) (act): GELU(approximate='none') (fc2): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1)) (drop): Dropout(p=0.0, inplace=False) ) (drop_path): Identity() )第一个PoolFormerBlock的输出为[-1,64,56,56],经过PatchEmbed后输出为[-1,128,28,28],然后进入下一个stage的PoolFormerBlock。
最终在stage4输出一个 [-1, 512, 7, 7] 的特征图。
接下来就是剩下head部分了,head部分包括两个操作。首先将[-1, 512, 7, 7]变成一维的向量,代码如下:
x.mean([-2, -1])-2代表向量从后面算起,第二个维度,-1是向量从后面算起,第一个维度。我们可以通过下面的代码理解:
x=torch.Tensor(range(0,512*5*7))x=x.reshape(512,5,7)x=x.mean(-2)print(x.shape)x=x.mean(-1)print(x.shape)输出结果:
torch.Size([512, 7])torch.Size([512])经过上面的计算,我们就可到了[-1,512]的向量了。然后通过全连接,将其降维或者升维到class的维度。
总结
这篇文章详细的介绍了PoolFormer模型,我是结合论文和官方的代码理解的,如果有不对的地方,欢迎大家指出来。

