ARM在汽车电子电器架构的应用
整理自ARM中国FAE高级经理及技术专家丁先生在集微网的演讲,侵删。
该演讲涵盖了汽车电子电器架构的多个方面,整体包含的知识面非常广。整个演讲非常精彩,也是非常佩服丁先生在汽车电子电器架构及ARM在其中的应用的精彩阐述。
本人也是从事汽车电子方面的工作,遂整理了一下演讲中的部分内容,和大家共享。
概要
- 经典汽车电子电器架构
- 功能安全设计
- 虚拟化设计
- 信息安全
- 自动驾驶芯片系统架构
- 实时性设计
- 应用场景
在每个部分中都有ARM IP在各设计中的应用
经典汽车电子电器架构
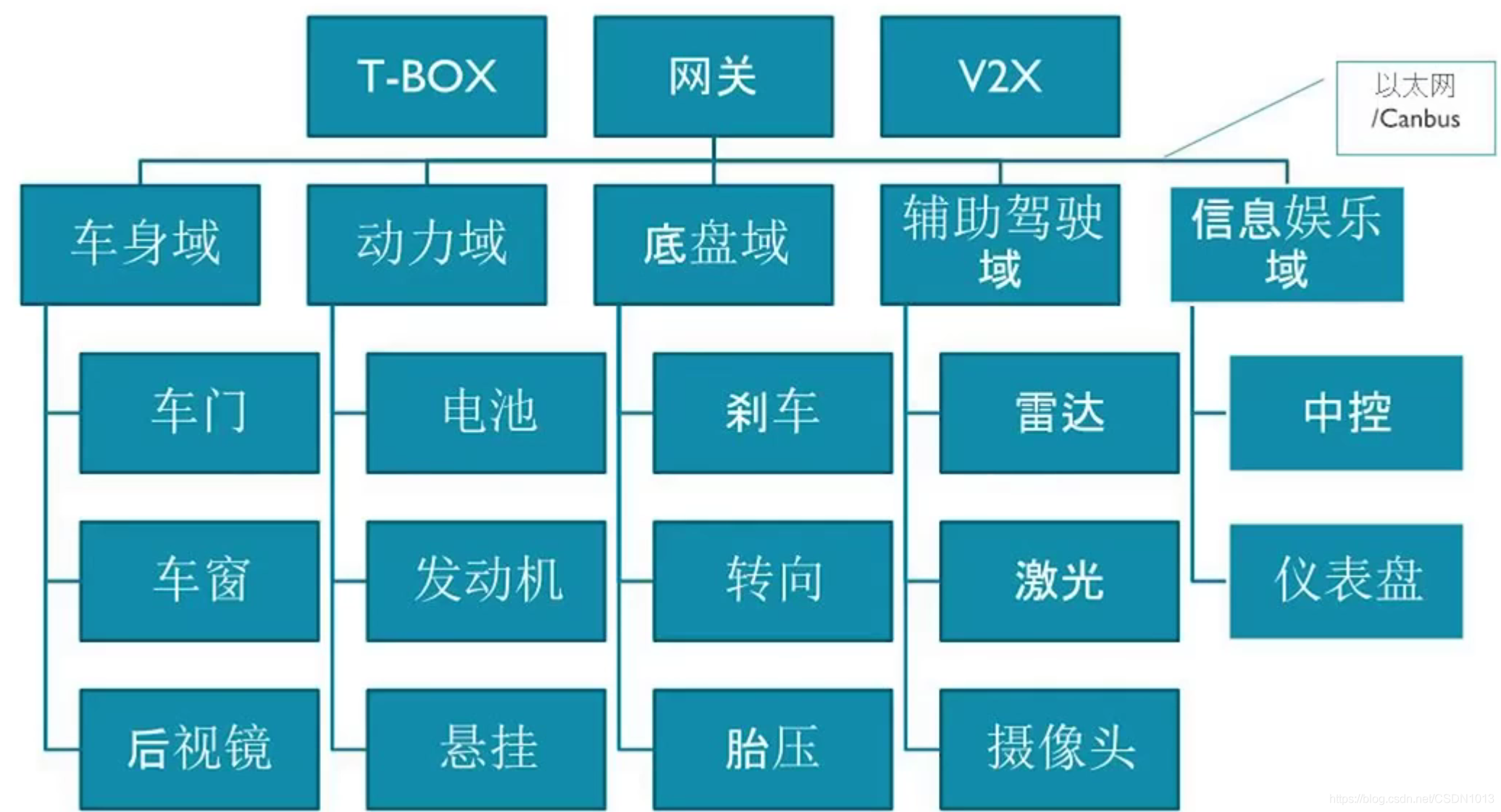
分布式的域设计。
车载娱乐芯片子系统:
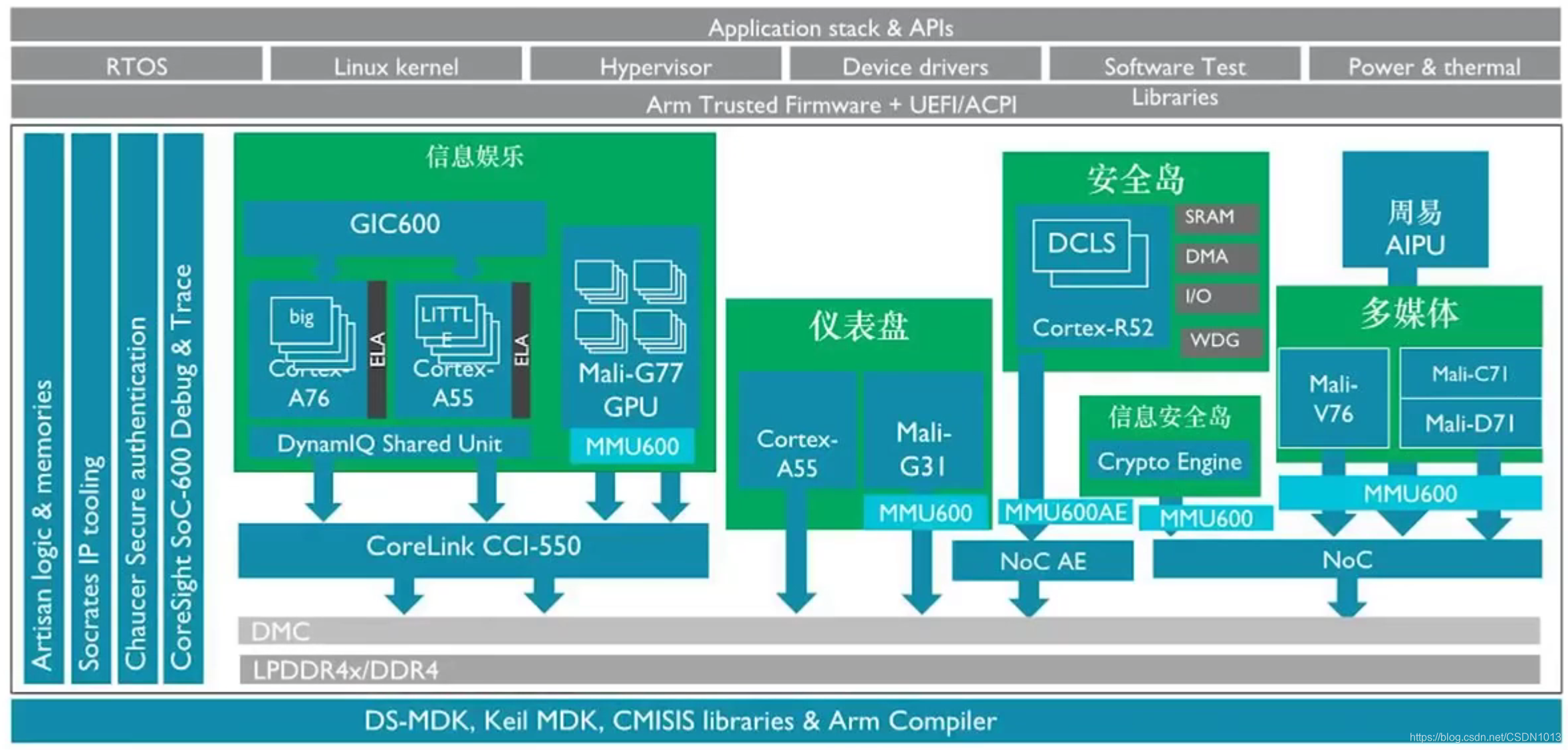
功能安全设计
-
安全岛:
-
仪表盘:
- ASIL-B:单点错误检测覆盖率达到90%以上
- 推荐和IVI操作系统进行隔离,拥有独立的CPU和GPU。否则CPU需要支持SMP
- SMP, CCI: 经过总线,所有的CPU看到对方的代码都是同一份的,绝对不会因为有各自的缓存而看到不同的代码,所有的数据和页表的信息都可以保证是一致的,不需要软件刷缓存的方法来实现。操作系统线程之间的迁移时互相对称的。
- 在SMP的前提下,跑hypervisor的时候,IVI和Cluster跑起来存在的问题:
- 如果CCI总线本身出现了硬件瞬时错误或者永久错误导致的地址或者其他的访问失败,无法告知软件这个错误并采取措施。这样,IVI和Cluster之间的干扰就无法排除。
- 跑在虚拟机之上的Cluster,启动时间可能无法达到要求
- 如何做到IVI和Cluster之间更好的隔离
- 操作系统本身最好具有一定的安全等级
-
Cortex-R52的功能安全设计案例

- 每个模块做冗余设计:双核锁步(检测瞬时错误),单点错误覆盖率 Single Point Fault Metric > 99%。Dual Core Lock Step (影响:双倍的面积)
- CPU内部的传输线: ECC校验
- 检查永久错误:周期性软件测试机制,系统上电跑LBIST和MBIST, 在线内存检测机制
- FMEA/FMEDA报告:
- 应用场景:RVC和Cluster
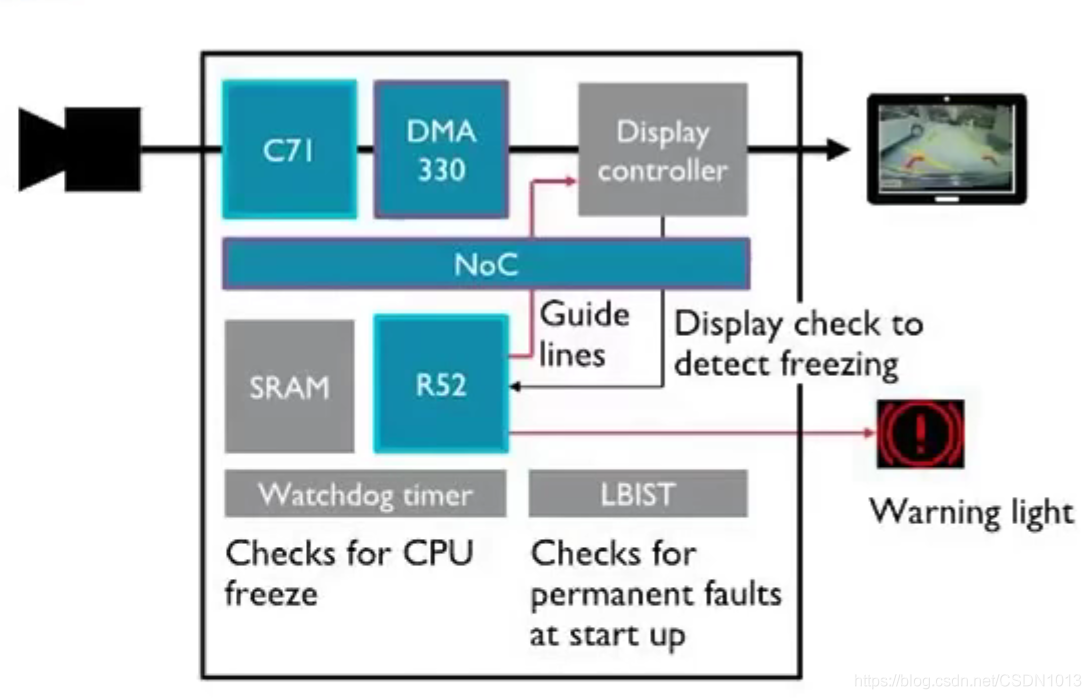
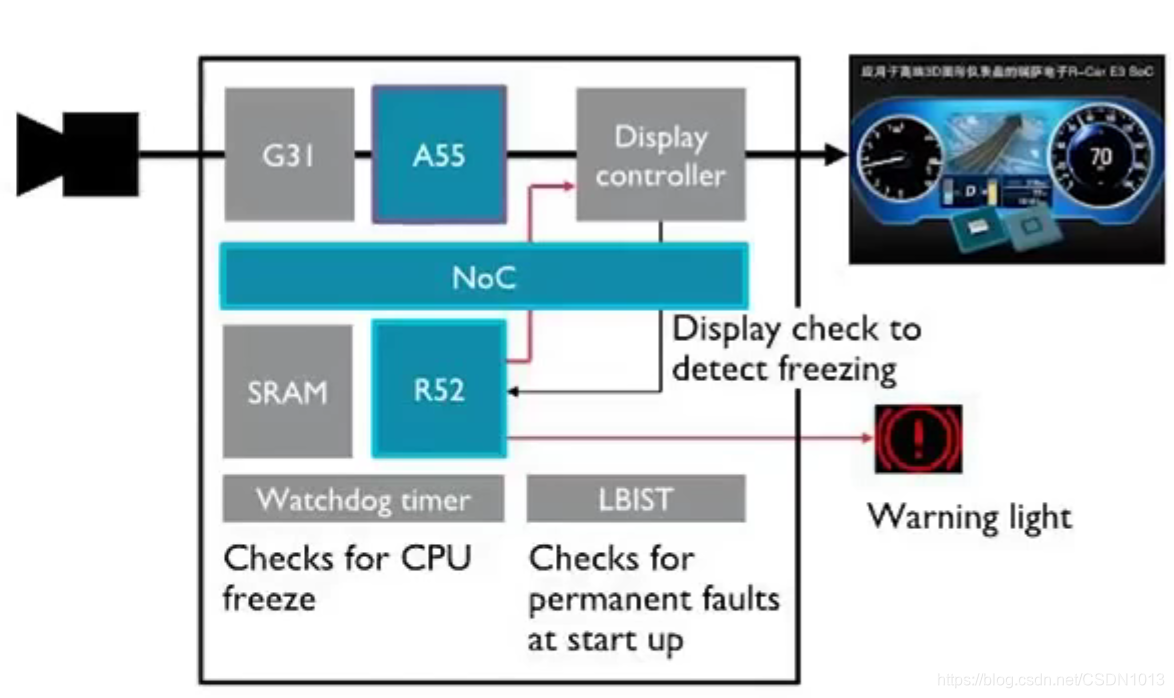
虚拟化
- 硬件虚拟化子系统:比单纯的软件虚拟化消耗的性能明显降低,且能够做到软件灵活。这在中控娱乐系统来说,是一个趋势。
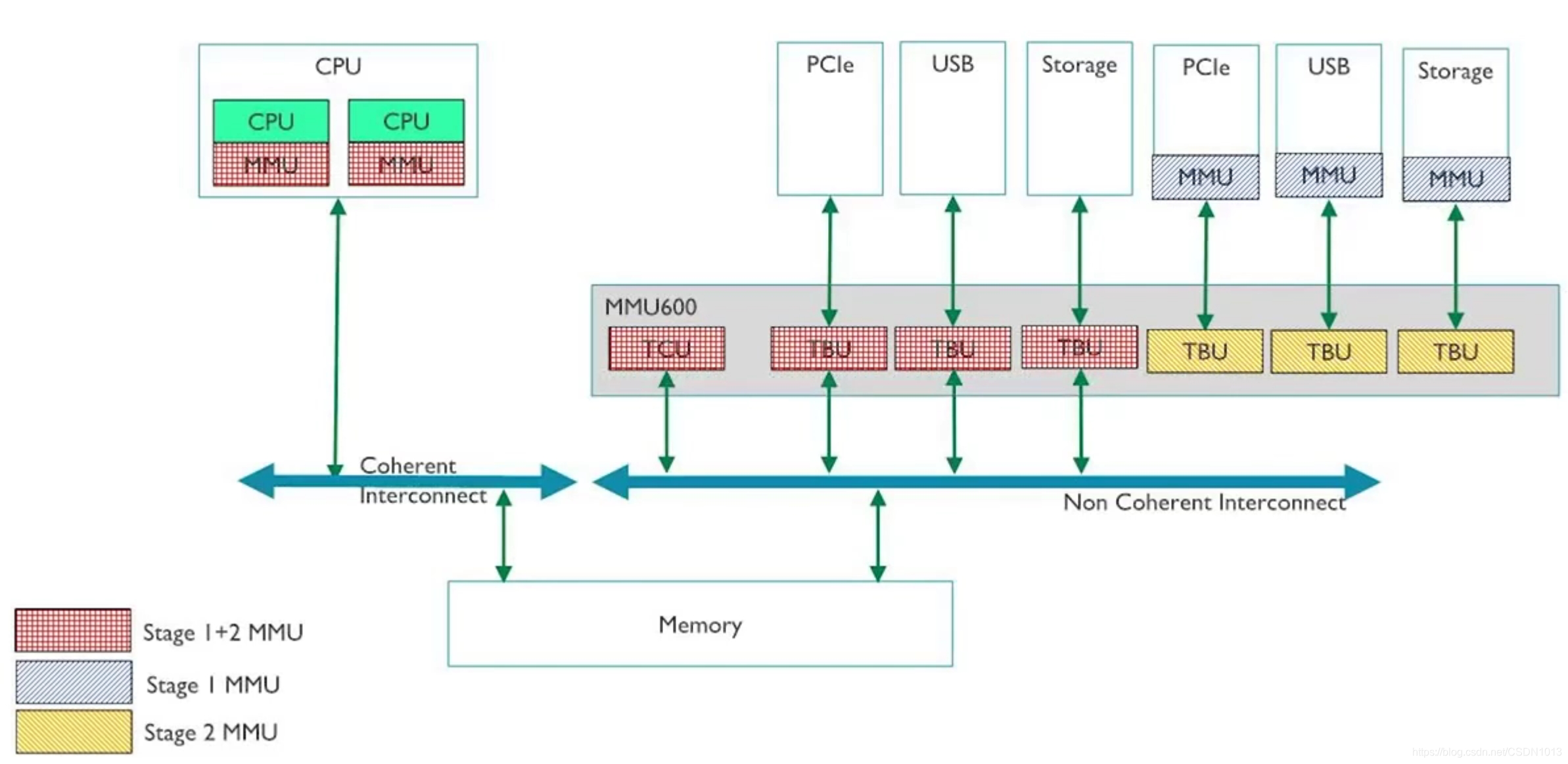
- MMU:虚地址向实地址的转换;实地址向物理地址的转换。外设需要MMU来和CPU通过MMU(一级或者两级)。推荐MMU600AE(Automotive Enhancement)
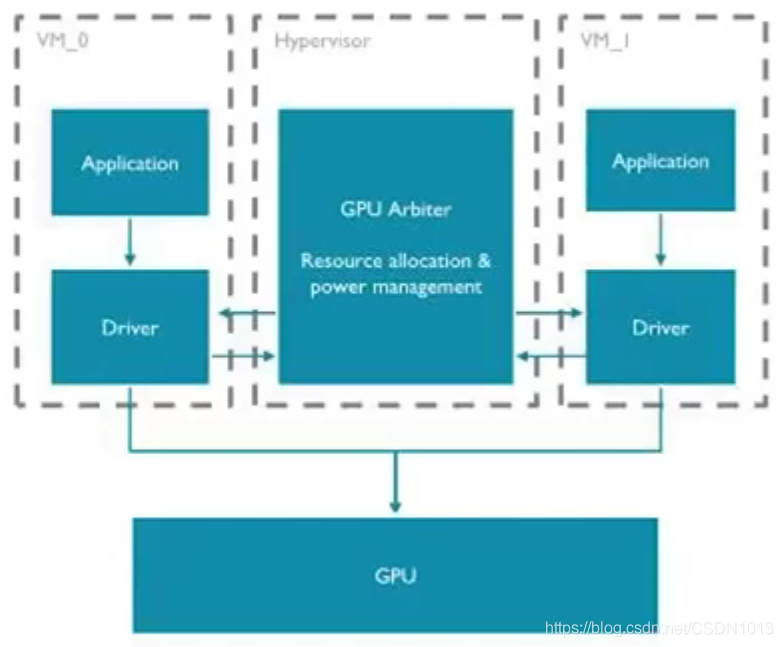
- 虚拟化的软件支持: ARM有支持硬件虚拟化的GPU,也有不支持硬件虚拟化的GPU。
- 如果GPU本身不支持硬件虚拟化,那么GPU如何共享支持不同操作系统的显示需求呢?
- Hypervisor里有一个scheduler,例如有两个Guest OS, 在Guest OS里面GPU跑非虚拟化的驱动。Guest OS并不知道其他Guest OS也使用了同一套GPU硬件。这样就可以通过pass through模式(虚拟机的一种工作模式,和不运行虚拟机时的访问是一样的,权限和内存访问通过配置MMU来实现),对于GPU来说性能损失很小。
- 调度器拥有类似决策和仲裁的机制。GPU在渲染的时候,会到hypervisor中询问调度器,是否可以进行渲染。调度器控制所有Guest OS对GPU的访问权限。不同Guest通过时分复用的方式,对GPU进行操作
- 如果GPU本身不支持硬件虚拟化,那么GPU如何共享支持不同操作系统的显示需求呢?
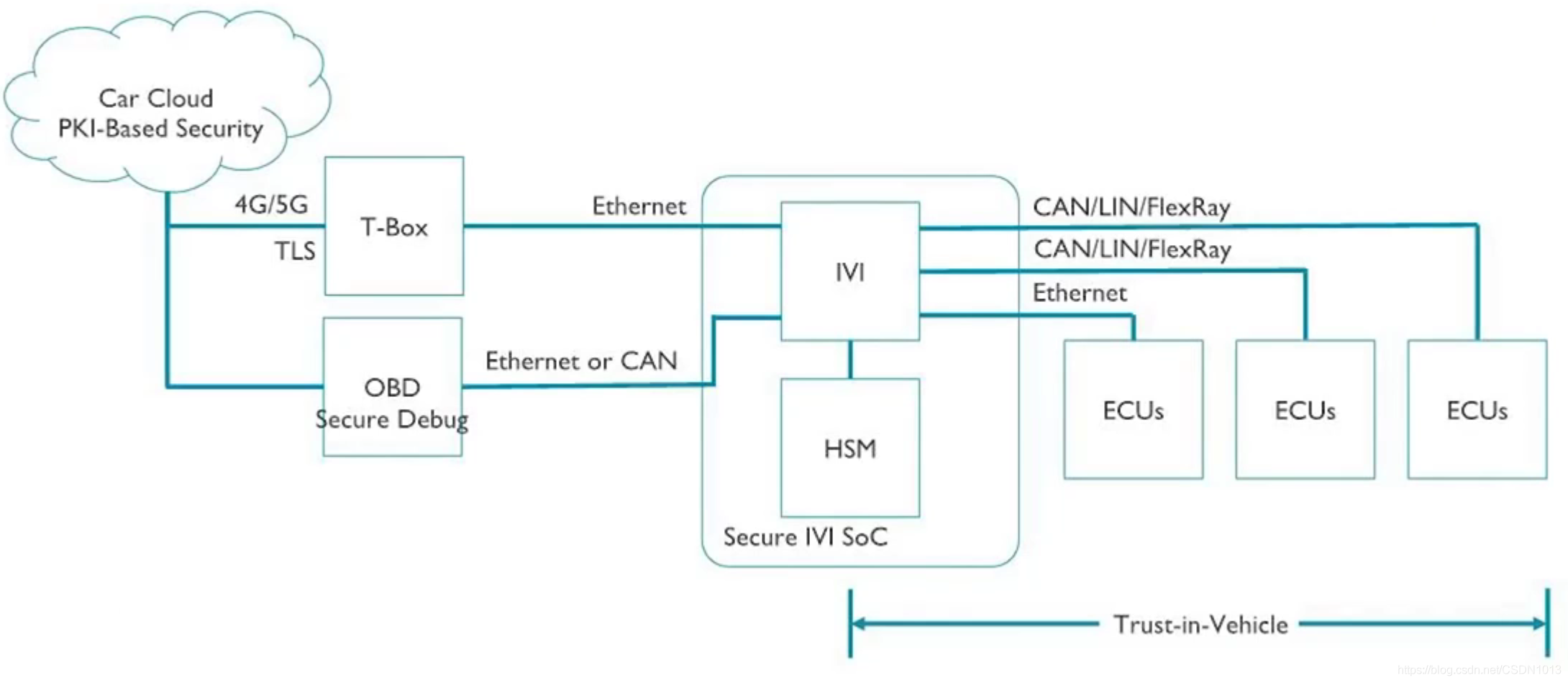
信息安全
汽车电子信息安全拓扑示例
自动驾驶芯片系统架构
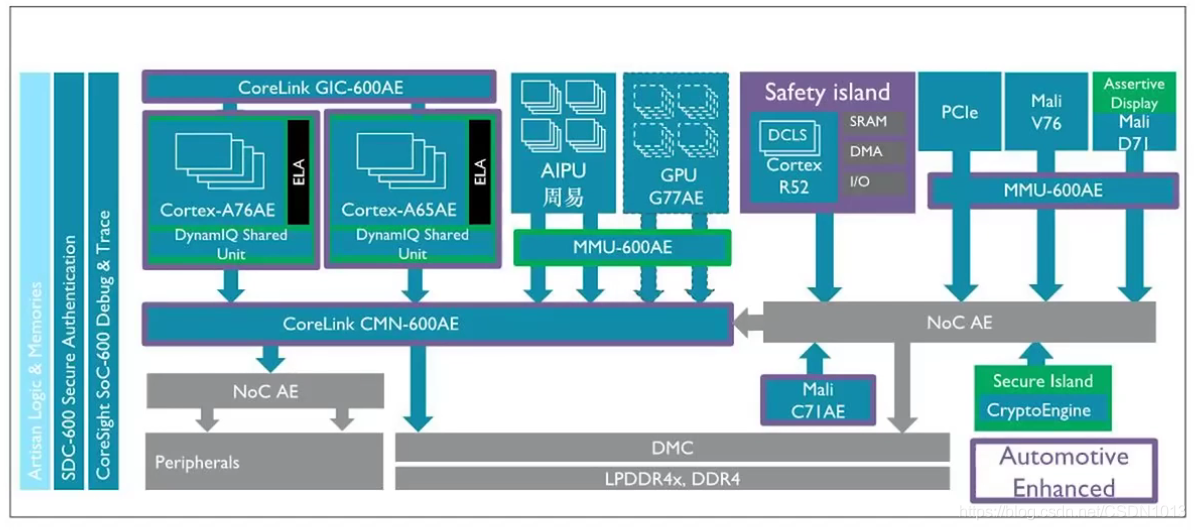
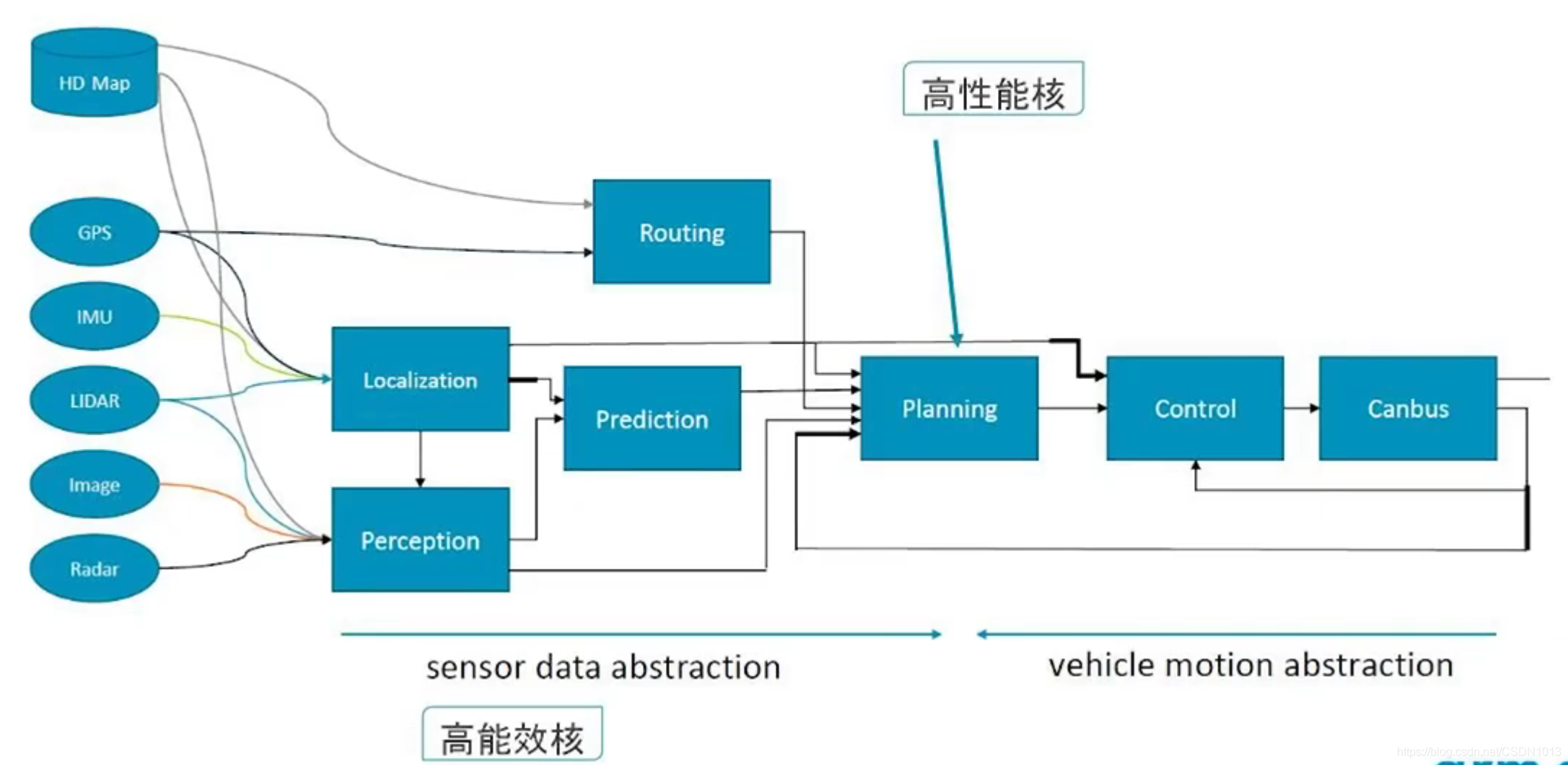
与信息娱乐域的最大不同:
- 更高的功能安全等级,需要做到ASIL-D。(两个ASIL-B可以合成一个ASIL-D)
- 场景覆盖比信息娱乐域更多,因为可能涉及到发动机或者车身控制
ARM对应的IP:
- Automotive Enhanced. A76AE, A65AE。多路的传感器数据输入并行处理,适合A65AE的应用。当数据处理完成后,需要同时处理最终结果,做决策,这是适合A76AE的应用场景。达到总体性能和效率的平衡
- A65: 本身为网络处理器而设计的。单核多线程,更高的并行处理能力。
- A76AE:单线程高性能的,适合运行大型App
- 总线,中断,GPU, MMU都做了Automotive Enhancement
实时性的要求和设计
- 操作的时间短
- 在确定时间内完成操作
Cortex-R52如何保证实时性呢?
- R52核心内部的TCM 紧耦合内存(Tightly-coupled memories )CPU流水线访问这个TCM可能只需要0~1个时钟周期。而且每个核心都有独占的TCM,既能保证访问周期确定又保证没有其他核心的竞争,性能不受影响。可以把中断代码或者常用代码放在片上TCM中,做到高性能且不受影响。

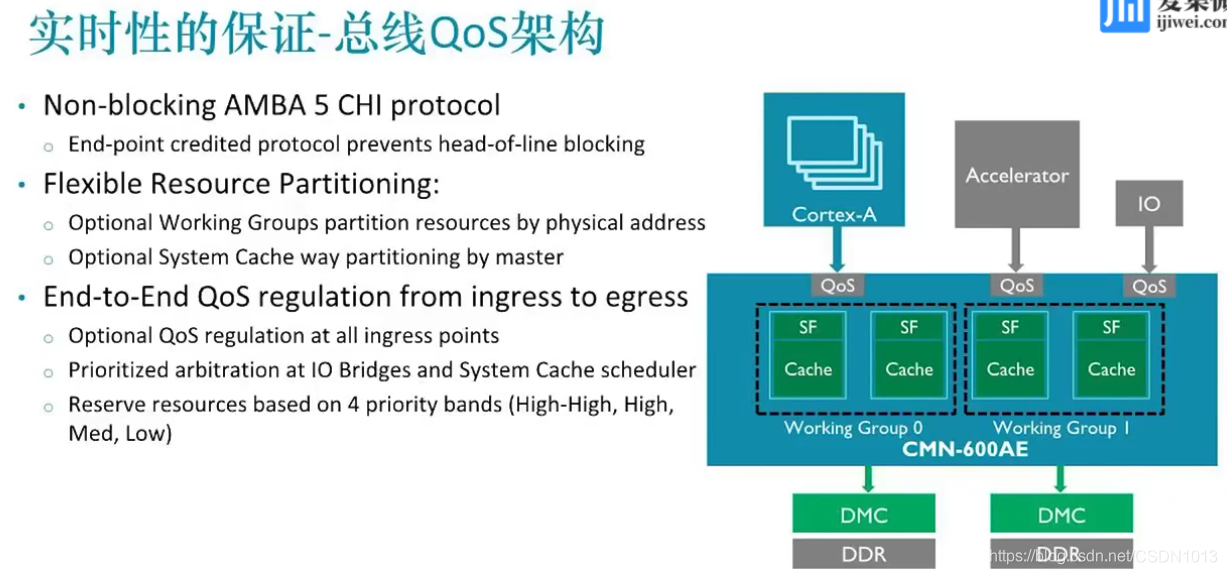
处理器外部的总线QoS架构
- 划分优先级。高优先级的任务在运行时 ,内部的所有资源(buffer,仲裁,总线的内存控制器等)需要保证最高优先级。这样在一定程度上能保证实时性
- 第一点存在的问题:head-of-line blocking. 如果一个低优先级的任务占用了资源,那么高优先级任务需要等待低优先级任务执行完成,增加了高优先级任务的执行不确定性。 ARM通过Token设计来解决这个问题。CMN600总线中所有的资源在第一次传输时,确保发出一个Token值,赋予一个优先级。资源需要有相应的Token值,才能进行优先访问。在任何访问之前,相当于已经通过预设的方式保留了资源访问的优先级。下一次一旦有高优先级任务进来,那么可以立刻进行传输或者中转。
- 片内的资源如Cache,进行等级划分。
处理器本身的实时性优化方法
- 使用大页表, 连续物理内存
- 绑定任务至特定核心,避免切换(减少开销)。使用轮询代替中断
- 关键代码和数据使用内部独有的SRAM(保证访问时间的确定性)
- 减少内核与用户空间切换(减少上下文切换的开销),使用用户态协议栈,文件系统和驱动
- 启用硬件支持的QoS(上文提到的总线的QoS机制)和相关机制
- 使用缓存分区,Cache Stashing等机制(把CPU即将需要处理的数据直接放到处理器中一级或二级缓存,这样CPU在轮询的时候可以直接在cache中获取数据)
- 使用多类型交织访问
中控典型应用场景
|
应用 |
分辨率/指标 |
Layer |
GPU |
|
IVI |
4K60 |
5-8 |
Mali-G77 MC4+显示模块 |
|
Cluster |
1080p60 |
4-5 |
Mali-G77 MC1+显示模块 |
|
HUD |
1080p60 |
4 |
Mali-G77 MC1+显示模块 |
|
SVM |
4K60 |
5-8 |
Mali-G77 MC4+显示模块+畸变矫正/G77 |

虽然架构设计中不是最新的ARM IP,但是还是具有非常好的参考性。
诸多细节还未完全理解,如有兴趣建议观看:http://zb.laoyaoba.com/watch/10196771

