使用Python实现ID3决策树中特征选择的先后顺序
一、实验目的
使用Python实现ID3决策树中特征选择的先后顺序。
二、实验原理
(1)信息熵
熵是对体系中混乱程度的度量。
熵越大则该体系越混乱。熵的计算公式如下所示:
l(xi)=-log2p(xi)
其中,xi表示第i个分类,p(xi)表示选择第i个分类的概率函数,其中 。
熵H(x)可表示为:
(2)条件熵
(3)信息增益
因此,决策树分类选特征应选信息增益最大的特征,也就是选择的特征能够使该系统从混乱到有序最快的特征。
三、Python包
(1)numpy
四、实验内容
(1)案例描述:通过头发和声音2个特征来判断学生的性别。使用Python实现求出其信息增益,并得出哪个特征优先被选择(注:数据处理使用程序计算)。
数据集如下:
注:数据集可直接用矩阵来描述:
[[‘长’, ‘粗’, ‘男’],
[‘短’, ‘粗’, ‘男’],
[‘短’, ‘粗’, ‘男’],
[‘长’, ‘细’, ‘女’],
[‘短’, ‘细’, ‘女’],
[‘短’, ‘粗’, ‘女’],
[‘长’, ‘粗’, ‘女’],
[‘长’, ‘粗’, ‘女’]]
代码:
import numpy as npimport math# 求出总熵def getData(pri_data): data = np.array(pri_data) boys = 0 girls = 0 for i in range(len(data)): if data[i][2] == '男': boys += 1 else: girls += 1 a = boys / len(data) total_shang = -(a) * math.log(a, 2) - (1 - a) * math.log((1 - a), 2) return total_shangdef empty1(pri_data): hair = [] #['长', '短', '短', '长', '短', '短', '长', '长'] voice = [] #['粗', '粗', '粗', '细', '细', '粗', '粗', '粗'] sex = [] #['男', '男', '男', '女', '女', '女', '女', '女'] for one in pri_data: hair.append(one[0]) voice.append(one[1]) sex.append(one[2]) cu_voive = voice.count('粗') #6 thin_voice = voice.count('细')#2 # 一维列表合并成多维列表 d = [] for i in range(len(hair)): for j in range(len(voice)): if i == j: for k in range(len(sex)): if j == k: t = [hair[i], voice[j], sex[k]] d.append(t) # print(d) a = d.count(['短', '粗', '男']) #2 b = d.count(['短', '粗', '女']) #1 c = d.count(['长', '粗', '男']) #1 e = d.count(['长', '粗', '女']) #2 f = d.count(['长', '细', '女']) #1 g = d.count(['短', '细', '女']) #1 #一维列表合并成二维列表 z=list(zip(voice,sex)) cu_woman =z.count(('粗','女')) cu_man = z.count(('粗','男')) num_v_h = (cu_woman + cu_man) return cu_voive, thin_voice, cu_woman, cu_man, num_v_hdef empty2(pri_data): hair = [] # ['长', '短', '短', '长', '短', '短', '长', '长'] voice = [] # ['粗', '粗', '粗', '细', '细', '粗', '粗', '粗'] sex = [] # ['男', '男', '男', '女', '女', '女', '女', '女'] for one in pri_data: hair.append(one[0]) voice.append(one[1]) sex.append(one[2]) # 一维列表合并成二维列表 k = list(zip(hair, sex)) long_man =k.count(('长','男')) long_woman = k.count(('长','女')) sum_hair1 = long_man + long_woman short_man = k.count(('短','男')) short_woman = k.count(('短','女')) sum_hair2 = short_man + short_woman sum_Hair = sum_hair1 + sum_hair2 return long_man, long_woman, sum_hair1,sum_hair2,sum_Hair,short_man,short_woman# 用声音作为优先选择特征求信息增益def xxx1(cu_voice,thin_voice,cu_woman,cu_man,num_v_h): voice_num=cu_voice+thin_voice A = -cu_voive/voice_num * (cu_woman/num_v_h) * np.log2(cu_woman/num_v_h) - \ cu_voive/voice_num * (cu_man/num_v_h) * np.log2(cu_man/num_v_h) sum_v = getData(pri_data) - A return sum_v# 用头发作为优先选择特征求信息增益def xxx2(long_man, long_woman, sum_hair,sum_hair2,sum_Hair,short_man,short_woman): B = -sum_hair/sum_Hair* (long_man/sum_hair) * np.log2(long_man/sum_hair) - \ sum_hair/sum_Hair * (long_woman/sum_hair) * np.log2(long_woman/sum_hair) - sum_hair2/sum_Hair * (short_man/sum_hair2) * np.log2(short_man/sum_hair2)\ - sum_hair2/sum_Hair* (short_woman/sum_hair2) * np.log2(short_woman/sum_hair2) sum_h = getData(pri_data) - B return sum_hif __name__ == "__main__": pri_data = [['长', '粗', '男'], ['短', '粗', '男'], ['短', '粗', '男'], ['长', '细', '女'], ['短', '细', '女'], ['短', '粗', '女'], ['长', '粗', '女'], ['长', '粗', '女']] total_shang=getData(pri_data) cu_voive, thin_voice, cu_woman, cu_man, num_v_h=empty1(pri_data) sum1 = xxx1(cu_voive, thin_voice, cu_woman, cu_man, num_v_h) print('用声音作为优先选择特征求信息增益:',sum1) long_man, long_woman, sum_hair1, sum_hair2, sum_Hair, short_man, short_woman=empty2(pri_data) sum2 = xxx2(long_man, long_woman, sum_hair1, sum_hair2, sum_Hair, short_man, short_woman) print('用头发作为优先选择特征求信息增益:',sum2) if sum1 > sum2: print("用声音作为优先选择特征求信息增益大") else: print("用头发作为优先选择特征求信息增益大")截图:
四、实验内容
(1)案例描述:通过天气、温度、湿度、是否有风4个特征来决策是否打球。使用Python实现求出其信息增益,并得出哪个特征优先被选择(注:数据处理使用程序计算,数据见data.xls)。
数据集如下: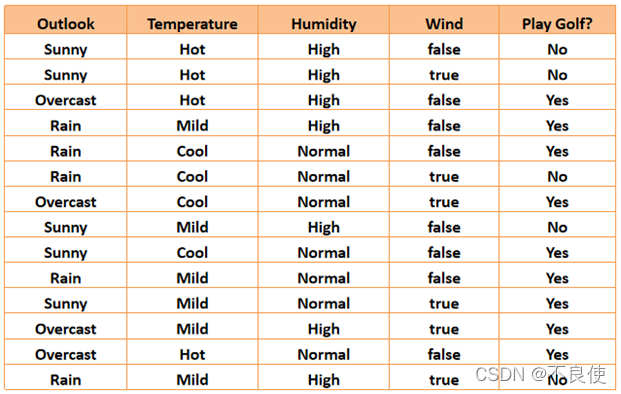
代码:
import xlrdimport numpy as npworkbook=xlrd.open_workbook("data.xls")sheet=workbook.sheet_by_name("Sheet1")row_count=sheet.nrowscol_count=sheet.ncolsdata_list=[]for i in range(1,row_count): data_list.append(sheet.row_values(i))play_golf_number=0no_play_golf_number=0total_count=0for i in data_list: if i[col_count-1]=="Yes": play_golf_number+=1 else: no_play_golf_number+=1 total_count+=1a=play_golf_number/total_count#求出总熵total_shang=-(a)*np.log2(a)-(1-a)*np.log2(1-a)print(total_shang)#求出各分熵,开始判别第一特征#1.根据天气b=(5/14)*((-2/5)*np.log2(2/5)-(3/5)*np.log2(3/5))+(5/14)*((-2/5)*np.log2(2/5)-(3/5)*np.log2(3/5))#2.根据温度c=(4/14)*((-1/2)*np.log2(1/2)-(1/2)*np.log2(1/2))+(4/14)*((-3/4)*np.log2(3/4)-(1/4)*np.log2(1/4))+(6/14)*((-2/3)*np.log2(2/3)-(1/3)*np.log2(1/3))#3.根据湿度d=(7/14)*((-3/7)*np.log2(3/7)-(4/7)*np.log2(4/7))+(7/14)*((-6/7)*np.log2(6/7)-(1/7)*np.log2(1/7))#4.根据风力e=(8/14)*((-6/8)*np.log2(6/8)-(2/8)*np.log2(2/8))+(6/14)*((-1/2)*np.log2(1/2)-(1/2)*np.log2(1/2))y1=1-by2=1-cy3=1-dy4=1-eshang_list1=[y1, y2, y3, y4]first_feature=min(shang_list1)if y1==first_feature: print("天气是第一特征")if y2 == first_feature: print("温度是第一特征")if y3==first_feature: print("湿度是第一特征")if y4==first_feature: print("风力是第一特征")#开始判别第二特征#1.根据天气f=(5/14)*((-2/5)*np.log2(2/5)-(3/5)*np.log2(3/5))+(5/14)*((-2/5)*np.log2(2/5)-(3/5)*np.log2(3/5))#2.根据湿度g=(7/14)*((-3/7)*np.log2(3/7)-(4/7)*np.log2(4/7))+(7/14)*((-6/7)*np.log2(6/7)-(1/7)*np.log2(1/7))#3.根据风力h=(8/14)*((-6/8)*np.log2(6/8)-(2/8)*np.log2(2/8))+(6/14)*((-1/2)*np.log2(1/2)-(1/2)*np.log2(1/2))y5=1-fy6=1-gy7=1-hshang_list2=[y5,y6,y7]second_feature=min(shang_list2)if y5==second_feature: print("天气是第二特征")if y6==second_feature: print("湿度是第二特征")if y7==second_feature: print("风力是第二特征")#开始判别第三特征#1.根据天气i=(3/11)*((-1/3)*np.log2(1/3)-(2/3)*np.log2(2/3))+(4/11)*((-1/2)*np.log2(1/2)-(1/2)*np.log2(1/2))#2.根据湿度j=(6/11)*((-1/2)*np.log2(1/2)-(1/2)*np.log2(1/2))+(5/11)*((-4/5)*np.log2(4/5)-(1/5)*np.log2(1/5))y8=1-iy9=1-jshang_list3=[y8,y9]third_feature=min(shang_list3)if y8==third_feature: print("天气是第三特征")if y9==third_feature: print("湿度是第三特征")print("天气是第四特征")
