XML简单学习
前言
本文是对XML语言的简单学习,适合后端开发者简单了解前端知识使用。
目录
一、什么是XML?
1.1、W3cSchool定义
1.2、HTML与XML的主要差异
二、XML的语法规则
2.1、基本语法规则
2.2、基本组成部分
2.2.1、文档声明
2.2.2、标签规则
2.2.3、CDATA区
2.2.4、XML约束
三、XML解析器
3.1、解析的定义:
3.2、JSoup解析器
3.3、Jsoup对象的使用
3.3.1、Jsoup:工具类
3.3.2、Document
3.3.3、Element:元素对象
3.4、快捷查询方式
3.4.1、Selector选择器
3.4. 2、Xpath
一、什么是XML?
1.1、W3cSchool定义
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 标签没有被预定义。您需要自行定义标签。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
为什么他又被称为可扩展语言呢?因为XML语言的标签都是自定义的,这个在代码的编写中就能体现。
之前我们学习过HTML,那么他和XML又有什么区别呢?
1.2、HTML与XML的主要差异
XML 不是 HTML 的替代。
XML 和 HTML 为不同的目的而设计:
XML 被设计为传输和存储数据,其焦点是数据的内容。
HTML 被设计用来显示数据,其焦点是数据的外观。
HTML 旨在显示信息,而 XML 旨在传输信息。
XML的语法相对来说较为严格,而HTML的语法相对较为松散
XML的标签是自定义的,而HTML的标签是预定义的
二、XML的语法规则
2.1、基本语法规则
1. xml文档的后缀名 .xml
2. xml第一行必须定义为文档声明
3. xml文档中有且仅有一个根标签
4. 属性值必须使用引号(单双都可)引起来
5. 标签必须正确关闭
6. xml标签名称区分大小写
一个简单的XML文档
zhangsan23male
lisi24female2.2、基本组成部分
2.2.1、文档声明
1. 格式:
2. 属性列表:
* version:版本号,必须的属性
* encoding:编码方式。告知解析引擎当前文档使用的字符集,默认值:ISO-8859-1
* standalone:是否独立
* 取值:
* yes:不依赖其他文件
* no:依赖其他文件
2.2.2、标签规则
标签元素名称自定义
自定义规则
* 名称可以包含字母、数字以及其他的字符
* 名称不能以数字或者标点符号开始
* 名称不能以字母 xml(或者 XML、Xml 等等)开始
* 名称不能包含空格
2.2.3、CDATA区
使用CDATA区:在该区域中的数据会被原样展示
格式
例如这行代码:
b && c>s) {} ]]> 效果: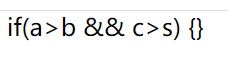
而如果我们不使用CDATA区:
if(a>b && c>s) {}不仅代码会报错,浏览器会直接无法解析
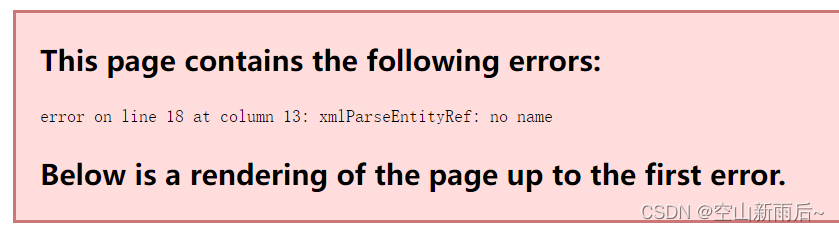
关于该语法的详细解释可以参考W3cSchool:XML CDATA (w3school.com.cn)
2.2.4、XML约束
约束的定义:规定XML文档的书写规则
约束的好处:
作为框架的使用者(开发者):
能够在XML中引入约束文档
能够简单的读懂约束文档
分类
1.DTD
用法
引入dtd文档到XML文档中
* 内部dtd:将约束规则定义在xml文档中
* 外部dtd:将约束的规则定义在外部的dtd文件中
* 本地:
* 网络:
代码实例:
dtd文件:
XML文档:
张三15男2. Schema
引入
1.填写xml文档的根元素
2.引入xsi前缀. xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
3.引入xsd文件命名空间. xsi:schemaLocation="http://www.baidu.cn/xml student.xsd"
4.为每一个xsd约束声明一个前缀,作为标识 xmlns="http://www.baidu.cn/xml"
代码实例:
xsd文件:
XML文档:
tom 18 male 三、XML解析器
3.1、解析的定义:
定义
操作XML文档,将文档中的数据读取到内存中
操作XML文档
1. 解析(读取):将文档中的数据读取到内存中
2. 写入:将内存中的数据保存到xml文档中。持久化的存储
* 解析xml的方式:
1. DOM:将标记语言文档一次性加载进内存,在内存中形成一颗dom树
* 优点:操作方便,可以对文档进行CRUD的所有操作
* 缺点:占内存
2. SAX:逐行读取,基于事件驱动的。一般用于移动操作系统
* 优点:不占内存。
* 缺点:只能读取,不能增删改
XML常见的解析器
1. JAXP:sun公司提供的解析器,支持dom和sax两种思想
2. DOM4J:一款非常优秀的解析器
3. Jsoup:jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。
4. PULL:Android操作系统内置的解析器,sax方式的。
3.2、JSoup解析器
基本的使用方法:
首先导入Jsoup jar包,
接着获取对应的Document对象,
用Document对象获取对应的标签的element元素对象
从而获取我们想要的数据
代码实例:
package Jsoup;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.File;import java.io.IOException;/ * @author wang * @version 1.0 * @packageName Jsoup * @className JsoupDemo1 * @date 2022/3/4 14:55 * @Description Jsoup快速入门 */public class JsoupDemo1 { public static void main(String[] args) throws IOException { //获取document对象,根据XML文档获取 //获取student.xml的路径对象 String path = JsoupDemo1.class.getClassLoader().getResource("student.xml").getPath(); //解析XML文档,加载文档进内存,获取DOM树 File file = new File(path); Document document = Jsoup.parse(file, "utf-8"); //获取元素对象 Elements elements = document.getElementsByTag("name"); System.out.println(elements.size()); //2 Element element = elements.get(0); String name = element.text(); System.out.println(name); //张三 }}3.3、Jsoup对象的使用
3.3.1、Jsoup:工具类
可以解析html或xml文档,返回Document
* parse:解析html或xml文档,返回Document方法:
* parse(File in, String charsetName):解析xml或html文件的。
* parse(String html):解析xml或html字符串
* parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象
代码演示:
package Jsoup;import com.sun.jndi.toolkit.url.UrlUtil;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.File;import java.io.IOException;import java.net.URL;/ * @author wang * @version 1.0 * @packageName Jsoup * @className JsoupDemo2 * @date 2022/3/4 14:55 * @Description Jsoup对象演示 */public class JsoupDemo2 { public static void main(String[] args) throws IOException { //获取document对象,根据XML文档获取 //获取student.xml的路径对象 String path = JsoupDemo2.class.getClassLoader().getResource("student.xml").getPath(); //解析XML文档,加载文档进内存,获取DOM树 File file = new File(path); //* parse(File in, String charsetName):解析xml或html文件的。 // Document document = Jsoup.parse(file, "utf-8"); //System.out.println(document); //* parse(String html):解析xml或html字符串 /* String str = "\n" + "\n" + " \n" + " \t\n" + " \t\ttom\n" + " \t\t18\n" + " \t\tmale\n" + " \t\n" + "\n" + "\t\n" + "\t\tjerry\n" + "\t\t13\n" + "\t\tfemale\n" + "\t\n" + "\t\t \n" + " "; Document document = Jsoup.parse(str); System.out.println(document);*/ //* parse(URL url, int timeoutMillis):通过网络路径获取指定的html或xml的文档对象 URL url = new URL("http://manmanbuy.com/p_685922.aspx"); Document document = Jsoup.parse(url, 10000); System.out.println(document); }}3.3.2、Document
文档对象,代表内存中的DOM树
* 获取Element对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
代码演示:
package Jsoup;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.File;import java.io.IOException;import java.net.URL;/ * @author wang * @version 1.0 * @packageName Jsoup * @className JsoupDemo3 * @date 2022/3/4 14:55 * @Description Jsoup document对象和element对象演示 */public class JsoupDemo3 { public static void main(String[] args) throws IOException { //获取document对象,根据XML文档获取// * parse(String html):解析xml或html字符串 String str = "\n" + "\n" + " \n" + " \t\n" + " \t\ttom\n" + " \t\t18\n" + " \t\tmale\n" + " \t\n" + "\n" + "\t\n" + "\t\tjerry\n" + "\t\t13\n" + "\t\tfemale\n" + "\t\n" + "\t\t \n" + " "; Document document = Jsoup.parse(str);// System.out.println(document); //* getElementById(String id):根据id属性值获取唯一的element对象 Element element = document.getElementById("001"); System.out.println(element); //* getElementsByTag(String tagName):根据标签名称获取元素对象集合 System.out.println("==========="); Elements elements = document.getElementsByTag("name"); System.out.println(elements);// * getElementsByAttribute(String key):根据属性名称获取元素对象集合 System.out.println("=============="); Elements elements1 = document.getElementsByAttribute("id"); System.out.println(elements1);// * getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合 System.out.println("==========="); Elements elements2 = document.getElementsByAttributeValue("id", "002"); System.out.println(elements2); }}3.3.3、Element:元素对象
1. 获取子元素对象
* getElementById(String id):根据id属性值获取唯一的element对象
* getElementsByTag(String tagName):根据标签名称获取元素对象集合
* getElementsByAttribute(String key):根据属性名称获取元素对象集合
* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合
2. 获取属性值
* String attr(String key):根据属性名称获取属性值
3. 获取文本内容
* String text():获取文本内容
* String html():获取标签体的所有内容(包括字标签的字符串内容)
代码演示:
package Jsoup;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.File;import java.io.IOException;/ * @author wang * @version 1.0 * @packageName Jsoup * @className JsoupDemo3 * @date 2022/3/4 14:55 * @Description Jsoup document对象和element对象演示 */public class JsoupDemo4 { public static void main(String[] args) throws IOException { //获取document对象,根据XML文档获取 String path = JsoupDemo4.class.getClassLoader().getResource("student.xml").getPath(); Document document = Jsoup.parse(new File(path), "utf-8"); //* getElementById(String id):根据id属性值获取唯一的element对象 Element number = document.getElementById("002"); System.out.println(number); System.out.println("========="); //* getElementsByTag(String tagName):根据标签名称获取元素对象集合 Elements names = document.getElementsByTag("name"); System.out.println(names.get(0)); System.out.println("========="); //* getElementsByAttribute(String key):根据属性名称获取元素对象集合 Elements elements = document.getElementsByAttribute("id"); System.out.println(elements); System.out.println("========"); //* getElementsByAttributeValue(String key, String value):根据对应的属性名和属性值获取元素对象集合 Elements id = document.getElementsByAttributeValue("id", "003"); System.out.println(id); System.out.println("======="); //2. 获取属性值 //* String attr(String key):根据属性名称获取属性值 String value = elements.attr("id"); System.out.println(value); System.out.println("======="); /*3. 获取文本内容 * String text():获取文本内容 * String html():获取标签体的所有内容(包括字标签的字符串内容)*/ Elements elements1 = document.getElementsByAttributeValue("id", "001"); String text = elements1.text(); System.out.println("文本内容" + text); String html = elements1.html(); System.out.println("标签内容" + html); }}3.4、快捷查询方式
3.4.1、Selector选择器
* 语法:参考Selector类中定义的语法
* 使用的方法:Elements select(String cssQuery)
代码
package Jsoup;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import java.io.File;import java.io.IOException;/ * @author wang * @version 1.0 * @packageName Jsoup * @className JsoupDemo3 * @date 2022/3/4 14:55 * @Description Jsoup selector选择器 */public class JsoupDemo5 { public static void main(String[] args) throws IOException { //获取document对象,根据XML文档获取 String path = JsoupDemo5.class.getClassLoader().getResource("student.xml").getPath(); Document document = Jsoup.parse(new File(path), "utf-8");// 1.查询name标签 Elements name = document.select("name");// System.out.println(name);// 2.查询ID值为001的元素 Elements select = document.select("#001");// System.out.println(select);// 3.获取student标签并且number属性值为heima_0001的age子标签 //获取student标签并且number属性值为heima_0001 Elements select1 = document.select("student[number=\"heima_0001\"]");// System.out.println(select1);//获取student标签并且number属性值为heima_0001的age子标签 Elements select2 = document.select("student[number=\"heima_0001\"] > age"); System.out.println(select2); }}3.4. 2、Xpath
XPath:XPath即为XML路径语言,它是一种用来确定XML(标准通用标记语言的子集)文档中某部分位置的语言
* 使用Jsoup的Xpath需要额外导入jar包。
* 查询w3cshool参考手册,使用xpath的语法完成查询
* 代码:
package Jsoup;import cn.wanghaomiao.xpath.exception.XpathSyntaxErrorException;import cn.wanghaomiao.xpath.model.JXDocument;import cn.wanghaomiao.xpath.model.JXNode;import org.jsoup.Jsoup;import org.jsoup.nodes.Document;import org.jsoup.select.Elements;import java.io.File;import java.io.IOException;import java.util.List;/ * @author wang * @version 1.0 * @packageName Jsoup * @className JsoupDemo3 * @date 2022/3/4 14:55 * @Description Jsoup Xpath选择器 */public class JsoupDemo6 { public static void main(String[] args) throws IOException, XpathSyntaxErrorException { //获取document对象,根据XML文档获取 String path = JsoupDemo6.class.getClassLoader().getResource("student.xml").getPath(); Document document = Jsoup.parse(new File(path), "utf-8");// 1.根据document对象创建JXdocument对象 JXDocument jxDocument = new JXDocument(document); //查询所有student标签 // //:从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置(取子孙节点)。 List jxNodes = jxDocument.selN("//student"); for (JXNode jxNode : jxNodes) { System.out.println(jxNode); } System.out.println("==========================="); //查询所有student标签下的name标签 // /:从根节点选取(取子节点)。 List jxNodes1 = jxDocument.selN("//student/name"); for (JXNode jxNode : jxNodes1) { System.out.println(jxNode); } System.out.println("==========================="); //查询所有student标签下的带有ID属性的name标签 // @:选取属性。 // 例如://title[@lang] 选取所有拥有名为 lang 的属性的 title 元素。 List jxNodes2 = jxDocument.selN("//student/name[@id]"); for (JXNode jxNode : jxNodes2) { System.out.println(jxNode); } System.out.println("==========================="); //查询所有student标签下的带有ID属性的name标签,并且ID的属性值为002 // 例如://title[@lang='eng'] 选取所有 title 元素,且这些元素拥有值为 eng 的 lang 属性。 List jxNodes3 = jxDocument.selN("//student/name[@id= '002']"); for (JXNode jxNode : jxNodes3) { System.out.println(jxNode); } }}
