高性能mysql读书笔记四-MySQL高级特性
文章目录
- mysql高级特性
mysql高级特性
1. 分区表
1.1 分区表概念
分区表就是按照某种规则将一个大表分成若干个小表,规则可能是某一个列的值分区分,或者涉及某个列的表达式。这样大量的数据被分散到不同表中,数据量变小查询性能自然变高。
使用分区表的好处
- 表数据非常大或者表数据有明显的冷热数据之分。
- 分区表的数据更容易维护,比如批量删除 可以清除整个分区形式并对独立分区进行优化、检查、修复。
- 分区表的数据可以维护在不同的物理设备,水平扩展性好。
- 避免InnoDB的单索引互斥访问,减少锁竞争。
使用分区表的限制
-
所有分区必须使用相同的存储引擎。
-
每张表的分区数有限,最大分区数目不能超过1024。
-
分区表达式只能是整数或者返回整数的表达式(函数)。
-
分区所用的字段,必须是唯一索引或者主键(主键也是唯一索引)。
-
无法使用外键、全文索引。
1.2 分区表类型
查看mysql是否支持分区
#5.6版本SHOW VARIABLES LIKE '%partition%'# 5.6版本之后show plugins;
-
RANGE分区:基于属于一个给定连续区间的列值,把多行分配给分区。
-
LIST分区:类似于按RANGE分区,区别在于LIST分区是基于列值匹配一个离散值集合中的某个值来进行选择。
-
HASH分区:基于用户定义的表达式的返回值来进行选择的分区,该表达式使用将要插入到表中的这些行的列值进行计算。这个函数可以包含MySQL 中有效的、产生非负整数值的任何表达式。
-
KEY分区:类似于按HASH分区,区别在于KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
1.3 分区表使用
range分区类型
创建分区表
-- 创建表DROP TABLE IF EXISTS `sales`;CREATE TABLE `sales` ( `id` int(11) NOT NULL, `money` decimal(11,2) NOT NULL, `order_date` date NOT NULL, PRIMARY KEY (`id`,`order_date`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY RANGE (YEAR(order_date))(PARTITION p_2020 VALUES LESS THAN (2021) ENGINE = InnoDB, PARTITION p_2021 VALUES LESS THAN (2022) ENGINE = InnoDB, PARTITION p_max VALUES LESS THAN MAXVALUE ENGINE = InnoDB);使用日期范围range 进行分区。,order_date 为分区字段 则必须包含在主键字段内,否则会报如下错误
A PRIMARY KEY must include all columns in the table's partitioning function
对于 MySQL 分区表,无法从数据库层面保证非分区列在表级别的唯一性,只能确保其在分区内的唯一性。
插入数据
-- 插入数据 INSERT INTO `sales` (`id`, `money`, `order_date`) VALUES('1','123.34','2021-12-01');INSERT INTO `sales` (`id`, `money`, `order_date`) VALUES('2','12132.33','2022-01-15');INSERT INTO `sales` (`id`, `money`, `order_date`) VALUES('3','32432.31','2020-03-22');查询分区统计
-- 查询数据分区分布SELECT PARTITION_NAME AS "分区",TABLE_ROWS AS "行数"FROM information_schema.partitions WHERE table_schema = "cds-temp" AND table_name = "sales"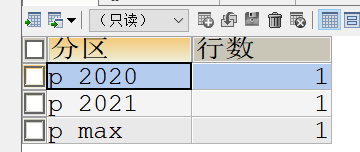
list分区类型
创建分区表
-- 创建表DROP TABLE IF EXISTS `sales`;CREATE TABLE `sales` ( `id` INT(11) NOT NULL, `money` DECIMAL(11,2) NOT NULL, `score` INT(2), `order_date` DATE NOT NULL, PRIMARY KEY (`id`,`score`)) ENGINE=INNODB DEFAULT CHARSET=utf8PARTITION BY LIST(score)( PARTITION pEven VALUES IN (1,3,5,7,9), PARTITION pOdd VALUES IN (2,4,6,8,10))插入数据
-- 插入数据INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('1','123.34',1,'2021-12-01');INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('2','12132.33',2,'2022-01-15');INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('3','32432.31',3,'2020-03-22');INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('4','32432.31',4,'2020-03-22');查询分区统计
-- 查询数据分区分布SELECT PARTITION_NAME AS "分区",TABLE_ROWS AS "行数"FROM information_schema.partitions WHERE table_schema = "cds-temp" AND table_name = "sales"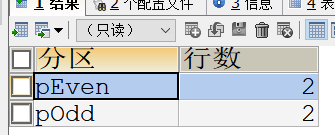
HASH分区类型
创建分区表
使用hash函数进行分区,分区数为3 分为p0、p1、p2三个分区。
DROP TABLE IF EXISTS `sales`;CREATE TABLE `sales` ( `id` INT(11) NOT NULL, `money` DECIMAL(11,2) NOT NULL, `score` INT(2) NOT NULL, `order_date` DATE NOT NULL, PRIMARY KEY (`id`,`score`)) ENGINE=INNODB DEFAULT CHARSET=utf8PARTITION BY HASH(score) PARTITIONS 3;插入数据
-- 插入数据INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('1','123.34',1,'2021-12-01');INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('2','12132.33',2,'2022-01-15');INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('3','32432.31',3,'2020-03-22');INSERT INTO `sales` (`id`, `money`, `score`,`order_date`) VALUES('4','32432.31',4,'2020-03-22');查询分区统计
-- 查询数据分区分布SELECT PARTITION_NAME AS "分区",TABLE_ROWS AS "行数"FROM information_schema.partitions WHERE table_schema = "cds-temp" AND table_name = "sales"
key分区类型
创建分区表
-- 创建表DROP TABLE IF EXISTS `sales`;CREATE TABLE `sales` ( `id` int(11) NOT NULL, `name` varchar(10) NOT NULL, `money` decimal(11,2) NOT NULL, `order_date` date NOT NULL, PRIMARY KEY (`id`,`name`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 PARTITION BY key (name) PARTITIONS 3;插入数据
-- 插入数据 INSERT INTO `sales` (`id`,`name`, `money`, `order_date`) VALUES('1','汽车','123.34','2021-12-01');INSERT INTO `sales` (`id`,`name`, `money`, `order_date`) VALUES('2','手机','12132.33','2022-01-15');INSERT INTO `sales` (`id`,`name`, `money`, `order_date`) VALUES('3','相机','32432.31','2020-03-22');查询分区统计
-- 查询数据分区分布SELECT PARTITION_NAME AS "分区",TABLE_ROWS AS "行数"FROM information_schema.partitions WHERE table_schema = "cds-temp" AND table_name = "sales"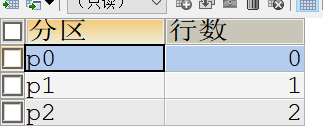
1.4 分区表原理
分区表是多个底层相关表组成,mysql分区后每个分区成了独立的文件,虽然从逻辑上还是一张表其实已经分成了多张独立的表,从“information_schema.INNODB_SYS_TABLES”系统表可以看到每个分区都存在独立的TABLE_ID, 由于Innodb数据和索引都是保存在".ibd"文件当中(从INNODB_SYS_INDEXES系统表中也可以得到每个索引都是对应各自的分区(primary key和unique也不例外)),所以分区表的索引也是随着各个分区单独存储。
-- 查看创建表的分区情况SELECT * FROM information_schema.INNODB_SYS_TABLES WHERE NAME LIKE "%sales%"
- select:查询一个分区表,分区层先打开并锁住所有底层表,优化器先过滤掉部分分区,然后再调用对应的存储引擎访问各个分区的数据。
- insert:写入记录,分区层先打开并锁住所有底层,确定某个分区插入数据,释放锁并将记录写入对应的分区。
- delete:删除记录,分区层先打开并锁住所有底层,确定数据对应的分区并删除对应分区数据。
- update:更新记录,分区层先打开并锁住所有底层,确定需要更新的数据在哪个分区并取出更新,再判断更新后数据需要放在哪个分区并写入,如果更新后不再同一分区还需要将原分区数据删除。
1.5 分区表使用
使用分区表的前提是数据量特别大,在数据量特别巨大的时候,比如10亿条数据,使用索引会产生入下问题:
大数据量的问题
- 创建和维护索引的成本比较高。
- 使用索引如果是覆盖索引还好不用回表。回表的可能会产生大量的随机IO。
分区表的两种策略
- 分区表的全表扫描
使用简单分区方式存放表,不使用其他索引,则该策略假定不依赖于内存数据,则需要控制分区表的数量限制在很小的范围内。
- 分离冷热数据,使用索引
数据有明显的’冷热’数据之分,只有热数据被频繁访问,其他数据几乎不会被访问,热数据存放到一个分区中且该热数据尽可能的使用内存,大部分查询在该热点分区中,也可以正常使用索引。
分区表的问题
-
null值问题
Mysql允许分区键值为NULL,分区键可能是一个字段或者一个用户定义的表达式。一般情况下,Mysql在分区的时候会把NULL值当作零值或者一个最小值进行处理。
如果分区键所在列没有notnull约束。
range分区表,那么null行将被保存在范围最小的分区。
list分区表,那么null行将被保存到list为0的分区。
HASH和KEY分区,任何产生NULL值的表达式mysql都视同它的返回值为0。
为了避免这种情况的产生,建议分区键设置成NOT NULL。或者设置一个p_ null的“无用”分区用来存放一些null值字段。
null值问题 此处笔者存疑,因为上述分区例子中,分区字段列均为主键,说明其不存在null值字段,即时使用分区表达式也没有输出null的情况
-
分区列和索引列不匹配
索引列和分区列不匹配是指你的sql语句where条件的包含带有索引的列但不包含分区列的情况,这时候不管分区列有没有索引都不会进行分区过滤。
-
选择分区成本很高
对应范围分区和list分区,所有的curd操作都需要进行入下
符合条件的行属于那些分区,对于查找来说可能需要扫描所有分区才能判断出结果,所以分区数不宜设置的过多,小于100个分区是笔者的建议。HASH和KEY分区不会有该情况。 -
分区查找锁表成本
curd访问分区表时都会出现锁住所有底层表的情况,这是一个硬性开销。该情况在分区过滤之前(所以不能使用分区过滤的形式减少开销),同时也与分区类型无关。
-
维护分区成本
就像创建索引能提高查询效率,但也增加了索引数据维护的开销,分区也有对应的维护成本,对于频繁的删除或者修改分区会产生一定的性能损耗。
1.6 分区查询
正常使用分区过滤
-- where条件只有带有分区列才能进行分区过滤EXPLAIN PARTITIONS SELECT * FROM sales WHERE order_date > "2022-01-01" 
-- 分区表作为关联表的第二张表且关联条件是分区键,查找也是能过来分区的EXPLAIN [ PARTITIONS ] SELECT * FROM commodity JOIN sales commodity.date = sales.order_date WHERE order_date > "2022-01-01" 不能使用分区过滤情况
-- mysql只有在查询条件中分区列本身进行比较 才能过滤分区-- 如下的使用列的表达式进行筛选 则无法过滤分区,会扫描所有分区EXPLAIN PARTITIONS SELECT * FROM sales WHERE order_date > YEAR("2022-01-01")
1.7 合并表
合并表和分区表类似,区别在于分区表时逻辑概念,我们无法直接访问底层表,但是合并表的所有字表都是真实存在的,只是通过使用语言将两张结构一致的表合并在一起处理。
DROP TABLE IF EXISTS `user_one`;CREATE TABLE `user_one` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=MyISAM AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;DROP TABLE IF EXISTS `user_two`;CREATE TABLE `user_two` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(50) DEFAULT NULL COMMENT '姓名', PRIMARY KEY (`id`)) ENGINE=MyISAM AUTO_INCREMENT=2 DEFAULT CHARSET=utf8;-- 插入数据INSERT INTO `user_one`(`id`,`name`) VALUES (1,'张三');INSERT INTO `user_two`(`id`,`name`) VALUES (1,'李四');-- union 必须是多个表结构一致且两个表引擎必须为MyISAM ---- 合并表DROP TABLE IF EXISTS `user_mrg`;CREATE TABLE `user_mrg` ( `id` INT(11) NOT NULL AUTO_INCREMENT , `name` VARCHAR(50) DEFAULT NULL, PRIMARY KEY (`id`)) ENGINE=MERGE UNION = (user_one,user_two) INSERT_METHOD LAST;INSERT INTO user_mrg() VALUE(NULL,"王五");SELECT * FROM user_mrg
合并表user_mrg与user_one和user_two表结构定义相同,但是主键出现了重复,说明虽然合并表结构要与子表一致,但是却不受主键限制(有点匪夷所思)。
INSERT_METHOD 设置插入数据时插入到合并表中的哪个字表中,first 插入到第一张表,last 插入数据到最后一张表
2. 视图
2.1 视图概念
MySQL 视图(View)是一种虚拟存在的表,数据库中只存放了视图的定义不存放数据,数据存放在定义视图查询涉及的真实表中。使用视图查询数据时,数据库会从真实表中取出对应的数据。
好处
简单性,简化用户对数据的理解和操作。对于经常查询的sql可以创建视图,简化复杂的sql操作。
安全性,视图可以筛选用户需要的列数据而隐藏用户不需要的列,变向的进行了简单的权限过滤。
相关语句
-- 创建视图CREATE VIEW [(列名 [, ...n])]AS SELECT语句-- 修改视图ALTER VIEW [( [, ...n])]AS SELECT语句 -- 删除视图DROP VIEW 2.2 视图原理
-- 创建视图CREATE VIEW sales_view (money,order_date)AS SELECT money,order_date FROM sales WHERE money >500 -- 查询视图SELECT * FROM sales_view WHERE order_date >"2020-05-01";mysql中实现视图的方式有两种方式。以上述视图例子为例
- 合并算法:所谓合并算法将视图中的查询条件和查询视图追加的条件进行合并转换为完整的sql进行执行,合并算法性能较好,优化器也能对其进行优化,所以此处推荐尽量使用合并算法。上述视图查询使用合并算法
-- 使用合并算法实现视图SELECT money, order_date FROM sales WHERE money > 500 -- 原视图查询条件 AND order_date > "2020-05-01" ; -- 查询创建视图 新的查询条件- 临时表算法:顾名思义,创建视图即为创建一张临时表将视图查询的数据存储到临时表中。基于视图查询操作就对临时表进行查询。
-- 使用临时表实现视图CREATE TEMPORARY TABLE sale_tmp AS SELECT money, order_date FROM sales WHERE money > 500 SELECT * FROM sale_tmp WHERE order_date >"2020-05-01";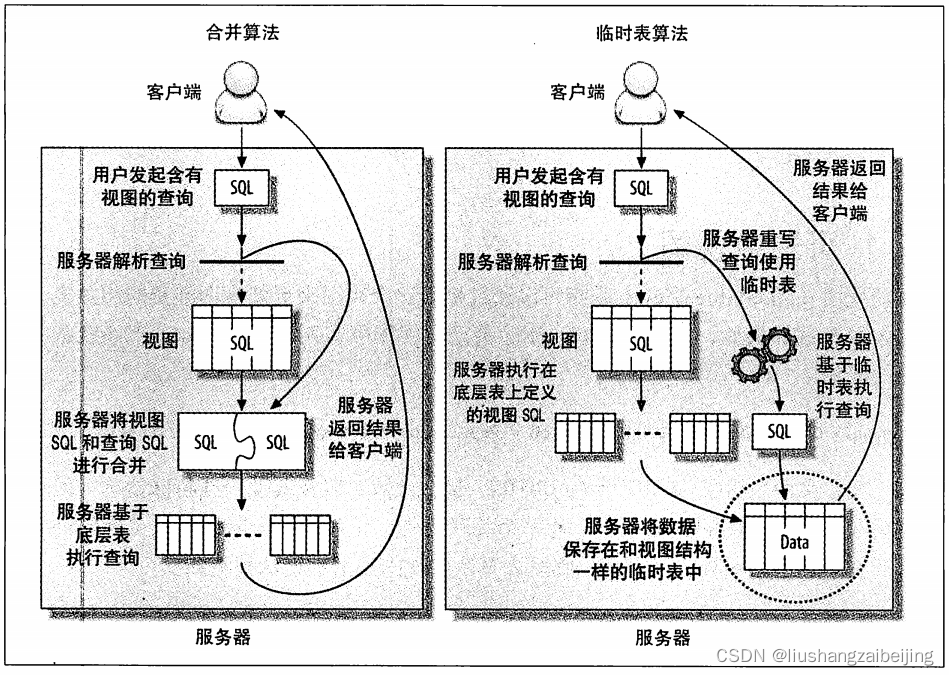
无法使用合并算法情况
group by、distinct,聚合函数、union、子查询等无法建立原表和视图表1对1映射场景 都会采用临时表形式进行视图实现。使用explain 分析视图 select_type 为DERIVED即使用临时表。
EXPLAIN SELECT * FROM {view_name}3. 存储代码
mysql的存储代码有四种类型
- 触发器:在 insert/update/delete 之前或之后,触发并执行触发器中定义的SQL语句
- 事件:在MySQL 5.1中新增了一个特色功能事件调度器(Event Scheduler),简称事件。它可以作为定时任务调度器。
- 存储函数:MySQL存储函数(自定义函数),函数一般用于计算和返回一个值,可以将经常需要使用的计算或功能写成一个函数。
- 存储过程:特定功能的SQL 语句集经编译后存储在数据库中,用户通过指定存储过程的名字并给出参数来执行它。
好处
- 存储代码在服务内部执行会节省网络带宽降低网络延迟
- 存储代码可重复使用,同时对于存储过程/函数,mysql会缓存其对应的执行计划,一次编译多次执行。
- 将程序开发和和DBA职能分开,专人专职。
缺陷
-
存储代码功能依赖的函数较少,适于简单逻辑编写,灵活复杂的逻辑还需要依赖应用程序。
-
存储代码可读性,可维护性差,没有相对完善的开发和调试工具(上百行的存储代码你维护一下试试)。
-
存储代码没有完备的异常处理机制,一个小错误可能拖死服务。
3.1 触发器
创建触发器
DELIMITER $CREATE TRIGGER 触发器名称BEFORE|AFTER INSERT|UPDATE|DELETEON 表名[FOR EACH ROW] -- 行级触发器BEGIN 触发器要执行的功能;END$DELIMITER ;场景:新增(删除、修改)用户(user)同时添加日志记录(user_log)
DELIMITER $CREATE TRIGGER user_log_triggerAFTER INSERTON `user`FOR EACH ROWBEGIN INSERT INTO `user_log` VALUE(NULL,"add","插入用户数据");END$DELIMITER ;-- 插入数据INSERT INTO `user`(`id`,`cust_no`,`first_name`,`last_name`,`alias`,`descption`,`birthday`) VALUES (20,'T000020','周杰伦','周杰伦','zjl','1983年9月20日出生于台湾省台',"1983-01-10");
3.2 事件
-- 查看定时策略是否开启show variables like '%event_schedu%';-- 开启定时策略:set global event_scheduler=1;CREATE[DEFINER={user | CURRENT_USER}] -- 权限控制 只有在这里声明用户才可以使用该事件EVENT [IF NOT EXISTS] event_name ON SCHEDULE schedule[ON COMPLETION [NOT] PRESERVE][ENABLE | DISABLE | DISABLE ON SLAVE][COMMENT 'comment']DO 事件要执行的功能;| 子句 | 说明 |
|---|---|
| DEFINER | 可选,用于定义事件执行时检查权限的用户 |
| IF NOT EXISTS | 可选项,用于判断要创建的事件是否存在 |
| EVENT event_name | 必选,用于指定事件名,event_name的最大长度为64个字符,如果为指定event_name,则默认为当前的MySQL用户名(不区分大小写) |
| ON SCHEDULE schedule | 必选,用于定义执行的时间和时间间隔 |
| ON COMPLETION [NOT] PRESERVE | 可选,用于定义事件是否循环执行,即是一次执行还是永久执行,默认为一次执行,即 NOT PRESERVE |
| ENABLE | DISABLE | DISABLE ON SLAVE | 可选项,用于指定事件的一种属性。其中,关键字ENABLE表示该事件是活动的,也就是调度器检查事件是否必选调用;关键字DISABLE表示该事件是关闭的,也就是事件的声明存储到目录中,但是调度器不会检查它是否应该调用;关键字DISABLE ON SLAVE表示事件在从机中是关闭的。如果不指定这三个选择中的任意一个,则在一个事件创建之后,它立即变为活动的。 |
| COMMENT ‘comment’ | 可选,用于定义事件的注释 |
| DO event_body | 必选,用于指定事件启动时所要执行的代码。可以是任何有效的SQL语句、存储过程或者一个计划执行的事件。如果包含多条语句,可以使用BEGIN…END复合结构 |
在ON SCHEDULE子句中,参数schedule的值为一个AS子句,用于指定事件在某个时刻发生,其语法格式如下:
AT timestamp [+ INTERVAL interval] ... | EVERY interval [STARTS timestamp [+ INTERVAL interval] ...] [ENDS timestamp [+ INTERVAL interval] ...]参数说明:
(1)timestamp:表示一个具体的时间点,后面加上一个时间间隔,表示在这个时间间隔后事件发生。
(2)every子句:用于表示事件在指定时间区间内每隔多长时间发生一次,其中 STARTS子句用于指定开始时间;ENDS子句用于指定结束时间。
(3)interval:表示一个从现在开始的时间,其值由一个数值和单位构成。例如,使用“4 WEEK”表示4周;使用“‘1:10’ HOUR_MINUTE”表示1小时10分钟。间隔的距离用DATE_ADD()函数来支配。
interval参数值的语法格式如下:
quantity {YEAR | QUARTER | MONTH | DAY | HOUR | MINUTE |WEEK | SECOND | YEAR_MONTH | DAY_HOUR | DAY_MINUTE |DAY_SECOND | HOUR_MINUTE | HOUR_SECOND | MINUTE_SECOND}创建事件
-- 每隔1秒 调用事件添加用户日志CREATE EVENT `user_log_event` ON SCHEDULE EVERY 1 SECOND ON COMPLETION PRESERVE ENABLEDO INSERT INTO `user_log` VALUE (NULL,"time_task","定时任务触发添加用户操作日志");
3.3 存储过程
- 增强SQL语言的功能和灵活性
- 存储过程创建后可以多次调用
- 存储过程执行速度快,存储过程一次编写后会将优化后的执行计划进行存储,每次不必进行优化直接执行。
-- 创建存储过程CREATE PROCEDURE 存储过程名(IN|OUT|INOUT 参数名 参数类型,...) -- IN输入参数 OUT输出参数 INOUT输入输出[characteristics ...] -- characteristics 表示创建存储过程时指定的对存储过程的约束条件BEGIN 存储过程体 END| 参数 | 说明 |
|---|---|
| LANGUAGE SQL | 存储过程的实体是由SQL语句组成 |
| [NOT] DETERMINISTIC | 存储过程执行结果是否确定,所谓确定:相同的输入会得到输出 |
| CONTAINS SQL NO SQL READS SQL DATA MODIFIES SQL DATA |
指定子程序使用SQL语句 CONTAINS SQL:包含的SQL语句是不进行读写的SQL语句 NO SQL:不包含SQL语句 READS SQL DATA:子程序包含读请求 MODIFIES SQL DATA:子程序包含写请求 |
| SQL SECURITY{ DEFINER | INVOKER} | 执行存储过程的权限。DEFINER:存储过程的创建者才有权调用,默认值 INVOKER:拥有当前存储过程访问权限的用户均有权调用。 |
| COMMENT ‘string’ | 注释信息,存储过程描述 |
DELIMITER $-- 创建储存过程 中运行 CREATE PROCEDURE sale_money_Procedure(IN s_money DECIMAL(11,2),OUT s_date DATE,INOUT s_num INT) BEGIN IF s_money IS NULL THEN SELECT MAX(order_date) FROM sales INTO s_date; ELSE SELECT MAX(order_date) FROM sales WHERE money > s_money INTO s_date; SET s_num = s_num * 10;END IF; END$DELIMITER ;-- 调用存储过程SET @s_num=7; CALL sale_money_Procedure(200.00,@max_order_date,@s_num); SELECT @max_order_date,@s_num;
3.4 存储函数
MySQL存储函数,函数一般用于计算和返回一个值,可以将经常需要使用的计算或功能写成一个函数。
CREATE FUNCTION func_name ([param_name type[,...]])RETURNS type[characteristic ...] BEGIN存储过程体 END;-- 调用存储过程SELECT func_name([parameter[,…]]);-- 查看存储过程和函数的状态信息SHOW {PROCEDURE | FUNCTION} STATUS [LIKE 'pattern']存储函数和存储过程异同
| 存储函数 | 存储过程 |
|---|---|
| 不能拥有输出参数 | 可以拥有输出参数 |
| 可以直接调用存储函数,不需要call语句 | 需要call语句调用存储过程 |
| 必须包含一条return语句 | 不允许包含return语句 |
DELIMITER $-- 创建储存函数 CREATE FUNCTION sale_money_Function(s_money DECIMAL(11,2)) RETURNS DATENOT DETERMINISTICBEGIN RETURN (SELECT MAX(order_date) FROM sales WHERE money > s_money);END$DELIMITER ;-- 调用存储函数SELECT sale_money_Function(200.00); 

