Pytorch神经网络实战学习笔记_32 对抗神经网络专题(一):简介+ 工作流程 + WGAN模型 + WGAN-gp模型 + 条件GAN + WGAN-div + W散度
1 对抗神经简介
1.1 对抗神经网络的基本组成
1.1.1 基本构成
对抗神经网络(即生成式对抗网络,GAN)一般由两个模型组成:
- 生成器模型(generator):用于合成与真实样本相差无几的模拟样本。
- 判别器模型(discriminator):用于判断某个样本是来自真实世界还是模拟生成的。
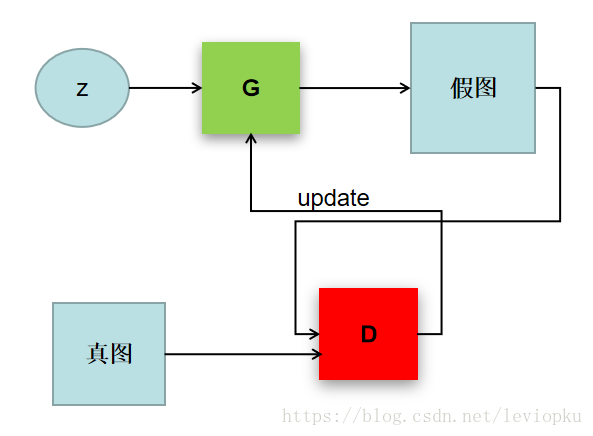
1.1.2 不同模型的在GAN中的主要作用
生成器模型的目的是,让判别器模型将合成样本当成直实样本。
判别器模的目的是,将合成样本与真实样本区分开。
1.1.3 独立任务
若将两个模型放在一起同步训练,那么生成器模型生成的模拟样本会更加真实,判别器模型对样本的判断会更加精准。
- 生成器模型可以当成生成式模型,用来独立处理生成式任务;
- 判别器模型可以当成分类器模型,用来独立处理分类任务。
1.2 对抗神经网络的工作流程
1.2.1生成器模型
生成器模型的输入是一个随机编码向量,输出是一个复杂样本(如图片)。从训练数据中产生相同分布的样本。对于输入样本x,类别标签y,在生成器模型中估计其联合概率分布,生成与输入样本x更为相似的样本。
1.2.2 判别器模型
根据条件概率分布区分真假样本。它的输入是一个复杂样本,输出是一个概率。这个概率用来判定输入样本是真实样本还是生成器输出的模拟样本。
1.2.3 工作流程简介
生成器模型与判别器模型都采用监督学习方式进行训练。二者的训练目标相反,存在对抗关系。将二者结合后,将形成如下图所示的网络结构。
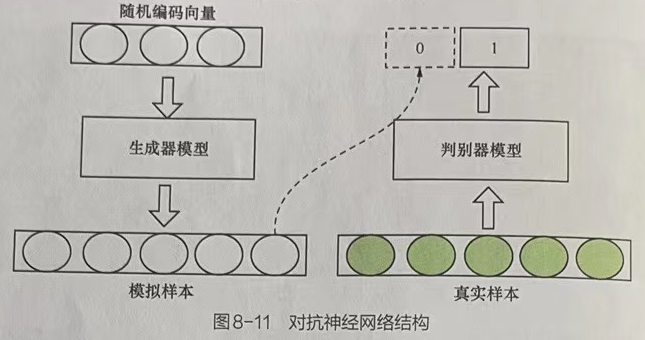
对抗神经网络结构对抗神经网络的训练方法各种各样,但其原理都是一样的,即在迭代练的优化过程中进行两个网络的优化。有的方法会在一个优化步骤中对两个网络进行优化、有的会对两个网络采取不同的优化步骤。
经过大量的迭代训练会使生成器模型尽可能模拟出“以假乱真”的样本,而判别模型会有更精确的鉴别真伪数据的能力,从而使整个对抗神经网络最终达到所谓的纳什均衡,即判别器模型对于生成器模型输出数据的鉴别结果为50%直、50%假。
1.3 对抗神经网络的功能
监督学习神经网络都属于判别器模型,自编码神经网络中,编码器部分就属于一个生成器模型
1.3.1 生成器模型的特性
- 在应用数学和工程方面,能够有效地表征高维数据分布。
- 在强化学习方面,作为一种技术手段有效表征强化学习模型中的状态。
- 在半览督学习方面,能够在数据缺失的情况下训练模型、并给出相应的输出。
1.3.2 举例
在视频中,通过场景预测下一帧的场景,而判别器模型的输出是维度很低的判别结果和期望输出的某个预测值,无法训练出单输入多输出的模型。
1.4 Gan模型难以训练的原因
GAN中最终达到对抗的纳什均衡只是一个理想状态,而现实情况是,随着训练次数的增多,判别器D的效果渐好,从而总是可以将生成器G的输出与真实样本区分开。
1.4.1 现象剖析
因为生成器G是从低维空间向高维空间(复杂的样本空间)的映射,其生成的样本分布空间Pg难以充满整个真实样本的分布空间Pr,即两个分布完全没有重叠的部分,或者重叠的部分可忽略,这就使得判别器D可以将其分开。
1.4.2 生成样本与真实样本重叠部分可忽略的原因
在二维平面中,随机取两条曲线,两条曲线上的点可以代表二者的分布。要想让判别器无法分辨它们,需要两个分布融合在一起,也就是它们之间需要存在重叠的线段,然而这样的概率为0。即使它们很可能会存在交叉点,但是相比于两条曲线而言,交叉点比曲线低一个维度,也就是它只是一个点,代表不了分布情况,因此可将其忽略。
1.4.2 原因分析
假设先将判别器D训练得足够好,固定判别器D后再来训练生成器G,通过实验会发现G的loss值无法收敛到最小值,而是无限地接近一个特定值。这个值可以理解为模拟样本分布Pg与原始样本分布Pr两个样本分布之间的距离。对于loss值恒定(即表明生成器G的梯度为0)的情况,生成器G无法通过训练来优化自己。
在原始GAN的训练中判别器训练得太好,生成器梯度就会逍失,生成器的lossS值降不下去;
在原始GAN的训练中判别器训练得不好,生成器梯度不准,抖动较大。
只有判别器训练到中间状态,才是最好的,但是这个尺度很难把握,甚至在同一轮训练的不同阶段这个状态出现的时段都不一样,这是一个完全不可控的情况。
2 WGAN模型
WGAN的名字源于Wasserstein GAN,Vasserstein是指Wasserstein距离,又称Earth-Mover(EM)推土机距离。
2.1 WGAN模型的原理
WGAN的原理是将生成的模拟样本分布Pg与原始样本分布Pr组合起来,并作为所有可能的联合分布的集合,并计算出二者的距离和距离的期望值。
2.1.1 WGAN原理的优势
可以通过训练模型的方式,让网络沿着其该网络所有可能的联合分布期望值的下界方向进行优化,即将两个分布的集合拉到一起。此时,原来的判别器就不再具有判别真伪的功能,而获得计算两个分布集合距离的功能。因此,将其称为评论器会更加合适。最后一层的Sigmoid函数也需要去掉(不需要将值域控制在0~1)。
2.2 WGAN模型的实现
使用神经网络来计算Wasserstein距离,可以让神经网络直接拟合下式:
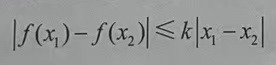
f(x)可以理解成神经网络的计算,让判别器实现将f(x1)与f(x2)的距离变换成x1-x2的绝对值乘以k(k≥0)。k代表函数f(x)的Lipschitz常数,这样两个分布集合的距离就可以表示成D(real)-D(G(x))的绝对值乘以k了。这个k可以理解成梯度,即在神经网络f(x)中乘以的梯度绝对值小于k。
将上式中的k忽略,经过整理后,可以得到二者分布的距离公式:
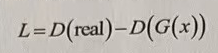
现在要做的就是将L当成目标来计算loss值。
判别器D的任务是区分它们,因为希望二者距离变大,所以loss值需要取反得到:
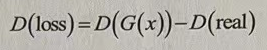
通过判别器D的losss值也可以看出生成器G的生成质量,即loss值越小,代表距离越近,生成的质量越高。
生成器G用来将希望模拟样本分布Pg越来越接近原始样本分布Pr,所以需要训练让距离L最小化。因为生成器G与第一项无关,所以G的loss值口可简化为:
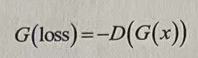
2.4 WGAN的缺点
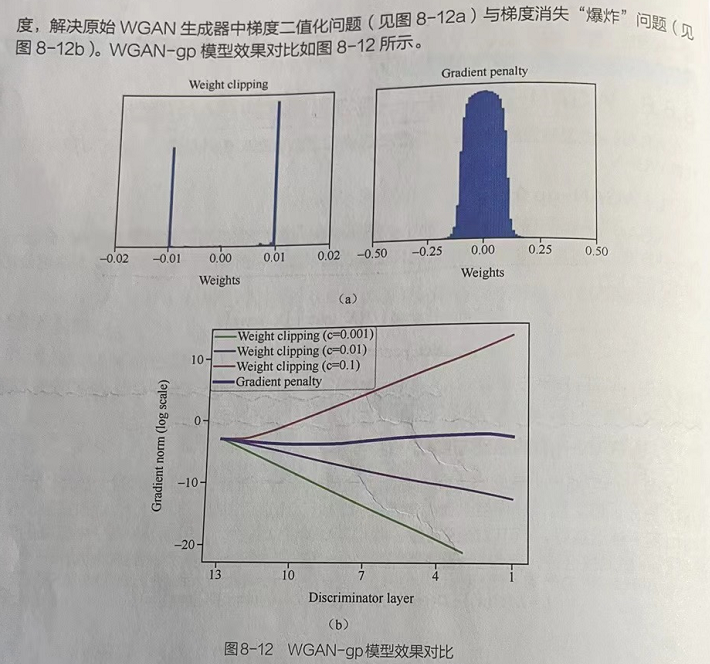
若原始WGAN的Lipschitz限制的施加方式不对,那么使用梯度截断方式太过生硬。每当更新完一次判别器的参数之后,就应检查判别器中所有参数的绝对值有没有超过阈值,有的话就把这些参数截断回[-0.01,0.01]范围内。
Lipschitz限制本意是当输入的样本稍微变化后,判别器给出的分数不能产生太过剧烈的变化。通过在训练过程中保证判别器的所有参数有界,可保证判别器不能对两个略微不同的样本给出天差地别的分数值,从而间接实现了Lipschitz限制。
这种期望与判别器本身的目的相矛盾。判别器中希望loss值尽可能大,这样才能拉大真假样本间的区别,但是这种情况会导致在判别器中,通过loss值算出来的梯度会沿着loss值越来越大的方向变化,然而经过梯度截断后每一个网络参数又被独立地限制了取值范圃(如[-0.01,0.01])。这种结果会使得所有的参数要么取最大值(如0.01),要么取最小值(如-0.01)。判别器没能充分利用自身的模型能力,经过它回传给生成器的梯度也会跟着变差。
如果判别器是一个多层网络,那么梯度截断还会导致梯度消失或者梯度“爆炸”问题。截断阀值设置得稍微低一点,那么每经过一层网络,梯度就会变小一点,多层之后就会呈指数衰减趋势。
反之截断阔值设置得稍大,每经过一层网络,梯度变大一点,则多层之后就会呈指数爆炸趋势。在实际应用中,很难做到设合适,让生或器获得恰到好处的回传梯度。
2.3 WGAN模型总结
WGAN引入了Wasserstein距离,由于它相对KL散度与JS散度具有优越的平滑特性,因此理论上可以解决梯度消失问题。再利用一个参数数值范围受限的判别器神经网络实现将Wasserstein距离数学变换写成可求解的形式的最大化,可近似得到Wasserstein距离。
在此近似最优判别器下,优化生成器使得Wasserstein距离缩小,这能有效拉近生成分布与真实分布。WGAN既解决了训练不稳定的问题,又提供了一个可靠的训练进程指标,而且该指标确实与生成样本的质量高度相关。
在实际训练过程中,WGAN直接使用截断(clipping)的方式来防止梯度过大或过小。但这个方式太过生硬,在实际应用中仍会出现问题,所以后来产生了其升级版WGAN-gp。
3 WGAN-gp模型(更容易训练的GAN模型)
WGAN-gp又称为具有梯度惩罚的WGAN,是WGAN的升级版,一般可以用来全面代替WGAN。
3.1 WGAN-gp介绍
WGAN-gp中的gp是梯度惩罚(gradient penalty)的意思,是替换weight clipping的一种方法。通过直接设置一个额外的梯度惩罚项来实现判别器的梯度不超过k。其表达公式为:
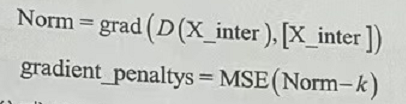
其中,MSE为平方差公式;X_inter为整个联合分布空间中的x取样,即梯度惩罚项gradent _penaltys为求整个联合分布空间中x对应D的梯度与k的平方差。
3.2 WGAN-gp的原理与实现


3.3 Tip
- 因为要对每个样本独立地施加梯度惩罚,所以在判别器的模型架构中不能使用BN算法,因为它会引入同一个批次中不同样本的相互依赖关系。
- 如果需要的话,那么可以选择其他归一化办法,如Layer Normalization、Weight Normalization、Instance Normalization等,这些方法不会引入样本之间的依赖。
4 条件GAN
条件GAN的作用是可以让GAN的生成器模型按照指定的类别生成模拟样本。
4.1 条件GAN的实现
条件GAN在GAN的生成器和判别器基础上各进行了一处改动;在它们的输入部分加入了一个标签向量(one_hot类型)。
4.2 条件GAN的原理
GAN的原理与条件变分自编码神经网络的原理一样。这种做法可以理解为给GAN增加一个条件,让网络学习图片分布时加入标签因素,这样可以按照标签的数值来生成指定的图片。
5 带有散度的GAN——WGAN-div
WGAN-div模型在WGAN-gp的基础上,从理论层面进行了二次深化。在WGAN-gp中,将判别器的梯度作为惩罚项加入判别器的loss值中。
在计算判别器梯度时,为了让X_inter从整个联合分布空间的x中取样,在真假样本之间采取随机取样的方式,保证采样区间属于真假样本的过渡区域。然而,这种方案更像是一种经验方案,没有更完备的理论支撑(使用个体采样代替整体分布,而没能从整体分布层面直接解决问题)。
3.1 WGAN-div模型的使用思路
WGAN-div模型与WGAN-gp相比,有截然不同的使用思路:不从梯度惩罚的角度去考虑,而通过两个样本间的分布距离来实现。
在WGAN-diⅳ模型中,引入了W散度用于度量真假样本分布之间的距离,并证明了中的W距离不是散度。这意味着WGAN-gp在训练判别器的时候,并非总会拉大两个分布间的距离,从而在理论上证明了WGAN-gp存在的缺陷一—会有训练失效的情况。
WGAN-div模型从理论层面对WGAN进行了补充。利用WGAN-div模型的理论所实现的loss值不再需要采样过程,并且所达到的训练效果也比WGAN-gp更胜一筹。
3.2 了解W散度

3.3 WGAN-div的损失函数


3.4 W散度与W距离间的关系


