JVM虚拟机入门教程(作者原创)
个人简介
作者是一个来自河源的大三在校生,以下笔记都是作者自学之路的一些浅薄经验,如有错误请指正,将来会不断的完善笔记,帮助更多的Java爱好者入门。
文章目录
-
- 个人简介
- JVM
-
- JVM的定义
- JVM带来的好处
- JVM、JRE、JDK的区别
- Java内存结构(JVM内存结构)
-
- 程序计数器
- 虚拟机栈
-
- 垃圾回收是否涉及栈内存
- 栈内存越大是否越好?
- 方法内的局部变量是否安全
- 栈溢出
- 排查CPU占用过高--重要
- 本地方法栈
- 堆
-
- 堆内存诊断工具
- 方法区
-
- 通过反编译来查看类的信息
- 常量池和字符串常量池StringTable区别
- JDK1.8后的intern
- JDK1.6的intern
- StringTable 垃圾回收
- StringTable调优
- 垃圾回收GC
-
- 判断对象是否可以垃圾回收
-
- 引用计数法
- 可达性分析算法(JVM所采用)
- 五种引用
-
- 强引用
- 软引用
- 弱引用
- 虚引用
- 终结器引用
- 引用队列
- 垃圾回收算法
-
- 标记-清除
- 标记-整理
- 复制
- 分代回收
- 垃圾回收器
- GC调优
- 类加载
JVM
JVM的定义
Java Virtual Machine(Java虚拟机),JAVA程序的运行环境(JAVA二进制字节码的运行环境)
JVM带来的好处
- 一次编写,到处运行
- 垃圾回收机制
- 数组下标越界检查(C语言是没有的)
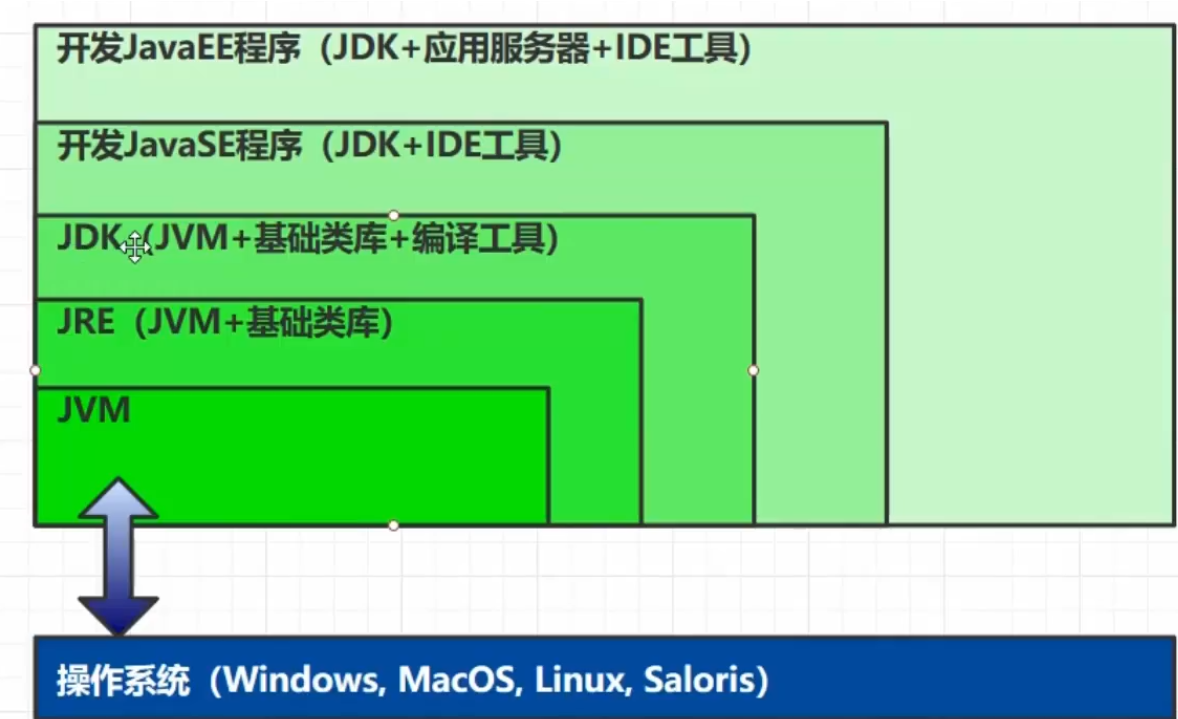
JVM、JRE、JDK的区别
包含关系:JDK>JRE>JVM
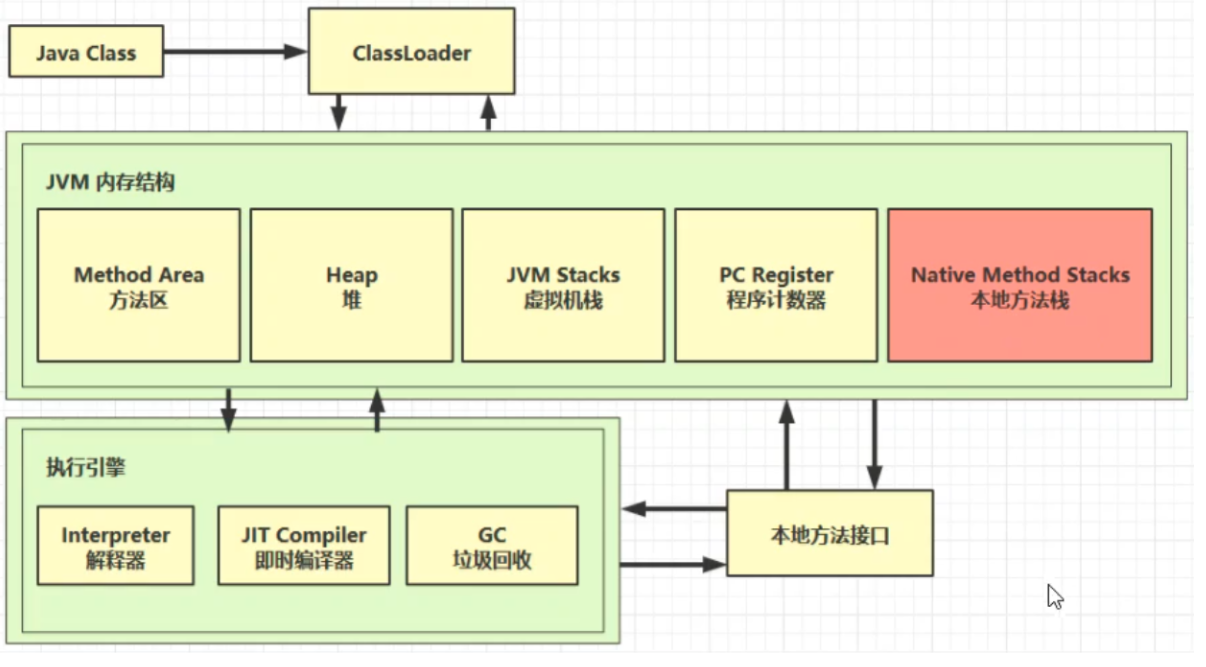
Java内存结构(JVM内存结构)
记得区别Java内存结构和Java内存模型,Java内存模型是虚构的,而Java内存结构是真实存在的
程序计数器
作用
记录下一条JVM执行的指令的地址
特点
- 线程私有
- CPU会为每个线程分配时间片,假如当前线程时间片用完之后就会执行另外一个线程的代码
- 每个线程都有一个程序计数器,CPU会不断重复上面的顺序去执行代码,由程序计数器去记录每个线程应该执行哪一句代码。
- 不存在内存溢出
虚拟机栈
定义
- 线程私有
- 每个线程运行需要的内存空间称为虚拟机栈
- 每个栈由多个栈帧组成,栈帧是由调用方法产生的(入栈),调用完方法后自动销毁(出栈)
- 每个线程创建的虚拟机栈都只有一个活动栈帧,对应着当前正在执行的方法
垃圾回收是否涉及栈内存
不涉及。因为虚拟机栈是由一个个栈帧组成,当调用方法时栈帧入栈,调用完该方法后该栈帧出栈,即内存释放了。所以不需要
垃圾回收器去回收栈内存。
栈内存越大是否越好?
不是。因为物理内存是固定的一个数值,栈内存增大,好处是可以接受更多次递归调用或者方法调用,但是可执行的线程就会变少。因为我们上面说了
当线程执行代码时就会创建一个虚拟机栈,假如我们物理内存有1000MB和每一个栈内存10MB,这种情况计算得可以支持的线程数是100个,
反之如果我们增大栈内存,物理内存还是1000MB而每一个栈内存变成100MB,这种情况下我们能够支持的线程数变成了10个。大幅减少了可支持线程线程数。
方法内的局部变量是否安全
- 如果方法外不能使用该局部变量,那么就是线程安全的,反之则是不安全
栈溢出
异常信息:Java.lang.stackOverflowError
原因:
- 递归没有终止条件,或者是永远无法达到递归终止条件,则会导致方法调用产生栈帧过多,最终发生栈溢出异常。(较为常见)
- 某个方法太过于庞大,导致栈帧多大,最终发生栈溢出。(不常见)
排查CPU占用过高–重要
第一步在控制台输入:top,然后找到了占用cpu过高的进程
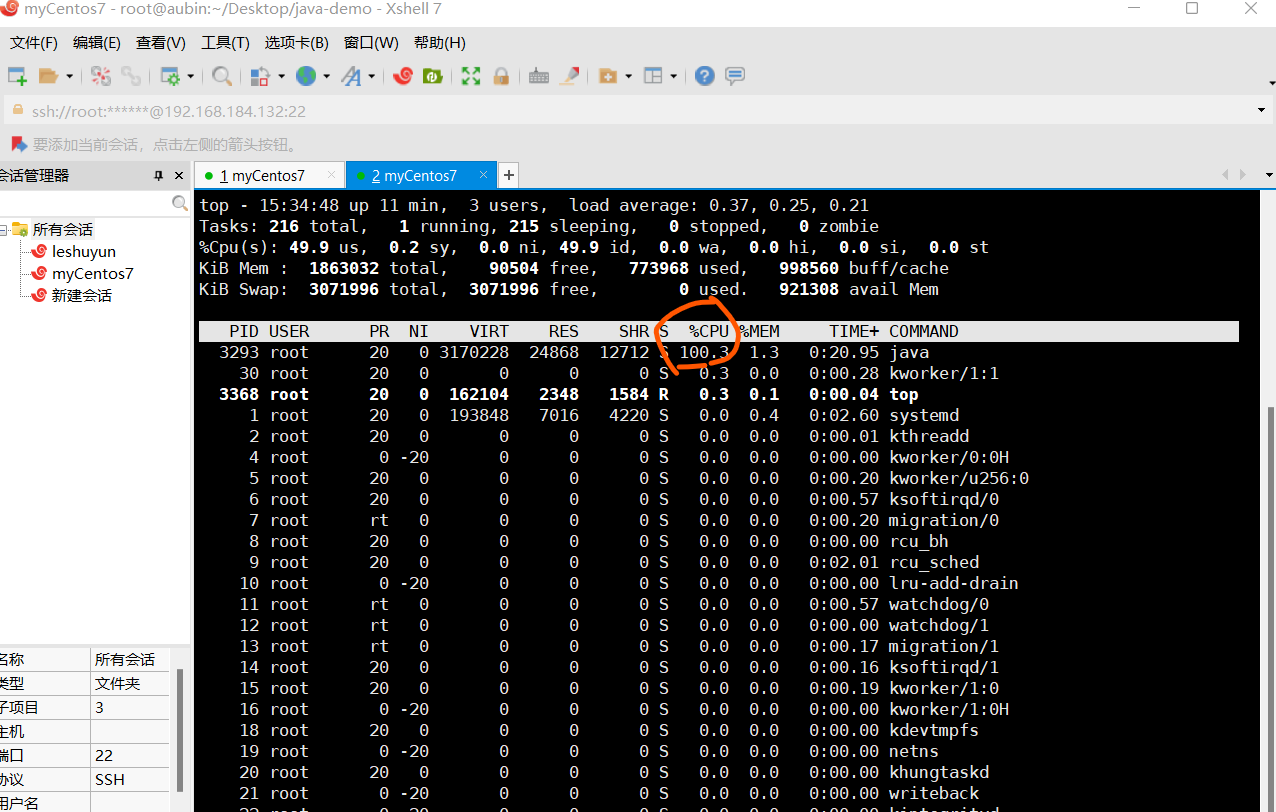
第二步输入:top -Hp cpu占用多高的进程id(也就是上面top命令查看到的进程id) ,然后就可以找到cpu占用高的线程id
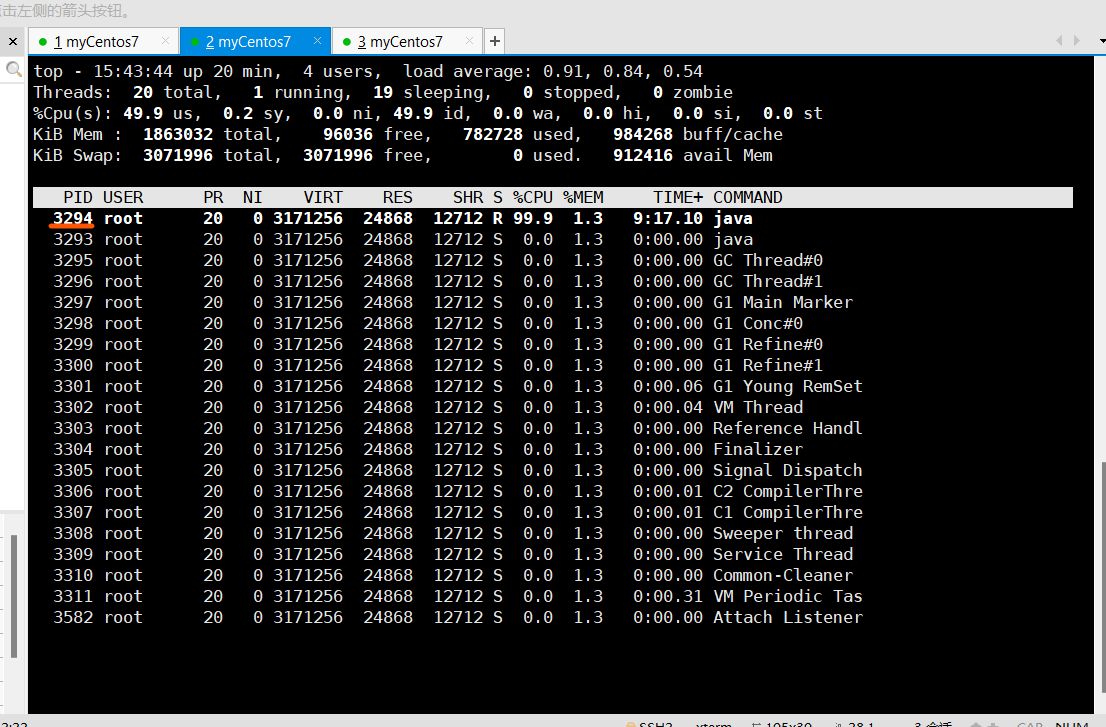
第三步输入:jstack 线程id
上面我们找到的线程id是3294。转成16进制,得0xCDE,根据这个16进制数找到对应的位置就可以看到信息了。
本地方法栈
一些带有native关键字的方法就会调用本地的C/C++函数,因为Java不能和系统底层交互,所以需要这些语言的借助。
堆
通过new关键字创建的对象就会被放到堆内存。
特点:
- 线程共享。堆内存的对象需要考虑线程安全问题
- 有垃圾回收机制
堆内存溢出
java.lang.OutofMemoryError,简称OOM
堆内存诊断工具
jps
D:\java code\netty-study>jps10276 Launcher18804 demo #目标进程id14236 Jps1:jmap
JDK8之前
jmap -heap 进程idJDK8之后
jhsdb jmap --heap --pid 进程id输出
Attaching to process ID 18804, please wait...Debugger attached successfully.Server compiler detected.JVM version is 10.0.2+13using thread-local object allocation.Garbage-First (G1) GC with 8 thread(s)Heap Configuration: MinHeapFreeRatio = 40 MaxHeapFreeRatio = 70 MaxHeapSize= 6402605056 (6106.0MB) NewSize = 1363144 (1.2999954223632812MB) MaxNewSize = 3840933888 (3663.0MB) OldSize = 5452592 (5.1999969482421875MB) NewRatio = 2 SurvivorRatio = 8 MetaspaceSize = 21807104 (20.796875MB) CompressedClassSpaceSize = 1073741824 (1024.0MB) MaxMetaspaceSize = 17592186044415 MB G1HeapRegionSize = 1048576 (1.0MB)Heap Usage:G1 Heap: regions = 6106 capacity = 6402605056 (6106.0MB) used = 4194304 (4.0MB) free = 6398410752 (6102.0MB) 0.06550933508024893% usedG1 Young Generation:Eden Space: regions = 4 capacity = 27262976 (26.0MB) used = 4194304 (4.0MB) free = 23068672 (22.0MB) 15.384615384615385% usedSurvivor Space: regions = 0 capacity = 0 (0.0MB) used = 0 (0.0MB) free = 0 (0.0MB) 0.0% usedG1 Old Generation: regions = 0 capacity = 373293056 (356.0MB) used = 0 (0.0MB) free = 373293056 (356.0MB) 0.0% used5360 interned Strings occupying 400600 bytes.2:jconsole
3:jvirsualvm
4:阿里巴巴arthas
方法区
JDK1.8之前和JDK1.8之后的方法区结构:
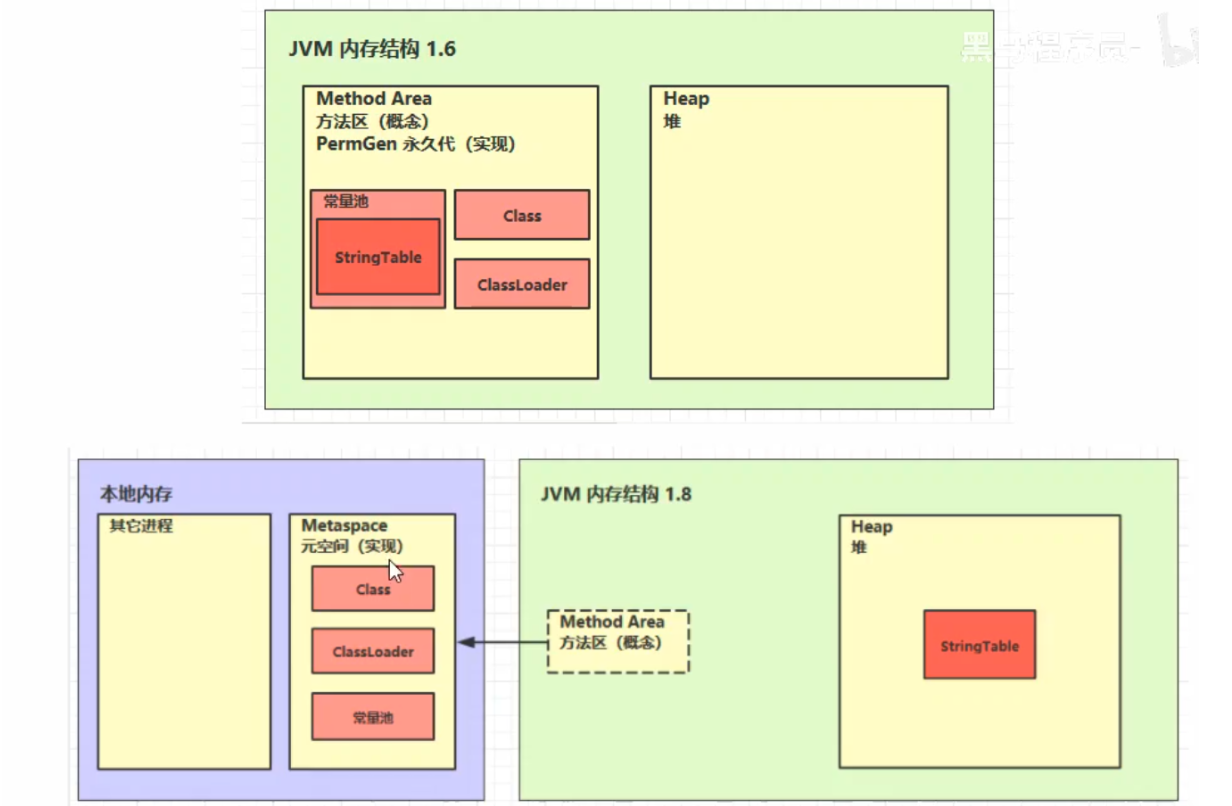
方法区的实现:
- JDK1.8之前,也就是jdk1.6、jdk1.7这些版本方法区采用的是永久代
- JDK1.8之后,也就是jdk1.8、jdk1.9这些版本方法区采用的是元空间
常量池
二进制字节码的组成:类的基本信息、常量池、类的方法定义、jvm指令
通过反编译来查看类的信息
1:先用javac编译成class
javac Demo1.java2:再用javap进行反编译字节码文件
javap -v Demo1.class3:输出反编译后的字节码信息
Classfile /D:/java code/jvm/src/com/jvm/demo1/Demo1.class Last modified 2022年2月21日; size 429 bytes MD5 checksum dcc0c07c66f64b64b606d0b6566c3c9c Compiled from "Demo1.java"public class com.jvm.demo1.Demo1 minor version: 0 major version: 54 flags: (0x0021) ACC_PUBLIC, ACC_SUPER this_class: #5 // com/jvm/demo1/Demo1 super_class: #6 // java/lang/Object interfaces: 0, fields: 0, methods: 2, attributes: 1Constant pool: #1 = Methodref #6.#15 // java/lang/Object."":()V #2 = String #16 // hello #3 = Fieldref #17.#18 // java/lang/System.out:Ljava/io/PrintStream; #4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V #5 = Class#21 // com/jvm/demo1/Demo1 #6 = Class#22 // java/lang/Object #7 = Utf8 #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 main #12 = Utf8 ([Ljava/lang/String;)V #13 = Utf8 SourceFile #14 = Utf8 Demo1.java #15 = NameAndType #7:#8 // "":()V #16 = Utf8 hello #17 = Class#23 // java/lang/System #18 = NameAndType #24:#25 // out:Ljava/io/PrintStream; #19 = Class#26 // java/io/PrintStream #20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V #21 = Utf8 com/jvm/demo1/Demo1 #22 = Utf8 java/lang/Object #23 = Utf8 java/lang/System #24 = Utf8 out #25 = Utf8 Ljava/io/PrintStream; #26 = Utf8 java/io/PrintStream #27 = Utf8 println #28 = Utf8 (Ljava/lang/String;)V{ public com.jvm.demo1.Demo1(); descriptor: ()V flags: (0x0001) ACC_PUBLIC Code: stack=1, locals=1, args_size=1 0: aload_0 1: invokespecial #1 // Method java/lang/Object."":()V 4: return LineNumberTable: line 3: 0 public static void main(java.lang.String[]); descriptor: ([Ljava/lang/String;)V flags: (0x0009) ACC_PUBLIC, ACC_STATIC Code: stack=2, locals=2, args_size=1 0: ldc #2 // String hello 2: astore_1 3: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream; 6: aload_1 7: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 10: return LineNumberTable: line 7: 0 line 9: 3 line 11: 10}SourceFile: "Demo1.java"真正编译的方法内容:
Code: stack=2, locals=2, args_size=1 0: ldc #2 // String hello 2: astore_1 3: getstatic #3 // Field java/lang/System.out:Ljava/io/PrintStream; 6: aload_1 7: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V 10: return这些#数字代表地址,需要去常量池里面找。。。。
常量池内容:
Constant pool: #1 = Methodref #6.#15 // java/lang/Object."":()V #2 = String #16 // hello #3 = Fieldref #17.#18 // java/lang/System.out:Ljava/io/PrintStream; #4 = Methodref #19.#20 // java/io/PrintStream.println:(Ljava/lang/String;)V #5 = Class#21 // com/jvm/demo1/Demo1 #6 = Class#22 // java/lang/Object #7 = Utf8 #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 main #12 = Utf8 ([Ljava/lang/String;)V #13 = Utf8 SourceFile #14 = Utf8 Demo1.java #15 = NameAndType #7:#8 // "":()V #16 = Utf8 hello #17 = Class#23 // java/lang/System #18 = NameAndType #24:#25 // out:Ljava/io/PrintStream; #19 = Class#26 // java/io/PrintStream #20 = NameAndType #27:#28 // println:(Ljava/lang/String;)V #21 = Utf8 com/jvm/demo1/Demo1 #22 = Utf8 java/lang/Object #23 = Utf8 java/lang/System #24 = Utf8 out #25 = Utf8 Ljava/io/PrintStream; #26 = Utf8 java/io/PrintStream #27 = Utf8 println #28 = Utf8 (Ljava/lang/String;)V运行时常量池
- 常量池的值是一个地址,不是真正的值
#2 = String #16 - 运行时常量池当该类被加载时,它的常量池信息(也就是上面展示的)就会变成真正的值。
常量池和字符串常量池StringTable区别
- StringTable底层是HashTable,是线程安全的
- 常量池的值是一个地址,只有运行时才会变成真正的值
- 可以利用字符串常量池StringTable的特性来避免重复创建String对象
- 字符串变量的加法拼接底层是new了一个StringBuilder再new一个String对象进行拼接
- 字符串常量的加法拼接原理是编译器优化。
- 可以使用intern方法主动将StringTable还没有的字符串放入StringTable。
- StringTable和堆的字符串都是对象
- StringTable用来放字符串对象且里面的元素不重复
基本操作展示
public static void main(String[] args) { String a="a"; String b="b"; String ab="ab"; }编译得:
Constant pool: #1 = Methodref #6.#15 // java/lang/Object."":()V #2 = String #16 // a #3 = String #17 // b #4 = String #18 // ab #5 = Class#19 // com/jvm/demo1/Demo1 #6 = Class#20 // java/lang/Object #7 = Utf8 #8 = Utf8 ()V #9 = Utf8 Code #10 = Utf8 LineNumberTable #11 = Utf8 main #12 = Utf8 ([Ljava/lang/String;)V #13 = Utf8 SourceFile #14 = Utf8 Demo1.java #15 = NameAndType #7:#8 // "":()V #16 = Utf8 a #17 = Utf8 b #18 = Utf8 ab #19 = Utf8 com/jvm/demo1/Demo1 #20 = Utf8 java/lang/Object 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: returnldc指令会把字符串放入StringTable。
上面代码执行后最终StringTable [“a”, “b”, “ab”]
注意:字符串对象的创建都是懒惰的,只有当运行到那一行字符串且在串池中不存在的时候(如 ldc #2)时,该字符串才会被创建并放入串池中。
使用拼接字符串变量对象创建字符串的过程
public static void main(String[] args) { String a="a"; String b="b"; String ab="ab"; String ab2=a+b; } Code: stack=2, locals=5, args_size=1 0: ldc #2 // String a 2: astore_1 3: ldc #3 // String b 5: astore_2 6: ldc #4 // String ab 8: astore_3 9: new #5 // class java/lang/StringBuilder 12: dup 13: invokespecial #6 // Method java/lang/StringBuilder."":()V 16: aload_1 17: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 20: aload_2 21: invokevirtual #7 // Method java/lang/StringBuilder.append:(Ljava/lang/String;)Ljava/lang/StringBuilder; 24: invokevirtual #8 // Method java/lang/StringBuilder.toString:()Ljava/lang/String; 27: astore 4 29: return通过拼接的方式来创建字符串的过程是:StringBuilder().append(“a”).append(“b”).toString()
最后的toString方法的返回值是一个新的字符串,但字符串的值和拼接的字符串一致,但是两个不同的字符串,一个存在于串池之中,一个存在于堆内存之中
public static void main(String[] args) { String a="a"; String b="b"; String ab="ab"; String ab2=a+b; System.out.println(ab==ab2);//false }字符串常量拼接
编译期优化会直接使用StringTable对象,必须全部都是常量才是这个结果,但凡有一个变量就不行。
场景1:
public static void main(String[] args) { String a="a"; String b="b"; String ab="ab"; String ab2="a"+"b"; System.out.println(ab==ab2);//编译期优化true }场景2:
public static void main(String[] args) { final String a="a"; final String b="b"; String ab="ab"; String ab2=a+b; System.out.println(ab==ab2);//true }使用拼接字符串常量的方法来创建新的字符串时,因为内容是常量,javac在编译期会进行优化,结果已在编译期确定为ab,而创建ab的时候已经在串池中放入了“ab
所以ab2直接从串池中获取值,所以进行的操作和 ab = “ab” 一致。
JDK1.8后的intern
public static void main(String[] args) { String a="a"; String b="b"; String ab="ab"; String ab2=a+b; System.out.println(ab==ab2);//false String ab3 = ab2.intern();System.out.println(ab==ab3); //true }JDK1.8后intern原理:
String ab3 = ab2.intern(); - 首先会拿ab2对象去StringTable找,如果没有就会把这个对象放入StringTable并返回这个地址
- 如果StringTable有这个字符串,则直接返回StringTable的这个字符串
- 无论放入是否成功,都会返回串池中的字符串对象
注意:此时如果调用intern方法成功,堆内存与串池中的字符串对象是同一个对象;如果失败,则不是同一个对象
JDK1.6的intern
JDK1.6intern原理:
- 调用字符串对象的intern方法,会将该字符串对象尝试放入到串池中
- 如果串池中没有该字符串对象,会将该字符串对象复制一份,再放入到串池中
- 如果有该字符串对象,则放入失败
- 无论放入是否成功,都会返回串池中的字符串对象
注意:此时无论调用intern方法成功与否,串池中的字符串对象和堆内存中的字符串对象都不是同一个对象
StringTable 垃圾回收
StringTable在内存紧张时,会发生垃圾回收
StringTable调优
- 因为StringTable底层是HashTable,所以可以适当增加HashTable桶的数量,来减少字符串放入串池的时间
-XX:StringTableSize=xxxx- 考虑是否需要将字符串对象入池
可以通过intern方法减少重复入池
垃圾回收GC
判断对象是否可以垃圾回收
引用计数法
Netty的ByteBuf就是用到引用计数法来释放内存(垃圾回收)。
弊端:当循环引用时,两个对象计数都为1,导致两个对象都释放不了。
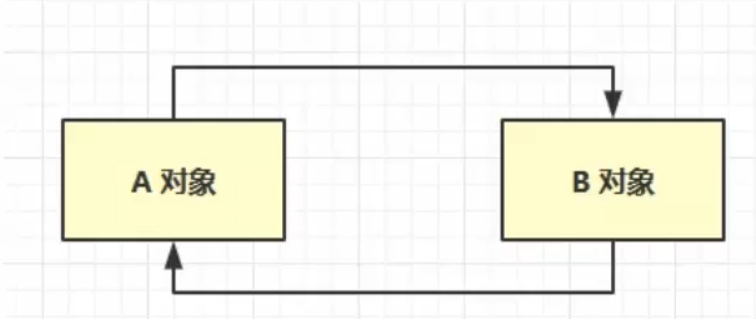
可达性分析算法(JVM所采用)
- JVM通过可达性分析算法来判断对象是否可以回收。
- 扫描堆内的对象,看是否可以沿着GC root找到该对象,如果找不到,则可以把这个对象回收掉
- 可以作为GC root的对象
- 虚拟机栈引用的对象
- 被static修饰的对象
- 被final修饰的对象
- native方法引用的对象
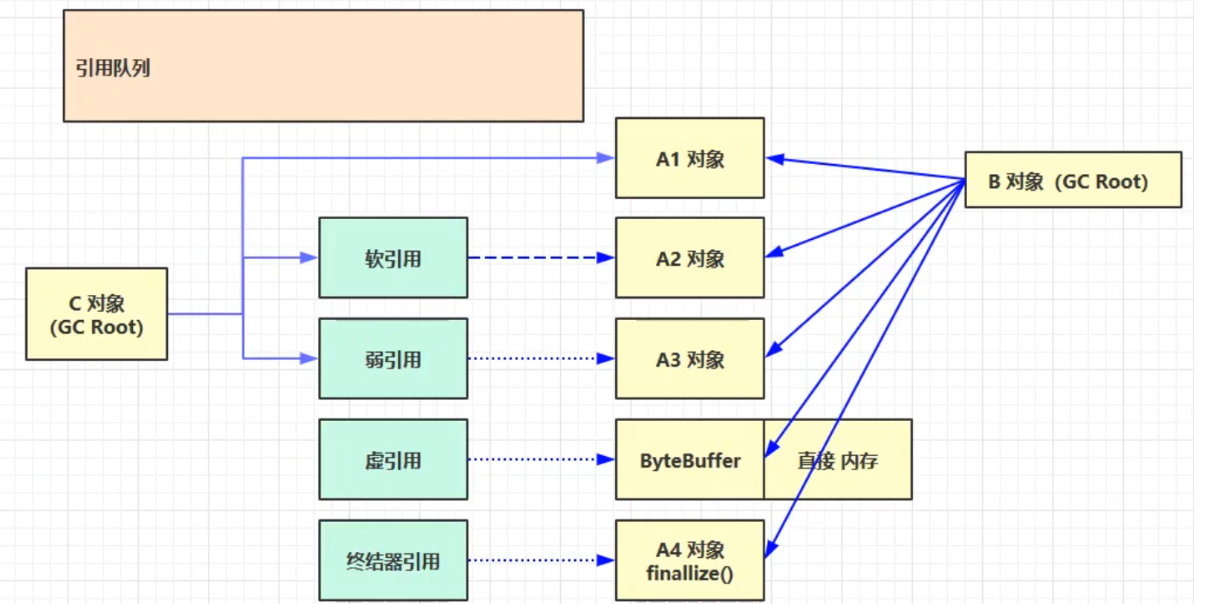
五种引用
强引用
我们日常使用的new对象都是强引用。
- 特点:当对象被强引用所引用时,该对象不会被垃圾回收。只有GC root都不引用这个对象才会被垃圾回收
//强引用 String str=new String("strong"); str=null; //断开引用 System.gc(); //垃圾回收 str=new String("aaa"); System.out.println(str);软引用
- 该对象没有被强引用所引用的前提下,该对象被软引用所引用,当内存不足时会被垃圾回收。
软引用,不搭配引用队列情况
//软引用 String str=new String("SoftReference"); SoftReference<String> softReference=new SoftReference<String>(str); str=null; System.gc();软引用,搭配引用队列情况
//软引用 String str=new String("SoftReference"); //创建引用队列 ReferenceQueue<String> referenceQueue=new ReferenceQueue<String>(); //引用队列绑定软引用 SoftReference<String> softReference=new SoftReference<String>(str,referenceQueue); System.out.println(referenceQueue.poll()); str=null; System.gc(); System.out.println(referenceQueue.poll()); //由于内存充足,不会被回收弱引用
- 该对象同样没有被强引用所引用,该对象被弱引用所引用,不管内存是否充足都会被回收。
弱引用,不搭配引用队列情况
int size=1024*100; byte bytes[]=new byte[size]; //绑定软引用、引用队列 WeakReference<byte[]> weakReference=new WeakReference<byte[]>(bytes); System.out.println(bytes); System.out.println(weakReference.get()); bytes=null; //断开强引用是前提 System.gc(); //gc System.out.println("=============="); System.out.println(weakReference.get()); //null System.out.println(bytes); //null System.out.println(weakReference);///java.lang.ref.WeakReference@66048bfd弱引用,搭配引用队列情况
int size=1024*100; byte bytes[]=new byte[size]; //创建引用队列 ReferenceQueue<byte[]> referenceQueue=new ReferenceQueue<>(); //绑定软引用、引用队列 WeakReference<byte[]> weakReference=new WeakReference<byte[]>(bytes,referenceQueue); System.out.println(referenceQueue.poll()); //因为没有gc后的对象在引用队列中所以null System.out.println(bytes); System.out.println(weakReference.get()); bytes=null; //断开强引用是前提 System.gc(); //gc System.out.println("=============="); System.out.println(weakReference.get()); //null System.out.println(bytes); //null Reference<? extends byte[]> reference = referenceQueue.poll(); //存储gc后的WeakReference对象 System.out.println(reference);//java.lang.ref.WeakReference@66048bfd System.out.println(weakReference);///java.lang.ref.WeakReference@66048bfd 和上面的一样 虚引用
- 相当于无引用,使对象无法被使用,必须与引用队列配合使用
- 当虚引用所引用的对象被垃圾回收时以后,虚引用对象就会被放入引用队列中,调用虚引用的方法。
- 虚引用的一个体现是释放直接内存,当引用的对象ByteBuffer被垃圾回收后*,虚引用对象Cleaner就会被放入引用队列,然后调用Clean的clean方法释放直接内存。
终结器引用
- 所有的类都继承自Object类,Object类有一个finalize方法,当某个对象不再被其他的对象所引用时,会先将终结器引用对象放入引用队列中,然后根据终结器引用对象找到它所引用的对象,然后调用该对象的finalize方法。调用以后,该对象就可以被垃圾回收了。
引用队列
- 软引用和弱引用 可以选择搭配引用队列
- 当软引用和弱引用被垃圾回收后,就会把这些引用放入引用队列,方便一起回收。
- 虚引用和终结器引用 必须搭配引用队列
- 虚引用和终结器引用在使用时会关联一个引用队列
垃圾回收算法
标记-清除
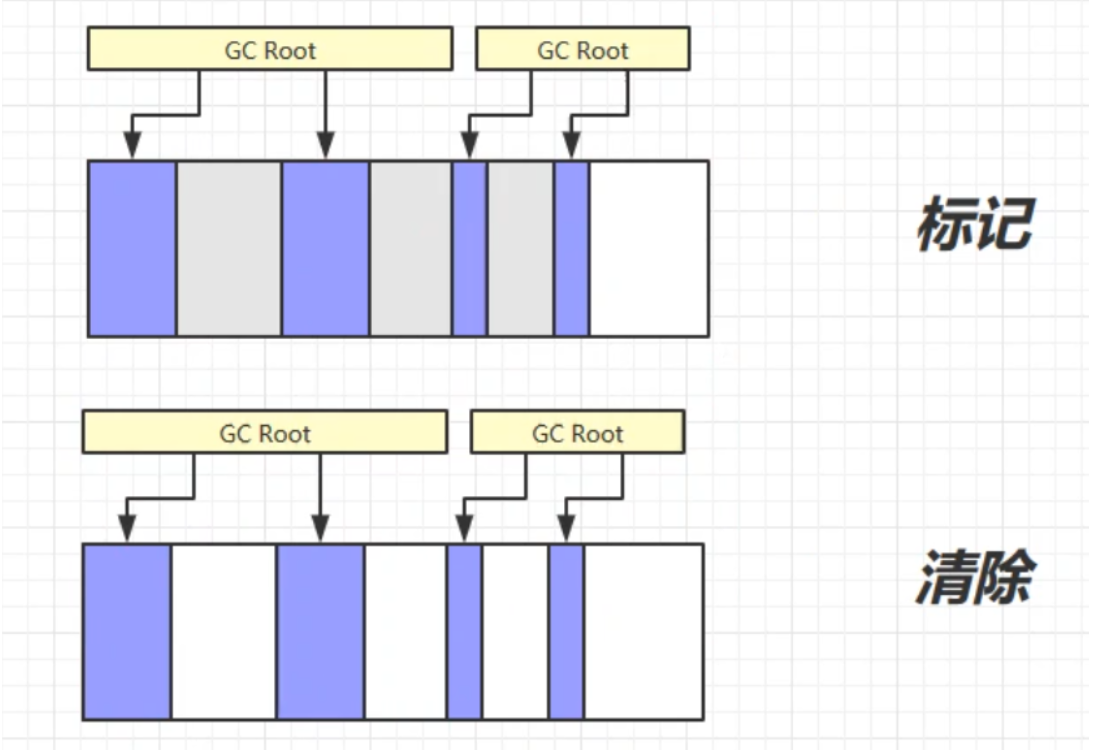
定义:标记清除算法指的是先标记可回收对象,然后再把这些可回收对象进行清除。
- 这里的清除不是把那块内存占用清0,而是记录其起始地址、结束地址,下次需要使用的时候直接覆盖那块内存即可。
缺点:容易产生大量内存碎片。导致大对象无法使用这些内存区域,从而导致GC,GC会导致STW暂停线程。
标记-整理
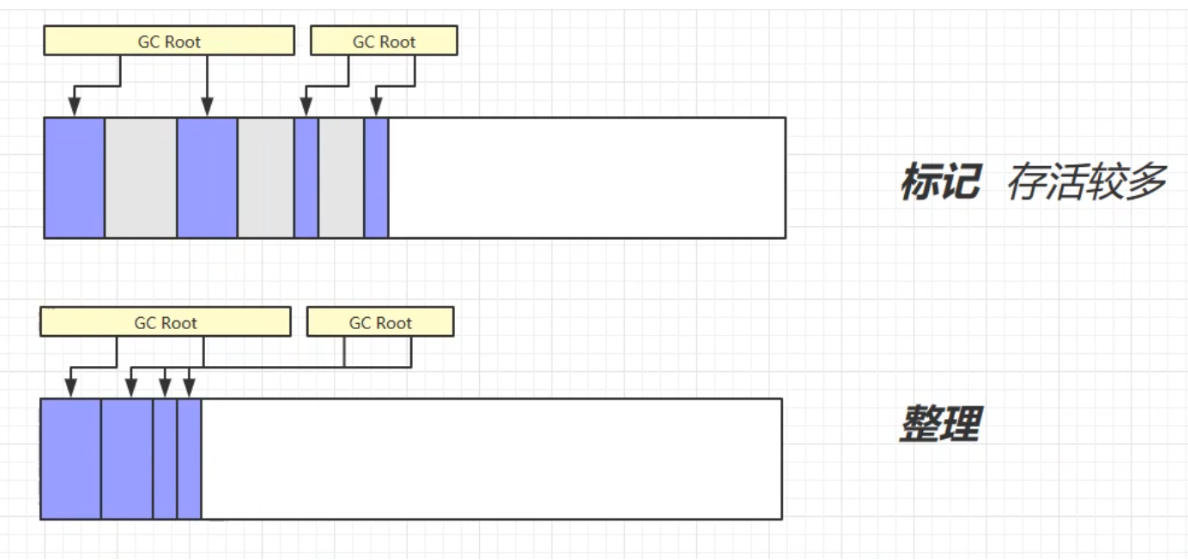
特点:和标记-清除算法相比标记整理算法不会有内存碎片,但是由于整理是需要时间的,所以速度方面会比较慢。
复制
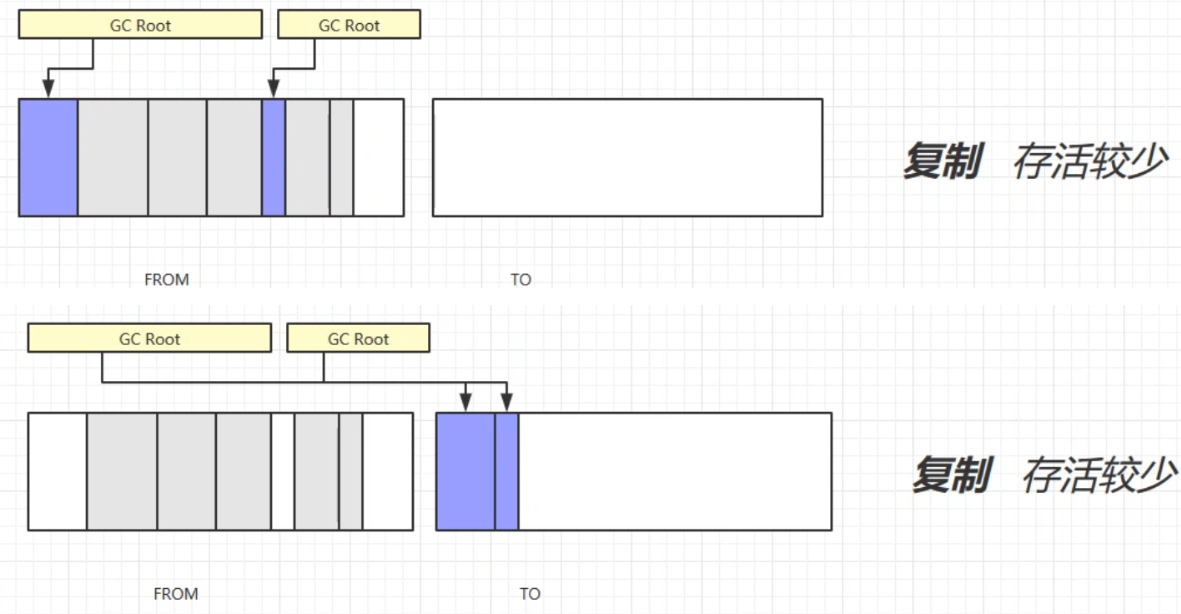
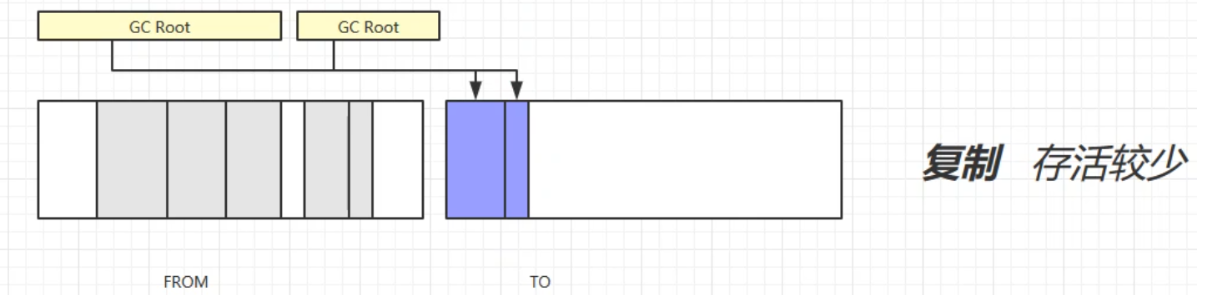
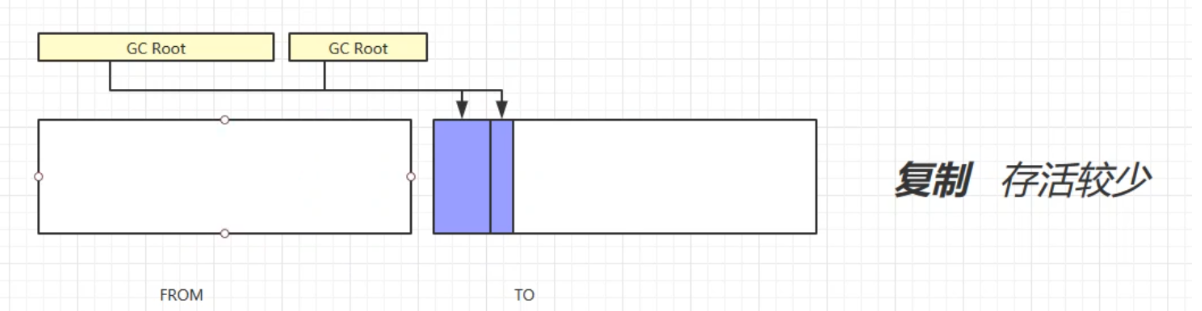
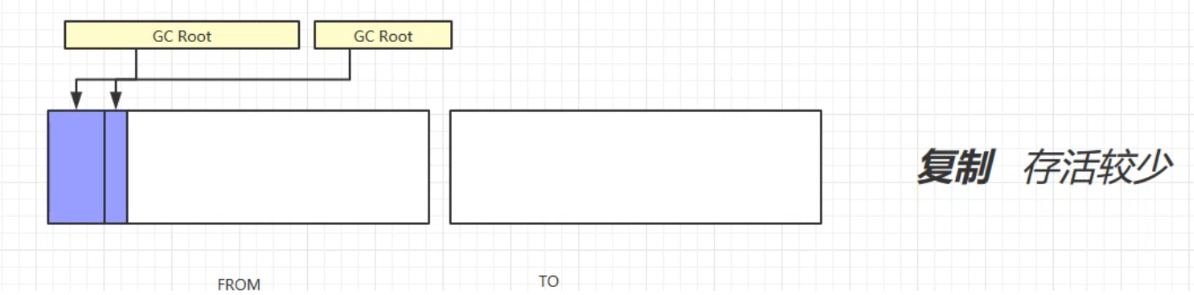
定义:复制算法首先会开辟多一块相同大小的内存空间TO,然后会将不可回收对象放到TO区域,再回收FROM区域的可回收对象,最后交换FROM和TO区域。
缺点:占用了双倍内存空间

