mongodb原理与实现
推荐一个零声学院免费公开课程,个人觉得老师讲得不错,分享给大家:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK等技术内容,立即学习
为什么使用mongodb?
关系型数据存在以下问题:
- 大数据处理能力差;水平扩展能力差;分库分表复杂;
- 应用程序开发效率低;
- 表结构变动困难;比如要增加字段,就需要改变表结构。
Mongodb是一个Nosql数据库,可以很好地解决上面的问题;
- mongodb集群支持分片,支持水平扩展;
- aggregate可以用于OLAP和OLTP;
- document使用的是bson格式,同一个collection的不同的document中的字段可以不同;
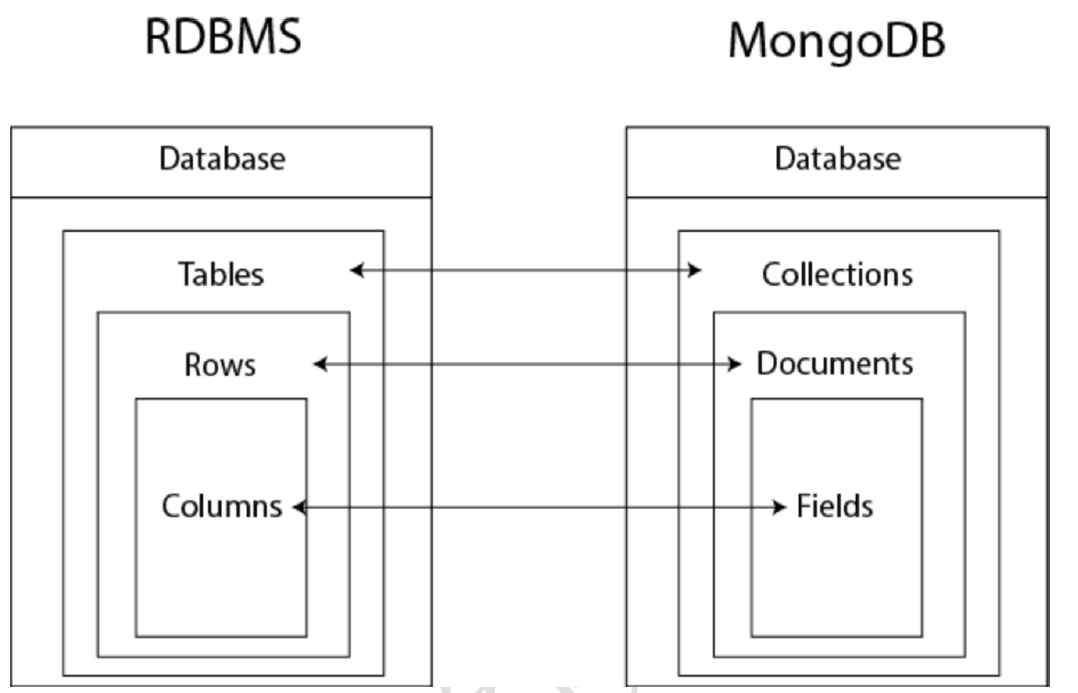
mongodb与关系型数据库结构比较
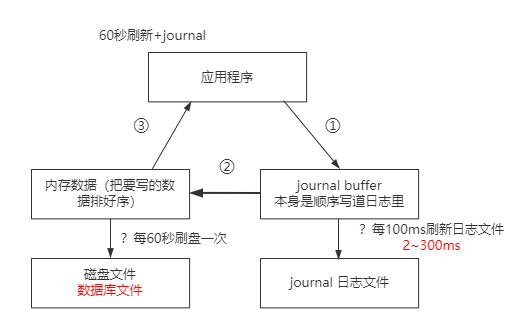
mongodb为什么快?
mongodb尽量将数据放在缓存中;
journal日志
mongodb的journal日志,是一种WAL日志,类似mysql的redo log;
mongodb集群
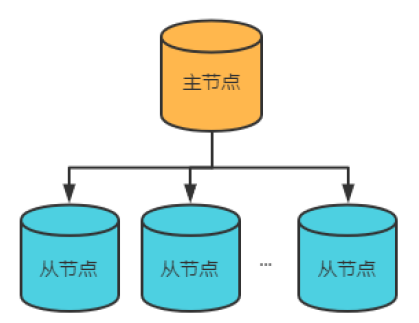
主从复制
主从复制,在主节点上进行写操作,从节点可以分担主节点的读压力;但是当主节点宕机后,无法对外提供服务;
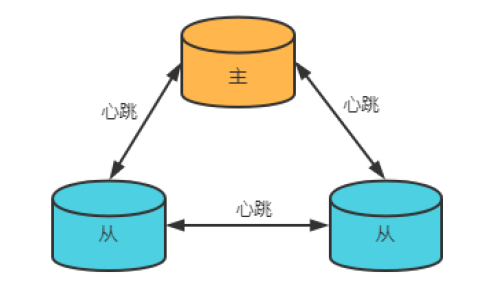
复制集
复制集主要对主从复制进行了优化,主节点宕机后能够选举出新的主节点,继续提供服务;
复制集工作原理
复制集中主要有三个角色:主节点(primary)、从节点(secondary)、仲裁者(Arbiter);主节点负责接收客户端的写请求等操作;从节点复制主节点的数据,也可以提供读服务;仲裁者则是辅助投票修复集群。
比较重要的两点:
- 主从节点如何进行数据的复制;通过oplog完成同步;
- 主节点宕机后,如何选举出新的主节点;通过心跳以及选举算法选出新的主节点。
oplog操作日志
类似于mysql中的binlog;主从节点通过发送oplog完成复制;oplog有时间戳,从节点通过以下操作完成数据同步:
- 查看自己oplog里面最后一条的时间戳;
- 查询主节点oplog里所有大于此时间戳的文档;
- 当那些应用到自己的库里,并添加写操作文档到自己的oplog里。
心跳机制
如果一定时间没有收到某个节点的心跳,则认为该节点已宕机;如果宕机的节点是Primary,Secondary会发起新的Primary选举;
如果主节点失去多数节点的心跳时,必须降级为从节点;
选举机制
从多个从节点中选举数据最新的从节点做为新的主节点;获得大多数选票的节点成为主节点;非仲裁节点可以配置优先级,范围为0~100,值越大越优先成为主节点;可以将性能好的机器的优先级设置的高一些;
数据回滚
主节点故障后,选出新的主节点;之后旧的主节点恢复工作,即使它的数据更新,仍然要以新的主节点的数据为准,旧的主节点要进行数据回滚;
mongodb分片
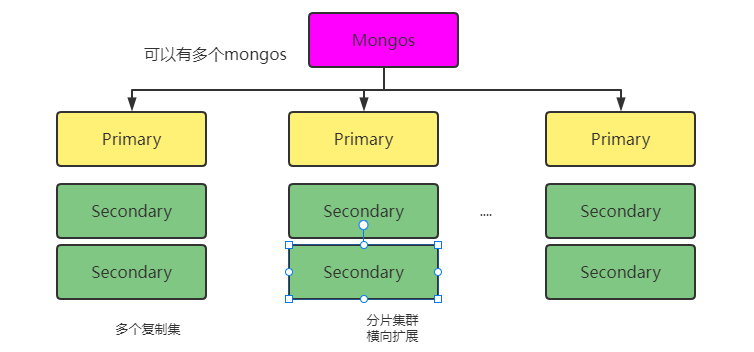
mongodb原生支持了自动分片,支持水平扩展;支持范围分片、哈希分片和标签分片等策略;
范围分片
根据key的范围进行分片;
优点:范围查询性能好,优化读;
缺点:数据分布可能会不均匀,容易有热点;
哈希分片
哈希分片最大的好处就是保证数据在各个节点上分布基本均匀;
优点:数据分布均匀,写优化;
缺点:范围查询效率低;
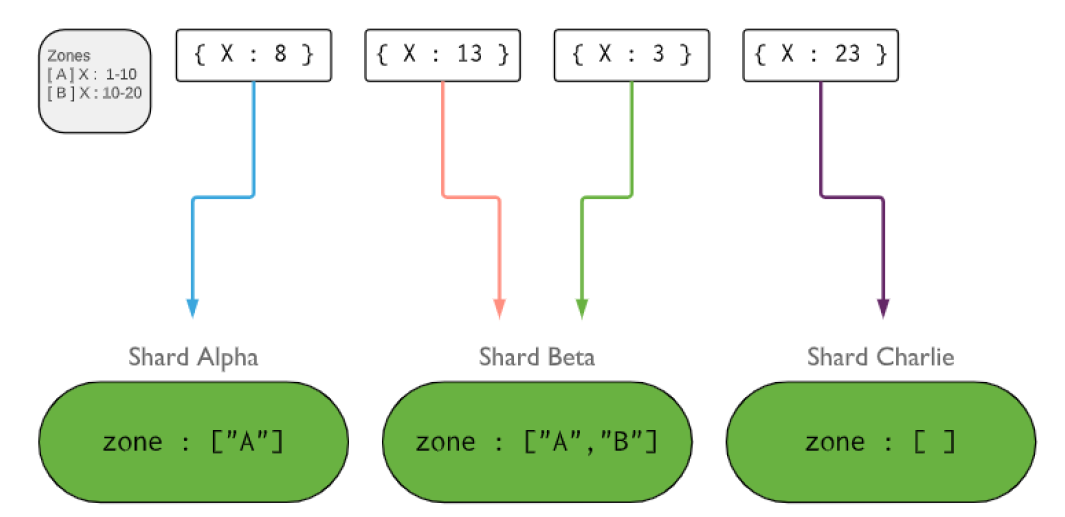
标签分片
标签分片也是基于key的范围进行的,对每一个节点打上一个或多个tag,每个tag对应key的一个范围;
写关注/读关注/读偏好
Write Concern
write concern表示事务是否关注写入的结果。
几个选项值:
- w:0;无需关注写入是否成功;
- w: 1~复制集最大节点数;默认情况下为1,表示写入到primary节点就开始往客户端发送确认写入成功;
- w:“majority”;大多数节点成功原则;
- w:“all”;所有节点都成功;
- j:true;默认情况为false,写入内存就算完成;如果设置为true,写道journal文件才算成功;
- wtimeout:写入超时时间;
设置示例:
writeConcern: {
w:“majority” // 大多数原则
j:true,
wtimeout: 5000,
}
使用示例:
db.user.insert({name: “congchp”}, {writeConcern: {w: “majority”}})
对于重要的数据可以应用w:“majority”,普通数据 w:1保证最佳性能;w设置的节点数越多,延迟就越大;
Read Preference
事务中使用readPreference来决定读取时从哪个节点读取;可方便的实现读写分离、就近读取策略;
可以设置为以下5个值:
- primary:默认模式,读操作只在主节点;主节点不可用,报错;
- primaryPreferred:首选主节点;主节点不可用,则从从节点读;
- secondary:读只在从节点;从节点不可用,报错;
- secondaryPreferred:首选从节点;
- nearest:读操作在最临近的节点;
Read Concern
readPreference决定从哪个节点读取,readConcern决定该节点的哪些数据是可读的;主要保证事务的隔离性,避免脏读;
主要的可选值:
local:默认值,数据写入本地;
majority:数据被写入大多数节点;
mongodb的readConcern默认使用local,readPreference是primary,就会有脏读的问题,例如,用户在主节点读取一条数据后,该节点未将数据同步至其它节点,就因为异常宕机或者网络故障,待主节点恢复后,需要将未同步至其它节点的数据进行回滚,就出现了脏读;
majority:数据被写入大多数节点;
mongodb的readConcern默认使用local,readPreference是primary,就会有脏读的问题,例如,用户在主节点读取一条数据后,该节点未将数据同步至其它节点,就因为异常宕机或者网络故障,待主节点恢复后,需要将未同步至其它节点的数据进行回滚,就出现了脏读;
readConcern设置为majority,保证读到的数据已经写入大多数节点,保证了事务的隔离性;

