Oracle-sql优化之统计信息
前言:
本文章主要讲述生产运维中常见的统计信息导致执行计划异常的情形以及如何确认统计信息是否存在问题,Oracle的执行计划生成是基于cost,而cost则是根据表的统计信息以及服务器性能指标去计算的,所以一个正确的统计信息对于执行计划的生成非常重要。
初始化测试数据:
#关闭动态收集,避免对测试造成影响alter system set optimizer_dynamic_sampling=0;#创建T1表create table t1(id number(10) primary key,id1 number(10),name varchar2(32),name1 varchar2(32),name2 varchar2(32),create_date date);create index t1_ind1 on t1(create_date);#插入500W数据declare v_count number(10):=0; v_interval number(10):=0;begin for i in 1..5000000 loop insert into T1 values(i,i+1,'aaaaaaaaa','bbbbbbbbbbbbbbbb','cccccccccccccc',sysdate-v_interval); v_count:=v_count+1; if v_count>=50000 THENcommit;v_count:=0;v_interval:=v_interval+1; end if; end loop; commit;end;/#创建表t2create table t2 as select * from t1 sample(30) where rownum 'SYS', tabname => 'T2', estimate_percent => 60, method_opt => 'for all columns size skewonly', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /场景一:表缺失统计信息或者统计信息过旧
由于初始化数据之后,我们并没有收集统计信息,所以现在表的统计信息是缺失的。
SELECT owner, table_name, num_rows, sample_size, round(sample_size / num_rows * 100) estimate_percent FROM DBA_TAB_STATISTICS WHERE table_name='T1'OWNER TABLE_NAME NUM_ROWS SAMPLE_SIZE ESTIMATE_PERCENT-------------------------------------------------- -------------------------------------------------- ---------- ----------- ----------------SYS T1执行以下查询。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*no_statistics */ count(name) from t1 where create_date>to_date('2022-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss');select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));执行计划走了索引扫描,执行时间2.09秒,估算的行数为35857,但实际扫描的行数为3580K。

通过10053获取执行计划的产生过程。
ALTER SESSION SET EVENTS='10053 trace name context forever, level 2';select /*no_statistics */ count(name) from t1 where create_date>to_date('2022-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss');ALTER SESSION SET EVENTS '10053 trace name context off';可以查看,由于统计信息为空,Oracle采用的是估算出的表的统计信息,但估算的统计信息与实际是差别很大的。
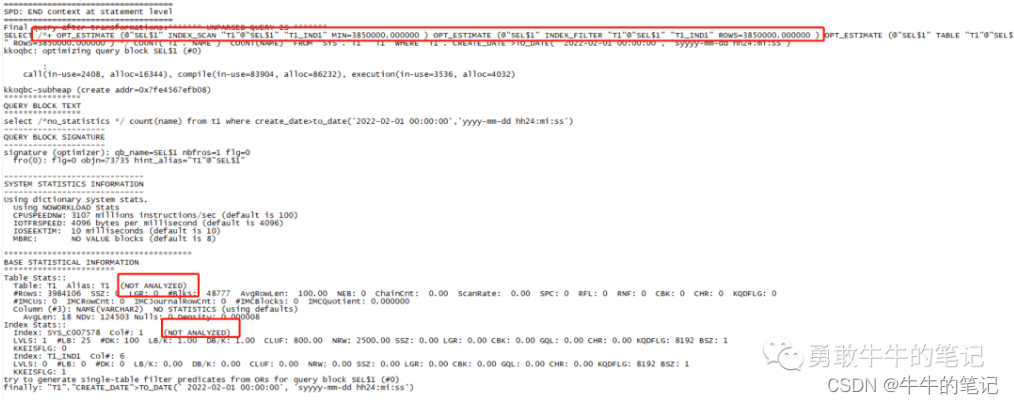
根据估算的统计信息,走全表扫描的cost为13253.374804,走索引的cost为0.000005,所以最终 优化器走了索引。

接下来,我们对表进行统计信息收集。
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SYS', tabname => 'T1', estimate_percent => 60, method_opt => 'for all columns size skewonly', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /再执行查询语句。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*statistics */ count(name) from t1 where create_date>to_date('2022-02-0100:00:00','yyyy-mm-dd hh24:mi:ss');select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));可以看到,这次执行计划走了全表扫描,执行时间0.47秒,估算的行数为3862K与实际扫描的行数3580K非常接近。
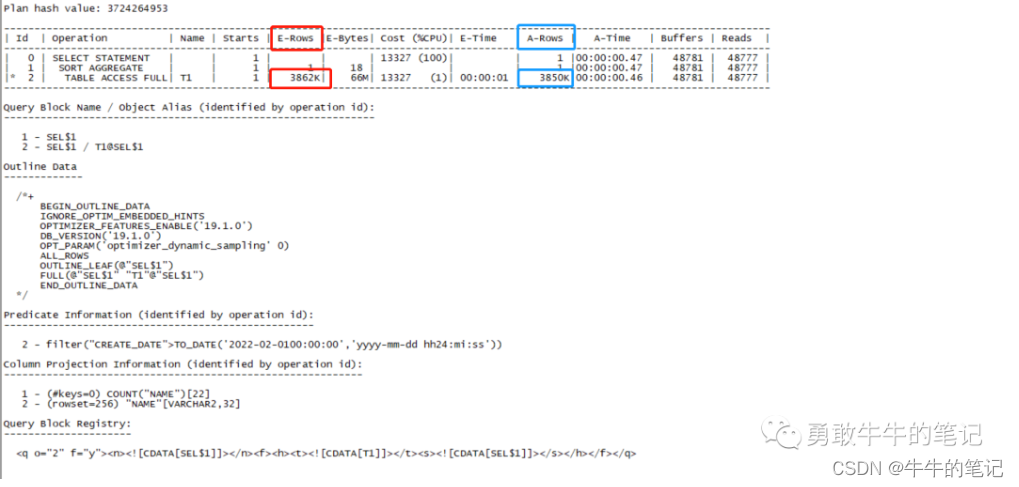
通过10053获取执行计划的产生过程。
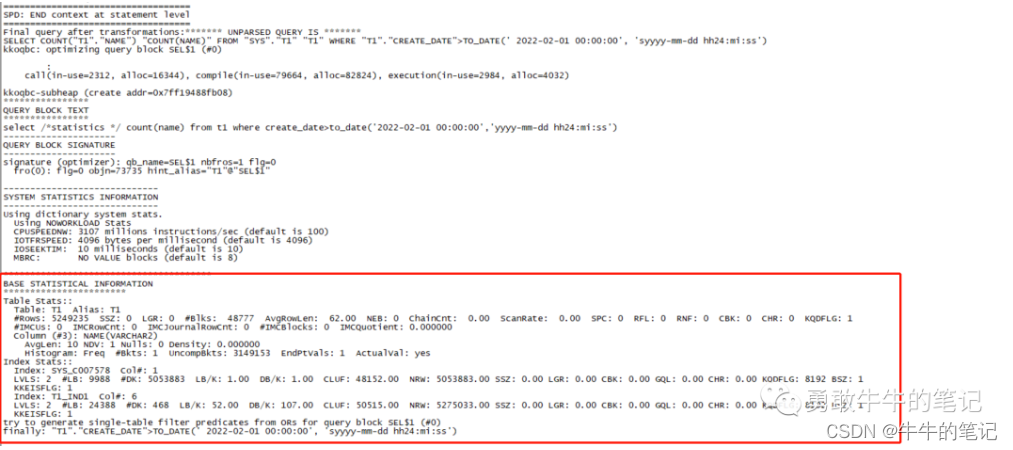
ALTER SESSION SET EVENTS='10053 trace name context forever, level 2';select /*statistics */ count(name) from t1 where create_date>to_date('2022-02-01 00:00:00','yyyy-mm-dd hh24:mi:ss');ALTER SESSION SET EVENTS '10053 trace name context off';可以看到,这次生成执行计划有了表的统计信息。
根据表的统计信息,走全表扫描的cost为13263.554628,走索引的cost为55119,所以最终优化器走了全表扫描。
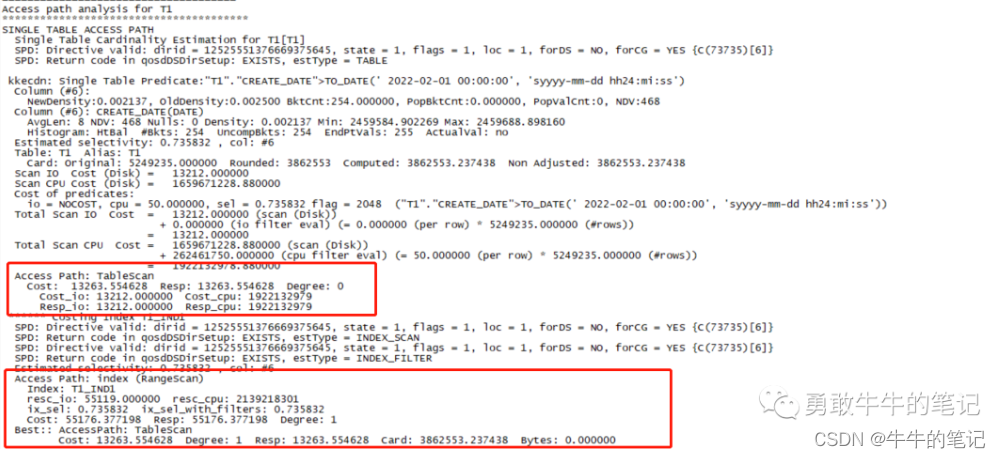
综上所述,我们可以看到一个正确的统计信息对于执行计划的重要性。
场景二:清理数据导致统计信息不准
在跑批的场景中,经常会对中间表进行清理数据的操作,重复流程为:跑批开始--->清理中间表--->插入数据--->处理数据,而有时候如果在清理数据--->插入数据期间刚好进行了统计信息收集,通常是数据库自己的定时统计信息收集,就会导致表的统计信息与实际的数据量差入很大的情况。
在这种情况下,往往会出现平常只需要跑几分钟的批量,由于执行计划的异常几个小时也跑不完。
清空t1数据。
truncate table t1;对t1执行统计信息收集。
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SYS', tabname => 'T1', estimate_percent => 60, method_opt => 'for all columns size skewonly', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /这时候的表统计信息都为0,因为没有数据。
set linesize 200set pagesize 200select a.column_name,a.owner,a.table_name, b.num_rows, a.num_nulls, a.num_distinct Cardinality, a.histogram, a.num_buckets, to_char(a.LAST_ANALYZED,'yyyy-mm-dd hh24:mi:ss') from dba_tab_col_statistics a, dba_tables b where a.owner = b.owner and a.table_name = b.table_name and a.table_name = 'T1'; 
再重新插入数据。
declare v_count number(10):=0; v_interval number(10):=0;begin for i in 1..5000000 loop insert into T1 values(i,i+1,'aaaaaaaaa','bbbbbbbbbbbbbbbb','cccccccccccccc',sysdate-v_interval); v_count:=v_count+1; if v_count>=50000 THENcommit;v_count:=0;v_interval:=v_interval+1; end if; end loop; commit;end;/执行sql,执行时间为1.33秒。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*no_statistics */ sum(t1.id1) from t1,t2 where t1.id=t2.id and t1.create_date>to_date('2022-03-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and t2.id1>10000;select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));通过执行计划可以看到,由于错误的统计信息,执行计划让T1做为了驱动表(统计信息里面数据量少,优化器认为是小表),这样最终会导致被驱动表走2500k次扫描,不是一个合理的执行计划。
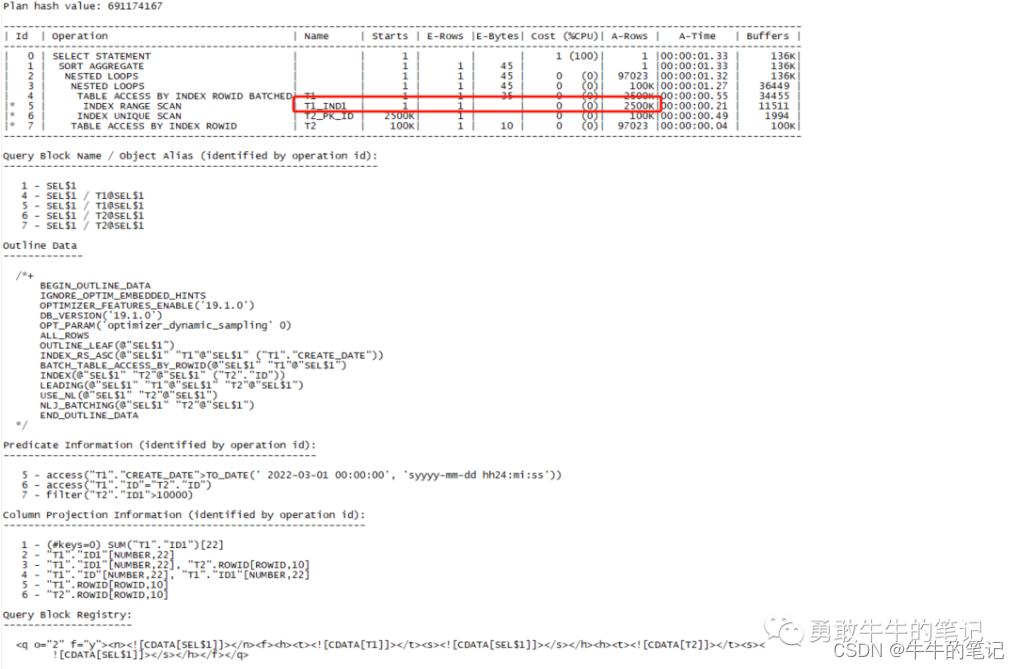
重新对T1表执行统计信息收集。
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SYS', tabname => 'T1', estimate_percent => 60, method_opt => 'for all columns size skewonly', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /重新执行sql,执行时间为0.6秒。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*statistics */ sum(t1.id1) from t1,t2 where t1.id=t2.id and t1.create_date>to_date('2022-03-01 00:00:00','yyyy-mm-dd hh24:mi:ss') and t2.id1>10000;select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));查看执行计划,T2为驱动表、T1为被驱动两表表全表扫描+hash join,因为T1,T2过滤之后的数据量还是很大,不适合走索引+nest loop,通过hash join关联走全表是一个合理的选择。
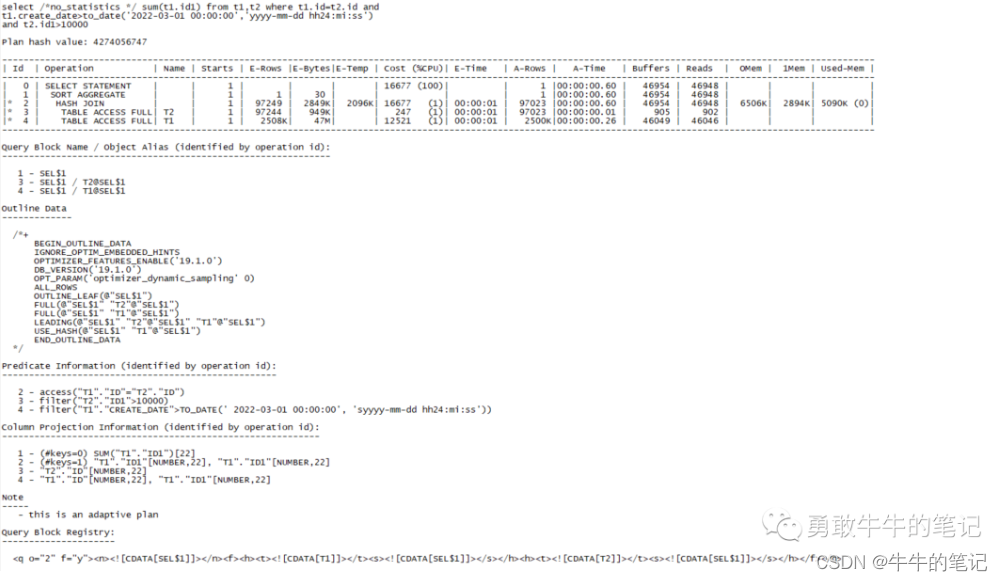
场景三: 新增数据导致统计信息不准
对于表每日新增的数据,由于统计信息不能及时的更新会导致执行计划的异常,特别是对于没有使用绑定变量的sql,每次执行都进行硬解析,执行计划异常的概率会更加大。
对T1表进行统计信息收集。
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SYS', tabname => 'T1', estimate_percent => 60, method_opt => 'for all columns size skewonly', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /执行sql查询2022-4-17号的数据,执行时间0.39秒。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*2022-4-17 */ sum(t1.id1) from t1,t2 where t1.id=t2.id and t1.create_date>to_date('2022-04-17 00:00:00','yyyy-mm-dd hh24:mi:ss') and t2.id1>10000;select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));T2作为驱动表、T1作为被驱动表走hash join,执行计划合理 。
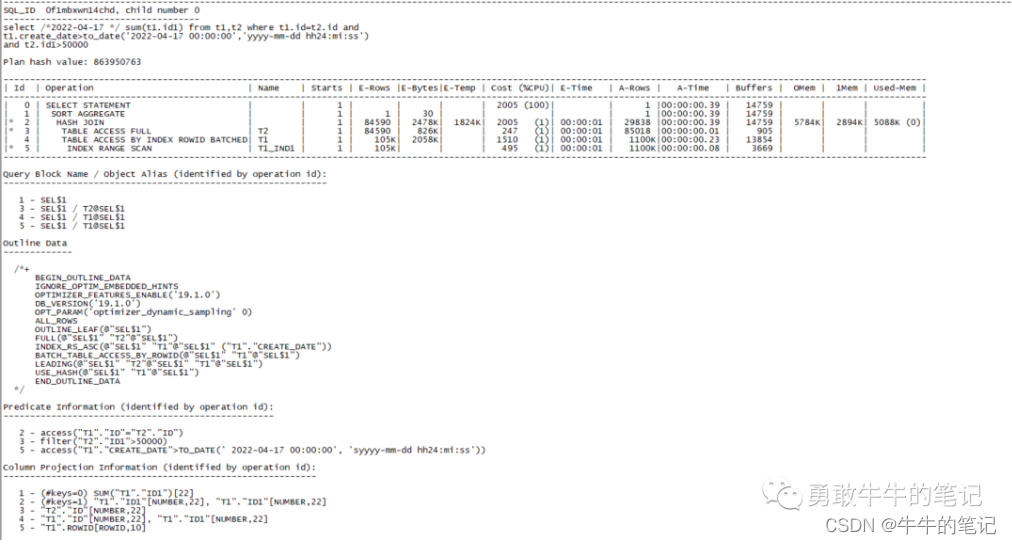
批量插入2022-04-19号的数据。
declare v_count number(10):=0; v_interval number(10):=0;begin for i in 5000001..6000000 loop insert into T1 values(i,i+1,'aaaaaaaaa','bbbbbbbbbbbbbbbb','cccccccccccccc',sysdate); v_count:=v_count+1; if v_count>=50000 THENcommit;v_count:=0;v_interval:=v_interval+1; end if; end loop; commit;end;/执行sql查询2022-4-19号的数据,0.59秒。
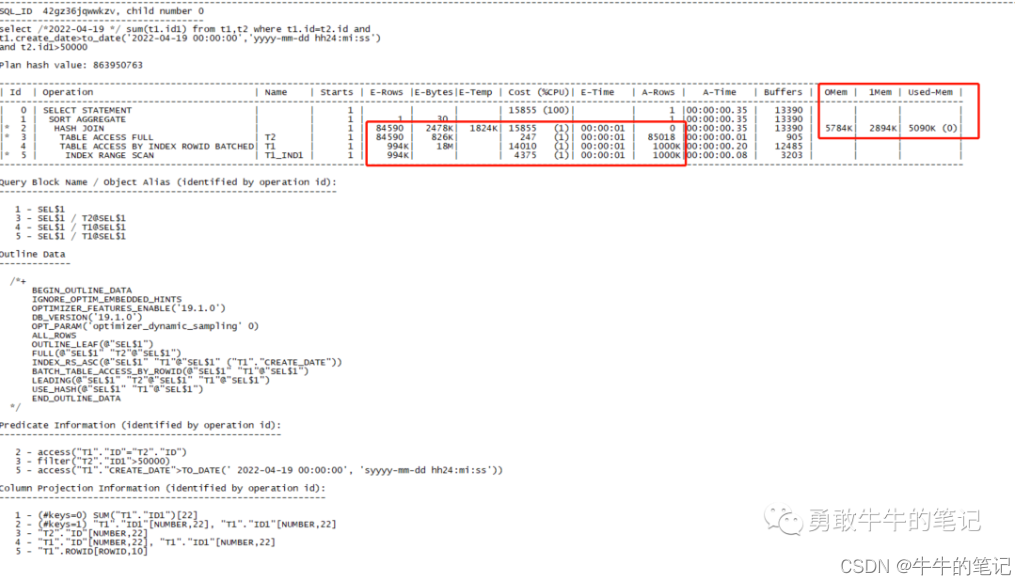
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*2022-04-19 */ sum(t1.id1) from t1,t2 where t1.id=t2.id and t1.create_date>to_date('2022-04-19 00:00:00','yyyy-mm-dd hh24:mi:ss') and t2.id1>50000;select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));可以看到执行计划用了T1表做驱动表,由于统计信息没有包含2022-04-19的信息,所以执行计划用了估算的统计信息,但T1表实际过滤之后还有1000K的数据,并且使用了hash join,需要消耗57M的内存,不是一个合理的执行计划。
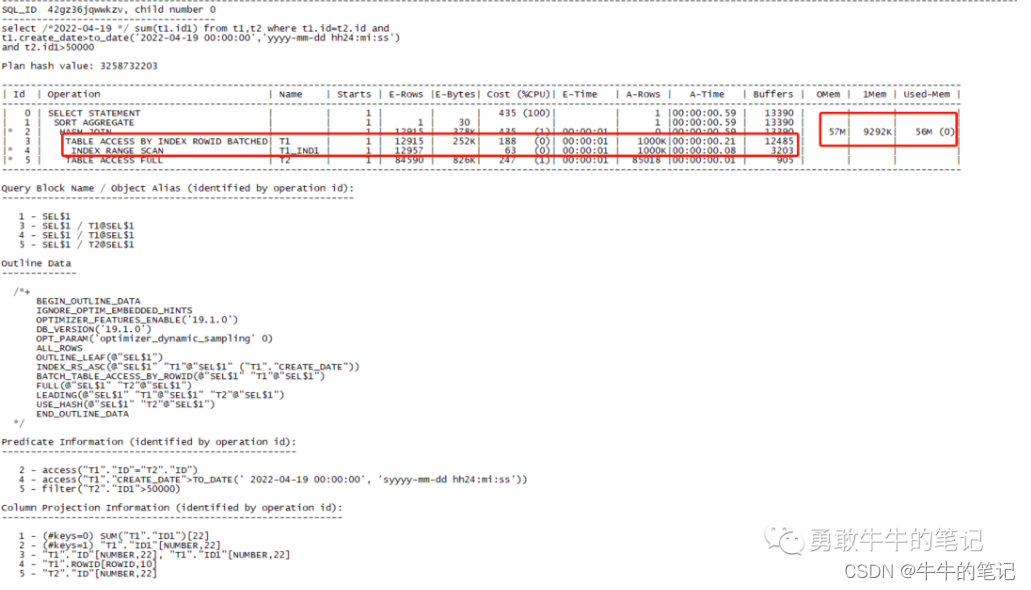
对T1表重新进行统计信息收集。
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SYS', tabname => 'T1', estimate_percent => 60, method_opt => 'for all columns size skewonly', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /再次执行sql查询2022-4-19号的数据,0.35秒。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*2022-04-19 */ sum(t1.id1) from t1,t2 where t1.id=t2.id and t1.create_date>to_date('2022-04-19 00:00:00','yyyy-mm-dd hh24:mi:ss') and t2.id1>50000;select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));查看这一次的执行计划,用了更小的表T2作为驱动表,依然是hash join但内存消耗只有5784k,并且速度更快,是一个合理的执行计划。
场景四:统计信息缺失直方图信息
如果表字段存在数据倾斜的情况,可能导致执行计划选择不合理的执行路径,为什么数据倾斜会导致不合理的执行路径?我们假设一个1000W的表,A列存放1000个不同值,其中a1值占了90%、其他值占剩下10%,那么对于其他10%的值走索引是个合理的执行计划,但对于占了90%的a1值来说,走索引的执行计划是不合理,这种情况我们需要对列索引收集直方图(数据的分布情况),来确保执行计划选择的正确性。
创建T3表,并插入倾斜数据channel_code,其中'1-1000'占20%,'888888888888'占80%。
#创建T3表create table t3(id number(10) primary key,id1 number(10),name varchar2(32),name1 varchar2(32),name2 varchar2(32),channel_code varchar2(32));create index t3_ind1 on t3(channel_code);#插入500W数据declare v_count number(10):=0; v_interval number(10):=0;begin for i in 1..1000000 loop insert into T3 values(i,i+1,'aaaaaaaaa','bbbbbbbbbbbbbbbb','cccccccccccccc',v_interval); v_count:=v_count+1; if v_count>=1000 THENcommit;v_count:=0;v_interval:=v_interval+1; end if; end loop; commit;end;/declare v_count number(10):=0; v_interval number(10):=0;begin for i in 1000001..5000000 loop insert into T3 values(i,i+1,'aaaaaaaaa','bbbbbbbbbbbbbbbb','cccccccccccccc','888888888888'); v_count:=v_count+1; if v_count>=100000 THENcommit;v_count:=0;v_interval:=v_interval+1; end if; end loop; commit;end;/进行统计信息收集,不收集直方图。
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SYS', tabname => 'T3', estimate_percent => 60, method_opt => 'for all columns size 1', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /查看表列的直方图信息,可以看到HISTOGRAM 为none,没有直方图信息。
set linesize 200col owner for a10col table_name for a15col column_name for a15alter session set nls_date_format='yyyy-mm-dd hh24:mi:ss';select owner,table_name,column_name,histogram,num_distinct,num_buckets,last_analyzedfrom dba_tab_columnswhere table_name='T3';
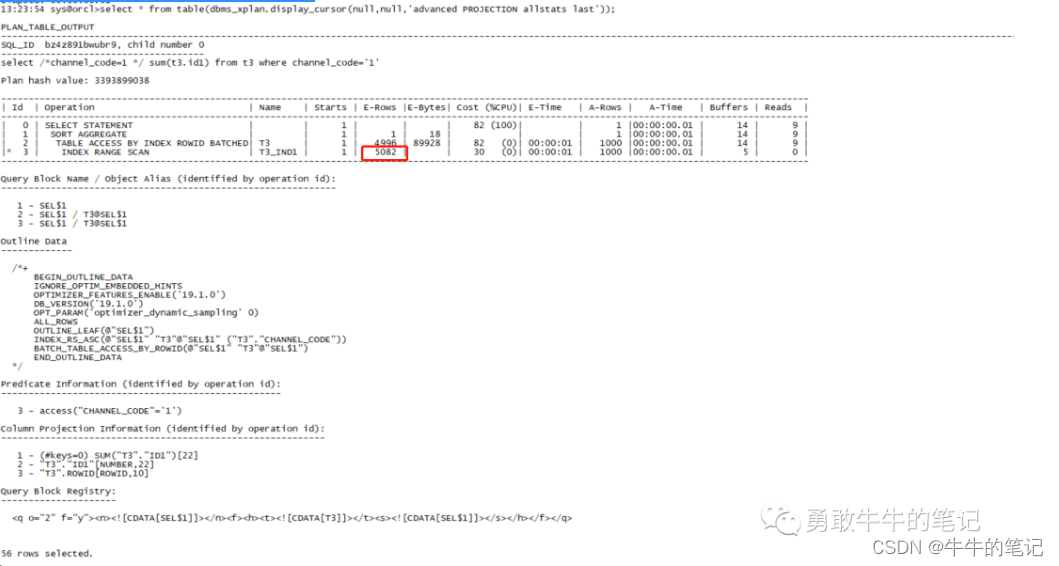
执行sql查询channel_code='1'。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*channel_code=1 */ sum(t3.id1) from t3 where channel_code='1';select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));可以看到走了T3_IND1的访问扫描,而估算的行数为5082,这个值为统计信息column_distinct/table_rows。
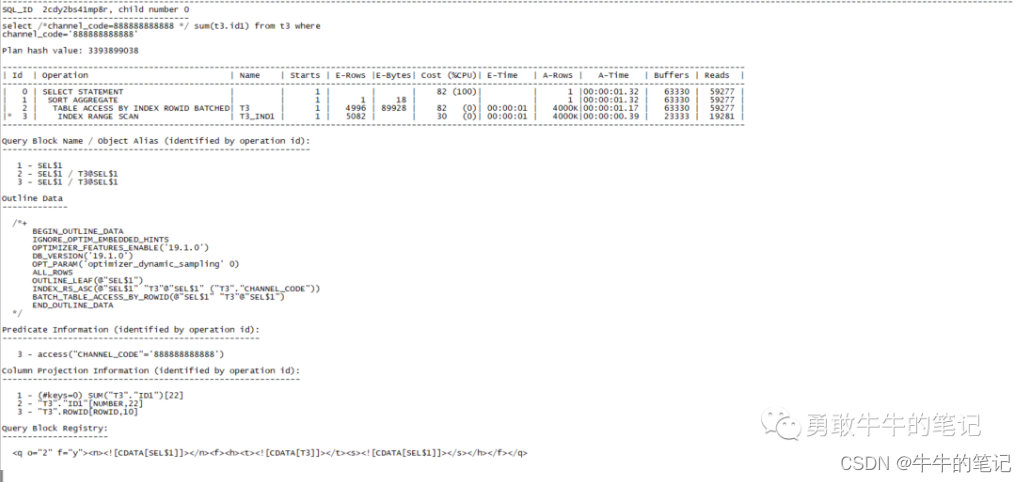
执行sql查询channel_code='888888888888'。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*channel_code=888888888888 */ sum(t3.id1) from t3 where channel_code='888888888888';select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));可以看到查询channel_code='888888888888',依然走的是索引范围扫描,估算的行依然是5082,但实际的行数为4000k,一致性读和物理读也很高。

对T3表重新进行统计信息收集,收集直方图。
BEGIN DBMS_STATS.GATHER_TABLE_STATS(ownname => 'SYS', tabname => 'T3', estimate_percent => 60, method_opt => 'for all columns size 245', no_invalidate => FALSE, degree => 1, cascade => TRUE); END; /查看表列的直方图信息,可以看到HISTOGRAM 为高度均衡直方图(height balanced)。

再次执行sql查询channel_code='888888888888'。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;select /*channel_code=888888888888 */ sum(t3.id1) from t3 where channel_code='888888888888';select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));可以看到查询走的是全表扫描,估算的行为3998k,一致性读和物理读比走索引下降了20%,执行时间也下降了1秒。

如何确认统计信息是否存在问题
1 通过执行计划确认统计信息是否正确,这种方法,需要我们获取实际的扫描行数并需要正常执行完sql。
要采用以下的方法执行sql,才能获取实际的扫描行数。
set linesize 200 pagesize 999set serveroutput offalter session set statistics_level=all;执行sql语句select * from table(dbms_xplan.display_cursor(null,null,'advanced PROJECTION allstats last'));通过比对估算E-ROWS 与实际行数A-ROWS的差异,来确认统计信息是否正确。

2 通过系统视图dba_tab_statistics查看是否过期,#STALE_STATS 显示为 YES 表示表的统计信息过期了。如果 STALE_STATS 显示为 NO,表示表的统计信息没有过期。
select owner, table_name , object_type, stale_stats, last_analyzed from dba_tab_statistics where owner = 'SYS' and table_name = 'T1';例如,现在查看表T1的统计信息stale_stats为NO,表示没有过期。

执行truncate 清空表数据。
 再次查看,会发现T1的统计信息stale_stats为YES,表示过期。
再次查看,会发现T1的统计信息stale_stats为YES,表示过期。

而过期的原因,我们可以通过dba_tab_modifications去获取。
#表记录的是上一次统计信息以来,表的DML操作记录select table_owner, table_name, inserts, updates, deletes, timestamp from dba_tab_modifications where table_owner = 'SYS' and table_name = 'T1';可以看到,过期的原因是因为delete了5948743行数据。

3 上述方法1,2都没有直观的去比较统计信息的差异,我们可以通过dbms_stats去比对统计信息的差异。
查询统计信息收集的历史执行情况。
select OBJ# ,ROWCNT,BLKCNT,AVGRLN,SAMPLESIZE,ANALYZETIME,SAVTIME from sys.WRI$_OPTSTAT_TAB_HISTORY where obj#=(select object_id from dba_objects where object_name='T1' and owner='SYS' and object_type='TABLE')order by ANALYZETIME;
比对当前执行计划跟2022-04-19 11:52:37的区别。
set longchunksize 99999;select *from table( dbms_stats.diff_table_stats_in_history( ownname => 'SYS', tabname => 'T1', time1 => systimestamp, time2 => to_timestamp(to_date('2022-04-19 11:52:37','yyyy-mm-dd hh24:mi:ss')) ));执行之后会生成一份报告,从报告我们可以看到当前的统计信息与之前的统计信息的差异,当前统计信息的行数为0,而之前旧的统计信息的行数接近500W,可以推断出这段时间表做了数据清理的工作。
#PCTTHRESHOLD : 10 表示差异超过10%的数据REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT----------#STATISTICS DIFFERENCE REPORT FOR:.................................TABLE : T1OWNER : SYSSOURCE A : Statistics as of 19-APR-22 07.25.10.225877 PM +08:00SOURCE B : Statistics as of 19-APR-22 11.52.37.000000 AM +08:00REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT----------PCTTHRESHOLD : 10~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~TABLE / (SUB)PARTITION STATISTICS DIFFERENCE:.............................................OBJECTNAME TYP SRC ROWSBLOCKS ROWLEN SAMPSIZE...............................................................................REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT----------T1 T A 0 0 0 0 B 4950363 48822 62 2970218~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~COLUMN STATISTICS DIFFERENCE:.............................COLUMN_NAME SRC NDV DENSITY HIST NULLS LEN MIN MAX SAMPSIZ...............................................................................REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT----------CREATE_DATE A 00 NO 00 NULL B 381 .003164556 YES 08 787A0 787A0 2968832IDA 00 NO 00 NULL B 4949143 .000000202 NO 06 C3060 C4056 2969486ID1 A 00 NO 00 NULL B 4948497 .000000202 NO 06 C3060 C406 2969098NAME A 00 NO 00 NULL B 1.000000101 YES 010 61616 61616 2969401REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT----------NAME1 A 00 NO 00 NULL B 1.000000100 YES 017 62626 62626 2971380NAME2 A 00 NO 00 NULL B 1.000000100 YES 015 63636 63636 2971287~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~INDEX / (SUB)PARTITION STATISTICS DIFFERENCE:.............................................REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT----------OBJECTNAME TYP SRC ROWS LEAFBLK DISTKEY LF/KY DB/KY CLF LVL SAMPSIZ............................................................................... INDEX: SYS_C007578 ..................SYS_C007578 I A 0000 0 00 0 B 5060837 10003 5060837 1 1 48137 2 3036502REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT---------- INDEX: T1_IND1 ..............T1_IND1 I A 0000 0 00 0 B 4966732 23065 381 60 124 47612 2 2980039#REPORT--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------MAXDIFFPCT如何避免统计信息对执行计划产生不利影响
1 要定期对统计信息过期的表做统计信息收集。
2 在进行大数据量的修改操作之后要进行统计信息收集。
3 sql语句要使用绑定变量,避免sql语句进行硬解析,每次硬解析的产生,都会重新解析生成执行计划,这会加大生成错误执行计划的概率。
4 对于已经确定最优的执行计划,可以人为的将执行计划与sql进行绑定,避免统计信息的影响。
5 合理使用dbms_stas对统计信息进行固化,避免统计信息变动对执行计划产生影响。
6 对于有索引的列,统计信息收集要包含直方图的采集。

