Java基础 | 15.Collection单列集合 -List接口与Set接口
文章目录
- 参考视频
- 1.单列集合概述
-
- 1.1.整体总述
- 1.2.单列集合选型
- 2.单列集合遍历方法
-
- 适用List和Set:使用Iterator迭代器迭代、forEach循环
- 仅适用List:普通for循环
- 3.List接口的常用实现类
-
- 3.1.ArrayList(线程不安全,类比StringBuilder) - 1.5倍扩容
- 3.2.Vector(线程安全,类比StringBuffer) - 2倍扩容
- 3.3.LinkedList(双向链表)
- 4.Set接口的常用实现类
-
- 4.1.HashSet(无序,底层为HashMap)
- 4.2.LinkedHashSet(存取同序,底层是LinkedHashMap)
- 4.3.TreeSet(默认自然排序,底层是TreeMap)
参考视频
【韩顺平讲Java】Java集合专题
1.单列集合概述
1.1.整体总述
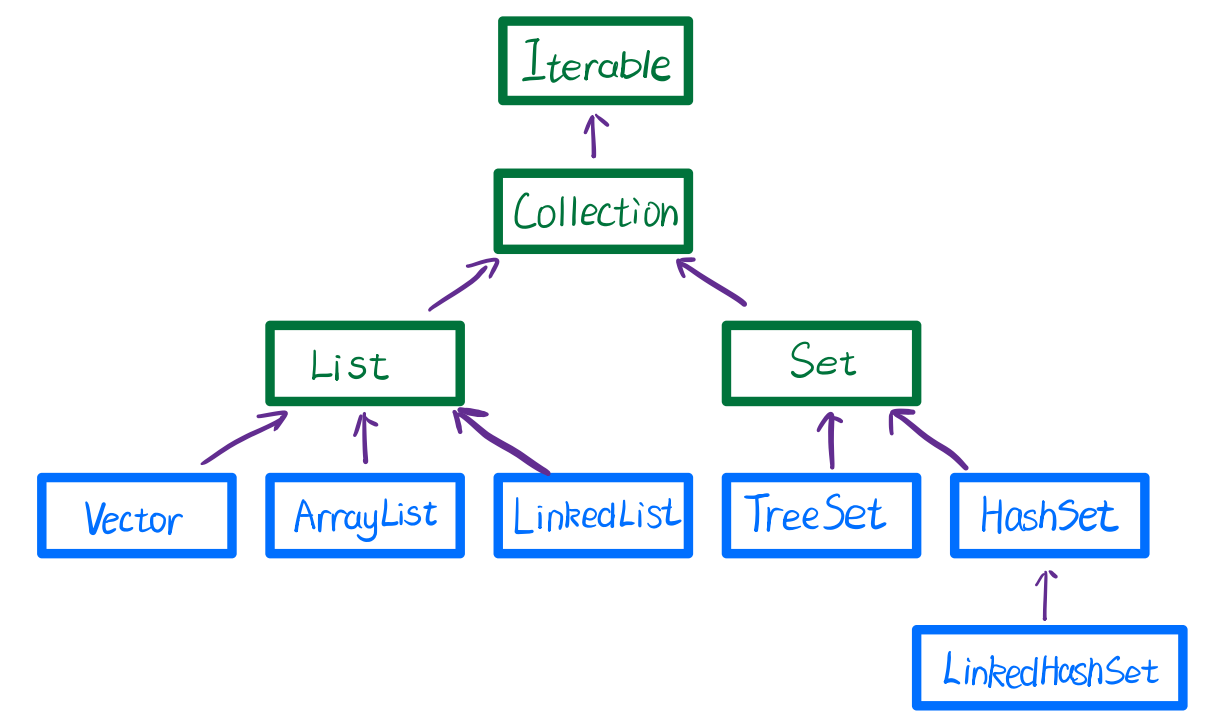
- List接口:元素有序,支持下标,可重复。
- Set接口:不一定有序(HashSet无序),有序的支持下标,不允许重复。
集合可动态保存任意个对象(Collection.addAll(Collection)),且类型可以不同(前提是定义泛型时,类型必须是高级别类型,常见为Object)
集合提供了一系列操作集合的方法,且集合可以随意拓展(底层代码有扩容机制),增删相比数组而言更加友好。
1.2.单列集合选型
-
允许重复:
– 增删多:选链表,即LinkedList,链表增删方便,不用维护索引;
– 查改多:选数组,删除数据时后续索引都将改变,通常用以下两种:
------ ArrayList,线程不安全,但效率高,开发首选;
------ Vector,线程安全,但效率低,通过synchronized保证线程同步。
-
不允许重复:
– 无序:HashSet,底层是HashMap;
– 存取同序:LinkedHashSet,底层是LinkedHashMap;
– 自然排序:TreeSet,底层是TreeMap。
2.单列集合遍历方法
适用List和Set:使用Iterator迭代器迭代、forEach循环
forEach的底层实际上就是使用迭代器迭代。因此这里重点讲述如何使用迭代器进行迭代。
Collection接口继承自Iterable接口,因此拥有继承的抽象方法Collection.iterator( ),任何Collection实现类对象都可以调用该方法来获取本集合的迭代器Iterator。
迭代器包含了集合中的所有元素,拥有指针,默认指向顶部的空值。
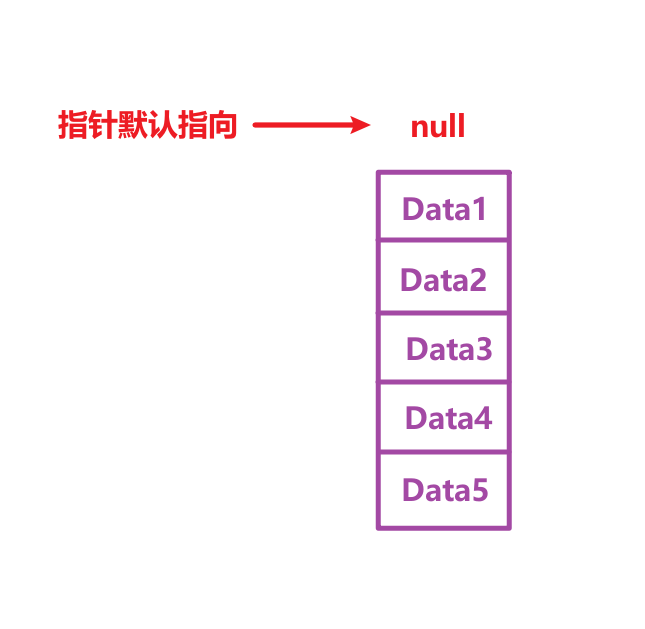
核心方法有两个:
- Iterator.hasNext( ):判断是否有下一个元素
- Iterator.next( ):将指针移动到下一位,并返回移动后指针所指数据,若没有下一位会抛出异常(NoSuchElementException)
据此,使用迭代器遍历集合的方法如下:
// 集合Collection<Integer> collection = new ArrayList<>();// 获取迭代器Iterator<Integer> iterator = colletcion.iterator();// 遍历while(iterator.hasNext()){ // 指针下移并获取移动后的数据 Integer data = iterator.next(); System.out.println(data);}注意:若希望重置迭代器,重新调用iterator( )即可。
仅适用List:普通for循环
只有List集合才允许通过索引获取数据(Vector、ArrayList、LinkedList等),这些集合就可以通过普通for循环来获取数据。
3.List接口的常用实现类
3.1.ArrayList(线程不安全,类比StringBuilder) - 1.5倍扩容
- 可存储null,允许重复
- 与Vector最大的区别:没有使用synchronized修饰方法,导致线程不安全。
- 底层本质上是一个数组elementData[ ],会在指定条件下扩容
如何扩容:
- 创建新的数组对象,容量为原来的1.5倍;
- 遍历旧数组,逐个加入到新的数组中;
- 将新数组重新赋值给elementData,此时旧数组将被回收。
扩容条件
- 无参构造创建ArrayList对象时,初始长度为0;首次添加扩为10;此后每当容量不足,就将容量变为原来的1.5倍。
- 有参构造创建ArrayList对象时,初始长度就为设定值;此后每当容量不足,就将容量变为原来的1.5倍。
3.2.Vector(线程安全,类比StringBuffer) - 2倍扩容
与ArrayList底层原理一致。所有方法都用synchronized修饰,保证线程安全,但效率低下,因此不常用。
扩容机制与ArrayList略有不同,无参构造默认容量为10,每次均为2倍扩容。
3.3.LinkedList(双向链表)
线程不安全,没有实现同步
双向链表意味着链表有first、last,对应的有addFirst(Object)和addLast(Object)
所有的结点(LinkedList$Node)都是双向的,有prev、item和next
4.Set接口的常用实现类
- 所有的Set接口实现类都没有索引,无法通过索引取值,只能通过迭代器遍历;
- 所有的Set底层都是由Map支撑的,对Set的操作本质上是对Map的操作。
详细了解Map,请移步13.Map双列集合 - Map接口;
详细了解HashMap,请移步14.HashMap新增结点机制、扩容机制、树化机制。
4.1.HashSet(无序,底层为HashMap)
- 底层是HashMap:数组 + 链表(+ 红黑树 );
- 可存储null,但Set不允许重复,因此只能有一个null;
// HashSet构造方法public HashSet(){ map = new HashMap<>();}底层本质是HashMap,意味着所有对HashSet的操作,本质上都是对HashMap的操作。举个例子:HashSet.add( )本质上是在执行HashMap.put( )
这里提一下HashMap.put( )的执行流程:
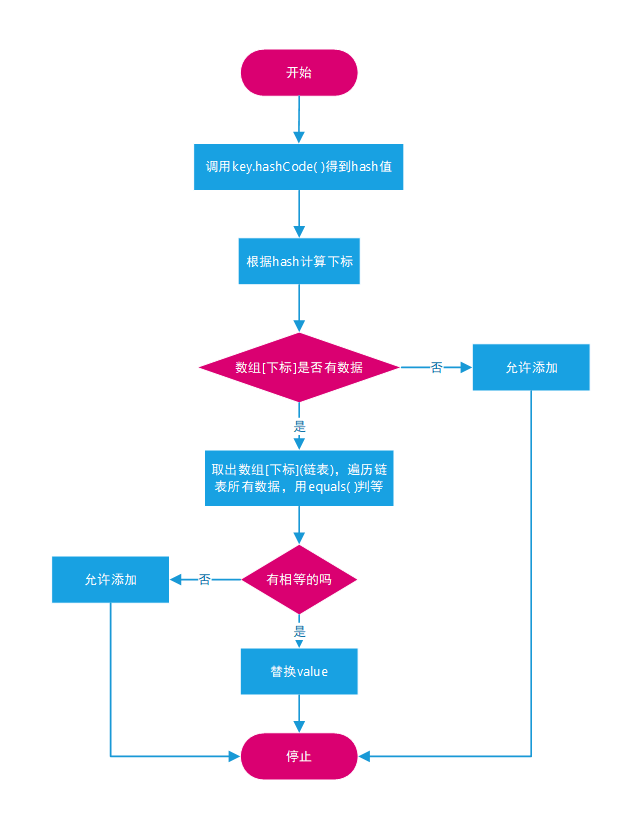
简单地说,就是先对key调用Object.hashCode( )获取hash,根据公示与hash值计算下标,然后从对应的链表或红黑树中,对value调用Object.equals(Object)来判断是否有相同数据。
正因如此,自定义类在创建时,需要重写hashCode( )和equals(Object)。
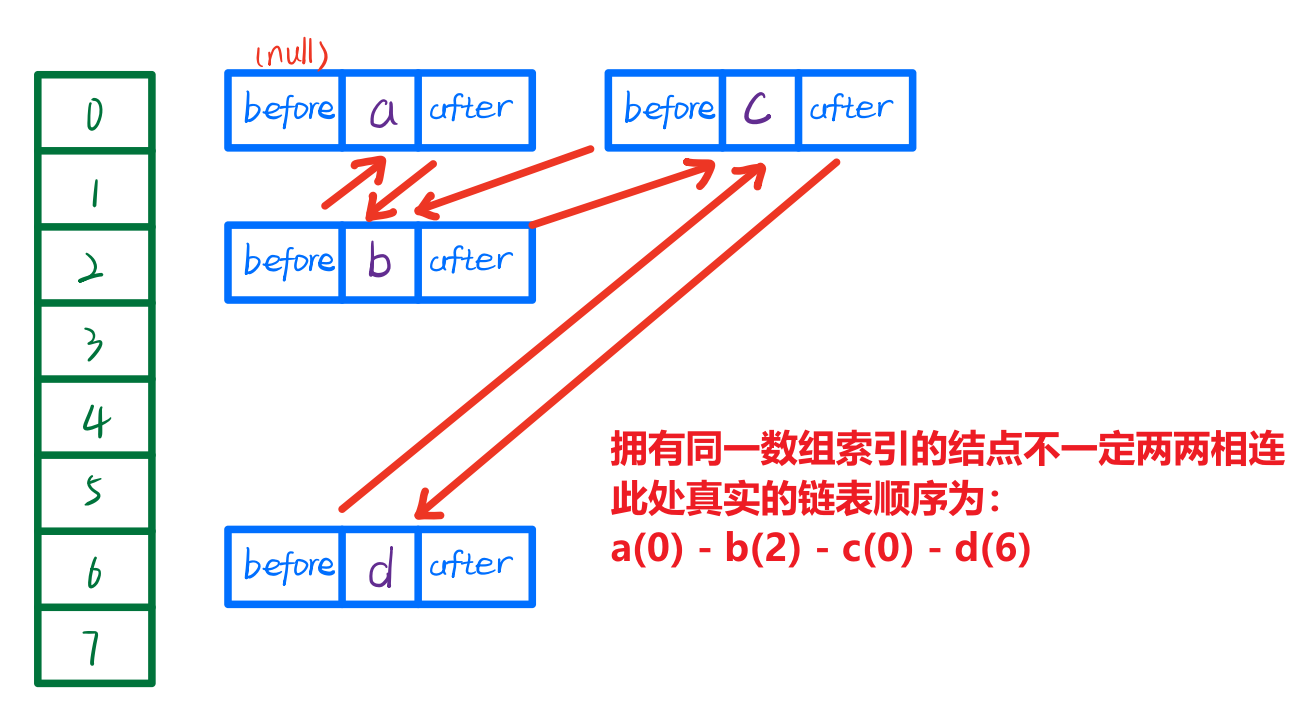
4.2.LinkedHashSet(存取同序,底层是LinkedHashMap)
- 底层是LinkedHashMap:数组 + 双向链表;
- 存取同序:通过双向链表保证次序;
- 继承自HashSet(自然实现了Set接口);
// 定义在HashSet中的构造方法// LinkedHashSet创建对象时借助super关键字调用HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }LinkedHashSet与HashSet的区别在于:底层是LinkedHashMap,结构为 数组 + 双向链表,依靠双向链表来保证存取同序,不会转换成红黑树。
LinkedHashSet(LinkedHashMap)中结点类型为LinkedHashMap Entry∗∗,它继承自∗∗HashMap Entry,它继承自HashMapEntry∗∗</font>,它继承自<fontcolor="green">∗∗HashMapNode,每个结点都有一个after指针和before指针,废弃了next指针。
4.3.TreeSet(默认自然排序,底层是TreeMap)
- 底层是TreeMap:数组 + 红黑树;
- 默认自然排序(即字典序)。
- 根据TreeNode的特性,存储时键与值都不可为null。
TreeSet(NavigableMap<E,Object> m) { this.m = m;}public TreeSet() { this(new TreeMap<E,Object>());}TreeMap在存取数据时会以字典序进行排序。

