selenium自动化测试哔哩哔哩信息保存至Excel实战案例
文章目录
-
- 前言
- 明确目标
- 最终效果
- 开发环境
- 思路分析
- 实现步骤
- 运行效果
- 以下是全部代码
前言
最近在B站学习知识,于是看完了视频就想着练习一下巩固一下知识,就地取材的做了个B站selenium小项目,感觉还挺适合新手入门的,于是迫不及待想分享给大家。希望大家都能学到新知识,本章说的还是selenium自动化测试实现。

明确目标
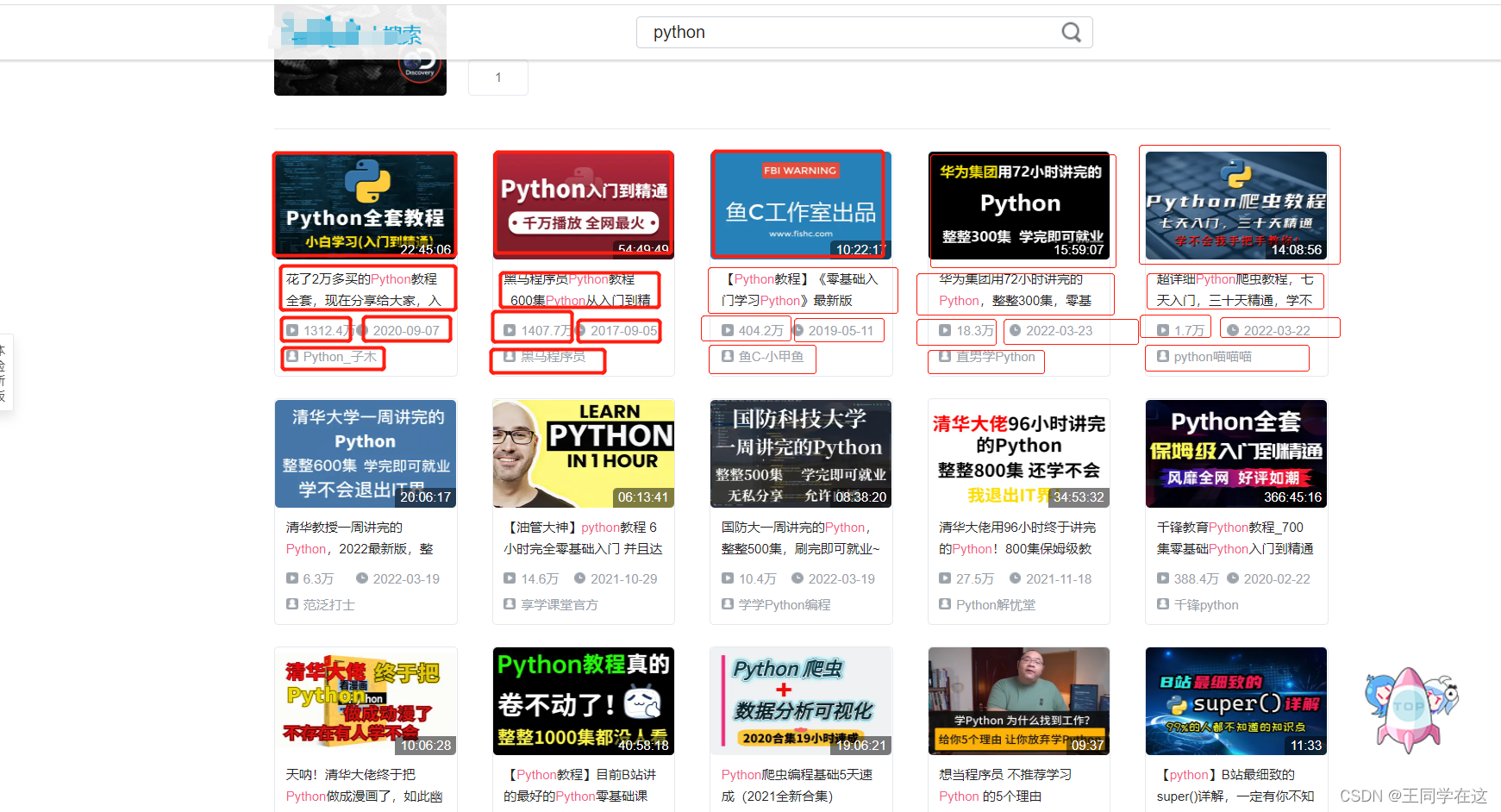
首先开始工作之前知道我们需要哪些信息,这里我框起来的是我需要的信息,(标题,封面,up博主,时间,观看次数)。
最终效果
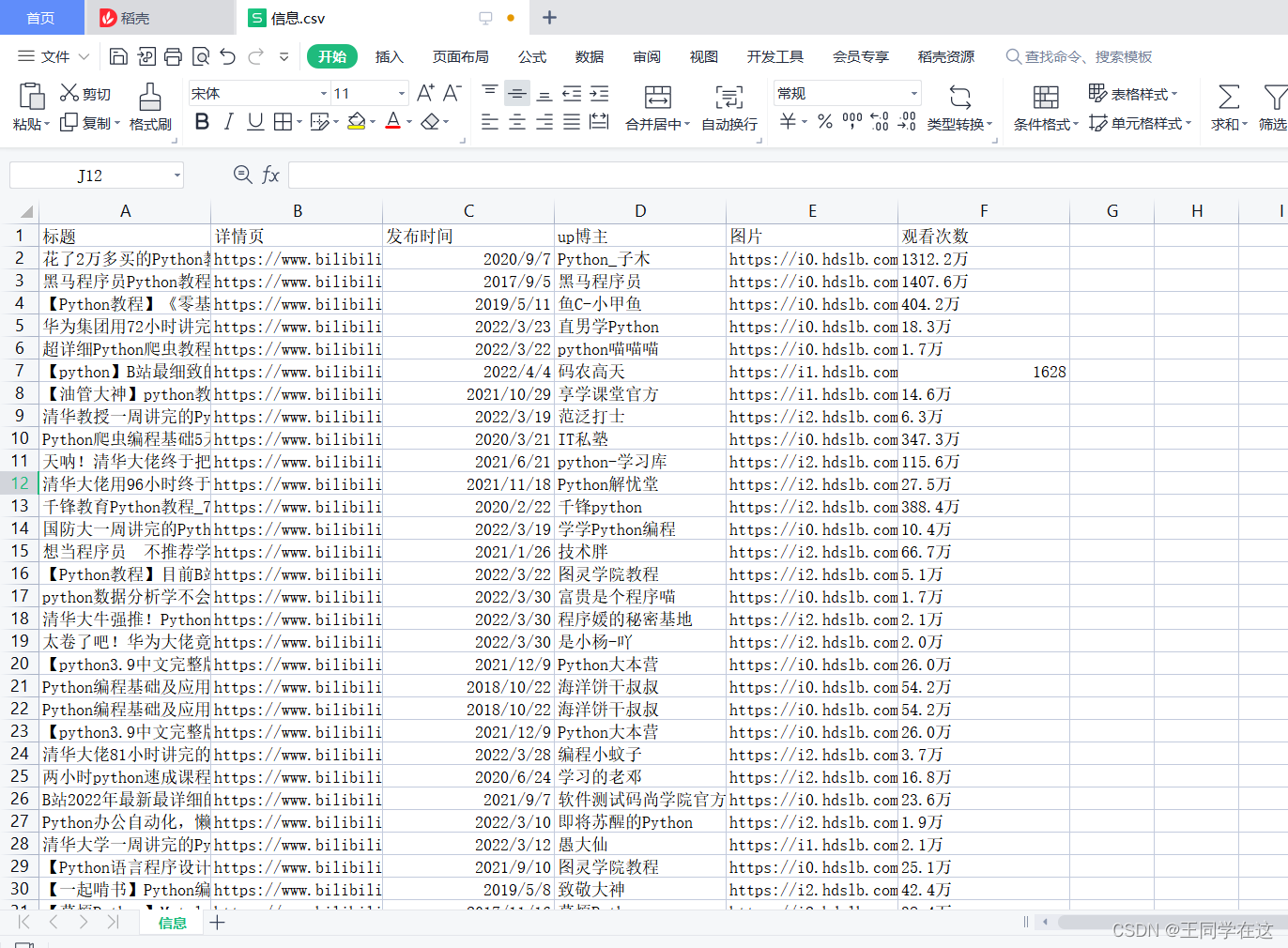
先看下程序实现的最终效果,需要的数据进行了保存。


看完了接下来开始操作吧

开发环境
配置好selenium运行的环境,及相关库,(可在博客上查找)
工具:pycharm
版本:Python 3.8
思路分析
操作pyCharm打开浏览器对象,观察页面源码,用selenium定位元素的方法找到输入框和搜索框,
(注意要看一下页面源码这两个框的位置在子页面中还是在当前页面,如果在子页面中就要切换进子页面中才能定位到元素,在当前页面就可以直接上selenium定位元素)。找到输入框就可以操作selenium输入信息,并点击搜索,信息搜索出来后selenium定位元素找到全部的视频div,遍历每个div,用selenium定位我们需要的信息并提取出来。

实现步骤
导入相关库

操作pyCharm打开浏览器对象,设置窗口最大化,打开浏览器后等待输入框元素加载出来后输入关键字python并点击搜索,然后切换窗口句柄对搜索页面操作,selenium定位元素回到旧版页面并点击,这样哔哩页面就切换回旧版的页面,最后返回driver让其他函数进行操作。

搜索信息出来后,selenium定位页面底部的一个元素(这里我定位的元素是下一页)设置动作链移动到页面底部,防止有些页面需要异步加载数据出来。

selenium找到全部的li,遍历每一个li再用selenium提供的定位元素方法找我需要的信息提取即可,提取完就构建字典储存数据,并在空列表的末尾增添我们字典,再调用其他函数传参对封面进行保存。

翻页实现,在页面底部我们观察发现所需的数据有50页,那么我们就可以定位到这个下一页的标签,让它每保存完一页就点击下一页,从而实现翻页的效果。
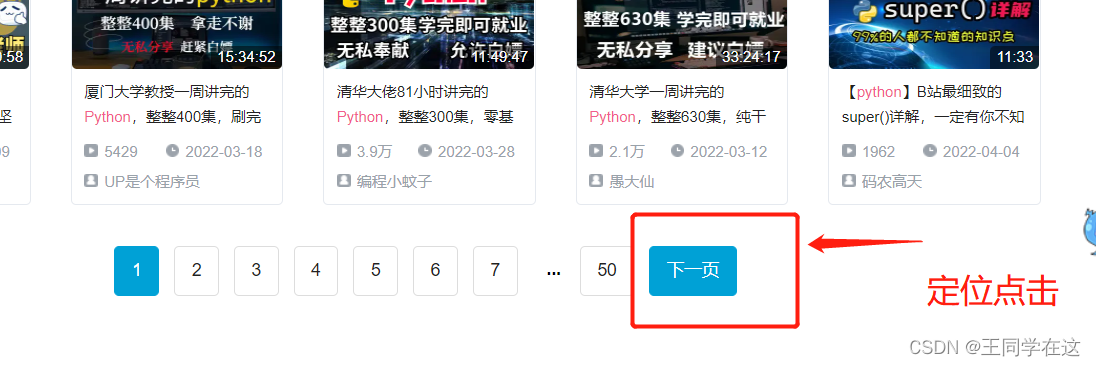
定位到下一页,如果没一页能找得到这个下一页的标签就点击,否则跳出循环。

下图函数是实现对封面进行储存。

数据保存至Exel中

运行效果

到这里程序就完成了,运行代码时注意保持网络畅通,如果网速太慢可能会失败,建议在网络好的环境下运行。

以下是全部代码
from selenium import webdriverfrom selenium.webdriver.common.by import Byfrom selenium.webdriver.support.wait import WebDriverWaitfrom selenium.webdriver import ActionChains # 动作链from selenium.webdriver import ChromeOptions # 浏览器配置from selenium.webdriver.support import expected_conditions as ECimport timeimport pandas as pdimport os.pathimport requestspage = 1def get_serch(url): # 创建浏览器对象 driver = webdriver.Chrome() # 时间等待 wait = WebDriverWait(driver,10) # 发送请求 driver.get(url=url) # 窗口最大化 driver.maximize_window() time.sleep(1) # 直到出现这个元素 wait.until(EC.presence_of_element_located((By.TAG_NAME,'input'))) # input输入 entry = driver.find_element(By.TAG_NAME,'input') entry.send_keys('python') time.sleep(1) # click button = driver.find_element(By.XPATH,'//div[@class="nav-search-btn"]') button.click() # 切换窗口视角 driver.switch_to.window(driver.window_handles[-1]) time.sleep(2) # 回到旧版 dic = driver.find_element(By.XPATH,'//*[@id="i_cecream"]/div[1]/div[2]/div/div/div/div/button[1]') dic.click() time.sleep(1) return driverdef get_data(driver): all_data = [] # 空列表 num = 1 while num <= 50: print(f'=====================================正在保存第{num}页的数据内容=================================') # 动作链 try: action = driver.find_element(By.XPATH, '//*[@class="page-item next"]/button') ActionChains(driver).move_to_element(action).perform() except: print('==============================没有下一页了========================') # 全部视频 time.sleep(1) all_li = driver.find_elements(By.XPATH,'//*[@id="all-list"]/div[1]/div[2]/ul[2]/li') # 判断空列表 if all_li == []: all_li = driver.find_elements(By.XPATH, '//*[@id="all-list"]/div[1]/ul/li') elif all_li != []: all_li = driver.find_elements(By.XPATH,'//*[@id="all-list"]/div[1]/div[2]/ul[2]/li') time.sleep(1) for i in all_li: ditail = i.find_element(By.XPATH,'./div/div[1]/a').get_attribute('href') title = i.find_element(By.XPATH,'./div/div[1]/a').get_attribute('title') new_time = i.find_element(By.XPATH,'./div/div[3]/span[3]').text user = i.find_element(By.XPATH,'./div/div[3]/span[4]').text images = i.find_element(By.XPATH,'./a/div/div[1]/img').get_attribute('src') if images == '': images = 'https://i0.hdslb.com/bfs/archive/9974b552950679b49c0e73d10bd55c29fcec35b9.png@400w_250h_1c.webp' watch = i.find_element(By.XPATH,'./div/div[3]/span[1]').text item = { '标题': title, '详情页': ditail, '发布时间': new_time, 'up博主': user, '图片': images, '观看次数': watch } print(item) all_data.append(item) save_Images(title,images) time.sleep(1) try: # 翻页 net_page = driver.find_element(By.XPATH,'//*[@class="page-item next"]/button') net_page.click() time.sleep(3) num += 1 except: break return all_datadef save_csv(all_data): df = pd.DataFrame(all_data) df.to_csv('哔哩.csv',index=False)def save_Images(title,images): global page if not os.path.exists('./哔哩/'): os.mkdir('./哔哩/') response = requests.get(url=images).content with open('./哔哩/' + str(page) + '.jpg',mode='wb')as f: f.write(response) print('正在保存图片:' + title) page += 1def mian(): url = 'https://www.bilibili.com/' driver = get_serch(url) all_data = get_data(driver) save_csv(all_data)if __name__ == '__main__': mian()
