Python零基础入门篇 - 63 - 持久化学生信息库的完善
| 无题 |
|---|
| 🎉 三载辛苦缘离别,今兮说与山鬼听。 🎉 |
| 🎉 惊觉山鬼不识字,西风难寐不动情。 🎉 |
前言:
✌ 作者简介:渴望力量的哈士奇,大家可以叫我 🐶哈士奇🐶 。(我真的有一只哈士奇)
📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
💬 人生格言:优于别人,并不高贵,真正的高贵应该是优于过去的自己。💬
🔥 如果感觉博主的文章还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主哦
📕 系列专栏:
👍 Python全栈系列 - [更新中] 【 本文在该系列】
👋 网安之路系列
🍋 网安之路踩坑篇
🍋 网安知识扫盲篇
🍋 Vulhub 漏洞复现篇
🍋 Shell脚本编程篇
🍋 Web攻防篇 2021年9月3日停止更新,转战先知等安全社区
🍋 渗透工具使用集锦 2021年9月3日停止更新,转战先知等安全社区
⭐️ 点点点工程师系列
🍹 测试神器 - Charles 篇
🍹 测试神器 - Fiddler 篇
🍹 测试神器 - Jmeter 篇
🍹 自动化 - RobotFrameWork 系列
🍹 自动化 - 基于 JAVA 实现的WEB端UI自动化
🍹 自动化 - 基于 MonkeyRunner 实现的APP端UI自动化


至今为止,我们学习了 python 中的包与模块,在这期间我们同事也学习了如何读取写入文件。今天我们要重新拿出之前的练习,学生信息库。
在此之前,我们的学生信息都是存在于 字典 中的,程序一但退出将会全部消失。所在在一开始,我们就定义了一些学生的初始化信息,今天我们就要做学生信息的持久化。
文章目录
-
- 学生信息库完善的需求
- 脚本完善后的源码
- 脚本演示需准备的学生信息与演示结果
- 总结梳理
学生信息库完善的需求
所谓持久化,就是将学生的信息数据存入磁盘中永久的保存。所以今天我们主要做两件事:
- 1、将学生信息存入到一个 json 文件中,并且添加
读与写的操作(读写 json 文件 的函数) - 2、将对于用户操作文件的记录进行日志记录,用户
添加、修改和删除的行为记录到日志文件中;添加与修改的行为使用 info 级别,而删除的行为则使用 warn 警告级别记录在日志文件。(让我们知道什么时间执行了添加与修改操作,什么时间执行了删除操作。)
脚本完善后的源码
完善后的脚本如下:
# coding:utf-8""" @Author:Neo @Date:2020/1/27 @Filename:students_info.py @Software:Pycharm"""import loggingimport jsonimport os''' 学生信息库 1: 将学生信息存入一个json文件中, 添加读与写json的函数 2: 我们要将用户添加修改和删除的行为记录到日志中,添加与修改都用info代表 而delete将要用warn警告来提示'''class NotArgError(Exception): def __init__(self, message): self.message = messageclass MissPathError(Exception): # 自定义一个异常类,判断存储学生信息的文件是否存在 def __init__(self, message): self.message = messageclass FormatError(Exception):# 自定义一个异常类,判断存储学生信息的文件是否是 'json' 格式(Format既是格式也代表容器的意思) def __init__(self, message): self.message = messageclass StudentInfo(object): def __init__(self, students_path, log_path): # TODO:初始化函数 (判断存储学生信息、日志文件是否存在) # 由于这次我们是要将信息存储在一个文件中,所以我们的初始化就要变更为 students_path # 之前我们使用的是 students 这个字典,这次我们使用 students_path 这个文件 self.students_path = students_path self.log_path = log_path self.log = self.__log() self.__init_path() # 确定 存储学生信息(student_path) 文件存在后,调用 __read() 函数 self.__read() # print(self.students, '-------') def __log(self): # 初始化 log 日志的对象 if os.path.exists(self.log_path):# 判断 log 文件是否存在,如果存在使用 'a'-追加模式;不存在,则使用 'w'-创建模式 mode = 'a' else: mode = 'w' logging.basicConfig( # 定义 basicConfig ,格式化日志输出的级别与格式 level=logging.INFO, format='%(asctime)s-%(filename)s-%(lineno)d-%(levelname)s-%(message)s', # 时间 - 文件名 - 触发日志的代码行 - 日志级别 - 日志信息 filename=self.log_path, filemode=mode ) # self.log = logging return logging def __init_path(self): # 定义一个私有函数 __init_path 判断 'students.json' 文件是否存在且是否是 json 格式文件,不存在则抛出异常 if not os.path.exists(self.students_path): raise MissPathError('当前的 %s 文件不存在:' % self.students_path) if not os.path.isfile(self.students_path): raise TypeError('当前的 \'students_path\' 不是一个文件') if not self.students_path.endswith('.json'): raise FormatError('当前不是一个json文件') def __read(self):# 定义一个私有 __read() 函数,读取文件 with open(self.students_path, 'r') as f: try: data = f.read() except Exception as e: raise e self.students = json.loads(data) def __save(self):# 定义一个私有 __save 函数,用以保存 with open(self.students_path, 'w') as f: json_data = json.dumps(self.students) f.write(json_data) def get_by_id(self, student_id): # 获取学生信息的id return self.students.get(student_id) def get_all_students(self): # 获取所有学生信息 for id_, value in self.students.items(): print('学号:{}, 姓名:{}, 年龄:{}, 性别:{}, 班级:{}'.format( id_, value['name'], value['age'], value['sex'], value['class_number'] )) return self.students def add(self, student):# TODO 执行写入操作、然后保存,并读取 try: self.check_user_info(student) except Exception as e: raise e self.__add(student) self.__save()# 存储是为了将最新的数据存储到 json 文件 self.__read()# 读取是为了当前的实例化对象拿到最新的 json 文件的数据 def adds(self, new_students):# TODO 执行写入操作、然后保存,并读取 for student in new_students: try: self.check_user_info(student) except Exception as e: print(e, student.get('name')) continue self.__add(student) self.__save()# 存储是为了将最新的数据存储到 json 文件 self.__read()# 读取是为了当前的实例化对象拿到最新的 json 文件的数据 def __add(self, student): if len(self.students) == 0: # 判断 self.students 是否为空,为空 new_id =1,不为空则自增 +1 new_id = 1 else: keys = list(self.students.keys()) _keys = [] for item in keys: _keys.append(int(item)) new_id = max(_keys) + 1 self.students[new_id] = student self.log.info('学生%s被注册了' % student['name']) def delete(self, student_id): if student_id not in self.students: print('{} 并不存在'.format(student_id)) else: user_info = self.students.pop(student_id) print('学号是{}, {}同学的信息已经被删除了'.format(student_id, user_info['name'])) self.log.warning('学号是{}, {}同学的信息已经被删除了'.format(student_id, user_info['name'])) self.__save()# 存储是为了将最新的数据存储到 json 文件 self.__read()# 读取是为了当前的实例化对象拿到最新的 json 文件的数据 def deletes(self, ids): for id_ in ids: if id_ not in self.students: print(f'{id_} 不存在学生库中') continue student_info = self.students.pop(id_) print(f'学号{id_} 学生{student_info["name"]} 已被移除') self.log.warning(f'学号{id_} 学生{student_info["name"]} 已被移除') self.__save()# 存储是为了将最新的数据存储到 json 文件 self.__read()# 读取是为了当前的实例化对象拿到最新的 json 文件的数据 def update(self, student_id, kwargs): if student_id not in self.students: print('并不存在这个学号:{}'.format(student_id)) try: self.check_user_info(kwargs) except Exception as e: raise e self.students[student_id] = kwargs self.__save()# 存储是为了将最新的数据存储到 json 文件 self.__read()# 读取是为了当前的实例化对象拿到最新的 json 文件的数据 print('同学信息更新完毕') def updates(self, update_students): for student in update_students: try: id_ = list(student.keys())[0] except IndexError as e: print(e) continue if id_ not in self.students: print(f'学号{id_} 不存在') continue user_info = student[id_] try: self.check_user_info(user_info) except Exception as e: print(e) continue self.students[id_] = user_info print('所有用户信息更新完成') self.__save()# 存储是为了将最新的数据存储到 json 文件 self.__read()# 读取是为了当前的实例化对象拿到最新的 json 文件的数据 def search_users(self, kwargs): assert len(kwargs) == 1, '参数数量传递错误' values = list(self.students.values()) key = None value = None result = [] if 'name' in kwargs: key = 'name' value = kwargs[key] elif 'sex' in kwargs: key = 'sex' value = kwargs['sex'] elif 'class_number' in kwargs: key = 'class_number' value = kwargs[key] elif 'age' in kwargs: key = 'age' value = kwargs[key] else: raise NotArgError('没有发现搜索的关键字') for user in values: # [{name, sex, age, class_number}, {}] if value in user[key]: result.append(user) return result def check_user_info(self, kwargs): assert len(kwargs) == 4, '参数必须是4个' if 'name' not in kwargs: raise NotArgError('没有发现学生姓名参数') if 'age' not in kwargs: raise NotArgError('缺少学生年龄参数') if 'sex' not in kwargs: raise NotArgError('缺少学生性别参数') if 'class_number' not in kwargs: raise NotArgError('缺少学生班级参数') name_value = kwargs['name'] # type(name_value) age_value = kwargs['age'] sex_value = kwargs['sex'] class_number_value = kwargs['class_number'] # isinstace(对比的数据, 目标类型) isinstance(1, str) if not isinstance(name_value, str): raise TypeError('name应该是字符串类型') if not isinstance(age_value, int): raise TypeError('age 应该是整型') if not isinstance(sex_value, str): raise TypeError('sex应该是字符串类型') if not isinstance(class_number_value, str): raise TypeError('class_number应该是字符串类型')students = { 1: { 'name': 'Neo', 'age': 18, 'class_number': 'A', 'sex': 'boy' }, 2: { 'name': 'Jack', 'age': 16, 'class_number': 'B', 'sex': 'boy' }, 3: { 'name': 'Lily', 'age': 18, 'class_number': 'A', 'sex': 'girl' }, 4: { 'name': 'Adem', 'age': 18, 'class_number': 'C', 'sex': 'boy' }, 5: { 'name': 'HanMeiMei', 'age': 18, 'class_number': 'B', 'sex': 'girl' }}if __name__ == '__main__': student_info = StudentInfo('students.json', 'students.log') user = student_info.get_by_id(1) student_info.add(name='Marry', age=16, class_number='A', sex='girl') users = [ {'name': 'Atom', 'age': 17, 'class_number': 'B', 'sex': 'boy'}, {'name': 'Lucy', 'age': 18, 'class_number': 'C', 'sex': 'girl'} ] student_info.adds(users) student_info.get_all_students() print('------------------------------------------------------') student_info.deletes([7, 8]) student_info.get_all_students() print('------------------------------------------------------') student_info.updates([ {1: {'name': 'Jone', 'age': 18, 'class_number': 'A', 'sex': 'boy'}}, {2: {'name': 'Nike', 'age': 18, 'class_number': 'A', 'sex': 'boy'}} ]) student_info.get_all_students() print('------------------------------------------------------') result = student_info.search_users(name='d') print(result) print('------------------------------------------------------') result = student_info.search_users(name='小') print(result) print('------------------------------------------------------') result = student_info.search_users(name='') print(result) result = student_info.search_users(name='小') print(result) print('------------------------------------------------------') result = student_info.search_users(name='') print(result) print('------------------------------------------------------')PS - 1:使用该脚本演示时,需要在 脚本文件 的相对路径下,创建一个 students.json 与 students.log 文件用来存储学生信息与记录日志。(文件名随意)
PS - 2:237行的 students 与 main 方法的 输出打印仅仅是为了调试演示效果。
脚本演示需准备的学生信息与演示结果
脚本演示截图如下:
准备添加的学生信息数据
object.add(name='Neo', age=18, class_number='A', sex='boy')object.add(name='Jack', age=16, class_number='B', sex='boy')object.add(name='Lily', age=18, class_number='A', sex='girl')object.add(name='Adem', age=17, class_number='C', sex='boy')object.add(name='HanMeiMei', age=18, class_number='B', sex='girl')object.add(name='Marry', age=16, class_number='A', sex='gir')object.add(name='Atom', age=17, class_number='B', sex='boy')object.add(name='Lucy', age=18, class_number='C', sex='girl')object.add(name='Jone', age=17, class_number='A', sex='boy')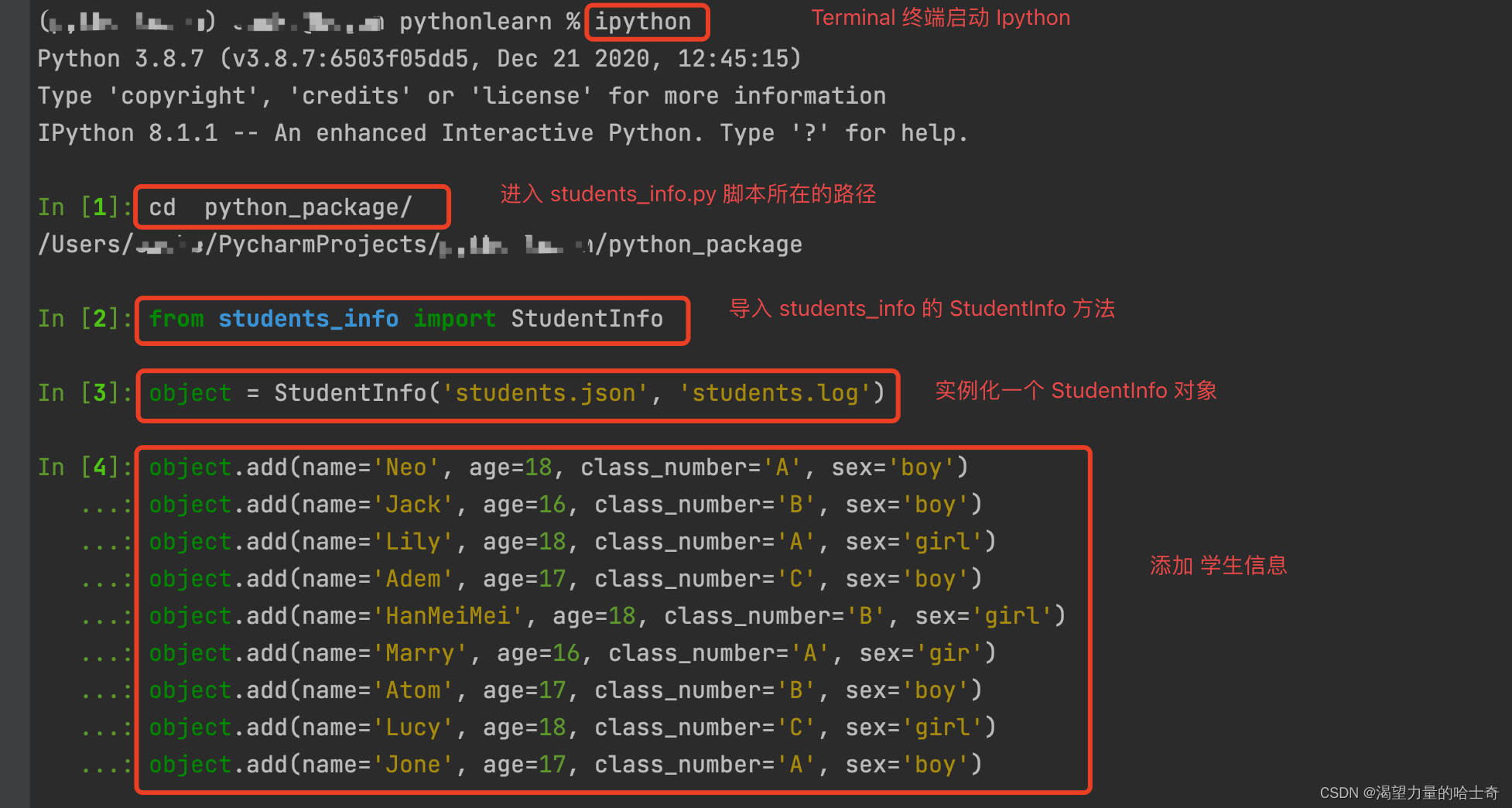
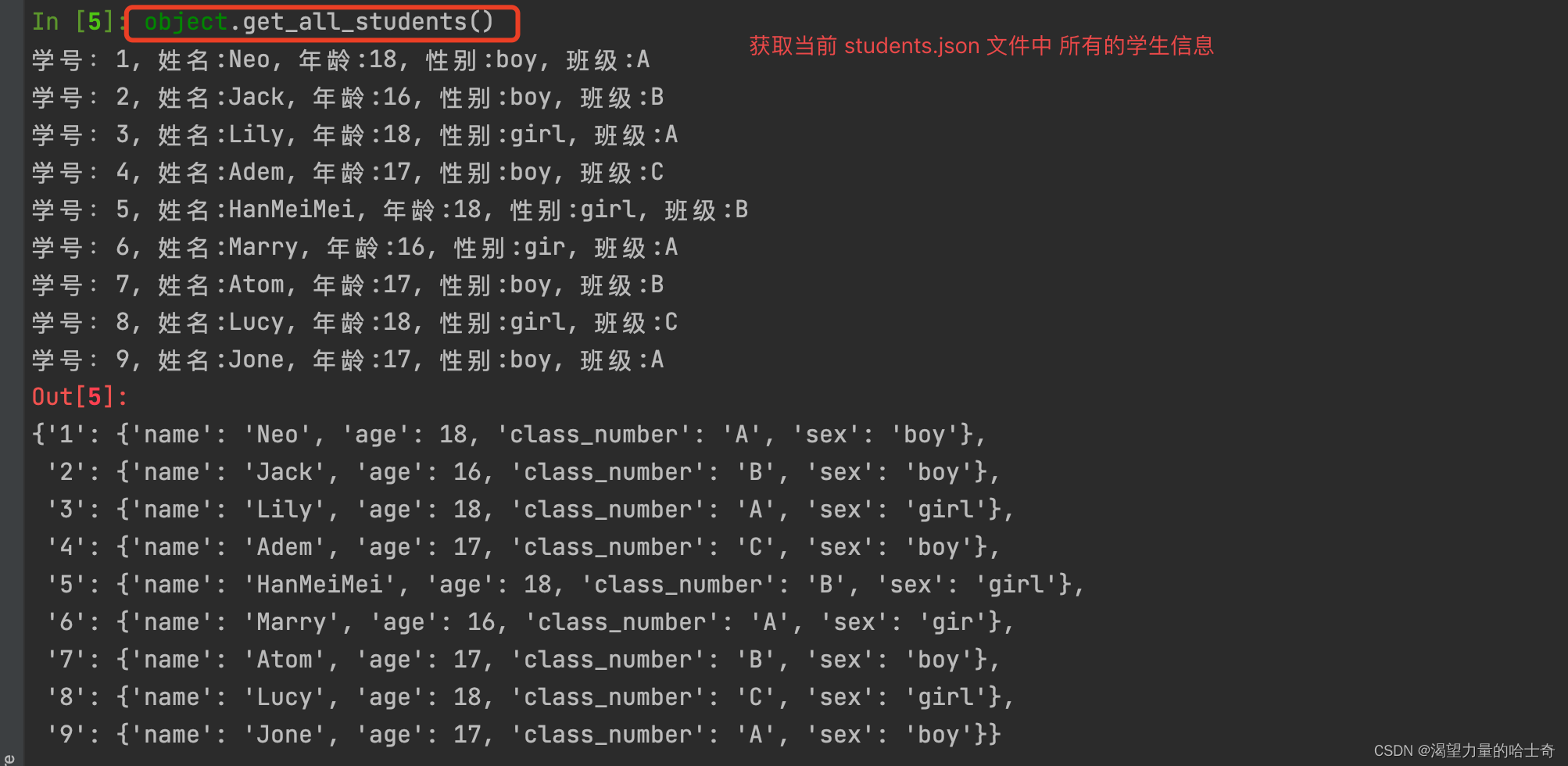

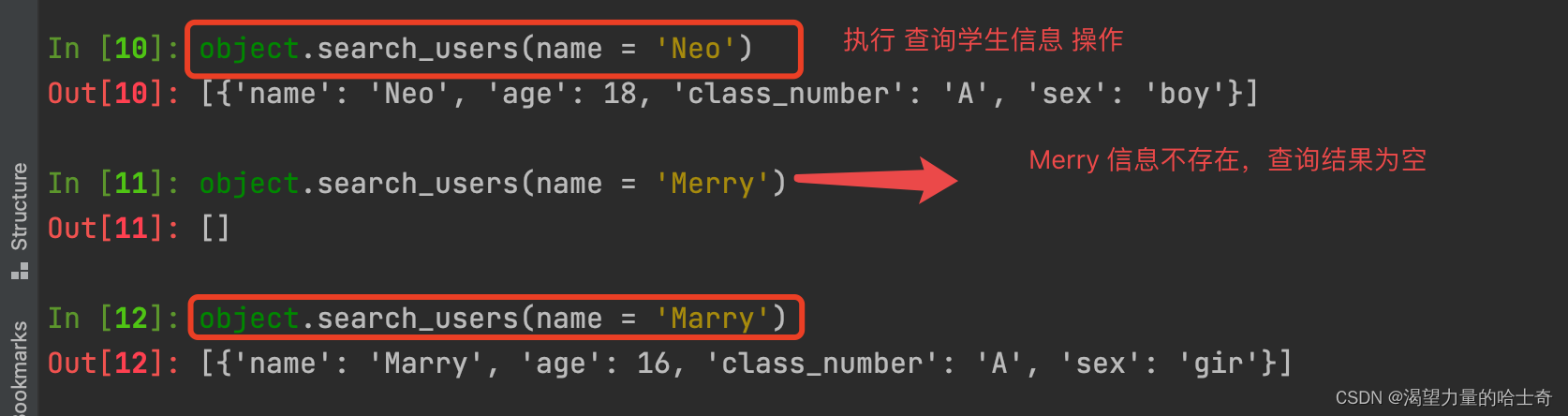
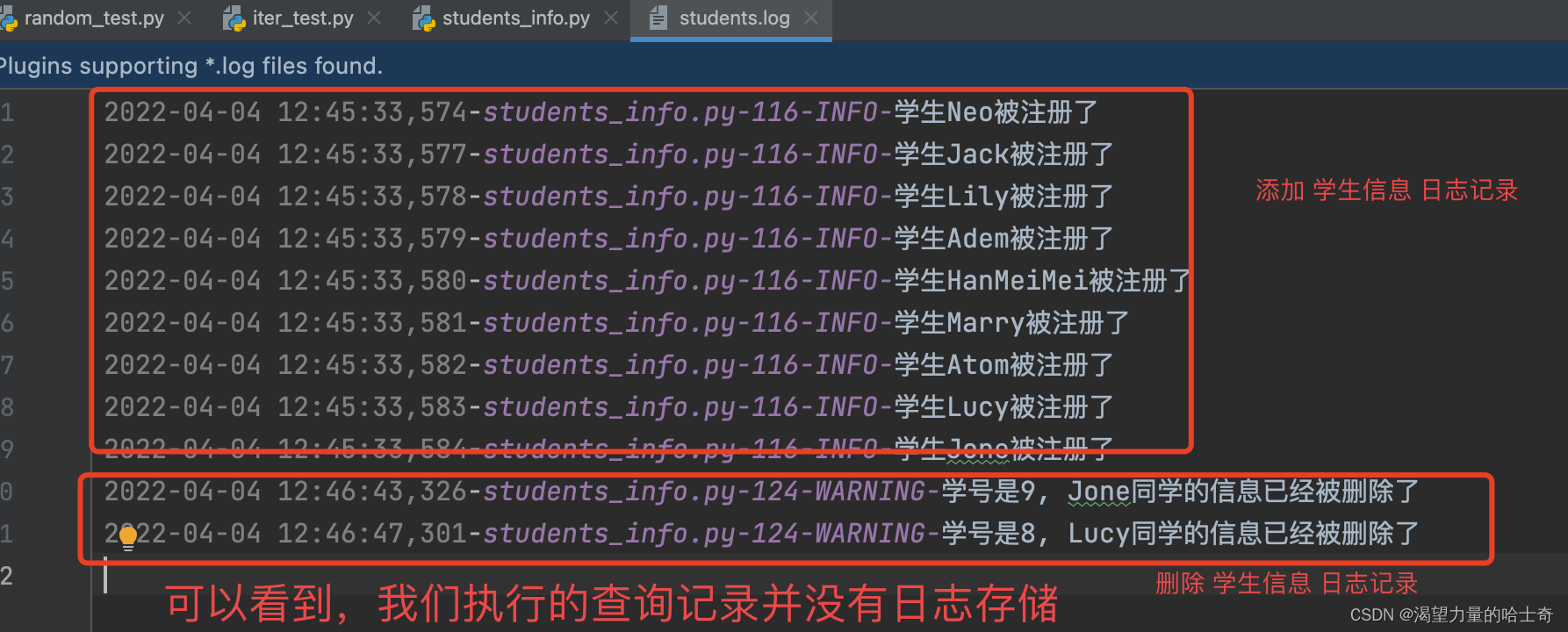
总结梳理
针对之前做的 学生信息库(升级学生信息库为面向对象形式),在今天我们主要做了两方面的内容。
1、将我们的学生信息数据 持久化 的存贮在了我们的 json 文件中,并且写入和读取。
2、针对我们执行对应操作的日志进行了 添加 和 删除 的行为做了记录。
目前我们也已经达到了,可能大家针对上文脚本中的 __log() 与 __init_path() 等函数还有一些疑惑;在之前的学习中,我们想要定义一个 self 的变量,都是在我们的构造函数中实现的,类似于 self.log_path = log_path 这样的等于一个传进来的参数这样来定义的。
实际上我们想要定义一个 self 的变量,并不拘泥与只在我们的构造函数中这样的实现方式。我们可以在任何函数中,通过 self 的形式生成一个 self 对应的变量。 就如同 上文的 __read() 函数中,我们通过 self.students = json.loads(data) 获取传进来的新的值。
那么该章节的练习也就在这里告一段落,到今天为止。我们的学生信息库真正的做到持久化,真正的做到可用的状态了。大家也可以拓展一下思维,更好的完善这个 学生信息库 。(讲道理,这样的学生信息库虽然已经实现了我们提到的功能,其实我认为还是不完善的。当然了,等我们学到 数据库开发阶段的话,那才叫做真正的 持久化 。)

