Centos7使用scala从外部MySQL数据库加载数据集出现ERROR TaskSetManager: Task 0 in stage 0.0 failed 4 times; aborting..
环境配置:使用的是Centos7.4版本的虚拟机,然后hive配置的是远程模式(master节点当作客户端,slave节点当作hive端),slave2节点安装的是MySQL数据库;spark版本为1.6.3,scala版本为2.10.6。
目的:在spark-shell中使用scala加载外部MySQL数据库中的菜品数据,然后做数据分析工作。
出现的问题:在master节点上访问MySQL数据库中的数据库的时候出现问题。
ERROR TaskSetManager: Task 0 in stage 0.0 failed 4 times; aborting joborg.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most r in stage 0.0 (TID 3, slave): java.lang.ClassNotFoundException: com.mysql.jdbc.Driver21/12/16 20:52:11 WARN TaskSetManager: Lost task 0.0 in stage 0.0 (TID 0, slave2): java.lang.ClassNotFoundExcrat org.apache.spark.repl.ExecutorClassLoader.findClass(ExecutorClassLoader.scala:84)at java.lang.ClassLoader.loadClass(ClassLoader.java:425)at java.lang.ClassLoader.loadClass(ClassLoader.java:358)at org.apache.spark.sql.execution.datasources.jdbc.DriverRegistry$.register(DriverRegistry.scala:38)at org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.applyat org.apache.spark.sql.execution.datasources.jdbc.JdbcUtils$$anonfun$createConnectionFactory$2.applyat org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD$$anon$1.<init>(JDBCRDD.scala:347)at org.apache.spark.sql.execution.datasources.jdbc.JDBCRDD.compute(JDBCRDD.scala:339)at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:306)at org.apache.spark.rdd.RDD.iterator(RDD.scala:270)at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:306)at org.apache.spark.rdd.RDD.iterator(RDD.scala:270)at org.apache.spark.rdd.MapPartitionsRDD.compute(MapPartitionsRDD.scala:38)at org.apache.spark.rdd.RDD.computeOrReadCheckpoint(RDD.scala:306)at org.apache.spark.rdd.RDD.iterator(RDD.scala:270)at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:66)at org.apache.spark.scheduler.Task.run(Task.scala:89)at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:227)at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:615)at java.lang.Thread.run(Thread.java:745)21/12/16 20:52:12 ERROR TaskSetManager: Task 0 in stage 0.0 failed 4 times; aborting joborg.apache.spark.SparkException: Job aborted due to stage failure: Task 0 in stage 0.0 failed 4 times, most r in stage 0.0 (TID 3, slave): java.lang.ClassNotFoundException: com.mysql.jdbc.Driverat org.apache.spark.repl.ExecutorClassLoader.findClass(ExecutorClassLoader.scala:84)scala代码:
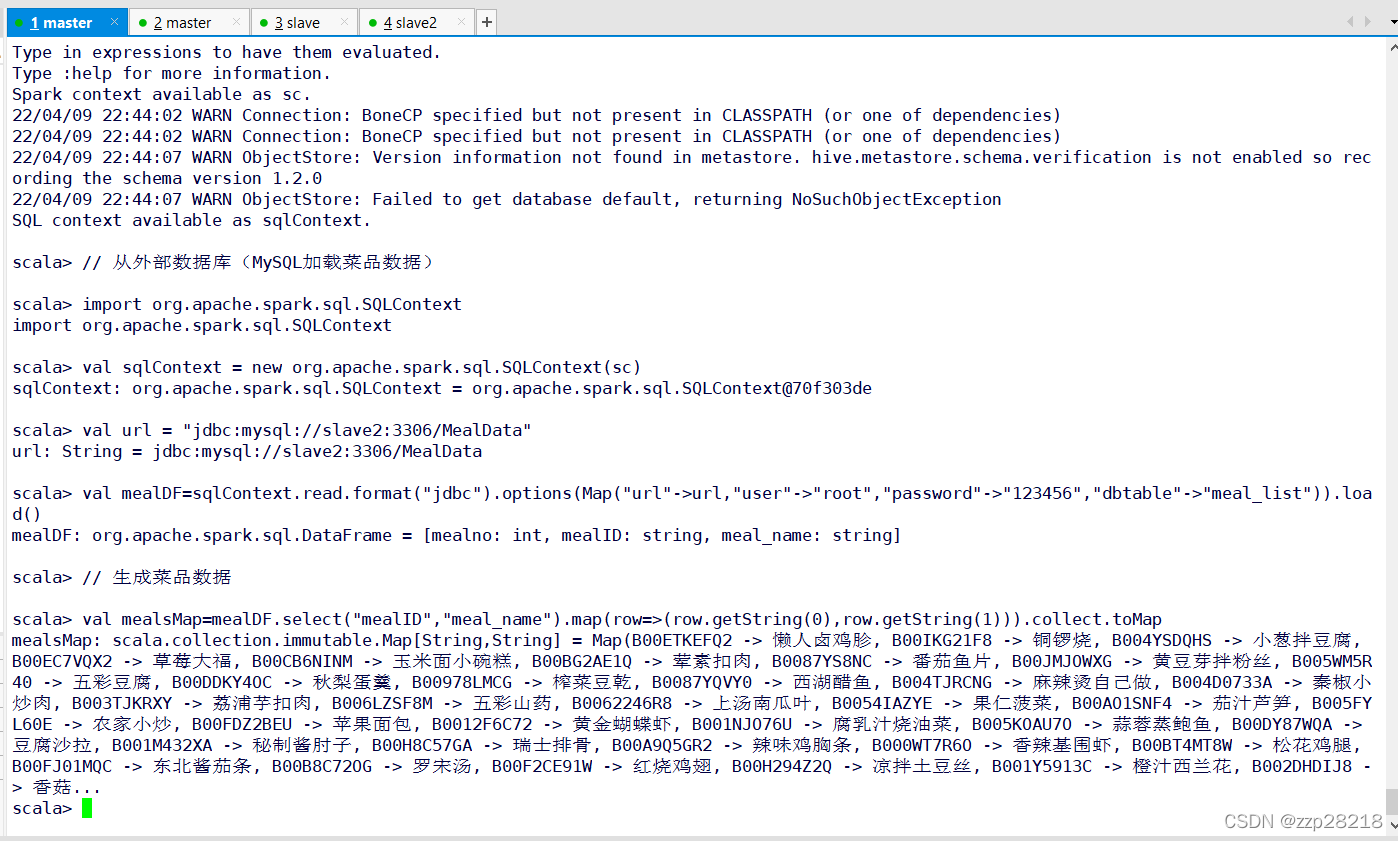
// 从外部数据库(MySQL加载菜品数据)import org.apache.spark.sql.SQLContextval sqlContext = new org.apache.spark.sql.SQLContext(sc)val url = "jdbc:mysql://slave2:3306/MealData"val mealDF=sqlContext.read.format("jdbc").options(Map("url"->url,"user"->"root","password"->"123456","dbtable"->"meal_list")).load()// 生成菜品数据val mealsMap=mealDF.select("mealID","meal_name").map(row=>(row.getString(0),row.getString(1))).collect.toMap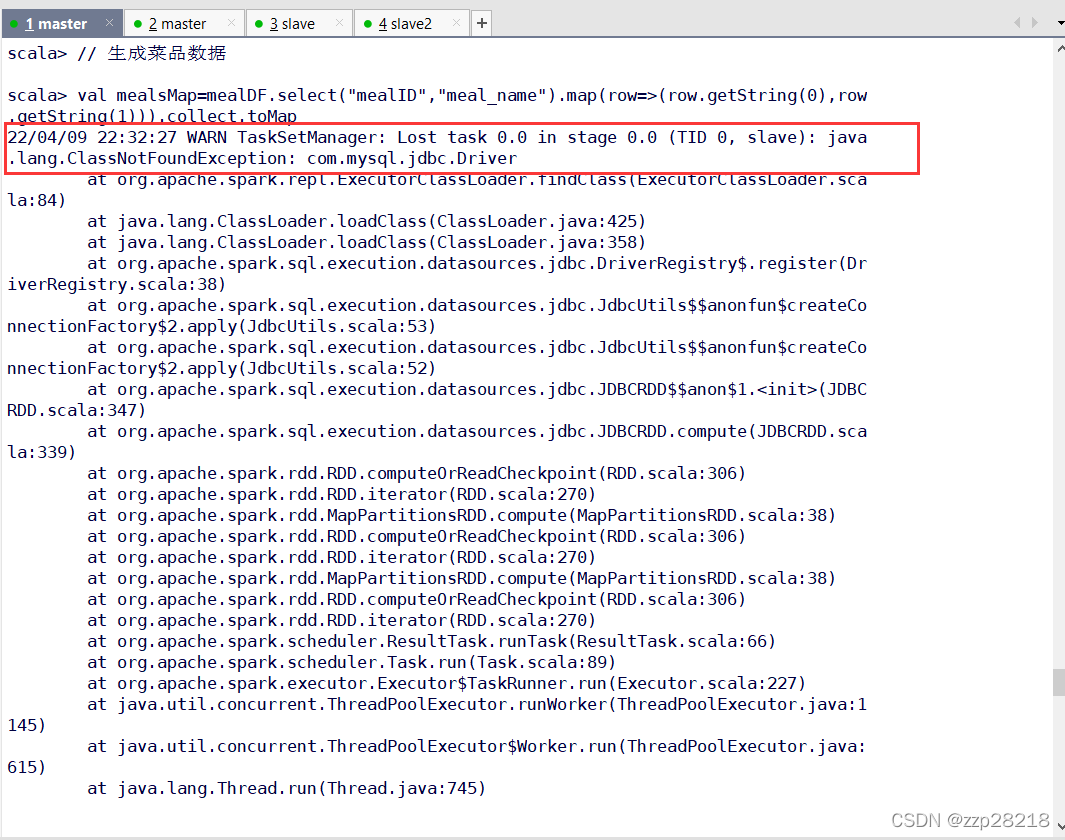
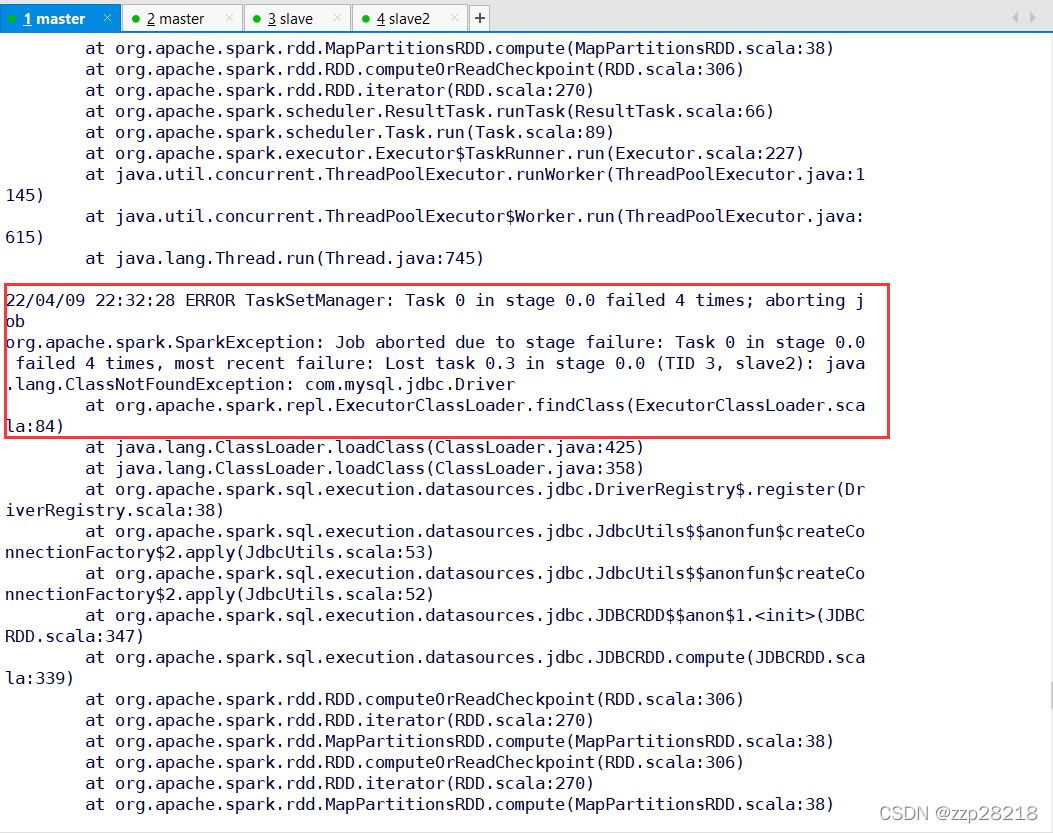
一直显示没有连接上MySQL服务。
解决办法:将MySQL的链接jar报复制到spark的lib目录下,类似于hive的远程模式中要把MySQL连接jar包复制到hive的lib目录下。
然后再在配置文件中spark-defaults.conf文件中添加如下配置项
spark.executor.extraClassPath /usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/mysql-connector-java-5.1.27-bin.jarspark.driver.extraClassPath /usr/local/src/spark-1.6.3-bin-hadoop2.6/lib/mysql-connector-java-5.1.27-bin.jar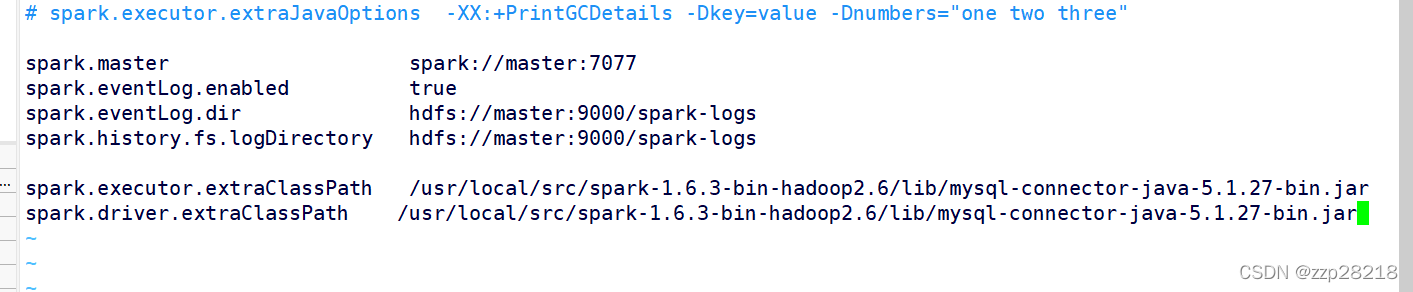
然后退出 spark-shell 重新进入在执行代码: