深度学习系列 -- 序列模型之自然语言处理与词嵌入(Natural Language Processing and Word Embeddings)
目录
1 词嵌入
2 词嵌入与迁移学习
3 词嵌入与类比推理
4 嵌入矩阵
5 学习词嵌入
5.1 神经概率语言模型
5.2 Word2Vec
5.2.1 Skip-gram
5.2.2 CBOW
5.2.3 负采样
5.3 Glove
6 情感分类
7 词嵌入除偏
7.1 中和本身与性别无关的词汇:
7.2 均衡本身与性别有关的词汇
1 词嵌入
one-hot 向量将每个单词表示为完全独立的个体,不同词向量都是正交的,因此单词间的相似度无法体现。
换用特征化表示方法能够解决这一问题。我们可以通过用语义特征作为维度来表示一个词,因此语义相近的词,其词向量也相近。
将高维的词嵌入“嵌入”到一个二维空间里,就可以进行可视化。常用的一种可视化算法是 t-SNE 算法。在通过复杂而非线性的方法映射到二维空间后,每个词会根据语义和相关程度聚在一起。(相关论文:van der Maaten and Hinton., 2008. Visualizing Data using t-SNE)
词嵌入(Word Embedding)是 NLP 中语言模型与表征学习技术的统称,概念上而言,它是指把一个维数为所有词的数量的高维空间(one-hot 形式表示的词)“嵌入”到一个维数低得多的连续向量空间中,每个单词或词组被映射为实数域上的向量。对大量词汇进行词嵌入后获得的词向量,可用于完成命名实体识别(Named Entity Recognition)等任务。词嵌入在语言模型、机器翻译领域用的少一些。
2 词嵌入与迁移学习
用词嵌入做迁移学习可以降低学习成本,提高效率。其步骤如下:
- 从大量文本集种学习词嵌入,或者下载网上开源的、预训练好的词嵌入模型;
- 将这些词嵌入模型迁移到新的、只有少量标注训练集的任务中;
- 可以选择是否微调词嵌入。当标记数据集不是很大时可以省下这一步骤。
3 词嵌入与类比推理
词嵌入可用于类比推理。
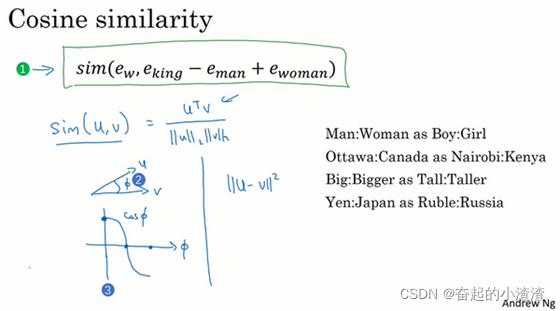
举一个例子,有一系列词嵌入可以捕捉的单词的特征表示。如果man如果对应woman,那么king应该对应什么?我们应该都能猜到king应该对应queen。能否有一种算法来自动推导出这种关系?

我们用一个四维向量来表示man,我们用 来表示,我们把它(上图编号1所示)称为
,而旁边这个(上图编号2所示)表示woman的嵌入向量,称它为
,对king和queen也是用一样的表示方法。在该例中,假设你用的是四维的嵌入向量,而不是比较典型的50到1000维的向量。这些向量有一个有趣的特性,就是假如你有向量
和
,将它们进行减法运算,即
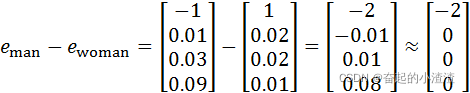
类似的,假如你用 减去
,最后也会得到一样的结果,即
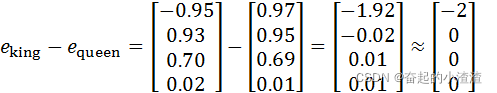
这个结果表示,man和woman主要的差异是gender(性别)上的差异,而king和queen之间的主要差异,根据向量的表示,也是gender(性别)上的差异,这就是为什么 -
和
结果是相同的。所以得出这种类比推理的结论的方法就是,当算法被问及man对woman相当于king对什么时,算法所做的就是计算
-
,然后找出一个向量也就是找出一个词,使得
,也就是说,当这个新词是queen时,式子的左边会近似地等于右边。
给定对应关系“男性(Man)”对“女性(Woman)”,想要类比出“国王(King)”对应的词汇。则可以有 , 之后的目标就是找到词向量
,来找到使相似度
最大。
一个最常用的相似度计算函数是余弦相似度(cosine similarity)。公式为:
相关论文:Mikolov et. al., 2013, Linguistic regularities in continuous space word representations
先不看分母,分子其实就是
和
的内积。如果
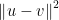
参考资料:
余弦相似度 为了测量两个词的相似程度,我们需要一种方法来测量两个词的两个嵌入向量之间的相似程度。给定两个向量
其中
是两个向量的点积(或内积),
是向量
的范数(或长度),并且
是向量
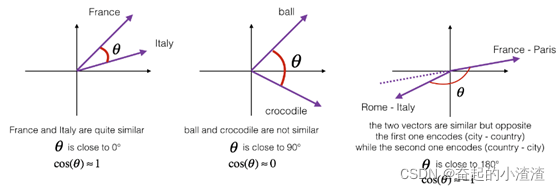
图1:两个向量之间角度的余弦是衡量它们有多相似的指标,角度越小,两个向量越相似。
从学术上来说,比起测量相似度,这个函数更容易测量的是相异度,所以我们需要对其取负,这个函数才能正常工作,不过我还是觉得余弦相似度用得更多一点,这两者的主要区别是它们对u 和v 之间的距离标准化的方式不同。
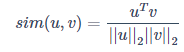
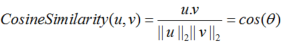
4 嵌入矩阵
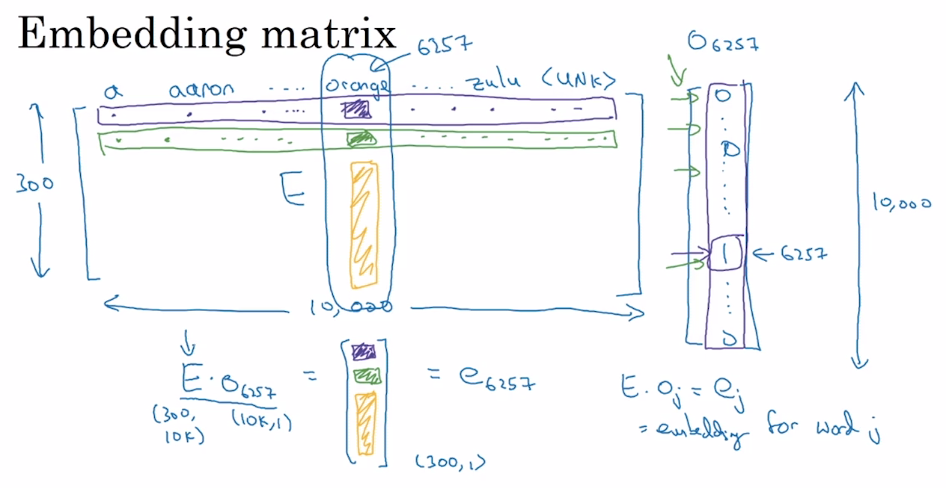
不同的词嵌入方法能够用不同的方式学习到一个嵌入矩阵(Embedding Matrix) 。将字典中位置为
的词的 one-hot 向量表示为
,词嵌入后生成的词向量用
表示,则有:
但在实际情况下一般不这么做。因为 one-hot 向量维度很高,且几乎所有元素都是 0,这样做的效率太低。因此,实践中直接用专门的函数查找矩阵 的特定列。
5 学习词嵌入
5.1 神经概率语言模型
神经概率语言模型(Neural Probabilistic Language Model)构建了一个能够通过上下文来预测未知词的神经网络,在训练这个语言模型的同时学习词嵌入。
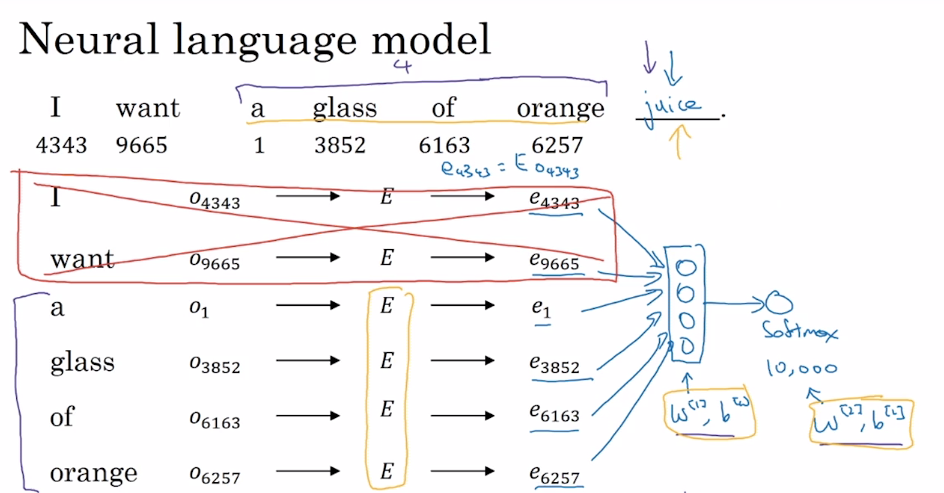
训练过程中,将语料库中的某些词作为目标词,以目标词的部分上下文作为输入,Softmax 输出的预测结果为目标词。嵌入矩阵 和
为需要通过训练得到的参数。这样,在得到嵌入矩阵后,就可以得到词嵌入后生成的词向量。
相关论文: Bengio et. al., 2003, A neural probabilistic language model
5.2 Word2Vec
Word2Vec是一种简单而且高效的词嵌入学习算法,包括2种模型:
- Skip - gram : 根据上下文预测目标函数
- Continuous Bag of Words(CBOW) : 根据上下文预测目标词
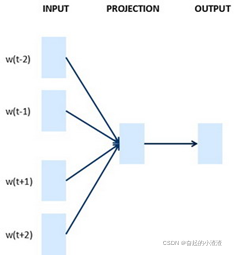
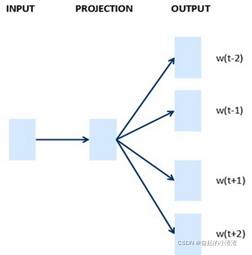
每种语言模型又包含负采样(Negative Sampling)和分级的 Softmax(Hierarchical Softmax)两种训练方法。
训练神经网络时候的隐藏层参数即是学习到的词嵌入。
相关论文:Mikolov et. al., 2013. Efficient estimation of word representations in vector space.
5.2.1 Skip-gram
从上图可以看到,从左到右是 One-hot 向量,乘以 center word 的矩阵 于是找到词向量,乘以另一个 context word 的矩阵
得到对每个词语的“相似度”,对相似度取 Softmax 得到概率,与答案对比计算损失。
设某个词为 ,该词的一定词距内选取一些配对的目标上下文
,则该网路仅有的一个 Softmax 单元输出条件概率:
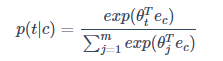
是一个与输出
有关的参数,其中省略了用以纠正偏差的参数。损失函数仍选用交叉熵:
在此 Softmax 分类中,每次计算条件概率时,需要对词典中所有词做求和操作,因此计算量很大。解决方案之一是使用一个分级的 Softmax 分类器(Hierarchical Softmax Classifier),形如二叉树。在实践中,一般采用霍夫曼树(Huffman Tree)而非平衡二叉树,常用词在顶部。
如果在语料库中随机均匀采样得到选定的词 c,则 'the', 'of', 'a', 'and' 等出现频繁的词将影响到训练结果。因此,采用了一些策略来平衡选择。
相关blog: 详解 Word2vec 之 Skip-gram 模型
5.2.2 CBOW
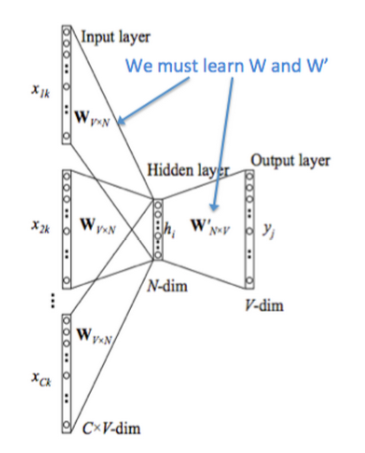
CBOW 模型的工作方式与 Skip-gram 相反,通过采样上下文中的词来预测中间的词。
相关资料: [NLP] 秒懂词向量Word2vec的本质
word2vec原理推导与代码分析-码农场
5.2.3 负采样
为了解决 Softmax 计算较慢的问题,Word2Vec 的作者后续提出了负采样(Negative Sampling)模型。对于监督学习问题中的分类任务,在训练时同时需要正例和负例。在分级的 Softmax 中,负例放在二叉树的根节点上;而对于负采样,负例是随机采样得到的。
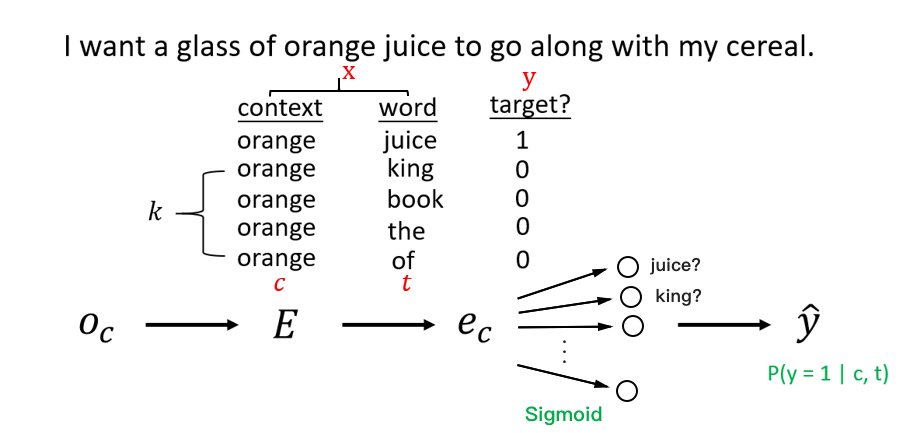
如上图所示,当输入的词为一对上下文-目标词时,标签设置为 1(这里的上下文也是一个词)。另外任意取 k 对非上下文-目标词作为负样本,标签设置为 0。对于小数据集,k 取 520 较为合适;而当有大量数据时,k 可以取 25。
改用多个 Sigmoid 输出上下文-目标词(c, t)为正样本的概率:![]()
其中,、
分别代表目标词和上下文的词向量。
之前训练中每次要更新 n 维的多分类 Softmax 单元(n 为词典中词的数量)。现在每次只需要更新 k+1 维的二分类 Sigmoid 单元,计算量大大降低。
关于计算选择某个词作为负样本的概率,推荐采用以下公式(而非经验频率或均匀分布):
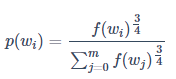
其中,代表语料库中单词
出现的频率。上述公式更加平滑,能够增加低频词的选取可能。
相关论文:Mikolov et. al., 2013. Distributed representation of words and phrases and their compositionality
5.3 Glove
GloVe全称为Global Vectors for Word Representation。
相关论文: 论文链接
GloVe(Global Vectors)是另一种流行的词嵌入算法。Glove 模型基于语料库统计了词的共现矩阵,
中的元素
表示单词
和单词
“为上下文-目标词”的次数。定义以下公式:
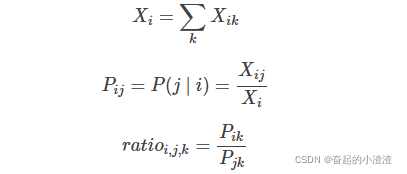
论文中提出 的值是有规律的:

可以看出, 能够反应出单词之间的相关性,而Glove模型便是利用了
。
GloVe模型的最终目的和Word2Vec是一样的,即得到每个单词对应的词嵌入向量。假设我们已经得到了单词 的词嵌入向量
,如果存在函数
使得:
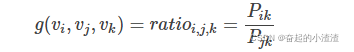
那么我们便可以认为我们学得的词嵌入向量与共现矩阵具有很好的一致性,也就说明我们的词嵌入向量中蕴含了共现矩阵中所蕴含的信息。
因此,很容易想到用二者差的平方作为代价函数(为语料库中的单词数目):
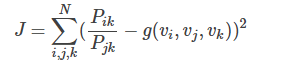
但是模型中包含3个单词,这就意味着要在N*N*N 的复杂度上进行计算,许要尝试对其进行简化。
我们要考虑单词
和单词
之间的关系,那么
中可能有一个
, 这是一个非常合理的猜测。
是一个标量,那么
.
其中,
是一个比值,我们希望
即:
因此我们只需要尽量让上述等式成立即可。又因为上式的分子和分母形式一样,所以等式可以简化为:
两边取对数:
我们把
展开:
将
移到等式的另一边:
上式中添加了一个偏差项
, 并且将
上式中添加了一个偏差项
中.
因此,代价函数就变成了 :
基于出现频率越高的词对权重应该越大的原则,在代价函数中添加权重项,完善代价函数:
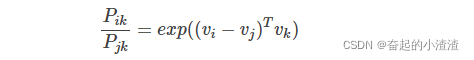
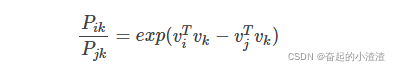
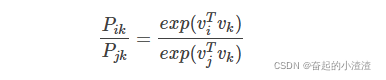
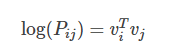

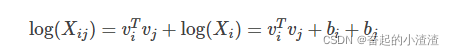
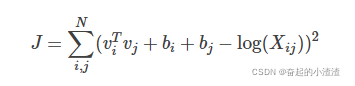
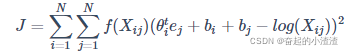
那么该如何定义权重函数
呢?
在论文中作者阐述: 权重函数应该有以下三个特点:
,即如果两个词没有用共同出现过,权重就是 0.
不能取太大的值。因为停用词的词汇都会很高,但是并没有很高的重要意义。
综上,
根据经验,作者认为
是一个比较好的选择。
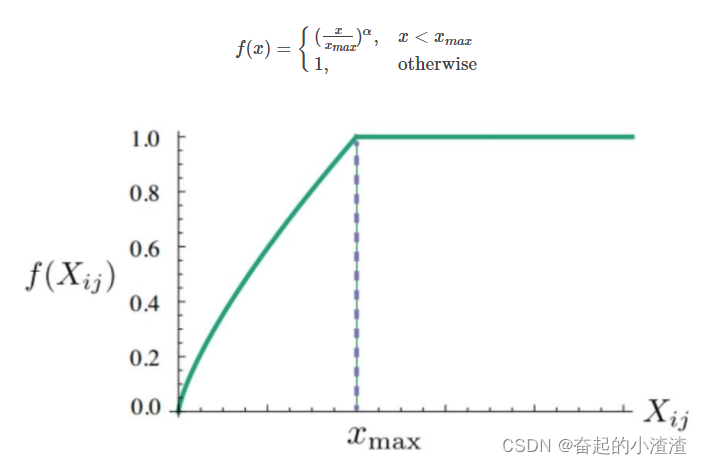
GloVe 模型中并没有用到神经网络。
6 情感分类
情感分析是NLP中最常见的一个应用。情感分类是指分析一段文本对某个对象的情感是正面的还是负面的,实际应用包括舆情分析、民意调查、产品意见调查等等。情感分类的问题之一是标记好的训练数据不足。但是有了词嵌入得到的词向量,中等规模的标记训练数据也能构建出一个效果不错的情感分类器。
举个例子,假设我们有训练集为顾客对一个餐馆的评价以及对应的评级:

训练集规模可能并不会太大,对于情感分类问题来说,训练集大小从10000到100000都是很常见的。但是我们可以通过一个一百亿大小的语料库训练词嵌入矩阵,这样的话,尽管情感分类任务的训练集的规模不大,但是我们依然可以训练出一个不错的情感分类模型。例如构建模型如下:
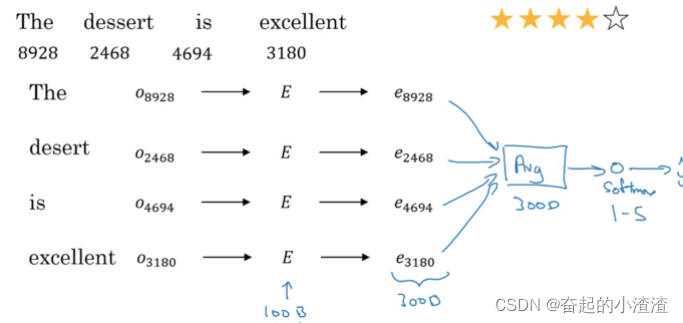
如图所示,用词嵌入方法获得嵌入矩阵后,计算出句子中每一个单词的词向量并取平均值,输入一个Softmax单元,输出预测结果。这种方法的优点是使用于任何长度的文本,缺点是没有考虑词的顺序,对于包含了多个正面评价词的负面评价,很容易预测到错误结果。如果有个句子“Completely lacking in good taste, good service, and good ambience.”,句子中多次出现“good”这个单词,在求平均之后,模型可能会误将该条评论预测为高评级,其实该评论的评级是很低的。因此,我们可以改用RNN模型来实现一个效果更好的情感分析器:
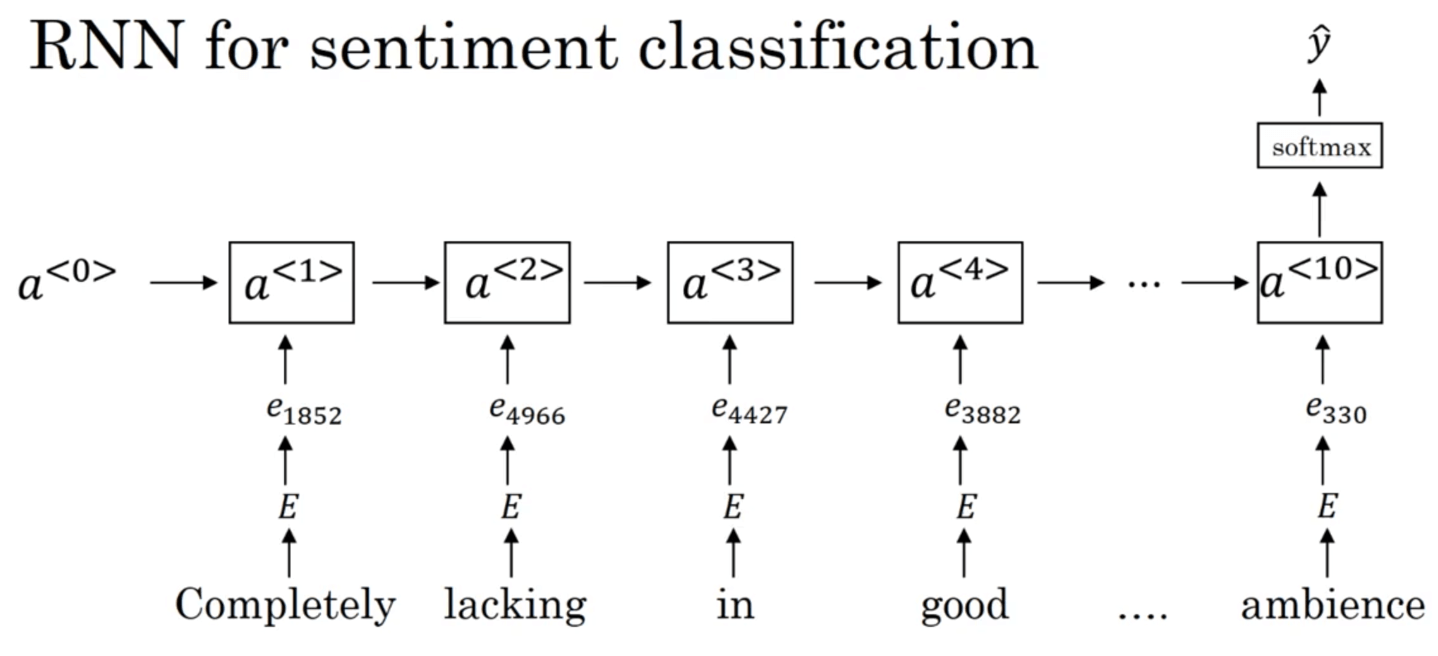
由于我们使用了一个不错的词嵌入矩阵,因此对于句子“Completely absent of good taste, good service, and good ambience.”,模型也同样可以预测出其评级为一颗星,尽管有可能单词“absent”压根就没在训练集中。
7 词嵌入除偏
语料库中可能存在着性别歧视、种族歧视、性取向歧视等非预见形式的偏见(Bias),这种预见会直接反映到通过词嵌入获得的词向量。例如,使用未除偏的词嵌入结果进行类比推理的时候,“Man”对 “Computer Programmer ” 可能得到带有性别偏见的结果。
词嵌入除偏的方法有以下几种:
7.1 中和本身与性别无关的词汇:
对于 “医生(Doctor)","老师(teacher)"、“接待员(receptionist)”等本身与性别无关的词汇,可以中和(Neutralize)其中的偏见。首先用“女性(woman)”的词向量减去“男性(man)”的词向量,得到的向量 就代表了“性别(gender)”。假设现有的词向量维数为 50,那么对某个词向量,将 50 维空间分成两个部分:与性别相关的方向
和与
正交的其他 49 个维度
。如下左图:
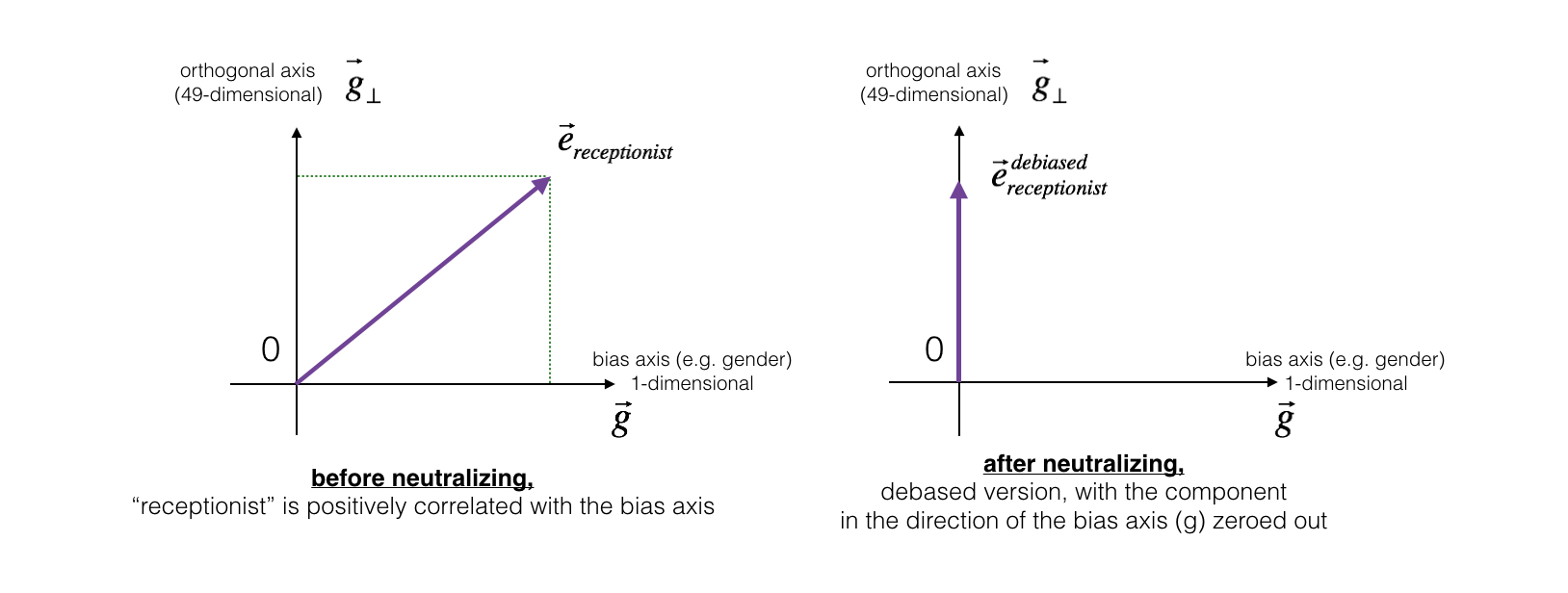
而除偏的步骤,是将要出偏的词向量(作图中的 )在向量中
方向上的值变为0,变成右图所示的
.
公式如下:
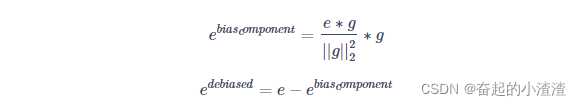
7.2 均衡本身与性别有关的词汇
对于“男演员(actor)”、“女演员(actress)”、“爷爷(grandfather)”等本身与性别有关词汇,中和“婴儿看护人(babysit)”中存在的性别偏见后,还是无法保证它到“女演员(actress)”与到“男演员(actor)”的距离相等。对这样一对性别有关的词,除偏的过程是均衡(Equalization)它们的性别属性。其核心思想是确保一对词(actor 和 actress)到 的距离相等。
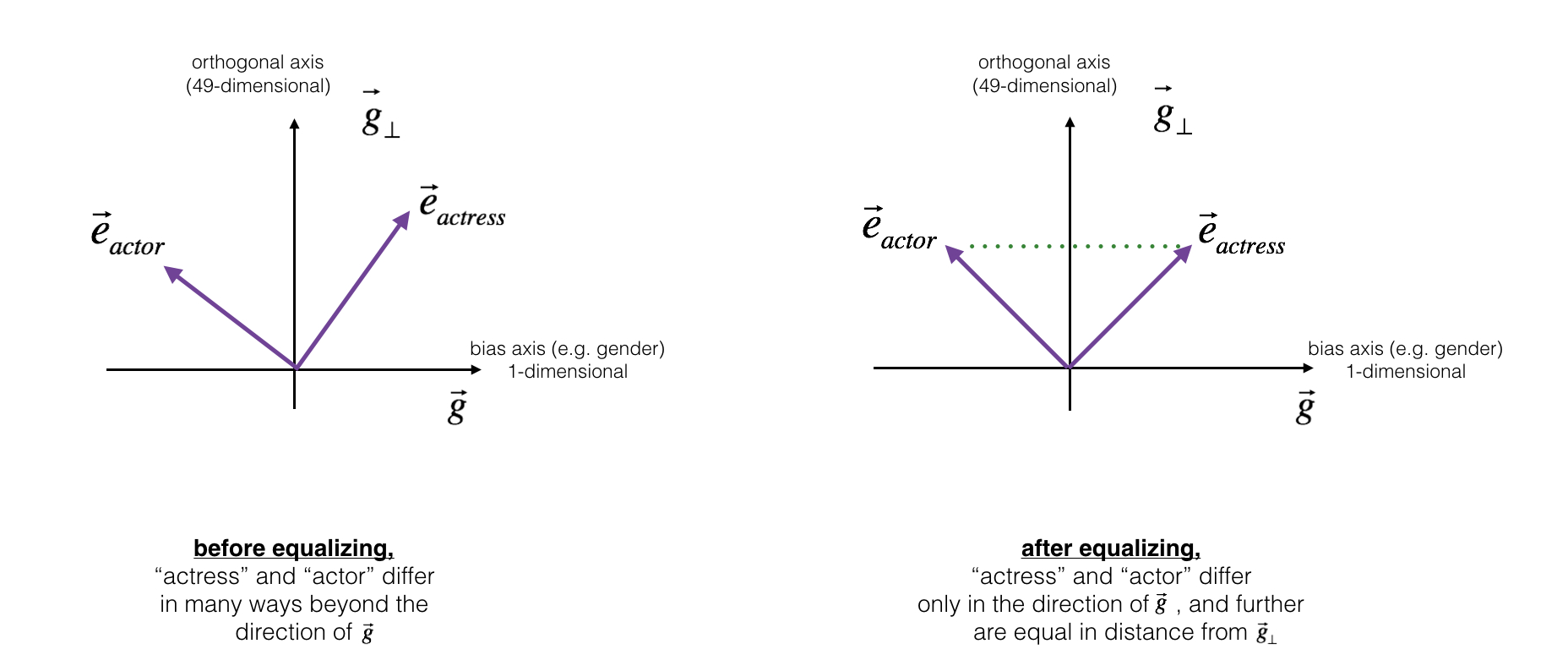
公式:

相关论文:
Bolukbasi et. al., 2016. Man is to computer programmer as woman is to homemaker? Debiasing word embeddings
减少或者是消除学习算法中的偏见问题是个十分重要的问题,因为这些算法会用来辅助制定越来越多的社会中的重要决策。

