Python语法进阶篇 - 70 - 线程的创建与常用方法
| 万叶集 |
|---|
| 🎉 隐约雷鸣,阴霾天空。 🎉 |
| 🎉 但盼风雨来,能留你在此。 🎉 |
前言:
✌ 作者简介:渴望力量的哈士奇,大家可以叫我 🐶哈士奇🐶 。(我真的有一只哈士奇)
📫 如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
💬 人生格言:优于别人,并不高贵,真正的高贵应该是优于过去的自己。💬
🔥 如果感觉博主的文章还不错的话,还请👍关注、点赞、收藏三连支持👍一下博主哦
📕 系列专栏:
⛽️ Python全栈系列 - [更新中] 【 本文在该系列】
🍎 Python零基础入门篇
🍎 Python语法进阶篇
👋 网安之路系列
🍋 网安之路踩坑篇
🍋 网安知识扫盲篇
🍋 Vulhub 漏洞复现篇
🍋 Shell脚本编程篇
🍋 Web攻防篇 2021年9月3日停止更新,转战先知等安全社区
🍋 渗透工具使用集锦 2021年9月3日停止更新,转战先知等安全社区
⭐️ 点点点工程师系列
🍹 测试神器 - Charles 篇
🍹 测试神器 - Fiddler 篇
🍹 测试神器 - Jmeter 篇
🍹 自动化 - RobotFrameWork 系列
🍹 自动化 - 基于 JAVA 实现的WEB端UI自动化
🍹 自动化 - 基于 MonkeyRunner 实现的APP端UI自动化


该章节我们要学习的是线程的使用,前面的学习我们知道进程的使用需要获取 CPU和内存 的资源,而线程则是利用进程的资源来执行业务,并且通过创建多个线程,对于资源的消耗相对来说会比较低,今天就来看一看线程的使用方法具体有哪些吧。
文章目录
-
- 🐳 线程的创建与使用
-
- 🐬 线程的创建 -threading
- 🐬 线程对象的常用方法
- 🐬 线程演示案例
-
- 🐋 单线程初始案例
- 🐋 多线程演示案例
- 🐳 线程的问题
🐳 线程的创建与使用
在Python中有很多的多线程模块,其中 threading 模块就是比较常用的。下面就来看一下如何利用 threading 创建线程以及它的常用方法。
🐬 线程的创建 -threading
函数名 介绍 举例 Thread 创建线程 Thread(target, args) Thread 的动能介绍:通过调用
threading模块的Thread类来实例化一个线程对象;它有两个参数:target 与 args(与创建进程时,参数相同)。target为创建线程时要执行的函数,而args为是要执行这个函数时需要传入的参数。
🐬 线程对象的常用方法
接下里看一下线程对象中都有哪些常用的方法:
函数名 介绍 用法 start 启动线程 start() join 阻塞线程直到线程执行结束 join(timeout=None) getName 获取线程的名字 getName() setName 设置线程的名字 setName(name) is_alive 判断线程是否存活 is_alive() setDaemon 守护线程 setDaemon(True)
- start 函数:启动一个线程;没有任何返回值和参数。
- join 函数:和进程中的 join 函数一样;阻塞当前的程序,主线程的任务需要等待当前子线程的任务结束后才可以继续执行;参数为
timeout:代表阻塞的超时时间。- getName 函数:获取当前线程的名字。
- setName 函数:给当前的线程设置名字;参数为
name:是一个字符串类型- is_alive 函数:判断当前线程的状态是否存货
- setDaemon 函数:它是一个守护线程;如果脚本任务执行完成之后,即便进程池还没有执行完成业务也会被强行终止。子线程也是如此,如果希望主进程或者是主线程先执行完自己的业务之后,依然允许子线程继续工作而不是强行关闭它们,只需要设置
setDaemon()为True就可以了。PS:通过上面的介绍,会发现其实线程对象里面的函数几乎和进程对象中的函数非常相似,它们的使用方法和使用场景几乎是相同的。
🐬 线程演示案例
🐋 单线程初始案例
演示 多线程之前 先看一下下面这个案例,运行结束后看看共计耗时多久
1、定义一个列表,里面写一些内容。
2、再定义一个新列表,将上一个列表的内容随机写入到新列表中;并且删除上一个列表中随机获取到的内容。
3、这里需要使用到
r andom内置模块
代码示例如下:
# coding:utf-8import timeimport randomold_lists = ['罗马假日', '怦然心动', '时空恋旅人', '天使爱美丽', '天使之城', '倒霉爱神', '爱乐之城']new_lists = []def work(): if len(old_lists) == 0: # 判断 old_list 的长度,如果为0 ,则表示 该列表的内容已经被删光了 return '\'old_list\' 列表内容已经全部删除' old_choice_data = random.choice(old_lists) # random 模块的 choice函数可以随机获取传入的 old_list 的元素 old_lists.remove(old_choice_data) # 当获取到这个随机元素之后,将该元素从 old_lists 中删除 new_choice_data = '%s_new' % old_choice_data # 将随机获取到的随机元素通过格式化方式重新赋值,区别于之前的元素 new_lists.append(new_choice_data) # 将格式化的新的随机元素添加至 new_lists 列表 time.sleep(1)if __name__ == '__main__': strat_time = time.time() for i in range(len(old_lists)): work() if len(old_lists) ==0: print('\'old_lists\' 当前为:{}'.format(None)) else: print(('\'old_lists\' 当前为:{}'.format(old_lists))) if not len(new_lists) == 0: print(('\'new_lists\' 当前为:{}'.format(new_lists))) else: print('\'new_lists\' 当前为:{}'.format(None)) end_time = time.time() print('运行结束,累计耗时:{} 秒'.format(end_time - strat_time))运行结果如下:
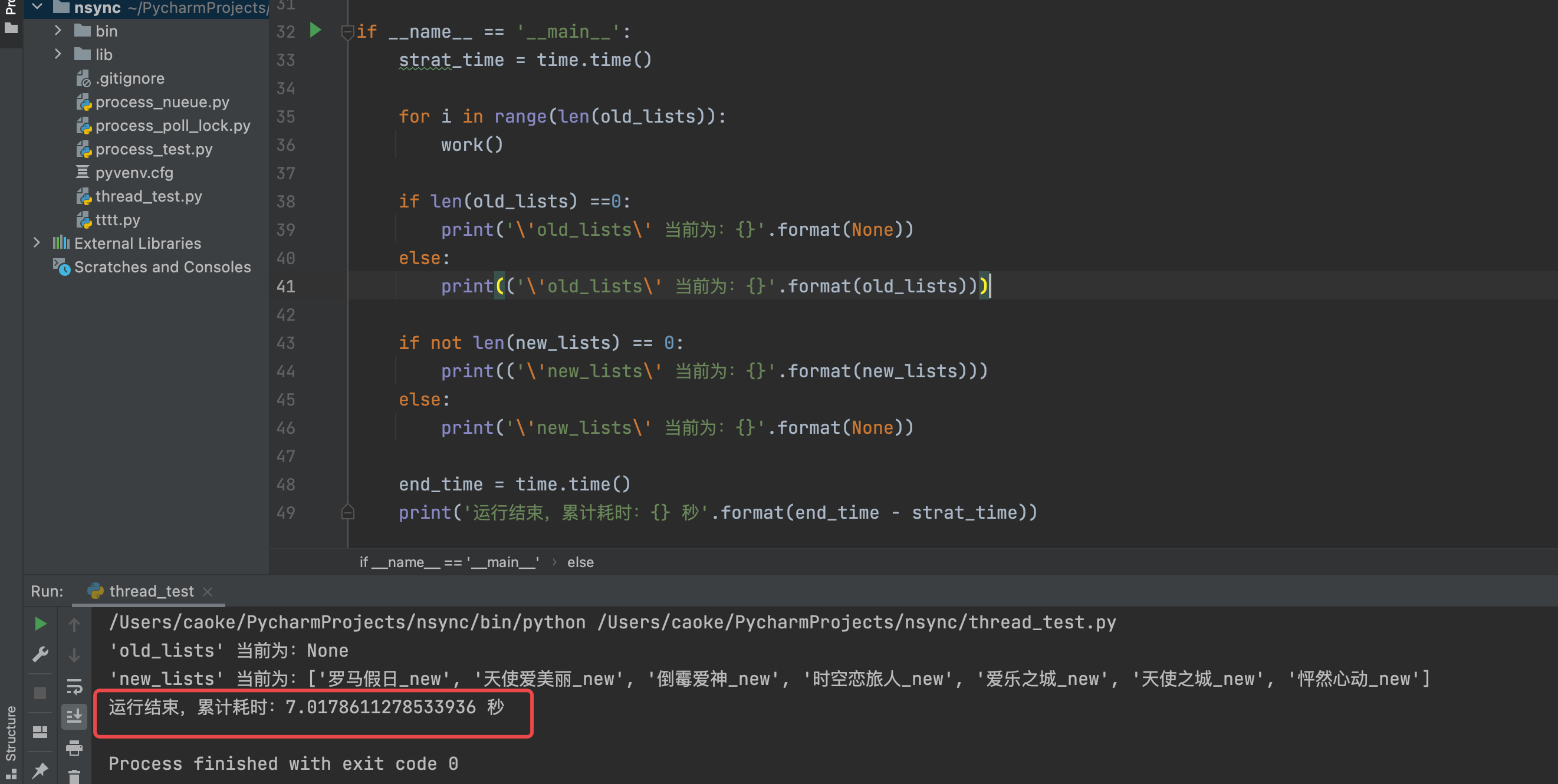
从运行输出结果我们可以看到整个脚本运行共计耗时7秒,而且 new_lists 列表内的元素都经过格式化处理后加上了 _new ;不仅如此, 因为 random模块的choice函数 原因,new_lists 的内容顺序与 old_lists 也是不一样;每次运行顺序都会不一样,所以 old_lists 的顺序是无法得到保障的。
🐋 多线程演示案例
代码示例如下:
# coding:utf-8import timeimport randomimport threadingold_lists = ['罗马假日', '怦然心动', '时空恋旅人', '天使爱美丽', '天使之城', '倒霉爱神', '爱乐之城']new_lists = []def work(): if len(old_lists) == 0: # 判断 old_list 的长度,如果为0 ,则表示 该列表的内容已经被删光了 return '\'old_list\' 列表内容已经全部删除' old_choice_data = random.choice(old_lists) # random 模块的 choice函数可以随机获取传入的 old_list 的元素 old_lists.remove(old_choice_data) # 当获取到这个随机元素之后,将该元素从 old_lists 中删除 new_choice_data = '%s_new' % old_choice_data # 将随机获取到的随机元素通过格式化方式重新赋值,区别于之前的元素 new_lists.append(new_choice_data) # 将格式化的新的随机元素添加至 new_lists 列表 time.sleep(1)if __name__ == '__main__': strat_time = time.time() print('\'old_lists\'初始长度为:{}'.format(len(old_lists)))# 获取 old_lists 与 new_lists 最初始的长度 print('\'new_lists\'初始长度为:{}'.format(len(new_lists))) thread_list = [] # 定义一个空的 thread_list 对象,用以下方添加每个线程 for i in range(len(old_lists)): thread_work = threading.Thread(target=work) # 定义一个线程实例化对象执行 work 函数,因为 work 函数没有参数所以不用传 args thread_list.append(thread_work) # 将 thread_work 添加进 thread_list thread_work.start() # 启动每一个线程 for t in thread_list: # 通过for循环将每一个线程进行阻塞 t.join() if len(old_lists) ==0: print('\'old_lists\' 当前为:{}'.format(None), '当前长度为:{}'.format(len(old_lists))) else: print(('\'old_lists\' 当前为:{}'.format(old_lists))) if not len(new_lists) == 0: print('\'new_lists\' 当前长度为:{}'.format(len(new_lists))) print('\'new_lists\' 当前的值为:{}'.format(new_lists)) else: print('\'new_lists\' 当前为:{}'.format(None)) end_time = time.time() print('运行结束,累计耗时:{} 秒'.format(end_time - strat_time))运行结果如下:
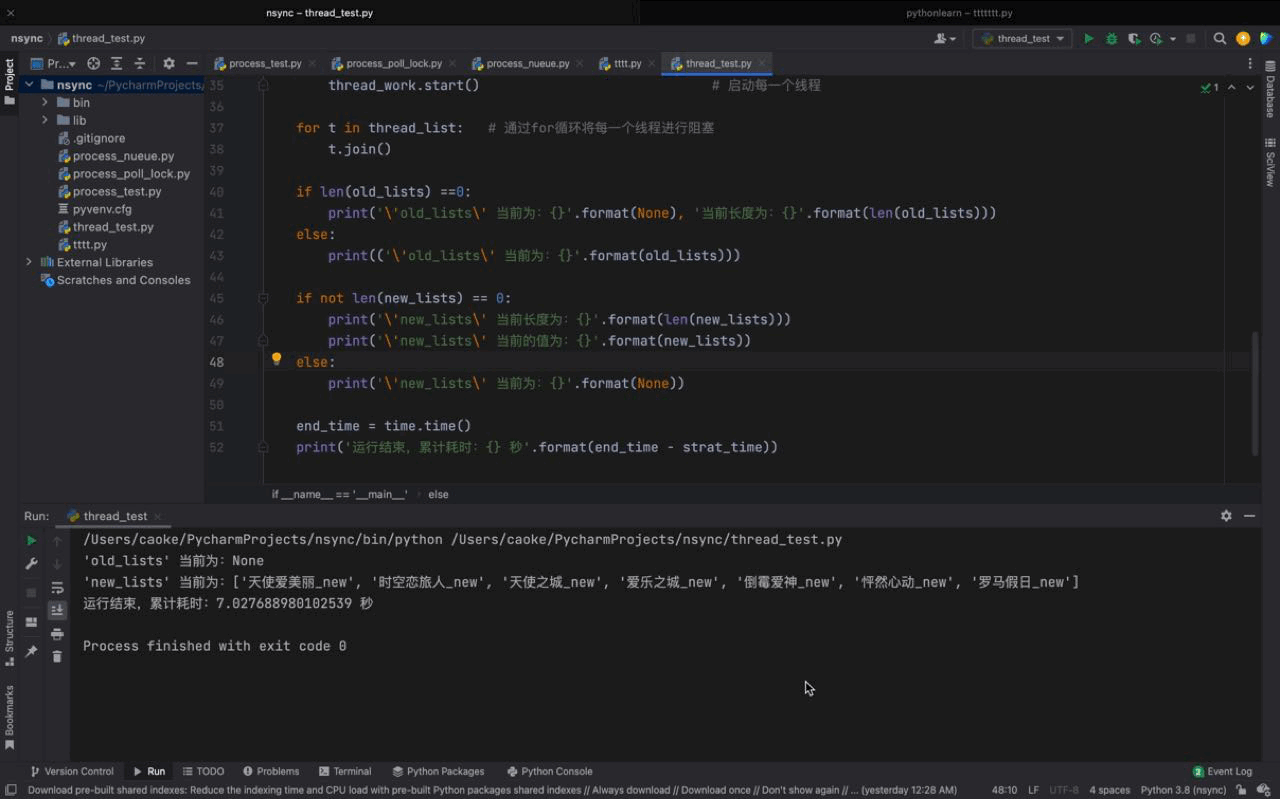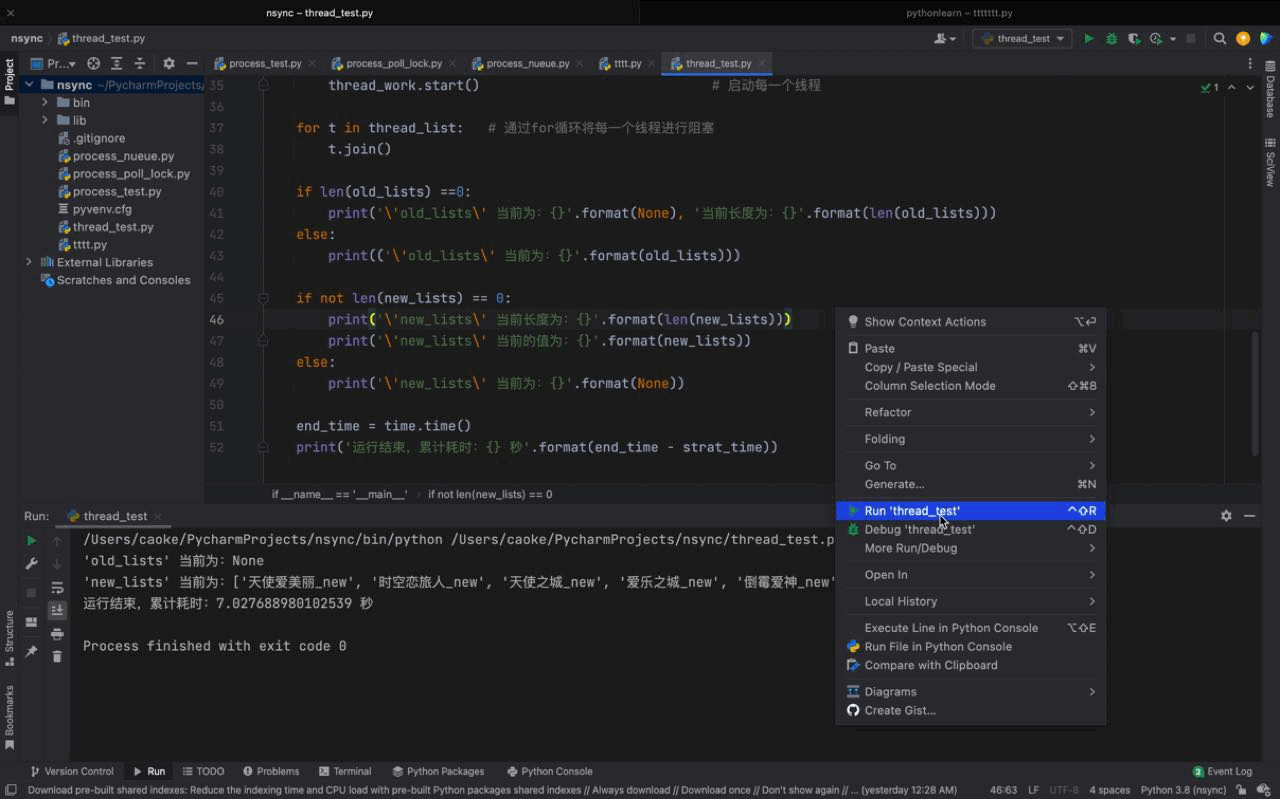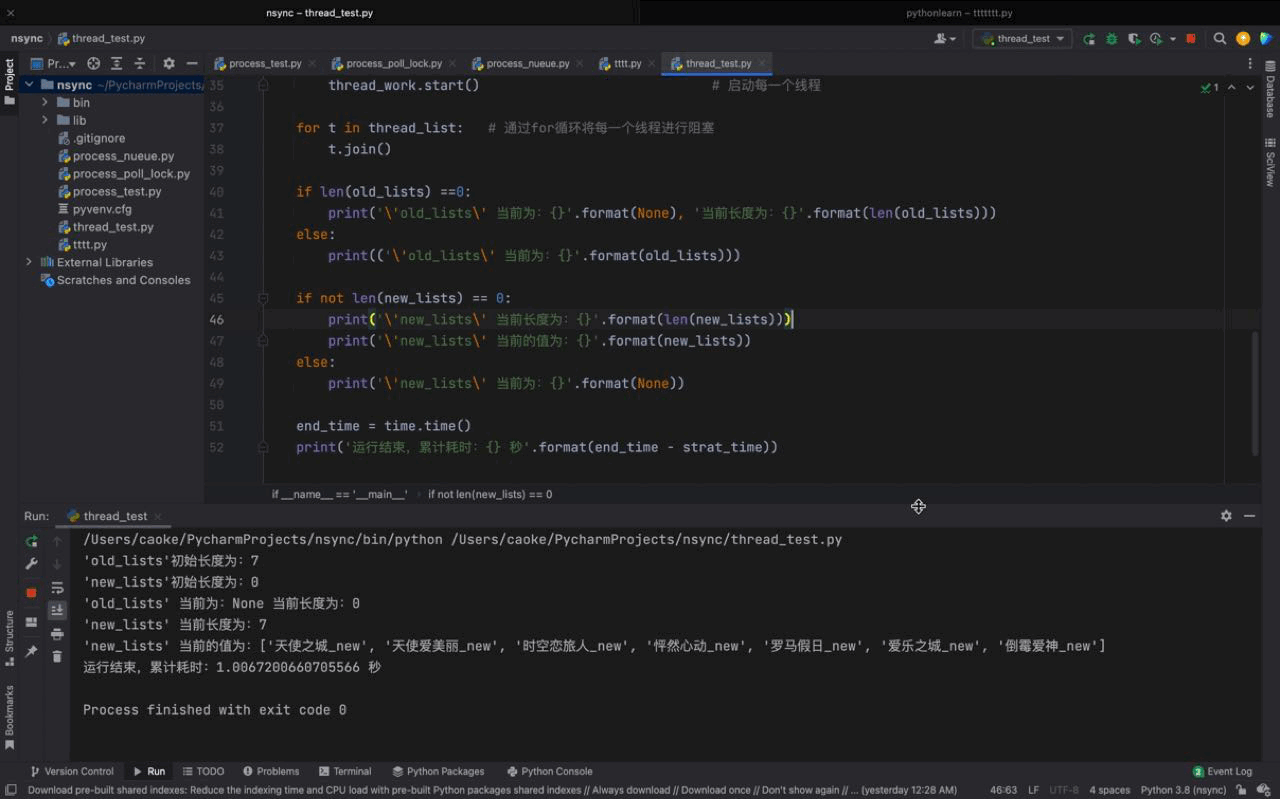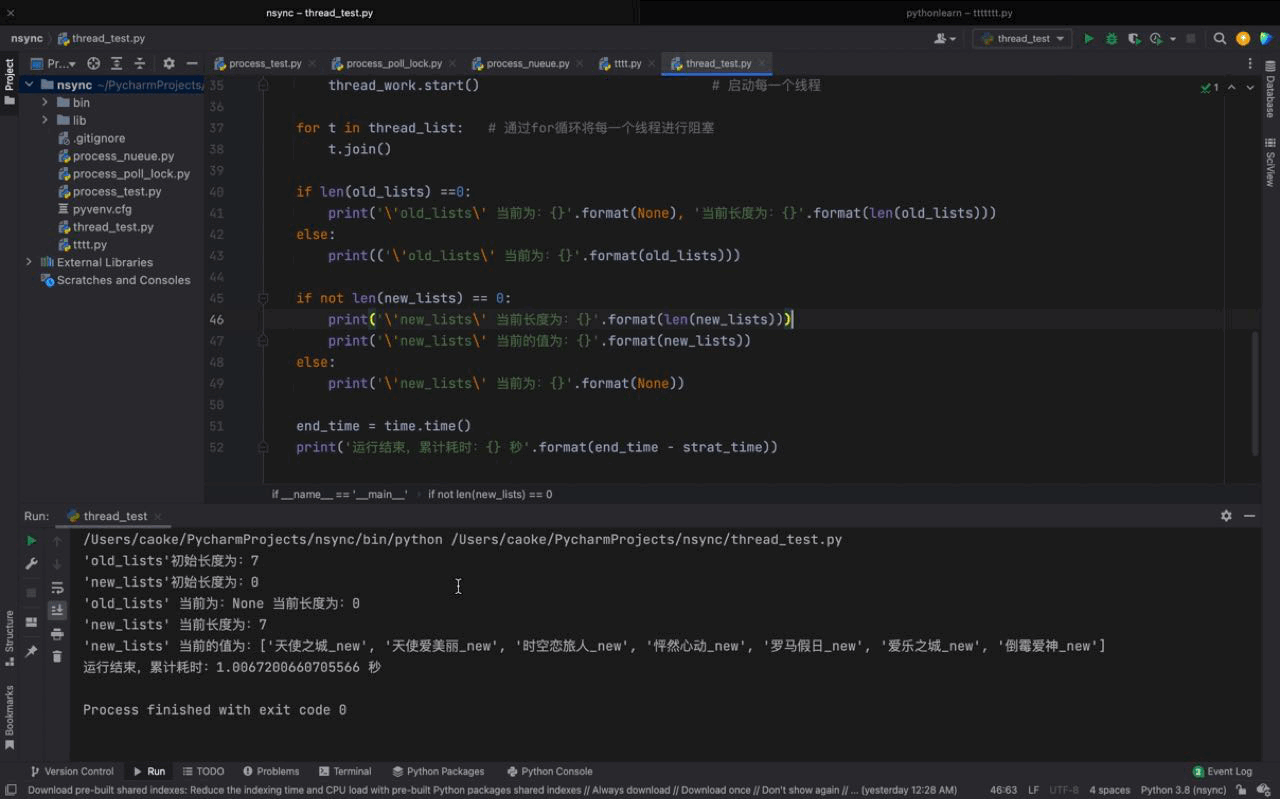
从运行的结果来看,我们初始的单线程任务耗时为 7秒,在使用多线程之后,仅耗时 1秒就完成了,大大的提高了我们的运行效率。
🐳 线程的问题
通过上面的练习,我们发现进程的使用方法几乎与进程是一模一样的。它们都可以互不干扰的执行程序,也可以使得主线程的程序不需要等待子线程的任务完成之后再去执行。只不过刚刚的演示案例中我们使用了 join() 函数进行了阻塞,这里可以吧 join() 去掉,看看执行效果。
与进程一样,线程也存在着一定的问题。
- 线程执行的函数,也同样是无法获取返回值的。
- 当多个线程同时修改文件一样会造成被修改文件的数据错乱的错误(因为都是并发去操作一个文件,特别是在处理交易场景的时候,需要尤为注意)。
关于这些线程中存在的问题同样是可以解决的,在下一章节的 线程池与全局锁 我们会有详细的介绍。

