Python 从无到有搭建WebUI自动化测试框架
目录
前言
1、Python库选择
2、分层设计
3、基础类
浏览器
页面操作
4、公共类
获取框架项目目录的绝对路径
读取excel用例
读取config配置
核心处理工厂
ddt驱动代码
执行并输出报告
打印Log
发送邮件
前言
一个迭代频繁的项目,少不了自动化测试,冒烟与回归全部使用自动化测试来实现,释放我们的人工来测试一些重要的,复杂的工作。节省成本是自动化测试最终目标
Python搭建自动化测试框架是高级测试的标志之一
核心处理工厂是一个骚操作
如果大家都懂了的核心工厂代码,实现了UI自动化框架后,做UI自动化测试时,时间成本比PO模式要低100倍,人力成本可以用初级测试工程师
PO :PageObject
为啥要注释PO呢,有人私下给我留言,意思是我这框架没用PageObject,不行,没写好。
事实上,PO时间和人力成本过于高了。个人追求高效高速低成本的目标,对于这个追求来说,PO它已经跟不上时代了,注定要淘汰。
介如很多朋友问源码,我就将其放在这里,:https://gitee.com/kerici/testUI.git
1、Python库选择
这套框架主要的Python库有 Selenium、unittest、ddt、HTMLTestRunner、win32gui、win32con、openpyxl、configparser、logging、smtplib、os等等
其中Selenium、unittest、ddt、HTMLTestRunner是框架核心模块,Selenium通过html属性得到元素,进而操作元素的方法属性,unittes单元测试模块与ddt数据驱动结合可以实现用例的收集与执行,HTMLTestRunner输出自动化测试报告。
win32gui、win32con操作浏览器一些windows的弹出框,比如上传文件的弹出框
openpyxl库读取excel文件,收集用例
configparser库读取config配置文件,实现常规流程设置可配
logging库输出自动化用例执行日志
smtplib使用email发送测试报告
os获取一些工程里的绝对路径
2、分层设计
目录:
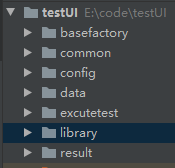
分层设计如目录
所谓分层设计:即是相同属性或类型的代码模块放到同一个目录下,使代码管理,扩展,维护待方便。
basefactory :存放浏览器操作与网页操作的基础代码库与一些浏览器驱动
common:存放执行工厂,收集用例,收集路径,读取配置文件的一代码库
config:存放配置文件
data:存放用例文件
excutetest:存放数据驱动用例代码
library:存放独立三方库,方便自行优化第三方库,引用方便,三方库跟着工程走,不会换环境又要重新下载
result:有三个子目录,log目录,report目录,screenshot目录
3、基础类
浏览器
浏览器操作,有开浏览器,关闭浏览器,切换网页,上传附件等等
个人喜好谷歌浏览器,所以IE与火狐暂没兼容,
1、配置浏览器驱动
首先我们需要下载一个浏览器驱动,下驱动之前先确认下本地浏览器版本
从谷歌浏览器右上角-点击自定义与控制-帮助-关于Google Chrome(G) 找到版本信息,我的是83.0.4103.61

浏览器输入淘宝的谷歌驱动镜像
http://npm.taobao.org/mirrors/chromedriver
找到一个与版本相同或相近的版本驱动

选择与电脑系统对应的驱动下载,一般有linux、mac、win三种。
我的是window系统。所以就下载win32版本,放心64位的系统可以用

下载下来的驱动是个zip,解压出一个chromedriver.exe文件

驱动如何配置,可以参照
https://blog.csdn.net/yinshuilan/article/details/78742728
而我个人喜欢直接丢在当前工程的目录下,放在基础目录 ,方便直接用,随时换。
其实建议按上面链接里的来,换环境方便,我这只是简单粗暴。
2、调试驱动是否有用
在browseroperator.py里写一段代码,
from selenium import webdriverdriver = webdriver.Chrome()driver.get('https://www.baidu.com')run,结果是自动打开谷歌进入百度了,安排

3、封装浏览器--初始化浏览器
谷歌驱动能用,万事俱备只欠东风,现我们来实现这个东风
代码引用里有from common.getconf import Config要先实现一个Config类,因为我们要的基础类里要用到一个配置项,这也是为了以后做大做强的需要一个东西,先说一下,具体见【读取config配置】
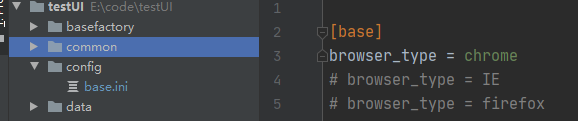
在config 目录下有一个配置文件,配置文件里配置了浏览器类型,只是为了以后能兼容三种浏览器,目前配置了chrome
首先我们新建名为BrowserOperator的类,初始化配置类的对象,获取到浏览器类型的配置项,得到驱动的目录。初始化用到了os
所以我们要import os
class BrowserOperator(object): def __init__(self): self.conf = Config() self.driver_path = os.path.join(BASEFACTORYDIR, 'chromedriver.exe') self.driver_type = str(self.conf.get('base', 'browser_type')).lower()然后我们在基础类里实现一个方法def open_url(self, kwargs): 打开浏览器,方法使用了不定长参数 kwargs接收传参,所以只能传指定参数或整个字典,
def open_url(self, kwargs): """ 打开网页 :param url: :return: 返回 webdriver """ try: url = kwargs['locator'] except KeyError: return False, '没有URL参数'这一段,kwargs里如果有locator,这是用例用例设计的一个参数,它负责传url与元素定位,后面讲excel读取时会说到的。
可以写成url = kwargs.get('locator'),就不需要try了,但要判断url是不是为None,是None还是要return False, ‘没有参数’,两个返回值是全框架设计的返回形式,用一个布尔值确认我的用例执行的成败,后面返回对象或执行日志。至于我写try,个人代码风格。
try: if self.driver_type == 'chrome': #处理chrom弹出的info # chrome_options = webdriver.ChromeOptions() # #option.add_argument('disable-infobars') # chrome_options.add_experimental_option("excludeSwitches", ['enable-automation']) # self.driver = webdriver.Chrome(options=chrome_options, executable_path=self.driver_path) self.driver = webdriver.Chrome(executable_path=self.driver_path) self.driver.maximize_window() self.driver.get(url) elif self.driver_type == 'ie': print('IE 浏览器') else: print('火狐浏览器') except Exception as e: return False, e return True, self.driver上面一段内容,判断是哪个浏览器,然后指定驱动浏览器打开url。
核心代码
self.dirver = webdriver.Chrome(executable_path=self.driver_path)
此时代码会自动帮我们打开一个浏览器,将浏览的句柄赋值给self.driver。这个句柄是操作网页元素的一个把手,不到浏览器关闭,它不会释放。
然后我们就可以用self.driver.get(url) 打开网站了。
外围包了一个try,就是如果浏览器驱动失败了,我们将返回一个Flase和异常,如果成功了,返回一个True 和浏览器 对象driver,
这里有人会问,driver已经返回了,还把它搞成self.driver 干啥呢,因为这个类后期的关闭浏览器,上传附件等操作要用到这个对象。
哦对了,你们不要问这个把浏览器最大化的方法了,万能固定写法: self.driver.maximize_window()
写完这个,我们来调试一把,在browseroperator.py文件下面写下两代码,然后运行
wd = BrowserOperator()wd.open_url(locator='https://www.qq.com')对的,locator='https://ww.....' 这就是指定传参
run,结果是打开了qq网站,说明代码已经执行成功了

然后我们改一下代码,
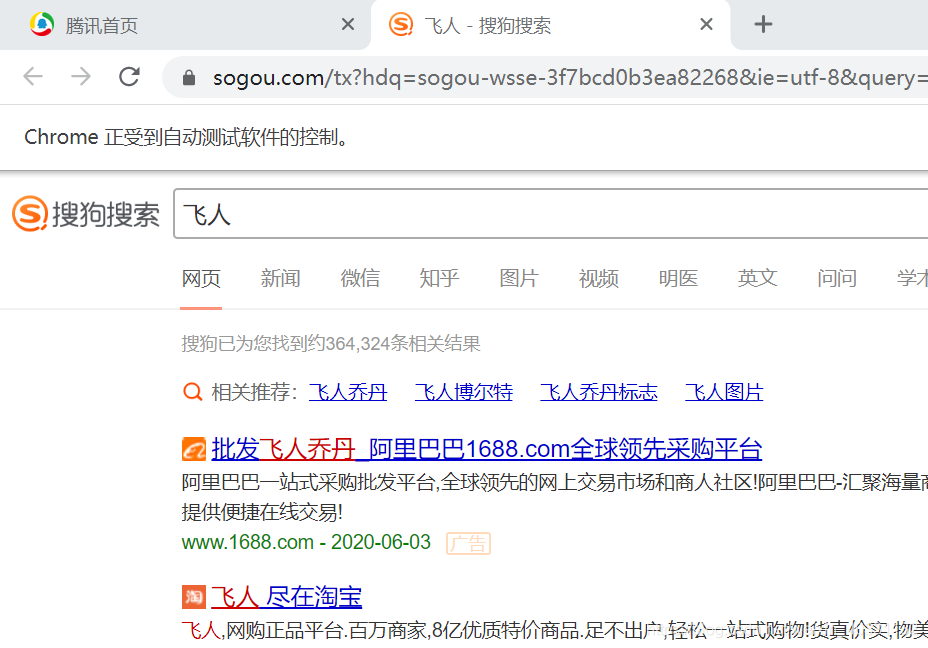
wd = BrowserOperator()isOK, deiver = wd.open_url(locator='https://www.qq.com')time.sleep(5)deiver.find_elements_by_xpath('//*[@id="sougouTxt"]')[0].send_keys('飞人')deiver.find_elements_by_xpath('//*[@id="searchBtn"]')[0].click()结果他开始搜索飞人了,说明第一步打开浏览器返回操作对象很成功。
4、关闭浏览器
在类下面实现一个方法def close_browser(self, kwargs):
def close_browser(self, kwargs): """ 关闭浏览器 :return: """ time.sleep(1) self.driver.quit() time.sleep(2) return True, '关闭浏览器成功'里面的的睡眠时间很重要的,不然调试时肉眼看不到最后执行结果与否,浏览器就关掉了。
关键代码self.driver.quit(),这个方法退出浏览器,哈哈哈
wd = BrowserOperator()isOK, deiver = wd.open_url(locator='https://www.qq.com')time.sleep(5)deiver.find_elements_by_xpath('//*[@id="sougouTxt"]')[0].send_keys('飞人')deiver.find_elements_by_xpath('//*[@id="searchBtn"]')[0].click()wd.close_browser()在执行代码后面添加一行wd.close_browser()
run,看着他打开浏览器,搜索飞人,然后关闭浏览器,执行通过。
上传附件,后面写完用例模块时,才能涉及到。网上也有很多上传附件的实现方法。所以就不说了,里面涉及windows的消息机制,很高深,照搬代码即可。
browseroperator.py里所有的代码提供给各位看官,希望多给两个赞,谢谢
import osimport win32guiimport win32conimport timefrom selenium import webdriverfrom common.getconf import Configfrom common.getfiledir import BASEFACTORYDIRfrom pywinauto import applicationclass BrowserOperator(object): def __init__(self): self.conf = Config() self.driver_path = os.path.join(BASEFACTORYDIR, 'chromedriver.exe') self.deriver_type = str(self.conf.get('base', 'browser_type')).lower() def open_url(self, kwargs): """ 打开网页 :param url: :return: 返回 webdriver """ try: url = kwargs['locator'] except KeyError: return False, '没有URL参数' try: if self.deriver_type == 'chrome': #处理chrom弹出的info # chrome_options = webdriver.ChromeOptions() # #option.add_argument('disable-infobars') # chrome_options.add_experimental_option("excludeSwitches", ['enable-automation']) # self.driver = webdriver.Chrome(options=chrome_options, executable_path=self.driver_path) self.driver = webdriver.Chrome(executable_path=self.driver_path) self.driver.maximize_window() self.driver.get(url) elif self.deriver_type == 'ie': print('IE 浏览器') else: print('火狐浏览器') except Exception as e: return False, e return True, self.driver def close_browser(self, kwargs): """ 关闭浏览器 :return: """ time.sleep(1) self.driver.quit() time.sleep(2) return True, '关闭浏览器成功' def upload_file(self, kwargs): """ 上传文件 :param kwargs: :return: """ try: dialog_class = kwargs['type'] file_dir = kwargs['locator'] button_name = kwargs['index'] except KeyError: return True, '没传对话框的标记或没传文件路径,' if self.deriver_type == "chrome": title = "打开" elif self.deriver_type == "firefox": title = "文件上传" elif self.deriver_type == "ie": title = "选择要加载的文件" else: title = "" # 这里根据其它不同浏览器类型来修改 # 找元素 # 一级窗口"#32770","打开" dialog = win32gui.FindWindow(dialog_class, title) if dialog == 0: return False, '传入对话框的class定位器有误' # 向下传递 ComboBoxEx32 = win32gui.FindWindowEx(dialog, 0, "ComboBoxEx32", None) # 二级 comboBox = win32gui.FindWindowEx(ComboBoxEx32, 0, "ComboBox", None) # 三级 # 编辑按钮 edit = win32gui.FindWindowEx(comboBox, 0, 'Edit', None) # 四级 # 打开按钮 button = win32gui.FindWindowEx(dialog, 0, 'Button', button_name) # 二级 if button == 0: return False, '按钮text属性传值有误' # 输入文件的绝对路径,点击“打开”按钮 win32gui.SendMessage(edit, win32con.WM_SETTEXT, None, file_dir) # 发送文件路径 time.sleep(1) win32gui.SendMessage(dialog, win32con.WM_COMMAND, 1, button) # 点击打开按钮 return True, '上传文件成功'页面操作
浏览器的代码先告一段落,接着得实现页面元素的操作类了
1、引用模块,导包
import osimport timefrom selenium.common.exceptions import NoSuchElementException, TimeoutExceptionfrom selenium.webdriver import Chromefrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.common.by import Byfrom common.getfiledir import SCREENSHOTDIRos 用来处理截图保存的路径
time处理等待、隐式、显示等待
NoSuchElementException, TimeoutException 前一个隐式等待的异常,后一个显示等的异常
Chrome用来声明driver是Chrome对象,方便driver联想出来方法
expected_conditions 判断元素的16种方法,显示等待用到
WebDriverWait 显示等待
By 可以By.ID,By.NAME等来用来决定元素定位,显示等待中用
SCREENSHOTDIR 截图路径,从getfiledir模块出来,具体见【获取工程绝对路径】
2、初始化类
创建一个类WebdriverOperator类并初始化,因为他需要浏览器driver对象,所以初始化这个对象为私有属性
class WebdriverOperator(object): def __init__(self, driver:Chrome): self.driver = driver这个也不好调试,先过
2、实现截图
先初始化文件路径与文件名称,文件名使用时间戳命名,保存为png
pic_name = str.split(str(time.time()), '.')[0] + str.split(str(time.time()), '.')[1] + '.png' screent_path = os.path.join(SCREENSHOTDIR, pic_name)
这两行就是实现文件路径的代码
self.driver.get_screenshot_as_file(screent_path)
截屏代码,因为我们是截浏览器的屏,所以使用self.driver对象调用截屏方法,传入路径,它便会自动截屏保存在screent_path文件中,最后返回路径,具休代码如下
def get_screenshot_as_file(self): """ 截屏保存 :return:返回路径 """ pic_name = str.split(str(time.time()), '.')[0] + str.split(str(time.time()), '.')[1] + '.png' screent_path = os.path.join(SCREENSHOTDIR, pic_name) self.driver.get_screenshot_as_file(screent_path) return screent_path我们来调试一下这个代码
在basefactory目录下面请建一个test.py文件
from basefactory.browseroperator import BrowserOperatorfrom basefactory.webdriveroperator import WebdriverOperatorbo = BrowserOperator()isOK, deiver = bo.open_url(locator='https://www.qq.com')wb = WebdriverOperator(deiver)result = wb.get_screenshot_as_file() #调用截图方法,返回路径打印print(result)输入这么一段代码。
run,它会打开浏览器,进入qq网站主页,然后打印截图文件目录

找到对应目录 与文件,截图方法调试成功
3、隐式等待
gotosleep(),这个方法不说了,死等。
隐式等待,等待页面元素加载成功便完成等待任务,只需要在用例初始化浏览器之处调用一次,全局可用,其实他只是一行代码,但为了符合框架统一,也封装一下,代码如下:
def web_implicitly_wait(self, kwargs): """ 隐式等待 :return: type 存时间 """ try: s = kwargs['time'] except KeyError: s = 10 try: self.driver.implicitly_wait(s) except NoSuchElementException: return False, '隐式等待设置失败' return True, '隐式等待设置成功'其实只有一行代码 self.driver.implicitly_wait(s) 有用的,里面的s是用例传过来的,调试时,只需要传指定time传一个数字,例:time=5,每次页面刷新,程序将等待页面元素加载5秒,5秒后,不管加载成功与否都执行下一行代码,如果2秒有加载完,那么不必等5秒,直接执行下一行代码
切记,隐式等待只需要初始化浏览器调用一次,后面的代码都会隐式等待。
因为我本地网速太好,打开了两个网络视频播放器去调试网页都没法使网页长时间加载,所以只贴上调试代码,结果自己看吧。
在test.py里更新调试代码
from basefactory.browseroperator import BrowserOperatorfrom basefactory.webdriveroperator import WebdriverOperatorbo = BrowserOperator()isOK, deiver = bo.open_url(locator='https://www.baidu.com')wb = WebdriverOperator(deiver)isOK, result = wb.web_implicitly_wait() #设置隐式等待,打印隐式等待的结果print(result)deiver.find_elements_by_xpath('//*[@id="kw"]')[0].send_keys('飞人')deiver.find_elements_by_xpath('//*[@id="su"]')[0].click()deiver.find_elements_by_xpath('//*[@id="rs"]/div')4、显示等待
隐式等待在页面切换后,加载成功但没展示出来,disable,hide等场景时,也能等待成功。所以不能满足需求。我们需要更强大的等待元素的方法,显示等待,代码如下:
def web_element_wait(self, kwargs): """ 等待元素可见 :return: """ try: type = kwargs['type'] locator = kwargs['locator'] except KeyError: return False, '未传需要等待元素的定位参数' try: s = kwargs['time'] if s is None: s = 30 except KeyError: s = 30 try: if type == 'id': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.ID, locator))) elif type == 'name': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.NAME, locator))) elif type == 'class': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.CLASS_NAME, locator))) elif type == 'xpath': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.XPATH, locator))) elif type == 'css': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.CSS_SELECTOR, locator))) else: return False, '不能识别元素类型[' + type + ']' except TimeoutException: screenshot_path = self.get_screenshot_as_file() return False, '元素[' + locator + ']等待出现失败,已截图[' + screenshot_path + '].' return True, '元素[' + locator + ']等待出现成功'这两行
type = kwargs['type']
locator = kwargs['locator']
type是用例设计里的locator定位器的类型,有id,name,xpath等主要定位类型,locator定位参数
所以我们调式时,就传两个参数,一个type='' 一个locator=‘’ ,例type='xpath', locator='//*[@id="kw"]'
s = kwargs['time'] 哦,还有这个,传入时间,如果没传,默认等待30秒
核心代码
WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.ID, locator)))
每0.5秒轮寻一次属性id为locator的元素是否可见,可见就跳出等待,返回等等元素出现成功;超过s秒便等待失败,返回元素等待出现失败,截图等信息。
调试一把,在test.py里修改代码如下
from basefactory.browseroperator import BrowserOperatorfrom basefactory.webdriveroperator import WebdriverOperatorbo = BrowserOperator()isOK, deiver = bo.open_url(locator='https://www.baidu.com')wb = WebdriverOperator(deiver)isOK, result = wb.web_element_wait(type='xpath', locator='//*[@id="kw"]', s=0.001)print(result)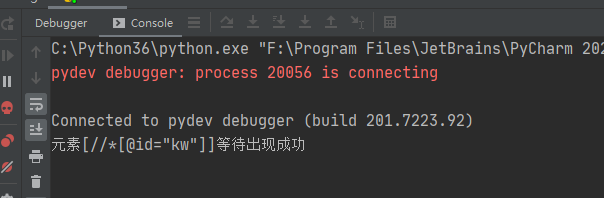
设置0.001秒,也能成功,网速太快了,失败的例子等各位来重现了,不想去使用高延迟工具了。
5、输入操作
输入,元素的send_key() 方法,所以在WebdriverOperator类里实现一个element_input方法,代码如下:
def element_input(self, kwargs): """ :param kwargs: :return: """ try: type = kwargs['type'] locator = kwargs['locator'] text = str(kwargs['input']) except KeyError: return False, '缺少传参' try: index = kwargs['index'] except KeyError: index = 0 try: if type == 'id': elem = self.driver.find_elements_by_id(locator)[index] elif type == 'name': elem = self.driver.find_elements_by_name(locator)[index] elif type == 'class': elem = self.driver.find_elements_by_class_name(locator)[index] elif type == 'xpath': elem = self.driver.find_elements_by_xpath(locator)[index] elif type == 'css': elem = self.driver.find_elements_by_css_selector(locator)[index] else: return False, '不能识别元素类型:[' + type + ']' except Exception as e: screenshot_path = self.get_screenshot_as_file() return False, '获取[' + type + ']元素[' + locator + ']失败,已截图[' + screenshot_path + '].' try: elem.send_keys(text) except Exception: screenshot_path = self.get_screenshot_as_file() return False, '元素['+ locator +']输入['+ text +']失败,已截图[' + screenshot_path + '].' return True, '元素['+ locator +']输入['+ text +']成功'代码
type = kwargs['type']locator = kwargs['locator']text = str(kwargs['input'])index = kwargs['index']type是用例设计里的locator定位器的类型,有id,name,xpath等主要类型,locator定位参数,input输入的内容,index是元素的在List里下标,一般页面相同的元素会有很多,我们find元素是得到一个list的结果,需要通过下标来取到自己想到的那个元素。不传默认为第0个。
所以我们调式时,就传四个参数,一个type='' 一个locator=‘’input='' index= ,例type='xpath', locator='//*[@id="kw"]', input='飞人',index=0
这一部分代码
try: if type == 'id': elem = self.driver.find_elements_by_id(locator)[index] elif type == 'name': elem = self.driver.find_elements_by_name(locator)[index] elif type == 'class': elem = self.driver.find_elements_by_class_name(locator)[index] elif type == 'xpath': elem = self.driver.find_elements_by_xpath(locator)[index] elif type == 'css': elem = self.driver.find_elements_by_css_selector(locator)[index] else: return False, '不能识别元素类型:[' + type + ']'except Exception as e: screenshot_path = self.get_screenshot_as_file() return False, '获取[' + type + ']元素[' + locator + ']失败,已截图[' + screenshot_path + '].'是用来查找页面元素是否存在的,如果存在,将元素找到存在elem变量,继续执行,如果失败,截图,返回False与失败日志
通过type判断,我们使用哪种元素定位方法,这些是基础,不懂的朋友可百度一下寻找元素定位的方法。
输入input的代码:
try: elem.send_keys(text)except Exception: screenshot_path = self.get_screenshot_as_file() return False, '元素['+ locator +']输入['+ text +']失败,已截图[' + screenshot_path + '].'return True, '元素['+ locator +']输入['+ text +']成功'输入成功,返回True与成功日志,失败,截图并返回False与失败日志
然后我们来调试一把,在test.py文件里更新代码如下:
bo = BrowserOperator()isOK, deiver = bo.open_url(locator='https://www.baidu.com')wb = WebdriverOperator(deiver)isOK, result = wb.web_element_wait(type='xpath', locator='//*[@id="kw"]', s=0.001)print(result)isOK, result = wb.element_input(type='xpath', locator='//*[@id="kw"]', input='飞人', index=0) #元素输入方法print(result)run,结果打开百度,在编搜索框输入 ‘飞人’,因为还没做点击,先不click百度一下了
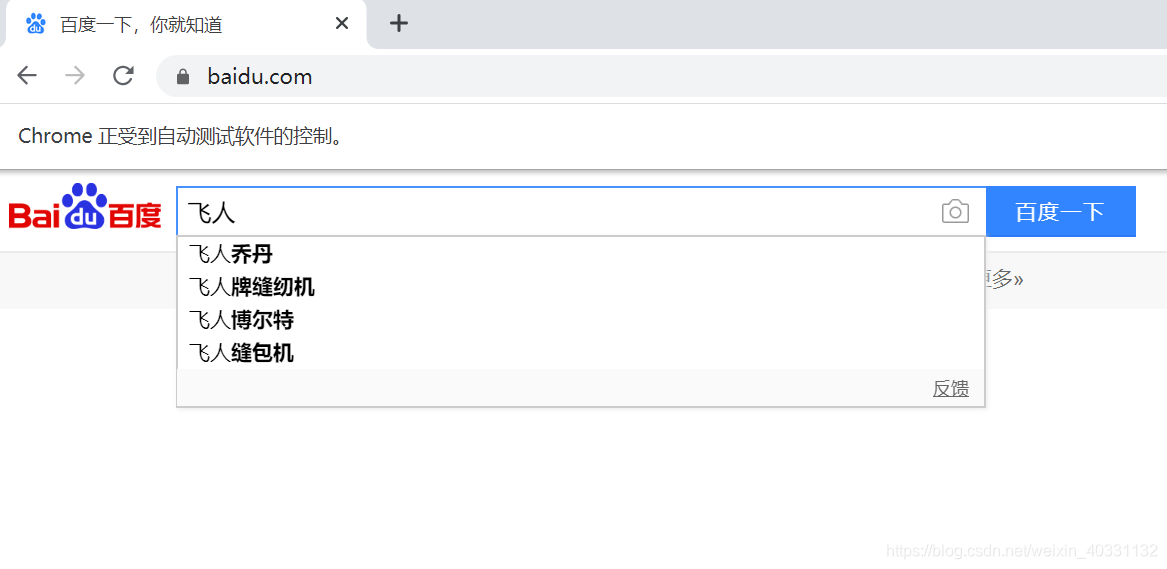
再看打印的运行日志
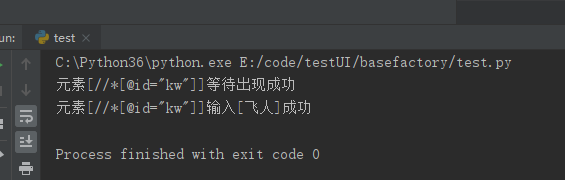
运行成功。
6、优化输入方法
输入方法中的find页面元素是否存在的代码,很多元素操作都需要的。所以再把它分离出来写一个单独的方法find_element,代码如下:
def find_element(self, type, locator, index=None): """ 定位元素 :param type: :param itor: :param index: :return: """ time.sleep(1) #isinstance(self.driver, selenium.webdriver.Chrome.) if index is None: index = 0 type = str.lower(type) try: if type == 'id': elem = self.driver.find_elements_by_id(locator)[index] elif type == 'name': elem = self.driver.find_elements_by_name(locator)[index] elif type == 'class': elem = self.driver.find_elements_by_class_name(locator)[index] elif type == 'xpath': elem = self.driver.find_elements_by_xpath(locator)[index] elif type == 'css': elem = self.driver.find_elements_by_css_selector(locator)[index] else: return False, '不能识别元素类型:[' + type + ']' except Exception as e: screenshot_path = self.get_screenshot_as_file() return False, '获取[' + type + ']元素[' + locator + ']失败,已截图[' + screenshot_path + '].' return True, elem然后我们的输入方法代码修改为:
def element_input(self, kwargs): """ :param kwargs: :return: """ try: type = kwargs['type'] locator = kwargs['locator'] text = str(kwargs['input']) except KeyError: return False, '缺少传参' try: index = kwargs['index'] except KeyError: index = 0 isOK, result = self.find_element(type, locator, index) if not isOK: # 元素没找到,返回失败结果 return isOK, result elem = result try: elem.send_keys(text) except Exception: screenshot_path = self.get_screenshot_as_file() return False, '元素['+ locator +']输入['+ text +']失败,已截图[' + screenshot_path + '].' return True, '元素['+ locator +']输入['+ text +']成功'继续使用用test.py中的代码调试,运行结果与第5点输入操作的运行结果一样,就优化成功了。
7、点击操作
点击操作,元素的click()方法,没有什么好说的,因为他的代码与第5点输入操作一样,只是少了个input参数。所以直接贴代码
def element_click(self, kwargs): """ :param kwargs: :return: """ try: type = kwargs['type'] locator = kwargs['locator'] except KeyError: return False, '缺少传参' try: index = kwargs['index'] except KeyError: index = 0 isOK, result = self.find_element(type, locator, index) if not isOK: #元素没找到,返回失败结果 return isOK, result elem = result try: elem.click() except Exception: screenshot_path = self.get_screenshot_as_file() return False, '元素['+ locator +']点击失败,已截图[' + screenshot_path + '].' return True, '元素['+ locator +']点击成功'调试,在test.py里更新代码
bo = BrowserOperator()isOK, deiver = bo.open_url(locator='https://www.baidu.com')wb = WebdriverOperator(deiver)isOK, result = wb.web_element_wait(type='xpath', locator='//*[@id="kw"]', s=0.001)print(result)isOK, result = wb.element_input(type='xpath', locator='//*[@id="kw"]', input='飞人', index=0)print(result)isOK, result = wb.element_click(type='xpath', locator='//*[@id="su"]', index=0) #元素点击方法print(result)run,运行结果,一切正常
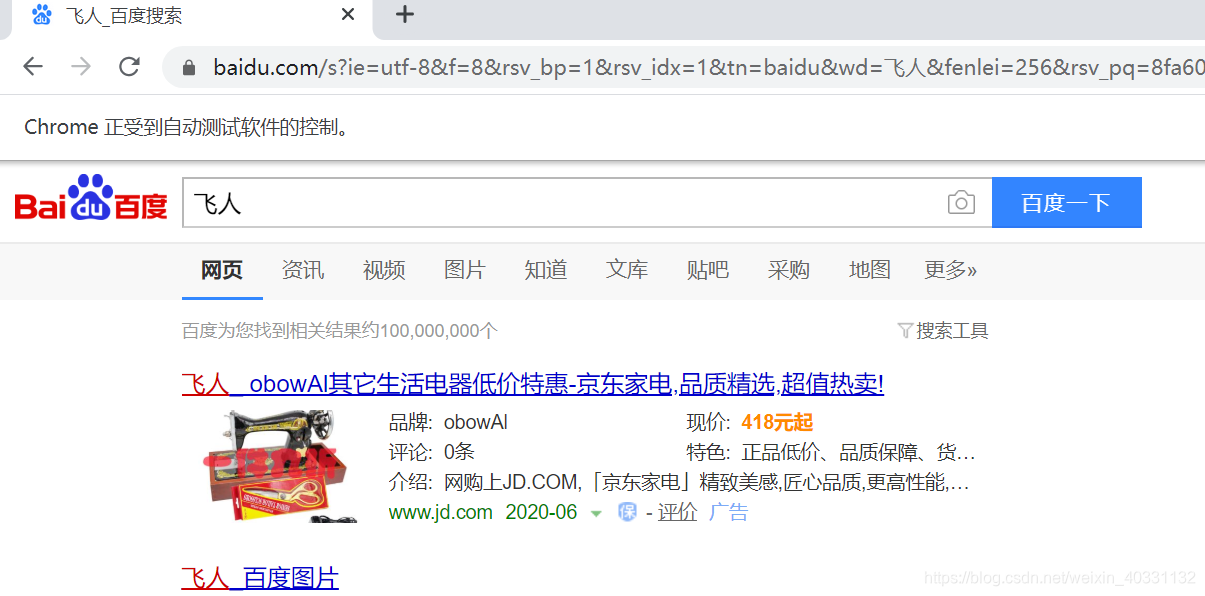
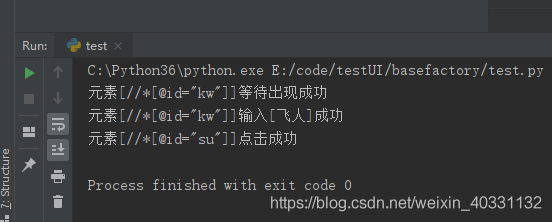
好,基本元素操作的代码解说完了,全部代码如下,不想自己写的可以copy。
还缺少执行JS与一些偏门控件的方法,这些给各位去自个儿写。
import osimport timefrom selenium.common.exceptions import NoSuchElementException, TimeoutExceptionfrom selenium.webdriver import Chromefrom selenium.webdriver.support import expected_conditions as ECfrom selenium.webdriver.support.ui import WebDriverWaitfrom selenium.webdriver.common.by import Byfrom common.getfiledir import SCREENSHOTDIRclass WebdriverOperator(object): def __init__(self, driver:Chrome): self.driver = driver def get_screenshot_as_file(self): """ 截屏保存 :return:返回路径 """ pic_name = str.split(str(time.time()), '.')[0] + str.split(str(time.time()), '.')[1] + '.png' screent_path = os.path.join(SCREENSHOTDIR, pic_name) self.driver.get_screenshot_as_file(screent_path) return screent_path def gotosleep(self, kwargs): time.sleep(3) return True, '等待成功' def web_implicitly_wait(self, kwargs): """ 隐式等待 :return: type 存时间 """ try: s = kwargs['time'] except KeyError: s = 10 try: self.driver.implicitly_wait(s) except NoSuchElementException: return False, '隐式等待 页面元素未加载完成' return True, '隐式等待 元素加载完成' def web_element_wait(self, kwargs): """ 等待元素可见 :return: """ try: type = kwargs['type'] locator = kwargs['locator'] except KeyError: return False, '未传需要等待元素的定位参数' try: s = kwargs['time'] if s is None: s = 30 except KeyError: s = 30 try: if type == 'id': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.ID, locator))) elif type == 'name': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.NAME, locator))) elif type == 'class': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.CLASS_NAME, locator))) elif type == 'xpath': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.XPATH, locator))) elif type == 'css': WebDriverWait(self.driver, s, 0.5).until(EC.visibility_of_element_located((By.CSS_SELECTOR, locator))) else: return False, '不能识别元素类型[' + type + ']' except TimeoutException: screenshot_path = self.get_screenshot_as_file() return False, '元素[' + locator + ']等待出现失败,已截图[' + screenshot_path + '].' return True, '元素[' + locator + ']等待出现成功' def find_element(self, type, locator, index=None): """ 定位元素 :param type: :param itor: :param index: :return: """ time.sleep(1) #isinstance(self.driver, selenium.webdriver.Chrome.) if index is None: index = 0 type = str.lower(type) try: if type == 'id': elem = self.driver.find_elements_by_id(locator)[index] elif type == 'name': elem = self.driver.find_elements_by_name(locator)[index] elif type == 'class': elem = self.driver.find_elements_by_class_name(locator)[index] elif type == 'xpath': elem = self.driver.find_elements_by_xpath(locator)[index] elif type == 'css': elem = self.driver.find_elements_by_css_selector(locator)[index] else: return False, '不能识别元素类型:[' + type + ']' except Exception as e: screenshot_path = self.get_screenshot_as_file() return False, '获取[' + type + ']元素[' + locator + ']失败,已截图[' + screenshot_path + '].' return True, elem def element_click(self, kwargs): """ :param kwargs: :return: """ try: type = kwargs['type'] locator = kwargs['locator'] except KeyError: return False, '缺少传参' try: index = kwargs['index'] except KeyError: index = 0 isOK, result = self.find_element(type, locator, index) if not isOK: #元素没找到,返回失败结果 return isOK, result elem = result try: elem.click() except Exception: screenshot_path = self.get_screenshot_as_file() return False, '元素['+ locator +']点击失败,已截图[' + screenshot_path + '].' return True, '元素['+ locator +']点击成功' def element_input(self, kwargs): """ :param kwargs: :return: """ try: type = kwargs['type'] locator = kwargs['locator'] text = str(kwargs['input']) except KeyError: return False, '缺少传参' try: index = kwargs['index'] except KeyError: index = 0 isOK, result = self.find_element(type, locator, index) if not isOK: # 元素没找到,返回失败结果 return isOK, result elem = result try: elem.send_keys(text) except Exception: screenshot_path = self.get_screenshot_as_file() return False, '元素['+ locator +']输入['+ text +']失败,已截图[' + screenshot_path + '].' return True, '元素['+ locator +']输入['+ text +']成功'4、公共类
获取框架项目目录的绝对路径
先在common目录下新增一个,getfiledir.py的文件
这一段没什么多说的,就是获取本框架各目录的绝对路径
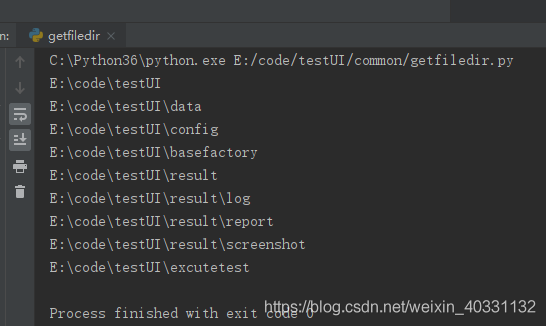
import osdir = os.path.dirname(os.path.dirname(os.path.abspath(__file__)))DATADIR = os.path.join(dir, 'data')CONFDIR = os.path.join(dir, 'config')BASEFACTORYDIR = os.path.join(dir, 'basefactory')RESULTDIR = os.path.join(dir, 'result')LOGDIR = os.path.join(RESULTDIR, 'log')REPORTDIR = os.path.join(RESULTDIR, 'report')SCREENSHOTDIR = os.path.join(RESULTDIR, 'screenshot')CASEDIR = os.path.join(dir, 'excutetest')#print(SCREENSHOTDIR)我们可以在每行代码下面写一个print()语名来打印目录,调试一把,结果如下,所以目录已成功得到
读取excel用例
先在common目录下新增一个getcase.py文件
1、用例设计与用例格式
首先,我们设计测试用例,格式如下:

保存为一个xlsx格式的excel文档,放在data目录下,这个我们的数据目录,也是存放测试用例的目录,数据驱动的数据,也就是这个目录。
读取用例在框架里存放的格式如下,
这个是基础,看得懂就行,写好了代码一万年不要动,似懂非懂利害了,需要去学习巩固一下Python dict,其他语言的json串
[
{ 整个xlsx文件的用例
"a": [ 整个sheet页的用例
{用例
"A": 2
},
{
"A": 3
}
]
},
{
"b": [
{
"A": 2
},
{
"A": 3
}
]
}
]
2、引用导包,初始化case.xlsx目录
import openpyxl
import os
from common.getfiledir import DATADIR #导入data目录
file = os.path.join(DATADIR, 'case.xlsx') #得到case文件的路径
导入了openpyxl,它只能操作xlsx,支持读写,本人只喜欢读,不喜欢写。
os,初始化用例目录有用到。写死用例文件,如果想灵活多变,可以把用例名字变成传参或变成配置
用例目录
3、初始化ReadCase
class ReadCase(object): def __init__(self): self.sw = openpyxl.load_workbook(file) print(self.sw)初始化类,顺便读取一下用例文件
调试
在文件里输入,
xlsx = ReadCase()
run,打印出这么一串人类不认识,那么就成功了,他打印了一个内存对象,保存了整个case文件
4、读取单个sheet页用例
实现一个方法readcase, 代码如下
def readcase(self, sh): """ 组合sheet页的数据 :param sh: :return: list,返回组合数据 """ if sh is None: return False, '用例页参数未传' datas = list(sh.rows) if datas == []: return False, '用例[' + sh.title + ']里面是空的' title = [i.value for i in datas[0]] rows = [] sh_dict = {} for i in datas[1:]: data = [v.value for v in i] row = dict(zip(title, data)) try: if str(row['id'])[0] is not '#': row['sheet'] = sh.title rows.append(row) except KeyError: raise e rows.append(row) sh_dict[sh.title] = rows return True, sh_dict参数传入一个sheet页对象,
然后判空,
if sh is None: return False, '用例页参数未传'通过列表保存sheet的每一行,判空
datas = list(sh.rows)if datas == []: return False, '用例[' + sh.title + ']里面是空的'得到第一行为title,为啥呢,看excel文件的格式
title = [i.value for i in datas[0]]用一个循环得到每一行的用例与title结合成一个字典json串,返回
for i in datas[1:]: data = [v.value for v in i] row = dict(zip(title, data)) try: if str(row['id'])[0] is not '#': row['sheet'] = sh.title rows.append(row) except KeyError: raise e rows.append(row) sh_dict[sh.title] = rowsreturn True, sh_dict好了,来调试一发,在下面输入代码:
xlsx = ReadCase()for sh in xlsx.sw: isOK, result = xlsx.readcase(sh) print(result)先看我们用例文件
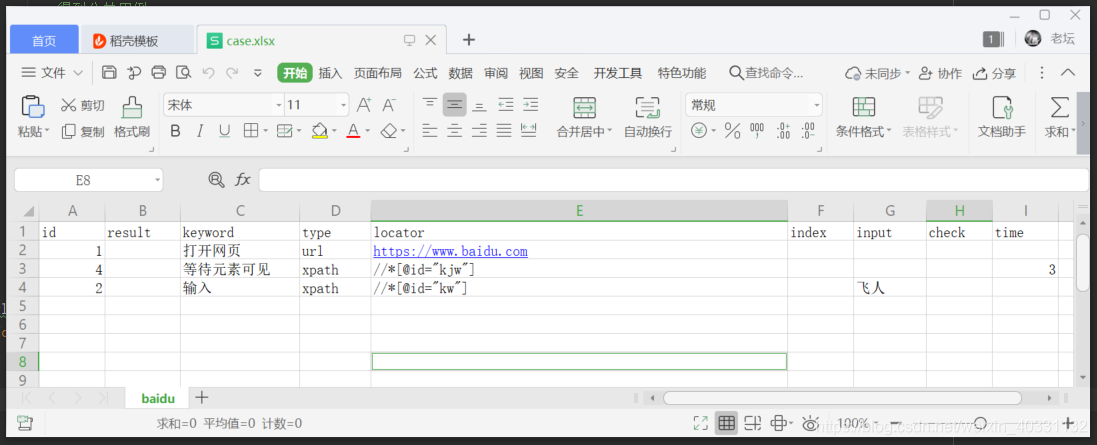
run,运行结果如下

格式化后的结果,完全是我们需要的样子,成功读取用例。
{
'baidu': [{
'id': 1,
'result': None,
'keyword': '打开网页',
'type': 'url',
'locator': 'https://www.baidu.com',
'index': None,
'input': None,
'check': None,
'time': None,
'sheet': 'baidu'
}, {
'id': 4,
'result': None,
'keyword': '等待元素可见',
'type': 'xpath',
'locator': '//*[@id="kjw"]',
'index': None,
'input': None,
'check': None,
'time': 3,
'sheet': 'baidu'
}, {
'id': 2,
'result': None,
'keyword': '输入',
'type': 'xpath',
'locator': '//*[@id="kw"]',
'index': None,
'input': '飞人',
'check': None,
'time': None,
'sheet': 'baidu'
}]
}
5、读取所有用例
因为我们设计的readcase方法,只需要传入一个sheet页,所以实现一个readallcase的方法,遍历所有sheet页,传给readcase读取所有用例,代码如下:
def readallcase(self): """ 取所有sheet页 :return:list,返回sheet页里的数据 """ sheet_list = [] for sh in self.sw: #遍历sheet, if 'common' != sh.title.split('_')[0] and 'common' != sh.title.split('-')[0] and sh.title[0] is not '#' : #判断是否可用的用例 isOK, result = self.readcase(sh) #传给readcase取用例 if isOK: sheet_list.append(result) #得到结果放到列表,又给用例套了一层sheet页的框 if sheet_list is None: return False, '用例集是空的,请检查用例' return True, sheet_list这里面有一个判断条件,是公共用例,common开头的用例不读取,注释用例以#号开头的用例,不读取
调试代码
xlsx = ReadCase()isOK, result = xlsx.readallcase()print(result)运行结果,请看比第4点运行的结果多了一个中括号,表示他已经可以读取所有的用例了

6、读取公共用例
实现一个get_common_case方法,方法很简单,查询是否有传参sheetname的sheet页存在,有的话就读取sheet页的用例,返回,代码如下。
def get_common_case(self, case_name): """ 得到公共用例 :param case_name: :return: """ try: sh = self.sw.get_sheet_by_name(case_name) except KeyError: return False, '未找到公共用例[' + case_name + '],请检查用例' except DeprecationWarning: pass return self.readcase(sh)要结合核心模块的调用
调试代码如下
xlsx = ReadCase()isOK, result = xlsx.get_common_case('baidu')print(result)结果如第5点结果一样
读取用例的全部代码如下:
import openpyxlimport osfrom common.getfiledir import DATADIRfile = os.path.join(DATADIR, 'case.xlsx')class ReadCase(object): def __init__(self): self.sw = openpyxl.load_workbook(file) print(self.sw) def openxlsx(self, file): """ 打开文件 :param dir: :return: """ # self.sw = openpyxl.load_workbook(file) #[{"a": [{"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}]},{"a": [5, 3, 2]}, {"a": [10, 4, 6]}] def readallcase(self): """ 取所有sheet页 :return:list,返回sheet页里的数据 """ sheet_list = [] for sh in self.sw: if 'common' != sh.title.split('_')[0] and 'common' != sh.title.split('-')[0] and sh.title[0] is not '#' : isOK, result = self.readcase(sh) if isOK: sheet_list.append(result) if sheet_list is None: return False, '用例集是空的,请检查用例' return True, sheet_list def readcase(self, sh): """ 组合sheet页的数据 :param sh: :return: list,返回组合数据 """ if sh is None: print('sheet页为空') datas = list(sh.rows) if datas == []: return False, '用例[' + sh.title + ']里面是空的' title = [i.value for i in datas[0]] rows = [] sh_dict = {} for i in datas[1:]: data = [v.value for v in i] row = dict(zip(title, data)) try: if str(row['id'])[0] is not '#': row['sheet'] = sh.title rows.append(row) except KeyError: raise e rows.append(row) sh_dict[sh.title] = rows return True, sh_dict def get_common_case(self, case_name): """ 得到公共用例 :param case_name: :return: """ try: sh = self.sw.get_sheet_by_name(case_name) except KeyError: return False, '未找到公共用例[' + case_name + '],请检查用例' except DeprecationWarning: pass return self.readcase(sh)读取config配置
目录:
Config类没有什么好解析的,暂时是为了封装而封装
具体代码如下:
import osfrom configparser import ConfigParserfrom common.getfiledir import CONFDIRclass Config(ConfigParser): def __init__(self): self.conf_name = os.path.join(CONFDIR, 'base.ini') super().__init__() super().read(self.conf_name, encoding='utf-8') def save_data(self, section, option, value): super().set(section=section, option=option, value=value) super().write(fp=open(self.conf_name, 'w'))配置文件分析一下
目录
内容
[base]browser_type = chrome# browser_type = IE# browser_type = firefox[LOG]level = INFO[email]host = smtp.qq.comport = 465user = xxxxx@qq.com pwd = * from_addr = xxxxx@qq.com to_addr = xxxxx@qq.com [Function] 打开网页 = open_url关闭浏览器 = close_browser对话框上传文件 = upload_file点击 = element_click输入 = element_input截图 = get_screenshot_as_file寻找元素 = find_element隐式等待 = web_implicitly_wait等待元素可见 = web_element_wait等待 = gotosleepinput上传文件 = upload_input_file模拟按键上传文件 = upload_endkey_file切换页面 = toggle_page执行JS = execute_js1、base配置,框架中的基础配置
目前只有浏览器类型
2、LOG配置
配置LOG的输出等级,为INFO,日志模块会讲到
3、email配置
email的一些参数配置,smtp服务器与端口,smtp账密,收发地址等
4、Function配置
两个基础类操作行方法 与 用例参数里的keyword的映射关系,核心处理工厂会用到
核心处理工厂
核心处理工厂为啥核心呢?
各位自动化测试大佬,应该知道PO模型吧,一些常用公共页面,封装到一个类里。之后哪里要用到,哪里就初始化这个类来调用各页面的代码执行。
但每个项目都有这么多页面,每更新一个项目就要写海量代码,这也是UI自动化不如接口自动化的地方,难维护,成本高,
但我这个核心代码,完全不需要用PO模式了,只需要在excel里面写公共用例,即可替代PO模式。
可以说,如果大家都懂了我这段核心代码,实现了UI自动化框架后,做UI自动化时,时间成本就比PO模式要低100倍,人力成本可以用初级测试工程师
上面只是说明核心是重点,但真正核心还是因为他是全框架的总枢纽,后面会细述说来
目录
1、引用模块,导包
from common.getconf import Configfrom common.getcase import ReadCasefrom basefactory.browseroperator import BrowserOperatorfrom basefactory.webdriveroperator import WebdriverOperator导入了Config,配置文件读取
导入了ReadCase,来初始化用例
导入了BrowserOperator,WebdriverOperator,初始化这个两个类,执行用例
2、初始化工厂类
class Factory(object): def __init__(self): self.con = Config() self.con_fun = dict(self.con.items('Function')) """ 浏览器操作对象 """ self.browser_opr = BrowserOperator() """ 网页操作对象 """ self.webdriver_opr = None将配置项Function初始化进来
self.con = Config()self.con_fun = dict(self.con.items('Function'))再初始化一下两个基础类对象,因为WebdriverOperator类要在打开URL后才能初始化,先初始化为None
self.browser_opr = BrowserOperator()
self.webdriver_opr = None
然后我们将初始化webdriver_opr的代码放在一个函数里面,方便后面执行方法里面调用,里面强制转换一下,不然很难联想其对应的方法
def init_webdriver_opr(self, driver): self.webdriver_opr = WebdriverOperator(driver)下面我们先说如何实现代替PO模型的用例初始化
3、初始化执行用例
初始化执行用例 def init_execute_case(self): 里面的内容:
def init_execute_case(self): print("----------初始化用例----------") xlsx = ReadCase() isOK, result = xlsx.readallcase() if not isOK: print(result) print("----------结束执行----------") exit() all_cases = result excu_cases = [] for cases_dict in all_cases: for key, cases in cases_dict.items(): isOK, result = self.init_common_case(cases) if isOK: cases_dict[key] = result else: cases_dict[key] = cases excu_cases.append(cases_dict) print("----------初始化用例完成----------") return excu_cases一、读取了excel里所有可执行用例
二、调用用初始化公共用例
4、初始化公共用例
#初始化公共用例 def init_common_case(self, cases): 里面的内容:
def init_common_case(self, cases): """ :param kwargs: :return: """ cases_len = len(cases) index = 0 for case in cases: if case['keyword'] == '调用用例': xlsx = ReadCase() try: case_name = case['locator'] except KeyError: return False, '调用用例没提供用例名,请检查用例' isOK, result = xlsx.get_common_case(case_name) if isOK and type([]) == type(result): isOK, result_1 = self.init_common_case(result) #递归检查公共用例里是否存在调用用例 elif not isOK: return isOK, result list_rows = result[case_name] cases[index: index+1] = list_rows #将公共用例插入到执行用例中去 index += 1 if cases_len == index: return False, '' return True, cases一、判断是否有‘调用用例’命令,有则取公共用例合并成可执行用例
二、递归取公共用例里是否有‘调用用例’命令,有则继续取公共合并成可执行用例
注意:公共用例不能调用自已,递归死循环
调试这两个方法一起
首先人们得在用例里面写上一个公共用例
再在baidu用例里写一行,调用用例

然后你们看看,这是不是就是PO模型,只需要在excel里面写写就行,完全不需要代码了
我们来调试一下,大工厂类里写下调试代码
fac = Factory()isOK, result = fac.init_execute_case()print(result)运行结果如下,我们初始化用例后,会把调用用例里被调用例的用例插入到执行用例中来,全部去执行。

下面来讲执行部分的
5、获取执行方法
获取两个基础WebdriverOperator、BrowserOperator的方法,具体代码如下:
def get_base_function(self, function_name): try: function = getattr(self.browser_opr, function_name) except Exception: try: function = getattr(self.webdriver_opr, function_name) except Exception: return False, '未找到注册方法[' + function_name + ']所对应的执行函数,请检查配置文件' return True, function传入方法名称function_name,通过getattr得到基础类的方法,成功得到方法,返回True,function,没有得到,返回False,日志
6、方法执行
实现一个方法,execute_keyword,统一入口调用两个基础类的操作
先放代码,再讲原理,代码如下:
def execute_keyword(self, kwargs): """ 工厂函数,用例执行方法的入口 :param kwargs: :return: """ try: keyword = kwargs['keyword'] if keyword is None: return False, '没有keyword,请检查用例' except KeyError: return False, '没有keyword,请检查用例' _isbrowser = False try: function_name = self.con_fun[keyword] except KeyError: return False, '方法Key['+ keyword +']未注册,请检查用例' #获取基础类方法 isOK, result = self.get_base_function(function_name) if isOK: function = result else: return isOK, result #执行基础方法,如打网点页、点击、定位、隐式等待 等 isOK, result = function(kwargs) #如果是打开网页,是浏览器初始化,需要将返回值传递给另一个基础类 if '打开网页' == keyword and isOK: url = kwargs['locator'] self.init_webdriver_opr(result) return isOK, '网页[' + url + ']打开成功' return isOK, result原理:先得到用例里的keyword,然后获取到两个基础类里方法,再传入kwargs调用,执行操作
取到keyword关键字,回顾上面用例excel里的有一个keyword的字段,传入进来,先取这个字段
try: keyword = kwargs['keyword'] if keyword is None: return False, '没有keyword,请检查用例'except KeyError: return False, '没有keyword,请检查用例'在self.con_fun键值对里取到keyword对应的方法名,具体方法可见配置文件那一节
try: function_name = self.con_fun[keyword]except KeyError: return False, '方法Key['+ keyword +']未注册,请检查用例'通过get_base_function得到基础类的方法
isOK, result = self.get_base_function(function_name)if isOK: function = resultelse: return isOK, result执行方法,返回结果
#执行基础方法,如打网点页、点击、定位、隐式等待 等isOK, result = function(kwargs)当然,里面有一个特别的,如果方法是打开浏览器,这时就要初始化一下self.webdriver
if '打开网页' == keyword and isOK: url = kwargs['locator'] self.init_webdriver_opr(result) return isOK, '网页[' + url + ']打开成功'最后我们返回执行结果return isOK, result调试,我们在common里面新增一个test.py文件,在里面输入调试代码
导入Factory,初始化一个工厂对象fac,用fac,调用execute_keyword()方法来执行所有网页操作
from common.factory import Factoryfac = Factory()isOK, result = fac.execute_keyword(keyword='打开网页', locator='http://www.baidu.com')print(result)isOK, result = fac.execute_keyword(keyword='隐式等待', time='30')print(result)isOK, result = fac.execute_keyword(keyword='输入', type='xpath', locator='//*[@id="kw"]',input='飞人乔丹')print(result)idOK, result = fac.execute_keyword(keyword='点击', type='xpath', locator='//*[@id="su"]')print(result)run,运行结果:
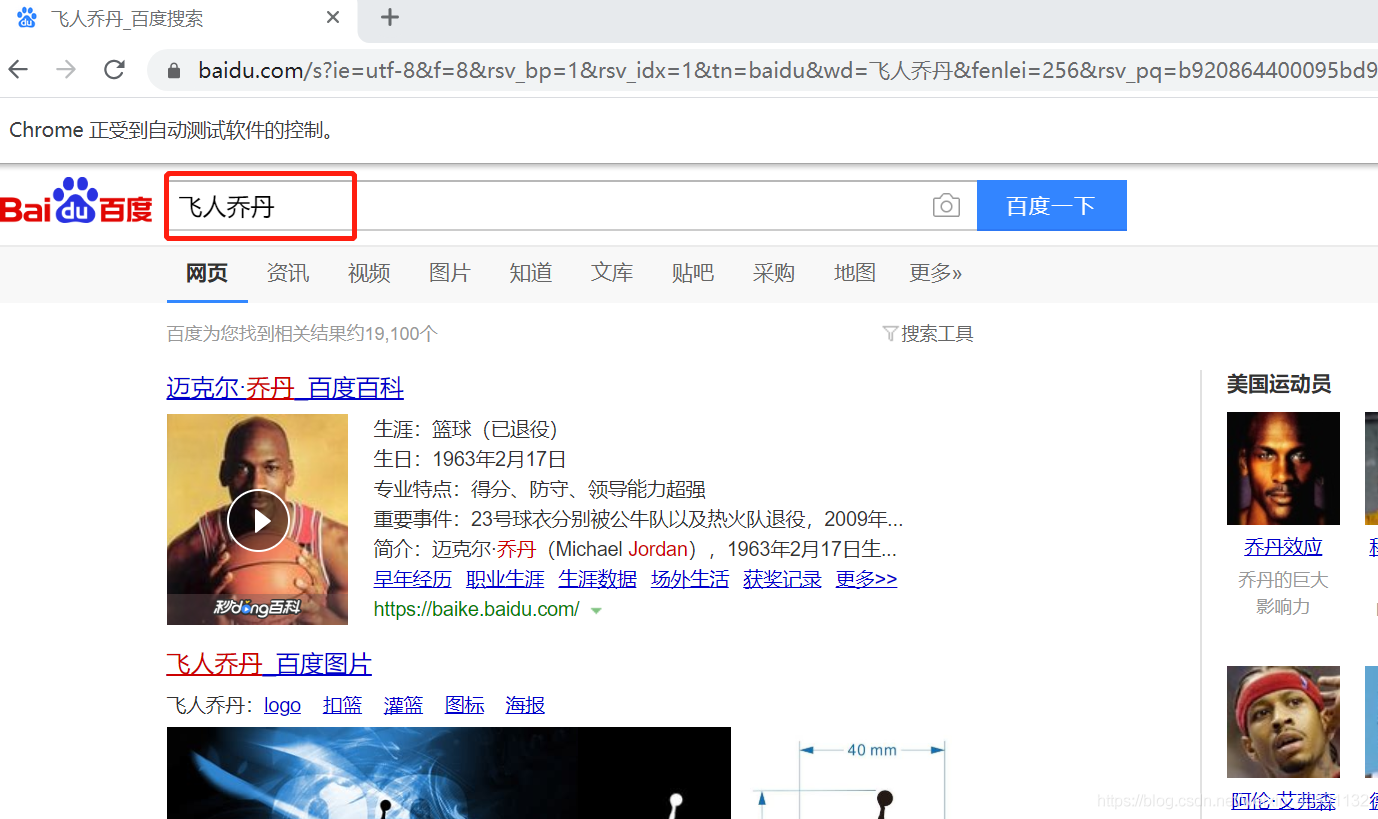
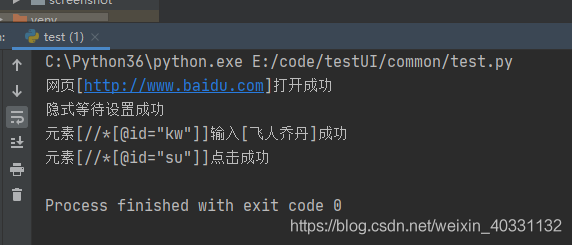
再联合读取excel用例来一起调试
因为
fac.execute_keyword(keyword='点击', type='xpath', locator='//*[@id="su"]')
这样传参其实就等于传了一个字典,所以我们可以将用例里面字典直接传与给execute_keyword()
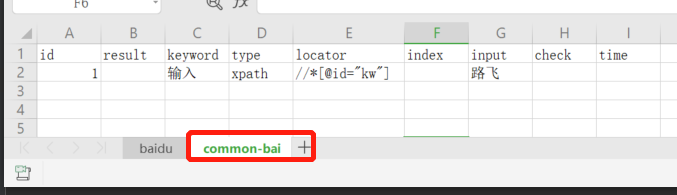
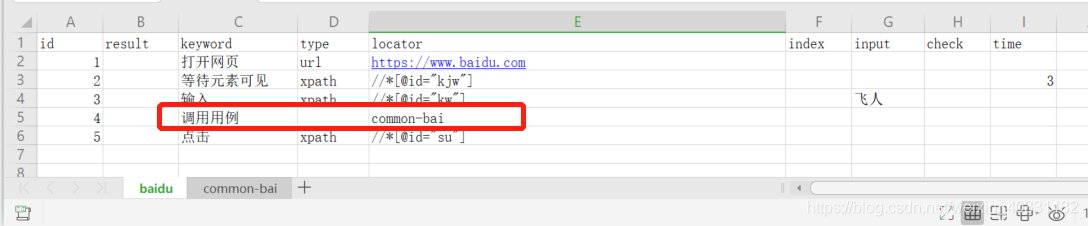
首先我们整理下excel里的用例
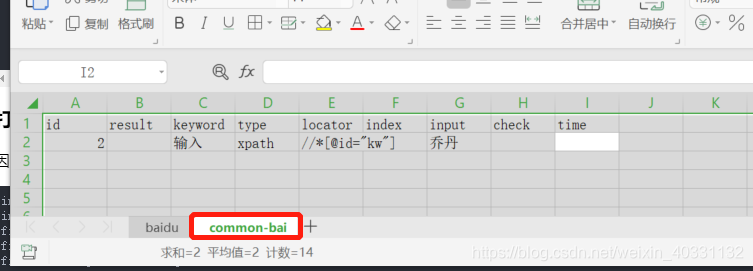
公共用例 common-bai里面是在一个id=kw的输入框中输入‘路飞’
可执行用例baidu,是打开百度网站,输入飞人,然后调用公共用例,再点击搜索的一个模拟搜索的用例
我们来写一下调试代码 ,在test.py里面修改代码
先初始化用例init_exceute_case()
然后解析用例,
for acases in result: #遍历外层list
for key, cases in acases.items(): #遍历中间的dict
for case in cases: #遍历将case取出
用例的层级关系在下面,用上面三行代码解析出case
[
{ 整个xlsx文件的用例
"a": [ 整个sheet页的用例
{用例
"A": 2
},
{
"A": 3
}
]
},
{
"b": [
{
"A": 2
},
{
"A": 3
}
]
}
]
解析完了
调用execute_keyword(case)
from common.factory import Factoryfac = Factory()isOK, result = fac.init_execute_case()for acases in result: for key, cases in acases.items(): for case in cases: isOK, result = fac.execute_keyword(case) print(result)run,运行结果如下
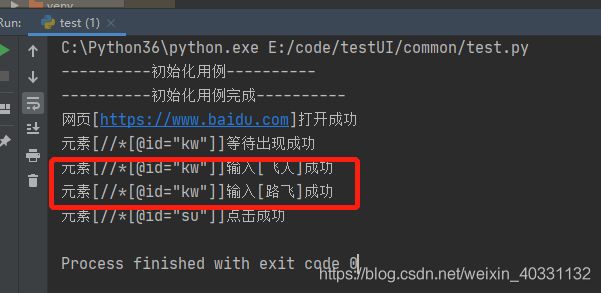
看,在执行用例里面的输入【飞人】成功,然后调用公共用例里面的,执行输入【路飞】成功
最后又回到执行用例里的点击su百度一下成功
核心代码的讲述解束
核心部分全部代码如下:
from common.getconf import Configfrom common.getcase import ReadCasefrom basefactory.browseroperator import BrowserOperatorfrom basefactory.webdriveroperator import WebdriverOperatorclass Factory(object): def __init__(self): self.con = Config() self.con_fun = dict(self.con.items('Function')) """ 浏览器操作对象 """ self.browser_opr = BrowserOperator() """ 网页操作对象 """ self.webdriver_opr = None def init_webdriver_opr(self, driver): self.webdriver_opr = WebdriverOperator(driver) def get_base_function(self, function_name): try: function = getattr(self.browser_opr, function_name) except Exception: try: function = getattr(self.webdriver_opr, function_name) except Exception: return False, '未找到注册方法[' + function_name + ']所对应的执行函数,请检查配置文件' return True, function def execute_keyword(self, kwargs): """ 工厂函数,用例执行方法的入口 :param kwargs: :return: """ try: keyword = kwargs['keyword'] if keyword is None: return False, '没有keyword,请检查用例' except KeyError: return False, '没有keyword,请检查用例' _isbrowser = False try: function_name = self.con_fun[keyword] except KeyError: return False, '方法Key['+ keyword +']未注册,请检查用例' #获取基础类方法 isOK, result = self.get_base_function(function_name) if isOK: function = result else: return isOK, result #执行基础方法,如打网点页、点击、定位、隐式等待 等 isOK, result = function(kwargs) #如果是打开网页,是浏览器初始化,需要将返回值传递给另一个基础类 if '打开网页' == keyword and isOK: url = kwargs['locator'] self.init_webdriver_opr(result) return isOK, '网页[' + url + ']打开成功' return isOK, result def init_common_case(self, cases): """ :param kwargs: :return: """ cases_len = len(cases) index = 0 for case in cases: if case['keyword'] == '调用用例': xlsx = ReadCase() try: case_name = case['locator'] except KeyError: return False, '调用用例没提供用例名,请检查用例' isOK, result = xlsx.get_common_case(case_name) if isOK and type([]) == type(result): isOK, result_1 = self.init_common_case(result) #递归检查公共用例里是否存在调用用例 elif not isOK: return isOK, result list_rows = result[case_name] cases[index: index+1] = list_rows #将公共用例插入到执行用例中去 index += 1 if cases_len == index: return False, '' return True, cases # [{"a": [{"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}, {"A": 2}]},{"a": [5, 3, 2]}, {"a": [10, 4, 6]}] def init_execute_case(self): print("----------初始化用例----------") xlsx = ReadCase() isOK, result = xlsx.readallcase() if not isOK: print(result) print("----------结束执行----------") exit() all_cases = result excu_cases = [] for cases_dict in all_cases: for key, cases in cases_dict.items(): isOK, result = self.init_common_case(cases) if isOK: cases_dict[key] = result else: cases_dict[key] = cases excu_cases.append(cases_dict) print("----------初始化用例完成----------") return excu_casesddt驱动代码
1、文件目录
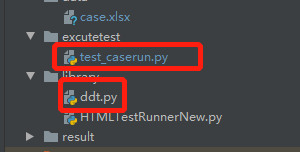
执行用例代码目录 excutetest下新增一个test_caserun.py ,先说,这里最好是以test开头定义执行文件
然后library里面放到ddt,数据驱动装饰器
2、导入库
在test_caserun.py里写代码
import unittestfrom common.factory import Factoryfrom common.log import mylogfrom library.ddt import ddt, dataunittest UT测试库,作自动化测试的都知道他是干啥的
Factory,这个框架的核心类
mylog,下一章实现的日志打印
ddt, data,数据驱动装饰器
2、代码分析
@ddtclass Test_caserun(unittest.TestCase): fac = Factory() isOK, excu_cases = fac.init_execute_case() @data(*excu_cases) def test_run(self, acases): for key, cases in acases.items(): mylog.info('\n----------用例【%s】开始----------' % cases[0].get('sheet')) print('\n') for case in cases: isOK, result = self.fac.execute_keyword(case) if isOK: print(result) mylog.info(result) else: mylog.error(result) raise Exception(result) mylog.info('\n----------用例【%s】结束----------\n' % cases[0].get('sheet')).定义一个类Test_caserun,用@ddt来装饰一下这个类,不要问这啥原理,一下子说不清楚,按要求来就行
初始化工厂fac = Factory()
得到用例isOK, excu_cases = fac.init_execute_case()
实现一个执行用例的方法,test_run
用@data() 来装饰这个方法,这个装饰器来帮忙遍历excu_cases用例,然后返回给test_run方法的acases,
@data() 的参数可以是元组、列表、字典等格式
data只遍历了第一层,后面的我们代码里面写
for key, cases in acases.items(): mylog.info('\n----------用例【%s】开始----------' % cases[0].get('sheet')) print('\n') for case in cases: isOK, result = self.fac.execute_keyword(case) if isOK: print(result) mylog.info(result) else: mylog.error(result) raise Exception(result) mylog.info('\n----------用例【%s】结束----------\n' % cases[0].get('sheet'))这一段就是执行用例,决断执行结果如
理念就是简练代码,一个用例执行代码,调用一个执行入口,执行任意网页操作,返回成功或失败
isOK is True 执行成功打info日志
isOK is False 执行失败打error日志,抛出异常日志
调试代码看下章
执行并输出报告
1、目录
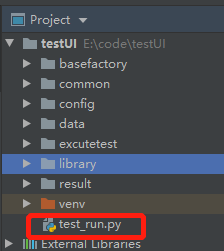
在工程主目录下添加一个文件test_run.py
https://download.csdn.net/download/weixin_40331132/12521680
下载上面链接里的一个文件放到library目录下,因为我的
网上有很多,但因为是我写的用例格式,所以HTMLTestRunner里的代码我改了一些。暂时不会修改这个文件的朋友,可以先下载我的来学习用
2、导包
在test_run里导入
import osimport unittestfrom library.HTMLTestRunnerNew import HTMLTestRunnerfrom common.getfiledir import CASEDIR, REPORTDIRos来处理路径
unittest来Loadcase的代码文件
HTMLTestRunner来执行用例,输出报告
具体代码如下,这一段网上通用,我也懒懒不细说了直接上
class Test_run(object): def __init__(self): self.suit = unittest.TestSuite() self.load = unittest.TestLoader() self.suit.addTest(self.load.discover(CASEDIR)) self.runner = HTMLTestRunner( stream=open(os.path.join(REPORTDIR, 'report.html'), 'wb'), title='魂尾自动化工厂', description='唯a饭木领', tester='HUNWEI' ) def excute(self): self.runner.run(self.suit)if __name__=="__main__": test_run = Test_run() test_run.excute()init初始化用例,与报告对象
excute执行
添加工程主执行入口main
直接运行调试,还是在之前的excel用例基础上运行
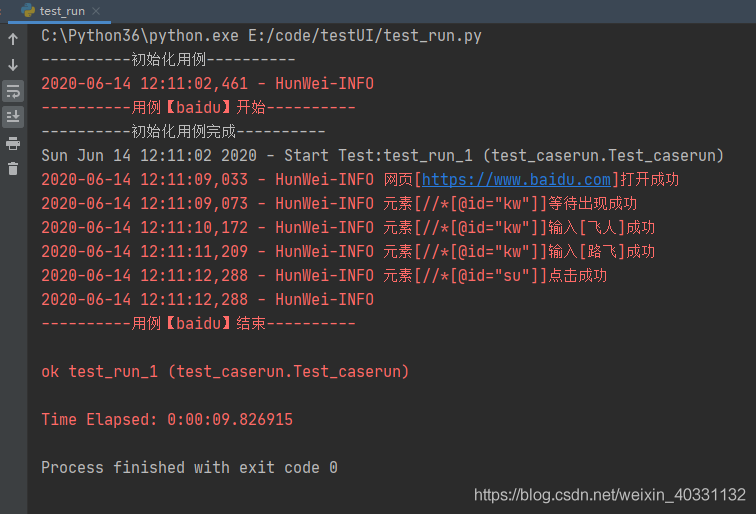
运行结果

输出日志:
报告结果:
找到这个目录
打开这个html
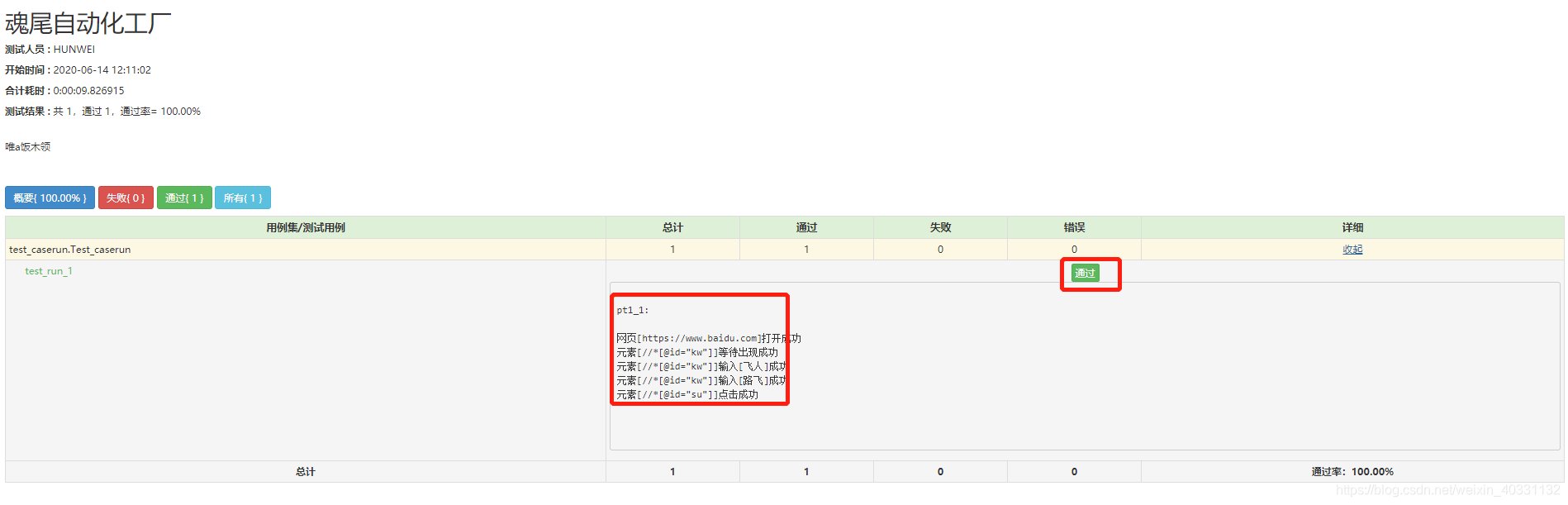
好,整个框架完成了,只剩扩展一些边边角角的了
比如:下面打印日志,与发送邮件的,便不细说了,可以直接看代码学习学习,很简单的。
打印Log
相关代码
import loggingimport osfrom logging.handlers import TimedRotatingFileHandlerfrom common.getconf import Configfrom common.getfiledir import LOGDIRclass Handlogging(): @staticmethod def emplorlog(): conf = Config() # set format formatter = logging.Formatter("%(asctime)s - %(name)s-%(levelname)s %(message)s") # create log set getlog level mylog = logging.getLogger('HunWei') mylog.setLevel(conf.get('LOG', 'level')) # create outputsteam set level sh = logging.StreamHandler() sh.setLevel(conf.get('LOG', 'level')) sh.setFormatter(formatter) mylog.addHandler(sh) #create file set level #fh = logging.FileHandler(os.path.join(LOGDIR,'test.log'), encoding='utf-8') log_path = os.path.join(LOGDIR, 'test') # interval 滚动周期, # when="MIDNIGHT", interval=1 表示每天0点为更新点,每天生成一个文件 # backupCount 表示日志保存个数 fh = TimedRotatingFileHandler( filename=log_path, when="D", backupCount=15, encoding='utf-8' ) fh.suffix = "%Y-%m-%d.log" fh.setLevel(conf.get('LOG', 'level')) fh.setFormatter(formatter) mylog.addHandler(fh) return mylogmylog = Handlogging.emplorlog()发送邮件
相关代码
import smtplibimport osfrom common.getconf import Configfrom email.mime.text import MIMETextfrom email.mime.multipart import MIMEMultipartfrom email.mime.application import MIMEApplicationfrom common.getfiledir import REPORTDIRclass Opr_email(object): def __init__(self): """ 初始化文件路径与相关配置 """ self.conf = Config() all_path = [] for maindir, subdir, file_list in os.walk(REPORTDIR): pass for filename in file_list: all_path.append(os.path.join(REPORTDIR, filename)) self.filename = all_path[0] self.host = self.conf.get('email', 'host') self.port = self.conf.get('email', 'port') self.user = self.conf.get('email', 'user') self.pwd = self.conf.get('email', 'pwd') self.from_addr = self.conf.get('email', 'from_addr') self.to_addr = self.conf.get('email', 'to_addr') def get_email_host_smtp(self): """ 连接stmp服务器 :return: """ self.smtp = smtplib.SMTP_SSL(host=self.host, port=self.port) self.smtp.login(user=self.user, password=self.pwd) def made_msg(self): """ 构建一封邮件 :return: """ self.msg = MIMEMultipart() with open(self.filename, 'rb') as f: content = f.read() # 创建文本内容 text_msg = MIMEText(content, _subtype='html', _charset='utf8') # 添加到多组件的邮件中 self.msg.attach(text_msg) # 创建邮件的附件 report_file = MIMEApplication(content) report_file.add_header('Content-Disposition', 'attachment', filename=str.split(self.filename, '\\').pop()) self.msg.attach(report_file) # 主题 self.msg['subject'] = '自动化测试报告' # 发件人 self.msg['From'] = self.from_addr # 收件人 self.msg['To'] = self.to_addr def send_email(self): """ 发送邮件 :return: """ self.get_email_host_smtp() self.made_msg() self.smtp.send_message(self.msg, from_addr=self.from_addr, to_addrs=self.to_addr)
