物理优化之统计信息
概述
本文旨在分析Kingbase中基于代价的查询优化的基本概念与代价模型,为自己以后工作提供一个笔记。同时该文章也适用于学习和开发PostgreSQL的同学
逻辑优化和物理优化
数据库优化器基本上都支持逻辑优化和物理优化。逻辑优化的核心是代数的等价转换。基于代价的查询优化技术是物理优化的一个重要部分。合理的代数等价转换和代价估算是数据库优化器的一项重要功能。
CBO概念:
基于代价的查询优化技术(Cose-Based Optimizaton,CBO),基于DBMS对数据库中的大量数据进行统计(抽样统计)得到的统计信息,考虑系统的各种参数(缓冲区大小,数据分布,存取路径等),DBMS优化器可以准确的估计出各种查询计划所需要的资源消耗和时间开销,从而选择出一条最合适的执行计划。
现在磁盘关系数据库(DBMS)的代价模型主要是基于磁盘IO和CPU计算开销建立的,其中磁盘IO开销又占据了开销的主要部分,基于代价的查询优化技术为数据库的每种物理运算符都建立了相关的代价模型,代价估计的准确性直接影响了查询计划的好坏。
统计信息概述
统计信息是基于代价的查询计划的基础,也是计算查询代价的原始材料,统计信息的准确度直接影响到了查询优化的结果。Kingbase为了支持基于代价的优化(CBO)提供了统计信息功能,主要信息包含包括两个方面:
1. 表统计信息
优化器在计算表的扫描成本时,需要知道表的基本数据,例如元组的总数,占据磁盘块的页面数等信息。这些信息主要保存在sys_class系统表中,主要包含两个主要的字段:reltuples和relpages。
reltuples :表示该表或者索引在磁盘中的元组数。
relpages:表或者索引占用的磁盘块数。
2. 列统计信息
列统计信息是指对表中的每一列的统计信息,主要存储在sys_statistic系统表中,它负责从多个角度描述该列的数据概况信息。
内容主要分2部分:
2.1 基本统计信息 – 主要是NULL值率、列的平均宽度、唯一值的个数或比例。见 sys_statistic 系统表中的stanullfrac、stawidth、stadistinct等字段。
2.2 数据分布信息 – 直方图、最频值(mcv)和空值率等统计信息来进行选择率的估计。见most_common_vals、most_common_freqs、histogram_bounds等字段。
stanullfrac:列的项为空的比例。
stawidth:非空项的平均存储宽度,以字节计。
stadistinct:唯一值的个数或者比例,如果全唯一则0,表示个数,否则<0,表示比例。
most_common_vals:列中最常用值的一个列表。
most_common_freqs:最常用值的频率。
most_common_elems:最经常出现的非空元素列表。
most_common_elem_freqs:最常用非空元素值的频率。
histogram_bounds:将列值划分成大小接近的直方图。
elem_count_histogram:非空元素值计数的一个直方图。
其他字段及其含义可以参考Kingbase相关的文档 统计和采样
收集统计信息可以进行精确的统计,以可以采用采样的方法。Kingbase中采用两种方式混合的策略收集统计信息。Kingbase通过两种方式收集统计信息,一种是通过VACUUM、ANALYZE操作进行采样统计,另一种方式是通过利用一些DDL语句执行的副产品得到统计信息,例如在创(重)建索引的时候,利用建立索引需要对属性进行扫描和排序的特点,可以收集reltuples和stadistinct。
选择率估算
Kingbase通过(等频)直方图,最频值(MCV)和空值率等统计信息来进行选择率的估算。
直方图简介
直方图是被广泛应用的一种统计图表,主要用于代价的选择率的选择上,根据统计方法的不同,直方图可分为:
-
等宽直方图,等宽直方图的宽度是相同的,下面图的宽度为1。
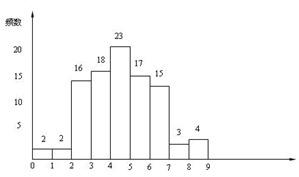
-
等频直方图,又称为等高直方图,它的高度是相同的。下图为等频直方图,它的高度是相同的,宽度是不同的。
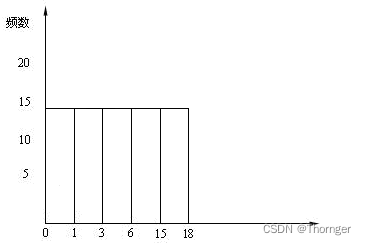
最频值(MCV)简介
最频值(MCV)统计列中出现频率最高的N个数值和每个数值出现的频率(MCVF)
信息收集
1、主动收集
用户可以通过执行VACUUM ANALYZE或者ANALYZE语句让Kingbase通过采样的方法收集统计信息。
2、自动收集
自动收集依赖于autovacuum进程,autovacuum launcher会定期或者根据触发条件进行触发,触发后将进行统计信息的统计。
代价模型常量
代价常量以一次IO为标准进行衡量的,也就是说一次IO的值为1.0,其他的代价常量都是以它作为参考进行设置的,该值是一种相对值,针对特殊的硬件需要进行特殊的处理
seq_page_cost (floating point) 一次顺序扫描获取磁盘页面的开销,默认是1.0。
random_page_cost (floating point) 一次随机获取一个磁盘页面的开销,默认值4.0
cpu_tuple_cost (floating point) 处理每一行的CPU代价估计。默认值是 0.01。
cpu_index_tuple_cost (floating point) 一次索引扫描中处理每一个索引项的代价估计。默认值是 0.005。
cpu_operator_cost (floating point) 一次查询中处理每个操作符或函数的代价估计。默认值是 0.0025。
parallel_setup_cost (floating point) 启动并行工作者进程的代价估计。默认是 1000。
parallel_tuple_cost (floating point) 从一个并行工作者进程传递一个元组给另一个进程的代价估计。默认是 0.1。
代价模型
顺序扫描代价模型
- 顺序扫描的代价模型, 顺序扫描的代价主要包括IO代价和CPU代价。
- IO代价:就是扫描一次的代价乘以扫描的块数。也就是
seq_page* relpages。(seq_page_cost为代价模型常量中一次顺序扫描的代价,relpages为sys_class中关于表的页面数的统计)。 - CPU代价:CPU的代价主要分为两方面 1、将IO或得的位串转换为内存中的元组(
cpu_tuple_cost)。2、将内存中的元组根据过滤条件进行过滤操作(cpu_operator_cost)。
顺序扫描模型:seq_page* relpages + (cpu_tuple_cost +cpu_operator_cost) * reltuples
索引扫描代价模型
- 索引扫描的代价模型主要包括:处理索引页产生的IO和CPU代价以及处理数据页产生的IO和CPU代价。
- 索引页的IO代价:
random_page_cost* pages_fetched - 索引页的CPU代价:
cpu_index_tuple_cost* reltuples(index)*indexSelectivity - 索引页的操作代价:
cpu_operator_cost*过滤条件数 - 启动代价:index_qual_cost.startup + (
index_qual_cost.per_tuple -cpu_operator_cost* 过滤条件的个数)
索引扫描代价模型(单表扫描): indexStartupCost + index->pages * random_page_cost + numIndexTuples * (cpu_index_tuple_cost + cpu_operator_cost * 过滤条件数)
注意:
上面的代价计算不包含数据页的扫描代价,数据页的扫描代价有两个极端情况。
1、如果数据是有序的,那么IO代价为一次随机IO+其余的顺序IO。
IO_cost = random_page_cost + (page_fetched -1) * seq_page_cost
2、如果数据页是无序的,那么IO代价为页面数*随机IO的代价常量
IO_cost = random_page_cost * page_fetched
统计信息缺陷
1、统计信息本身具有偏差性,例如:基于表的统计信息是根据ANALYZE或者VACUUM等操作通过扫描部分信息进行估算的,具有一定的偏差性。
2、统计信息具有延后性,即使统计信息刚刚进行了更新操作,它的数据也是延后的,并不是实时的数据。所以与当前的实际数据具有一定的差异。
这会导致查询引擎在基于该统计信息计算最优查询访问路径时候的偏差,从而导致最后选择计划的偏差。
3、代价模型中不恰当的假设条件。不同的硬件系统对应的磁盘IO的读写性能是不相同的。例如:磁盘阵列(RAID)和固态硬盘(Solid State Disk)作为数据存储设备,写操作、顺序读取和随机读取的代价都有显著的不同。
参考资料:
www.postgresql.org
help.kingbase.com.cn
【更多人大金仓数据库信息,详见:[https://help.kingbase.com.cn]】

