Mysql分库分表
文章目录
- 👑前言
- ❤️分库分表简介
-
- 🤍垂直拆分
- 🤍水平拆分
- 🤍分库分表主键问题
- 🤍分库分表扩容
- ❤️Sharding-JDBC
-
- 🤍Sharding-JDBC简介
- 🤍使用Sharding-JDBC分库
- 🤍使用Sharding-JDBC分表
- 🤍使用Sharding-JDBC读写分离
👑前言
当前互联网发展速度越来越快,很多应用的用户量也越来越多,很多大的互联网项目的用户量甚至破亿,日活跃用户也在几千万,用户的活动信息一般都记录到了数据库中,那么Mysql怎么存放这些数据才能有更好的性能呢?本文简单讲解了一下Mysql中的分库分表方案。
❤️分库分表简介
🔊分库分表是两个方面的优化:分库,当表的数量很多导致数据系统的单个数据库很大,这时候需要根据不同业务将表拆分到多个数据库中;分表,当表中的数据太多的时候导致单个表的太大,这时候需要将表中的数据拆分到多个表中。
所以分库分表在实际操作中可以分为三种实现:分库、分表、分库分表。
🔊分库分表主要实现在垂直拆分和水平拆分两个方向。
🤍垂直拆分
垂直拆分又分为两种情况:垂直分库和垂直分表。
🔊 垂直分库
垂直分库指的是内部的表数量太多导致的单个库的体积太过庞大,例如常见的电商系统中有用户信息相关的表、商品信息相关的表、订单信息相关的表等,这些表都存放在一个数据库里整个数据库太过臃肿庞大,所以要将表根据业务的分类拆分到多个数据库中,同时项目也拆分成了分布式的项目。
🔊 垂直分表
垂直分表指的是表中的字段过多导致的单个表的体积太过臃肿,常见的拆分方案:根据表中字段的访问情况进行拆分,例如一张表30个字段,其中18个字段是核心字段,另外12个字段是非核心字段,这就可以将该表拆分成一个主表和一个扩展表;在前面讲解innoDB引擎时也提到了一个特殊情况,表中含有较长的可变长度字段,这就需要将表中长可变长度字段拆分出一个表来提高主表的查询效率。
🔊垂直拆分后系统数据库业务分明比较清晰,单个Page可以存放更多的Row,查询效率更快,但是表拆分之后单表操作变成了多表操作导致JOIN连表,同时会增加事务复杂度。
🤍水平拆分
水平拆分指的是单个表中数据量太多,导致查询的时候速度变慢。例如电商平台的日PV应该可以达到上亿,这些数据如果记录在单个表中那查询效率可想而知了,这时候就可以根据情况拆分多个表。
水平拆分的方案需要根据具体的业务数据来进行处理,例如表中有不同分类的数据,可以将根据分类拆分多个表,或者根据时间信息拆分,咱的项目日志不就一般根据时间拆分的吗?如果表中没有可以拆分的依据可以通过ID取模来进行分表。
🔊水平拆分后单表的数据量变小了,查询效率变快了,但是对于通过ID取模拆分的表来说扩容就变成了一个难点,需要把所有数据重新划分多个表中;如果拆分规则不好的话可能需要跨表查询甚至跨库查询导致查询难度增加。
🤍分库分表主键问题
以前数据库中的ID可能是让数据库自增生成的,但是分库分表后就不太适合了,多个表可能会出现主键重复的情况,下面介绍几种主键生成策略。
🔊 UUID
对于UUID大家应该不陌生了,UUID随机生成重复的概率极低,相信很多人都使用过UUID来作为表中的主键,但是UUID是没有规律的,所以索引的B+树的变动比较频繁,而且主键长在辅助索引的树中占用的空间就比较多。
🔊 COMB
COMB是UUID的一种改进方案,因为UUID没有规律而且没有顺序导致索引树变动频繁,那么有没有一种有序的UUID?所以大佬们就开发出了COMB。COMB是UUID和时间信息的结合体,这样生成的ID就有顺序了,索引树的变动就可控了。因为有时间信息所以要保证多个服务器时间同步。
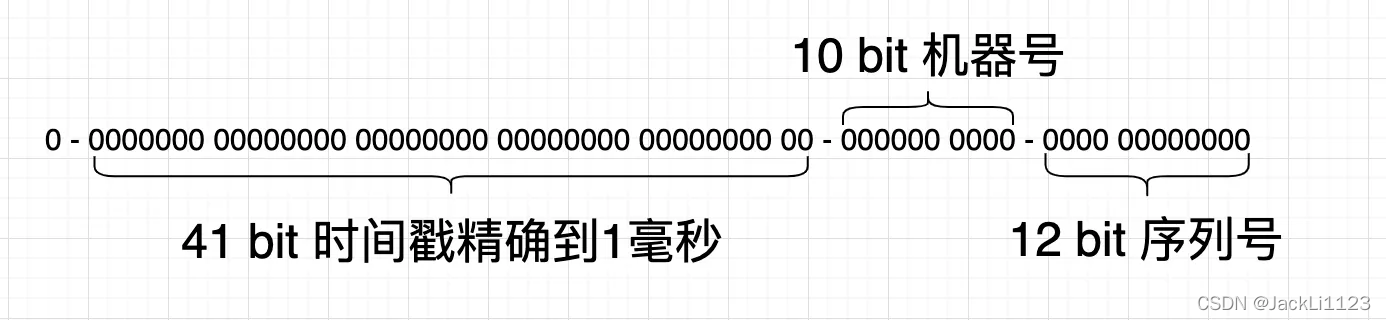
🔊 雪花算法
雪花算法是一种Twitter开源的分布式ID生成算法,是long类型的ID,占用8字节的空间,由时间信息+机器信息+流水号组成。因为前面是时间信息所以保证了ID的有序性,同时占用空间要比前面两种小。因为有时间信息所以要保证多个服务器时间同步。
🔊 第三方表生成ID
因为是多个表存放数据采用主键自增肯定会导致表中的ID出现重复的情况,那么可不可以使用另一个表专门生成ID呢?每次执行都向表中插入数据获取新的ID,这样就保证了多个表的ID自增。这种方案理论上是可行的,但是在性能和可靠性上存在缺陷,因为每次都要进行一次数据库网络请求获取ID,效率较低,而且第三方表的依赖性太强。
🔊 Redis生成ID
使用SQL数据库生产自增ID的效率太低,那么咱是不是可以使用Redis自增来生成ID呢?可以让Redis进行原子自增操作来获取ID,这种方法性能较高,对Redis依赖性也比较强,但是咱项目使用Redis不可能让Redis挂掉吧。Redis搭建集群后集群的步长需要调整,扩展性不太好。
关于这么多ID生成策略,个人比较喜欢雪花算法,因为其相较于UUID来说性能比较高,而对比第三方ID来说没有这么强的依赖性,只要代码能跑就能生成ID。
🤍分库分表扩容
很多系统业务数据时时刻刻都在产生,所以数据库的容量上限经常会达到极限,这时候就需要对数据库进行扩容操作。
🔊 停机扩容
停机扩容是指将项目停掉不对外服务了,这期间内进行数据库扩容操作,重新对数据进行分配,结束后再启动服务。停机扩容一般常见于金融项目,例如我目前的金融账户使用的华宝证券的,它们每周末非交易日的时候就会发布停机公告,对于部分业务停止服务,当然有可能是数据库扩容也可能是其他信息维护。
停机扩容实现起来比较简单,但是需要定期进行处理,而且处理完之后需要严格的测试。同时停机扩容的高可用咱就不说了,预计双九都不到。
🔊 平滑扩容
对于互联网电商肯定不能使用停机扩容,停机之后相关业务停止得丢失多少用户,所以他们一般采用平滑扩容方案。平滑扩容一般采用的是二倍扩容。
平滑扩容的过程大致是这样的:
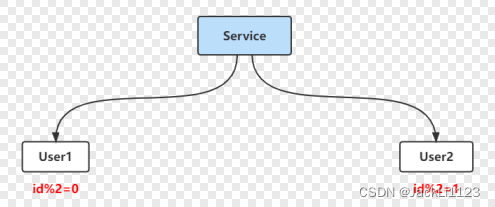
1️⃣目前的服务器数据库是有User1和User2两个数据库的,User1中为id取模0的数据,User2中是ID取模1的数据。
2️⃣增加一倍数据库,设置双主单写模式,将User1的数据复制一份给User3,将User2的数据复制一份给User4。
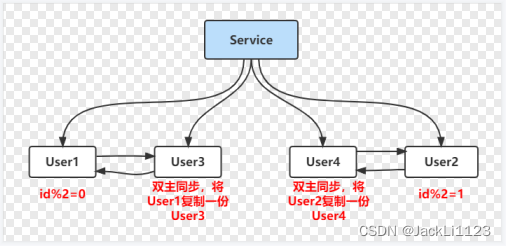
3️⃣数据同步完成,此时的数据情况是这样的User1和User3存放的都是ID取模0的,User2和User4都是取模为1的数据,这时候将双主单写修改为双主双写,保证数据的准确性。
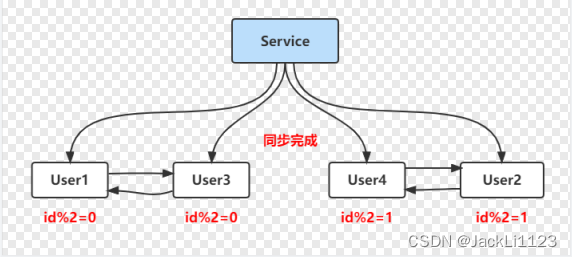
4️⃣四台数据库的需要对4取模,将User1中取模2的删除,将User2中取模3的删除,将User3中取模0的删除,将User4中取模1的删除。然后关掉双主模式,修改数据库配置重启数据库。
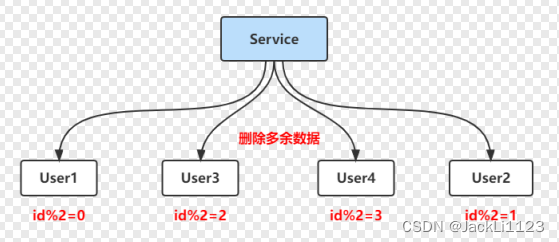
平滑扩容停机时间非常短,仅仅是数据库重启的时间,保证了高可用,但是实现起来比较费劲,而且越到后期的扩容越费劲。
❤️Sharding-JDBC
分库分表的中间件有很多,根据其使用位置分为代理层的Mycat、Sharding-Proxy和MySQL Proxy,代理层分库分表是通过中间件来配置数据库,代码不用改动,访问的数据库的时候代理已经给处理好了;还有应用层的中间件Sharding-JDBC,个人用Sharding-JDBC比较多,所以就用Sharding-JDBC来演示一下分库分表操作了。
本次演示使用的是SpringbootTest+mybatis-plus+sharding-JDBC。
使用Sharding-JDBC后我们的业务代码该怎么写还是怎么写,只需要在yml配置文件中增加一个Sharding配置文件,配置好那些表进行分库分表以及分库分表的策略就行了。
🤍Sharding-JDBC简介
Sharding-JDBC是一个轻量级的数据操作中间件,使用Java语言编写的,可以理解为Sharding-JDBC在JDBC操作的上面又加了一层服务,根据其配置修改JDBC的执行达到数据控制效果。
🔊 Sharding-JDBC中的一些相关的概念
- 真实表: 真实表就是在数据库中真实存在的表,例如user1,user2,user3。
- 逻辑表: 逻辑表就像是真是表构成的假表,例如user1,user2,user3,我们在使用的时候用的是user逻辑表。
- 数据节点: 数据节点是数据库和表构成的组合,例如database0.user1。
- 绑定表: 绑定表指的是两个有关联的表,例如user和user_extend表,查询的时候SELECT * FROM user a LEFT JOIN user_extend b on (a.user_id = b.user_id)。用户表和它的扩展表就是一个绑定表组合,合起来才是一个完整用户数据。
- 广播表: 广播表指的是一些字典表,为了查询这些表每个数据库都存在而且数据也是相同的。
🔊 Sharding-JDBC的分片策略
- 标准分片策略StandardShardingStrategy: 只支持单分片键,也就是只能通过一个字段来分片。可以通过SQL语句中的=、>、< 、in等操作来进行分片。支持精准分片算法和范围分片算法。
- 复合分片策略ComplexShardingStrategy: 支持多分片键,也就是可以通过多个字段来进行分片,这个需要自己实现。
- 行表达式分片策略InlineShardingStrategy: 只支持但分片键,通过Groovy表达式来分片,例如:user_${id%2}这个语句跟前端拼接字符串很像,意思是id对2取模然后拼接前面的字符串user_来识别区分不同的分片。
- Hint分片策略HintShardingStrategy: Hint分片是通过表中字段之外的值进行分片。
🔊 Sharding-JDBC注意事项
Sharding-JDBC不支持持CASE WHEN、HAVING、UNION操作,如果在使用的时候SQL中写了这些操作可能会不识别导致出错。
Sharding-JDBC的嵌套子查询只支持一层,如果有子查询中嵌套子查询的可能会报错。
使用Sharding-JDBC的时候就不要再在SQL中指定数据了(例如select * from db1.user),否则可能会报错。
使用Sharding-JDBC的时候不要对分片键做处理(例如使用type字段做分片禁止对type做计算操作),否则可能会出错。
🤍使用Sharding-JDBC分库
🔊 引入Sharding-JDBC的Jar包
<dependency> <groupId>org.apache.shardingsphere</groupId> <artifactId>sharding-jdbc-spring-boot-starter</artifactId> <version>4.1.0</version></dependency>🔊 properties配置
#配置两个数据源spring.shardingsphere.datasource.names=ds0,ds1#数据源1spring.shardingsphere.datasource.ds1.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds1.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds1.jdbc-url=jdbc:mysql://82.157.173.148:3306/test002?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=falsespring.shardingsphere.datasource.ds1.username=rootspring.shardingsphere.datasource.ds1.password=#数据源2spring.shardingsphere.datasource.ds0.type=com.zaxxer.hikari.HikariDataSourcespring.shardingsphere.datasource.ds0.driver-class-name=com.mysql.jdbc.Driverspring.shardingsphere.datasource.ds0.jdbc-url=jdbc:mysql://82.156.90.65:3306/test001?useUnicode=true&characterEncoding=UTF-8&serverTimezone=GMT%2B8&useSSL=falsespring.shardingsphere.datasource.ds0.username=rootspring.shardingsphere.datasource.ds0.password=#分库策略,通过ID取模进行分库spring.shardingsphere.sharding.tables.user.database-strategy.inline.sharding-column=idspring.shardingsphere.sharding.tables.user.database-strategy.inline.algorithm-expression=ds$->{id % 2}#SQL结果打印spring.shardingsphere.props.sql.show=truespring.main.allow-bean-definition-overriding=true🔊 测试代码
以前怎么写的业务代码还是怎么写,sharding会自动的给分配到对应的数据库。
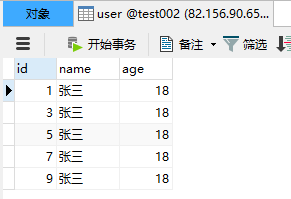
@RunWith(SpringRunner.class)@SpringBootTest(classes = ShardingJdbcDemoApplication.class)public class Test001 { @Resource private UserMapper userMapper; @Test public void test() { for (int i = 0; i < 10; i++) { User user = new User(); user.setId(i); user.setName("张三"); user.setAge(18); userMapper.insert(user); } }}🔊 打印日志
可以看到在写入的时候会根据ID取模自动匹配对应的数据库中进行保存,一个数据库中只保存了奇数ID另一个数据库值保存了偶数ID。
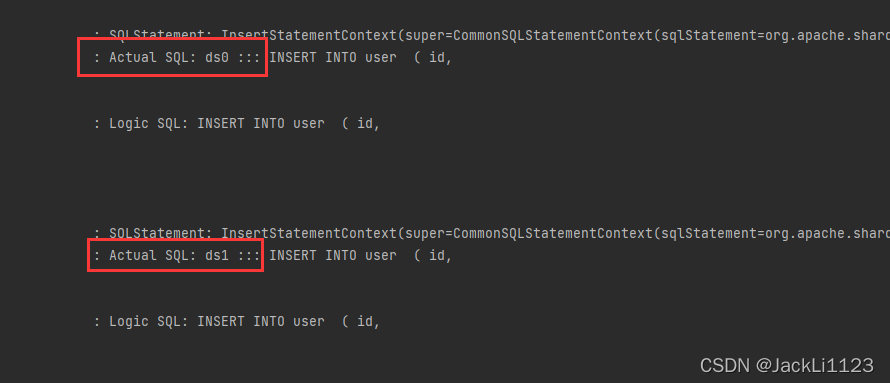
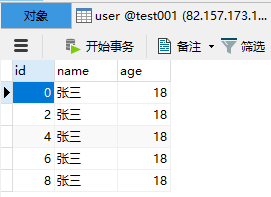
🔊 读取数据操作的原理是在两个库中都执行SQL语句,将最终的结果加在一起。
🤍使用Sharding-JDBC分表
🔊 properties配置
咱就不同时分库又分表了,看一下一个库中分表,
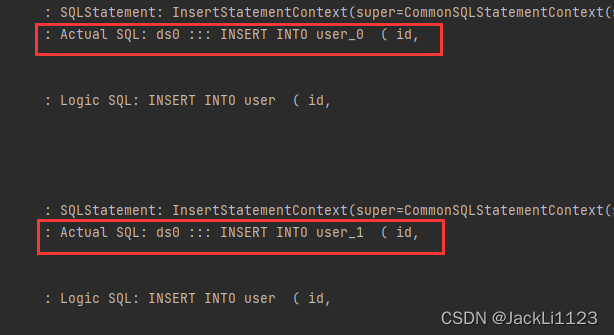
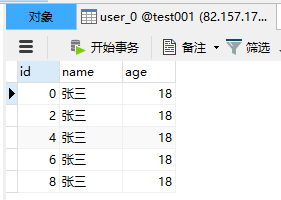
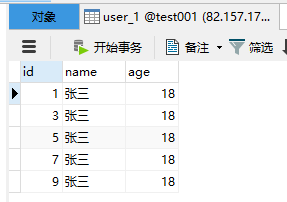
#分库策略,通过ID取模进行分库spring.shardingsphere.sharding.tables.user.database-strategy.inline.sharding-column=idspring.shardingsphere.sharding.tables.user.database-strategy.inline.algorithm-expression=ds0#数据节点配置spring.shardingsphere.sharding.tables.user.actual-data-nodes=ds0.user_$->{0..1}#分表策略,通过ID取模进行分表spring.shardingsphere.sharding.tables.user.table-strategy.inline.sharding-column=idspring.shardingsphere.sharding.tables.user.table-strategy.inline.algorithm-expression=user_$->{id % 2}测试代码还是那个插入操作,直接看执行结果吧,会根据ID取模自动匹配对应的表。
🔊 打印日志
🤍使用Sharding-JDBC读写分离
🔊 properties配置
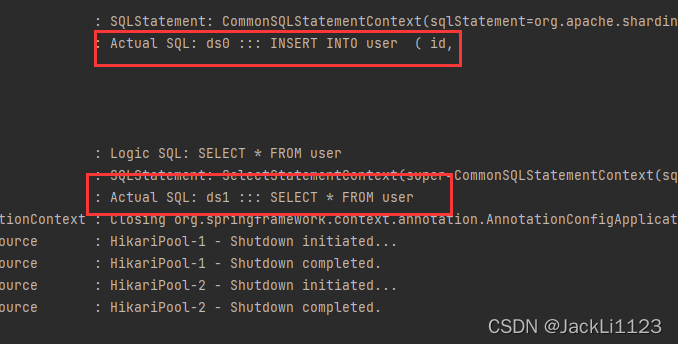
#主数据库配置spring.shardingsphere.masterslave.name=datasourcespring.shardingsphere.masterslave.master-data-source-name=ds0#从数据库配置,可以是多个采用负载均衡策略spring.shardingsphere.masterslave.slave-data-source-names=ds1spring.shardingsphere.masterslave.load-balance-algorithm-type=ROUND_ROBIN#使用雪花算法生成IDspring.shardingsphere.sharding.tables.user.key-generator.column=idspring.shardingsphere.sharding.tables.user.key-generator.type=SNOWFLAKE🔊 打印日志
可以看到执行插入操作使用的是database0,执行查询操作使用的是database1。