【道高一尺,魔高一丈】Python爬虫之如何应对网站反爬虫策略
目录
一、一句话核心
二、我经常用的反反爬技术:
2.1 模拟请求头
2.2 伪造请求cookie
2.3 随机等待间隔
2.4 使用代理IP
2.5 验证码破解
三、爬虫写得好,牢饭吃到饱?
关于应对爬虫的反爬,最近整理了一些心得,落笔成文,复盘记录下。
一、一句话核心
应对反爬策略多种多样,但万变不离其宗,核心一句话就是:
"爬虫越像人为操作,越不会被检测到反爬。"
二、我经常用的反反爬技术:
2.1 模拟请求头
request header,其中最关键的一项,User-Agent,可以写个agent_list,每次请求,随机选择一个agent,像这样:
agent_list = ["Mozilla/5.0 (Linux; U; Android 2.3.6; en-us; Nexus S Build/GRK39F) AppleWebKit/533.1 (KHTML, like Gecko) Version/4.0 Mobile Safari/533.1","Avant Browser/1.2.789rel1 (http://www.avantbrowser.com)","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5","Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7","Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14","Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1","Mozilla/5.0 (Windows NT 6.0) AppleWebKit/535.2 (KHTML, like Gecko) Chrome/15.0.874.120 Safari/535.2","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.7 (KHTML, like Gecko) Chrome/16.0.912.36 Safari/535.7","Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre","Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.9.0.10) Gecko/2009042316 Firefox/3.0.10"]在调用的时候,随机选取一个就可以了:
'User-Agent': random.choice(agent_list)当然,你也可以使用fake_useragent(一个前人集成好的随机UA库)这个库,但有时候不好使,通常会报一个这种Error:
fake_useragent.errors.FakeUserAgentError: Maximum amount of retries reached
遇到这种报错不要慌,简单粗暴一点,把fake_useragent的json内容down到本地,目的是把从网站服务器获取,改为从本地获取,就可以避免timeout这种Error了。
json获取地址:https://fake-useragent.herokuapp.com/browsers/0.1.11
2.2 伪造请求cookie
发送请求的时候,request header里面,加上"cookie"这一项,伪造自己登陆了的假象。
从哪里获取"cookie"值呢?同样是按F12打开浏览器开发者模式,找到目标地址对应的headers->request headers,找到cookie这一项,把值复制下来。
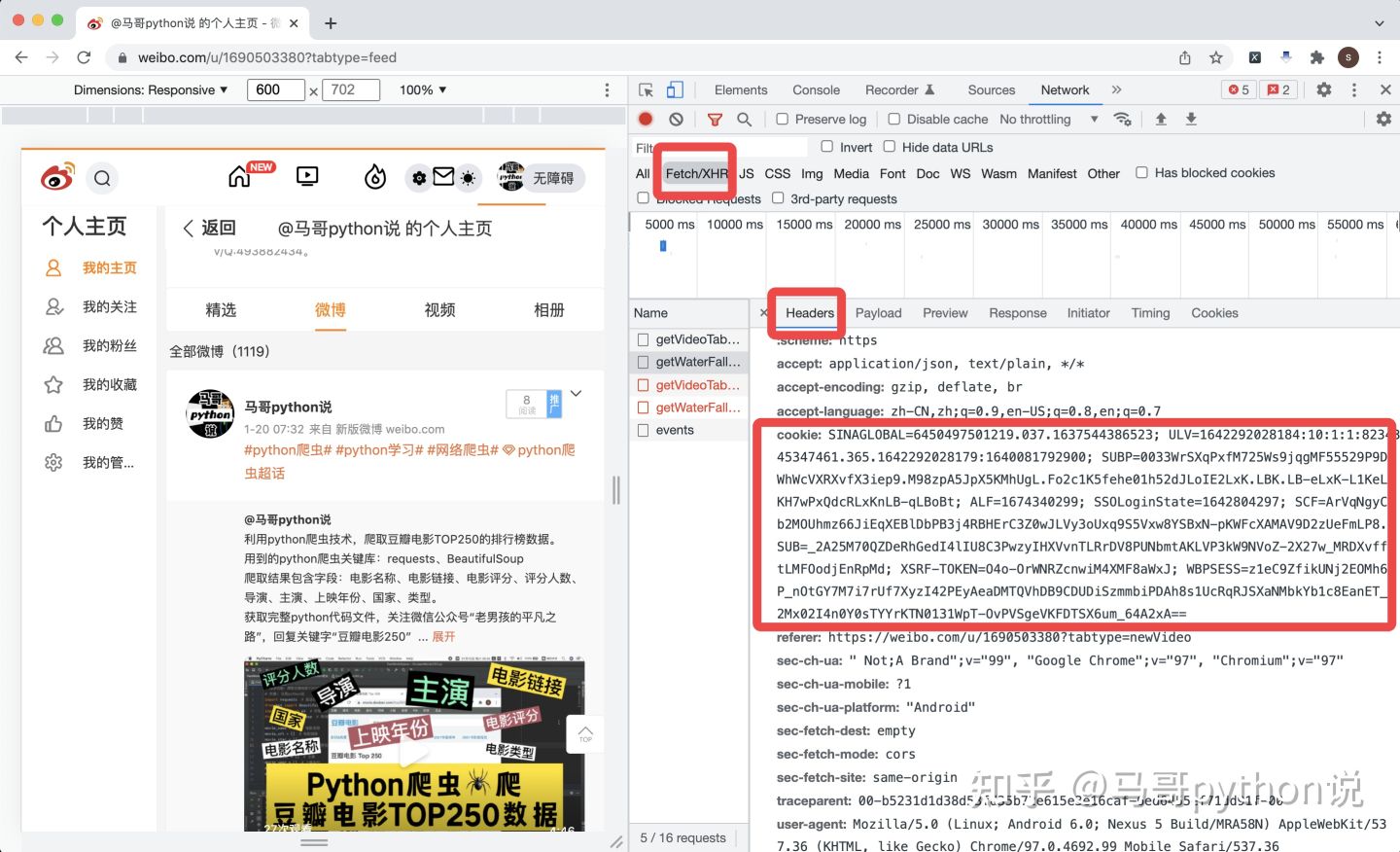
查看网页的cookie值
放到爬虫代码的请求头里,类似这样:

把cookie值粘到爬虫代码
2.3 随机等待间隔
每次发送请求后,sleep随机等待时间,像这样:
time.sleep(random.uniform(0.5, 1)) # 随机等待时间是0.5秒和1秒之间的一个小数尽量不要用sleep(1)、sleep(3)这种整数时间的等待,一看就是机器。。
还是那句话,让爬虫程序表现地更像一个人!

2.4 使用代理IP
使用代理IP解决反爬。(免费代理不靠谱,最好使用付费的。有按次数收费的,有按时长收费的,根据自身情况选择)
是什么意思呢,就是每次发送请求,让你像从不同的地域发过来的一样,第一次我的ip地址是河北,第二次是广东,第三次是美国。。。像这样:
def get_ip_pool(cnt):"""获取代理ip的函数"""url_api = '获取代理IP的API地址'try:r = requests.get(url_api)res_text = r.textres_status = r.status_codeprint('获取代理ip状态码:', res_status)print('返回内容是:', res_text)res_json = json.loads(res_text)ip_pool = random.choice(res_json['RESULT'])ip = ip_pool['ip']port = ip_pool['port']ret = str(ip) + ':' + str(port)print('获取代理ip成功 -> ', ret)return retexcept Exception as e:print('get_ip_pool except:', str(e))proxies = get_ip_pool() # 调用获取代理ip的函数requests.get(url=url, headers=headers, proxies={'HTTPS': proxies}) # 发送请求这样,对端服务器就会认为你/你们是很多地域的访客,就算访问很频繁,可能也不会反爬你!
2.5 验证码破解
关于验证码破解,我建议大家阅读崔庆才写的《Python3网络爬虫开发实战》
其中,第8章:验证码的识别,提到了四类验证码的破解:
- 8.1 图形验证码的识别
- 8.2 极验滑动验证码的识别
- 8.3 点触验证码的识别
- 8.4 微博宫格验证码的识别
在8.3章节里,作者提到用第三方打码平台超级鹰平台,我也应用到了下面这个案例。
用第三方打码平台,直接调用它的接口,省心省力。
我之前为了破解Google的recaptcha验证码,就这种:

调用的超级鹰的图像识别打码方法。大致思路是:
- 把页面弹出的验证码图片元素,截图保存到本地。
- 按照打码平台的图片大小要求,用PIL库进行缩放、裁剪并保存。
- 把处理好的图片,通过调用平台api发送给打码平台服务器,平台识别成功后返回坐标值对,利用python的selenium库依次点击相应坐标,完成验证码的自动识别。(此期间需逻辑判断,如果平台返回有误,需重新触发点击操作,直至验证成功)
顺便贴一下python代码:
def f_solve_captcha(v_infile, offset_x, offset_y, multiple=0.55):"""利用超级鹰识别验证码:param offset_x: x轴偏移量:param offset_y: y轴偏移量:param v_infile: 验证码图片:param multiple: 图片缩小系数:return: 验证码识别结果坐标list"""outfile = 'new-' + v_infile# 1、图片缩小到超级鹰要求:宽不超过460px,高不超过310pximg = Image.open(v_infile)w, h = img.sizew, h = round(w * multiple), round(h * multiple) # 去掉浮点,防报错img = img.resize((w, h), Image.ANTIALIAS)img.save(outfile, optimize=True, quality=85) # 质量为85效果最好print('pic smaller done!')# 2、调用超级鹰识别chaojiying = Chaojiying_Client(cjy_username, cjy_password, cjy_soft_id)im = open(outfile, 'rb').read()ret = chaojiying.PostPic(im, 9008)print(ret)loc_list2 = []if ret['err_no'] == 0: # 返回码0代表成功loc_list = ret['pic_str'].split('|')for loc in loc_list:loc_x = round(int(loc.split(',')[0]) / multiple)loc_y = round(int(loc.split(',')[1]) / multiple)loc_list2.append((loc_x + offset_x, loc_y + offset_y))print('超级鹰返回正确,loc_list2 is:')print(loc_list2)print('长度是:{}'.format(len(loc_list2)))else:print('超级鹰返回错误!错误码:{},错误内容:{}'.format(ret['err_no'], ret['err_str']))return loc_list2路过的爬虫大佬,可以给我支个招,我感觉这个办法太笨了,有点楞~
三、爬虫写得好,牢饭吃到饱?
关于爬虫这门开发技术,是否触犯法律,一直争议不断。我们作为技术人员,要时刻警醒自己,什么能爬,什么不能爬,心中要有一杆称:
- 爬之前,花费你珍贵的10秒钟,看看目标网页的robots.txt,如果人家明确写了User-agent: * Disallow: / ,再爬就是你的不对了不是。。看不懂robots语法的,请自行移步:https://developers.google.com/search/reference/robots_txt?hl=zh-cn
- 别爬敏感数据、隐私数据
- 别把数据商用,自己做数据分析,练练手就好
- 如果目标网站对外开放了API接口,就直接用吧,别自己写网页爬虫了。正门给你敞开了,你非要爬窗户进,咋地?职业习惯吗??
- 别可劲儿爬、可劲儿造,收着点儿,千万别给对端服务器造成访问影响,甚至宕机!
我们身为程序猿/程序媛,写代码是为了让这个世界变得更美好,一定要做遵纪守法的好公民!
peace~
同步公众号文章:
【道高一尺,魔高一丈】Python爬虫之如何应对网站反爬虫策略关于应对爬虫的反爬,最近整理了一些心得,落笔成文,复盘记录下。一、一句话核心应对反爬策略多种多样,但万变不离https://mp.weixin.qq.com/s?__biz=MzU5MjQ2MzI0Nw==&mid=2247484238&idx=1&sn=e68f02ba613b0eea88da40e013d2f756&chksm=fe1e17aec9699eb81c0063dc0f259425cd3316deb1507ac2b0854426dbf9d10c7ee38c12e948&token=928226833&lang=zh_CN#rd
我是马哥,全网累计粉丝上万,欢迎一起交流python技术。
各平台搜索“马哥python说”:知乎、哔哩哔哩、小红书、新浪微博。

