JVM垃圾回收算法和垃圾回收器
java中的自动内存回收是java的一大特点,他依赖于底层的JVM实现,最近通过回顾和学习,主要分享一下几点:
垃圾确认方式
垃圾回收算法
垃圾回收器的组合
垃圾确认方式
垃圾的定义:没有任何引用指向的对象就是垃圾。
垃圾确认算法有两种:
1.引用计数:对象中标记被应用的数量,也就是每有一个引用指向对象,引用计数会加1,当引用不指向对象时,计数器会减1,当引用计数为0时就垃圾可以回收了。
引用计数缺点:当有循环依赖时,将无法回收对象空间,即A引用B,B引用C,C又引用A,这样A、B、C都不能被回收。
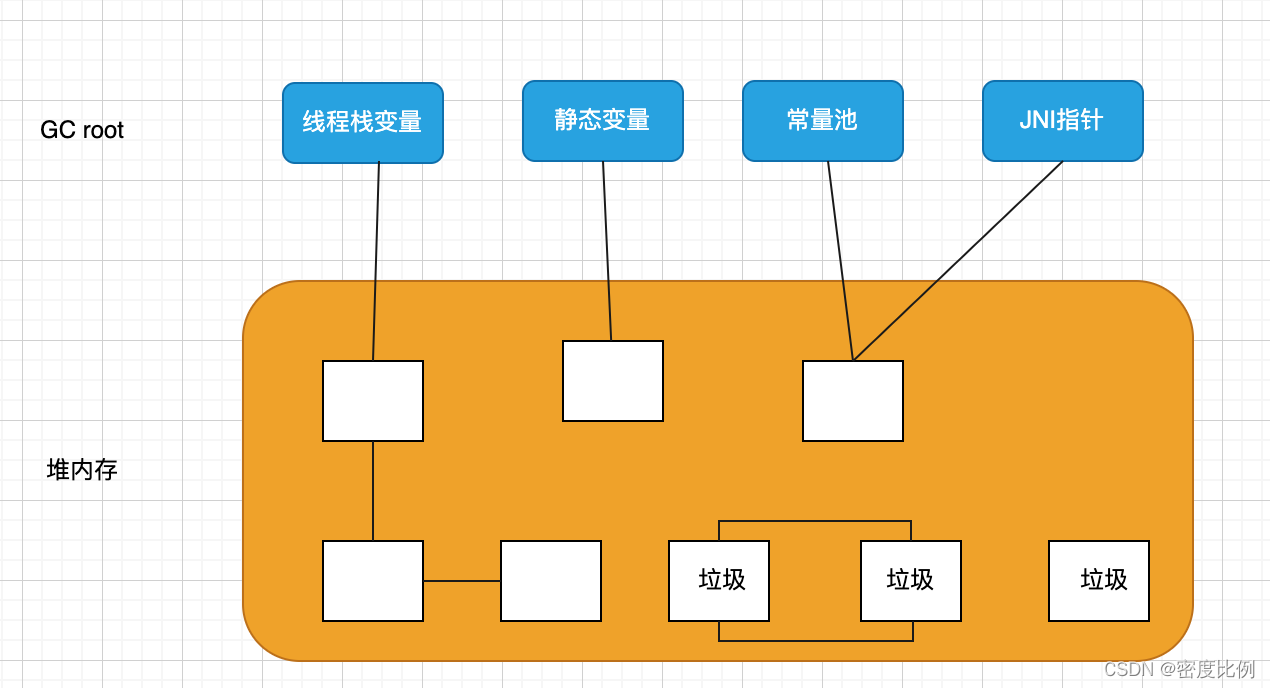
2. 根可达性算法(root searching):从根对象开始查找,不可达的对象就会成为垃圾,如下图:
垃圾回收算法
垃圾回收算法大致有三种:
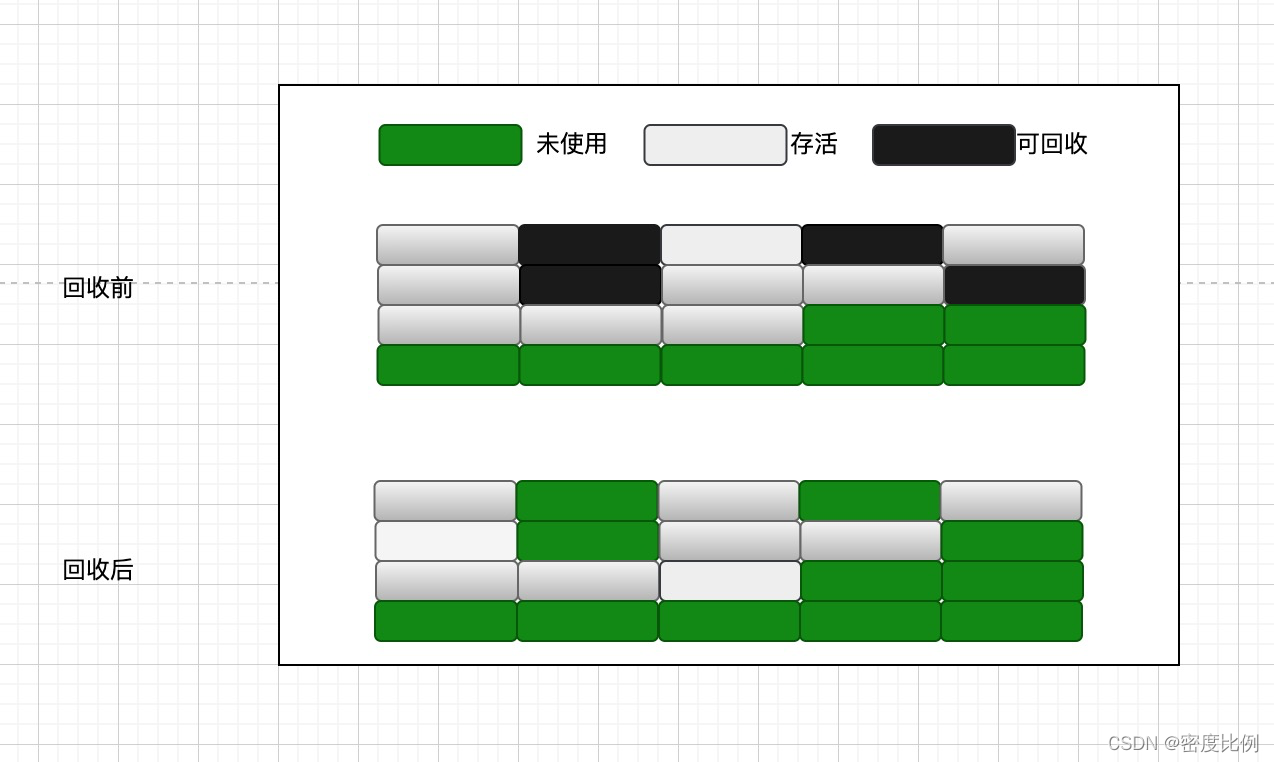
1.标记清除(mark-sweep )
定义:根据根可达性算法找到不可回收对象,清理可回收对象。
特点:算法简单,在存活对象比较多的情况下效率比较高。
缺点:两边扫描,效率偏低,容易产生内存碎片,
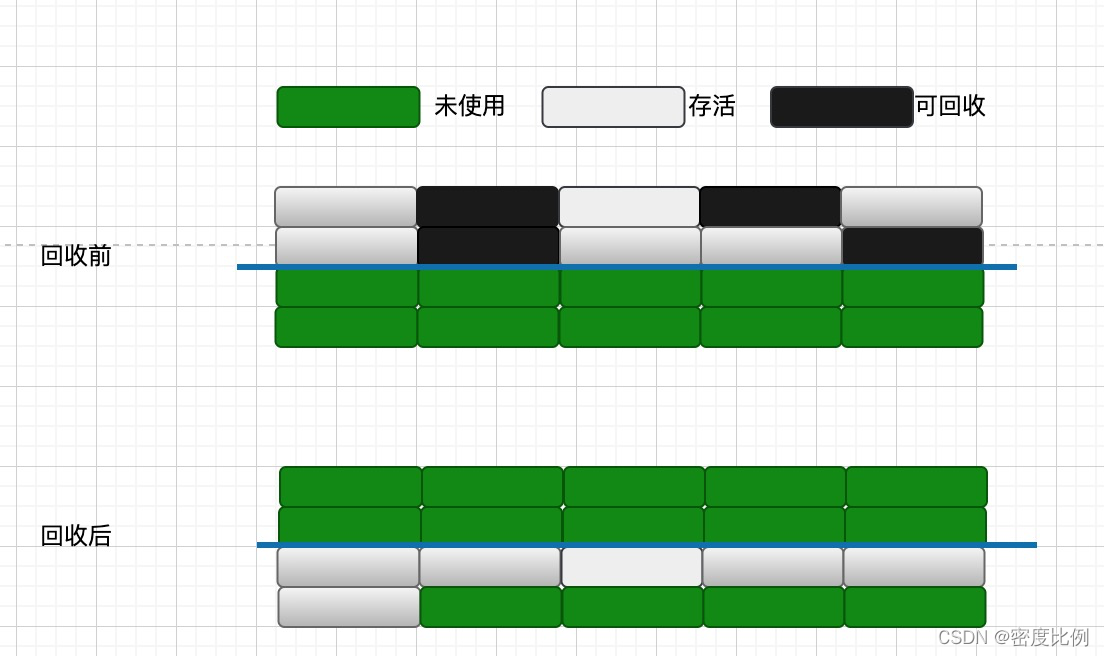
2.拷贝(copying)
定义:将内存一分为二,将不可回收的对象拷贝到另一块空闲内存区域,然后当前内存区域全部清理。
特点:只扫描一次,效率比较高,没有内存碎片产生,适用于存活对象比较少的场景。
缺陷:浪费内存空间,有对象的移动,需要修改对象的引用。
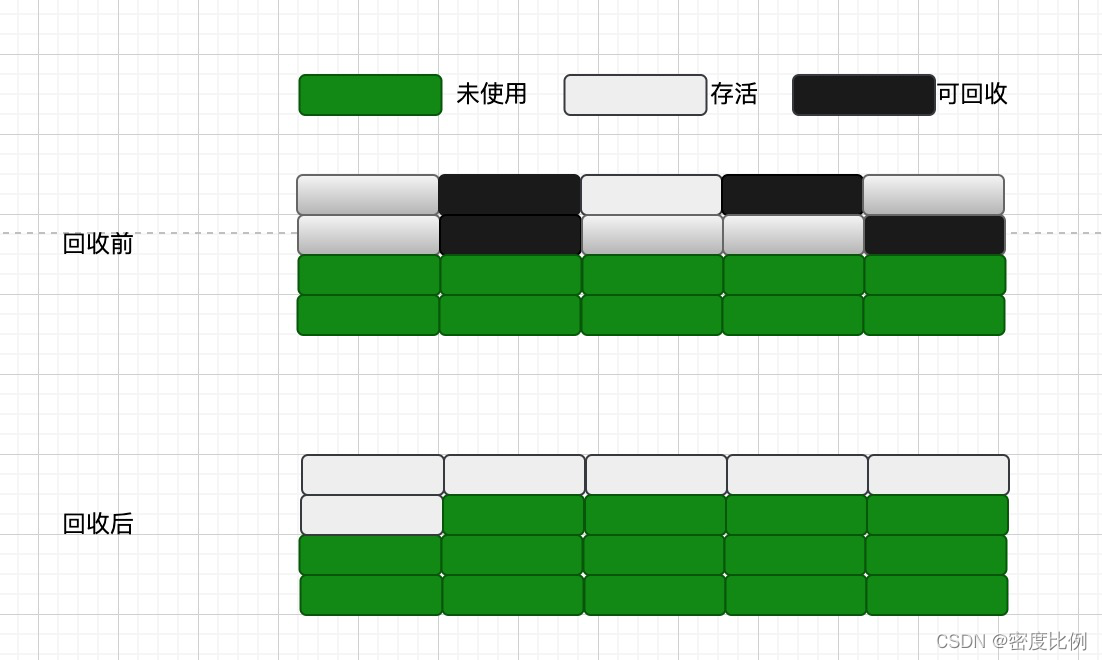
3.标记压缩(mark-compact)
定义:通过根可达性算法标记出有效对象,然后将垃圾对象移动到内存区域的前端,这样一来无效对象和有效对象在内存中是连续的,直接清理调无效对象区域。
特点:不会产生碎片,不会使内存减半,
缺点:需要扫描两次,产生对象移动,效率偏低。
垃圾回收器的组合
垃圾回收我们一般是指的回收堆内存,在hotspot虚拟机中,堆内存的逻辑分区目前较为常用的是分代的方式,分为年轻代和老年代,年轻代又分为:eden和两个survivor。
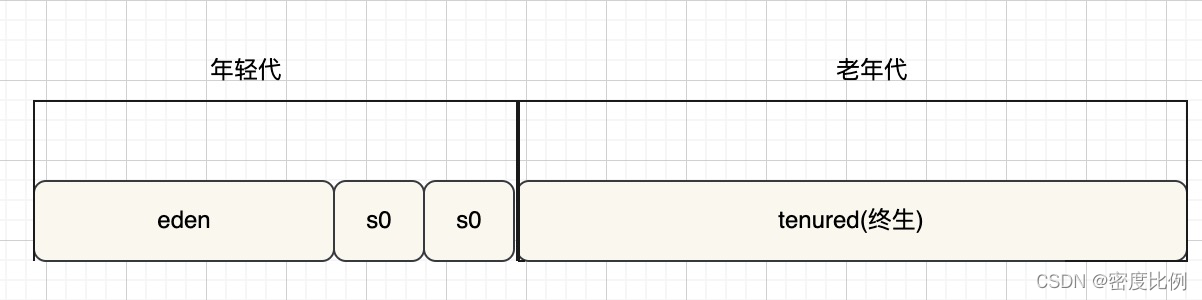
常见的垃圾回收器如下图:
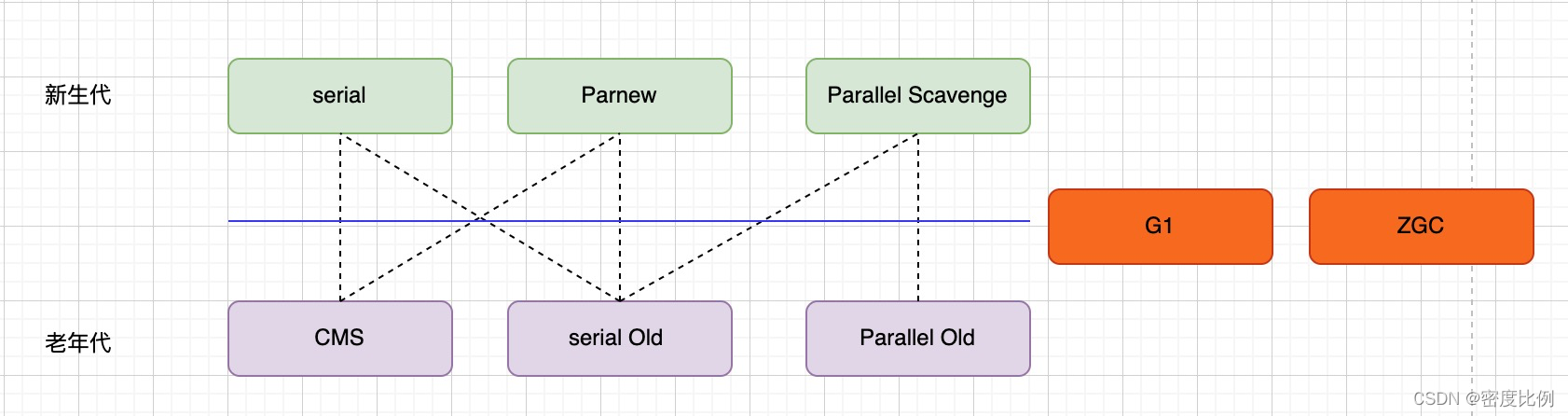
如图:图中的连线代表着可以搭配使用的收集器,
新生代收集器:Serial、ParNew、Parallel Scavenge,这几个收集器都是采用的复制算法
老年代收集器:CMS(标记-清理)、Serial Old(标记-整理)、Parallel Old(标记整理)
整堆收集器(不分代的模式): G1(一个Region中是标记-清除算法,2个Region之间是复制算法)
下面我们详细介绍一下每种垃圾回收器的特点:
Serial:是最早的垃圾收集器,,
特点:会产生STW(stop the world),单线程垃圾收集器,用在年轻代,采用的是复制算法、单CPU效率最高,虚拟机是是client模式时默认的垃圾收集器。
Serial old: 老年代算法,目前基本不用了,当内存很大时,stw时间会很长。
特点:会产生STW(stop the world),单线程垃圾收集器,采用的是标记压缩,标记清除算法。
Parallel Scavenge:用在年轻代,目前常用的常与Parallel old组合使用。
特点:会产生STW(stop the world),多线程清理垃圾,
Parallel Old:用在老年代,采用标记压缩算法,
特点:会产生STW(stop the world),多线程清理垃圾,
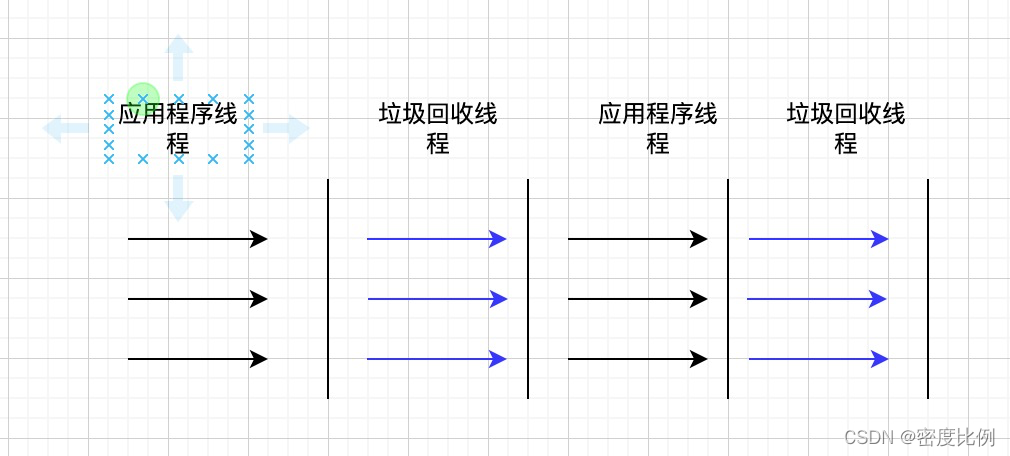
ParNew: 用在年轻代,采用复制算法,是Parallel Scavenge的增强版,与CMS结合使用。
特点:会产生STW(stop the world),多线程并行清理垃圾,默认线程数是cpu数量。
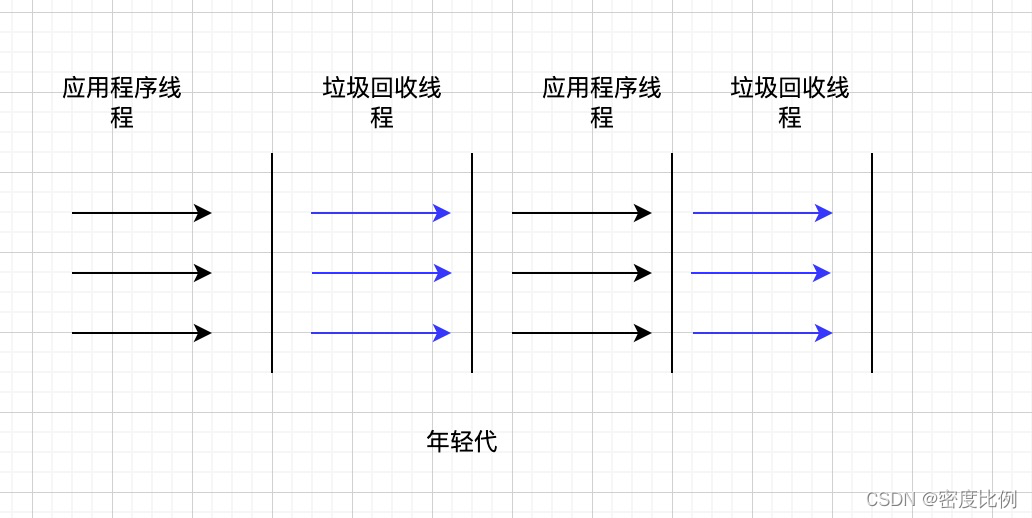
CMS:应用在老年代,是里程碑式的垃圾收集器,开启了并发回收的过程,即内存回收过程是与用户线程一起并发执行 ,但CMS存在很多问题,所以不是默认的垃圾回收期。
特点: 并发回收(内存回收和用户线程一起执行,在清理垃圾的过程,同时产生垃圾)
缺点:对cpu资源非常敏感,无法处理浮动垃圾,可能会出现concurrent mondel failure失败,而导致一次full gc的产生。采用标记清除算法,会产生内存碎片。
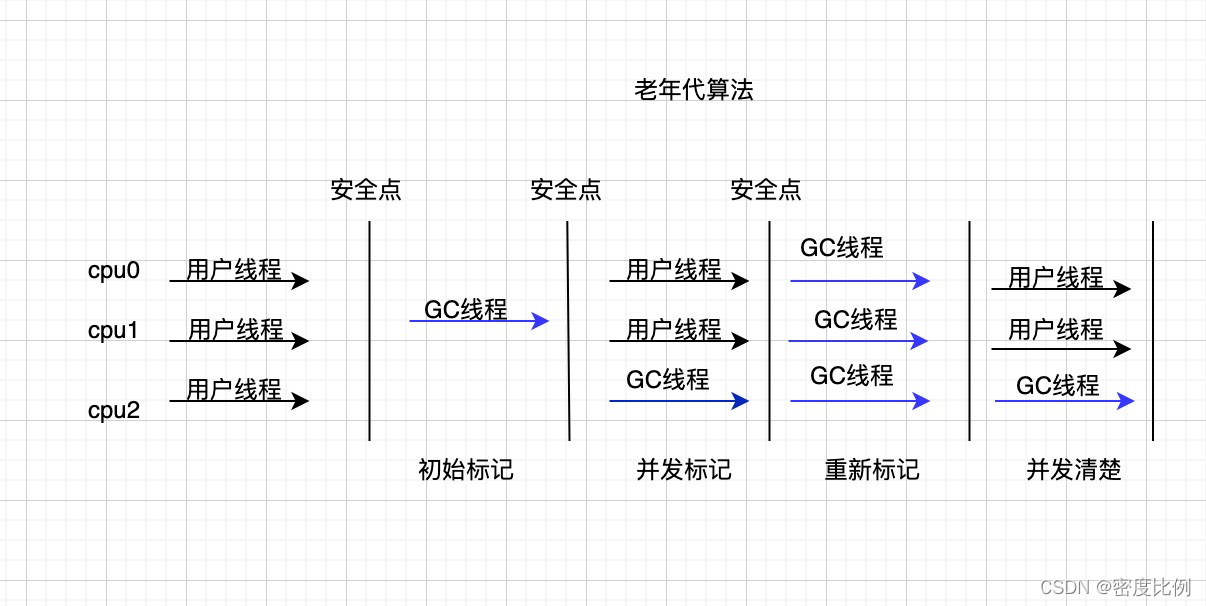
如上图:cms大体分为4个阶段,
1.初始标记阶段:是标记出所有的根对象(GC roots),速度很快,但仍需要stop the world。
2.并发标记阶段:根据跟对象标记出有效的对象,这是用户线程可并发执行。
3.重新标记:在并发标记的过程中,有些对象可能无效,有些对象可能由无效变成有效,所以需要重新标记这部分对象,这个时候也是需要stop the world。
4.并发清除:对垃圾对象进行清除。
G1:是面向服务端的垃圾回收器,采用三色标记+SATB算法。
特点:
并行与并发:G1能充分利用多CPU、多核环境下的硬件优势,使用多个CPU来缩短Stop-The-World停顿 时间。部分收集器原本需要停顿Java线程来执行GC动作,G1收集器仍然可以通过并发的方式让Java程序 继续运行。 分代收集:G1能够独自管理整个Java堆,并且采用不同的方式去处理新创建的对象和已经存活了一段时 间、熬过多次GC的旧对象以获取更好的收集效果。 空间整合:G1运作期间不会产生空间碎片,收集后能提供规整的可用内存。

