Debezium同步之PostgreSQL数据到Kafka的同步
目录
一、前言
二、概述
三、设置 Postgres
3.1 云上的 PostgreSQL
3.3 插件差异
3.4 配置 PostgreSQL 服务器
3.5 设置权限
3.6 设置权限以启用 Debezium 在您使用时创建 PostgreSQL 发布pgoutput
3.7 配置 PostgreSQL 以允许使用 Debezium 连接器主机进行复制
3.8 支持的 PostgreSQL 拓扑
3.9 WAL 磁盘空间消耗
四、部署
4.1 连接器配置示例
4.2 添加连接器配置
一、前言
Debezium PostgreSQL 连接器捕获 PostgreSQL 数据库模式中的行级更改。有关与连接器兼容的 PostgreSQL 版本的信息,请参阅Debezium 版本概述。
第一次连接到 PostgreSQL 服务器或集群时,连接器会拍摄所有模式的一致快照。在该快照完成后,连接器会持续捕获插入、更新和删除数据库内容以及提交到 PostgreSQL 数据库的行级更改。连接器生成数据更改事件记录并将它们流式传输到 Kafka 主题。对于每个表,默认行为是连接器将所有生成的事件流式传输到该表的单独 Kafka 主题。应用程序和服务使用来自该主题的数据更改事件记录。
二、概述
PostgreSQL 的逻辑解码功能是在 9.4 版本中引入的。它是一种机制,允许提取提交到事务日志的更改,并在输出插件的帮助下以用户友好的方式处理这些更改。输出插件使客户端能够使用更改。
PostgreSQL 连接器包含两个主要部分,它们协同工作以读取和处理数据库更改:
-
一个逻辑解码输出插件。您可能需要安装您选择使用的输出插件。在运行 PostgreSQL 服务器之前,您必须配置一个使用您选择的输出插件的复制槽。插件可以是以下之一:
-
decoderbufs基于 Protobuf 并由 Debezium 社区维护。
-
wal2json基于 JSON 并由 wal2json 社区维护(已弃用,计划在 Debezium 2.0 中删除)。
-
pgoutput是 PostgreSQL 10+ 中的标准逻辑解码输出插件。它由 PostgreSQL 社区维护,并由 PostgreSQL 本身用于逻辑复制。此插件始终存在,因此无需安装其他库。Debezium 连接器将原始复制事件流直接解释为更改事件。
-
-
读取所选逻辑解码输出插件产生的更改的 Java 代码(实际的 Kafka Connect 连接器)。它使用 PostgreSQL 的流复制协议,通过 PostgreSQL JDBC 驱动程序
连接器为捕获的每个行级插入、更新和删除操作生成一个更改事件,并为单独的 Kafka 主题中的每个表发送更改事件记录。客户端应用程序读取与感兴趣的数据库表对应的 Kafka 主题,并且可以对从这些主题接收到的每个行级事件做出反应。
PostgreSQL 通常会在一段时间后清除 write-ahead log (WAL) 段。这意味着连接器没有对数据库所做的所有更改的完整历史记录。因此,当 PostgreSQL 连接器第一次连接到特定的 PostgreSQL 数据库时,它首先对每个数据库模式执行一致的快照。连接器完成快照后,它会从创建快照的确切点继续流式传输更改。这样,连接器从所有数据的一致视图开始,并且不会忽略在拍摄快照时所做的任何更改。
连接器可以容忍故障。当连接器读取更改并产生事件时,它会记录每个事件的 WAL 位置。如果连接器因任何原因(包括通信故障、网络问题或崩溃)停止,则在重新启动时,连接器会继续读取上次停止的 WAL。这包括快照。如果连接器在快照期间停止,则连接器在重新启动时会开始新的快照。
|
连接器依赖并反映了 PostgreSQL 逻辑解码特性,该特性有以下限制:
出现问题时的行为描述了连接器在出现问题时所做的事情。 |
|
Debezium 目前仅支持使用 UTF-8 字符编码的数据库。使用单字节字符编码,无法正确处理包含扩展 ASCII 代码字符的字符串。 |
三、设置 Postgres
在使用 PostgreSQL 连接器监控 PostgreSQL 服务器上提交的更改之前,请确定您打算使用哪个逻辑解码插件。如果您不打算使用本机pgoutput逻辑复制流支持,则必须将逻辑解码插件安装到 PostgreSQL 服务器中。之后,启用复制槽,并配置具有足够权限的用户来执行复制。
如果您的数据库由Heroku Postgres等服务托管,您可能无法安装该插件。如果是这样,并且如果您使用的是 PostgreSQL 10+,则可以使用pgoutput解码器支持来捕获数据库中的更改。如果这不是一个选项,您将无法将 Debezium 与您的数据库一起使用。
3.1 云上的 PostgreSQL
Amazon RDS 上的 PostgreSQL
可以在Amazon RDS中运行的 PostgreSQL 数据库中捕获更改。去做这个:
-
将实例参数设置
rds.logical_replication为1。 -
通过以数据库 RDS 主用户身份运行查询来验证
wal_level参数是否设置为。在多区域复制设置中可能不是这种情况。您不能手动设置此选项。参数设置为时自动更改。如果您进行上述更改后没有设置为,则可能是因为参数组更改后必须重新启动实例。重新启动发生在您的维护时段内,或者您可以手动启动重新启动。logicalSHOW wal_levelrds.logical_replication1wal_levellogical -
将 Debezium
plugin.name参数设置为pgoutput。 -
从具有该
rds_replication角色的 AWS 账户启动逻辑复制。该角色授予管理逻辑槽和使用逻辑槽流式传输数据的权限。默认情况下,只有 AWS 上的主用户账户具有rds_replicationAmazon RDS 上的角色。要启用主帐户以外的用户帐户来启动逻辑复制,您必须授予该帐户rds_replication角色。例如,。您必须有权将角色授予用户。要使主账户以外的账户能够创建初始快照,您必须向要捕获的表上的账户授予权限。有关 PostgreSQL 逻辑复制的安全性的更多信息,请参阅PostgreSQL 文档。grant rds_replication tosuperuserrds_replicationSELECT
(1)Azure 上的 PostgreSQL
可以将 Debezium 与 Azure Database for PostgreSQL一起使用,后者支持 Debezium 支持的pgoutput逻辑解码插件。
将 Azure 复制支持设置为 logical. 您可以使用Azure CLI或Azure 门户进行配置。例如,要使用 Azure CLI,az postgres server您需要执行以下命令:
az postgres server configuration set --resource-group mygroup --server-name myserver --name azure.replication_support --value logicalaz postgres server restart --resource-group mygroup --name myserver(2)CrunchyBridge 上的 PostgreSQL
可以将 Debezium 与CrunchyBridge一起使用;逻辑复制已打开。该pgoutput插件可用。您必须创建一个复制用户并提供正确的权限。
|
使用 |
3.2 安装逻辑解码输出插件
|
有关设置和测试逻辑解码插件的更详细说明,请参阅PostgreSQL 的逻辑解码输出插件安装。 |
从 PostgreSQL 9.4 开始,读取预写日志更改的唯一方法是安装逻辑解码输出插件。插件用 C 语言编写、编译并安装在运行 PostgreSQL 服务器的机器上。插件使用许多 PostgreSQL 特定的 API,如PostgreSQL 文档中所述。
PostgreSQL 连接器与 Debezium 支持的逻辑解码插件之一一起使用,以Protobuf 格式或pgoutput格式从数据库接收更改事件。该pgoutput插件与 PostgreSQL 数据库一起开箱即用。有关通过decoderbufs插件使用 Protobuf 的更多详细信息,请参阅插件,documentation其中讨论了它的要求、限制以及如何编译它。
为简单起见,Debezium 还提供了基于上游 PostgreSQL 服务器镜像的容器镜像,在其之上编译和安装插件。您可以将此图像用作安装所需详细步骤的示例。
|
Debezium 逻辑解码插件仅在 Linux 机器上安装和测试。对于 Windows 和其他操作系统,可能需要不同的安装步骤。 |
3.3 插件差异
对于所有情况,插件行为并不完全相同。这些差异已被确定:
-
虽然所有插件都会在流式传输期间检测到模式更改时从数据库中刷新模式元数据,但
pgoutput插件更“渴望”触发此类刷新。例如,更改列的默认值将触发刷新pgoutput,而其他插件将不会知道此更改,直到另一个更改触发刷新(例如,添加新列)。这是由于的行为pgoutput,而不是 Debezium 本身。
所有最新的差异都在测试套件Java 类中进行跟踪。
3.4 配置 PostgreSQL 服务器
如果你使用的是除pgoutput之外的逻辑解码插件,安装后,配置PostgreSQL服务器如下:
-
要在启动时加载插件,请将以下内容添加到
postgresql.conf文件中:shared_preload_libraries = 'decoderbufs'1 指示服务器 decoderbufs在启动时加载逻辑解码插件(插件名称在Protobufmake文件中设置)。 -
要配置复制槽而不考虑使用的解码器,请在
postgresql.conf文件中指定以下内容:wal_level = logical1 指示服务器对预写日志使用逻辑解码。
根据您的要求,您可能需要在使用 Debezium 时设置其他 PostgreSQL 流式复制参数。示例包括增加可以同时访问发送服务器的连接器数量,以及max_wal_senders限制复制槽将保留的最大 WAL 大小。有关配置流复制的更多信息,请参阅PostgreSQL 文档。max_replication_slotswal_keep_size
Debezium 使用 PostgreSQL 的逻辑解码,它使用复制槽。即使在 Debezium 中断期间,复制槽也保证保留 Debezium 所需的所有 WAL 段。出于这个原因,密切监视复制槽非常重要,以避免过多的磁盘消耗和其他可能发生的情况,例如如果复制槽长时间未使用,则可能发生目录膨胀。有关更多信息,请参阅PostgreSQL 流式复制文档。
如果您使用的synchronous_commit设置不是on,建议设置wal_writer_delay为 10 毫秒等值,以实现更改事件的低延迟。否则,将应用其默认值,这会增加大约 200 毫秒的延迟。
|
强烈建议阅读和理解有关 PostgreSQL 预写日志的机制和配置的 PostgreSQL 文档。 |
3.5 设置权限
设置 PostgreSQL 服务器以运行 Debezium 连接器需要可以执行复制的数据库用户。复制只能由具有适当权限的数据库用户执行,并且只能用于配置数量的主机。
尽管默认情况下,超级用户具有必要的角色REPLICATION和LOGIN角色,如Security中所述,但最好不要为 Debezium 复制用户提供提升的权限。相反,创建一个具有最低要求权限的 Debezium 用户。
先决条件
-
PostgreSQL 管理权限。
程序
-
要为用户提供复制权限,请定义至少具有
REPLICATION和LOGIN权限的 PostgreSQL 角色,然后将该角色授予用户。例如:CREATE ROLE REPLICATION LOGIN;
3.6 设置权限以启用 Debezium 在您使用时创建 PostgreSQL 发布pgoutput
如果pgoutput用作逻辑解码插件,Debezium 必须以具有特定权限的用户身份在数据库中操作。
Debezium 从为表创建的发布中流式传输 PostgreSQL 源表的更改事件。发布包含从一个或多个表生成的一组过滤的更改事件。根据发布规范过滤每个发布中的数据。该规范可以由 PostgreSQL 数据库管理员或 Debezium 连接器创建。要允许 Debezium PostgreSQL 连接器创建发布并指定要复制到其中的数据,连接器必须在数据库中以特定权限运行。
有几个选项可用于确定如何创建出版物。通常,最好在设置连接器之前为要捕获的表手动创建发布。但是,您可以以允许 Debezium 自动创建发布并指定添加到其中的数据的方式配置您的环境。
Debezium 使用包含列表和排除列表属性来指定如何在发布中插入数据。有关启用 Debezium 创建发布的选项的更多信息,请参阅publication.autocreate.mode。
要让 Debezium 创建 PostgreSQL 发布,它必须以具有以下权限的用户身份运行:
-
将表添加到发布的数据库中的复制权限。
-
CREATE数据库上添加出版物的权限。 -
SELECT表上的权限以复制初始表数据。表所有者自动拥有SELECT该表的权限。
要将表添加到发布,用户必须是表的所有者。但是由于源表已经存在,您需要一种机制来与原始所有者共享所有权。要启用共享所有权,您需要创建一个 PostgreSQL 复制组,然后将现有表所有者和复制用户添加到该组。
程序
-
创建复制组。
CREATE ROLE ; -
将表的原始所有者添加到组中。
GRANT REPLICATION_GROUP TO ; -
将 Debezium 复制用户添加到该组。
GRANT REPLICATION_GROUP TO ; -
将表的所有权转移到
.ALTER TABLEOWNER TO REPLICATION_GROUP;
要让 Debezium 指定捕获配置,publication.autocreate.mode必须将 的值设置为
filtered。3.7 配置 PostgreSQL 以允许使用 Debezium 连接器主机进行复制
要使 Debezium 能够复制 PostgreSQL 数据,您必须将数据库配置为允许与运行 PostgreSQL 连接器的主机进行复制。要指定允许与数据库一起复制的客户端,请将条目添加到 PostgreSQL 基于主机的身份验证文件
pg_hba.conf. 有关该pg_hba.conf文件的更多信息,请参阅PostgreSQL文档。程序
-
向文件中添加条目以
pg_hba.conf指定可以与数据库主机一起复制的 Debezium 连接器主机。例如,pg_hba.conf文件示例:local replication trust host replication 127.0.0.1/32 trust host replication ::1/128 trust1 指示服务器允许 本地复制,即在服务器计算机上。2 指示服务器允许 onlocalhost使用 接收复制更改IPV4。3 指示服务器允许 onlocalhost使用 接收复制更改IPV6。
有关网络掩码的更多信息,请参阅PostgreSQL 文档。
3.8 支持的 PostgreSQL 拓扑
PostgreSQL 连接器可以与独立的 PostgreSQL 服务器或 PostgreSQL 服务器集群一起使用。
如开头所述,PostgreSQL(适用于所有版本 ⇐ 12)仅支持
primary服务器上的逻辑复制槽。这意味着不能为 PostgreSQL 集群中的副本配置逻辑复制,因此 Debezium PostgreSQL 连接器只能与主服务器连接和通信。如果此服务器出现故障,连接器将停止。集群修复后,如果原来的主服务器再次提升为primary,可以重启连接器。但是,如果将具有插件和正确配置的不同 PostgreSQL 服务器升级为primary,则必须更改连接器配置以指向新primary服务器,然后才能重新启动连接器。3.9 WAL 磁盘空间消耗
在某些情况下,WAL 文件消耗的 PostgreSQL 磁盘空间可能会激增或超出正常比例。这种情况有几个可能的原因:
-
连接器接收到数据的 LSN在服务器视图的
confirmed_flush_lsn列中可用。pg_replication_slots早于此 LSN 的数据不再可用,数据库负责回收磁盘空间。同样在
pg_replication_slots视图中,该restart_lsn列包含连接器可能需要的最旧 WAL 的 LSN。如果 for 的值confirmed_flush_lsn定期增加并且值restart_lsn滞后,则数据库需要回收空间。数据库通常以批处理块的形式回收磁盘空间。这是预期行为,无需用户采取任何行动。
-
正在跟踪的数据库中有许多更新,但只有极少数更新与连接器正在捕获更改的表和模式相关。这种情况可以通过周期性的心跳事件轻松解决。设置heartbeat.interval.ms连接器配置属性。
-
PostgreSQL 实例包含多个数据库,其中一个是高流量数据库。Debezium 捕获与另一个数据库相比流量较低的另一个数据库中的更改。然后,Debezium 无法确认 LSN,因为复制槽在每个数据库中工作,并且没有调用 Debezium。由于 WAL 由所有数据库共享,因此使用量趋于增长,直到 Debezium 正在捕获更改的数据库发出事件。为了克服这个问题,有必要:
-
heartbeat.interval.ms使用连接器配置属性启用定期心跳记录生成。 -
定期从 Debezium 捕获更改的数据库中发出更改事件。
然后,一个单独的进程将通过插入新行或重复更新同一行来定期更新表。PostgreSQL 然后调用 Debezium,它确认最新的 LSN 并允许数据库回收 WAL 空间。此任务可以通过heartbeat.action.query连接器配置属性自动执行。
-
对于使用 PostgreSQL 的 AWS RDS 上的用户,在空闲环境中可能会出现类似于高流量/低流量场景的情况。AWS RDS 会导致客户端频繁(5 分钟)看不到对其自己系统表的写入。同样,定期发出事件可以解决问题。
四、部署
要部署 Debezium PostgreSQL 连接器,请安装 Debezium PostgreSQL 连接器存档,配置连接器,然后通过将其配置添加到 Kafka Connect 来启动连接器。
先决条件
-
Zookeeper、Kafka和Kafka Connect已安装。
-
PostgreSQL 已安装并设置为运行 Debezium 连接器。
程序
-
下载 Debezium PostgreSQL 连接器插件存档。
-
将文件提取到您的 Kafka Connect 环境中。
-
将包含 JAR 文件的目录添加到Kafka Connect 的plugin.path.
-
重新启动 Kafka Connect 进程以获取新的 JAR 文件。
如果您正在使用不可变容器,请参阅Debezium 的Zookeeper、Kafka、PostgreSQL 和 Kafka Connect 容器映像,其中 PostgreSQL 连接器已安装并准备好运行。您还可以在 Kubernetes 和 OpenShift 上运行 Debezium。
4.1 连接器配置示例
以下是 PostgreSQL 连接器的配置示例,该连接器在 192.168.99.100 的端口 5432 上连接到 PostgreSQL 服务器,其逻辑名称为
fulfillment. 通常,您通过设置可用于连接器的配置属性,在 JSON 文件中配置 Debezium PostgreSQL 连接器。您可以选择为数据库中的模式和表的子集生成事件。或者,您可以忽略、屏蔽或截断包含敏感数据、大于指定大小或您不需要的列。
{ "name": "fulfillment-connector", "config": { "connector.class": "io.debezium.connector.postgresql.PostgresConnector", "database.hostname": "192.168.99.100", "database.port": "5432", "database.user": "postgres", "database.password": "postgres", "database.dbname" : "postgres", "database.server.name": "fulfillment", "table.include.list": "public.inventory" }}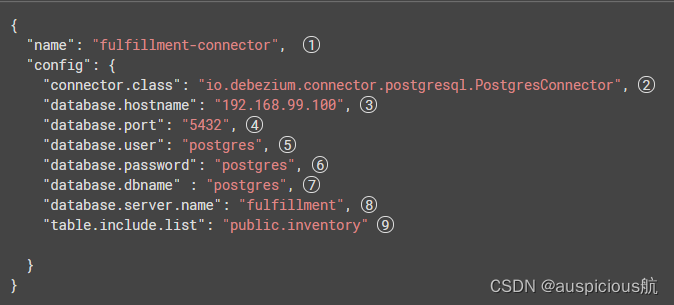
1 向 Kafka Connect 服务注册时的连接器名称。 2 此 PostgreSQL 连接器类的名称。 3 PostgreSQL 服务器的地址。 4 PostgreSQL 服务器的端口号。 5 具有所需权限的 PostgreSQL 用户的名称。 6 具有所需权限的 PostgreSQL 用户的密码。 7 要连接的 PostgreSQL 数据库的名称 8 PostgreSQL 服务器/集群的逻辑名称,形成一个命名空间,用于连接器写入的 Kafka 主题的所有名称、Kafka Connect 模式名称以及 Avro 转换器运行时相应 Avro 模式的命名空间用过的。 9 此连接器将监视的此服务器托管的所有表的列表。这是可选的,还有其他属性用于列出要从监视中包含或排除的模式和表。 请参阅可以在这些配置中指定的 PostgreSQL 连接器属性的完整列表。
您可以使用命令将此配置发送
POST到正在运行的 Kafka Connect 服务。该服务记录配置并启动一个执行以下操作的连接器任务:-
连接到 PostgreSQL 数据库。
-
读取事务日志。
-
流将事件记录更改为 Kafka 主题。
4.2 添加连接器配置
要运行 Debezium PostgreSQL 连接器,请创建一个连接器配置并将该配置添加到您的 Kafka Connect 集群。
先决条件
-
PostgreSQL 被配置为支持逻辑复制。
-
已安装逻辑解码插件。
-
PostgreSQL 连接器已安装。
程序
-
为 PostgreSQL 连接器创建配置。
-
使用Kafka Connect REST API将该连接器配置添加到您的 Kafka Connect 集群。
结果
连接器启动后,它会为连接器配置的 PostgreSQL 服务器数据库执行一致的快照。然后,连接器开始为行级操作生成数据更改事件,并将更改事件记录流式传输到 Kafka 主题。
 创作挑战赛
创作挑战赛  新人创作奖励来咯,坚持创作打卡瓜分现金大奖
新人创作奖励来咯,坚持创作打卡瓜分现金大奖 -

