篮球哥带你深度解剖C语言 —— 《关键字》(第二期)

打个赌,你一定会更喜欢明天的你! 💪
Be Legendary!
今天我们会穿插着讲一些关键字之外的内容:
🏀 1、数据类型
🥎 2、变量命名规则
⚽ 3、最冤枉的关键字sizeof
🏐 4、signed、unsigned关键字
🎱 5、大小端存储
🏀 1、数据类型
首先我们通过一张图来认识一下C语言中的数据类型:
那么我们常用数值类型在我们内存中占多大的空间呢?这里我们可以用一个关键字sizeof求一下所占空间大小!(sizeof下面会讲)
如上图可知,可能有小伙伴会有疑问,为什么long跟int占的空间一样大呢?(严格意义应该用 zu% 打印sizeof返回的值,因为sizeof 定义是 size_t 可以理解成无符号整型)
其实是这样的,long可以有多种定义,可以是32位,也可以是64位,C++标准上只是说long至少要和int一样大,也就是long只要>=int就可以了。
那么我们接着来思考,那么C语言中为什么要有类型呢?
本质对内存进行划分,按需索取!
C语言中为什么会存在这么多的类型呢?
应用场景不同,解决应用场景对应的计算方式不同,需要空间的大小也是不同的,本质:用最小成本解决各种多样化的场景问题!


🥎 2、变量命名规则
不知道小伙伴们在阅读其他人代码的时候会不会出现 int xishu; int hanshu; 这样的例子,看着真是让人头痛,其实良好的命名规则和代码风格在以后面试中会留下好印象的,所以,养成良好的命名规范从现在做起!
规则一:命名应该直观并且可以拼读,可见名知意,不允许使用拼音!英文不能复杂,用词应当准确。
规则二:命名长度应该适中(最短长度,最大信息),C语言是一种简捷的语言,命名也应如此,比如变量名MaxVal就比MaxValueUntilOverflow要好很多。标识符长度一般不要太长,英文词尽量不要缩写。
规则三:当标识符由多个词组成的时候,每个词的第一个字母大写,其他全部小写,例如:QuickSort(快速排序),这样的名会更清晰,比拼英或者单个字母好多了,这个叫做大驼峰命名。(建议函数这样命名)
规则四:尽量避免名字中出现数字编号,如Value1、Value2等,除非逻辑上需要编号,初学者总是喜欢用代编号的变量名或函数名,这样子看上去简单方便,但这样的命名无疑是一颗定时炸弹,一定要改过来!
规则五:程序中不得出现仅靠大小写区分的相似的标识符,例如:int x = 0; int X = 0;
规则六:一个函数名禁止被用于其他支出,例如:我们有一个fun函数,变量就不能以fun命名!不要让变量名和函数名一样!
规则七:所有宏定义,枚举常量,只读变量全用大写字母命名,用下划线分隔单词,比如:#define INT_MAX 100;
规则八:定义变量的同时不要忘记初始化。定义变量时编译器并不一定清空了这块内存,它的值可能是随机值。
我们目前暂时只需要:见名知意,大小驼峰,数字字母下划线即可。
⚽ 3、最冤枉的关键字sizeof
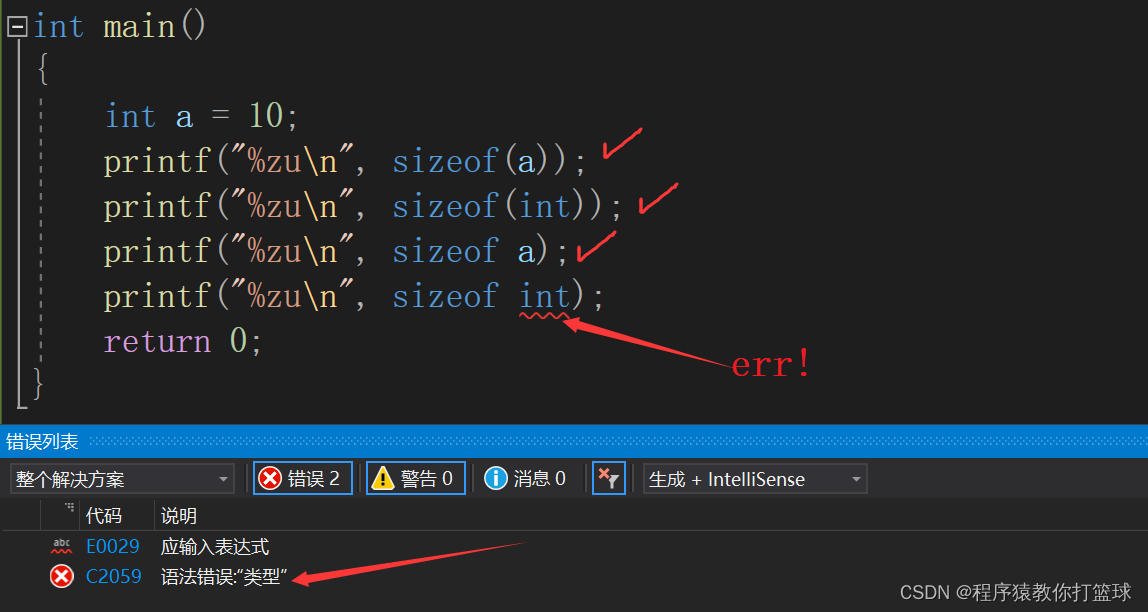
我们先了解下sizeof的几种写法:
这里我们可以看到,前面三种写法都是正确的,但是为什么第四种写法就会报错呢?
首先,从第三个printf可以看出来sizeof可以不带括号,可以证明sizeof并不是函数!而是关键字或者操作符,而且函数调用会压栈,sizeof并不会压栈,再者sizeof是一个关键字,int也是一个关键字,sizeof是不能直接去求另一个特定关键字的大小!
sizeof常用的场景我们后期碰到会讲解的,比如求数组元素个数:sizoef(arr) / sizeof(arr[0]);
🏐 4、signed、unsigned关键字
我们之前讲过一个变量的创建是要在内存中开辟空间的,空间的大小是根据不同的类型而决定的。 那么,数据在所开辟内存中到底是如何存储的呢?
我们先来了解概念,数据的存储分为有符号数和无符号数,那么计算机中有符号数有三种表示方法,分别是原码、反码、补码。
这三种方法均有符号为和数值位两部分,符号位都是用0表示正,用1表示负,而数值位三种表示方法各不相同:
如果一个数是负数,那么就要遵守下面规则进行转化:
- 原码:直接将一个二进制按照正负数的形式翻译成二进制就可以了。
- 反码:将原码的符号位不变,其他位一次按位取反。
- 补码:反码+1就可以得到补码。
如果一个数是正数,那么它的反码原码补码都相同。
- 无符号数:不需要转换
- 对于整型来说:数据存放在内存中是补码。
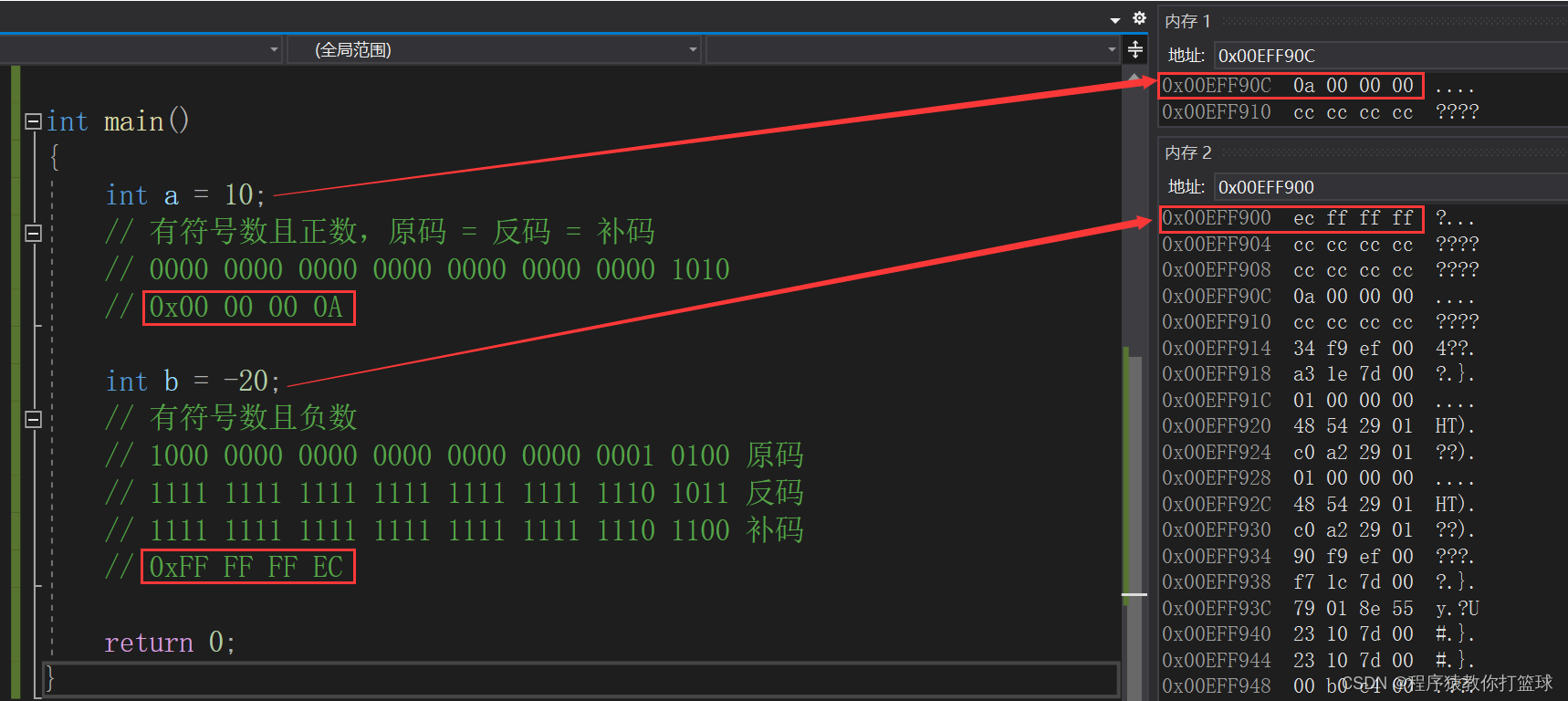
上图我们可以看到,有符号位在内存中的存储跟我们上述所说的是一样的,那么为什么内存看到的是反过来的呢,因为我们这里是小端存储(后面讲),那么我们的无符号数是没有符号位的,并且原码反码补码都相等。
那么负数补码如何转换成原码呢?
- 方法一:补码-1然后除符号位按位取反
- 方法二:符号位不变按位取反然后加1
我们来看一个unsigend的例子:
定义一个变量: unsigned int b = -10; 这个代码有问题吗?没有问题!!!
我们知道,定义一个变量运行时就是开辟一个空间,先有空间才有内容,我们现在将 -10转化为二进制补码:1111 1111 1111 1111 1111 1111 1111 0110 在我们数据保存到空间的时候,数据已经被转化成二进制了!所以整型在存储的时候,空间是不关心存什么内容,他只需要把这一串二进制存储起来就行,那么我们 unsigned int 这个变量类型在什么时候起效果呢?在我们读取的时候起效果,也就是说,类型决定了如何解释空间内部保存的二进制序列!
我们来看代码:
第一个printf 就是在实际输出的时候以unsigned int 来解释对应的空间的
第二个printf 就是在实际输出的时候以signed int 来解释对应空间的
所以我们就要来探讨变量存和取的过程:
变量存:字面数据必须先转成补码,再放入空间当中,所以,所谓符号位,完全是看数据本身是否携带+-号,和变量是否有符号无关!
变量取:取数据一定要先看变量本身类型,然后才决定要不要看最高符号位,如果不需要,直接二进制转十进制,如果需要则需转成原码,然后才能识别(当然符号位在哪里,我们要明确大小端)。
同过上面的讲解,可能小伙伴还有一个问题,为什么计算机中要使用补码呢?
在计算机系统中,数值一律用补码来表示和存储。原因在于,使用补码,可以将符号位和数值域统一处理; 同 时,加法和减法也可以统一处理(CPU只有加法器)。此外,补码与原码相互转换,其运算过程是相同的,不 需要额外的硬件电路。

🎱 5、大小端存储
要了解大小端,我们先抛出一个问题,见代码:
为什么a变量存在内存中是反过来的呢?这里我们就要引入大小端的概念了!
如何理解大小端呢?
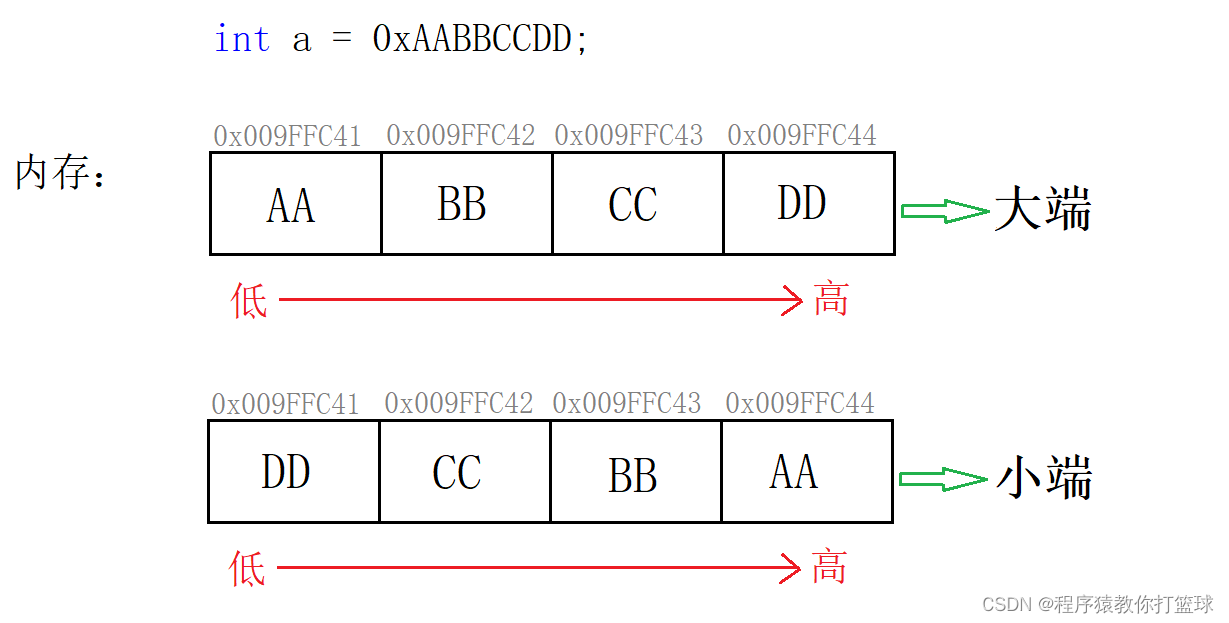
我们知道内存是连续的存储空间,有高地址和低地址之分,那么我们的数据也要按照字节为单位划分,数据是有高权值位和低权值位的区别的,比如 0xAA BB CC DD,AA的权值就大于DD的权值,那么大小端是如何存放的呢?(目前基本都是小端存储)
- 大端:按照字节为单位,低权值位数据存储在高地址处,就叫做大端
- 小端:按照字节为单位,低权值位数据存储再低地址处,就叫做小端
图解:
所以,数据取的时候不仅仅要考虑原反补,还要考虑大小端,如何存就如何取。

以上就是我们本期的内容了,如果有疑问可以随时问我哦,我们下期见!
上半场打不好没关系,还有下半场!🏀


