只要5秒就能“克隆”本人语音!美玉学姐不再查寝,而是吃起了桃桃丨开源
博雯 萧箫 发自 凹非寺
量子位 报道 | 公众号 QbitAI
现在,AI已经能克隆任意人的声音了!
比如,前一秒的美玉学姐还在宿舍查寝:
后一秒就打算吃个桃桃:
简直就是鬼畜区的福利啊!
(像我们后面就试着白学了一下华强买瓜 )
)
此外,还有正经的方言版,比如台湾腔就完全冇问题:
这就是GitHub博主Vega最新的语音克隆项目MockingBird,能够在5秒之内克隆任意中文语音,并用这一音色合成新的说话内容。
这一模型短短2个月就狂揽7.6k星,更是一度登上GitHub趋势榜第一:
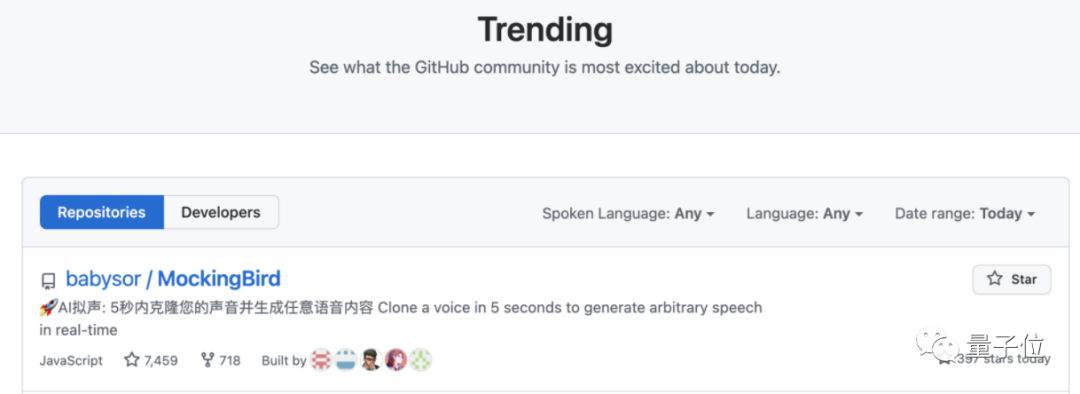
社区里更是涌入了无数人求预训练模型和保姆级教程。
于是,我们也借此机会试了试这个“柯南模拟器”,并与开发者本人进行了一次深♂入交谈。
5秒合成一段语音,效果如何?
我们先选用一位路人小姐姐的声音,试着让他像华强一样,来一句“这瓜保熟吗”,效果如何?

嗯,果然小姐姐的语气没有华强的凶猛,不过也准确还原了本人的音色:
这不禁让我们有了一些大胆的想法。
试试只用一声喊叫的语音(甚至小于5s),让AI直接输出一段“我从未见过如此……之人”:
从视频中来听,虽然有一些破碎,不过整体效果还是可以的。
至于诸葛村夫本人,我们反向操作,让他吃起了桃桃:
有生之年,竟然能听见诸葛村夫撒娇……
输出效果现在看来不错,那么输出语音质量究竟如何呢?
我们决定用开头台湾腔生成的语音作为样本,再次合成语音试试。

模型再次顺利地合成了“我要买一百个瓜”,看来合成的音频质量效果也是不错的:
除此之外,我们还试了一下其他文本,基本效果都挺OK。
但我们发现,如果采用强烈情绪/腔调的语音(电影、电视剧中的演员语音效果),效果就会和预想中有点差别。
例如,在某位同事的强烈建议下,我们拜托作者用最新的预训练模型白学了一把华强:
嗯?原本的黑社会混混,真就变成了一位内向白学家……
其实,为了防止不法分子利用,作者并没有上传最新的模型。
不过,现在几个预训练版本的音色模仿效果都已经挺不错了,你也可以上手调戏一下这个AI。
已有预训练模型,可直接试玩
那么,这个AI模型究竟要怎么用呢?
作者表示,模型支持在Windows、Linux系统上运行,在苹果系统M1版上也有成功运行案例。
但我们偏偏用双核英特尔Core i3(1.1GHz)的苹果系统试着运行了一下……

事实证明,Mac系统也可以直接将调教好的预训练模型拿来用!
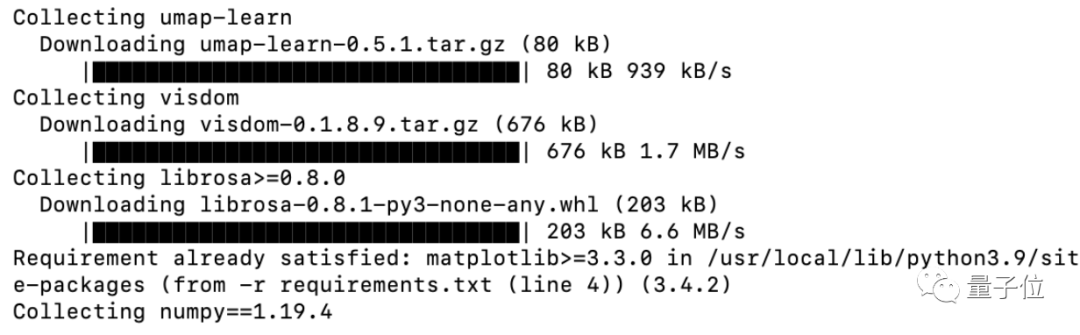
由于模型框架用的是PyTorch,需要提前安装一下环境,这里用的的版本是Python3.9.4和PyTorch1.9.1,再用pip安装一下ffmpeg、webrtcvad。
然后,下载MockingBird下requirements.txt中的必要包:
pip install -r requirements.txt运行情况如图:
成功后,下载预训练模型,替换掉MockingBird中的相关文件夹:

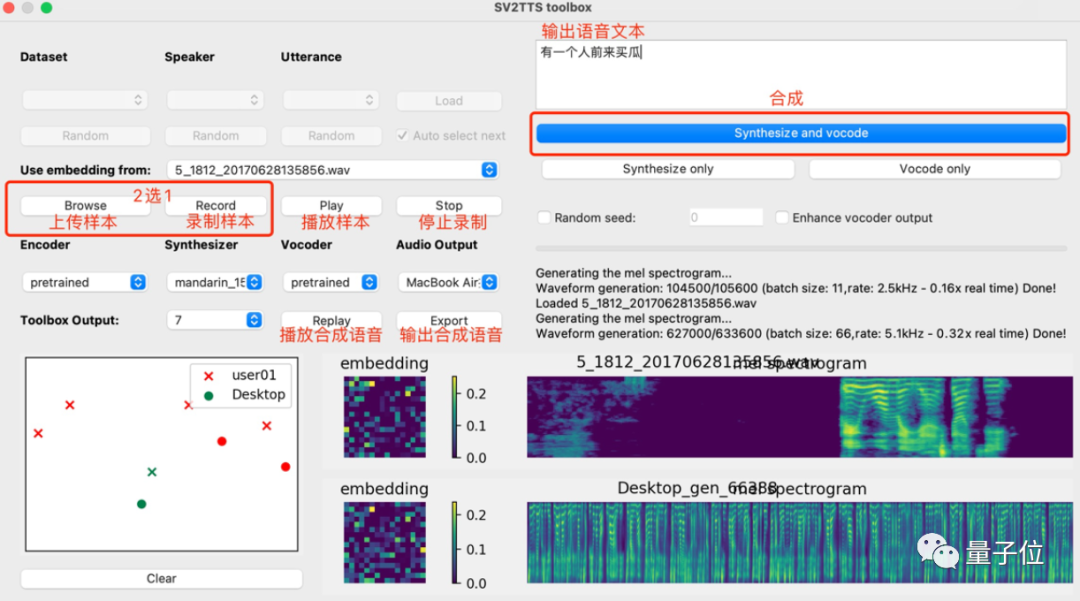
再启动python demo_toolbox.py,当你看到这个界面的时候,就说明运行成功了:
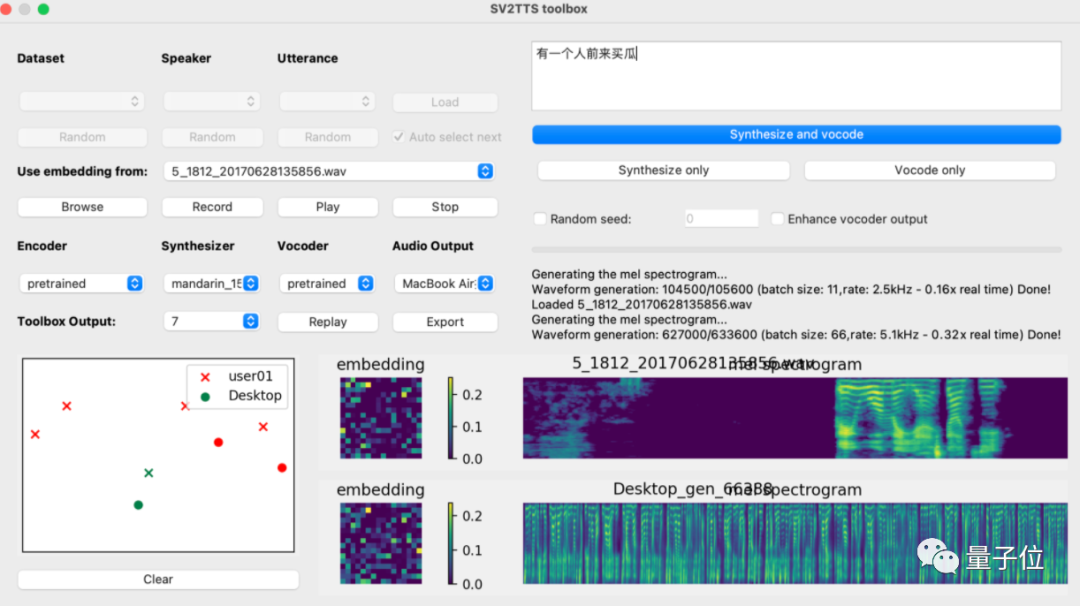
这个时候,就可以上传你想要“克隆”的对象的声音。(支持wav格式,噪音等干扰尽可能低)
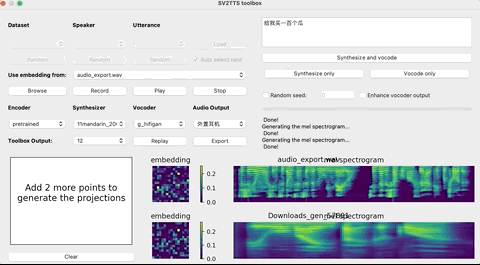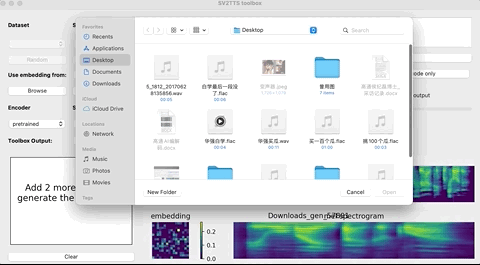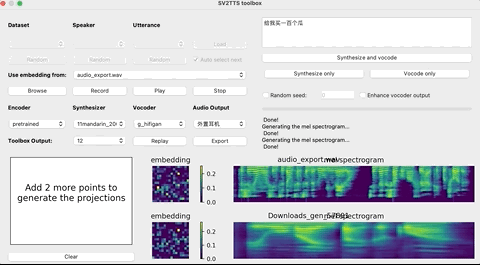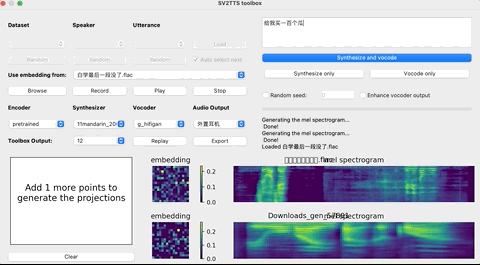
上传完录音后,选择需要的合成器、声码器,然后在文本框中输出想要合成的语音文本,等待一会儿。
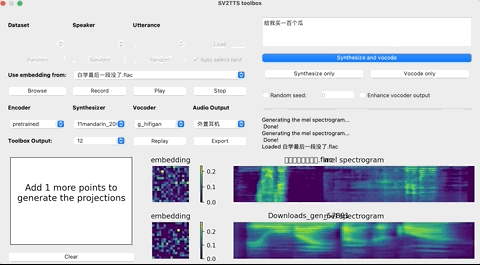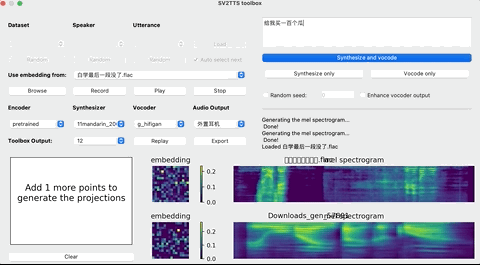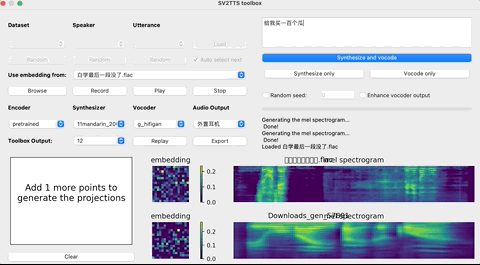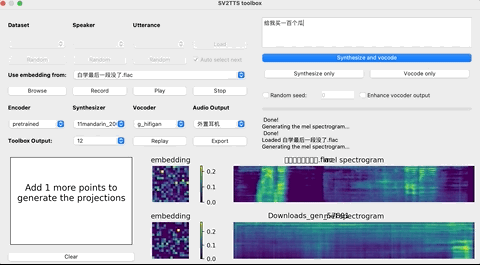
点击Replay,就能听见合成的声音了!
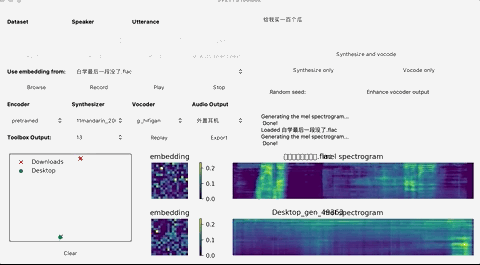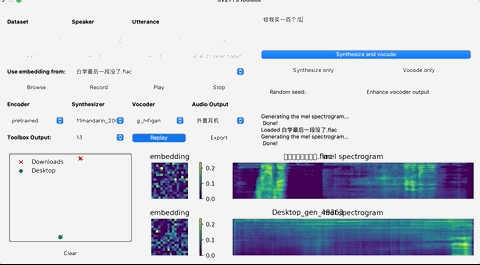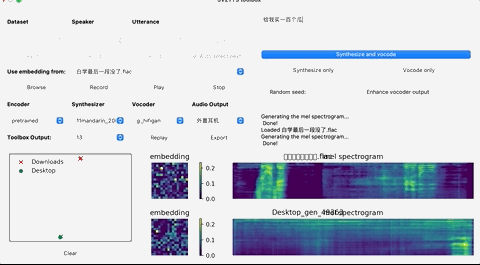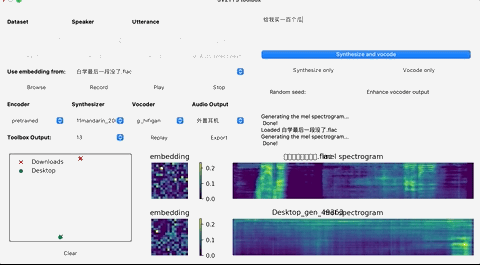
如果想要输出的话,点击Export输出就行,整个界面的基本操作如下:
我们在这台电脑上尝试发现,10秒以内的样本+10个字语音文本,合成的时间比较快,如果vocoder采用Hifi-GAN的话,几乎一秒就能训练完成。
当然,如果你想用自己的数据集和方法训练一个语音克隆模型、或是想训练声码器(vocoder),也可以查看项目中的相关说明(文末附项目地址)。
据作者表示,当出现注意力模型、同时loss(损失)足够低的时候,就表明训练完成了:
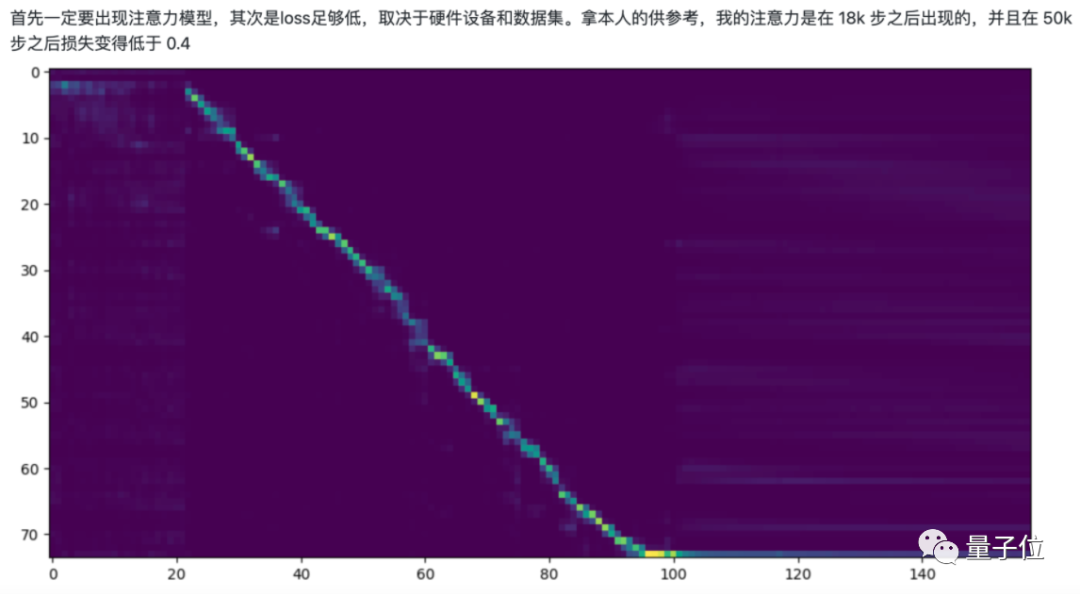
“中文版”SV2TTS模型已开源
那么这个柯南变声器……哦不,实时语音克隆是如何实现的呢?
简单来说,这是一个语音到文本再到语音的任务。
要完成这个任务,则需要以下三个元件组成的一种模型结构:
-
说话人编码器(Speaker encoder)
-
合成器(Synthesizer)
-
声码器(Vocoder)

首先,由说话人编码器(绿色部分)来提取指定音频的特征向量,相当于学习说话人的音色。
具体来说,是利用一个高度可扩展的神经网络框架,将从语料中计算得到的对数谱图帧序列映射到一个固定维度的嵌入向量。
在得到这种数字化的音频之后,我们就进入了传统的TTS(Text-to-Speech)环节:
也就是将上述的说话人的语音特征融入指定文本,产生对应的语音频谱。
这一部分的合成器(蓝色部分)采用典型的解码器-编码器结构,中间还加了注意力机制。
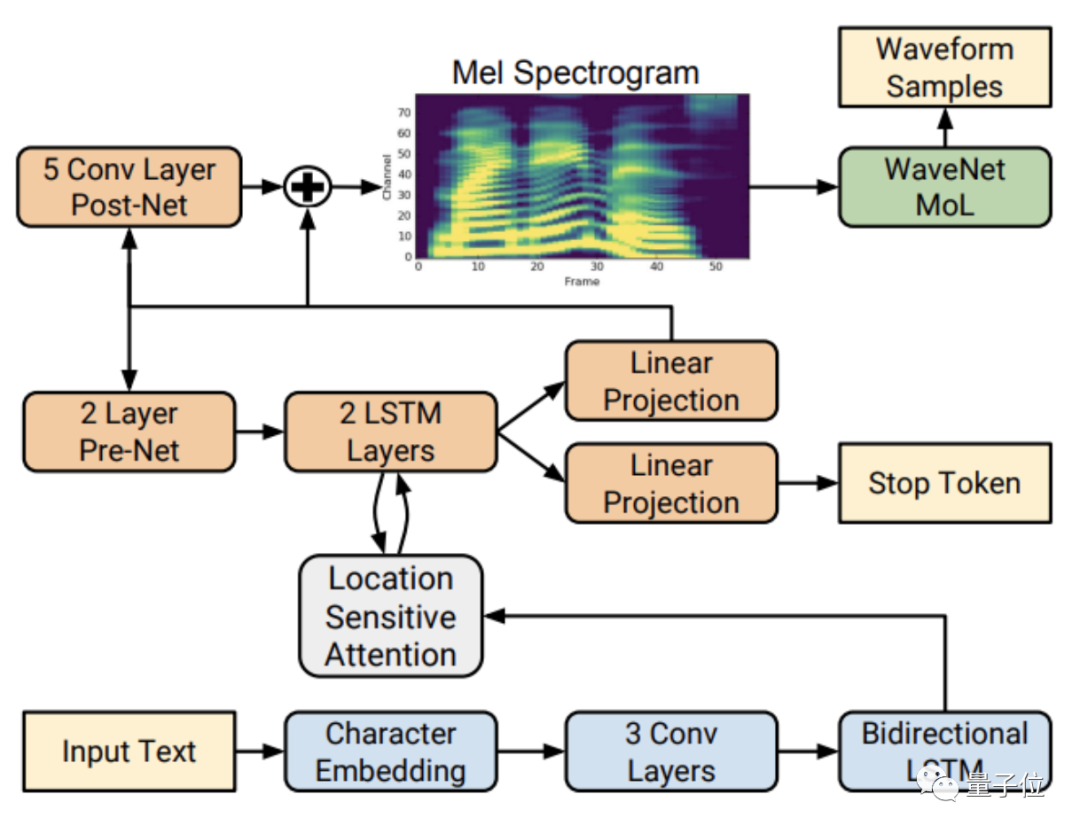
再以梅尔频谱(Mel-Spectrogram)作为中间变量,将合成器中生成的语音频谱传到声码器(红色部分)中。
在这里使用深度自回归模型WaveNet作为声码器,用频谱生成最终的语音。
其实,上述流程基本都来自谷歌在2019年开发的框架SV2TTS。
当时的预训练模型是英文的,但也可以在不同的数据集上单独训练,以支持另一种语言。
开发者对“开发另一种语言的模型”给出的建议是:
1、一个足够大的无标注数据集(1000人/1000小时以上),用来训练第一部分Speaker encoder。
2、一个相对小的有标注数据集(300-500小时),用来训练第二、三部分Synthesizer和Vocoder。

这正是Vega在“汉化”这一模型时所遇到的最大的困难。
他提到,中文多说话人的开源数据集比较少,质量也没达到预想效果,经常训练难以甚至无法收敛。
在多方搜寻之后,他最终确定了三个中文语音数据集:aidatatang_200zh、magicdata、aishell3。
其中aidatatang_200zh包含了600人200小时的语音数据,magicdata包含1080人755小时的语音数据,aishell3则有85小时的88035句中文语音数据,
而针对难以收敛的问题,Vega在训练早期加入了Guided Attention以提高收敛速度,再进行多个数据集混合训练的方式,提高中文版的训练成功率。
在不修改模型的核心架构的基础上,他又引入了HiFi-GAN,使vocoder的推理速度比原先的WaveRNN两到三倍,基本可以在5秒内输出克隆语音。
“希望更多人一起来玩”
那么这个项目背后还有哪些故事呢?
我们与作者Vega聊了聊。
其实在问到开发这一项目的初衷时,他说:最开始只是出于兴趣。
业内已经成熟的TTS技术、可以实时克隆语音的SV2TTS、还有近期的小冰发布会,这都使Vega对语音合成产生了极大的兴趣。
因此,一方面想要尝试改进一下这类学术项目的可玩性,同时也抱着国内开发者可以一起探索更多中文语音合成的愿景,他就开始利用业余时间进行开发。
但这一完全个人的项目在初期就收到了意想不到的热度。
不仅标星数有7.6k,社区中也涌现出了大量新的改进反馈,包括不少模型改进建议和项目优化点。
这使得这一项目越来越完整。
现在,Vega已经把这次的经验分享给做西班牙语等其他外语的开发者,未来也可能会把相关成果补充到现在项目中。
他也提到,这一模型现在已经有了很多潜在的商业化场景。
比如为不想录音或懒得补录的音视频制作者们合成语音,或者帮助主播给打赏DD们发送(合成的)个性语音等等。
在交谈中,Vega也向我们透露了他正在拓展的方向。
比如跨语言的语音合成,能够让实时翻译器最终实现说话人音色的翻译,或帮助面向多地区发行的影视作品中的配音转化语种。
当然,现阶段暂时不会去落地太具体的应用,而是把接口和基础能力做好,让社区其他开发者去实现多个有价值的场景。
Vega笑道,在应用这方面主要是广大网友们在探索,他打辅助。
当然,他也提到:
项目现在还是处在一个萌芽阶段,要在实时性、泛性、效果中找到最佳效果还面临着许多困难。
比如由于模型逻辑会根据标点符号做断句成多段文字输入,独立并行处理,因此文本的标点符号会影响语音合成的质量。
还有情绪化的语气、方言口音、自然停顿等等,也是模型现在面临的问题。
所以,他希望有更多的开发者和爱好者一起加速这个项目的演进。
而关于自己,Vega表示,他在16年就从北美Facebook回国创业,目前正在BAT工作。
他现阶段的工作项目内容包括提供更低成本的沉浸式AI语音互动,主要方向与AI、云原生和元宇宙方向探索比较一致。
而这也是他个人最大的业余爱好。
在最后,Vega表示:
我们可以期盼未来,在元宇宙等虚拟世界里面,跟我们互动的不再是念固定台词的NPC,而是一些生动的AI人物,以及一个熟悉或者你想象应该有的声音在对话。
项目地址:
https://github.com/babysor/MockingBird/blob/main/README-CN.md
训练者教程:
https://vaj2fgg8yn.feishu.cn/docs/doccn7kAbr3SJz0KM0SIDJ0Xnhd
参考链接:
[1]https://www.bilibili.com/video/BV1sA411P7wM/
[2]https://www.bilibili.com/video/BV1uh411B7AD/
[3]https://github.com/CorentinJ/Real-Time-Voice-Cloning/issues/30

