【数据结构】二叉树 —— 遍历二叉树 + 递归的分治(链式存储)
文章目录
- 前言:
- 1. 二叉树的四种遍历结构:
-
-
- 1.1 二叉树结构划分:
- 1.2 二叉树的遍历结构:
-
- 2.递归的分治思想:
- 3. 链式二叉树的创建:(BinaryTree)
-
- 具体函数实现:
-
- 3.1 创建二叉树
- 3.2 前序遍历
- 3.3 中序 / 后序遍历
- 3.4 树中结点个的数
- 3.5 叶子结点个数
- 3.6 第K层的结点个数
- 3.7 求二叉树的深度
- 3.8 查找二叉树值为x的结点
- 测试函数:
- 总结:
前言:
学习二叉树结构,最简单的方式就是遍历。所谓二叉树遍历(Traversal)是按照某种特定的规则,依次对二叉树中的节点进行相应的操作,并且每个节点只操作一次。 访问结点所做的操作依赖于具体的应用问题。 遍历是二叉树上最重要的运算之一,也是二叉树上进行其它运算的基础。
1. 二叉树的四种遍历结构:
1.1 二叉树结构划分:
任何二叉树都能分成三个结构:
- 根,左子树,右子树
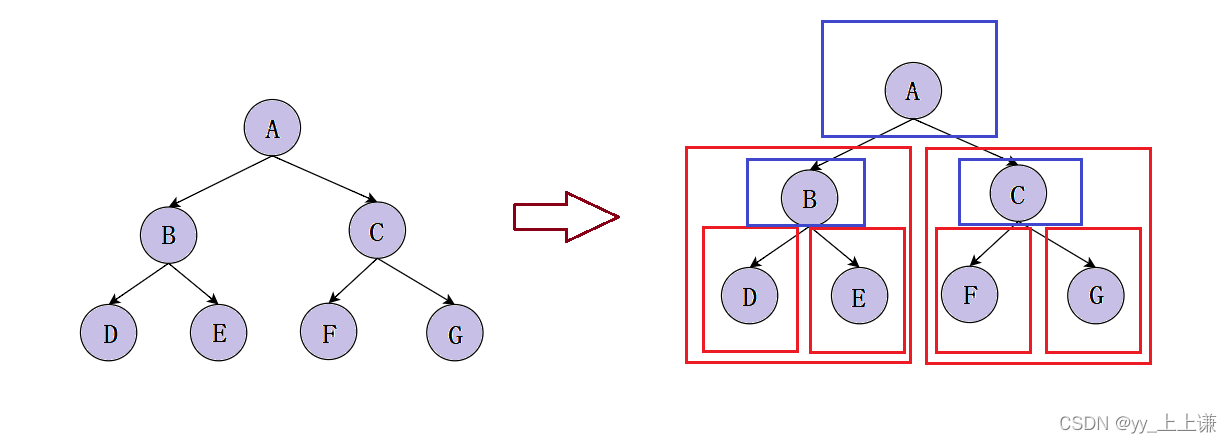
从概念中可以看出,二叉树定义是递归式的,因此后序基本操作中基本都是按照该概念实现的。
1.2 二叉树的遍历结构:
二叉树的四种遍历结构:
-
前序遍历 : - (先根遍历):根节点,左子树,右子树
-
中序遍历 : 左子树, 根节点, 右子树
-
后序遍历 : - (后跟遍历): 左子树,右子树,根节点
-
层序遍历 : 一层一层遍历


2.递归的分治思想:
-
递归调用自己建立栈帧
-
执行指令,建立栈帧,局部变量就存在栈帧里面的
-
二叉树复杂的原因是它是双路递归
分治: (分而治之) -
把复杂的问题,分成更小规模的子问题,子问题再分成更小规模的子问题。。。
-
直到子问题不可再分割,直接能出结果。
3. 链式二叉树的创建:(BinaryTree)
具体函数实现:
typedef int BTDataType;typedef struct BinaryTreeNode{struct BinaryTreeNode* left;struct BinaryTreeNode* right;BTDataType data;}BTNode;//创建新结点BTNode* BuyBTNode(BTDataType x){BTNode* node = (BTNode*)malloc(sizeof(BTNode));if (node == NULL){exit(-1);}node->data = x;node->left = node->right = NULL;return node;}3.1 创建二叉树
创建完之后的二叉树如图所示:
//创建二叉树BTNode* CreatBinaryTree(){BTNode* node1 = BuyBTNode(1);BTNode* node2 = BuyBTNode(2);BTNode* node3 = BuyBTNode(3);BTNode* node4 = BuyBTNode(4);BTNode* node5 = BuyBTNode(5);BTNode* node6 = BuyBTNode(6);node1->left = node2;node1->right = node4;node2->left = node3;node4->left = node5;node4->right = node6;return node1;}3.2 前序遍历
//前序遍历void PrevOrder(BTNode* root){if (root == NULL){printf("NULL ");return;}printf("%d ", root->data);PrevOrder(root->left);PrevOrder(root->right);}- 前序遍历的顺序是:根,左子树,右子树,
- 再从子树中继续分:根,左子树,右子树
- ……
- 直到不可再分为止,这就是递归的分治思想。
递归展开图如下:

3.3 中序 / 后序遍历
中序遍历和后序遍历与前序遍历极其相似,根据其特定的遍历顺序依次递归即可。
//中序遍历void InOrder(BTNode* root){if (root == NULL){printf("NULL ");return;}InOrder(root->left);printf("%d ", root->data);InOrder(root->right);}//后续遍历void BackOrder(BTNode* root){if (root == NULL){printf("NULL ");return;}BackOrder(root->left);BackOrder(root->right);printf("%d ", root->data);}3.4 树中结点个的数
计算二叉树中结点的个数
- 设置一个变量用来计数
- 但是这个计数变量不能设为局部变量
- 因为每次递归依次,都会创建一个新的栈帧,每个栈帧里面都会创建一个新的计数变量
- 这样就不能起到计数的作用
- 将计数变量设置成静态或全区变量
- 设置成静态变量,但是这都需要返回值
- 全局变量虽然很方便但是,但是还是存在问题,会有线程安全的问题,这个以后linux学就知道了
- 多次调用的时候会出现累加的现象
- 运用指针,传计数变量的地址
- 这种做法是最安全的
- 但是还是存在多次调用出现累加的现象
//树中结点的个数 - 设置全局变量int count = 0;void BTreeSize(BTNode* root){if (root == NULL){return;}count++;BTreeSize(root->left);BTreeSize(root->right);}//最安全的方式 - 传地址//思想: 遍历 + 计数void BTreeSize(BTNode* root, int* pCount){if (root == NULL){return;}(*pCount)++;BTreeSize(root->left, pCount);BTreeSize(root->right, pCount);}新思路:用递归的分治的思想
- 计算二叉树结点的总个数
- 那么可以理解成,总结点个数 = 左子树结点数目 + 右子树结点数目 + 根结点
- 然后子树再继续分,左子树结点个数 = 左子树根节点左子树结点数目 + 左子树根节点右子树结点数目 + 左子树根节点
- 右子树结点个数 = 右子树根节点右子树结点数目 + 右子树根节点右子树结点数目 + 右子树根节点
- 一直分到左右子树为叶子结点的时候,再往回反。

//结点数目 - 新思路int BTreeSize(BTNode* root){return root == NULL ? 0 : BTreeSize(root->left) + BTreeSize(root->right) + 1;}3.5 叶子结点个数
- 分治的思想,整个树的叶子结点 = 左子树叶子结点 + 右子树叶子结点
- 在子树中继续分,左子树叶子结点 + 右子树叶子结点
- 直到分成最小问题之后不可再分,再一层一层往回反
//计算叶子结点的个数int BTreeLeafSize(BTNode* root){if (root == NULL){return 0;}if (root->left == NULL && root->right == NULL){return 1;}return BTreeLeafSize(root->left) + BTreeLeafSize(root->right);}3.6 第K层的结点个数
分治的思想:
- 空树,返回0
- 非空,且k == 1,返回1
- 非空,且k > 1,转换成求: 左子树k - 1层结点个数 + 右子树k - 1层结点个数
- 一直将问题分解
- 直到找到最小规模子问题,依次往上回

//第k层的结点的个数, k >= 1int BTreeKLevelSize(BTNode* root, int k){assert(k >= 1);if (root == NULL){return 0;}if (k == 1){return 1;}return BTreeKLevelSize(root->left, k - 1) ++BTreeKLevelSize(root->right, k - 1);3.7 求二叉树的深度
分治的思想:
- 左子树高度 和 右子树高度 比较
- 大的那个 + 1
- 一直将问题分解
- 直到找到最小规模子问题,依次往上返回

//求二叉树的深度(高度)int BTreeDepth(BTNode* root){if (root == NULL){return 0;}int leftDepth = BTreeDepth(root->left);int rightDepth = BTreeDepth(root->right);return leftDepth > rightDepth ? leftDepth + 1 : rightDepth + 1;}3.8 查找二叉树值为x的结点
分治的思想:
- 现在左子树中找,找到返回地址,找不到NULL,再去右树中找
- 再在子树中分子树的左右子树找
- 一直将问题分解
- 直到找到最小规模子问题
- 找到:依次往上返回找到等于该值的结点的地址
- 找不到:依次向上返回NULL
递归展开图如下:

//查找二叉树值为x的结点BTNode* BTreeFind(BTNode* root, BTDataType x){if (root == NULL){return NULL;}if (root->data == x){return root;}BTNode* ret1 = BTreeFind(root->left, x);if (ret1){return ret1;}BTNode* ret2 = BTreeFind(root->right, x);if (ret2){return ret2;}return NULL;}测试函数:
int main(){BTNode* tree = CreatBinaryTree();PrevOrder(tree);printf("\n");InOrder(tree);printf("\n");BackOrder(tree);printf("\n");/*count = 0;BTreeSize(tree);printf("size:%d\n",count);count = 0;BTreeSize(tree);printf("size:%d\n", count);*//*int count1 = 0;BTreeSize(tree, &count1);printf("size:%d\n", count1);int count2 = 0;BTreeSize(tree, &count2);printf("size:%d\n", count2);*/printf("size:%d\n", BTreeSize(tree));printf("Leaf size:%d\n", BTreeLeafSize(tree));printf("Depth size:%d\n", BTreeDepth(tree));printf("BTree 3 level size:%d\n", BTreeKLevelSize(tree, 3));for (int i = 1; i <= 7; i++){printf("Find: %d,%p\n", i, BTreeFind(tree, i));}return 0;}总结:
- 二叉树复杂的原因是它是双路递归
- 普通二叉树的增删查改没意义
- 用链式二叉树增删查改价值不大了 - 那么复杂的结构
- 二叉树的遍历等操作的学习,能够更好地控制它的结构
- 为后续学习更复杂的(平衡)搜索二叉树打基础
- 很多二叉树OJ算法题,都出在普通二叉树上
- 后续衍生出来的问题:平衡搜索二叉树:AVL树,红黑树
- B树 B+树 B*树 - 高阶数据结构