Pytorch-深度学习笔记
文章目录
- Pytorch-深度学习笔记
Pytorch-深度学习笔记
学习链接:
《PyTorch深度学习实践》完结合集
LEARNING PYTORCH WITH EXAMPLES
环境搭建
Pytorch
-
确定cuda版本
- 打开pytorch官网,根据需要确定下载指令

-
复制,在conda里下载即可
-
验证
import torch
查看pytorch是否能使用cuda加速
查看cuda是否安装正确并能被Pytorch检测到
import torchprint(torch.cuda.is_available())看Pytorch能不能调用cuda加速
a = torch.Tensor(5, 3)a = a.cuda()print(a)Pytorch将模型和张量加载到GPU
方法1
# 如果GPU可用,将模型和张量加载到GPU上if torch.cuda.is_available(): model = model.cuda() x = x.cuda() y = y.cuda()方法2
# 分配到的GPU或CPUdevice=torch.device("cuda:0" if torch.cuda.is_available() else "cpu")# 将模型加到GPUmodel=model.to(device)# 将张量加到GPUx=x.to(device)y=y.to(device)Overview
课程链接:01.Overview
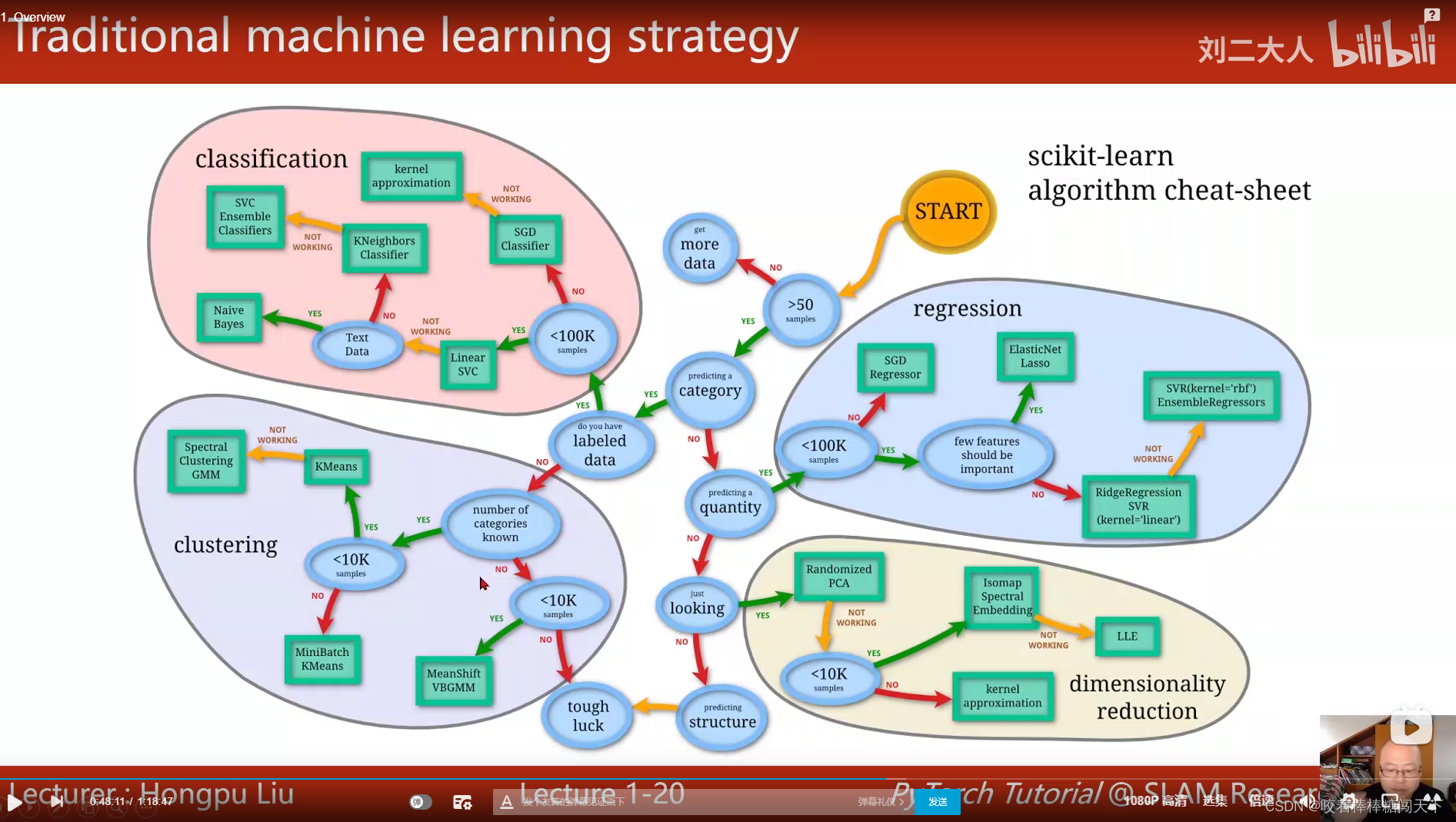
传统:Features与Mapping from features是分开的
Deeplearning:Features与Mapping from features是一起的,因此被称为End to End。
传统策略:分类、聚类、回归、降维
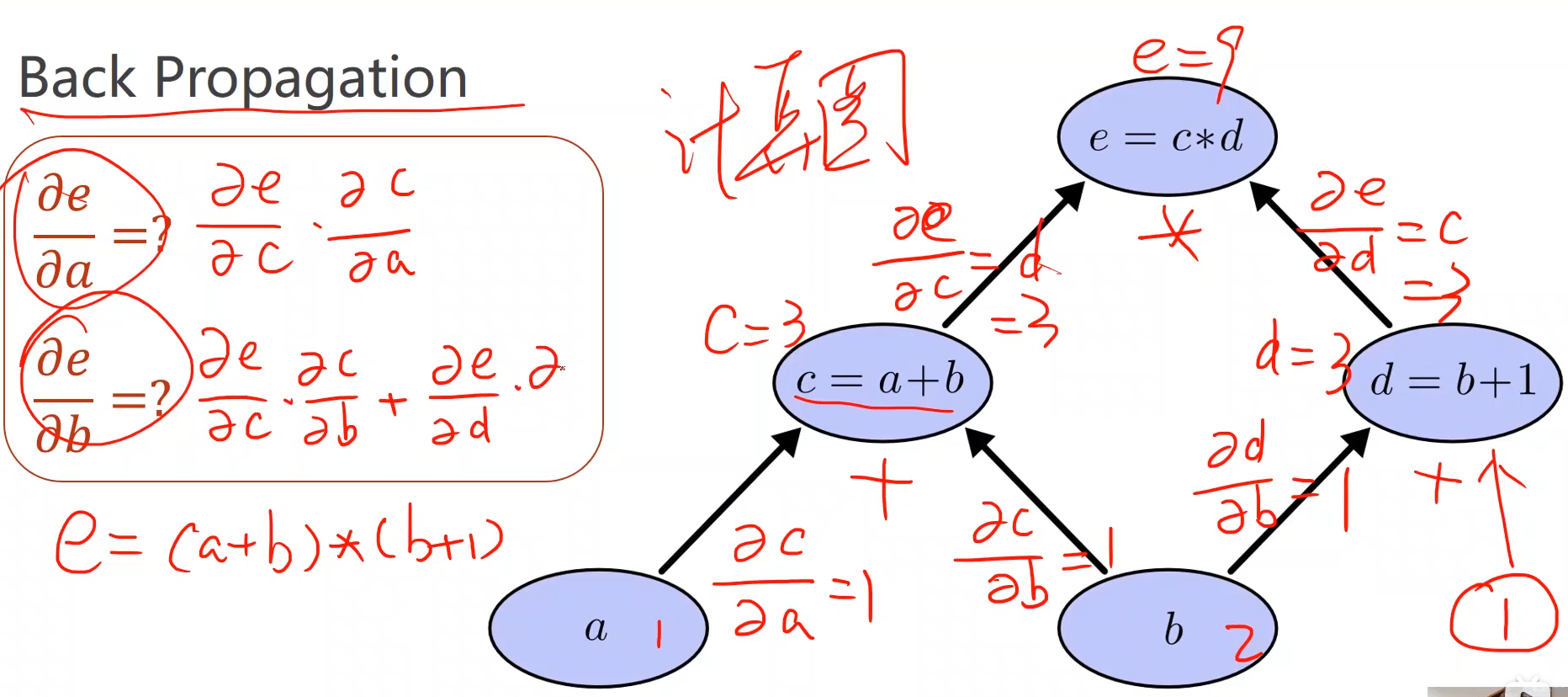
反向传播的核心:计算图
将路径上的偏导进行相乘—>求导链式法则—>误差的反向传播
近些年来的进展:算法、数据集、算力
TensorFlow: static graph 静态图,灵活性低
PyTorch: Dynamic graph 动态图
线性模型
课程链接:02.线性模型
学习深度学习:
-
DataSet
-
Model
-
Training
-
Infering
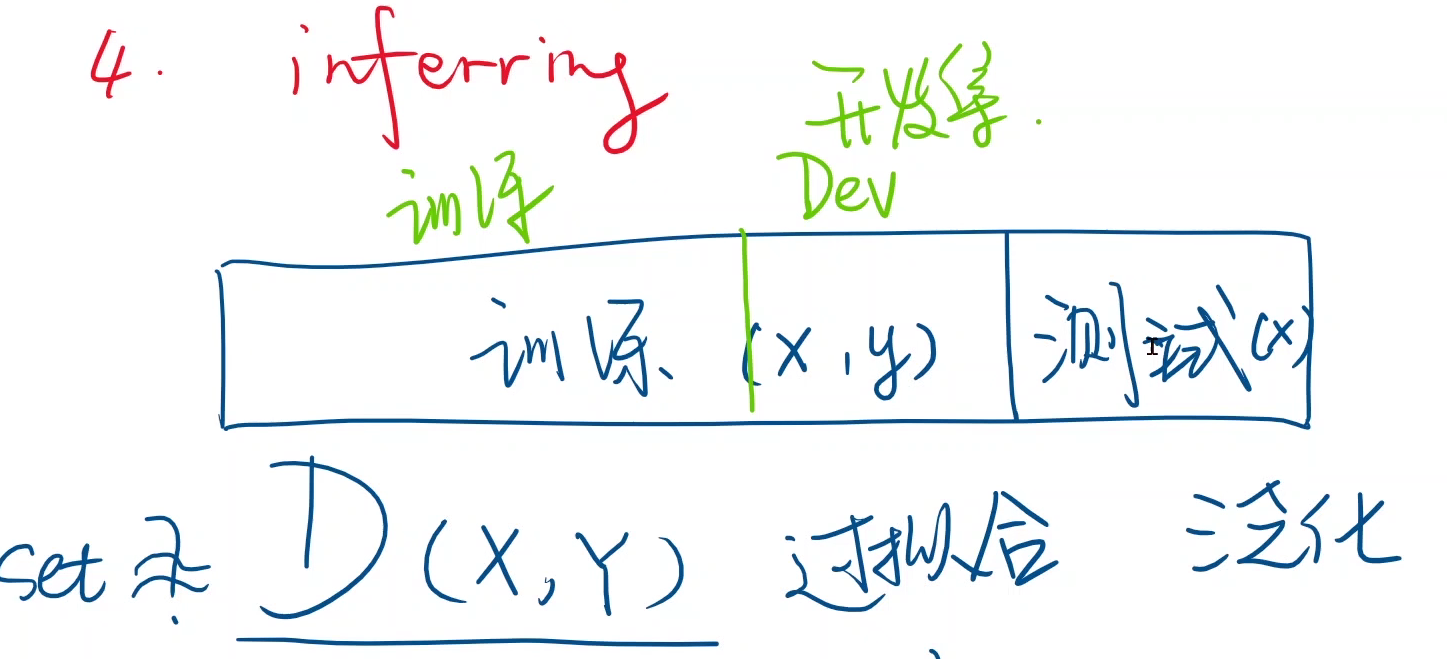
为了评估模型,需要吧训练集分为两部分:训练集、开发集
损失函数常用:MSE(Mean Square Error)
M S E : c o s t =1N ∑ n = 1 N (y ^ n− y n) 2 MSE: cost=\frac{1}{N} \sum_{n=1}^{N} \left(\hat{y}_{n}-y_{n}\right)^{2} MSE:cost=N1n=1∑N(y^n−yn)2
vistom 可视化绘图 提供web服务
code
线性模型
import numpy as npimport matplotlib.pyplot as plt x_data = [1.0, 2.0, 3.0]y_data = [2.0, 4.0, 6.0] def forward(x): return x*w def loss(x, y): y_pred = forward(x) return (y_pred - y)2 # 穷举法w_list = []mse_list = []for w in np.arange(0.0, 4.1, 0.1): print("w=", w) l_sum = 0 for x_val, y_val in zip(x_data, y_data): y_pred_val = forward(x_val) loss_val = loss(x_val, y_val) l_sum += loss_val print('\t', x_val, y_val, y_pred_val, loss_val) print('MSE=', l_sum/3) w_list.append(w) mse_list.append(l_sum/3) plt.plot(w_list,mse_list)plt.ylabel('Loss')plt.xlabel('w')plt.show()实现线性模型(y=wx+b)并输出loss的3D图像
import numpy as npimport matplotlib.pyplot as pltfrom mpl_toolkits.mplot3d import Axes3D#这里设函数为y=3x+2x_data = [1.0,2.0,3.0]y_data = [5.0,8.0,11.0]def forward(x): return x * w + bdef loss(x,y): y_pred = forward(x) return (y_pred-y)*(y_pred-y)mse_list = []W=np.arange(0.0,4.1,0.1)B=np.arange(0.0,4.1,0.1)[w,b]=np.meshgrid(W,B)l_sum = 0for x_val, y_val in zip(x_data, y_data): # zip:打包为元组的列表 y_pred_val = forward(x_val) print(y_pred_val) loss_val = loss(x_val, y_val) l_sum += loss_valfig = plt.figure()ax = Axes3D(fig)ax.plot_surface(w, b, l_sum/3)plt.show()梯度下降算法
课程链接:03.梯度下降算法
导数:函数增加的方向
Gradient:∂cost ∂ω \frac{\partial cost}{\partial \omega} ∂ω∂cost Update: ω = ω − α ∂cost ∂ω \omega=\omega-\alpha\frac{\partial cost}{\partial \omega} ω=ω−α∂ω∂cost ( α \alpha α:学习率)
核心思想:贪心,只关注目前的最优结果,非凸函数里容易陷入局部最优
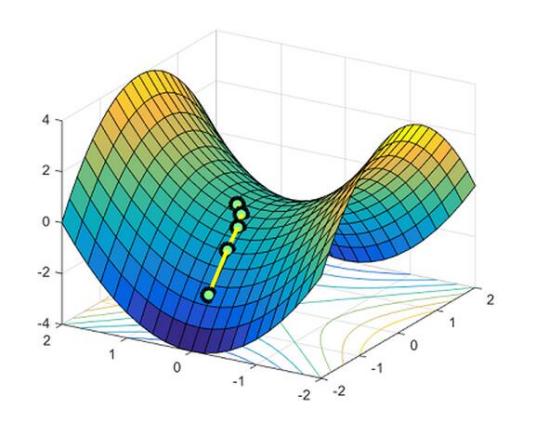
不过在深度神经网络损失函数当中,并没有那么多局部最优点,很难陷入。不过有鞍点(梯度为0)。到达鞍点后无法继续迭代—>陷入鞍点。
局部最优并不是最大的问题,鞍点才是最大的问题。
code
梯度下降
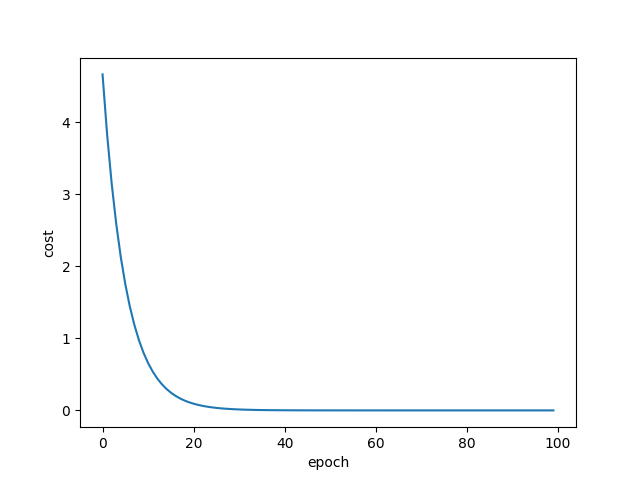
import matplotlib.pyplot as plt # prepare the training setx_data = [1.0, 2.0, 3.0]y_data = [2.0, 4.0, 6.0] # initial guess of weight w = 1.0 # define the model linear model y = w*xdef forward(x): return x*w #define the cost function MSE def cost(xs, ys): cost = 0 for x, y in zip(xs,ys): y_pred = forward(x) cost += (y_pred - y)2 return cost / len(xs) # define the gradient function gddef gradient(xs,ys): grad = 0 for x, y in zip(xs,ys): grad += 2*x*(x*w - y) return grad / len(xs) epoch_list = []cost_list = []print('predict (before training)', 4, forward(4))for epoch in range(100): cost_val = cost(x_data, y_data) grad_val = gradient(x_data, y_data) w-= 0.01 * grad_val # 0.01 learning rate print('epoch:', epoch, 'w=', w, 'loss=', cost_val) epoch_list.append(epoch) cost_list.append(cost_val) print('predict (after training)', 4, forward(4))plt.plot(epoch_list,cost_list)plt.ylabel('cost')plt.xlabel('epoch')plt.show() result
epoch: 98 w= 1.9999387202080534 loss= 2.131797981222471e-08epoch: 99 w= 1.9999444396553017 loss= 1.752432687141379e-08predict (after training) 4 7.999777758621207损失值曲线,如下图:
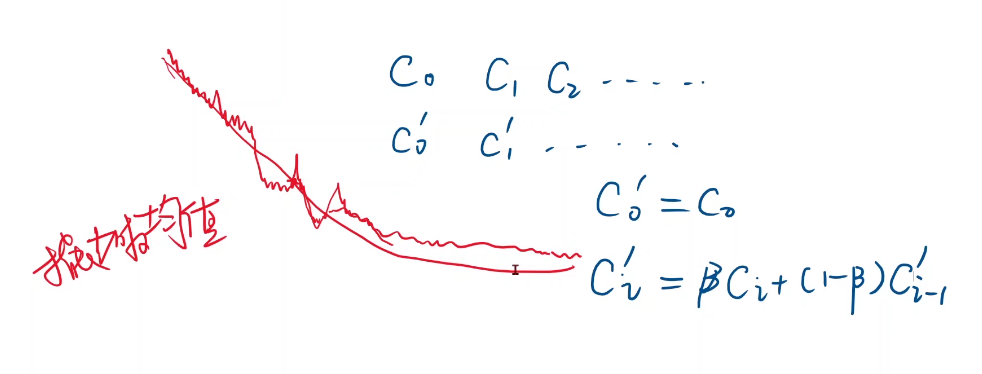
实际上训练很少有平滑的cost function,可以使用指数加权均值的方式来进行平滑
C 0 ′ = C 0 C i ′ = β C i + ( 1 − β ) C i − 1 ′ \begin{aligned} &C_{0}^{\prime}=C_{0} \\ &C_{i}^{\prime}=\beta C_{i}+(1-\beta) C_{i-1}^{\prime} \end{aligned} C0′=C0Ci′=βCi+(1−β)Ci−1′
如果cost function最后发散了,说明本次学习失败。常见的原因是:学习率太大

现在常用随机梯度下降,使用单个样本的损失函数来对权重求导,并更新
原因:在鞍点处使用一个样本的情况,随机噪声可能会把我们向前推动,就有可能跨越鞍点。
code
随机梯度下降(SGD)
import matplotlib.pyplot as plt x_data = [1.0, 2.0, 3.0]y_data = [2.0, 4.0, 6.0] w = 1.0 def forward(x): return x*w # calculate loss functiondef loss(x, y): y_pred = forward(x) return (y_pred - y)2 # define the gradient function sgddef gradient(x, y): return 2*x*(x*w - y) epoch_list = []loss_list = []print('predict (before training)', 4, forward(4))for epoch in range(100): for x,y in zip(x_data, y_data): grad = gradient(x,y) w = w - 0.01*grad # update weight by every grad of sample of training set print("\tgrad:", x, y,grad) l = loss(x,y) print("progress:",epoch,"w=",w,"loss=",l) epoch_list.append(epoch) loss_list.append(l) print('predict (after training)', 4, forward(4))plt.plot(epoch_list,loss_list)plt.ylabel('loss')plt.xlabel('epoch')plt.show() 随机梯度下降法和梯度下降法的主要区别在于:
- 损失函数由cost()更改为loss()。cost是计算所有训练数据的损失,loss是计算一个训练函数的损失。对应于源代码则是少了两个for循环。
- 梯度函数gradient()由计算所有训练数据的梯度更改为计算一个训练数据的梯度。
本算法中的随机梯度主要是指,每次拿一个训练数据来训练,然后更新梯度参数。本算法中梯度总共更新100(epoch)x3 = 300次。梯度下降法中梯度总共更新100(epoch)次。
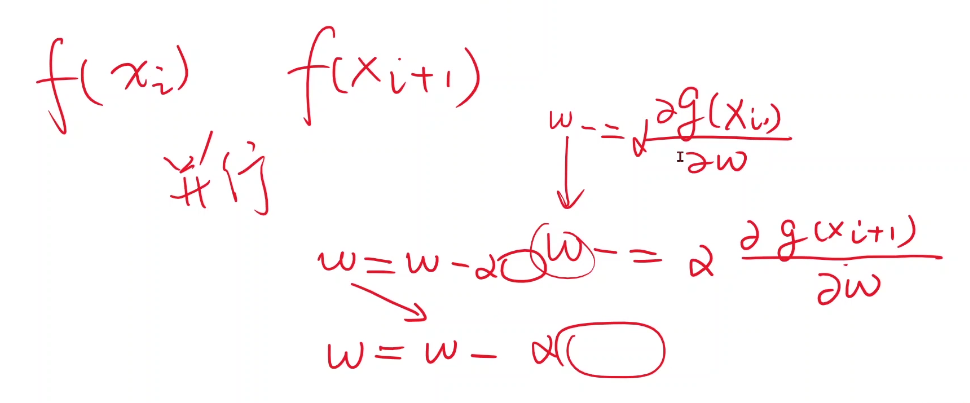
但是,随机梯度下降无法并行计算,时间复杂度比较高。因为 f ( x i ) f(x_i) f(xi)与 f ( xi+1 ) f(x_{i+1}) f(xi+1)之间有前后依赖关系,过程中权重w需要更新。
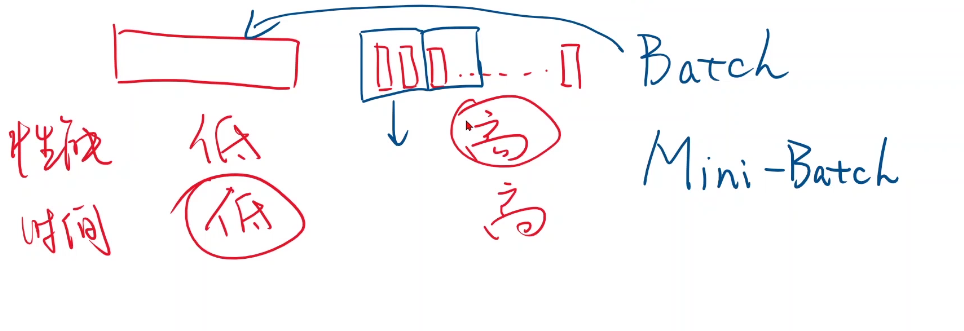
所以在深度学习中,采取了一种折中的方式:批量的随机梯度下降—>mini-batch。
batch本意指全体样本,mini-batch指部分的样本。
但现在也常用batch指代mini-batch
反向传播
课程链接:04.反向传播
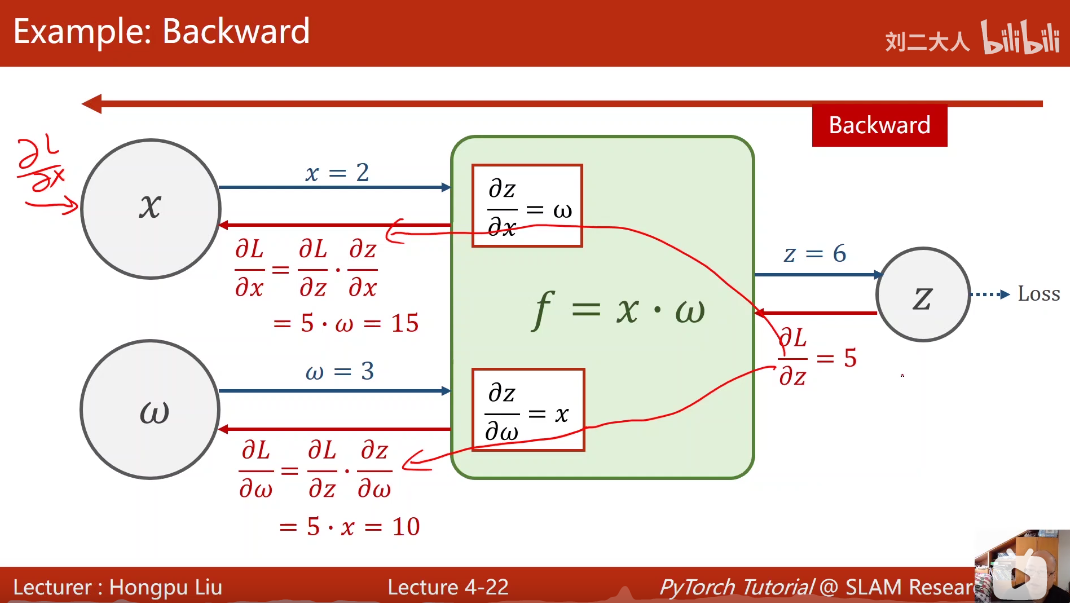
函数计算模块中可以计算局部梯度,沿着计算模块的路径反向计算出变量的梯度。(在pytorch中梯度存到变量里)
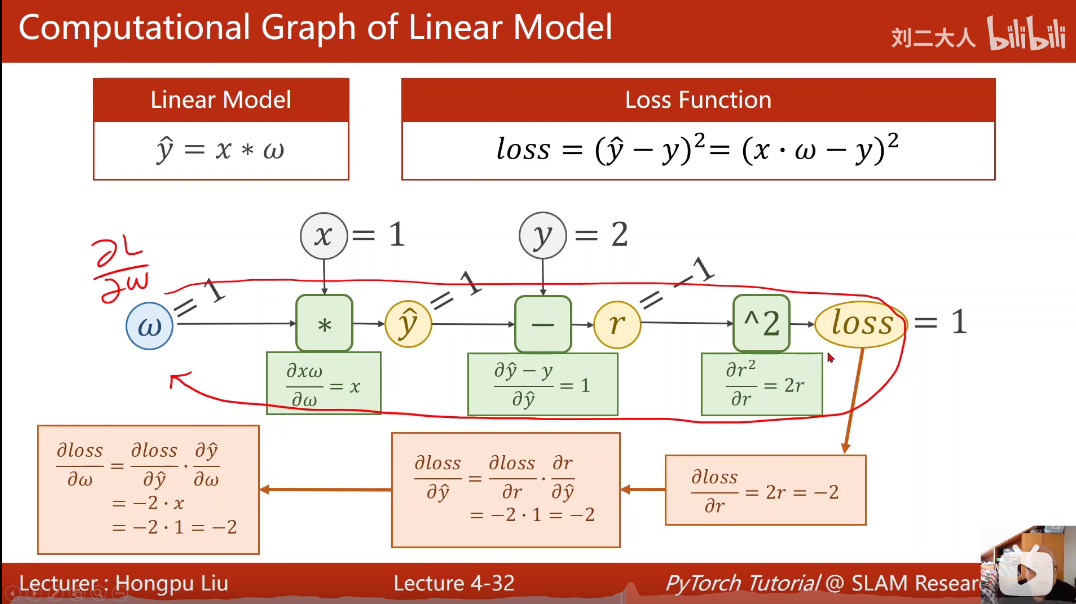
计算路径如图所示
在计算过程中,loss一般也存一下,能体现出训练是否能进入收敛的程度。
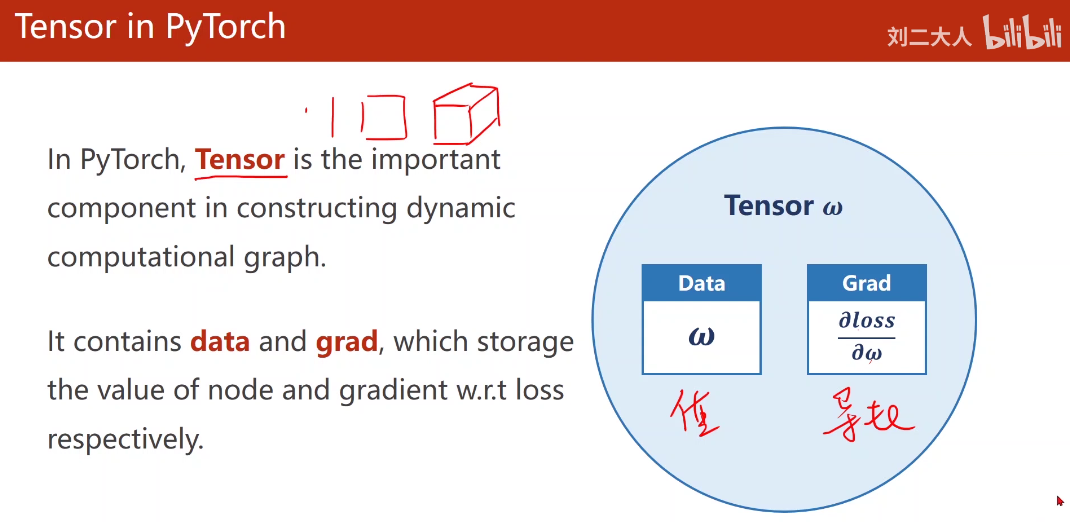
在pytorch中,基本数据类型为tensor,用来存数据的。
tensor类里包括两个重要组成部分:data、grad,分别用来存本身的值和对权重的导数。
w = torch.Tensor([1.0])W = requires_grad = (Ture) # 需要计算梯度张量之间的计算时,会创建计算图。每完成一次计算,都会把计算图给释放掉。

非张量之间的计算,不会创建计算图

上图中的梯度grad也是张量,w.grad.item()是为了避免产生计算图。
注意:不需要使用张量时要注意使用.item()来进行标量计算,避免计算图过长占用内存。

注意对梯度显式地进行清零,否则下一次计算会是∂ L 1 ∂ω + ∂ L 2 ∂ω \frac{\partial L_{1}}{\partial \omega}+\frac{\partial L_{2}}{\partial \omega} ∂ω∂L1+∂ω∂L2
在Pytorch中,Tensor和tensor都用于生成新的张量
a = torch.Tensor([1, 2])# tensor([1., 2.])a=torch.tensor([1,2])# tensor([1, 2])但torch.tensor与torch.Tensor有区别:
torch.Tensor()是python类,更明确的说,是默认张量类型torch.FloatTensor()的别名,torch.Tensor([1,2]) 会调用Tensor类的构造函数__init__,生成单精度浮点类型的张量。
torch.tensor()仅仅是Python的函数,函数原型是:
torch.tensor(data, dtype=None, device=None, requires_grad=False)其中data可以是:list, tuple, array, scalar等类型。
torch.tensor()可以从data中的数据部分做拷贝(而不是直接引用),根据原始数据类型生成相应的torch.LongTensor,torch.FloatTensor,torch.DoubleTensor。
参考链接:
Tensor和tensor的区别
torch.FloatTensor和torch.Tensor、torch.tensor
加深理解:
import torcha = torch.tensor([1.0])a.requires_grad = True # 或者 a.requires_grad_()print(a)print(a.data)print(a.type()) # a的类型是tensorprint(a.data.type()) # a.data的类型是tensorprint(a.grad)print(type(a.grad))结果如下
tensor([1.], requires_grad=True)tensor([1.])torch.FloatTensortorch.FloatTensorNoneimport torchx_data = [1.0, 2.0, 3.0]y_data = [2.0, 4.0, 6.0] w = torch.tensor([1.0]) # w的初值为1.0w.requires_grad = True # 需要计算梯度 def forward(x): return x*w # w是一个Tensor def loss(x, y): y_pred = forward(x) return (y_pred - y)2 print("predict (before training)", 4, forward(4).item()) for epoch in range(100): for x, y in zip(x_data, y_data): l =loss(x,y) # l是一个张量,tensor主要是在建立计算图 forward, compute the loss l.backward() # backward,compute grad for Tensor whose requires_grad set to True print('\tgrad:', x, y, w.grad.item()) w.data = w.data - 0.01 * w.grad.data # 权重更新时,需要用到标量,注意grad也是一个tensor w.grad.data.zero_() # after update, remember set the grad to zero print('progress:', epoch, l.item()) # 取出loss使用l.item,不要直接使用l(l是tensor会构建计算图) print("predict (after training)", 4, forward(4).item())w是Tensor, forward函数的返回值也是Tensor,loss函数的返回值也是Tensor。
本算法中反向传播主要体现在:l.backward()。调用该方法后w.grad由None更新为Tensor类型,且w.grad.data的值用于后续w.data的更新。
l.backward()会把计算图中所有需要梯度(grad)的地方都会求出来,然后把梯度都存在对应的待求的参数中,最终计算图被释放。
取tensor中的data是不会构建计算图的。
code
基于y=w*x线性模型,用pytorch实现反向传播
import numpy as npimport matplotlib.pyplot as pltimport torchx_data = [1.0,2.0,3.0]y_data = [2.0,4.0,6.0]w = torch.Tensor([1.0])#初始权值w.requires_grad = True#计算梯度,默认是不计算的def forward(x): return x * wdef loss(x,y):#构建计算图 y_pred = forward(x) return (y_pred-y) 2print('Predict (befortraining)',4,forward(4))for epoch in range(100): l = loss(1, 2)#为了在for循环之前定义l,以便之后的输出,无实际意义 for x,y in zip(x_data,y_data): l = loss(x, y) l.backward() print('\tgrad:',x,y,w.grad.item()) w.data = w.data - 0.01*w.grad.data #注意这里的grad是一个tensor,所以要取他的data w.grad.data.zero_() #释放之前计算的梯度 print('Epoch:',epoch,l.item())print('Predict(after training)',4,forward(4).item())result
......progress: 98 9.094947017729282e-13grad: 1.0 2.0 -7.152557373046875e-07grad: 2.0 4.0 -2.86102294921875e-06grad: 3.0 6.0 -5.7220458984375e-06progress: 99 9.094947017729282e-13predict (after training) 4 7.999998569488525用PyTorch实现线性回归
课程链接:05.用PyTorch实现线性回归
重点:构建张量计算图
y^ = ω ∗ x + b \hat{y}=\omega* x +b y^=ω∗x+b
要想知道 ω \omega ω的维度,需要先知道 y ^ \hat{y} y^与 x x x的维度
算出来的loss如果是向量,是没办法用backword的

所有的模型,都要继承自Module,最少都要实现两个函数:__init__()和forword()。
__init__():构造函数,初始化对象
forward():前馈过程中需要执行的计算
没有backword()函数:因为Module构造出的对象会自动根据计算图来自动实现backward。
如果需要自己计算梯度,可以继承自Functions类,构造自己的计算块。


torch. nn. Linear(1,1) :构造一个对象,包含了权重和偏置。其中Linear也是继承自Module,能够自动实现反向传播。nn:neural network。

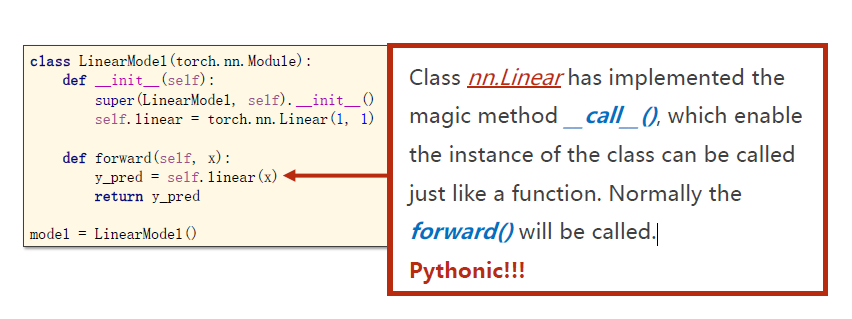
Module有个__call__方法,它使类的实例可以像函数一样被调用,里面通常会调用forward()。
自己定义forward()实际上是函数的重载。
此时model是可调用的:model(x)


其中criterion需要传参 y ^ \hat{y} y^与 y y y
优化器不会构建计算图,来自optimizor,是个类。
model.parameters()会检查所有的成员函数,如果有相应的权重,就会都加到需要训练的参数集合上。取Linear权重的时候是使用Linear.parameters()。
无论模型多复杂,都可用model.parameters()它能把参数都找到—>方便模型的嵌套
学习率lr一般设置为固定的,当然也能对模型的不同部分使用不同的学习率。

loss是个对象,打印loss的时候会自动调用__str__(),不会产生计算图
注意梯度归零
step()是用来进行更新的,会根据参数包含的梯度与设置的学习率来自动更新
步骤:
y ^ \hat{y} y^—>loss—>zero_grad—>backword—>update
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b1jwfRfk-1650706665863)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731494.png)]
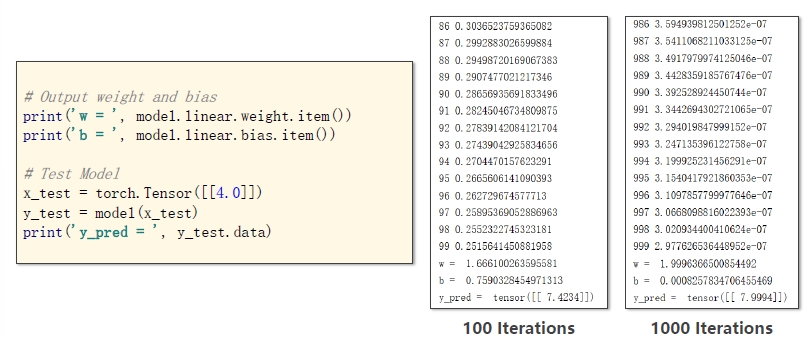
model.linear.weight虽然是只有一个值,但其实还是个矩阵,需要.item来直接取得值
 torch optim. Adaarad
torch optim. Adaarad
不同优化器的损失过程不一样:
- torch.optim. Adam
- torch optim. Adamax
- torch.optim.ASGD
- torch.optim. LBFGS
- torch. optim. Rmsprop
- torch.optim Rprop
- torch.optim SGD
可以通过网站学习更多的例子:
LEARNING PYTORCH WITH EXAMPLES
code
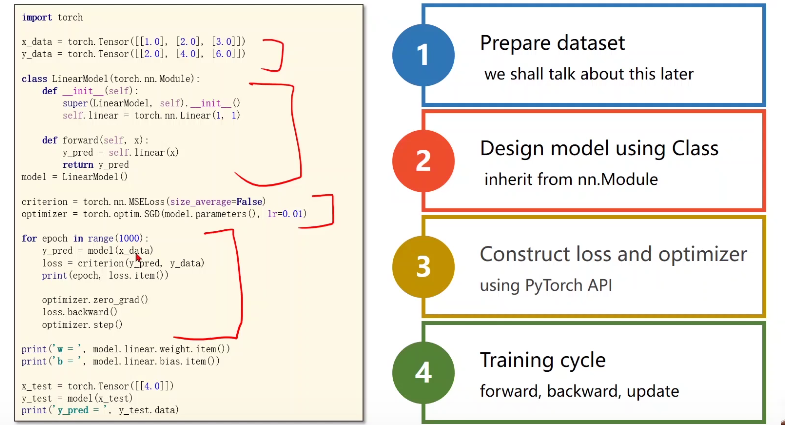
用Pytorch实现线性回归
import torch# prepare dataset# x,y是矩阵,3行1列 也就是说总共有3个数据,每个数据只有1个特征x_data = torch.tensor([[1.0], [2.0], [3.0]])y_data = torch.tensor([[2.0], [4.0], [6.0]]) #design model using class"""our model class should be inherit from nn.Module, which is base class for all neural network modules.member methods __init__() and forward() have to be implementedclass nn.linear contain two member Tensors: weight and biasclass nn.Linear has implemented the magic method __call__(),which enable the instance of the class canbe called just like a function.Normally the forward() will be called """class LinearModel(torch.nn.Module): def __init__(self): super(LinearModel, self).__init__() # (1,1)是指输入x和输出y的特征维度,这里数据集中的x和y的特征都是1维的 # 该线性层需要学习的参数是w和b 获取w/b的方式分别是~linear.weight/linear.bias self.linear = torch.nn.Linear(1, 1) def forward(self, x): y_pred = self.linear(x) return y_pred model = LinearModel() # construct loss and optimizer# criterion = torch.nn.MSELoss(size_average = False)criterion = torch.nn.MSELoss(reduction = 'sum')optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) # model.parameters()自动完成参数的初始化操作 # training cycle forward, backward, updatefor epoch in range(100): y_pred = model(x_data) # forward:predict loss = criterion(y_pred, y_data) # forward: loss print(epoch, loss.item()) optimizer.zero_grad() # the grad computer by .backward() will be accumulated. so before backward, remember set the grad to zero loss.backward() # backward: autograd,自动计算梯度 optimizer.step() # update 参数,即更新w和b的值 print('w = ', model.linear.weight.item())print('b = ', model.linear.bias.item()) x_test = torch.tensor([[4.0]])y_test = model(x_test)print('y_pred = ', y_test.data)逻辑斯蒂(losgitic)回归
课程链接:06.逻辑斯蒂回归
叫回归,但是是做分类的
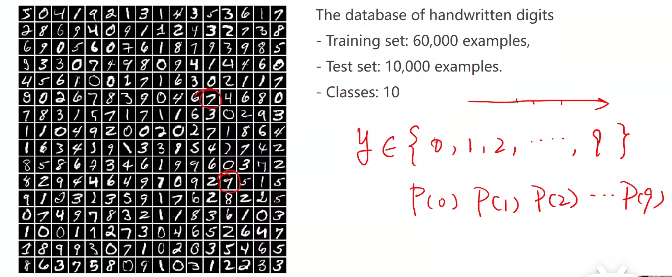
分类问题中,不能简单的输出0、1、2、3…9,因为这些类别中并没有实数中的数值大小概念:并没有说图片7和图片9有实数中7和9一样相差2的数值差别。
在分类问题中,输出的其实是概率P(0)、P(1)、P(2)、P(3)…P(9)
import torchvisiontrain_set = torchvision.datasets.MNIST(root="../dataset/mnist", train=True, download=True)test_set = torchvision.datasets.MNIST(root="../dataset/mnist", train=False, download=True)pytorch中有个模块torchvision,里面有很多主流数据集

import torchvisiontrain_set=torchvision. datasets. CIFAR10(...)test_set =torchvision. datasets. CIFAR10(...)losgitic function
σ ( x ) =1 1 + e − x \sigma(x)=\frac{1}{1+e^{-x}} σ(x)=1+e−x1
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xnz9B5Bz-1650706665873)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731498.jpg)]
想要计算概率,必须要使输出值在[0,1]
其它的sigmoid函数
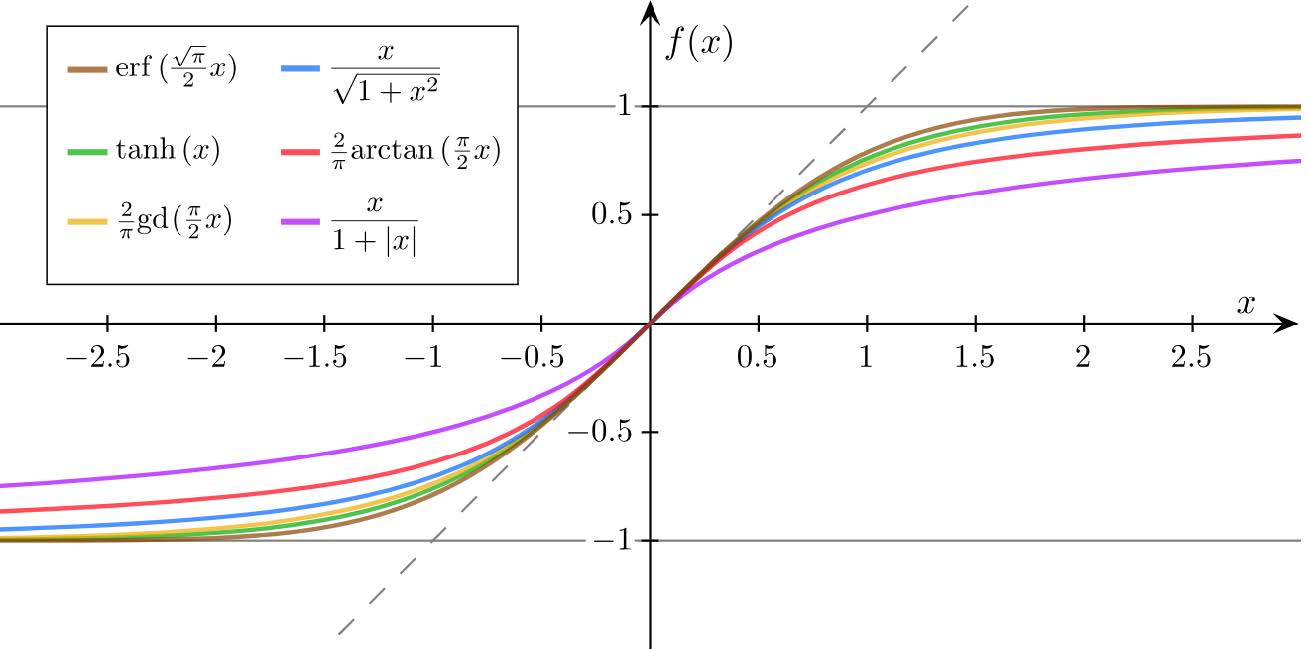
-
饱和函数
-
[0,1]
-
单调递增
满足以上特点即为sigmoid函数
但是现在因为logistic function比较出名,因此logistic 也被称为sigmoid函数,其实只是sigmoid的其中一种。
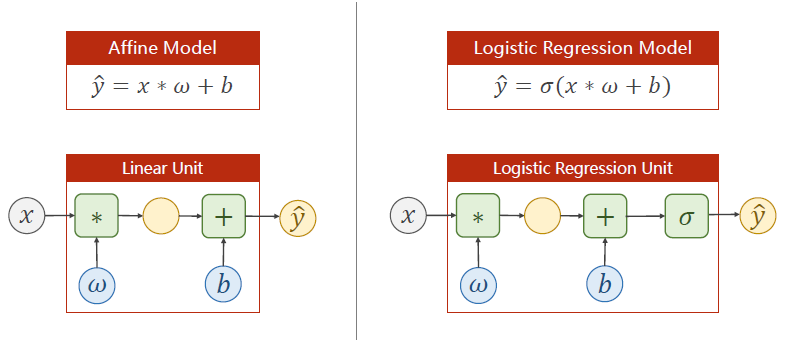
与线性回归的差别就在于线性回归之后加了一个sigmoid用来做变换,将数值缩放到[0,1]
σ \sigma σ常被用作指代sigmoid函数

以前线性回归的loss是计算 y ^ \hat{y} y^与 y y y之间的距离,现在logistic不是输出数值了,而是输出一个分布。现在loss是要比较分布的差异。
KL散度、cross-entropy交叉熵
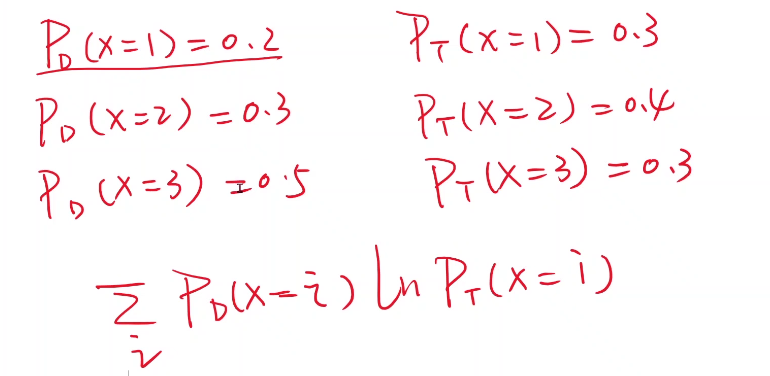
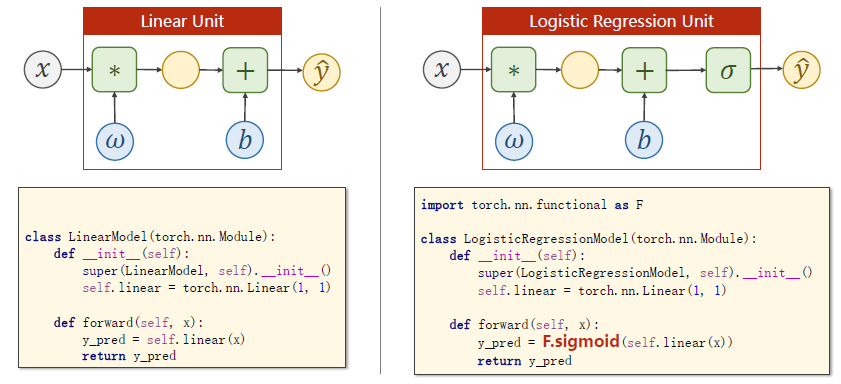
写模型的时候需要做什么改变?
线性部分没有什么改变,因为 σ \sigma σ部分没有参数,不需要在构造函数中初始化它
sigmoid函数在torch. nn. functional中
把sigmoid函数应用在线性变换的结果上
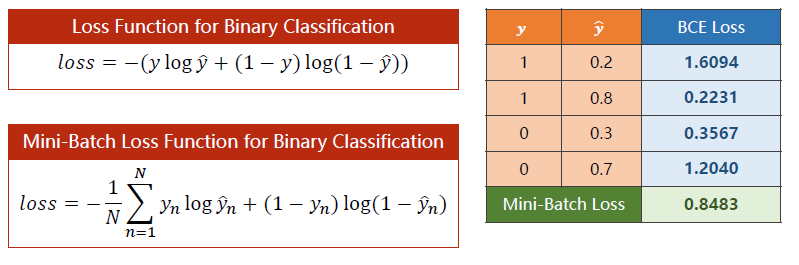
损失函数改成BCELoss(二分类问题交叉熵损失)
criterion = torch.nn.BCELOSS(size_average=False)是否求平均会影响到将来的学习率设置,因为求平均意味着前面加了一个很小的数,将来求导的时候前面还是会有这个小的数。
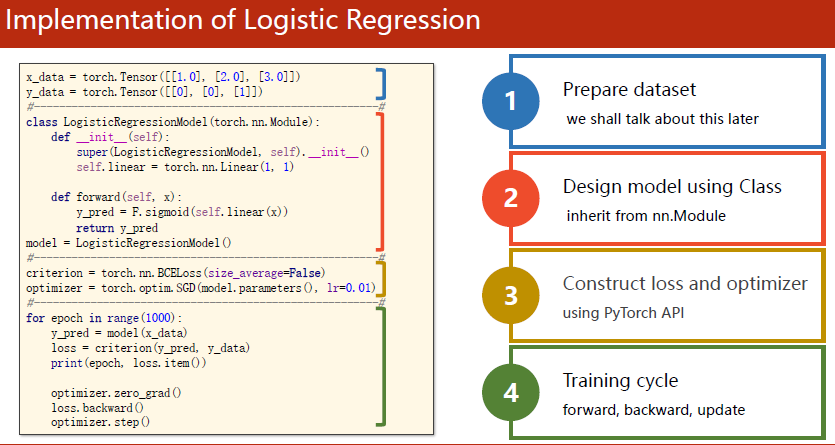
基本上可归纳为这几个步骤:
- Prepare dataset
we shall talk about this later - Design model using Class
inherit from nn.Module - Construct loss and optim
using Pytorch Apl - Training cycle
forward, backward, update
以后数据集的读取建立可能会比较复杂,可以自己封装起来,主程序中再import。
code
基于逻辑斯蒂回归实现二分类
import torch# import torch.nn.functional as F # prepare datasetx_data = torch.Tensor([[1.0], [2.0], [3.0]])y_data = torch.Tensor([[0], [0], [1]]) #design model using classclass LogisticRegressionModel(torch.nn.Module): def __init__(self): super(LogisticRegressionModel, self).__init__() self.linear = torch.nn.Linear(1,1) def forward(self, x): # y_pred = F.sigmoid(self.linear(x)) y_pred = torch.sigmoid(self.linear(x)) return y_predmodel = LogisticRegressionModel() # construct loss and optimizer# 默认情况下,loss会基于element平均,如果size_average=False的话,loss会被累加。criterion = torch.nn.BCELoss(size_average = False) optimizer = torch.optim.SGD(model.parameters(), lr = 0.01) # training cycle forward, backward, updatefor epoch in range(1000): y_pred = model(x_data) loss = criterion(y_pred, y_data) print(epoch, loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() print('w = ', model.linear.weight.item())print('b = ', model.linear.bias.item()) x_test = torch.Tensor([[4.0]])y_test = model(x_test)print('y_pred = ', y_test.data)注意:
- [五分钟理解:BCELoss 和 BCEWithLogitsLoss的区别]
BCELoss 是CrossEntropyLoss的一个特例,只用于二分类问题,而CrossEntropyLoss可以用于二分类,也可以用于多分类
- pytorch nn.BCELoss()详解
处理多维特征的输入
课程链接:07.处理多维特征的输入
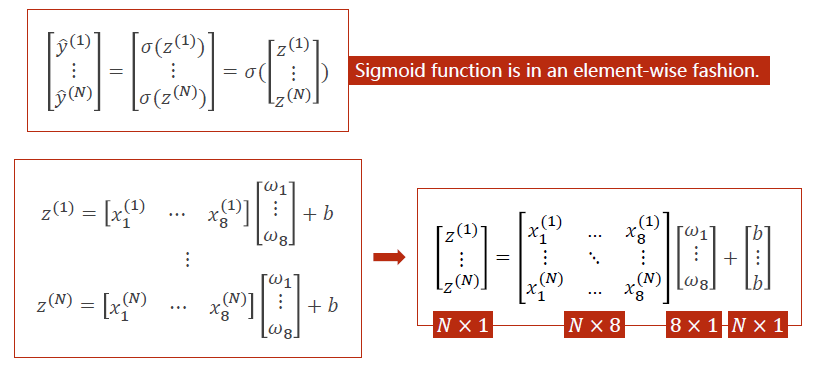
变成矩阵运算有利于使用并行计算。
矩阵是一种空间变换的函数
本质上是想找一个8D—>1D的非线性变换, σ \sigma σ是一种引入非线性的方式
因此可以8D—>6D—>2D—>1D,或8D—>24D—>12D—>1D
一般来说,隐层越多,神经元越多,对非线性变换的学习能力越强。但不是学习能力越强越好,因为这样会把数据中的噪声学进去。我们要学的只是数据真值本身的规律。
必须要有泛化能力才是最好的
一般会使用超参数搜索的方式来确定说哪样更好
一般dtype = np.float32,因为一般显卡里面只支持float32,只有特斯拉这样的显卡才有double的数据

之前调用的是torch.nn.functional里的sigmoid,这次是nn下的sigmoid,也是继承自module。
torch.sigmoid、torch.nn.sigmoid、torch.nn.functional.sigmoid区别:
torch.sigmoid()、torch.nn.Sigmoid()和torch.nn.functional.sigmoid()三者之间的区别
- torch.sigmoid是一个方法,包含了参数和返回值
- torch.nn.sigmoid是一个类,在定义模型的初始化方法中使用,需要在_init__中定义,然后再使用
- torch.nn.functional.sigmoid是一个方法,可以直接在正向传播中使用,而不需要初始化。
==注意:==建议一直用x,这是惯例,避免调用错误
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZBRVmHEL-1650706665875)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731509.png)]
这没使用mini_batch,直接全放进去训练了。以后再用DataLoader来制作mini_batch
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T53DhCBn-1650706665875)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731510.png)]
Activation Functions for Artificial Neural Networks
Visualising Activation Functions in Neural Networks
可以尝试不同的激活函数
pytorch中有很多的激活函数
https://pytorch.org/docs/stable/nn.html#non linear activations weighted sum nonlinearit
==注意:==ReLu是最小是会到0的,最后如果计算log0的话会有问题。如果要使用ReLu的话可以改最后一个为sigmoid避免这个问题。
code
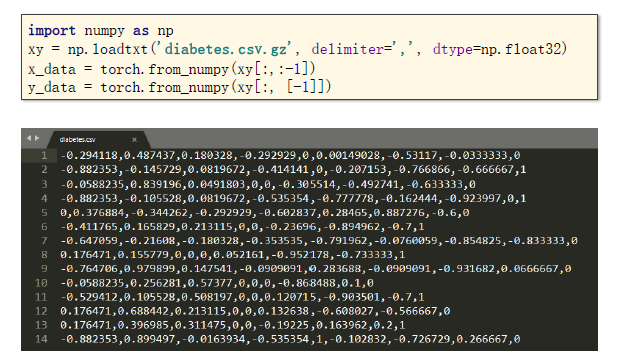
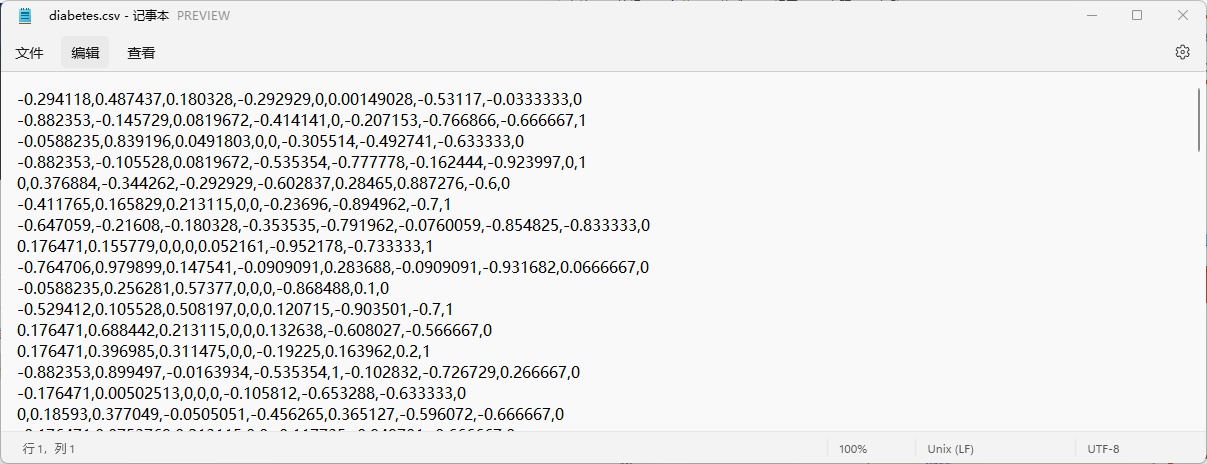
糖尿病预测
import numpy as npimport torchimport matplotlib.pyplot as plt # prepare datasetxy = np.loadtxt('diabetes.csv', delimiter=',', dtype=np.float32)x_data = torch.from_numpy(xy[:, :-1]) # 第一个‘:’是指读取所有行,第二个‘:’是指从第一列开始,最后一列不要y_data = torch.from_numpy(xy[:, [-1]]) # [-1] 最后得到的是个矩阵 # design model using class class Model(torch.nn.Module): def __init__(self): super(Model, self).__init__() self.linear1 = torch.nn.Linear(8, 6) # 输入数据x的特征是8维,x有8个特征 self.linear2 = torch.nn.Linear(6, 4) self.linear3 = torch.nn.Linear(4, 1) self.sigmoid = torch.nn.Sigmoid() # 将其看作是网络的一层,而不是简单的函数使用 def forward(self, x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) # y hat return x model = Model() # construct loss and optimizer# criterion = torch.nn.BCELoss(size_average = True)criterion = torch.nn.BCELoss(reduction='mean') optimizer = torch.optim.SGD(model.parameters(), lr=0.1) epoch_list = []loss_list = []# training cycle forward, backward, updatefor epoch in range(100): y_pred = model(x_data) loss = criterion(y_pred, y_data) print(epoch, loss.item()) epoch_list.append(epoch) loss_list.append(loss.item()) optimizer.zero_grad() loss.backward() optimizer.step() plt.plot(epoch_list, loss_list)plt.ylabel('loss')plt.xlabel('epoch')plt.show()diabetesDatasets的格式如下:
如果想查看某些层的参数,可以这样
# 参数说明# 第一层的参数:layer1_weight = model.linear1.weight.data layer1_bias = model.linear1.bias.data print("layer1_weight", layer1_weight)print("layer1_weight.shape", layer1_weight.shape)print("layer1_bias", layer1_bias)print("layer1_bias.shape", layer1_bias.shape)加载数据集
课程链接:08.加载数据集
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-UoNLC1Ks-1650706665876)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731512.png)]
Epoch:所有样本都进行了一次训练,叫一个Epoch
Batch_size:每次训练(前馈、反馈)的时候用的样本数量
Iteration:batch一共分了多少个
样本数 = Batch_size*Iteration。示例:10000个样本,batch_size取1000,则Iteration为10。
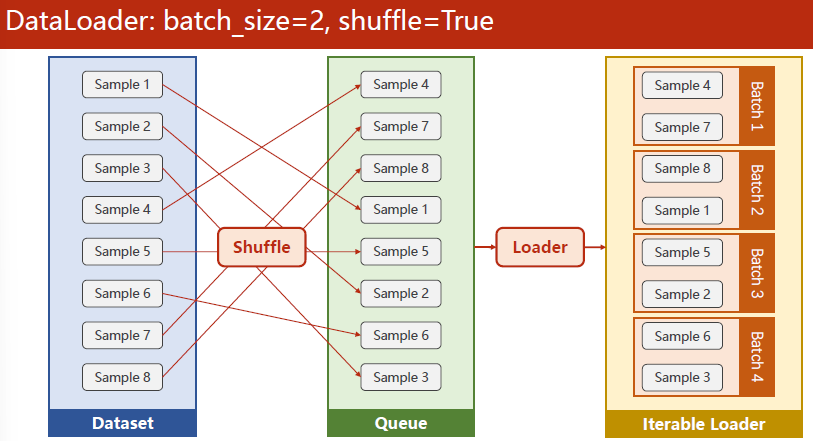
数据集需要支持索引,并且知道长度。只要能知道这两个信息,将来dataloader就可以对dataset自动进行小批量的数据集生成。
Dataset是一个抽象类,无法实例化,只能被子类继承。DataLoader是用来加载数据的。
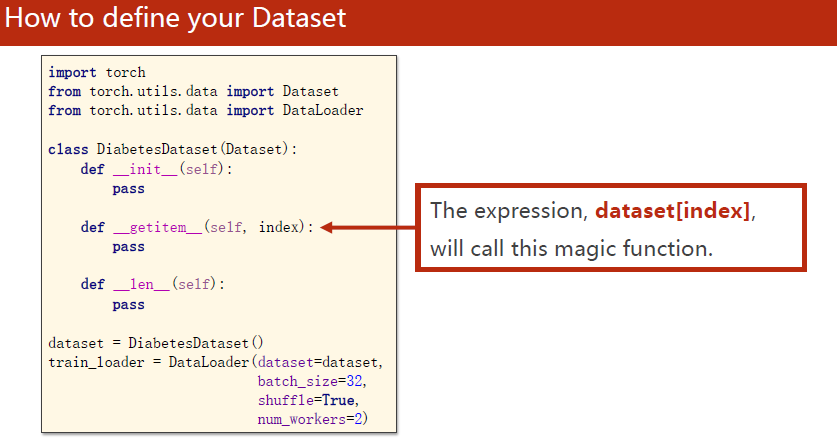
实现__getitem__方法,将来实例化之后,这个对象可以进行下标操作进行索引。
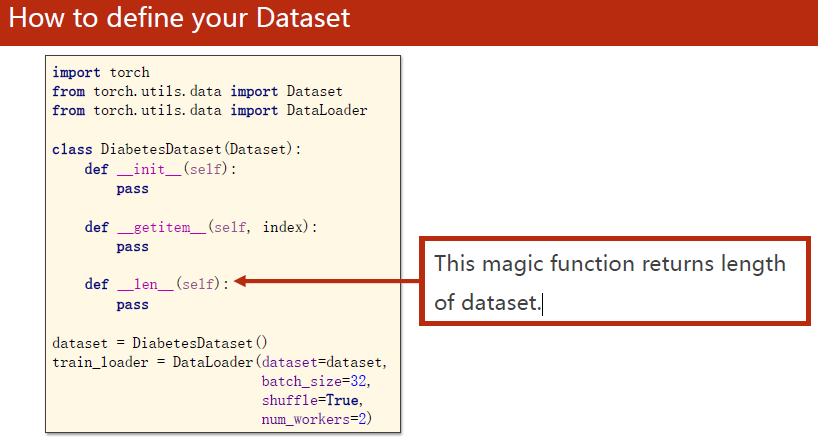
__len__可以返回数据条数
__init__函数的两种设计思路:
- 先在__init__中读所有的data,再在__getitem__中按索引丢出去
适用数据量小的数据集
- 只做一些初始化,定义一些读写的操作。譬如构造一个文件列表,标签列表。等到__getitem__中再现读出来。保持内存的高效使用。
适合数据量大的,譬如图像语音等无结构数据
DataLoader一般要定义以下几个变量:
- dataset
- batch_size
- shuffle:是否打乱。打乱可以引入随机性,不打乱方便观察。
- num_works:是否需要并行的进程来进行读取mini_batch

注意:windows中使用spawn而不是fork
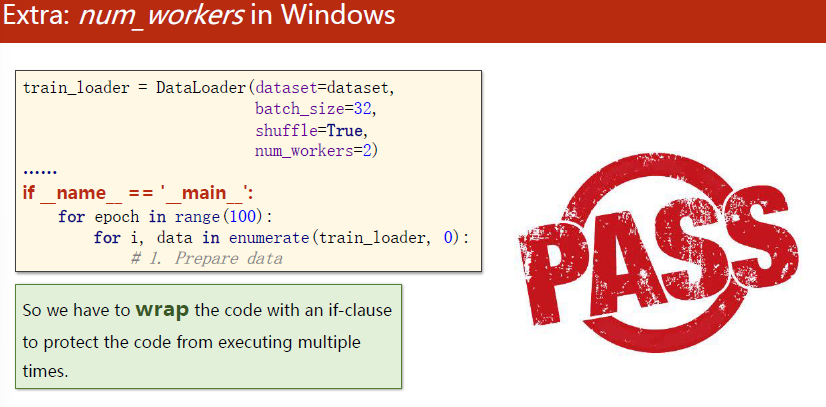
因此需要这样把代码封装进一个if语句中来执行,避免重复执行
input,label是会自动转换为tensor
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DwezAsV0-1650706665877)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731519.png)]
torchvision.datasets里有很多数据集
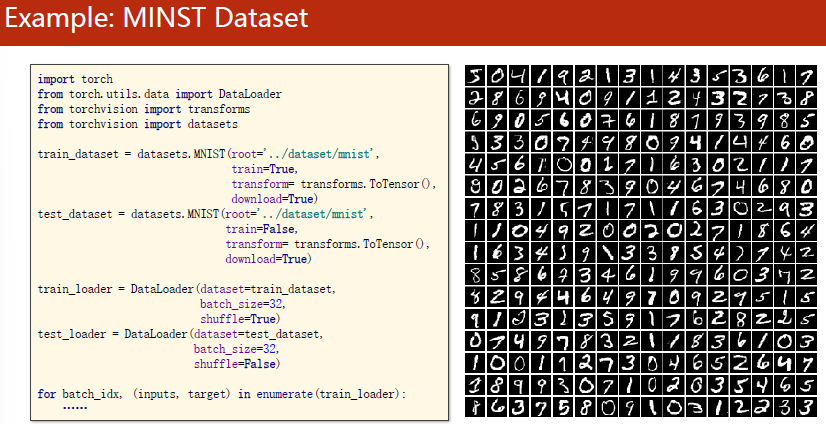
可以直接进行import并构造
code
糖尿病预测
import torchimport numpy as npfrom torch.utils.data import Datasetfrom torch.utils.data import DataLoader # prepare dataset class DiabetesDataset(Dataset): def __init__(self, filepath): xy = np.loadtxt(filepath, delimiter=',', dtype=np.float32) self.len = xy.shape[0] # shape(多少行,多少列) self.x_data = torch.from_numpy(xy[:, :-1]) self.y_data = torch.from_numpy(xy[:, [-1]]) def __getitem__(self, index): return self.x_data[index], self.y_data[index] def __len__(self): return self.len dataset = DiabetesDataset('diabetes.csv')train_loader = DataLoader(dataset=dataset, batch_size=32, shuffle=True, num_workers=2) #num_workers 多线程 # design model using class class Model(torch.nn.Module): def __init__(self): super(Model, self).__init__() self.linear1 = torch.nn.Linear(8, 6) self.linear2 = torch.nn.Linear(6, 4) self.linear3 = torch.nn.Linear(4, 1) self.sigmoid = torch.nn.Sigmoid() def forward(self, x): x = self.sigmoid(self.linear1(x)) x = self.sigmoid(self.linear2(x)) x = self.sigmoid(self.linear3(x)) return x model = Model() # construct loss and optimizercriterion = torch.nn.BCELoss(reduction='mean')optimizer = torch.optim.SGD(model.parameters(), lr=0.01) # training cycle forward, backward, updateif __name__ == '__main__': for epoch in range(100): for i, data in enumerate(train_loader, 0): # train_loader 是先shuffle后mini_batch inputs, labels = data y_pred = model(inputs) loss = criterion(y_pred, labels) print(epoch, i, loss.item()) optimizer.zero_grad() loss.backward() optimizer.step()diabetesDatasets的格式如下:
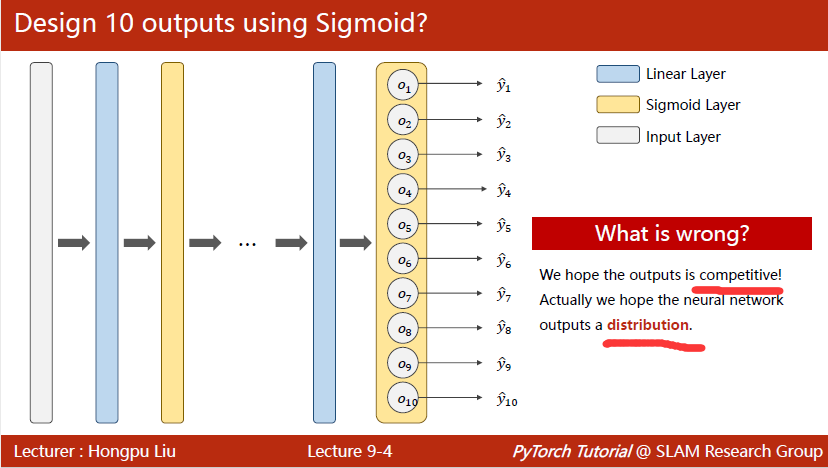
多分类问题
课程链接:09.多分类问题
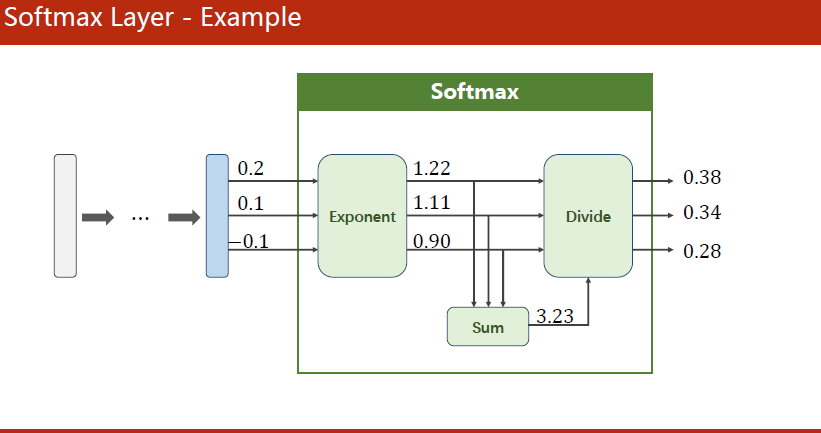
多分类问题一般会用到一种分类器:softmax
假设 Zl ∈RK Z^{l} \in \mathbb{R}^{K} Zl∈RK是最后一个线性层的输出。则softmax为:
P ( y = i ) = e z i ∑ j = 0 K − 1 e z j , i ∈ { 0 , … , K − 1 } P(y=i)=\frac{e^{z_{i}}}{\sum_{j=0}^{K-1} e^{z_{j}}}, i \in\{0, \ldots, K-1\} P(y=i)=∑j=0K−1ezjezi,i∈{0,…,K−1}
多分类问题一般需要具备“抑制”或是“互斥”,所以之前的二分类问题用的BCELoss(二分类问题大交叉熵损失)就不好用了
分类问题的核心:输出的是“分布”(每个输出的值都是大于等于0的,它们的和等于1)
分母指数部分会保证大于0,分子目的是为了满足求和后保证为1
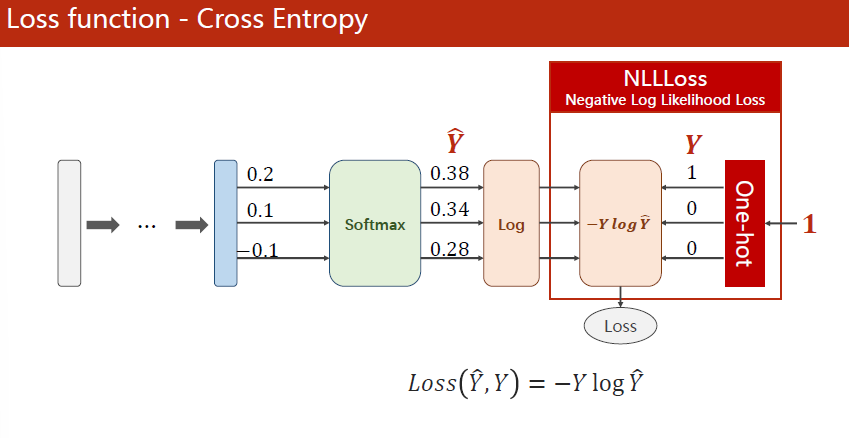
之前在二分类问题时,实际上在计算时loss = − ( y log y^ + ( 1 − y ) log ( 1 −y^ ) ) \operatorname{loss}=-(y \log \hat{y}+(1-y) \log (1-\hat{y})) loss=−(ylogy^+(1−y)log(1−y^)),最后求和时这两项只会有一项是非0的。
现在多分类问题中用NLLLoss(Negative Log Likelihood Loss,负对数似然损失)损失函数 loss ( Y ^ , Y ) = − Y log Y ^ \operatorname{loss}(\hat{Y}, Y)=-Y \log \hat{Y} loss(Y^,Y)=−YlogY^来计算,最后只会保留一项。
基于numpy的实现
import numpy as npy = np.array([1, 0, 0])z = np.array([0.2, 0.1, -0.1])y_pred = np.exp(z) / np.exp(z).sum()loss = (- y * np.log(y_pred)).sum()print(loss)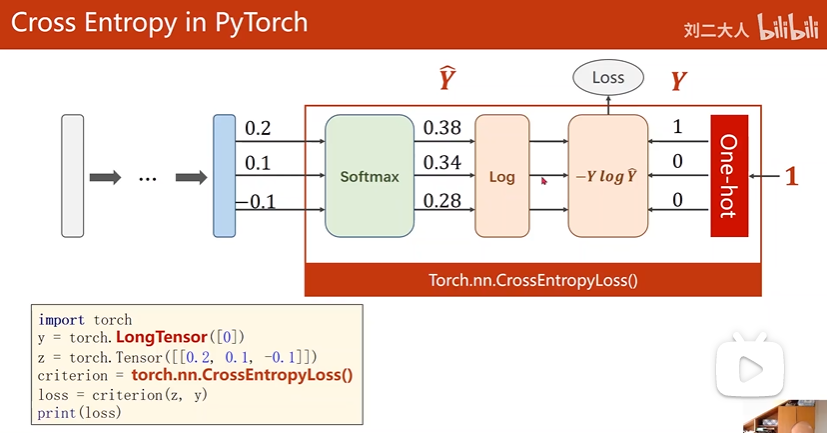
基于pytorch的实现
import torchy = torch.LongTensor([0])z = torch.Tensor([[0.2, 0.1, -0.1]])criterion = torch.nn.CrossEntropyLoss() loss = criterion(z, y)print(loss)其中使用了CrossEntropyLoss(交叉熵损失),包括由类别生成独热向量,再进行计算的整个过程。
所以这时候神经网络最后一层不要做激活(非线性变换)。
关于交叉熵需要注意:
- y需要是一个LongTensor,长整型的一个张量。
- 直接使用torch.nn.CrossEntropyLoss()
关于NLLLoss与CrossEntropyLoss,有CrossEntropyLoss LogSoftmax + NLLLoss,
可见链接:
-
Pytorch损失函数NLLLoss()与CrossEntropyLoss()的关系
-
https://pytorch.org/docs/stable/nn.html#crossentropyloss
-
https://pytorch.org/docs/stable/nn.html#nllloss

样本为28*28一共784个像素的图片
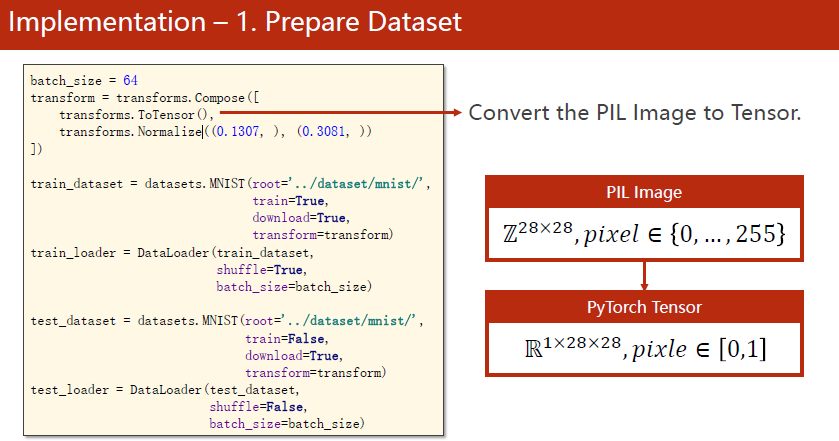
torchvision中的transforms里面包含一些对图像的处理工具
神经网络喜欢输入的数值在0~1之间,符合正态分布,所以需要将原始图像转变为图像张量,像素值为0~1,可以使用transforms中一些关于PIL(Pillow)的一些功能
pytorch中transforms.Compose()使用
在使用卷积运算前,应该将w×h×c的图像转换成c×w×h的格式
transforms.Compose这个类可以将中括号中的一系列的calllable对象构成一个pipeline一样的处理:
-
单通道变多通道的过程可以由transforms.ToTensor实现
-
归一化的过程可以用transforms.Normalize实现,其中均值0.1307和标准差0.3081并不是随便设的,而是针对MNIST数据集样本算出的一个经验值。归一化:Pixel norm = Pixel origin − mean std ∣ _{\text {norm }}=\frac{\text { Pixel }_{\text {origin }}-\text { mean }}{\text { std } \mid}norm = std ∣ Pixel origin − mean

transform放进数据集中可以在以后拿到数据的时候直接进行转换处理。这里是因为这个数据集不大,要是大的可以放到getitem中进行处理
先把三阶张量变成二阶张量(向量)进行输入,可以使用view函数,改变张量形状
由于网络有点大了,因此优化器选用带冲量(momentum)的
现在又要训练又要测试,如果都丢进trainning cycle中会显得不便,因此现在把一轮训练封装成一个函数
记录损失,每300轮输出一次
取损失的时候记得用.item(),不然会构建计算图
测试的时候不用计算梯度,因此使用
with torch.no_grad():这样就不会计算梯度了
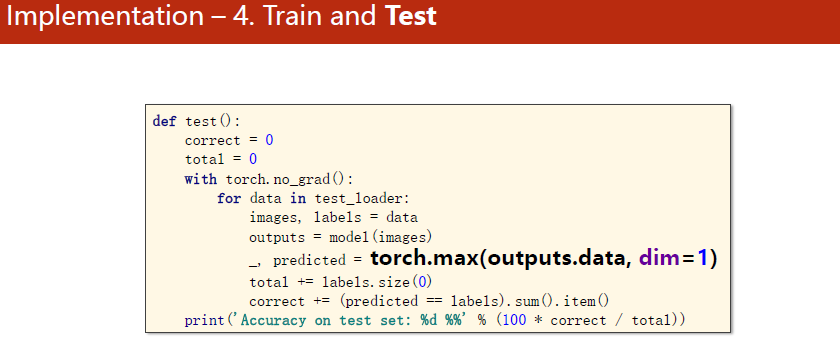
预测的结果是个矩阵,每个样本占1行,共10列,需要求每一行的最大值的下标(对应的分类)
label是一个N×1的矩阵,因此label.size(0)是等于N
最后结果准确率会无法一直增加,停留在97%左右,因为使用全连接层来做图像,意味着每个像素之间都要产生联系,导致权重不够多;处理图像的时候,更关注一些高抽象级别的特征,可能需要做图像的特征提取,如人工的FFT(快速傅立叶变换),wavelet(小波),自动的CNN
code
全连接网络,MNIST手写数字识别
import torchfrom torchvision import transformsfrom torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.nn.functional as Fimport torch.optim as optim # prepare dataset batch_size = 64transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差 train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size) # design model using class class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.l1 = torch.nn.Linear(784, 512) self.l2 = torch.nn.Linear(512, 256) self.l3 = torch.nn.Linear(256, 128) self.l4 = torch.nn.Linear(128, 64) self.l5 = torch.nn.Linear(64, 10) def forward(self, x): x = x.view(-1, 784) # -1其实就是自动获取mini_batch x = F.relu(self.l1(x)) x = F.relu(self.l2(x)) x = F.relu(self.l3(x)) x = F.relu(self.l4(x)) return self.l5(x) # 最后一层不做激活,不进行非线性变换 model = Net() # construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # training cycle forward, backward, update def train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): # 获得一个批次的数据和标签 inputs, target = data optimizer.zero_grad() # 获得模型预测结果(64, 10) outputs = model(inputs) # 交叉熵代价函数outputs(64,10),target(64) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch+1, batch_idx+1, running_loss/300)) running_loss = 0.0 def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度 total += labels.size(0) correct += (predicted == labels).sum().item() # 张量之间的比较运算 print('accuracy on test set: %d %% ' % (100*correct/total)) if __name__ == '__main__': for epoch in range(10): train(epoch) test()结果
[1, 300] loss: 2.161[1, 600] loss: 0.841[1, 900] loss: 0.418......accuracy on test set: 97 % [10, 300] loss: 0.031[10, 600] loss: 0.027[10, 900] loss: 0.034accuracy on test set: 97 % 卷积神经网络(基础篇)
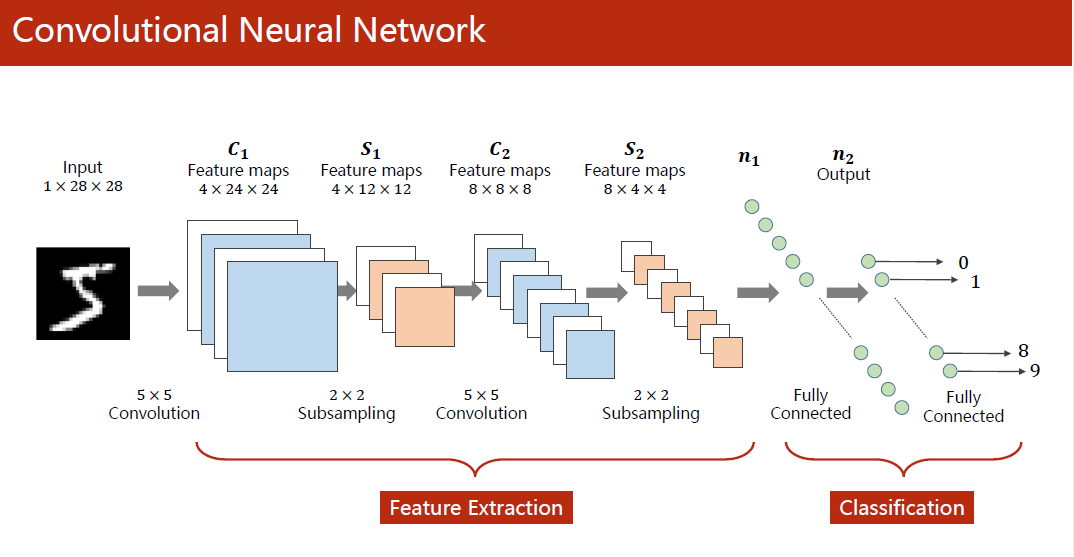
课程链接:10.卷积神经网络(基础篇)
卷积:convolution
全连接:都是线性层连接起来的
卷积层:保留图像的空间特征
卷积过后依旧是一个三维的张量
下采样的时候通道数不变,但是图像的宽度和高度会变
下采样的目的是减少数据量,降低运算需求
特征提取器(feature extraction):卷积、下采样 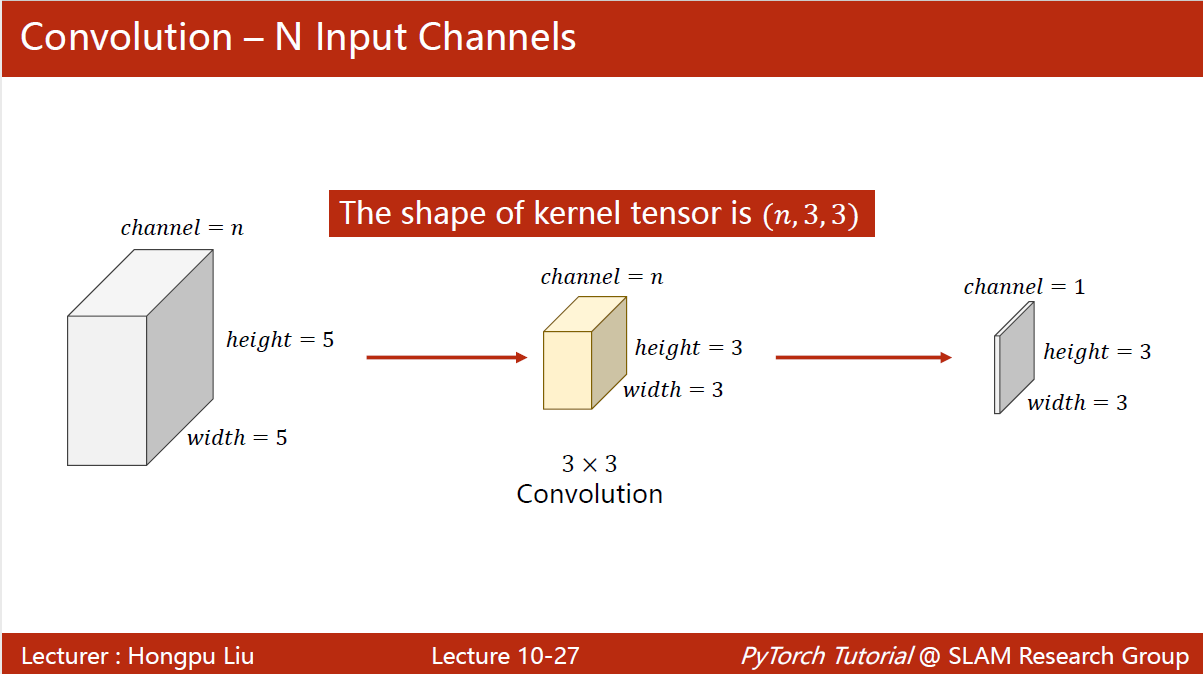
卷积之后的形状变化如上图所示
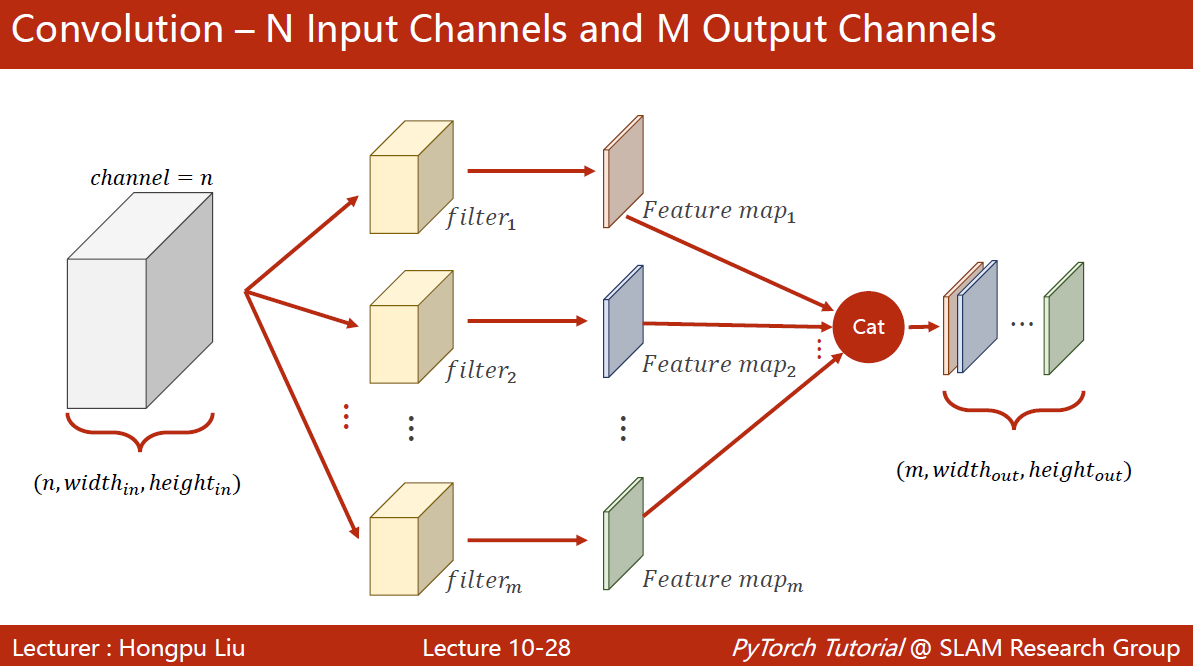
可以使用多个卷积核进行卷积运算,最后拼接到一起
注意:
-
每一个卷积核通道数要求和输入通道数一致,n
-
卷积核总数与输出通道数一致,m
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1WkDcjaP-1650706665879)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731535.png)]
卷积层是一个4维的4 m × n × k e r n e l _ s i zewidth × k e r n e l _ s i zeheight 4m \times n \times kernel\_size_{\text {width }} \times kernel\_size _{\text {height }} 4m×n×kernel_sizewidth ×kernel_sizeheight
卷积层对输入图像的宽度与高度没有要求,对batch_size也没有要求,对输入通道数有要求
在pytorch中为:torch.nn.Conv2d
卷积层的一些参数:
padding:填充有多种方式,默认是零填充
bias:偏置量
stride:步长
import torchinput = [ 3, 4, 6, 5, 7 2, 4, 6, 8, 2 1, 6, 7, 8, 4 9, 7, 4, 6, 2 3, 7, 5, 4, 1 ]input = torch.Tensor(input).view( 1, 1, 5, 5)conv_layer = torch.nn.Conv2d( 1, 1, kernel_size=3, padding=1, bias =False)kernel = torch.Tensor([ 1, 2, 3, 4, 5, 6, 7, 8, 9 ]). view(1, 1, 3, 3)conv_layer.weight.data = kernel.dataoutput = conv_layer(input)print(output)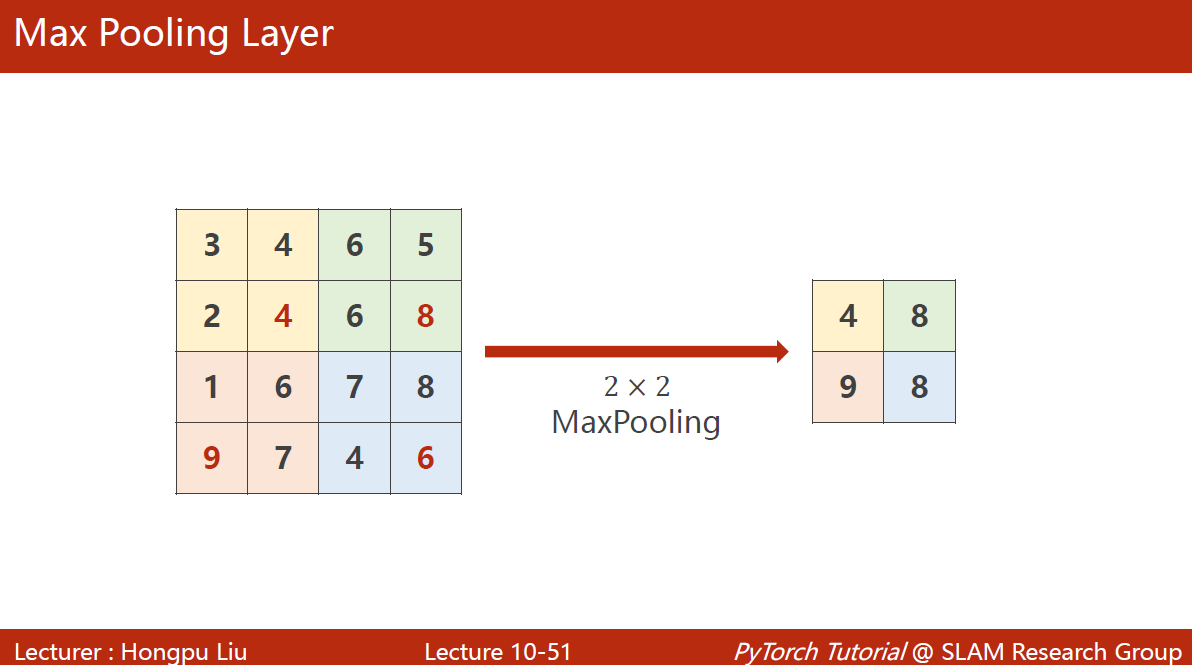
下采样用的最多的叫maxPooling(最大池化层),默认stride = 2
做maxPooling后通道数是不变的
在pytorch中为torch. nn.MaxPool2d
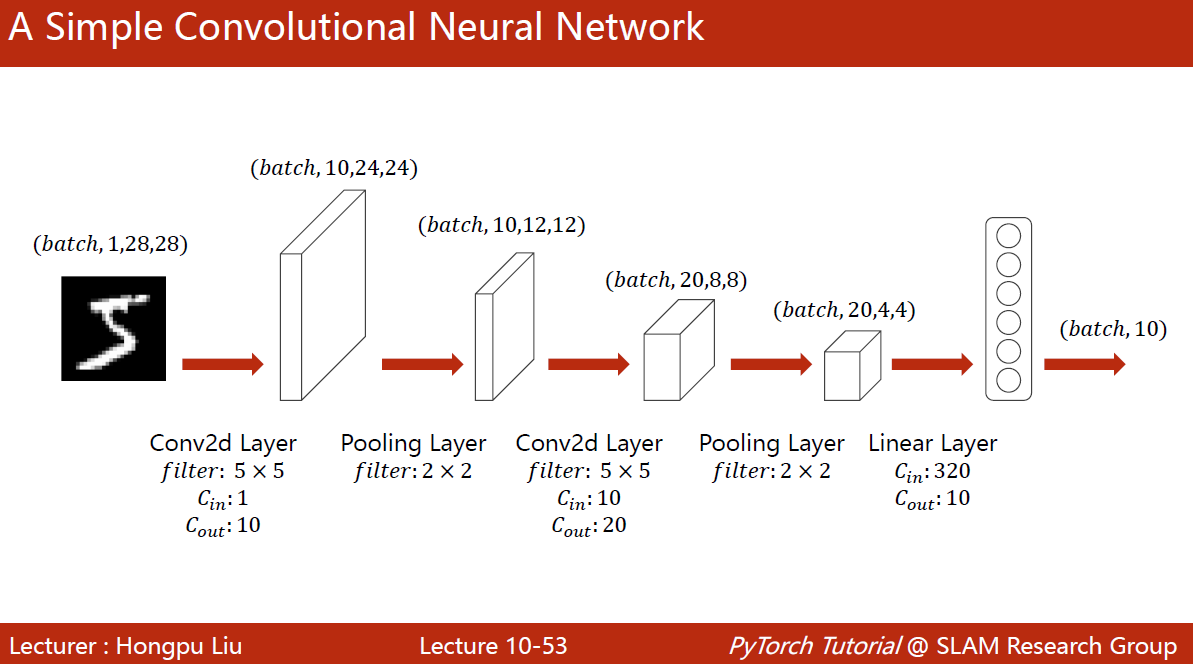
注意每一层之间的衔接
多大的图像都能丢进来算,只是最后全连接层的维度会产生变化
全连接层的维度可以手算,也可以使用pytorch计算卷积层之后输出结果的维度来算
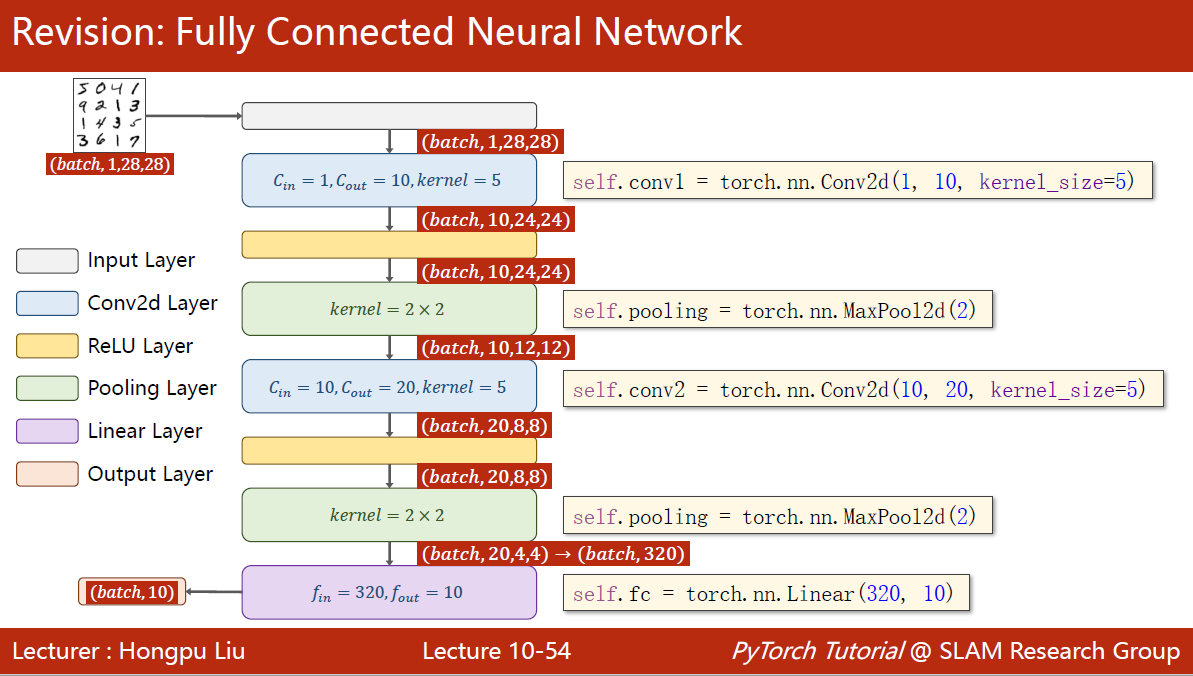
无权重的层可以只做一个,但是有权重的层需要单独做一个实例
class Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) self.pooling = torch.nn.MaxPool2d(2) self.fc = torch.nn.Linear(320, 10) def forward(self, x): # flatten data from (n,1,28,28) to (n, 784) batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = x.view(batch_size, -1) # flatten # -1 此处自动算出的是320 x = self.fc(x) return x model = Net()要做交叉熵损失,因此最后一层不做激活。
如果要用GPU计算,需要
-
模型迁移到GPU

device = torch.device("cuda:0"if torch.cuda.is_available()else "cpu")model.to(device) -
需要计算的张量也要迁移至GPU
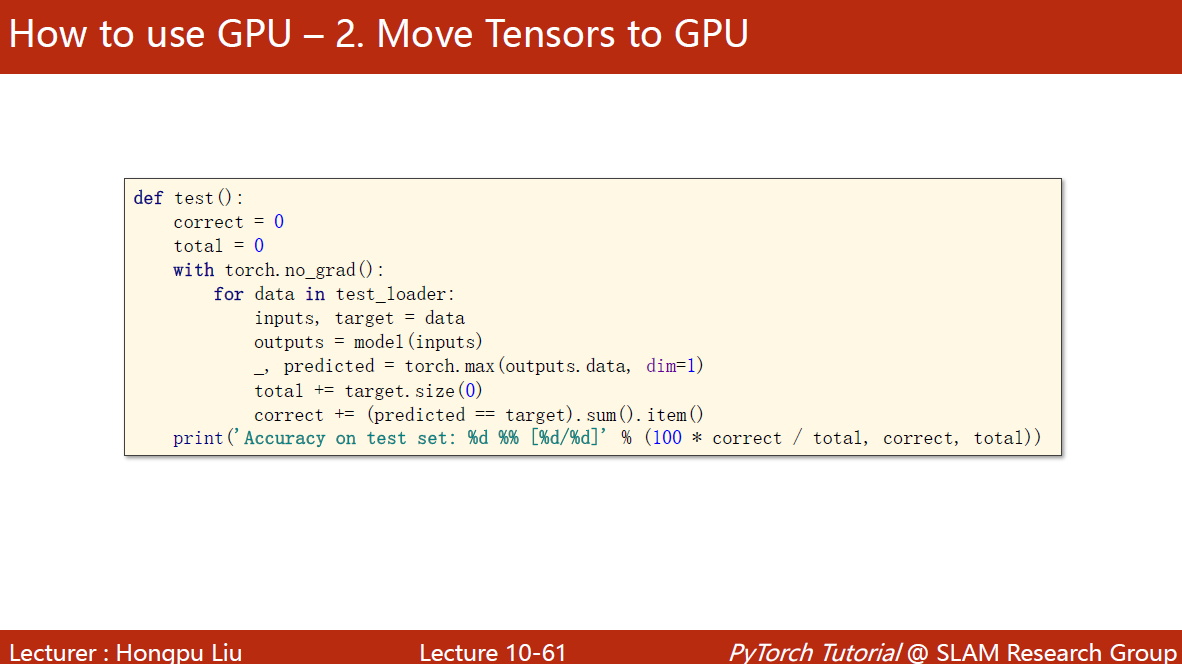
inputs, target = inputs.to(device), target.to(device)注意:模型与数据要放同一个显卡中
-
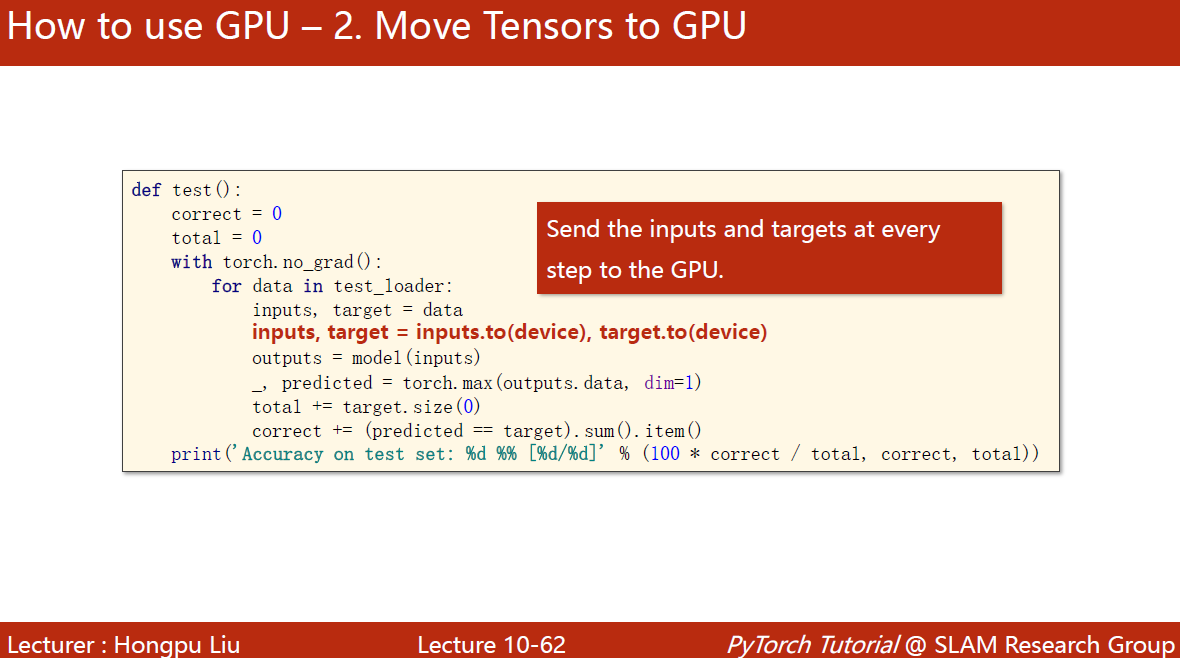
测试的时候也把数据放同一个显卡中
code
卷积神经网络,MNIST手写数字识别
# -*- encoding: utf-8 -*-"""@File : lecture_10.py @Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/2/23 20:21 ZhouCanzong 1.0 卷积神经网络 MNIST"""# import libimport torchfrom torchvision import transformsfrom torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.nn.functional as Fimport torch.optim as optim# parametersbatch_size = 64# prepare dataset# transforms.Compose是一个类,Compose()类会将transforms列表里面的transform操作进行遍历。transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design modelclass Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=3, padding=1, bias=False) # 1,28,28 self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=3, padding=1, bias=False) self.conv3 = torch.nn.Conv2d(20, 30, kernel_size=3, padding=1, bias=False) self.pooling = torch.nn.MaxPool2d(2) self.l1 = torch.nn.Linear(270, 10) # 通道数,10类 def forward(self, x): # flatten data from (n,1,28,28) to (n, 784) # print(x.shape) batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = F.relu(self.pooling(self.conv3(x))) x = x.view(batch_size, -1) # -1 此处自动算出的是270 x = self.l1(x) return xmodel = Net()# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): # 获得一个批次的数据和标签 inputs, target = data optimizer.zero_grad() # 获得模型预测结果 outputs = model(inputs) # 交叉熵代价函数 loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) running_loss = 0.0def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度 total += labels.size(0) correct += (predicted == labels).sum().item() # 张量之间的比较运算 print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__': for epoch in range(10): train(epoch) test()code
卷积神经网络,MNIST手写数字识别,GPU
# -*- encoding: utf-8 -*-"""@File : lecture_10(2).py@Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/2/25 9:12 ZhouCanzong 1.0 卷积神经网络 MNIST GPU"""# import lib# import libimport torchfrom torchvision import transformsfrom torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.nn.functional as Fimport torch.optim as optim# parametersbatch_size = 64device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# prepare dataset# transforms.Compose是一个类,Compose()类会将transforms列表里面的transform操作进行遍历。transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design modelclass Net(torch.nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=3, padding=1, bias=False) # 1,28,28 self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=3, padding=1, bias=False) self.conv3 = torch.nn.Conv2d(20, 30, kernel_size=3, padding=1, bias=False) self.pooling = torch.nn.MaxPool2d(2) self.l1 = torch.nn.Linear(270, 10) # 通道数,10类 def forward(self, x): # flatten data from (n,1,28,28) to (n, 784) # print(x.shape) batch_size = x.size(0) x = F.relu(self.pooling(self.conv1(x))) x = F.relu(self.pooling(self.conv2(x))) x = F.relu(self.pooling(self.conv3(x))) x = x.view(batch_size, -1) # -1 此处自动算出的是270 x = self.l1(x) return xmodel = Net()model.to(device=device)# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): # 获得一个批次的数据和标签 inputs, target = data inputs, target = inputs.to(device), target.to(device) optimizer.zero_grad() # 获得模型预测结果 outputs = model(inputs) # 交叉熵代价函数 loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) running_loss = 0.0def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) # dim = 1 列是第0个维度,行是第1个维度 total += labels.size(0) correct += (predicted == labels).sum().item() # 张量之间的比较运算 print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__': for epoch in range(10): train(epoch) test()卷积神经网络(高级篇)
课程链接:11.卷积神经网络(高级篇)
GoogLeNet
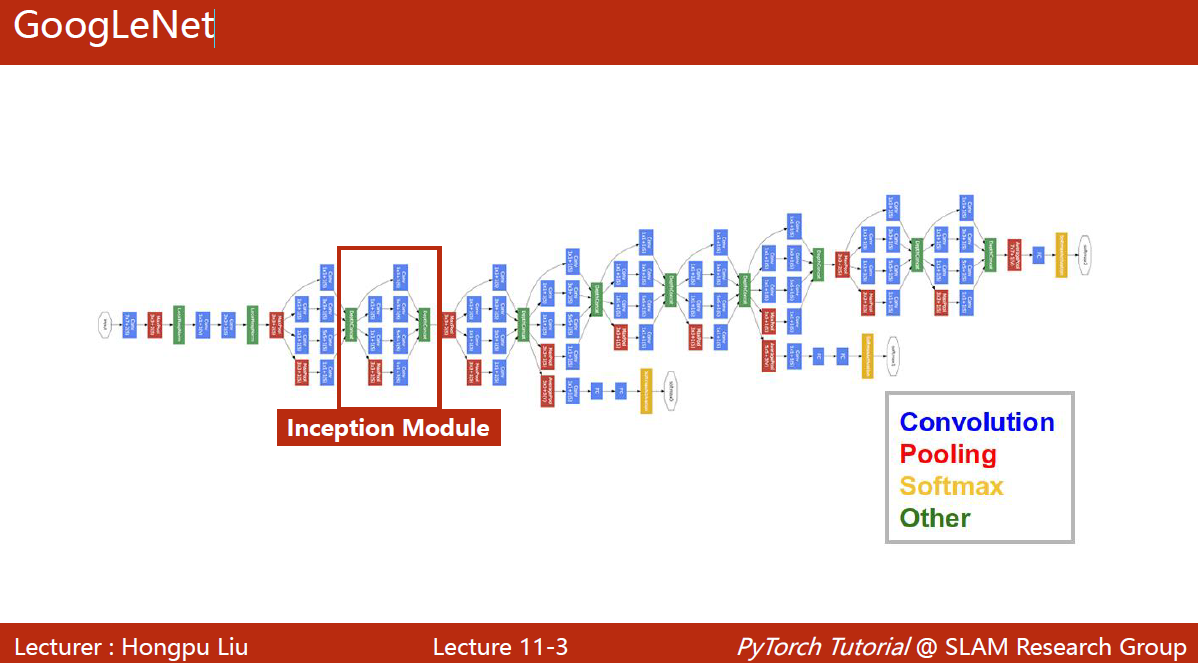
编程的时候要减少代码的冗余:函数/类
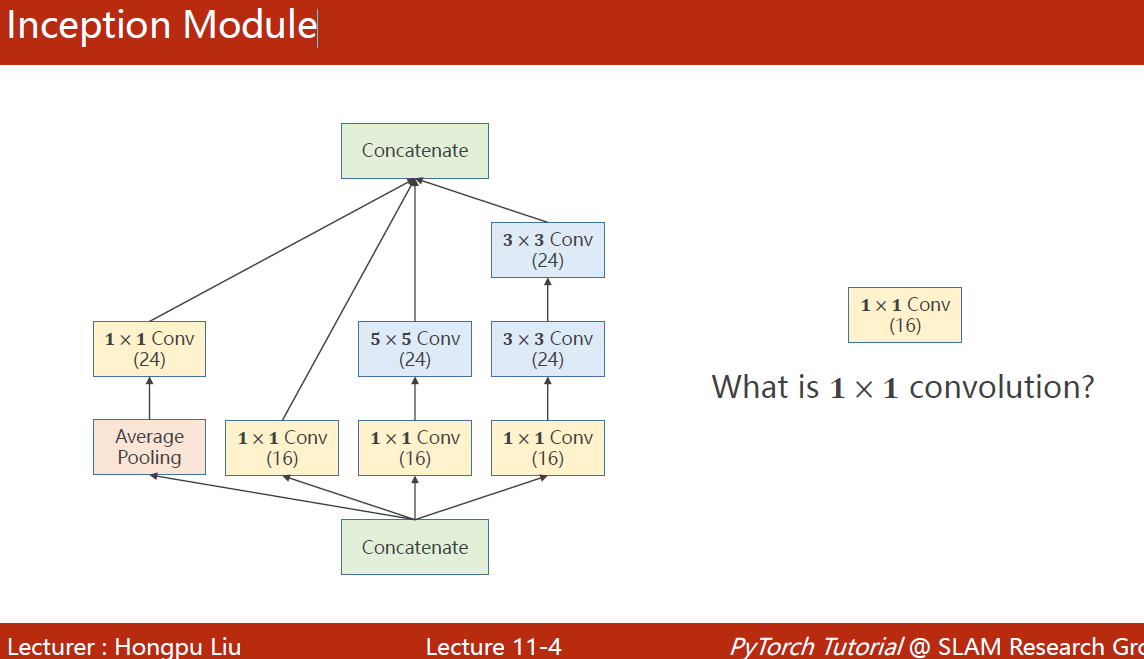
GoogLeNet:不知道哪一种卷积核好用,就都用一下,放到一起 。如果将来3×3的好用,那自然3×3的权重自然会大一些。
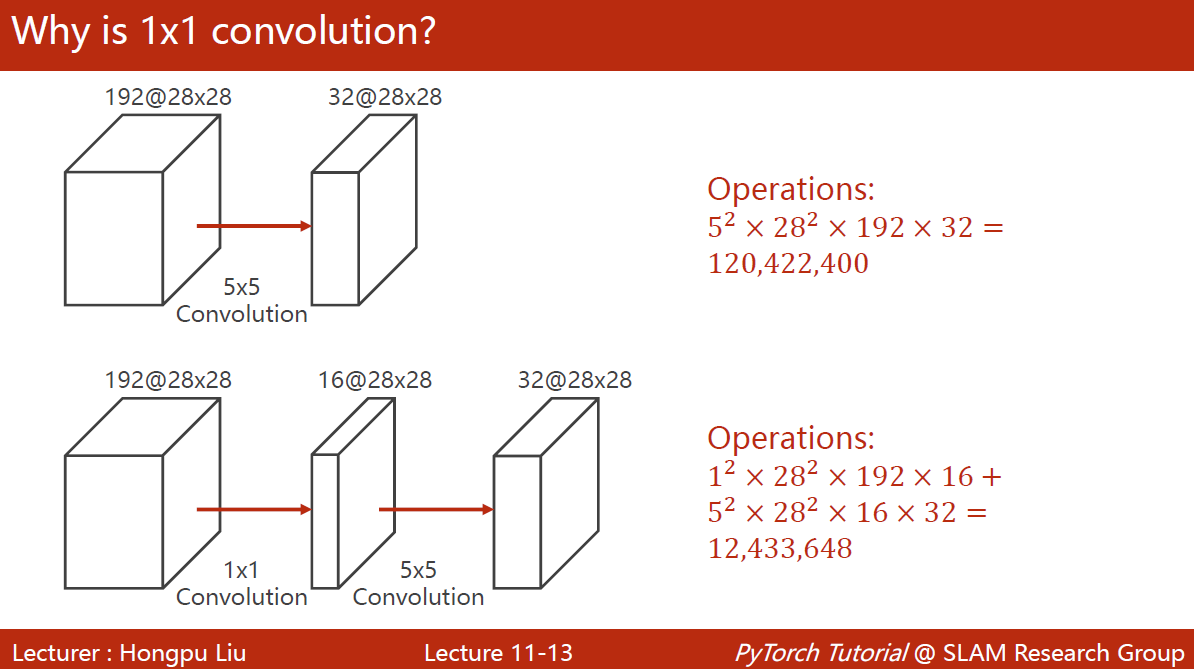
1×1的卷积:数量与通道数一致,可以遍历所有通道相同位置的信息,融合在一起。改变通道数量。——>减少计算量。被称为network in network。
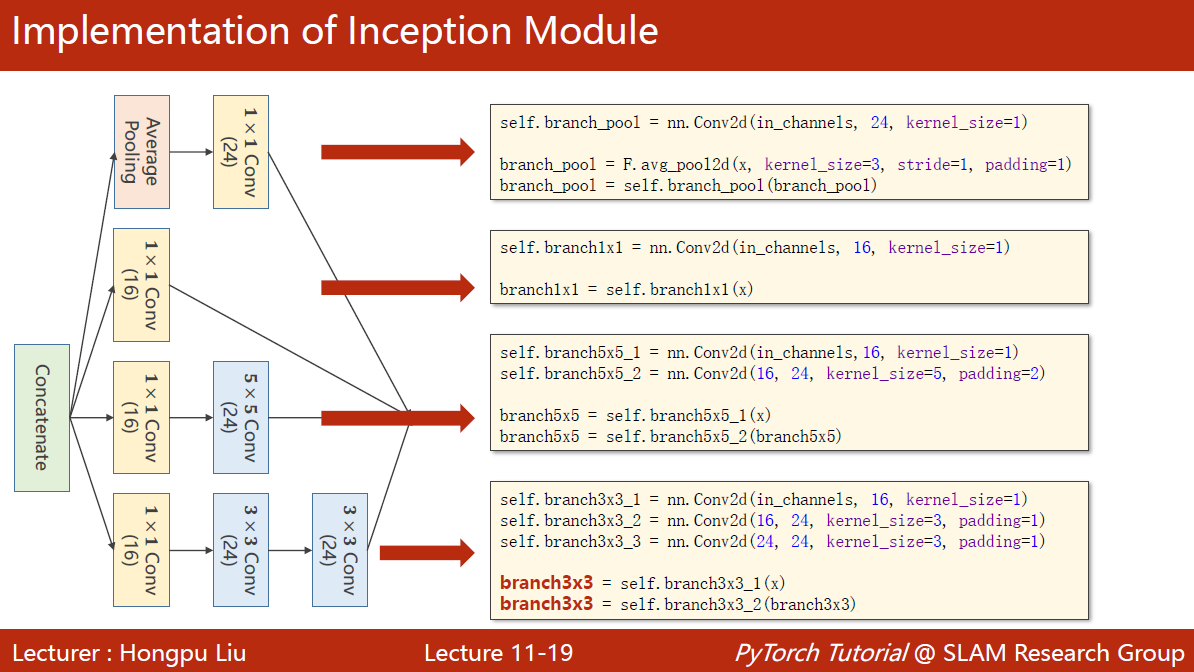
AveragePooling是没有参数的,使用函数就行了,函数原型为 F.avg_pool2d(x, kernel_size=3, stride=1, padding=1),stride=1, padding=1可以保证图像的宽度和高度不变
拼接到一起的运算叫Concatenate,函数使用方式为:
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]return torch.cat(outputs, dim= 1)沿着dimension为1的方向拼接起来,因为张量维度为b,c,w,h,要沿着channel(从0开始数)拼起来。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DMe1yaE5-1650706665881)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731546.png)]
Residual Net
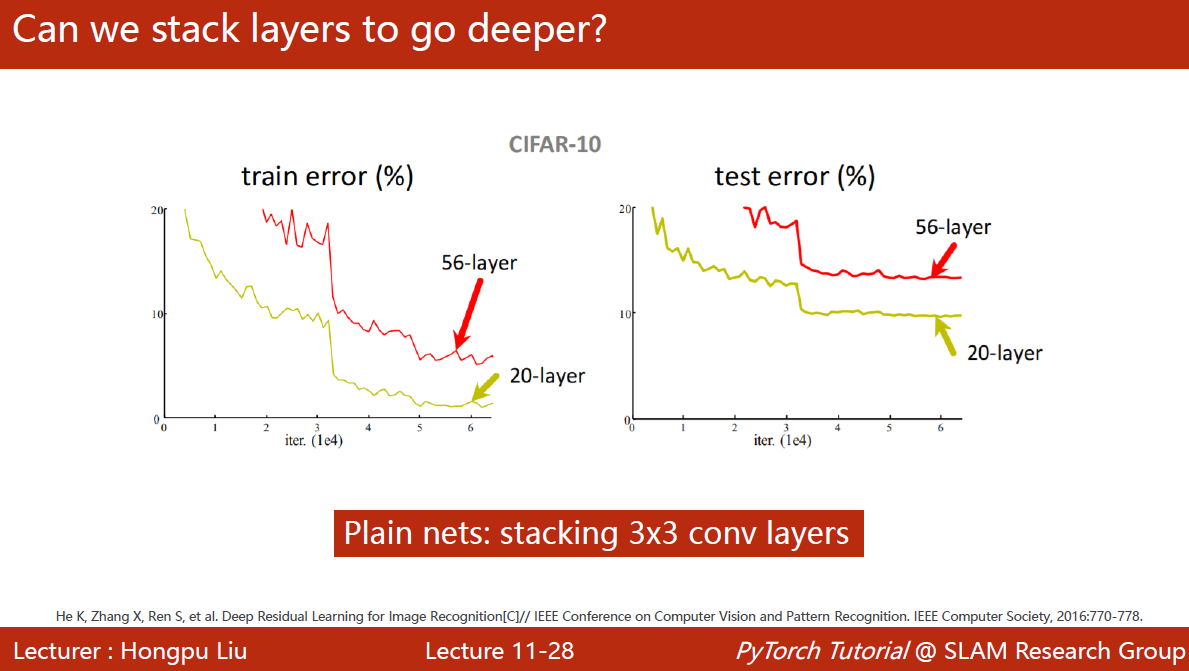
3×3网络一直叠加下去,20层要比56层要好。其中有一种可能是梯度消失
当一连串的小于1的梯度乘起来,会导致 w = w − α g w = w - \alpha g w=w−αg中的 g g g趋近于0,使得网络最开始的块没办法得到充分的训练,权重无法更新。
有一种方法是逐层训练,但是在深度神经网络里会很麻烦
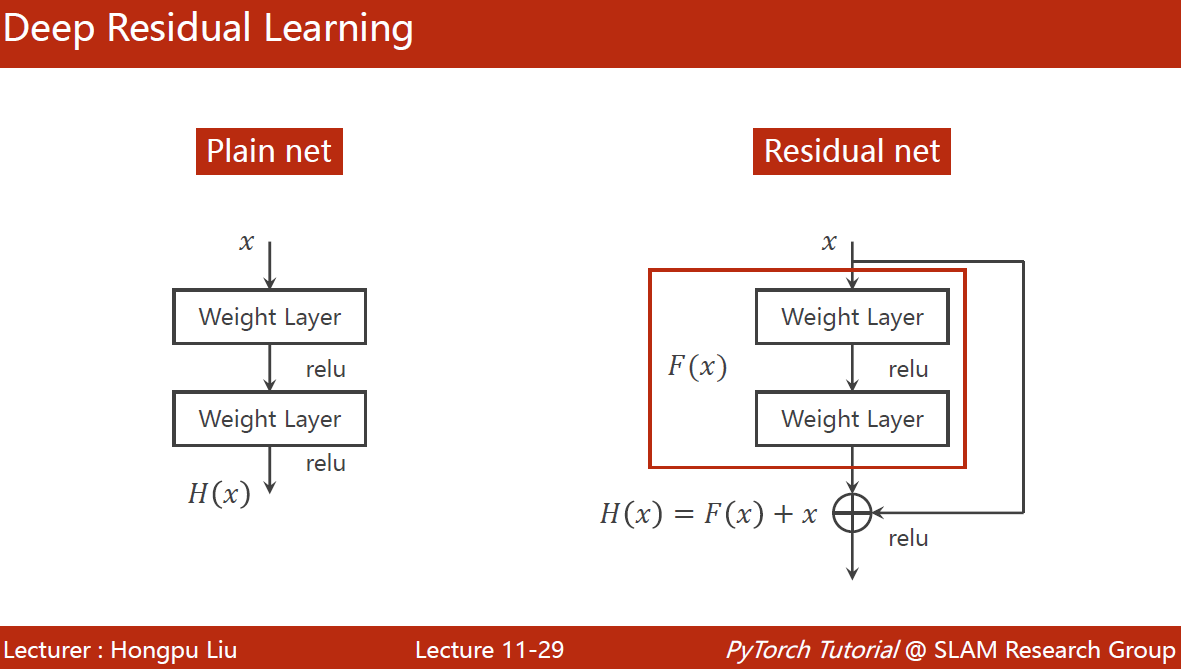
residual net使用了一种跳连接,使得反向传播时导数会>1,即便是很小的时候也会在1的附近
==注意:==这两层的输出要和x的输入张量维度要是一样的
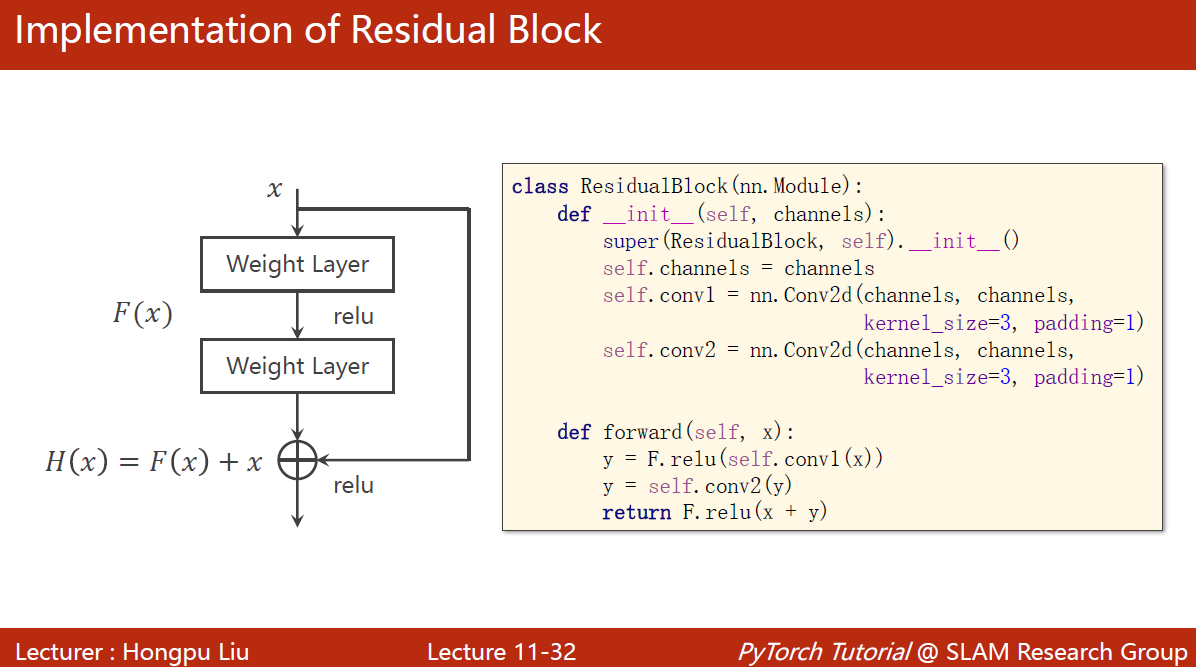
residual block的构造如上图
如果网络基本结构很复杂,则可以给它做个新的类
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Put6hw2l-1650706665882)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731550.png)]
写网络建议增量式开发,否则调试起来会很麻烦
其它一些residual block:constant scaling和conv shortcut构造方式见下图
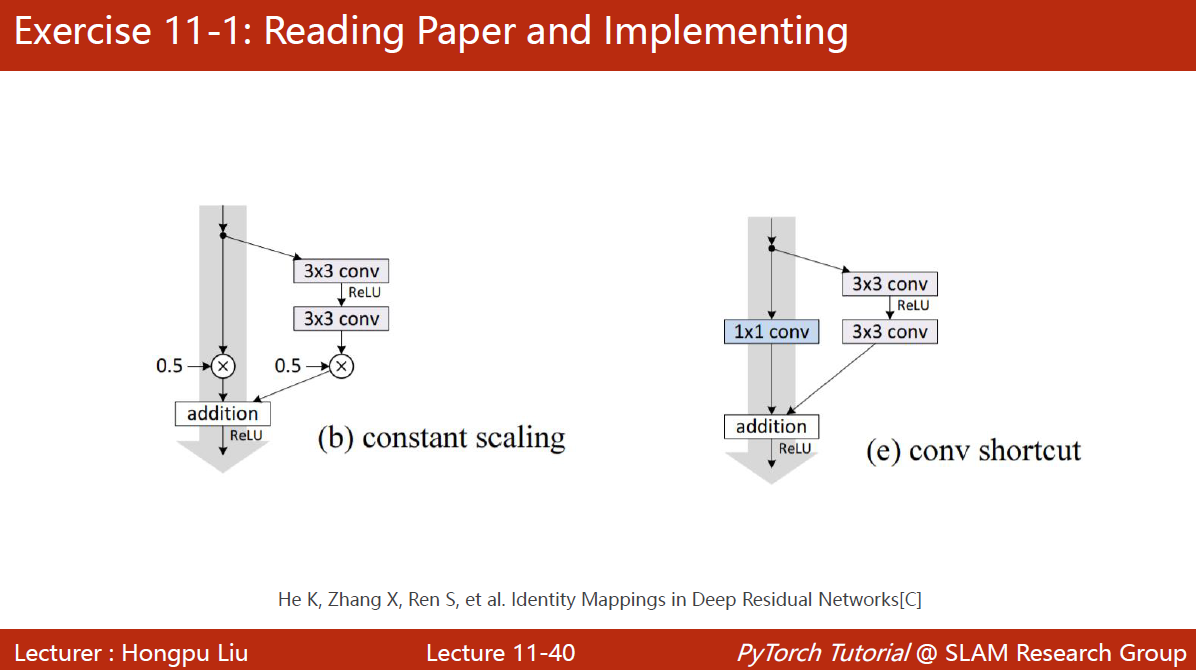
code
使用基于Inception Module的CNN实现MINIST
# -*- encoding: utf-8 -*-"""@File : lecture_11.py @Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/2/26 17:04 ZhouCanzong 1.0 使用基于Inception Module的CNN实现MINIST"""# import libimport torchimport torch.nn as nnfrom torchvision import transformsfrom torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.nn.functional as Fimport torch.optim as optim# parametersbatch_size = 64device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# prepare dataset# transforms.Compose是一个类,Compose()类会将transforms列表里面的transform操作进行遍历。transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design modelclass InceptionA(nn.Module): def __init__(self, inChannels): super(InceptionA, self).__init__() self.branch1x1 = nn.Conv2d(inChannels, 16, kernel_size=1) # 只改变channel数 self.branch5x5_1 = nn.Conv2d(inChannels, 16, kernel_size=1) self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2) self.branch3x3_1 = nn.Conv2d(inChannels, 16, kernel_size=1) self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1) self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1) self.branch_pool = nn.Conv2d(inChannels, 24, kernel_size=1) def forward(self, x): branch1x1 = self.branch1x1(x) branch5x5 = self.branch5x5_1(x) branch5x5 = self.branch5x5_2(branch5x5) branch3x3 = self.branch3x3_1(x) branch3x3 = self.branch3x3_2(branch3x3) branch3x3 = self.branch3x3_3(branch3x3) branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1) branch_pool = self.branch_pool(branch_pool) outputs = [branch1x1, branch5x5, branch3x3, branch_pool] return torch.cat(outputs, dim=1) # b,c,w,h c对应的是dim=1class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 10, kernel_size=5) self.conv2 = nn.Conv2d(88, 20, kernel_size=5) # 88 = 24x3 + 16 self.incep1 = InceptionA(inChannels=10) # 与conv1 中的10对应 channel:10to88 self.incep2 = InceptionA(inChannels=20) # 与conv2 中的20对应 channel:20to88 self.mp = nn.MaxPool2d(2) self.fc = nn.Linear(1408, 10) def forward(self, x): in_size = x.size(0) # x = (n,1,28,28) x = F.relu(self.mp(self.conv1(x))) x = self.incep1(x) x = F.relu(self.mp(self.conv2(x))) x = self.incep2(x) x = x.view(in_size, -1) x = self.fc(x) return xmodel = Net()model.to(device=device)# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data inputs, target = inputs.to(device), target.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) running_loss = 0.0def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__': for epoch in range(10): train(epoch) test()code
使用基于ResidualBlock的CNN实现MINIST
# -*- encoding: utf-8 -*-"""@File : lecture_11(2).py @Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/2/28 22:19 ZhouCanzong 1.0 使用基于ResidualBlock的CNN实现MINIST"""# import libimport torchimport torch.nn as nnfrom torchvision import transformsfrom torchvision import datasetsfrom torch.utils.data import DataLoaderimport torch.nn.functional as Fimport torch.optim as optim# parametersbatch_size = 64device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# prepare datasettransform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))]) # 归一化,均值和方差train_dataset = datasets.MNIST(root='../dataset/mnist/', train=True, download=True, transform=transform)train_loader = DataLoader(train_dataset, shuffle=True, batch_size=batch_size)test_dataset = datasets.MNIST(root='../dataset/mnist/', train=False, download=True, transform=transform)test_loader = DataLoader(test_dataset, shuffle=False, batch_size=batch_size)# design modelclass ResidualBlock(nn.Module): def __init__(self, channels): super(ResidualBlock, self).__init__() self.channels = channels self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1) def forward(self, x): y = F.relu(self.conv1(x)) y = self.conv2(y) return F.relu(x + y)class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.conv1 = nn.Conv2d(1, 16, kernel_size=5) self.conv2 = nn.Conv2d(16, 32, kernel_size=5) # 88 = 24x3 + 16 self.rblock1 = ResidualBlock(16) self.rblock2 = ResidualBlock(32) self.mp = nn.MaxPool2d(2) self.fc = nn.Linear(512, 10) def forward(self, x): in_size = x.size(0) x = self.mp(F.relu(self.conv1(x))) x = self.rblock1(x) x = self.mp(F.relu(self.conv2(x))) x = self.rblock2(x) x = x.view(in_size, -1) x = self.fc(x) return xmodel = Net()model.to(device=device)# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = optim.SGD(model.parameters(), lr=0.01, momentum=0.5)# training cycle forward, backward, updatedef train(epoch): running_loss = 0.0 for batch_idx, data in enumerate(train_loader, 0): inputs, target = data inputs, target = inputs.to(device), target.to(device) optimizer.zero_grad() outputs = model(inputs) loss = criterion(outputs, target) loss.backward() optimizer.step() running_loss += loss.item() if batch_idx % 300 == 299: print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300)) running_loss = 0.0def test(): correct = 0 total = 0 with torch.no_grad(): for data in test_loader: images, labels = data images, labels = images.to(device), labels.to(device) outputs = model(images) _, predicted = torch.max(outputs.data, dim=1) total += labels.size(0) correct += (predicted == labels).sum().item() print('accuracy on test set: %d %% ' % (100 * correct / total))if __name__ == '__main__': for epoch in range(10): train(epoch) test() 循环神经网络(基础篇)
课程链接:12.循环神经网络(基础篇)
全连接网络也叫,Dense 稠密网络、Deep
全连接层参数比较多,用来做与序列模式有关的预测比较耗资源
具有序列关系:天气、自然语言
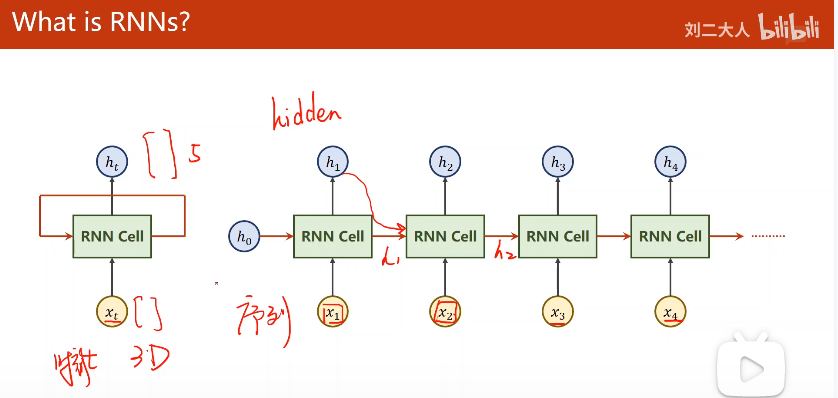
RNN使用了一种参数共享的思路
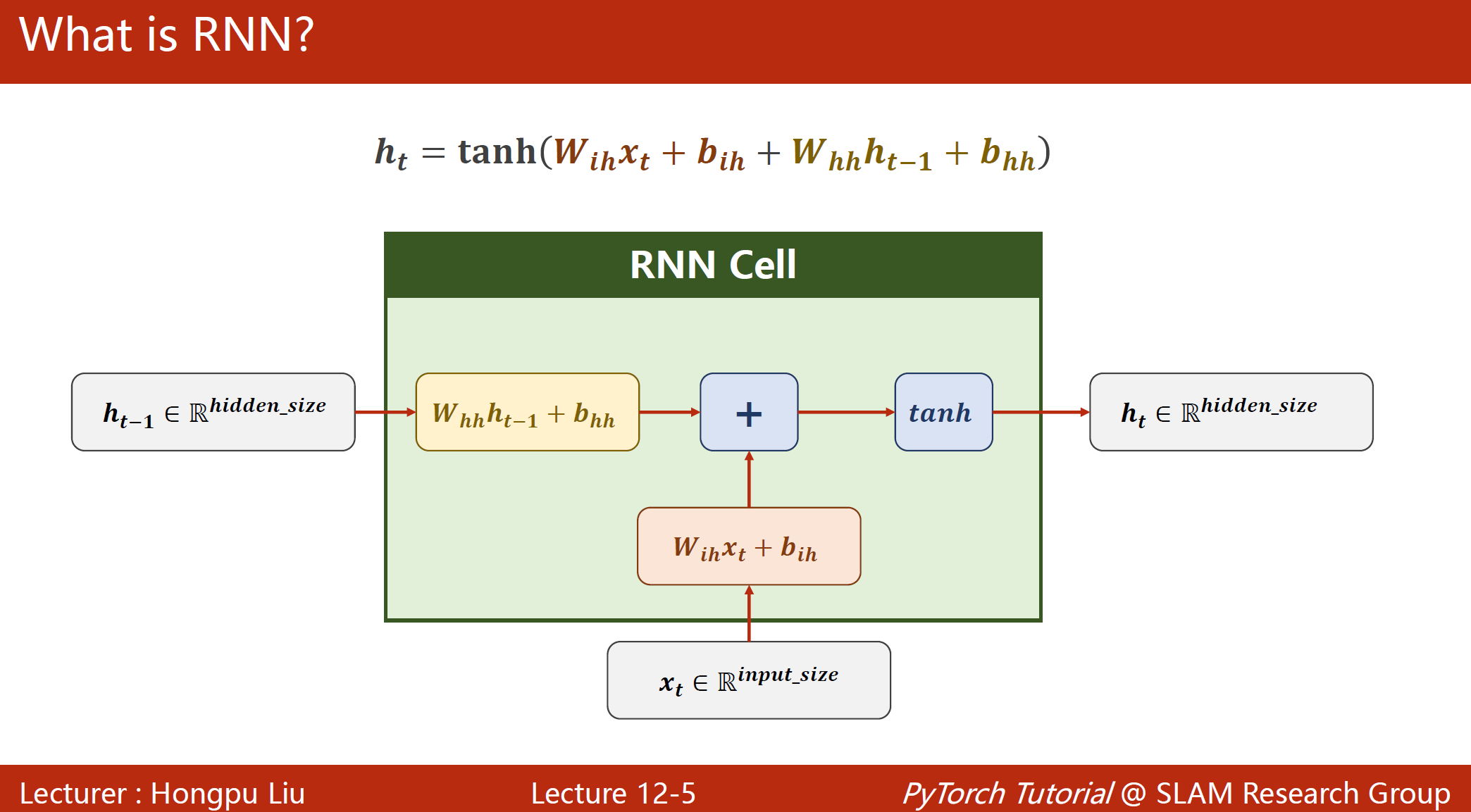
RNN Cell本质上还是一个线性层,只不过是参数共享的
因为tanh是-1到+1之间的,因此觉得tanh有更好的性能,循环神经网络中常用tanh
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-u2aLc8DR-1650706665883)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731554.png)]
两个hidden_size的向量进行融合的时候,常拼一起进行计算

关键在于弄清楚张量维度

dataset把seqlen(序列长度)放最前面,是循环的时候每次拿出当前时刻t的一组张量,比较符合理解

简单的一个示例,理解其中的维度。
RNN的运算比较耗时,因此要注意长度
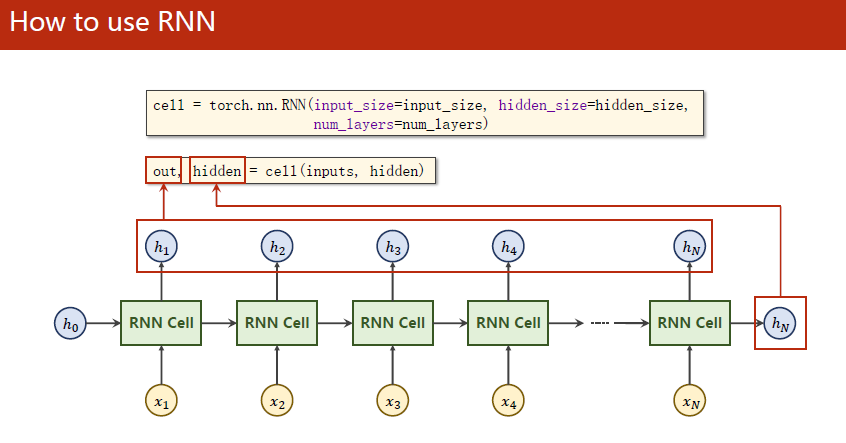
注意cell的输出有两个,一个是out,一个是hidden
给定h0之后,RNN会自动循环,不需要我们自己操作

numlayers指几层的RNN,如下图所示
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JfgzlTPq-1650706665884)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731560.png)]
注意:同样颜色的是同一个RNNcell,如上图只有3个RNNcell
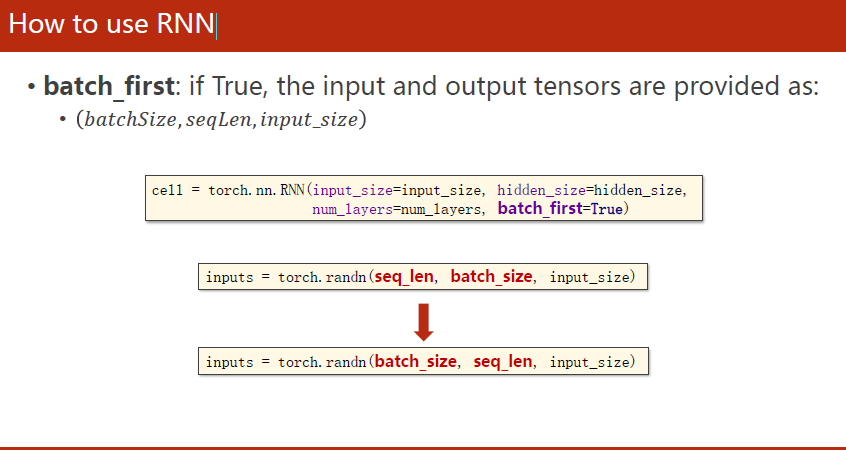
==注意:==当设置了batch_first的时候,需要调整一下输入输出张量维度的顺序
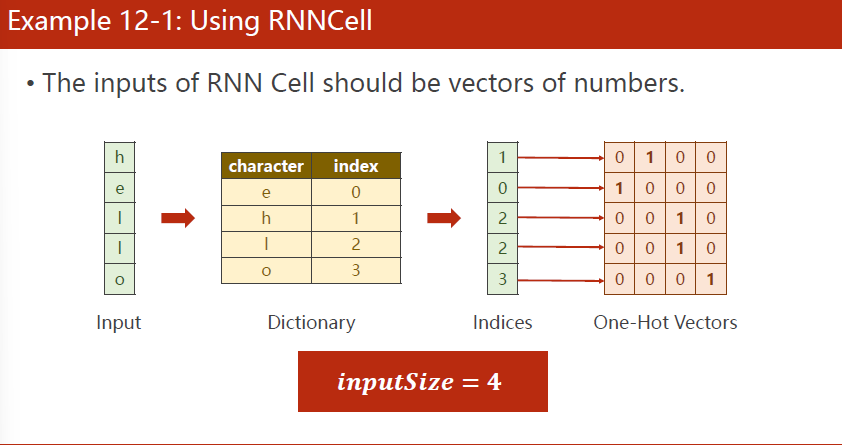
自然语言处理的时候一般先根据字符构造词典,给每个词分配一个索引,得到索引后根据词典,将词变成相应的索引,然后变成向量(one-hot独热编码)。input_size与独热编码维度有关。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EurhIUOJ-1650706665884)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731563.png)]
输出是一个4维的向量,之后接一个交叉熵,就能训练了
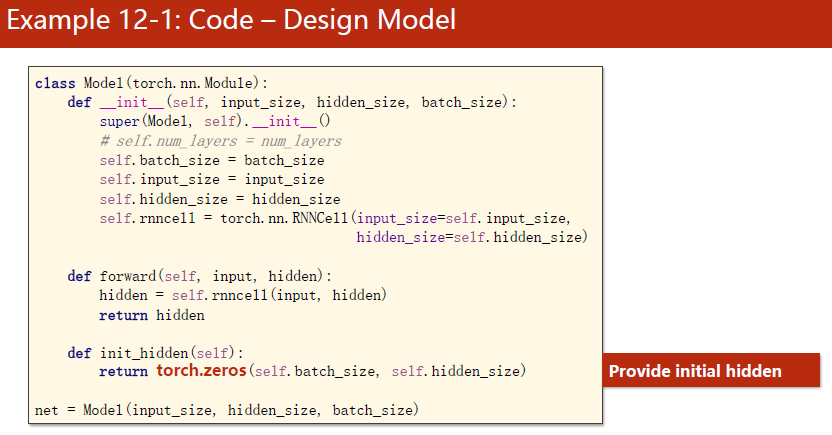
model中定义一个工具,init_hidden,提供初始工具h0,实际上就是构造一个全0的初始隐层。batch_size这个也就只在构造h0的时候用一下。
如果是之前RNN不使用seqlen参数的方法:
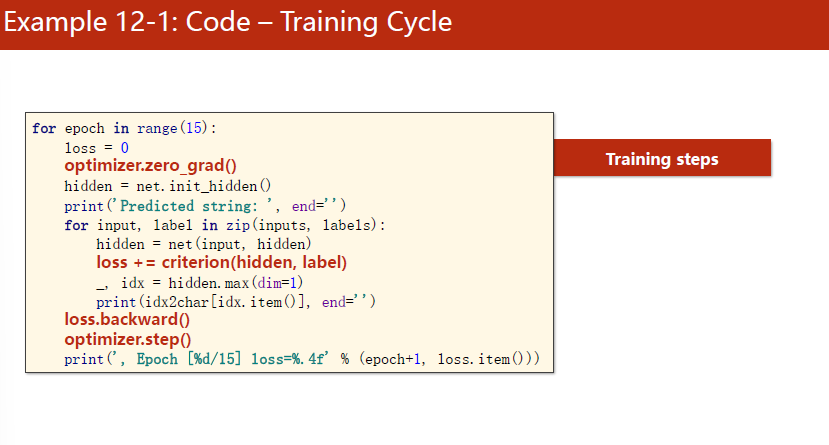
训练的时候,记得先把梯度归零,然后初始化h0。写循环的时候,注意inputs是seq,batch,input_size。
- Shape of inputs:(seqLen,batchSize,inputSize)
- Shape of input:(batchSize,hiddenSize)
- Shape of labels:(seqSize,1)
- Shape of label:(1)
==注意:==loss没有写.item(),因为损失是整个序列相加的和是最终损失,而这个是需要构造计算图的。
如果是现在用RNN使用seqlen参数的方法:

就不必在epoch中进行再一次的循环,RNN会自己完成。
模型改为如下所示:
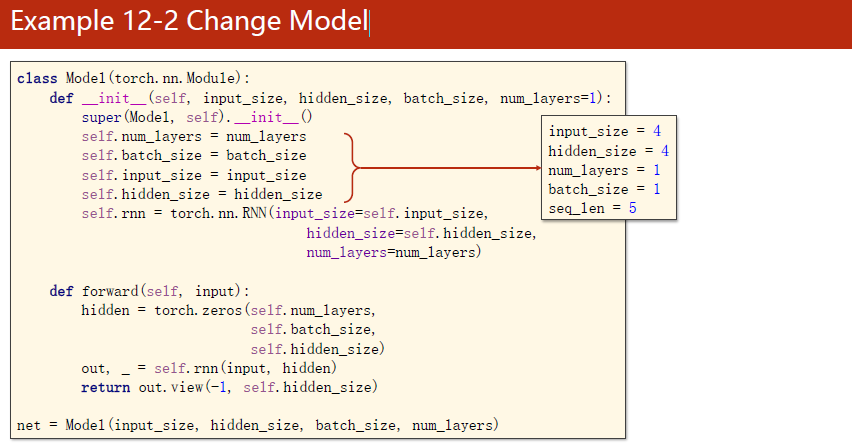
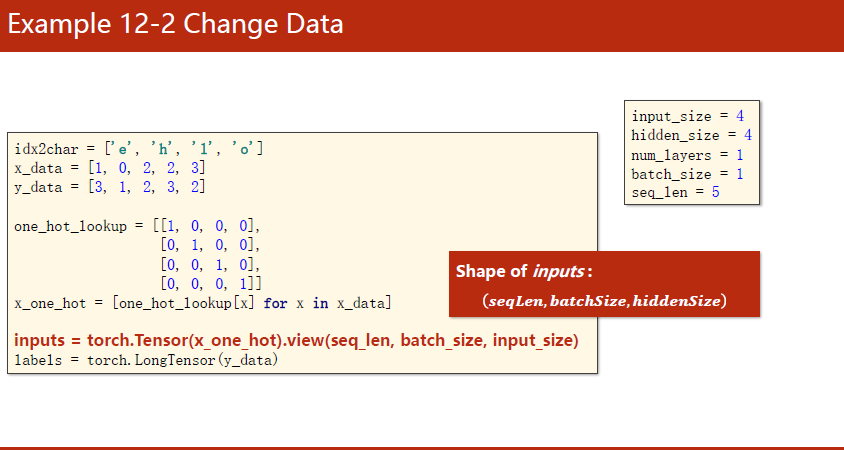
在模型中定义好num_layers。out,__=self.rnn(input,hidden)的主要目的是Reshape out to:(seqLen X batchSize,hiddenSize),变为两维的。目的是在计算交叉熵的时候变成了一个矩阵,labels也要变成(seqLen X batchSize,1),如下图所示:

one-hot编码有如下特点:
- The one-hot vectors are high-dimension.太高维会引起“维度的诅咒”
- The one-hot vectors are sparse. 稀疏
- The one-hot vectors are hardcoded.硬编码的,不是学习出来的
而我们想要的是低维度的、稠密的、可学习的
比较受欢迎的是EMBEDDING(嵌入层),把高维稀疏的样本映射到低维稠密的空间里。——>数据降维
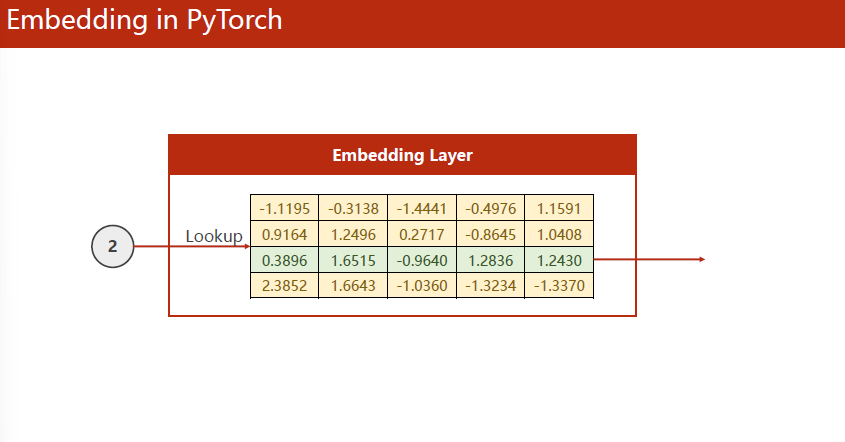
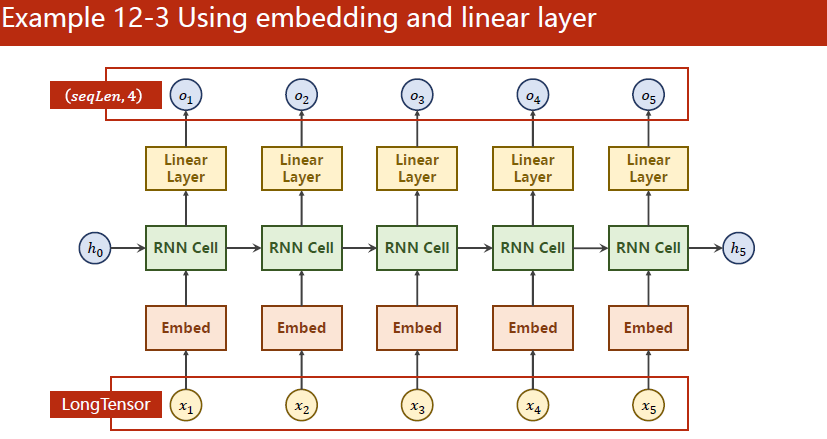
这时候隐层维度与要输出的结果不一样了,可以加个线性层。

embedding层主要需要初始化num_embedding(embedding字典的尺寸,input的独热向量是几维的)、embedding_dim。这两个就构成了矩阵的高度和宽度。
线性层、交叉熵可以支持RNN的维度来变换的,如下图所示

embedding的使用见图

LSTM见下图
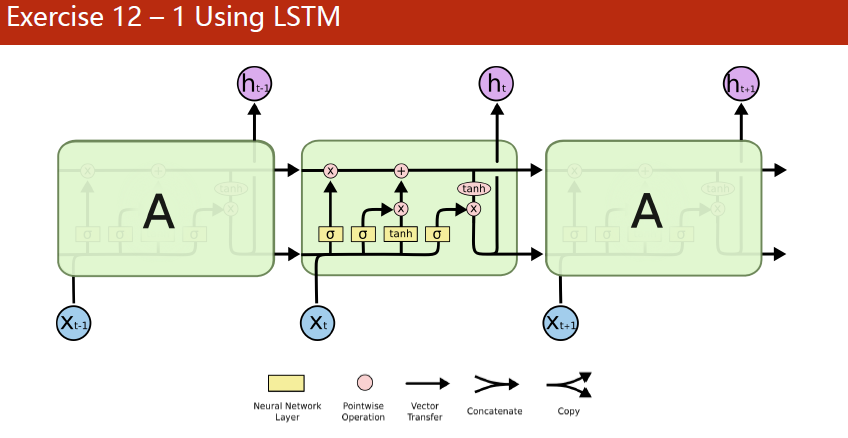
看起来结构复杂,但实际上都是这几条公式
i t = σ ( W i ix t + b i i + W h ih ( t − 1 ) + b h i ) f t = σ ( W i fx t + b i f + W h fh ( t − 1 ) + b h f ) g t = tanh ( W i gx t + b i g + W h gh ( t − 1 ) + b h g ) o t = σ ( W i ox t + b i o + W h oh ( t − 1 ) + b h o ) c t = f t c ( t − 1 ) + i t g t h t = o t tanh ( c t ) \begin{aligned} &i_{t}=\sigma\left(W_{i i} x_{t}+b_{i i}+W_{h i} h_{(t-1)}+b_{h i}\right) \\ &f_{t}=\sigma\left(W_{i f} x_{t}+b_{i f}+W_{h f} h_{(t-1)}+b_{h f}\right) \\ &g_{t}=\tanh \left(W_{i g} x_{t}+b_{i g}+W_{h g} h_{(t-1)}+b_{h g}\right) \\ &o_{t}=\sigma\left(W_{i o} x_{t}+b_{i o}+W_{h o} h_{(t-1)}+b_{h o}\right) \\ &c_{t}=f_{t} c_{(t-1)}+i_{t} g_{t} \\ &h_{t}=o_{t} \tanh \left(c_{t}\right) \end{aligned} it=σ(Wiixt+bii+Whih(t−1)+bhi)ft=σ(Wifxt+bif+Whfh(t−1)+bhf)gt=tanh(Wigxt+big+Whgh(t−1)+bhg)ot=σ(Wioxt+bio+Whoh(t−1)+bho)ct=ftc(t−1)+itgtht=ottanh(ct)
遗忘门本质上可能是旁路连接减少梯度消失
pytorch的LSTM输入有h_0,c_0,输出有h_n,c_n参数
LSTM计算比较复杂,时间复杂度高。
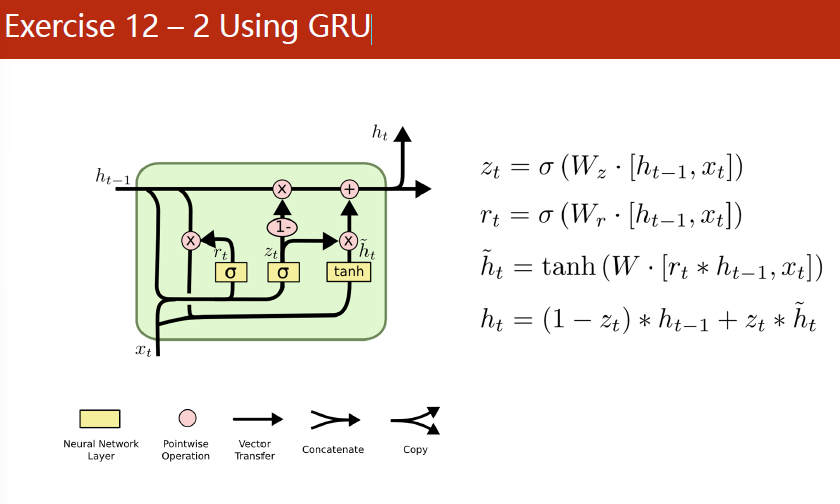
如果想在RNN和LSTM中求取一个平衡,可以考虑GRU
code
使用RNN 将hello映射为ohlolm,不使用seqlen参数
# -*- encoding: utf-8 -*-"""@File : lecture_12.py @Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/3/18 16:29 ZhouCanzong 1.0 使用RNN 将hello映射为ohlol 不使用seqlen参数"""# import libimport torchimport torch.nn as nn# parametersinput_size = 4hidden_size = 4batch_size = 1epochs = 15# prepare datasetidx2char = ['e', 'h', 'l', 'o']x_data = [1, 0, 2, 3, 3] # hello中各个字符的下标y_data = [3, 1, 2, 3, 2] # ohlol中各个字符的下标one_hot_lookup = [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]]x_one_hot = [one_hot_lookup[x] for x in x_data] # (seqLen, inputSize)inputs = torch.Tensor(x_one_hot).view(-1, batch_size, input_size)labels = torch.LongTensor(y_data).view(-1, 1) # torch.Tensor默认是torch.FloatTensor是32位浮点类型数据,torch.LongTensor是64位整型# print(inputs.shape, labels.shape)# design modelclass Model(nn.Module): def __init__(self, input_size, hidden_size, batch_size): super(Model, self).__init__() self.batch_size = batch_size self.input_size = input_size self.hidden_size = hidden_size self.rnncell = nn.RNNCell(input_size=self.input_size, hidden_size=self.hidden_size) def forward(self, inputs, hidden): hidden = self.rnncell(inputs, hidden) # (batch_size, hidden_size) return hidden def init_hidden(self): return torch.zeros(self.batch_size, self.hidden_size)net = Model(input_size, hidden_size, batch_size)# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.1)# training cycle forward, backward, updatedef train(): for epoch in range(epochs): loss = 0 optimizer.zero_grad() hidden = net.init_hidden() print('Predicted string:', end='') for input, label in zip(inputs, labels): hidden = net(input, hidden) # 注意交叉熵在计算loss的时候维度关系,这里的hidden是([1, 4]), label是 ([1]) loss += criterion(hidden, label) _, idx = hidden.max(dim=1) print(idx2char[idx.item()], end='') loss.backward() optimizer.step() print(', Epoch [%d/15] loss=%.4f' % (epoch + 1, loss.item()))# mainif __name__ == '__main__': train()结果
Predicted: loloh, Epoch [1/15] loss = 1.321......Predicted: ohlol, Epoch [14/15] loss = 0.440Predicted: ohlol, Epoch [15/15] loss = 0.425code
使用RNN 将hello映射为ohlolm,使用seqlen参数
# -*- encoding: utf-8 -*-"""@File : lecture_11.py@Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/2/26 17:04 ZhouCanzong 1.0 使用RNN 将hello映射为ohlol"""# import libimport torchimport torch.nn as nn# parametersinput_size = 4hidden_size = 4batch_size = 1seq_len = 5num_layers = 1epochs = 15# prepare datasetidx2char = ['e', 'h', 'l', 'o']x_data = [1, 0, 2, 3, 3] # hello中各个字符的下标y_data = [3, 1, 2, 3, 2] # ohlol中各个字符的下标one_hot_lookup = [[1, 0, 0, 0], [0, 1, 0, 0], [0, 0, 1, 0], [0, 0, 0, 1]]x_one_hot = [one_hot_lookup[x] for x in x_data] # (seqLen, inputSize)inputs = torch.Tensor(x_one_hot).view(seq_len, batch_size, input_size)labels = torch.LongTensor(y_data)# print(x_one_hot)# print(inputs.shape, labels.shape)# design modelclass Model(nn.Module): def __init__(self, input_size, hidden_size, batch_size, num_layers=1): super(Model, self).__init__() self.num_layers = num_layers self.batch_size = batch_size self.input_size = input_size self.hidden_size = hidden_size self.rnn = nn.RNN(input_size=self.input_size, hidden_size=self.hidden_size, ) def forward(self, inputs): hidden = torch.zeros(self.num_layers, self.batch_size, self.hidden_size) out, _ = self.rnn(inputs, hidden) # 注意维度是(seqLen, batch_size, hidden_size) return out.view(-1, self.hidden_size) # 为了容易计算交叉熵这里调整维度为(seqLen * batch_size, hidden_size)net = Model(input_size, hidden_size, batch_size)# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.1)# training cycle forward, backward, updatefor epoch in range(epochs): optimizer.zero_grad() outputs = net(inputs) # print(outputs.shape, labels.shape) # 这里的outputs维度是([seqLen * batch_size, hidden]), labels维度是([seqLen]) loss = criterion(outputs, labels) loss.backward() optimizer.step() _, idx = outputs.max(dim=1) idx = idx.data.numpy() print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='') print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))code
使用RNN 将hello映射为ohlolm,使用Embedding
# -*- encoding: utf-8 -*-"""@File : lecture_12(3).py @Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/3/18 16:58 ZhouCanzong 1.0 None"""# import libimport torchimport torch.nn as nn# parametersnum_class = 4input_size = 4hidden_size = 8embedding_size = 10num_layers = 2batch_size = 1seq_len = 5epochs = 15# prepare datasetidx2char = ['e', 'h', 'l', 'o']x_data = [[1, 0, 2, 2, 3]] # (batch, seq_len)y_data = [3, 1, 2, 3, 2] # (batch * seq_len)inputs = torch.LongTensor(x_data) # Input should be LongTensor: (batchSize, seqLen)labels = torch.LongTensor(y_data) # Target should be LongTensor: (batchSize * seqLen)# print(inputs.shape, labels.shape)# design modelclass Model(nn.Module): def __init__(self): super(Model, self).__init__() self.emb = torch.nn.Embedding(input_size, embedding_size) self.rnn = nn.RNN(input_size=embedding_size, hidden_size=hidden_size, num_layers=num_layers, batch_first=True) self.fc = nn.Linear(hidden_size, num_class) def forward(self, x): hidden = torch.zeros(num_layers, x.size(0), hidden_size) x = self.emb(x) # (batch, seqLen, embeddingSize) x, _ = self.rnn(x, hidden) # 输出(𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆, 𝒔𝒆𝒒𝑳𝒆𝒏, hidden_size) x = self.fc(x) # 输出(𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆, 𝒔𝒆𝒒𝑳𝒆𝒏, 𝒏𝒖𝒎𝑪𝒍𝒂𝒔𝒔) return x.view(-1, num_class) # reshape to use Cross Entropy: (𝒃𝒂𝒕𝒄𝒉𝑺𝒊𝒛𝒆×𝒔𝒆𝒒𝑳𝒆𝒏, 𝒏𝒖𝒎𝑪𝒍𝒂𝒔𝒔)net = Model()# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(net.parameters(), lr=0.1)# training cycle forward, backward, updatedef train(): for epoch in range(epochs): optimizer.zero_grad() outputs = net(inputs) loss = criterion(outputs, labels) loss.backward() optimizer.step() _, idx = outputs.max(dim=1) idx = idx.data.numpy() print('Predicted: ', ''.join([idx2char[x] for x in idx]), end='') print(', Epoch [%d/15] loss = %.3f' % (epoch + 1, loss.item()))# mainif __name__ == '__main__': train()结果
Predicted: ohehh, Epoch [1/15] loss = 1.446Predicted: ohlol, Epoch [2/15] loss = 0.927收敛得比前两个方法快很多
循环神经网络(高级篇)
课程链接:13.循环神经网络(高级)
当在自然语言处理中,序列长短,输出难以确定。
可以使用以下这种结构
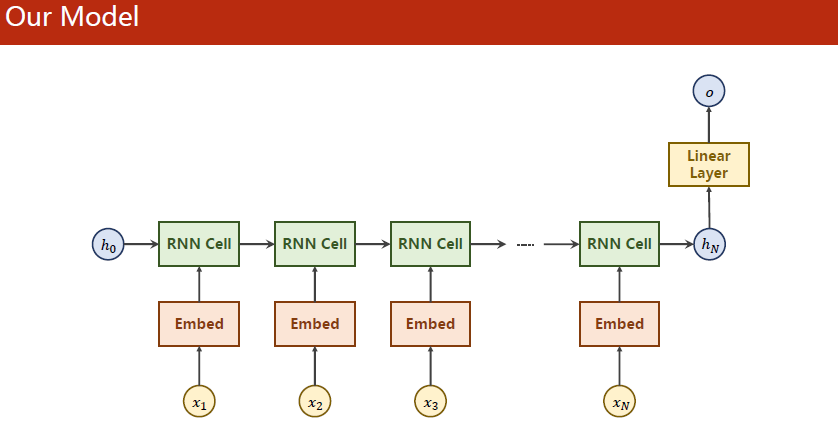
实现一个名字到国家的分类
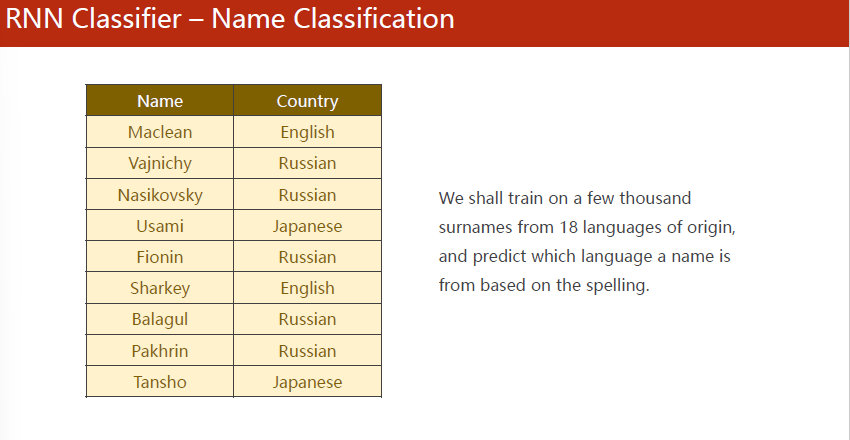
首先要将名字分离,并做词典(这里都是字符,可用ascii码表)
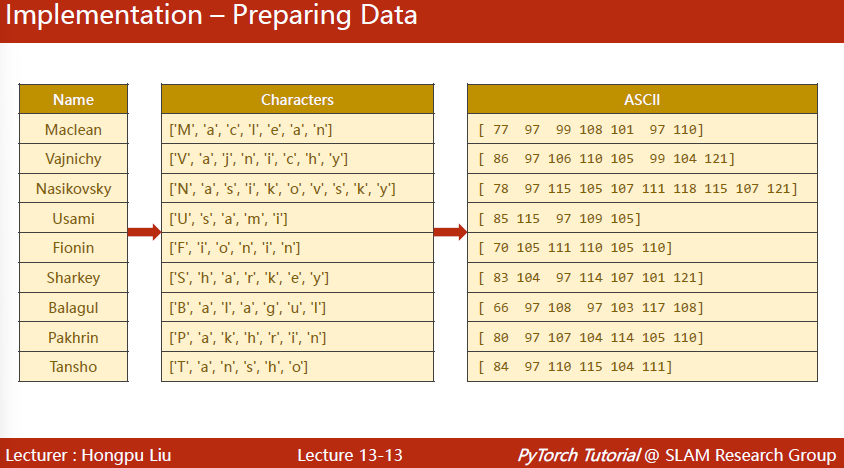 表中的“数字”并不是数字,而是一个128维的向量。但是对于embedding层来说,只需要告诉它第几维为1就行了。因此这里直接放ascii码值。
表中的“数字”并不是数字,而是一个128维的向量。但是对于embedding层来说,只需要告诉它第几维为1就行了。因此这里直接放ascii码值。
第二个问题是序列长短不一,我们需要做个padding。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-onH53SO7-1650706665887)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731580.png)]
接下来要对国家转成一个分类索引
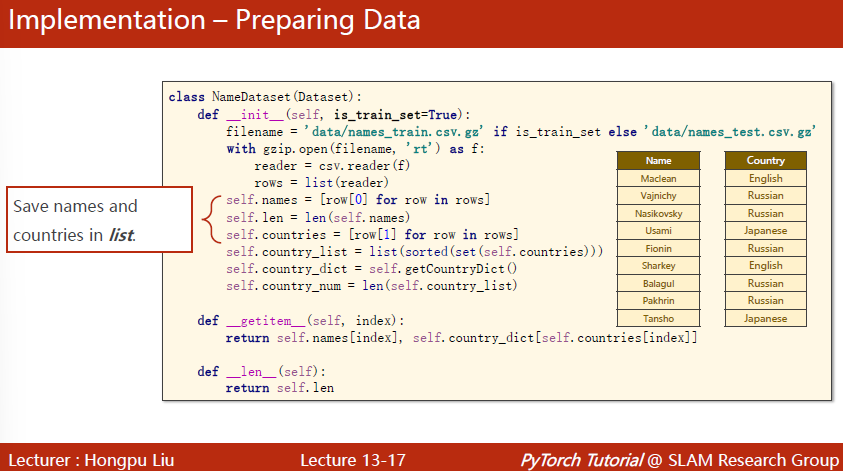
在init中,因为名字占用内存不多,可以直接一次性读进来。
读zip文件可以使用gzip.open,之后可以csv.reader读csv文件。针对不同格式(pickle/HDFS/HD5)用不同的包来读取。
行里面的信息是一个个的元组(name,country)
但是我们要对country做一个索引,set就是把列表变成集合,去除重复的元素,每个country只存在一个实例。接着排序,做成一个列表。接下来调用getCountry,将列表做成一个字典。
getitem中返回的时候返回两项,是输入样本name,输入样本country中的index。一个字符串和一个国家的索引。
getCountryDict很好实现:
def getCountryDict(self): country_dictdict() for idx,country_name in enumerate(self.country_list,0): country_dict[country_name]=idxreturn country_dict构建dataset实例,用dataloader来构建加载器
N_country作为一个常量,表示的是最后模型输出的维度
GRU中的bidirection参数表明这个是单向还是双向。双向2否则1
单向的RNNcell只包含过去的信息,但是自然语音处理等场景还包括未来的信息
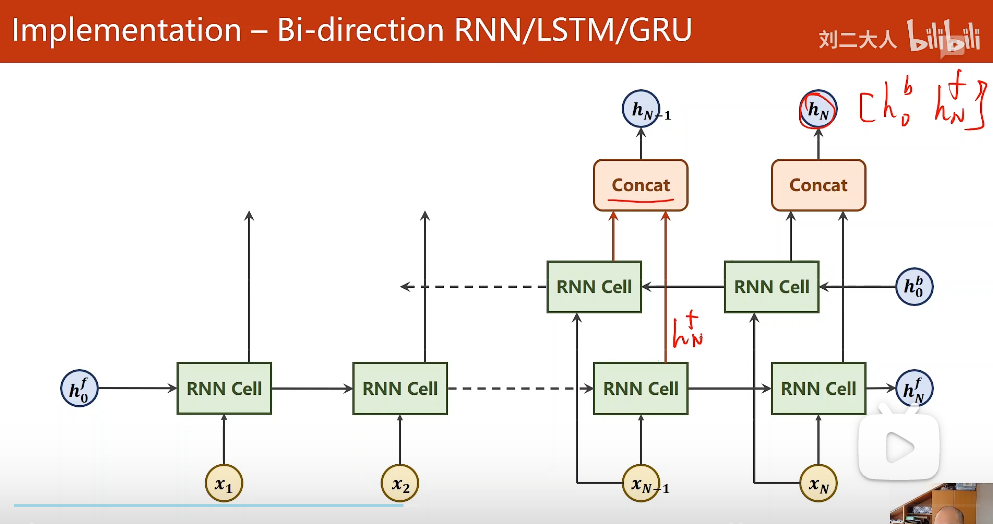
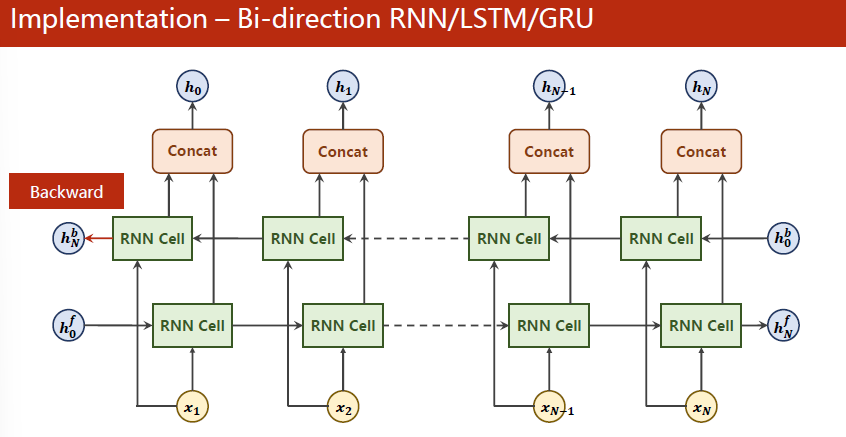
输出的时候有out和hidden,hidden包括两项
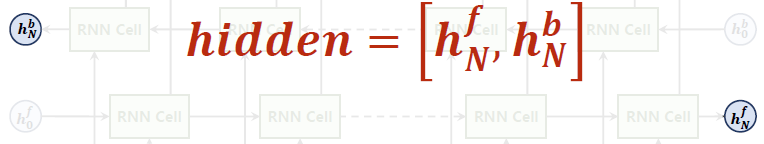
GRU有一种提速方式:pack_padded_sequence(embedding, seq_lengths),尤其是面对序列长短不一的情况下。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-j9R35KHc-1650706665888)(https://gitee.com/zhoucanzong/blogimage/raw/master/202204231731585.png)]
把所有为0的填充全去掉
但是这样无法打包,因为打包的程序里是按序列长短降序排列
要想使用,需要序列长度的数据seq_lengths
最后实现的模型如下图所示:
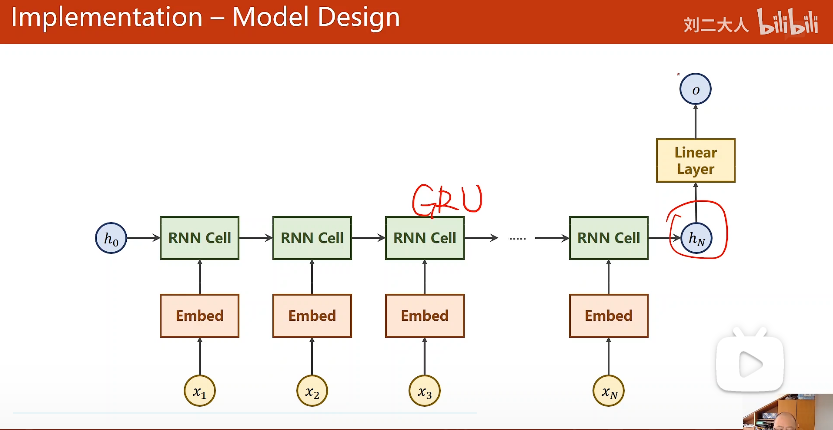
隐层输出再加个线性层
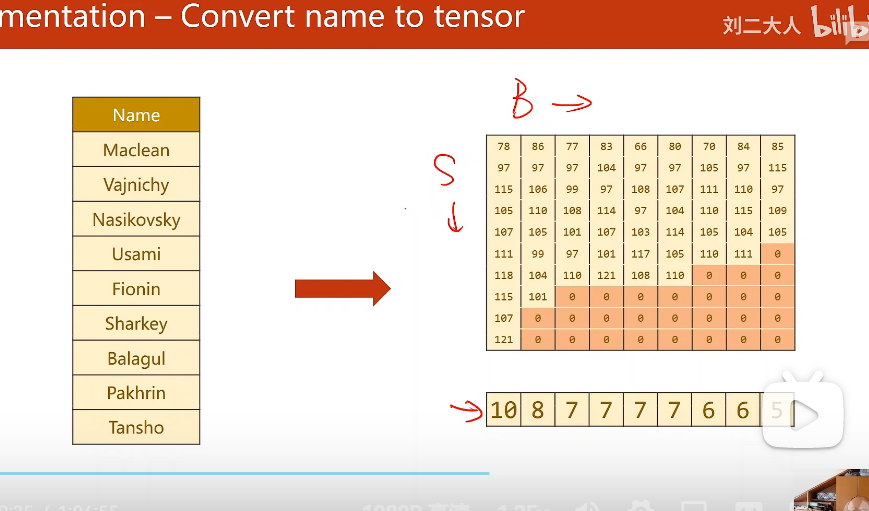
字符串——>字符——>ascii码值——>填充——>转置——>排序
padding:先做一个全0的,再复制粘贴过去
在分布中进行随机:重要性采样
code
使用双向RNN 基于人名来进行国家分类
# -*- encoding: utf-8 -*-"""@File : lecture_13.py @Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/3/20 22:18 ZhouCanzong 1.0 使用双向RNN 基于人名来进行国家分类"""# import libimport torchfrom torch.utils.data import Datasetfrom torch.utils.data import DataLoaderimport gzipimport csvimport timeimport math# parametersHIDDEN_SIZE = 100BATCH_SIZE = 256N_LAYER = 2N_EPOCHS = 50N_CHARS = 128 # 这个是为了构造嵌入层# prepare datasetclass NameDataset(Dataset): def __init__(self, is_train_set): filename = '../files/names_train.csv.gz' if is_train_set else '../files/names_test.csv.gz' with gzip.open(filename, 'rt') as f: # r表示只读,从文件头开始 t表示文本模式 reader = csv.reader(f) rows = list(reader) self.names = [row[0] for row in rows] self.len = len(self.names) self.countries = [row[1] for row in rows] self.country_list = list(sorted(set(self.countries))) self.country_dict = self.getCountryDict() self.country_num = len(self.country_list) def __getitem__(self, index): # 根据索引拿到的是 名字,国家的索引 return self.names[index], self.country_dict[self.countries[index]] def __len__(self): return self.len def getCountryDict(self): country_dict = dict() for idx, country_name in enumerate(self.country_list, 0): country_dict[country_name] = idx return country_dict def idx2country(self, index): return self.country_list[index] def getCountriesNum(self): return self.country_numtrainSet = NameDataset(is_train_set=True)trainLoader = DataLoader(trainSet, batch_size=BATCH_SIZE, shuffle=True)testSet = NameDataset(is_train_set=False)testLoader = DataLoader(testSet, batch_size=BATCH_SIZE, shuffle=False)N_COUNTRY = trainSet.getCountriesNum()# design modelclass RNNClassifier(torch.nn.Module): def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True): super(RNNClassifier, self).__init__() self.hidden_size = hidden_size self.n_layers = n_layers self.n_directions = 2 if bidirectional else 1 # 使用双向的GRU # 嵌入层(𝑠𝑒𝑞𝐿𝑒𝑛, 𝑏𝑎𝑡𝑐ℎ𝑆𝑖𝑧𝑒) --> (𝑠𝑒𝑞𝐿𝑒𝑛, 𝑏𝑎𝑡𝑐ℎ𝑆𝑖𝑧𝑒, hidden_size) self.embedding = torch.nn.Embedding(input_size, hidden_size) self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional) self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def _init_hidden(self, batch_size): hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size) return hidden def forward(self, input, seq_lengths): # input shape : B x S -> S x B input = input.t() batch_size = input.size(1) hidden = self._init_hidden(batch_size) embedding = self.embedding(input) # pack them up gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths) output, hidden = self.gru(gru_input, hidden) if self.n_directions == 2: hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1) else: hidden_cat = hidden[-1] fc_output = self.fc(hidden_cat) return fc_outputdef name2list(name): arr = [ord(c) for c in name] return arr, len(arr)def make_tensors(names, countries): sequences_and_lengths = [name2list(name) for name in names] name_sequences = [s1[0] for s1 in sequences_and_lengths] seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_lengths]) countries = countries.long() # make tensor of name, BatchSize * seqLen # 他这里补零的方式先将所有的0 Tensor给初始化出来,然后在每行前面填充每个名字 seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long() # print("seq_lengths.max:", seq_lengths.max()) for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0): seq_tensor[idx, :seq_len] = torch.LongTensor(seq) # sort by length to use pack_padded_sequence # 将名字长度降序排列,并且返回降序之后的长度在原tensor中的小标perm_idx seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True) # 这个Tensor中的类似于列表中切片的方法神奇啊,直接返回下标对应的元素,相等于排序了 seq_tensor = seq_tensor[perm_idx] countries = countries[perm_idx] # 返回排序之后名字Tensor,排序之后的名字长度Tensor,排序之后的国家名字Tensor return seq_tensor, seq_lengths, countriesclassifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)def trainModel(): def time_since(since): s = time.time() - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s) total_loss = 0 for i, (names, countries) in enumerate(trainLoader, 1): # print(type(names), type(countries)) # print(len(names), countries.shape) inputs, seq_lengths, target = make_tensors(names, countries) output = classifier(inputs, seq_lengths) # print("Shape:", output.shape, target.shape) # 注意输出和目标的维度:Shape: torch.Size([256, 18]) torch.Size([256]) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() if i % 10 == 0: print(f'[{time_since(start)}] Epoch {epoch} ', end='') print(f'[{i * len(inputs)}/{len(trainSet)}] ', end='') print(f'loss={total_loss / (i * len(inputs))}') return total_lossdef testModel(): correct = 0 total = len(testSet) print("evaluating trained model ... ") with torch.no_grad(): for i, (names, countries) in enumerate(testLoader): inputs, seq_lengths, target = make_tensors(names, countries) output = classifier(inputs, seq_lengths) # 注意这个keepdim的使用,为了直接和target计算loss pred = output.max(dim=1, keepdim=True)[1] # 注意这个view_as 和 eq correct += pred.eq(target.view_as(pred)).sum().item() percent = '%.2f' % (100 * correct / total) print(f'Test set: Accuracy {correct}/{total} {percent}%') return correct / total# mainif __name__ == '__main__': start = time.time() print("Training for %d epochs..." % N_EPOCHS) acc_list = [] for epoch in range(1, N_EPOCHS + 1): # Train cycle trainModel() acc = testModel() acc_list.append(acc)code
使用双向RNN 基于人名来进行国家分类 GPU
# -*- encoding: utf-8 -*-"""@File : lecture_13.py@Contact : ZhouCanzong@163.com@License : (C)Copyright 2021-, None@Modify Time @Author @Version @Description------------ ------- -------- -----------2022/3/20 22:18 ZhouCanzong 1.0 使用双向RNN 基于人名来进行国家分类 GPU"""# import libimport torchfrom torch.utils.data import Datasetfrom torch.utils.data import DataLoaderimport gzipimport csvimport timeimport math# parametersHIDDEN_SIZE = 100BATCH_SIZE = 256N_LAYER = 2N_EPOCHS = 50N_CHARS = 128 # 这个是为了构造嵌入层device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# prepare datasetclass NameDataset(Dataset): def __init__(self, is_train_set): filename = '../files/names_train.csv.gz' if is_train_set else '../files/names_test.csv.gz' with gzip.open(filename, 'rt') as f: # r表示只读,从文件头开始 t表示文本模式 reader = csv.reader(f) rows = list(reader) self.names = [row[0] for row in rows] self.len = len(self.names) self.countries = [row[1] for row in rows] self.country_list = list(sorted(set(self.countries))) self.country_dict = self.getCountryDict() self.country_num = len(self.country_list) def __getitem__(self, index): # 根据索引拿到的是 名字,国家的索引 return self.names[index], self.country_dict[self.countries[index]] def __len__(self): return self.len def getCountryDict(self): country_dict = dict() for idx, country_name in enumerate(self.country_list, 0): country_dict[country_name] = idx return country_dict def idx2country(self, index): return self.country_list[index] def getCountriesNum(self): return self.country_numtrainSet = NameDataset(is_train_set=True)trainLoader = DataLoader(trainSet, batch_size=BATCH_SIZE, shuffle=True)testSet = NameDataset(is_train_set=False)testLoader = DataLoader(testSet, batch_size=BATCH_SIZE, shuffle=False)N_COUNTRY = trainSet.getCountriesNum()# design modelclass RNNClassifier(torch.nn.Module): def __init__(self, input_size, hidden_size, output_size, n_layers=1, bidirectional=True): super(RNNClassifier, self).__init__() self.hidden_size = hidden_size self.n_layers = n_layers self.n_directions = 2 if bidirectional else 1 # 使用双向的GRU # 嵌入层(𝑠𝑒𝑞𝐿𝑒𝑛, 𝑏𝑎𝑡𝑐ℎ𝑆𝑖𝑧𝑒) --> (𝑠𝑒𝑞𝐿𝑒𝑛, 𝑏𝑎𝑡𝑐ℎ𝑆𝑖𝑧𝑒, hidden_size) self.embedding = torch.nn.Embedding(input_size, hidden_size) self.gru = torch.nn.GRU(hidden_size, hidden_size, n_layers, bidirectional=bidirectional) self.fc = torch.nn.Linear(hidden_size * self.n_directions, output_size) def _init_hidden(self, batch_size): hidden = torch.zeros(self.n_layers * self.n_directions, batch_size, self.hidden_size) return hidden def forward(self, input, seq_lengths): # input shape : B x S -> S x B input = input.t() batch_size = input.size(1) hidden = self._init_hidden(batch_size).to(device) embedding = self.embedding(input) # pack them up gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths.cpu()) output, hidden = self.gru(gru_input, hidden) if self.n_directions == 2: hidden_cat = torch.cat([hidden[-1], hidden[-2]], dim=1) else: hidden_cat = hidden[-1] fc_output = self.fc(hidden_cat) return fc_outputdef name2list(name): arr = [ord(c) for c in name] return arr, len(arr)def make_tensors(names, countries): sequences_and_lengths = [name2list(name) for name in names] name_sequences = [s1[0] for s1 in sequences_and_lengths] seq_lengths = torch.LongTensor([s1[1] for s1 in sequences_and_lengths]) countries = countries.long() # make tensor of name, BatchSize * seqLen # 他这里补零的方式先将所有的0 Tensor给初始化出来,然后在每行前面填充每个名字 seq_tensor = torch.zeros(len(name_sequences), seq_lengths.max()).long() # print("seq_lengths.max:", seq_lengths.max()) for idx, (seq, seq_len) in enumerate(zip(name_sequences, seq_lengths), 0): seq_tensor[idx, :seq_len] = torch.LongTensor(seq) # sort by length to use pack_padded_sequence # 将名字长度降序排列,并且返回降序之后的长度在原tensor中的小标perm_idx seq_lengths, perm_idx = seq_lengths.sort(dim=0, descending=True) # 这个Tensor中的类似于列表中切片的方法神奇啊,直接返回下标对应的元素,相等于排序了 seq_tensor = seq_tensor[perm_idx] countries = countries[perm_idx] # 返回排序之后名字Tensor,排序之后的名字长度Tensor,排序之后的国家名字Tensor return seq_tensor, seq_lengths, countriesclassifier = RNNClassifier(N_CHARS, HIDDEN_SIZE, N_COUNTRY, N_LAYER)classifier = classifier.to(device=device)# construct loss and optimizercriterion = torch.nn.CrossEntropyLoss()optimizer = torch.optim.Adam(classifier.parameters(), lr=0.001)def trainModel(): def time_since(since): s = time.time() - since m = math.floor(s / 60) s -= m * 60 return '%dm %ds' % (m, s) total_loss = 0 for i, (names, countries) in enumerate(trainLoader, 1): # print(type(names), type(countries)) # print(len(names), countries.shape) inputs, seq_lengths, target = make_tensors(names, countries) inputs, seq_lengths, target = inputs.to(device), seq_lengths.to(device), target.to(device) output = classifier(inputs, seq_lengths) # print("Shape:", output.shape, target.shape) # 注意输出和目标的维度:Shape: torch.Size([256, 18]) torch.Size([256]) loss = criterion(output, target) optimizer.zero_grad() loss.backward() optimizer.step() total_loss += loss.item() if i % 10 == 0: print(f'[{time_since(start)}] Epoch {epoch} ', end='') print(f'[{i * len(inputs)}/{len(trainSet)}] ', end='') print(f'loss={total_loss / (i * len(inputs))}') return total_lossdef testModel(): correct = 0 total = len(testSet) print("evaluating trained model ... ") with torch.no_grad(): for i, (names, countries) in enumerate(testLoader): inputs, seq_lengths, target = make_tensors(names, countries) inputs, seq_lengths, target = inputs.to(device), seq_lengths.to(device), target.to(device) output = classifier(inputs, seq_lengths) # 注意这个keepdim的使用,为了直接和target计算loss pred = output.max(dim=1, keepdim=True)[1] # 注意这个view_as 和 eq correct += pred.eq(target.view_as(pred)).sum().item() percent = '%.2f' % (100 * correct / total) print(f'Test set: Accuracy {correct}/{total} {percent}%') return correct / total# mainif __name__ == '__main__': start = time.time() print("Training for %d epochs..." % N_EPOCHS) acc_list = [] for epoch in range(1, N_EPOCHS + 1): # Train cycle trainModel() acc = testModel() acc_list.append(acc)改动之处:
-
参数定义:device = torch.device(“cuda” if torch.cuda.is_available() else “cpu”)
-
第一处在模型中:hidden = self._init_hidden(batch_size).to(device)
-
第二处在模型中:gru_input = torch.nn.utils.rnn.pack_padded_sequence(embedding, seq_lengths.cpu())
使用torch.nn.utils.rnn.pack_padded_sequence,seq_lengths就只能用cpu。见nn.utils.rnn.pack_padded_sequence: RuntimeError: ‘lengths’ argument should be a 1D CPU int64 tensor, but got 1D cuda:0 Long tensor
-
第三处在实例化模型时:classifier = classifier.to(device=device)
-
第四五处在训练时、测试时:inputs, seq_lengths, target = inputs.to(device), seq_lengths.to(device), target.to(device)

