文件操作《二》(5000字总结篇)
个人主页:欢迎大家光临——>沙漠下的胡杨
各位大帅哥,大漂亮
如果觉得文章对自己有帮助
可以一键三连支持博主
你的每一分关心都是我坚持的动力

☄: 本期重点:文件操作相关知识讲解
上篇主要讲了文件的顺序读写,不太懂的小伙伴点这哦——》 文件1
希望大家每天都心情愉悦的学习工作。


下面进入今天的学习:
那么文件怎么进行随机读写呢?
那么偏移量怎么计算呢?
怎么让文件指针指向起始位置?
二进制文件和文本文件区别
文件读取结束的判断
是否存在缓冲区的概念:
scanf和fscanf和sscanf
printf和fprintf函数sprintf
fprintf和fscanf实例
sscanf和sprint实例:
那么文件怎么进行随机读写呢?
使同fseek函数进行随机读写,我们看看函数原型来进行分析:
首先,第一个函数参数是文件流,没啥说的
第二个参数是偏移量,偏移量有相对位置的,相对于文件指针位置的偏移量。
第三个参数是文件指针位置,有三种状态
SEEK_CUR
文件指针当前位置
SEEK_END
文件指针末尾位置
SEEK_SET
文件指针开始位置
综上所述:我们要随机读写,就是在文件指针的位置处,在加上偏移量就可以实现文件随机的读写。
例:
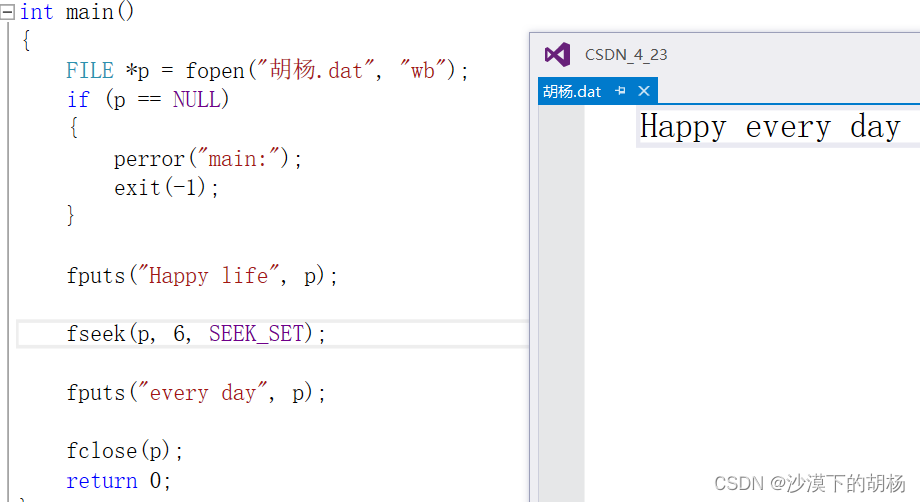
int main(){FILE *p = fopen("胡杨.dat", "wb");if (p == NULL){perror("main:");exit(-1);}fputs("Happy life", p);fseek(p, 6, SEEK_SET);fputs("every day", p);fclose(p);return 0;}
先写入了“Happy life”,然后我们从文件指针的起始位置开始,偏移量为6,进行写入,就会覆盖“Happy ”之后的东西,就变为了"Happy every day"。
文件的随机读:
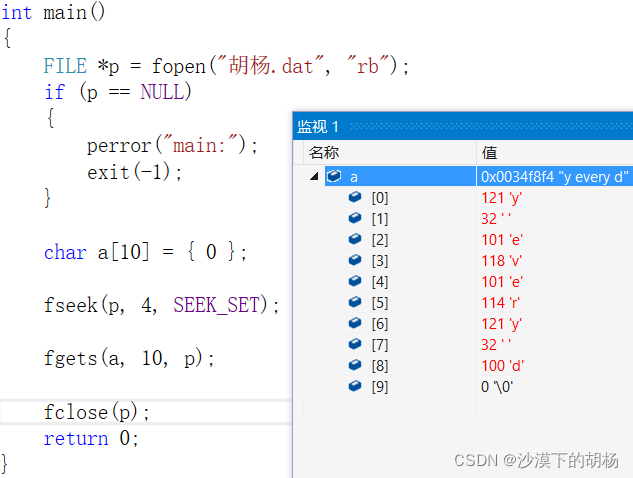
int main(){FILE *p = fopen("胡杨.dat", "rb");if (p == NULL){perror("main:");exit(-1);}char a[10] = { 0 };fseek(p, 4, SEEK_SET);fgets(a, 10, p);fclose(p);return 0;}
首先文件指针是文件起始位置,偏移量为4,所以就从 ’y‘ 字符开始读,向后读9个字符,因为fgets最后会读一个 '\0'。
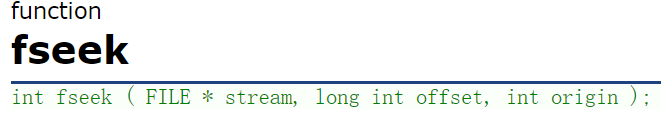
那么偏移量怎么计算呢?
我们用ftell函数来进行确认当前位置距离起始位置的偏移量。
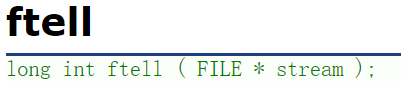
函数原型为
只用传入当前位置的文件指针就可以啦。
看个例子:
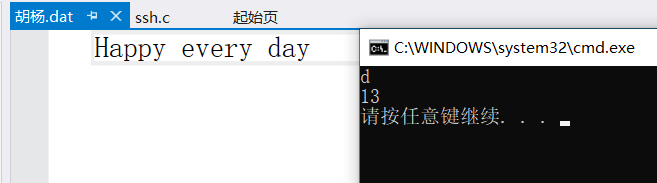
int main(){FILE *p = fopen("胡杨.dat", "rb");if (p == NULL){perror("main:");exit(-1);}fseek(p, -3, SEEK_END);printf("%c",fgetc(p));int a = ftell(p);printf("\n%d\n", a);fclose(p);return 0;}
分析下:首先我们先找到文件指针末尾,然后偏移量为 -3 ,就是从文件末尾向前偏移 3个字符,然后读取就是d('a' 'y' ’\0‘),此时文件指针位于 'a' 处,距离文件起始位置为13的偏移量。
怎么让文件指针指向起始位置?
我们可以使用rewind函数来实现
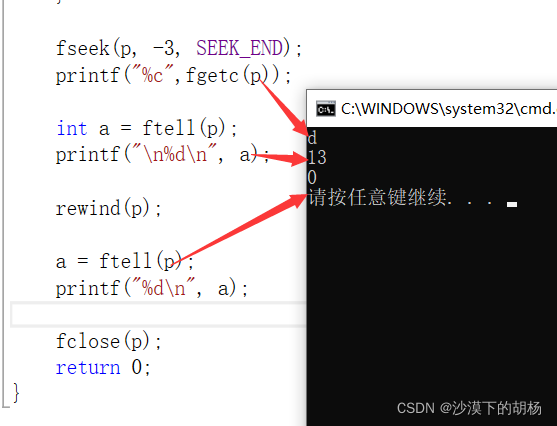
int main(){FILE *p = fopen("胡杨.dat", "rb");if (p == NULL){perror("main:");exit(-1);}fseek(p, -3, SEEK_END);printf("%c",fgetc(p));int a = ftell(p);printf("\n%d\n", a);rewind(p);a = ftell(p);printf("%d\n", a);fclose(p);return 0;}
使用rewind之后文件的偏移量就为0啦。
二进制文件和文本文件区别
根据数据的组织形式,数据文件被称为 文本文件 或者 二进制文件 。 数据在内存中以二进制的形式存储,如果不加转换的输出到外存,就是二进制文件。 。
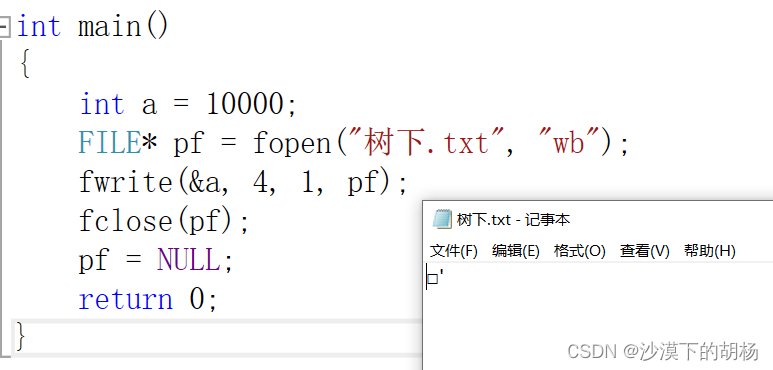
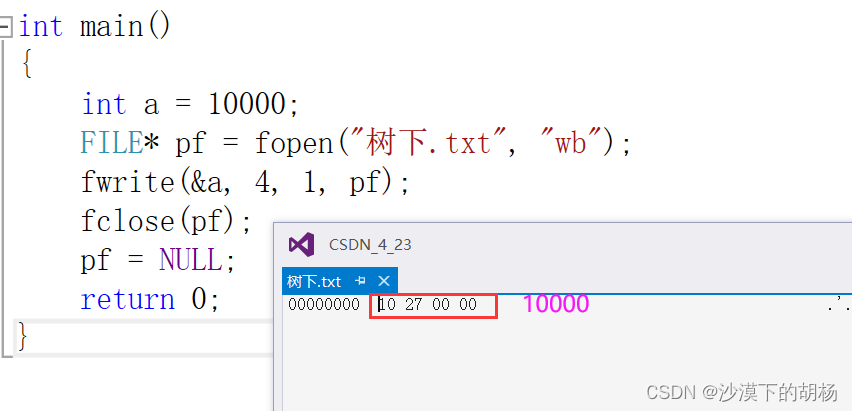
以ASCII字符的形式存储的文件就是文本文件。 字符一律以 ASCII 形式存储,数值型数据既可以用 ASCII 形式存储,也可以使用二进制形式存储。 下面我们看个例子理解下:int main(){int a = 10000;FILE* pf = fopen("树下.txt", "wb");fwrite(&a, 4, 1, pf);fclose(pf);pf = NULL;return 0;}我们把10000以二进制写入文件中去啦,那我们来看看吧,先用文本形式打来看看。
这我们看不懂呀,那么我们就要二进制打来看看能不能看懂啦.
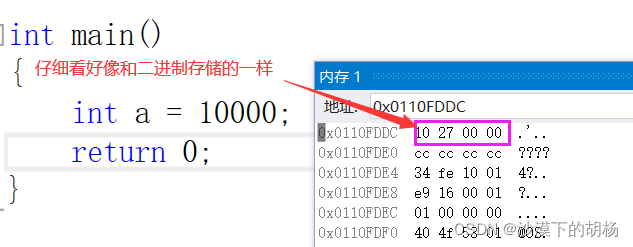
二级制形式打来我们好像也看不太懂哦,那我们看看10000在内存中怎么存储的吧。
我们发现在内存中存储的好像和二进制存储的一样。而且是占用的是4个字节。我们知道在文本形式显示是10000是5个字符,也就是5个字节,而在内存中和二进制中是4个字节。
文件读取结束的判断
牢记:在文件读取过程中,不能用feof函数的返回值直接用来判断文件的是否结束。 而是 应用于当文件读取结束的时候,判断是读取失败结束,还是遇到文件尾结束 。 1. 文本文件读取是否结束,判断返回值是否为 EOF ( fgetc ),或者 NULL ( fgets ) 例如: fgetc 判断是否为 EOF . fgets 判断返回值是否为 NULL . 2. 二进制文件的读取结束判断,判断返回值是否小于实际要读的个数。 例如: fread判断返回值是否小于实际要读的个数。关于fread在说明下把:

返回值为读取的个数,参数1是存放的空间,参数2是读取每个大小,参数3是要读取的个数,参数4是文件流。如果实际读取的个数小于要读取的个数,那么就表示文件读取结束啦。
是否存在缓冲区的概念:
ANSIC 标准采用“缓冲文件系统”处理的数据文件的 ,所谓缓冲文件系统是指系统自动地在内存中为程序 中每一个正在使用的文件开辟一块“ 文件缓冲区 ” 。从内存向磁盘输出数据会先送到内存中的缓冲区,装 满缓冲区后才一起送到磁盘上。如果从磁盘向计算机读入数据,则从磁盘文件中读取数据输入到内存缓 冲区(充满缓冲区),然后再从缓冲区逐个地将数据送到程序数据区(程序变量等)。缓冲区的大小根 据C 编译系统决定的。下面我们看一个例子来证明下:
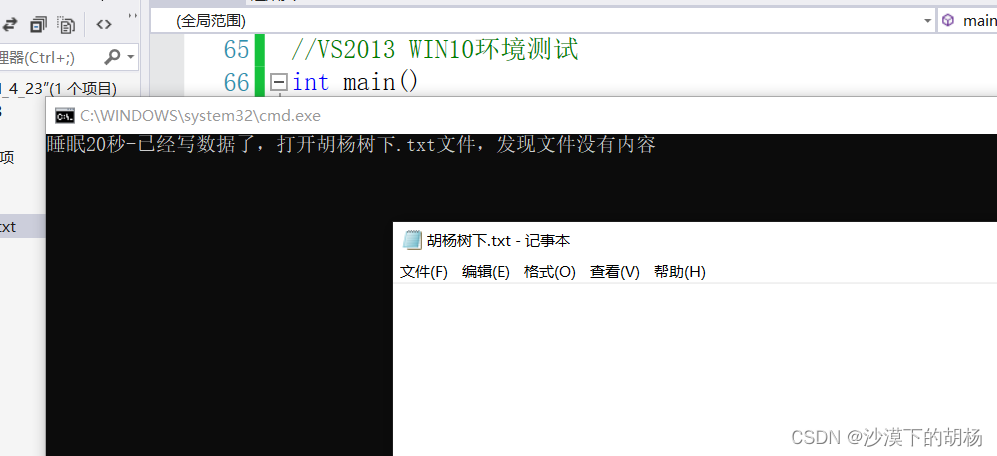
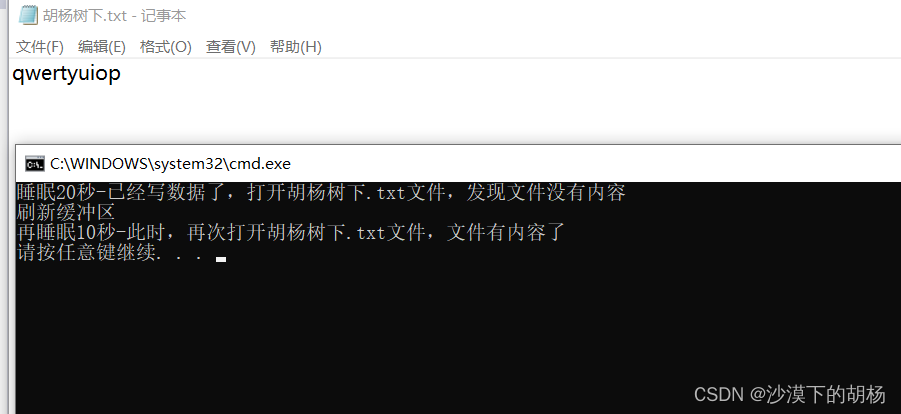
//VS2013 WIN10环境测试int main(){FILE*pf = fopen("胡杨树下.txt", "w");fputs("qwertyuiop", pf);//先将代码放在输出缓冲区printf("睡眠20秒-已经写数据了,打开胡杨树下.txt文件,发现文件没有内容\n");Sleep(20000);printf("刷新缓冲区\n");fflush(pf);//刷新缓冲区时,才将输出缓冲区的数据写到文件(磁盘)//注:fflush 在高版本的VS上不能使用了printf("再睡眠10秒-此时,再次打开胡杨树下.txt文件,文件有内容了\n");Sleep(10000);fclose(pf);//注:fclose在关闭文件的时候,也会刷新缓冲区pf = NULL;return 0;}
scanf和fscanf和sscanf
我们对比看下scanf和fsacnf和sscanf函数



这是三个函数有相似的地方,scanf叫做格式化输入,fscanf是针对所有的输入流的格式化的输入函数,sscanf是把一个字符串转化为格式化的数据。
printf和fprintf函数sprintf
看下函数原型
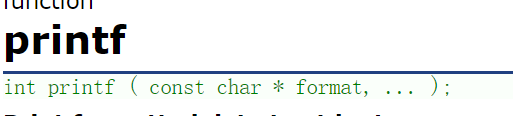

printf是格式化输出函数,fprintf是针对所有的输出流的格式化输出函数,sprintf是把一个格式化的数据转化为字符串。

fprintf和fscanf实例
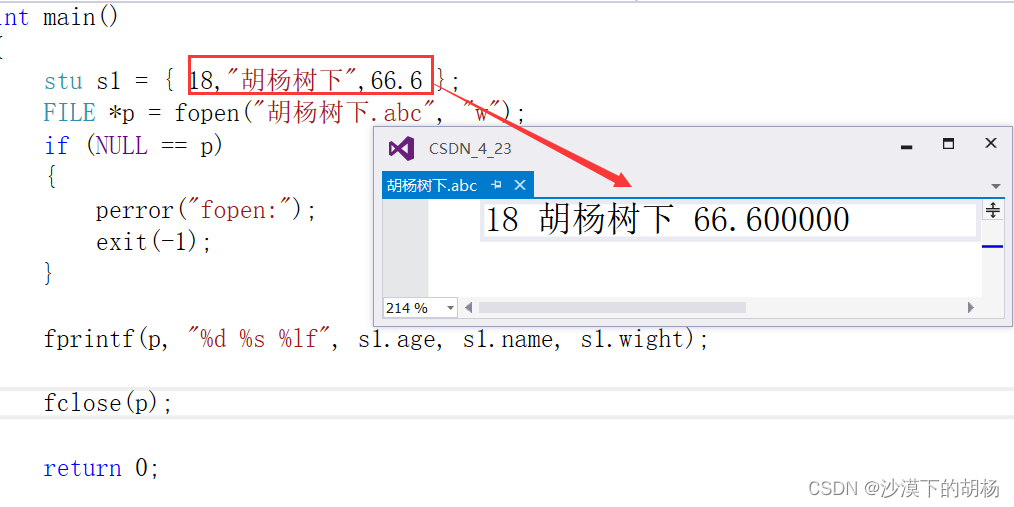
typedef struct stu{int age;char name[20];double wight;}stu;int main(){stu s1 = { 18,"胡杨树下",66.6 };FILE *p = fopen("胡杨树下.abc", "w");if (NULL == p){perror("fopen:");exit(-1);}fprintf(p, "%d %s %lf", s1.age, s1.name, s1.wight);fclose(p);return 0;}
我们写入了,下面进行读出。
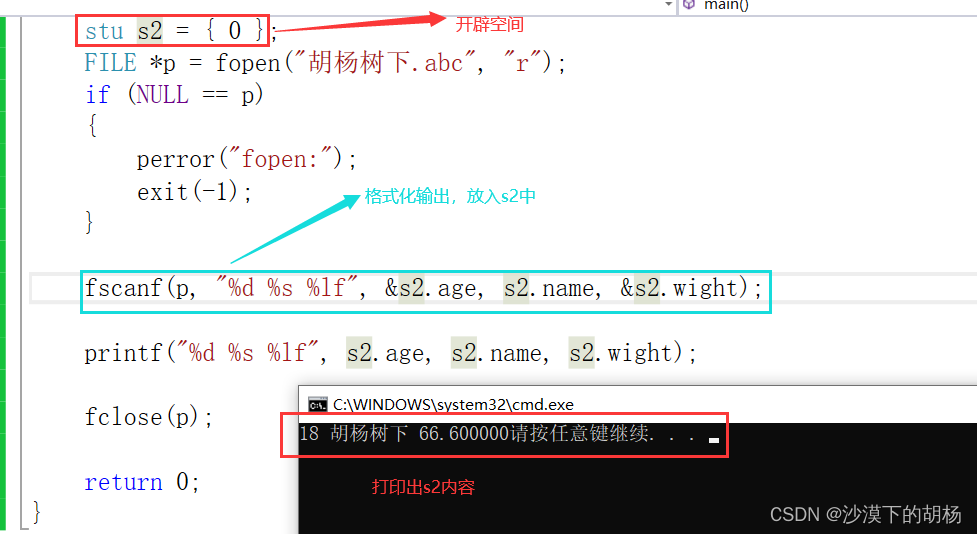
int main(){stu s2 = { 0 };FILE *p = fopen("胡杨树下.abc", "r");if (NULL == p){perror("fopen:");exit(-1);}fscanf(p, "%d %s %lf", &s2.age, s2.name, &s2.wight);printf("%d %s %lf", s2.age, s2.name, s2.wight);fclose(p);return 0;}
sscanf和sprint实例:
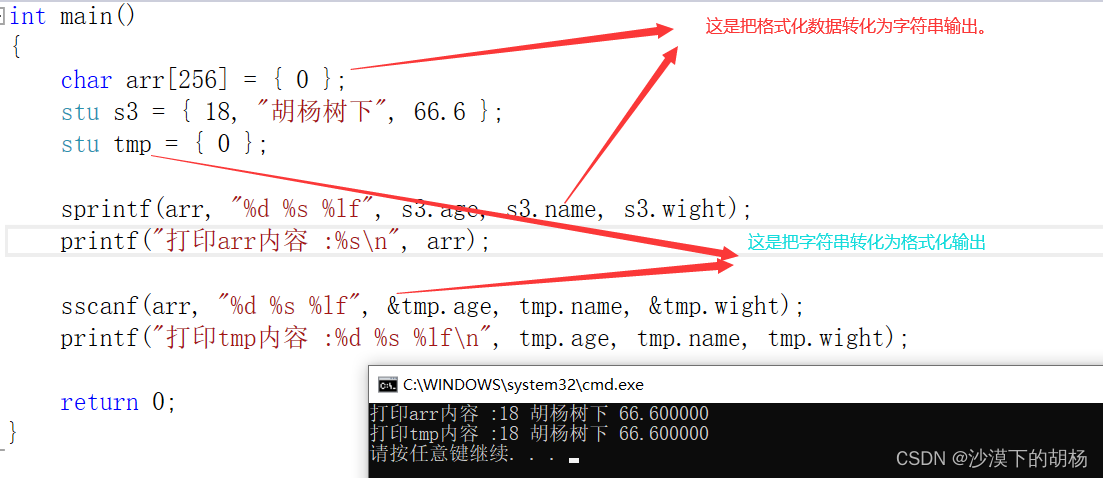
typedef struct stu{int age;char name[20];double wight;}stu;int main(){char arr[256] = { 0 };stu s3 = { 18, "胡杨树下", 66.6 };stu tmp = { 0 }; sprintf(arr, "%d %s %lf", s3.age, s3.name, s3.wight);printf("打印arr内容 :%s\n", arr);sscanf(arr, "%d %s %lf", &tmp.age, tmp.name, &tmp.wight);printf("打印tmp内容 :%d %s %lf\n", tmp.age, tmp.name, tmp.wight);return 0;}
这里我们是把和格式化数据先转化为了字符串输出,再把字符串转化为格式化数据进行输出。