创建项目并初始化业务数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(六)
系列文章目录
- 初识推荐系统——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(一)
- 利用用户行为数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(二)
- 项目主要效果展示——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(三)
- 项目体系架构设计——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(四)
- 基础环境搭建——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(五)
- 创建项目并初始化业务数据——基于Spark平台的协同过滤实时电影推荐系统项目系列博客(六)
- ……
项目资源下载
- 电影推荐系统网站项目源码Github地址(可Fork可Clone)
- 电影推荐系统网站项目源码Gitee地址(可Fork可Clone)
- 电影推荐系统网站项目源码压缩包下载(直接使用)
- 电影推荐系统网站项目源码所需全部工具合集打包下载(spark、kafka、flume、tomcat、azkaban、elasticsearch、zookeeper)
- 电影推荐系统网站项目源数据(可直接使用)
- 电影推荐系统网站项目个人原创论文
- 电影推荐系统网站项目前端代码
- 电影推荐系统网站项目前端css代码
文章目录
- 系列文章目录
- 项目资源下载
- 前言
- 一、在 I D E A IDEA IDEA中创建 M a v e n Maven Maven项目
-
- 1.1 项目框架搭建
- 1.2 声明项目中工具的版本信息
- 1.3 添加项目依赖
- 二、数据加载准备
-
- 2.1 M o v i e sMovies Movies数据集
- 2.2 R a t i n g sRatings Ratings数据集
- 2.3 T a gTag Tag数据集
- 2.4 日志管理配置文件
- 三、数据初始化到 M o n g o D B MongoDB MongoDB
-
- 3.1 启动 M o n g o D BMongoDB MongoDB数据库
- 3.2 数据加载程序主体实现
- 3.3 将数据写入 M o n g o D BMongoDB MongoDB
- 四、数据初始化到 E l a s t i c S e a r c h ElasticSearch ElasticSearch
-
- 4.1 启动 E l a s t i c S e a r c hElasticSearch ElasticSearch数据库
- 4.2 将数据写入 E l a s t i c S e a r c hElasticSearch ElasticSearch
- 总结
前言
今天给大家带来的博文是关于代码项目的初始化以及整个项目所需数据的初始化,其中包括,在 I D E A IDEA IDEA中创建 m a v e n maven maven项目、数据加载准备、数据初始化到 M o n g o D B MongoDB MongoDB、数据初始化到 E l a s t i c S e a r c h ElasticSearch ElasticSearch等内容,通过这篇博文我们就可以把整个项目的框架搭建起来了。另外有一点很重要,关于代码的内容大家要注意可能和我的命名不同,当然允许不同,但是要注意修改相关的位置,相信能做到这里的读者应该都是有一定基础的,但还是要提醒一下,需要注意。当然,读者还是要有Scala和Maven的基础。下面就开始今天的学习吧!
一、在 I D E A IDEA IDEA中创建 M a v e n Maven Maven项目
项目主体用 S c a l a Scala Scala编写,采用 I D E A IDEA IDEA作为开发环境进行项目编写,采用 M a v e n Maven Maven作为项目构建和管理工具
首先打开 I D E A IDEA IDEA,创建一个 M a v e n Maven Maven项目,命名为MovieRecommendSystem。为了方便后期的联调,会把业务系统的代码也添加进来,所以可以以MovieRecommendSystem作为父项目,并在其下建一个名为recommender的子项目,然后再在下面搭建多个子项目用于提供不同的推荐服务。
1.1 项目框架搭建
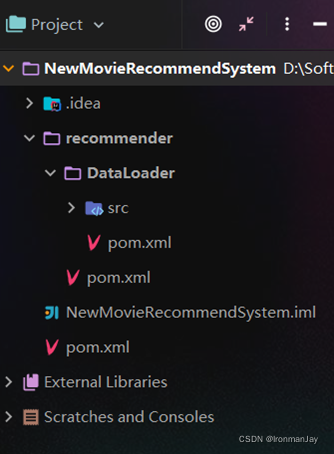
在MovieRecommendSystem的pom.xml文件中加入元素pom,然后新建一个maven module。子项目的第一步是初始化业务数据,所以子项目命名为DataLoader
父项目只是为了规范化项目结构,方便依赖管理,本身是不需要代码实现的,所以MovieRecommendSystem和recommender下的src文件夹都可以删掉
目前的整体项目框架如下:
1.2 声明项目中工具的版本信息
整个项目需要用到多个工具,它们的不同版本可能会对程序运行造成影响,所以应该在最外层的MovieRecommendSystem中声明所有子项目共用的版本信息。在MovieRecommendSystem/pom.xml中加入以下配置:
<properties><log4j.version>1.2.17</log4j.version><slf4j.version>1.7.22</slf4j.version><mongodb-spark.version>2.0.0</mongodb-spark.version><casbah.version>3.1.1</casbah.version><elasticsearch-spark.version>5.6.2</elasticsearch-spark.version><elasticsearch.version>5.6.2</elasticsearch.version><redis.version>2.9.0</redis.version><kafka.version>0.10.2.1</kafka.version><spark.version>2.1.1</spark.version><scala.version>2.11.8</scala.version><jblas.version>1.2.1</jblas.version></properties>1.3 添加项目依赖
首先,对于整个项目而言,应该有同样的日志管理,在MovieRecommendSystem中引入公有依赖:
<dependencies><!—引入共同的日志管理工具 --><dependency><groupId>org.slf4j</groupId><artifactId>jcl-over-slf4j</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-api</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>org.slf4j</groupId><artifactId>slf4j-log4j12</artifactId><version>${slf4j.version}</version></dependency><dependency><groupId>log4j</groupId><artifactId>log4j</artifactId><version>${log4j.version}</version></dependency></dependencies>同样,对于maven项目的构建,可以引入公有的插件:
<build><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-compiler-plugin</artifactId><version>3.6.1</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin></plugins><pluginManagement><plugins><plugin><groupId>org.apache.maven.plugins</groupId><artifactId>maven-assembly-plugin</artifactId><version>3.0.0</version><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin><plugin><groupId>net.alchim31.maven</groupId><artifactId>scala-maven-plugin</artifactId><version>3.2.2</version><executions><execution><goals><goal>compile</goal><goal>testCompile</goal></goals></execution></executions></plugin></plugins></pluginManageme></build>然后,在MovieRecommendSystem/recommender/ pom.xml模块中,可以为所有的推荐模块声明spark相关依赖(这里的dependencyManagement表示仅声明相关信息,子项目如果依赖需要自行导入)
<dependencyManagement> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-graphx_2.11</artifactId> <version>${spark.version}</version> </dependency><dependency> <groupId>org.scala-lang</groupId><artifactId>scala-library</artifactId><version>${scala.version}</version></dependency> </dependencies></dependencyManagement>由于各推荐模块都是scala代码,还应该引入scala-maven-plugin插件,用于scala程序的编译。因为插件已经在父项目中声明,所以这里不需要再声明版本和具体配置:
<build> <plugins> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> </plugin> </plugins></build>对于具体的DataLoader子项目,需要spark相关组件,还需要mongodb的相关依赖,在MovieRecommendSystem/recommender/DataLoader/pom.xml文件中引入所有依赖(在父项目中已声明的不需要再加详细信息):
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> </dependency> <dependency> <groupId>org.mongodb</groupId> <artifactId>casbah-core_2.11</artifactId> <version>${casbah.version}</version> </dependency> <dependency> <groupId>org.mongodb.spark</groupId> <artifactId>mongo-spark-connector_2.11</artifactId> <version>${mongodb-spark.version}</version> </dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>transport</artifactId><version>${elasticsearch.version}</version></dependency><dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch-spark-20_2.11</artifactId><version>${elasticsearch-spark.version}</version><exclusions><exclusion><groupId>org.apache.hive</groupId><artifactId>hive-service</artifactId></exclusion></exclusions></dependency></dependencies>至此,做数据加载需要的依赖都已配置好,可以开始写代码了
二、数据加载准备
在src/main/目录下,可以看到已有的默认源文件目录是java,可以将其改名为scala。将数据文件movies.csv、ratings.csv、tags.csv复制到资源文件目录src/main/resources下,将从这里读取数据并加载到Mongodb和Elasticsearch中
2.1 M o v i e s Movies Movies数据集
数据格式如下:
mid,name,descri,timelong,issue,shoot,language,genres,actors,directors
例子如下:
1^Toy Story (1995)^ ^81 minutes^March 20, 2001^1995^English
^Adventure|Animation|Children|Comedy|Fantasy ^Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn|John Ratzenberger|Annie Potts|John Morris|Erik von Detten|Laurie Metcalf|R. Lee Ermey|Sarah Freeman|Penn Jillette|Tom Hanks|Tim Allen|Don Rickles|Jim Varney|Wallace Shawn ^John Lasseter
Movie数据集有10个字段,每个字段之间通过“^”符号进行分割
| 字段名 | 字段类型 | 字段描述 | 字段备注 |
|---|---|---|---|
| mid | Int | 电影的ID | |
| name | String | 电影的名称 | |
| descri | String | 电影的描述 | |
| timelong | String | 电影的时长 | |
| shoot | String | 电影拍摄时间 | |
| issue | String | 电影发布时间 | |
| language | Array[String] | 电影语言 | 每一项用“|”分割 |
| genres | Array[String] | 电影所属类别 | 每一项用“|”分割 |
| director | Array[String] | 电影的导演 | 每一项用“|”分割 |
| actors | Array[String] | 电影的演员 | 每一项用“|”分割 |
2.2 R a t i n g s Ratings Ratings数据集
数据格式如下:
userId,movieId,rating,timestamp
例子如下:
1,31,2.5,1260759144
Rating数据集有4个字段,每个字段之间通过“,”符号进行分割
| 字段名 | 字段类型 | 字段描述 | 字段备注 |
|---|---|---|---|
| uid | Int | 用户的ID | |
| mid | Int | 电影的ID | |
| score | Double | 电影的分值 | |
| timestamp | Long | 评分的时间 |
2.3 T a g Tag Tag数据集
数据格式如下:
userId,movieId,tag,timestamp
例子如下:
1,31,action,1260759144
Tag数据集有4个字段,每个字段之间通过“,”符号进行分割
| 字段名 | 字段类型 | 字段描述 | 字段备注 |
|---|---|---|---|
| uid | Int | 用户的ID | |
| mid | Int | 电影的ID | |
| tag | String | 电影的标签 | |
| timestamp | Long | 评分的时间 |
2.4 日志管理配置文件
log4j对日志的管理,需要通过配置文件来生效。在src/main/resources下新建配置文件log4j.properties,写入以下内容:
log4j.rootLogger=info, stdoutlog4j.appender.stdout=org.apache.log4j.ConsoleAppenderlog4j.appender.stdout.layout=org.apache.log4j.PatternLayoutlog4j.appender.stdout.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss,SSS} %5p --- [%50t] %-80c(line:%5L) : %m%n三、数据初始化到 M o n g o D B MongoDB MongoDB
3.1 启动 M o n g o D B MongoDB MongoDB数据库
[bigdata@linux mongodb]$ bin/mongod -config data/mongodb.conf3.2 数据加载程序主体实现
为原始数据定义几个样例类,通过SparkContext的textFile方法从文件中读取数据,并转换成DataFrame,再利用Spark SQL提供的write方法进行数据的分布式插入
在DataLoader/src/main/scala下新建package,命名为com.IronmanJay.recommender,新建名为DataLoader的scala class文件,也就是:DataLoader/src/main/scala/com.IronmanJay.recommerder/DataLoader.scala
程序主体代码如下:
/ * Movie 数据集 * * 260 电影ID,mid * Star Wars: Episode IV - A New Hope (1977) 电影名称,name * Princess Leia is captured and held hostage 详情描述,descri * 121 minutes 时长,timelong * September 21, 2004 发行时间,issue * 1977 拍摄时间,shoot * English 语言,language * Action|Adventure|Sci-Fi类型,genres * Mark Hamill|Harrison Ford|Carrie Fisher 演员表,actors * George Lucas 导演,directors * */case class Movie(mid: Int, name: String, descri: String, timelong: String, issue: String, shoot: String, language: String, genres: String, actors: String, directors: String)/ * Rating数据集 * * 1,31,2.5,1260759144 */case class Rating(uid: Int, mid: Int, score: Double, timestamp: Int)/ * Tag数据集 * * 15,1955,dentist,1193435061 */case class Tag(uid: Int, mid: Int, tag: String, timestamp: Int)// 把mongo和es的配置封装成样例类/ * * @param uri MongoDB连接 * @param db MongoDB数据库 */case class MongoConfig(uri: String, db: String)/ * * @param httpHosts http主机列表,逗号分隔 * @param transportHosts transport主机列表 * @param index 需要操作的索引 * @param clustername 集群名称,默认elasticsearch */case class ESConfig(httpHosts: String, transportHosts: String, index: String, clustername: String)object DataLoader { // 定义常量 val MOVIE_DATA_PATH = "D:\\Software\\MovieRecommendSystem\\recommender\\DataLoader\\src\\main\\resources\\movies.csv" val RATING_DATA_PATH = "D:\\Software\\MovieRecommendSystem\\recommender\\DataLoader\\src\\main\\resources\\ratings.csv" val TAG_DATA_PATH = "D:\\Software\\MovieRecommendSystem\\recommender\\DataLoader\\src\\main\\resources\\tags.csv" val MONGODB_MOVIE_COLLECTION = "Movie" val MONGODB_RATING_COLLECTION = "Rating" val MONGODB_TAG_COLLECTION = "Tag" val ES_MOVIE_INDEX = "Movie" def main(args: Array[String]): Unit = { val config = Map( "spark.cores" -> "local[*]", "mongo.uri" -> "mongodb://linux:27017/recommender", "mongo.db" -> "recommender", "es.httpHosts" -> "linux:9200", "es.transportHosts" -> "linux:9300", "es.index" -> "recommender", "es.cluster.name" -> "es-cluster" ) // 创建一个sparkConf val sparkConf = new SparkConf().setMaster(config("spark.cores")).setAppName("DataLoader") // 创建一个SparkSession val spark = SparkSession.builder().config(sparkConf).getOrCreate() import spark.implicits._ // 加载数据 val movieRDD = spark.sparkContext.textFile(MOVIE_DATA_PATH) val movieDF = movieRDD.map( item => { val attr = item.split("\\^") Movie(attr(0).toInt, attr(1).trim, attr(2).trim, attr(3).trim, attr(4).trim, attr(5).trim, attr(6).trim, attr(7).trim, attr(8).trim, attr(9).trim) } ).toDF() val ratingRDD = spark.sparkContext.textFile(RATING_DATA_PATH) val ratingDF = ratingRDD.map(item => { val attr = item.split(",") Rating(attr(0).toInt, attr(1).toInt, attr(2).toDouble, attr(3).toInt) }).toDF() val tagRDD = spark.sparkContext.textFile(TAG_DATA_PATH) //将tagRDD装换为DataFrame val tagDF = tagRDD.map(item => { val attr = item.split(",") Tag(attr(0).toInt, attr(1).toInt, attr(2).trim, attr(3).toInt) }).toDF() implicit val mongoConfig = MongoConfig(config("mongo.uri"), config("mongo.db")) // 将数据保存到MongoDB storeDataInMongoDB(movieDF, ratingDF, tagDF) // 数据预处理,把movie对应的tag信息添加进去,加一列 tag1|tag2|tag3... import org.apache.spark.sql.functions._ / * mid, tags * * tags: tag1|tag2|tag3... */ val newTag = tagDF.groupBy($"mid") .agg(concat_ws("|", collect_set($"tag")).as("tags")) .select("mid", "tags") // newTag和movie做join,数据合并在一起,左外连接 val movieWithTagsDF = movieDF.join(newTag, Seq("mid"), "left") implicit val esConfig = ESConfig(config("es.httpHosts"), config("es.transportHosts"), config("es.index"), config("es.cluster.name")) // 保存数据到ES storeDataInES(movieWithTagsDF) spark.stop() }}3.3 将数据写入 M o n g o D B MongoDB MongoDB
接下来,实现storeDataInMongo方法,将数据写入Mongodb中:
def storeDataInMongoDB(movieDF: DataFrame, ratingDF: DataFrame, tagDF: DataFrame)(implicit mongoConfig: MongoConfig): Unit = { // 新建一个mongodb的连接 val mongoClient = MongoClient(MongoClientURI(mongoConfig.uri)) // 如果mongodb中已经有相应的数据库,先删除 mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).dropCollection() mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).dropCollection() mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).dropCollection() // 将DF数据写入对应的mongodb表中 movieDF.write .option("uri", mongoConfig.uri) .option("collection", MONGODB_MOVIE_COLLECTION) .mode("overwrite") .format("com.mongodb.spark.sql") .save() ratingDF.write .option("uri", mongoConfig.uri) .option("collection", MONGODB_RATING_COLLECTION) .mode("overwrite") .format("com.mongodb.spark.sql") .save() tagDF.write .option("uri", mongoConfig.uri) .option("collection", MONGODB_TAG_COLLECTION) .mode("overwrite") .format("com.mongodb.spark.sql") .save() //对数据表建索引 mongoClient(mongoConfig.db)(MONGODB_MOVIE_COLLECTION).createIndex(MongoDBObject("mid" -> 1)) mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("uid" -> 1)) mongoClient(mongoConfig.db)(MONGODB_RATING_COLLECTION).createIndex(MongoDBObject("mid" -> 1)) mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("uid" -> 1)) mongoClient(mongoConfig.db)(MONGODB_TAG_COLLECTION).createIndex(MongoDBObject("mid" -> 1)) mongoClient.close()}四、数据初始化到 E l a s t i c S e a r c h ElasticSearch ElasticSearch
4.1 启动 E l a s t i c S e a r c h ElasticSearch ElasticSearch数据库
这里有一个小坑,如果有的读者习惯使用root用户,那么启动ElasticSearch的时候要切换为非root用户,并且这个非root用户要被授权,关闭的时候也如此,否则会出现打不开或者其他问题的现象。启动ElasticSearch的命令如下:
[bigdata@linux elasticsearch-5.6.2]$ ./bin/elasticsearch -d4.2 将数据写入 E l a s t i c S e a r c h ElasticSearch ElasticSearch
与上节类似,同样主要通过Spark SQL提供的write方法进行数据的分布式插入,实现storeDataInES方法:
def storeDataInES(movieDF: DataFrame)(implicit eSConfig: ESConfig): Unit = { // 新建es配置 val settings: Settings = Settings.builder().put("cluster.name", eSConfig.clustername).build() // 新建一个es客户端 val esClient = new PreBuiltTransportClient(settings) val REGEX_HOST_PORT = "(.+):(\\d+)".r eSConfig.transportHosts.split(",").foreach { case REGEX_HOST_PORT(host: String, port: String) => { esClient.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName(host), port.toInt)) } } // 先清理遗留的数据 if (esClient.admin().indices().exists(new IndicesExistsRequest(eSConfig.index)) .actionGet() .isExists ) { esClient.admin().indices().delete(new DeleteIndexRequest(eSConfig.index)) } esClient.admin().indices().create(new CreateIndexRequest(eSConfig.index)) movieDF.write .option("es.nodes", eSConfig.httpHosts) .option("es.http.timeout", "100m") .option("es.mapping.id", "mid").option("es.nodes.wan.only", "true") .mode("overwrite") .format("org.elasticsearch.spark.sql") .save(eSConfig.index + "/" + ES_MOVIE_INDEX)}总结
最近有点忙,考研复试结束之后再到拟录取之后,一直在摆(bushi),所以把这个系列给搁置了,刚刚抽出空给这次补上了,后面我争取一周一篇(立一个小小的flag)。也请大家一起努力,加油,我在下篇博客等你!哦,对了,这篇博客因为有代码,所以有些小细节大家一定要注意,比如命名之类的,一定注意!

