【Numpy金融领域的应用】伽玛分布和贝塔分布随机抽样——以债券违约率与回收率为分析对象
【Numpy金融领域的应用】伽玛分布和贝塔分布随机抽样——以债券违约率与回收率为分析对象
1、案例详情
J银行是总部位于英国伦敦的一家商业银行,该银行的固定收益投资部门负责整个银行的债券投资业务。假定你是该部门的债券分析师助理,日常的工作之一就是协助投资经理分析债券的信用风险,并且重点参考了全球最大的3家信用评级机构之一——穆迪(Moody’s )定期发布的全球企业债券违约率与回收率"。根据2017年2月穆迪发布的《年度违约研究:1920-2016年企业违约率与回收率》(Annual Default Study: Corporate Default and RecoveryRates,1920-2016 )的报告,表2-10列出了2000年至2016年全部债券的违约率和违约发生后的回收率(简称“回收率”)。
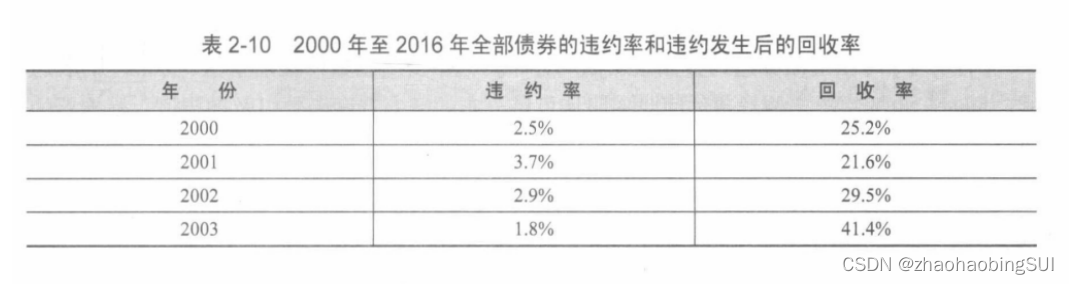
续表:
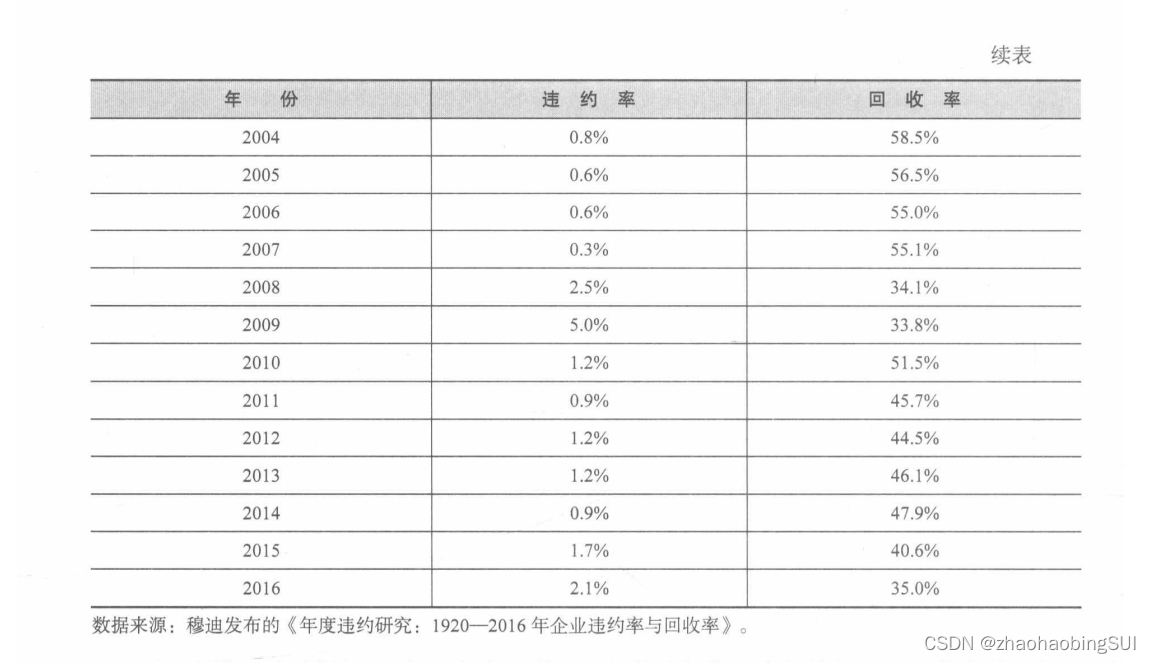
基于投资风险分散的原则,J银行目前配置的债券投资组合中共有200只债券并且每只债券的配置权重均相同,投资的债券面值共计120亿英镑,在分析风险时,设定债券违约金额服从伽玛分布(Gamma distribution ),回收率则服从贝塔分布(Beta distribution )。
为了协助投资经理完成一份针对J银行债券投资组合的风险分析报告,你需要根据表2-10的数据并运用Python完成4项编程任务。
2、编程任务
【任务1】写出当债券违约金额服从伽玛分布的概率密度函数以及期望值、标准差的表达式,同时,也要写出当债券违约回收率服从贝塔分布的概率密度函数以及期望值、标准差的表达式。
【任务2】分别创建包含表2-10的违约率和回收率的数组,运用这些数据计算J银行目前债券投资组合的违约金额、回收率的均值和标准差。
【任务3】根据任务2计算得到的债券违约金额均值和标准差,计算债券违约金额服从伽玛分布的形状参数cα、尺度参数p的数值;对满足这两个参数的伽玛分布进行10万次随机抽样以模拟债券违约金额,并计算随机抽样结果的均值与标准差。
【任务4】根据任务2计算得到的回收率均值和标准差,计算回收率服从贝塔分布的参数a、β;同时从满足这两个参数的贝塔分布中进行10万次随机抽样以模拟债券违约的回收率,并计算随机抽样结果的均值与标准差。
3、编程实现
Task1_Begin
假设债券违约金额变量x服从伽玛分布(也称伽马分布),概率密度函数如下:
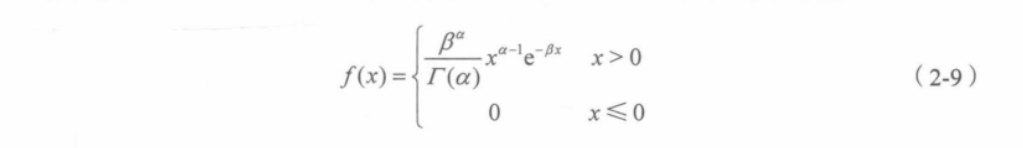
式 (2-9)中的r是一个伽玛函数,伽玛分布的期望值E(x)= αB-’,方差D(x)= aB2,标准差是、√D(x)=√aβ’。其中,α称为形状参数( shape parameter ),3称为尺度参数(( scaleparameter )。
假设回收率变量y服从贝塔分布(也称B分布),它的概率密度函数如下:
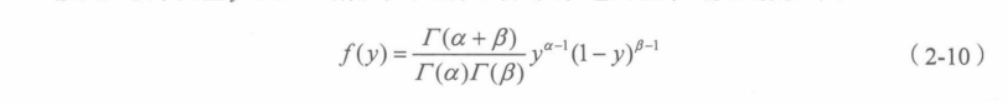
式 (2-10)中的厂依然是伽玛函数,此外,0<y0,B0。
贝塔分布的期望值E(x)= α/(α+ 3),方差D(x)= αB/[(a + B)(α + β+1)],标准差就是√D(x) =√aB/[K(a +B)(a+ β+ 1)]。
Task2_Begin
import numpy as npdefault_prob=np.array([0.025,0.037,0.029,0.018,0.008,0.006,0.006,0.003 ,0.025,0.050,0.012,0.009,0.012,0.012,0.009,0.017,0.021])#债券违约率数组recovery=np.array ([0.252,0.216,0.295,0.414,0.585,0.565,0.550,0.551,0.341,0.338,0.515,0.457,0.445,0.461,0.479,0.406,0.350])#债券违约回收率的数par=120 #债券投资组合的面值(亿英镑)default_value=default_prob*par#违约金额的数组default_mean=default_value.mean()#计算违约金额的平均default_std=default_value.std()#计算违约金额的标准print('J银行债券投资组合的违约金额平均值(亿英镑)',round (default_mean,2))print('J银行债券投资组合的违约金额的标准差(亿英镑)',round (default_std,2))recovery_mean=recovery.mean()#计算回收率的平均值recovery_std=recovery.std()#计算回收率的标准差print('J银行债券违约后回收率的平均值',round (recovery_mean,6))print('J银行债券违约后回收率的标准差1',round (recovery_std,6))Task3_Begin
alpha_gamma=default_mean2 /default_std2#违约率服从伽玛分布的 alphabeta_gamma=default_mean/default_std2#违约率服从伽玛分布的betaprint('违约金额服从伽玛分布的alpha',alpha_gamma)print('违约金额服从伽玛分布的beta',beta_gamma)I=100000#随机抽样的次数random_gamma=np.random.gamma(shape=alpha_gamma, scale=beta_gamma,size=I)#按照债券违约率服从的伽玛分布进行随机抽样random_gamma.mean ()#输出随机抽样结果的均值random_gamma.mean ()#输出随机抽样结果的均值Task4_Begin
import scipy.optimize as sco#导入 SciPy子模块 optimizedef f(x):#需要定义一个函数 a,b=x eql=a/(a+b)-recovery_mean eq2=a*b/((a+b+1)* (a+b)2)-recovery_std2 return [eql,eq2]result=sco.fsolve(f,[0.5,0.5])print('回收率服从贝塔分布的alpha' , result [0])print('回收率服从贝塔分布的beta' , result [1])random_beta=np.random.beta(a=result[0] , b=result[1],size=I)#按照回收率服从的贝塔分布进行随机抽样random_beta.mean()#随机抽样的均值random_beta.std()#随机抽样的标准差以上随机抽样得到债券违约回收率的均值和标准差,与任务2中计算得出的债券违约回收率均值0.424 706和标准差0.108 919也是很接近的。

