DCGAN论文解读-----DCGAN原理简介与基础GAN的区别
还未了解基础GAN的,可以先看下面两篇文章:
GNA笔记--GAN生成式对抗网络原理以及数学表达式解剖
入门GAN实战---生成MNIST手写数据集代码实现pytorch
2016年,Alec等人发表的论文《UNSUPERVISED REPRESENTATION LEARNING WITH DEEP CONVOLUTIONAL GENERATIVE ADVERSARIAL NETWORKS》(简称DCGAN),首次提出将卷积神经网络应用到GAN生成对抗网络的模型中,从而代替全连接层。这篇论文中讨论了GAN特征的可视化、潜在空间差值等。本文知识总结来源也是这篇论文。
一、什么是DCGAN?
DCGAN是GAN的一个变体,DCGAN就是将CNN和原始的GAN结合到一起,生成网络和鉴别网络都运用到了深度卷积神经网络。DCGAN提高了基础GAN的稳定性和生成结果质量。
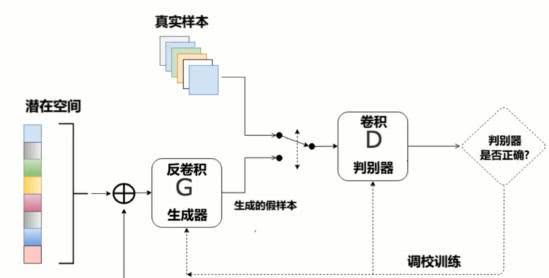
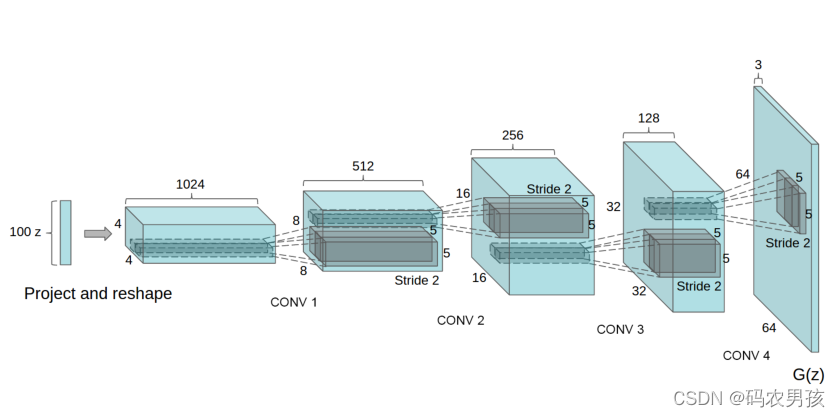
二、与基础GAN相比,改进方面?
DCGAN主要是在网络架构上改进了原始GAN,DCGAN的生成器和鉴别器都利用CNN架构替换了原始GAN的全连接网络,主要改进之处有如下几个方面:
- DCGAN的生成器和鉴别器都舍弃了CNN的pooling层(池化层),鉴别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层(ConvTranspose2d)
- 在鉴别器和生成器中使用了BN(Batch Normalization)层,加速模型训练,提升了训练的稳定性。但是在生成器的输出层和鉴别器的输入层不使用BN层【直接应用batchnorm到所有层会导致样本振荡和模型不稳定】
- 生成器网络中使用ReLU作为激活函数,最后一层使用Tanh()【使用有界激活(a bounded activation)可以让模型更快地学习,以饱和和覆盖训练分布的颜色空间】
- 鉴别器网络中使用LeakyReLU作为激活函数
- 使用Adam优化器,一阶矩估计的指数衰减率的值设置为0.5
三、论文中一些参数推荐
- 所有模型均采用小批量随机梯度下降(SGD)训练,Batch_size大小为128。
- 所有权重均根据零中心正态分布进行初始化,标准偏差为0.02。
- 在LeakyReLU中,斜率均设置为0.2。
- 使用了Adam优化器并调整超参数。基础GAN中建议的学习率0.001太高了,改为使用0.0002。
- 此外,将动量项β1保留在建议值0.9会导致训练振荡和不稳定性,而将其降低到0.5有助于稳定训练。
四、论文中提及到的训练
论文中提到模型在三个数据集上对DCGANs进行了训练,即大规模场景理解(LSUN)、Imagenet-1k和一个新组装的人脸数据集。下面给出了每个数据集的训练细节
1.LSUN
随着生成图像模型样本的视觉质量的提高,对训练样本的过度拟合和记忆的担忧也随之增加。为了观察训练的模型如何随着更多数据和更高分辨率的生成而扩展,在包含300多万个训练示例的LSUN Bedrooms数据集上训练了一个模型。实验证明,模型的学习速度与其泛化性能之间存在直接联系。 【没有对图像进行数据增强】
上图为1个训练时期的样本
 上图为 5个epoch后的结果
上图为 5个epoch后的结果
2.FACES
这个数据集有来自1万人的300万张图片。我们在这些图像上运行OpenCV人脸检测器,使检测保持足够高的分辨率,这为我们提供了大约350000个face boxes,我们用这些face boxes来训练。
3.IMAGENET-1K
使用Imagenet-1k 作为无监督训练的自然图像源,We train on 32 × 32 min-resized center crops
五、对DCGAN能力的证明
评估无监督表示学习算法质量的一种常用技术是将其作为有监督数据集的特征提取器应用,并评估基于这些特征的线性模型的性能。
使用GANS作为特征提取器对CIFAR-10进行分类(DCGAN不是在CIFAR-10上预训练的,而是在Imagenet-1k上训练的,这些特征用于对CIFAR-10图像进行分类 )实验结果如下图所示

当使用大量特征图(4800)时,K-means可达到80.6%的准确率,DCGAN达到了82.8%的准确率,超过了所有基于K均值的方法。值得注意的是,与基于K-means的技术相比,鉴别器的特征图要少得多(最高层为512),但由于有4×4个空间位置的多个层,鉴别器确实会导致更大的总特征向量大小。DCGANs的性能仍然低于样本CNN。
六、结论和今后的工作
文章提出了一套更稳定的生成性对抗网络训练体系结构,并证明了对抗性网络能够学习良好的图像表示,用于监督学习和生成性model。但是仍然存在一些不稳定性——随着模型训练时间的延长,它们有时会将滤波器子集折叠为单一振荡模式。需要进一步的工作来解决这一不稳定因素。我们认为,将这个框架扩展到其他领域,比如视频(用于帧预测)和音频(用于语音合成的预训练功能)应该是非常有趣的。进一步研究学习到的潜在空间的性质也会很有趣。
七、其他知识
1.无监督表征学习的经典方法是对数据进行聚类(例如k-means),另一种方法是训练自动编码器(auto-encoder)还有深度置信网络。
2.生成图像模型大致可以分为两类:参数模型和非参数模型
非参数模型:通常从现有图像数据库中进行匹配,通常是匹配patch of images
参数模型:①生成图像的变分采样方法(variational sampling),缺点是会出现模糊图像
②使用迭代的正向扩散过程生成images
③GAN生成,但是噪声多。拉普拉斯金字塔扩展后得到了更高质量图像,但仍有噪声产生的影响。
④递归网络和反卷积网络方法
八、实战
DCGAN实战(1)---生成MNIST手写数字代码实现pytorch版
九、总结
如果将目前对于GAN的研究方向进行划分的话,可以大致分为以下两个方向:
1.对各种GAN的实际应用研究,比如有意思的应用在图像风格的迁移:pix2pixGAN和CycleGAN
可参考:1.GAN系列之 pix2pixGAN 网络原理介绍以及论文解读
2.GAN实战之Pytorch使用pix2pixGAN生成建筑物Label to Facade
3.一文看懂CycleGAN网络原理以及论文精华解读 4. GAN项目实战 使用CycleGAN将苹果变成橙子Pytorch版
2.关于如何稳定GAN的训练进行研究,可参考WGAN
一文看懂GAN系列之WGAN(Wasserstein GAN)原理

