一文了解人工智能顶级会议AAAI 2025的研究热点与最新趋势_人工智能顶会
一、会议介绍

AAAI(AAAI Conference on Artificial Intelligence)是由国际人工智能促进协会主办的国际顶级学术会议,是人工智能领域中历史最悠久、涵盖内容最广泛的会议之一,被中国计算机学会(CCF)评为A类会议。人工智能促进协会成立于1979年,原名“美国人工智能协会”,并于2007年更名为人工智能促进协会(AAAI)。它在全球拥有超过6000名成员。汇集了全球最顶尖的人工智能领域专家学者,一直是人工智能界的研究风向标,在学术界久负盛名。
会议官网:https://aaai.org/conference/aaai/aaai-25/
二、 AAAI 2025录用情况
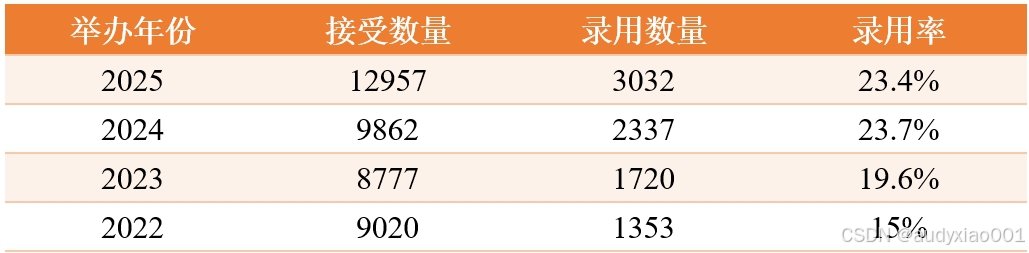
AAAI 2025于2025年2月25日至3月4日在美国宾夕法尼亚州费城举办,为期8天。本次会议共收到 12,957 篇有效投稿,其中3,032 篇被接收,录用率约为 23.4%。会议涵盖了多智能体优化、神经符号推理、不确定性决策、生物多样性计算等多个前沿方向,为学术界和工业界提供了广阔的交流平台。
与以往相比,本次会议的投稿量显著增加。但录用相较于其他顶级会议波动较大。回顾过去几年,2022年的录用率低至15%,处于较低水平。而近两年则呈现逐步上升的态势,并在今年达到了23.4%。这一趋势表明,AAAI在保持高标准评审的同时,也在适应投稿量的增长,为更多优秀的研究成果提供展示的机会。近年录取率详见表1。
表1 AAAI 近年录取情况
三、 热点分析
表2 AAAI 2025高频主题词
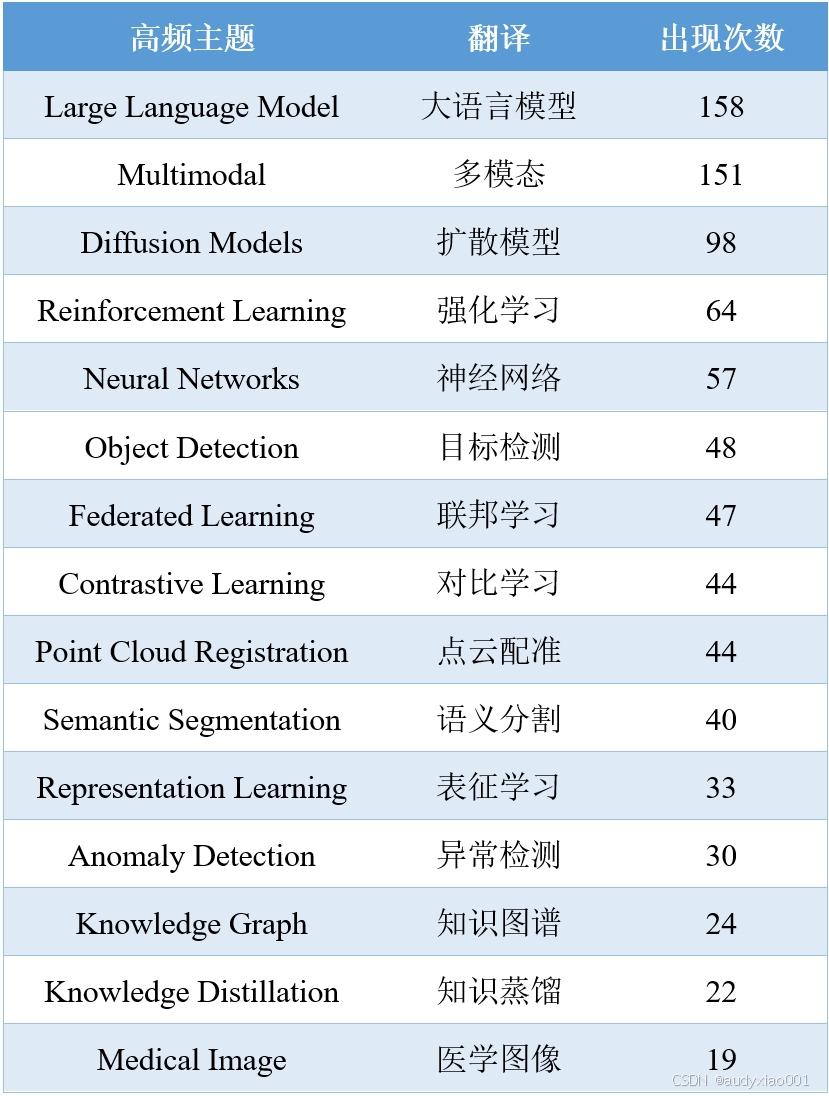
表 2和图 1基于AAAI 2025会议录用的3032篇论文标题数据,统计了高频主题词并生成了词云图。通过对于高频主题词的分析,当前对于AI研究的主要热点聚焦于以下几个方向,首先是生成式模型的持续突破,大语言模型(Large Language Models, LLMs)已从自然语言处理(NLP)扩展到多模态任务,如视觉-语言交互,推动了生成式AI的广泛应用。而扩散模型(Diffusion Models)因其在图像与视频生成中的高保真度,仍是生成技术的重要手段,但其研究重心已转向效率优化与跨模态适配,如文本到3D生成等。
在计算机视觉领域,目标检测(Object Detection)和语义分割(Semantic Segmentation)通过结合Transformer架构,进一步提升了复杂场景下的鲁棒性。点云配准(Point Cloud Registration)在自动驾驶领域的应用持续增长,同时与神经辐射场技术结合,推动了三维重建的精度提升。
强化学习(Reinforcement Learning)在具身智能和多智能体协作中广泛运用并取得新进展,而联邦学习(Federated Learning)因隐私保护需求成为分布式学习的标准范式之一。对比学习(Contrastive Learning)则与自监督学习结合,显著提升了小样本场景下的表征学习(Representation Learning)效果。
AI技术的快速发展正在深度渗透到各个垂直领域,例如医学图像处理在AAAI 2025中展现出了跨学科研究的潜力。异常检测(Anomaly Detection)和知识图谱(Knowledge Graph)则在金融风控与智能制造等地方中广泛应用。

图 1 AAAI 2025研究热点词云图
四、杰出论文
AAAI 2025共有四篇论文获得了杰出论文奖,分别是南京大学周志华老师团队的《Efficient rectification of neuro-symbolic reasoning inconsistencies by abductive reflection》;多伦多大学的《Every Bit Helps: Achieving the Optimal Distortion with a Few Queries》;波尔多大学、巴黎大学、安特卫普大学合作的《Revelations: A decidable class of POMDPs with omega-regular objectives》以及斯坦福大学、弗莱堡大学等六个机构合作的《DiVShift: Exploring domain-specific distribution shift in volunteer-collected biodiversity datasets》(该论文获得了AI社会对齐方向的杰出论文奖)。以下是四篇杰出论文的详细信息。
1.Hu, W. C., Dai, W. Z., Jiang, Y., & Zhou, Z. H. (2024). Efficient Rectification of Neuro-Symbolic Reasoning Inconsistencies by Abductive Reflection. arXiv preprint arXiv:2412.08457.
论文下载:https://arxiv.org/pdf/2412.08457
2.Ebadian, S., & Shah, N. (2025). Every bit helps: Achieving the optimal distortion with a few queries. In Proceedings of the 39th Annual AAAI Conference on Artificial Intelligence (AAAI).
论文下载:https://www.cs.toronto.edu/~nisarg/papers/value-queries.pdf
3.Belly, M., Fijalkow, N., Gimbert, H., Horn, F., PÊrez, G. A., & Vandenhove, P. (2024). Revelations: A Decidable Class of POMDPs with Omega-Regular Objectives. arXiv preprint arXiv:2412.12063.
论文下载:https://arxiv.org/pdf/2412.12063
代码下载:https://github.com/gaperez64/pomdps-reveal
4.Sierra, E., Gillespie, L. E., Soltani, S., Exposito-Alonso, M., & Kattenborn, T. (2024). DivShift: Exploring Domain-Specific Distribution Shift in Volunteer-Collected Biodiversity Datasets. arXiv preprint arXiv:2410.19816.
论文下载:https://arxiv.org/pdf/2410.19816

更多内容敬请关注本公众号

