高并发内存池(五):性能测试与性能优化
前言
在前几期的实现中,我们完成了tcmalloc基础的内存管理功能,但还存在两个关键问题:
-
未处理超过256KB的大内存申请。
-
前期测试覆盖不足,导致多线程场景下隐藏了一些bug。
本文将修复这些问题,并实现三个目标:
-
增加大块内存分配逻辑
-
替换系统自带的malloc
-
通过性能测试定位优化瓶颈
目录
一、功能完善
1.大内存块需求
1.1.申请
1.2.释放
2.优化释放
3.测试
二、脱离malloc
1.定长内存池替代new
三、Bug修复
四、性能测试
Debug
性能分析
五、性能优化
测试结果
Debug模式
Release模式
六、源码
一、功能完善
1.大内存块需求
1.1.申请
在ThreadCache中我们最大只能申请到256KB的内存,要申请大于256KB的内存,就要添加新的逻辑,不能到自由链表桶中申请。
怎么解决呢?很简单,既然在ThreadCache层解决不了,那么直接去PageCache的桶中获取Span就行,因为我们以8KB为一页,256KB也就是32页。只要在32页到128页内的空间申请都到PageCache桶中申请。
代码实现:在ConcurrentAlloc函数中添加一个size>256KB的分支,让它到PageCache中申请Span,注意这个过程需要进行内存对齐和加锁。内存对齐:因为现在是以页为单位申请,所以需要以1页为对齐数对齐。需要添加RoundUp函数逻辑,如下:
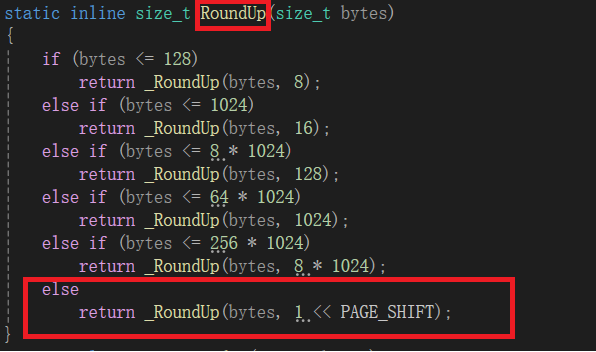
这里看上去8*1024和1<<PAGE_SHIFT(即1<<13)是一样的,但事实上8*1024字节是固定的,PAGE_SHIFT是根据需求改变的。
ConcurrentAlloc中添加的部分:
static void* ConcurrentAlloc(size_t size){ if (size > MAX_BYTES) { PAGE_ID bytes = SizeClass::RoundUp(size); PageCache::GetInstance()->_pageMtx.lock(); Span* span = PageCache::GetInstance()->NewSpan(bytes >> PAGE_SHIFT); PageCache::GetInstance()->_pageMtx.unlock(); void* ptr = (void*)(span->_pageId << PAGE_SHIFT); return ptr; } else { //正常逻辑 //...... }}对于小于128页的内存申请NewSpan无需修改,如果用户需求是>128页呢?此时PageCache桶就无法满足,我们直接向系统申请即可,并且使用Span结构统一管理。如下NewSpan中添加的部分:
Span* PageCache::NewSpan(size_t k){assert(k > 0);if (k > NPAGES - 1){Span* kSpan = new Span;void* ptr = SystemAlloc(k);kSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;kSpan->_n = k;_idSpanMap[kSpan->_pageId] = kSpan;return kSpan;}//......}1.2.释放
大内存块不能被挂在ThreadCache桶中,需要单独写释放逻辑。即直接放到PageCache桶中。代码实现:在ConcurrentFree中添加size>256KB的分支,调用ReleaseSpanToPageCache,并且在此期间进行上锁。如下,添加的部分:
static void ConcurrentFree(void* ptr,size_t size){ Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr); if (size > MAX_BYTES) { PageCache::GetInstance()->_pageMtx.lock(); PageCache::GetInstance()->ReleaseSpanToPageCache(span); PageCache::GetInstance()->_pageMtx.unlock(); } else { //正常逻辑 //...... }}同样的对于小于128页的内存释放ReleaseSpanToPageCache无需修改,如果释放的内存是>128页呢?此时无法挂到PageCache桶中,我们直接让系统释放即可,并且删除Span结构。如下ReleaseSpanToPageCache中添加的部分:
void PageCache::ReleaseSpanToPageCache(Span* span){if (span->_n > NPAGES - 1){void* ptr = (void*)(span->_pageId << PAGE_SHIFT);SystemFree(ptr);delete span;return;}//......}2.优化释放
![]()
如上实现,用户在调用释放内存的接口时是需要手动传入内存大小size,这样很繁琐,而且容易出错。我们希望不需要用户传这个参数也能完成工作。
该如何做?可以从这个方向思考?
- 理清楚这个参数的作用是什么,是否用其他操作可以替代这个效果。
- 有没有其他方式获得size,比如通过传入的ptr。
第1点基本上不用考虑了,因为我们的代码中已经充斥着大量的size的使用,要用其他方式来替代成本太大了。
对于第2点是有可行性的,因为在Span切割时已经确定了一个Span中切割的所有小块内存的大小都是一样的。而在上一期我们已经建立了页号与Span的映射表,一个地址(ptr)除以8KB就能得到它所在的页号,也就能得到它对于的Span。
也就是在Span中记录它切割的内存块大小即可。所以添加成员变量_objSize,在Span分配和切割时进行填写,这里就不展示。
接下来可以把size参数去掉,通过ptr找到Span然后找到_objSize。如下:
static void ConcurrentFree(void* ptr){ Span* span = PageCache::GetInstance()->MapObjectToSpan(ptr); if (span->_objSize > MAX_BYTES) { PageCache::GetInstance()->_pageMtx.lock(); PageCache::GetInstance()->ReleaseSpanToPageCache(span); PageCache::GetInstance()->_pageMtx.unlock(); } else { assert(pTLSThreadCache); pTLSThreadCache->Deallocate(ptr, span->_objSize); }}3.测试
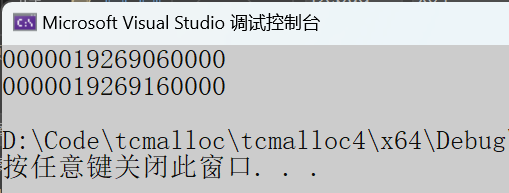
测试代码:
void BigAlloc(){void* p1 = ConcurrentAlloc(257 * 1024);cout << p1 << endl;ConcurrentFree(p1);void* p2 = ConcurrentAlloc(129 * 8 * 1024);cout << p2 << endl;ConcurrentFree(p2);}测试结果:
二、脱离malloc
1.定长内存池替代new
在程序中我们还有一些地方使用了malloc,比如申请Span时,申请ThreadCache时。
注:new的底层就是malloc。
我们希望把这些地方也脱离malloc,为什么呢?
-
锁竞争:malloc/free 通常使用全局锁来保证线程安全,在高并发场景下会成为严重瓶颈。
-
系统调用开销:malloc 可能触发 brk/sbrk 或 mmap 系统调用,导致用户态/内核态切换。
-
传统 malloc 难以有效处理高频率小内存分配释放导致的内存碎片。
-
长期运行后可能出现内存足够但无法分配的情况。
-
通用 malloc 需要兼顾各种场景,无法针对特定应用模式优化。
-
高并发场景通常有特定的内存使用模式(如固定大小对象)。
因为Span和ThreadCache都是固定的内存大小,我们可以使用定长内存池来替代。定长内存池的学习可以参考下文:
定长内存池原理及实现-CSDN博客
然后在Common.h中添加头文件,并定义一个模板参数为Span的定长内存池。
#include \"ObjectPool.h\"using namespace my_MemoryPool;struct Span;static FixedMemoryPool _spanPool;如果是VS2022可以通过Ctrl+f查找所有的new和delete申请释放的Span,把它们替换成 _spanPool.New()和_spanPool.Delete()。
在ThreadCache的申请中,定义一个模板参数为ThreadCache的定长内存池静态变量。然后替换new。如下:
static void* ConcurrentAlloc(size_t size){ if (size > MAX_BYTES) { //...... } else { if (pTLSThreadCache == nullptr) { static FixedMemoryPool tcPool; pTLSThreadCache = tcPool.New(); } return pTLSThreadCache->Allocate(size); }}三、Bug修复
1.页号到Span的映射
在NewSpan中满足_spanLists[k]不为空的逻辑,我们需要把取到的Span的页与Span映射填写到哈希表中。并且把它_isUse设为true。
对哈希表(_idSpanMap)的查找MapObjectToSpan函数中涉及find,可能被多个线程同时访问出现错误,需要加锁。
2.桶下标计算
static inline int _Index(size_t bytes, size_t align_shift){ return ((bytes + (1 <> align_shift) - 1;}我们讲过以上计算出来的只是这个对齐后的字节数 对于相应 对齐数 在数组上起始位置的相对位置,还需要加上前面对齐占用的数组元素个数才能得到正确的下标。而忽略了需要给_Index传的也是相对位置,如下:
static inline size_t Index(size_t bytes){ assert(bytes <= MAX_BYTES); static int group_array[4] = { 16, 56, 56, 56 }; if (bytes <= 128) return _Index(bytes, 3); else if (bytes <= 1024) return _Index(bytes - 128, 4) + group_array[0]; else if (bytes <= 8 * 1024) return _Index(bytes - 1024, 7) + group_array[0] + group_array[1]; else if (bytes <= 64 * 1024) return _Index(bytes - 8 * 1024, 10) + group_array[0] + group_array[1] + group_array[2]; else if (bytes <= 256 * 1024) return _Index(bytes - 64 * 1024, 13) + group_array[0] + group_array[1] + group_array[2] + group_array[3]; else { assert(false); return -1; }}FetchRangeObj函数中计算桶下标写成了SizeClass::RoundUp(size); 正确的应该是:
//计算Span链表桶下标size_t index = SizeClass::Index(size); 3.SpanList[页数]
有很多地方需要加SpanList[页数]都写成了SpanList,可以通过Ctrl+f查找并修改。
4.Span切割
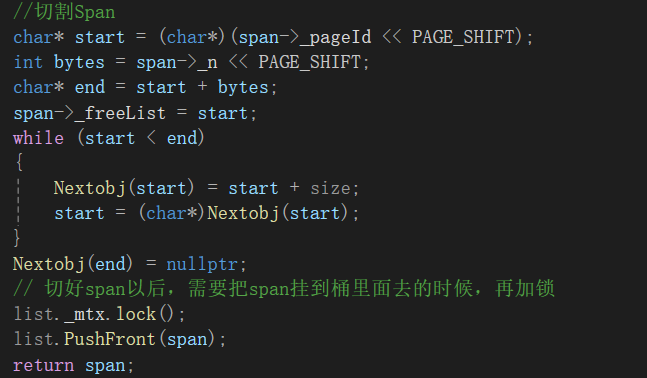
如上写法,因为end已经是结尾的最后一个字符了,虽然这里Nextobj(end)是合法的,但只用了一个字节,而我们再次访问空间的时候用的是4/8字节,就检测不到nullptr,被误认为是开好的空间,从而出现非法访问。
解决方法:添加一个中间变量,如下:
char* start = (char*)((PAGE_ID)span->_pageId <_n <_freeList = start;char* tmp = start;start += size;while (start _objSize = size;// 切好span以后,需要把span挂到桶里面去的时候,再加锁list._mtx.lock();list.PushFront(span);return span;四、性能测试
主要是与malloc做对比,这里这样设计,每轮申请和释放ntimes次,nworks个线程,执行rounds轮,然后计算它们要花费的时间。以下给出测试代码,不过这里大家大可不必纠结代码,我们直接来看结果。
性能测试代码:
#include\"ConcurrentAlloc.h\"#include// ntimes 一轮申请和释放内存的次数// rounds 轮次void BenchmarkMalloc(size_t ntimes, size_t nworks, size_t rounds){std::vector vthread(nworks);std::atomic malloc_costtime = 0;std::atomic free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&, k]() {std::vector v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(malloc(16));//v.push_back(malloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++)free(v[i]);size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread){t.join();}printf(\"%zu个线程并发执行%zu轮次,每轮次malloc %zu次: 花费:%.2f ms\\n\",nworks, rounds, ntimes, (double)malloc_costtime);printf(\"%zu个线程并发执行%zu轮次,每轮次free %zu次: 花费:%.2f ms\\n\",nworks, rounds, ntimes, (double)free_costtime);printf(\"%zu个线程并发malloc&free %zu次,总计花费:%.2f ms\\n\",nworks, nworks * rounds * ntimes, (double)(malloc_costtime + free_costtime));}// 单轮次申请释放次数 线程数 轮次void BenchmarkConcurrentMalloc(size_t ntimes, size_t nworks, size_t rounds){std::vector vthread(nworks);std::atomic malloc_costtime = 0;std::atomic free_costtime = 0;for (size_t k = 0; k < nworks; ++k){vthread[k] = std::thread([&]() {std::vector v;v.reserve(ntimes);for (size_t j = 0; j < rounds; ++j){size_t begin1 = clock();for (size_t i = 0; i < ntimes; i++){v.push_back(ConcurrentAlloc(16));//v.push_back(ConcurrentAlloc((16 + i) % 8192 + 1));}size_t end1 = clock();size_t begin2 = clock();for (size_t i = 0; i < ntimes; i++){ConcurrentFree(v[i]);}size_t end2 = clock();v.clear();malloc_costtime += (end1 - begin1);free_costtime += (end2 - begin2);}});}for (auto& t : vthread)t.join();printf(\"%zu个线程并发执行%zu轮次,每轮次concurrent alloc %zu次: 花费:%.2f ms\\n\",nworks, rounds, ntimes, (double)malloc_costtime);printf(\"%zu个线程并发执行%zu轮次,每轮次concurrent dealloc %zu次: 花费:%.2f ms\\n\",nworks, rounds, ntimes, (double)free_costtime);printf(\"%zu个线程并发concurrent alloc&dealloc %zu次,总计花费:%.2f ms\\n\",nworks, nworks * rounds * ntimes, (double)(malloc_costtime + free_costtime));}int main(){size_t n = 10000;cout << \"==========================================================\" << endl;BenchmarkConcurrentMalloc(n, 4, 10);cout << endl << endl;BenchmarkMalloc(n, 4, 10);cout << \"==========================================================\" << endl;return 0;}Debug
固定内存:
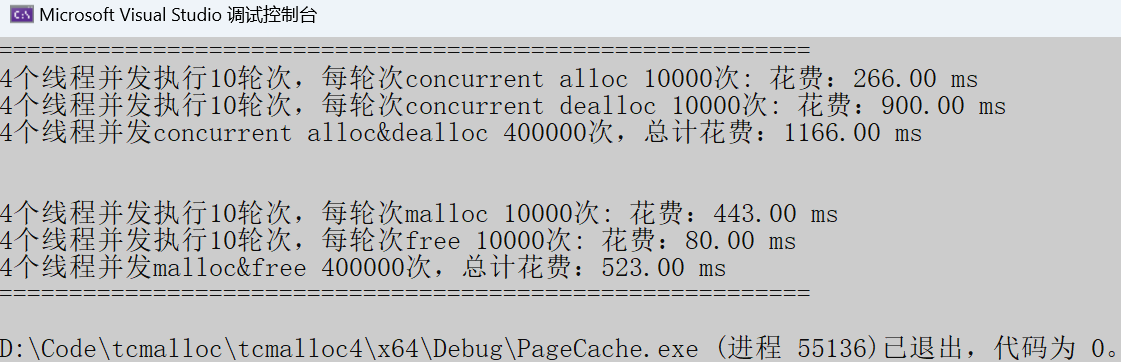
- 申请内存:tcmalloc快于malloc两倍左右。
- 释放内存:tcmalloc整整慢了malloc十倍多。
随机内存:
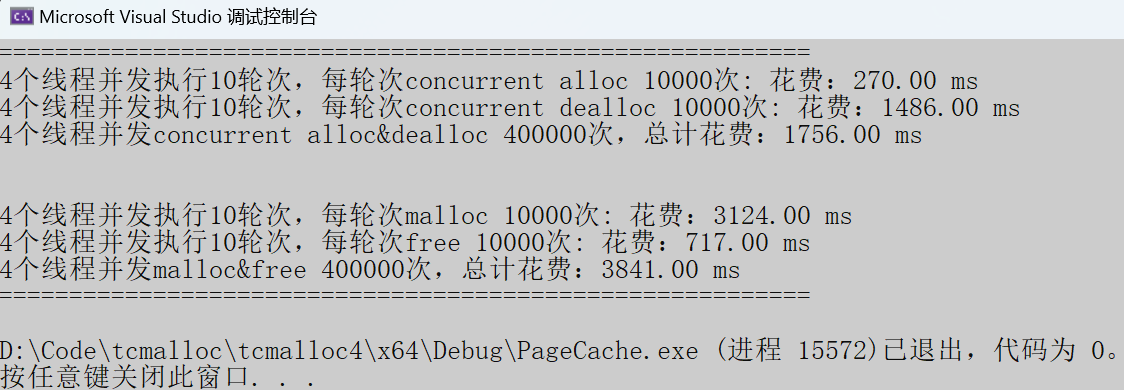
- 申请内存:tcmalloc快于malloc十倍多。
- 释放内存:tcmalloc慢了malloc两倍多。
我们观察发现,tcmalloc总在释放的过程慢于malloc,要突破性能瓶颈我们就需要对tcmalloc的释放过程做优化。
性能分析
这里做性能分析主要是找到哪个函数消耗的时间长,然后针对性的进行修改。
在做性能分析时要保证是在debug下,并把向malloc申请内存的部分注释掉。然后做如下操作:
右键项目打开属性,然后做如下配置:
打开调试性能探查器
打开检测
打开详细信息
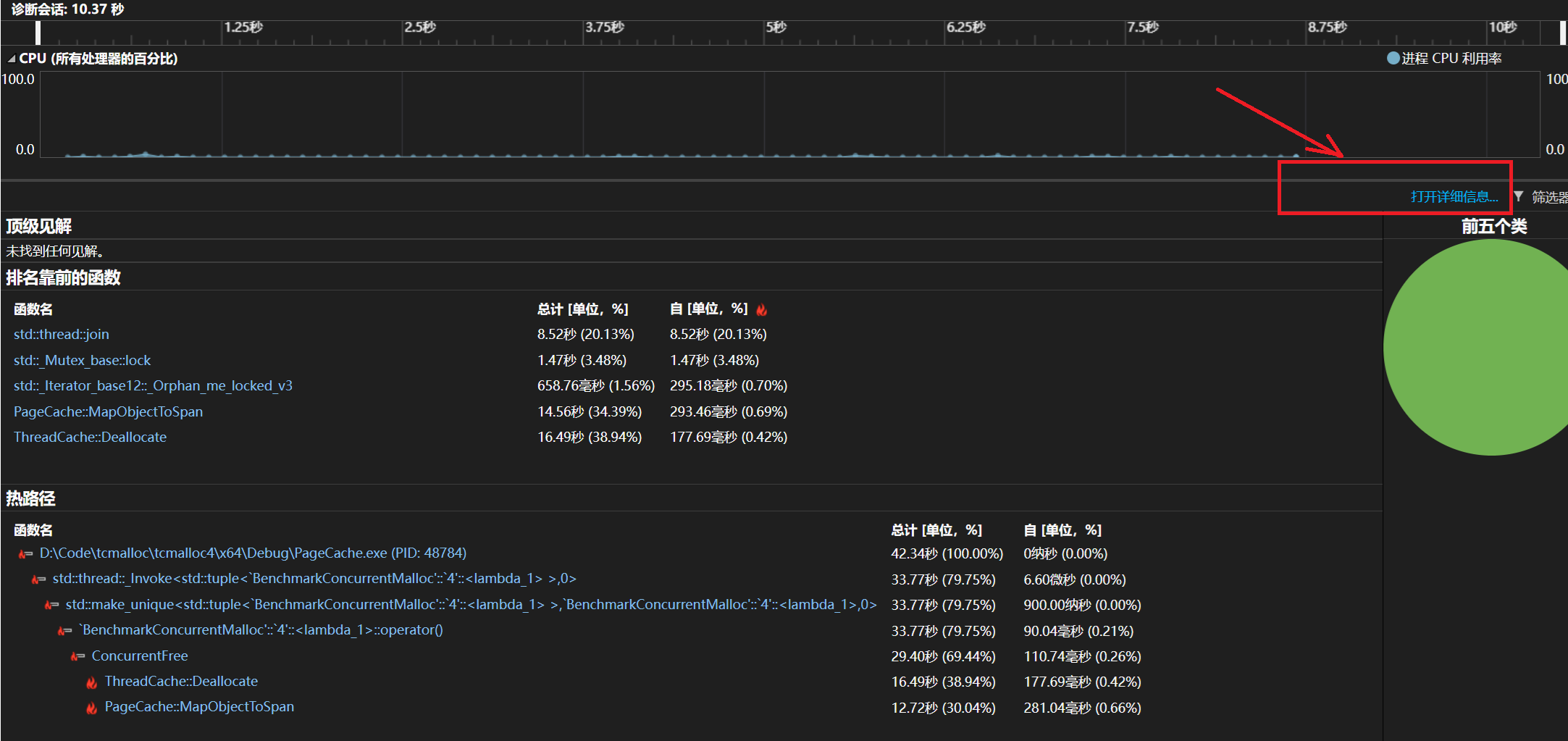
打开火焰图
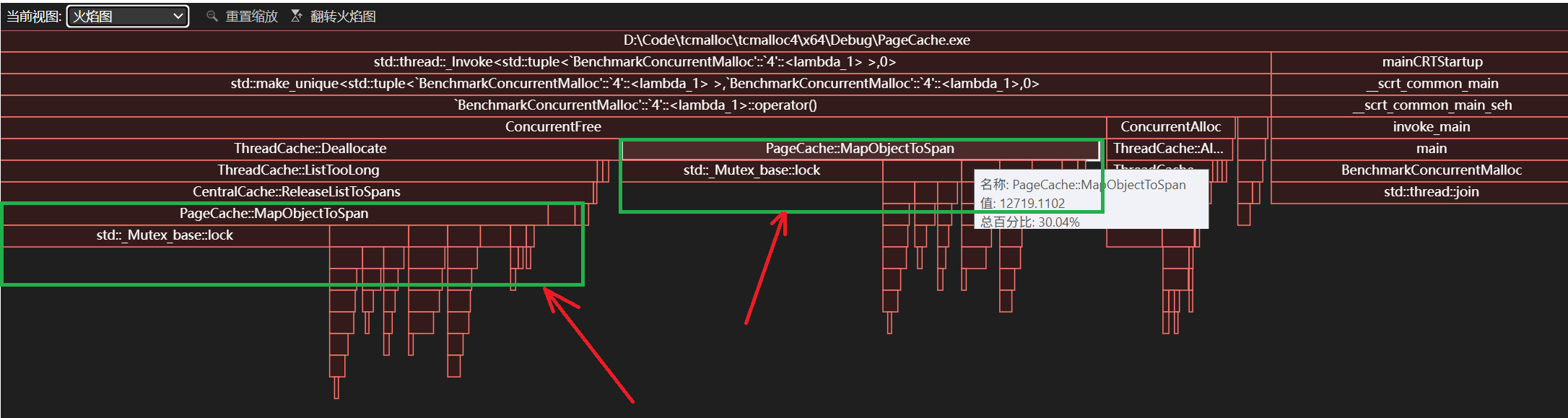
我们可以观察到几乎60%以上的时间消耗都是来自函数MapObjectToSpan,而主要是来自内部锁竞争的消耗。在map中查找越慢,锁竞争越激烈。
接下来我们对MapObjectToSpan进行替代。
五、性能优化
MapObjectToSpan是用来查找页号与Span的映射关系的,使用哈希桶unordered_map,STL中并未对数据结构并发访问问题进行处理,不是原子的。所以在find()查找过程会出问题,需要加锁来保护临界资源。
这里我们考虑换一种结构,使用基数树,基数树是一种通过压缩公共前缀路径优化存储的前缀树结构,支持高效的前缀匹配和键值查询。
这里我们设定三棵基数树,分别是一层,两层,三层。
只有一层的基数树本质就是数组(直接定址法的哈希表),页号到Span的映射,如下:
template class TCMalloc_PageMap1 {private:static const int LENGTH = 1 << BITS;void** array_;public:typedef uintptr_t Number;//构造函数,给数组开空间explicit TCMalloc_PageMap1() {size_t size = sizeof(void*) << BITS;size_t alignSize = SizeClass::_RoundUp(size, 1 <> PAGE_SHIFT);memset(array_, 0, sizeof(void*) <> BITS) > 0) {return NULL;}return array_[k];}//添加页号与Span的映射void set(Number k, void* v) {array_[k] = v;}};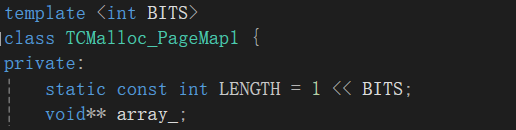
BITS给的是32-PAGE_SHIFT(32位下)或64-PAGE_SHIFT(64位下),表示存储页号的位数。
比如32位机器下8KB为一页,需要(2^32)/(2^13)=2^19个页号,即2^(32-PAGE_SHIFT)。
如果内存比较大,就需要开辟更大的数组,又因为很难一次性开出。所以把它拆除多块。即2层或3层
对于两层这样设定:
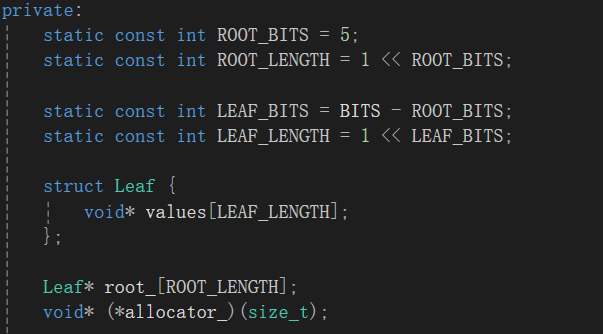
以32位为例,如上需要19位空间来储存页号,对于第一层给5位,也就是2^5=32个空间。然后把后14位给第二层。合计开辟(2^5)*(2^14)。与一层基数树开辟的空间相同。
拿到传来的页号,它是4字节的即32位,用前5位去匹配第一层并找到第二层的映射表,再用后面的位去匹配映射表找到对应的Span。
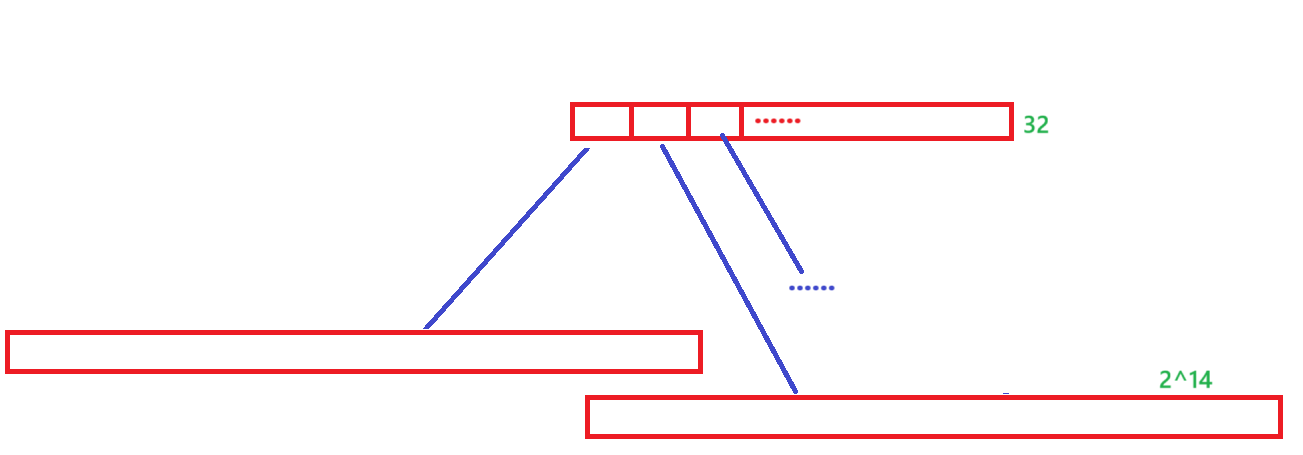
三层基数树的设定同理,不做讲解。
注意对于64位机器,(2^64)/(2^13)=2^53个页,要一次性开辟这么大的空间几乎是不可能的,所以必须使用三层,相当于把空间拆成小块开辟。而且等需要用到时再开辟,要不然会造成很多浪费。
以32位机器为例,把原来unordered_map结构改为TCMalloc_PageMap1,如下:
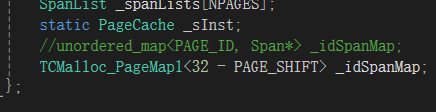
然后用Ctrl+f找到所有使用_idSpanMap的地方,进行修改。
再次进行性能测试查看火焰图:
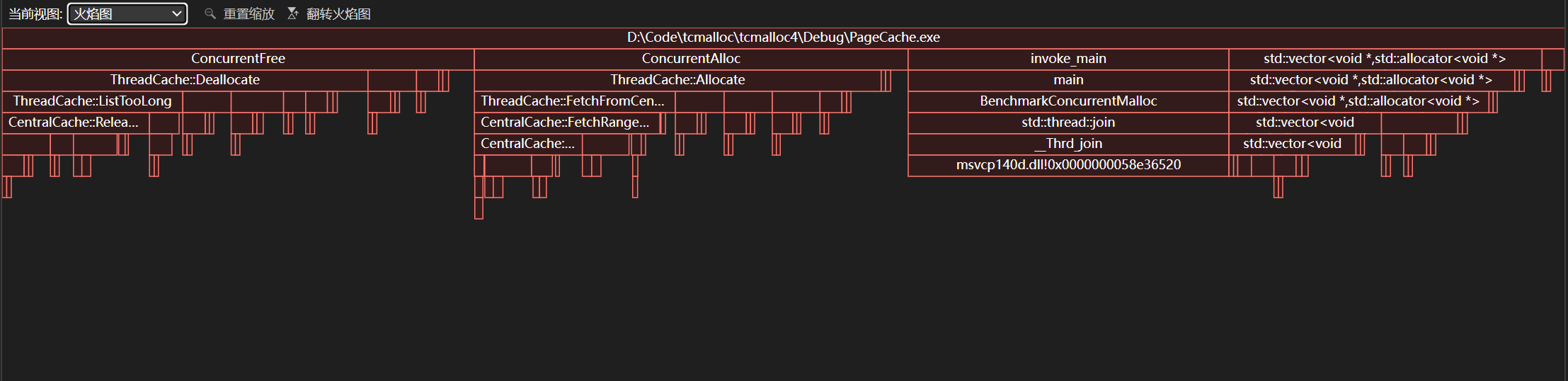
它们的时间消耗的是差不多的,没有针对性的优化意义不是很大。
测试结果
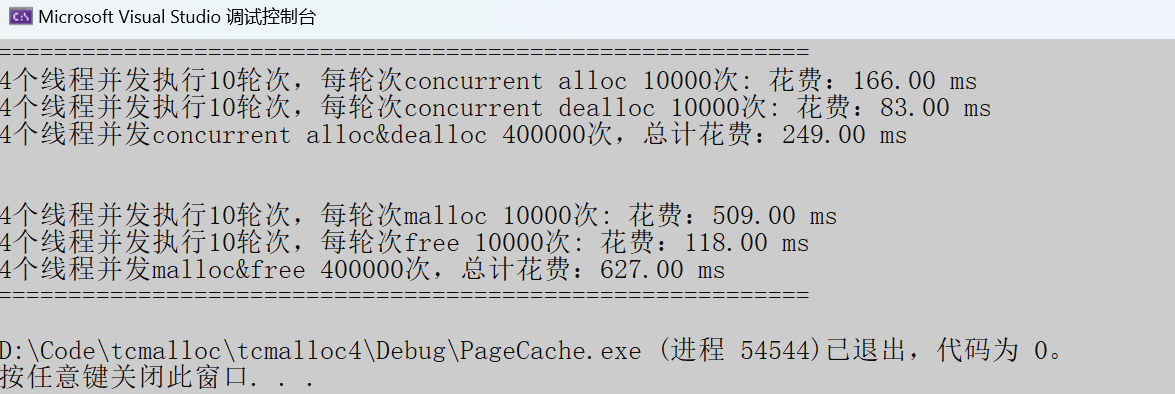
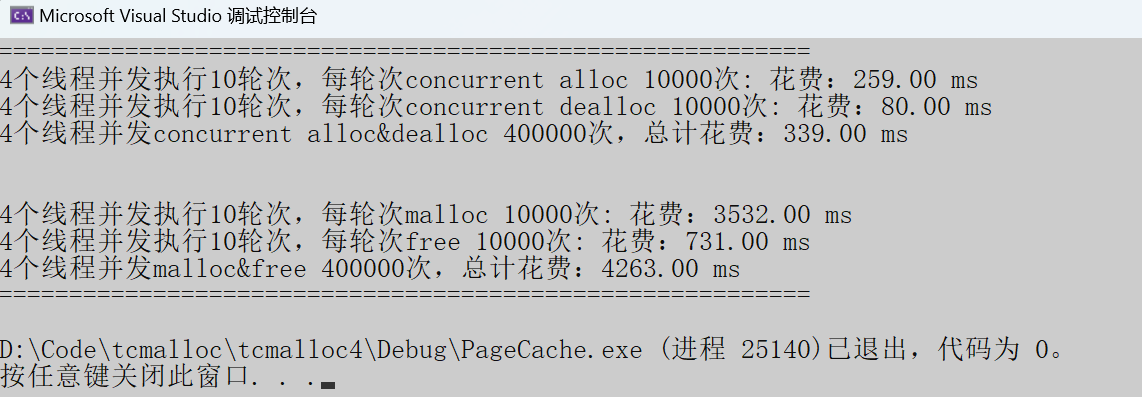
Debug模式
固定内存申请
随机内存申请:
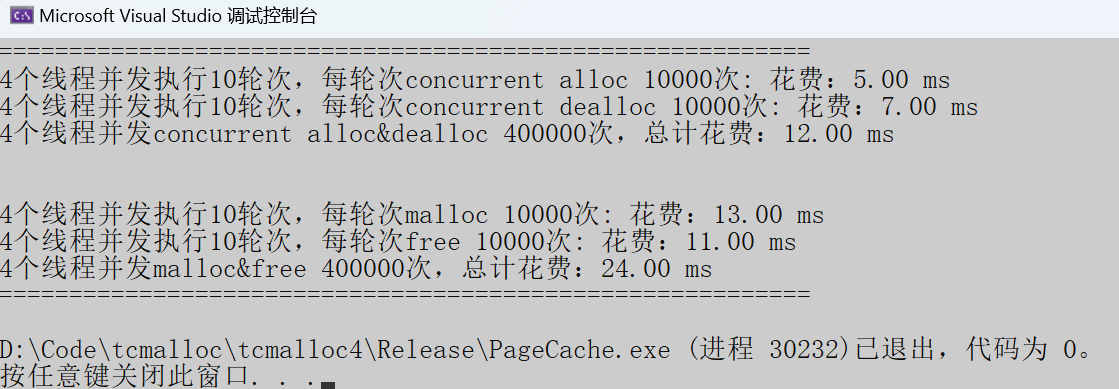
Release模式
固定内存申请:
随机内存申请:
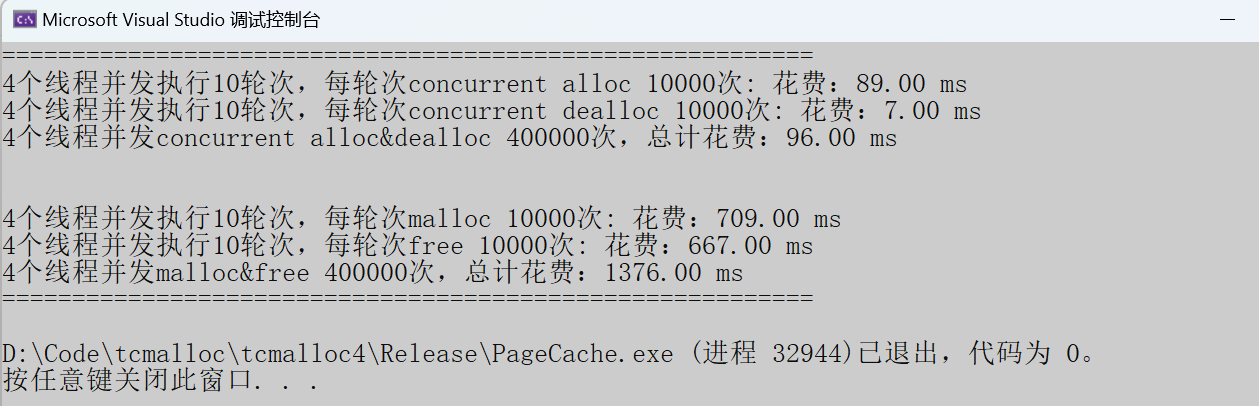
当下 tcmalloc 的性能堪称一骑绝尘,对 malloc 形成了直接碾压,优势一目了然!
非常感谢您能耐心读完这篇文章。倘若您从中有所收获,还望多多支持呀!

六、源码
tcmalloc/Code · 敲上瘾/ConcurrentMemoryPool - 码云 - 开源中国

