一周刷爆LeetCode,直击BTAJ等一线大厂必问算法面试题真题详解 【第四弹】
目录
11、排序算法的稳定性及其汇总
11.1 排序算法的稳定性
11.2 常见的坑
11.3 工程上对排序的改进
12、链表
12.1 HashSet 和 HashMap
12.2 有序表
12.3 面试时链表解题的方法论
*12.4 关于链表的练习题
*
11、排序算法的稳定性及其汇总
11.1 排序算法的稳定性
同样值的个体之间,如果不因为排序而改变相对次序,就是这个排序是有稳定性的;否则就没有。
误区:认为稳定性是随数据的差异会影响算法的时间空间复杂度【容易产生的认知】
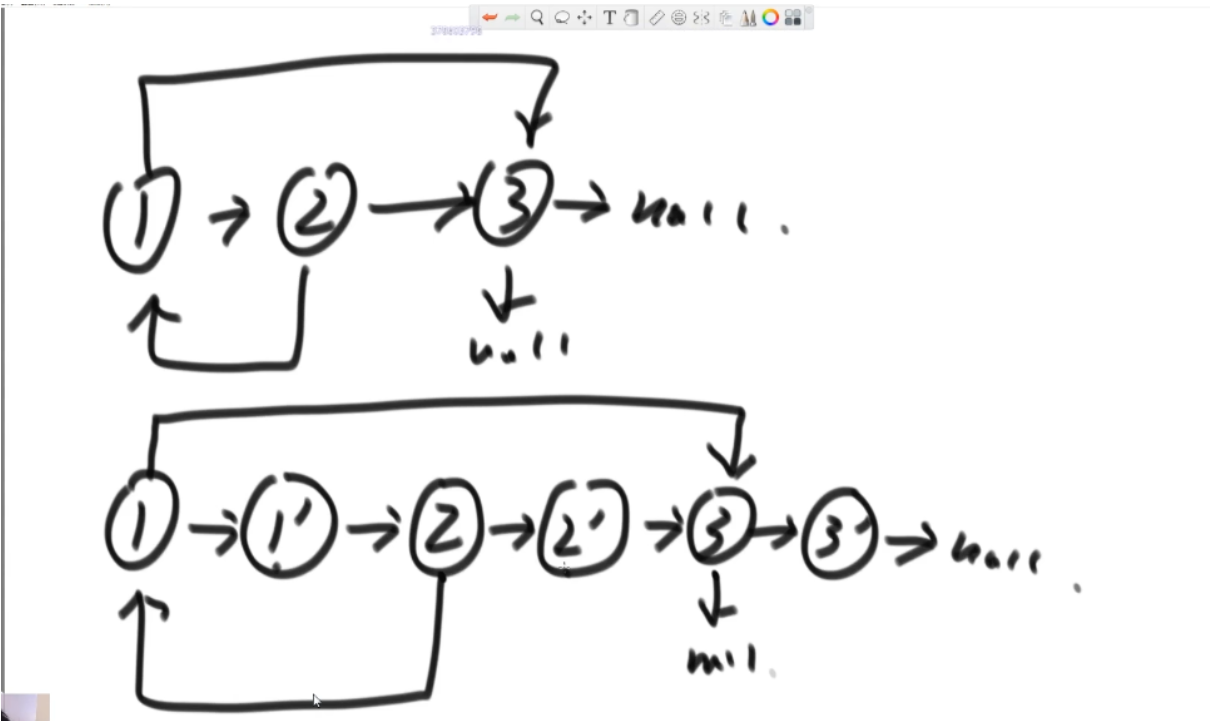
不具备稳定性的排序: 选择排序、快速排序、堆排序
具备稳定性的排序: 冒泡排序、插入排序、归并排序、一切桶排序思想下的排序
总结:只要有跨度的交换,就会丧失稳定性。相邻交换的则不会。

不具有稳定性的排序算法:
选择排序
快速排序
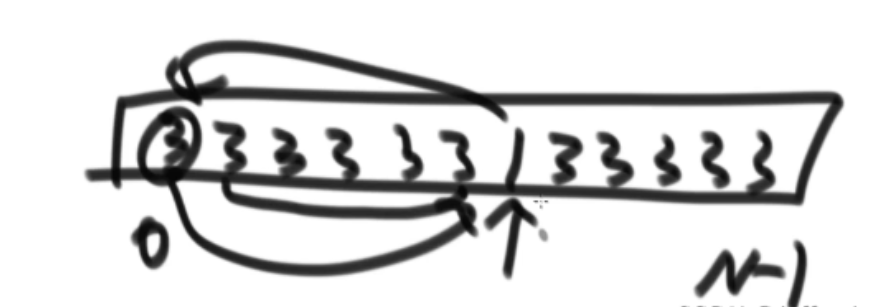
堆排序更是无视稳定性,他只认识孩子和父亲,进行大跨度无序交换
具有稳定性的排序算法:
冒泡排序
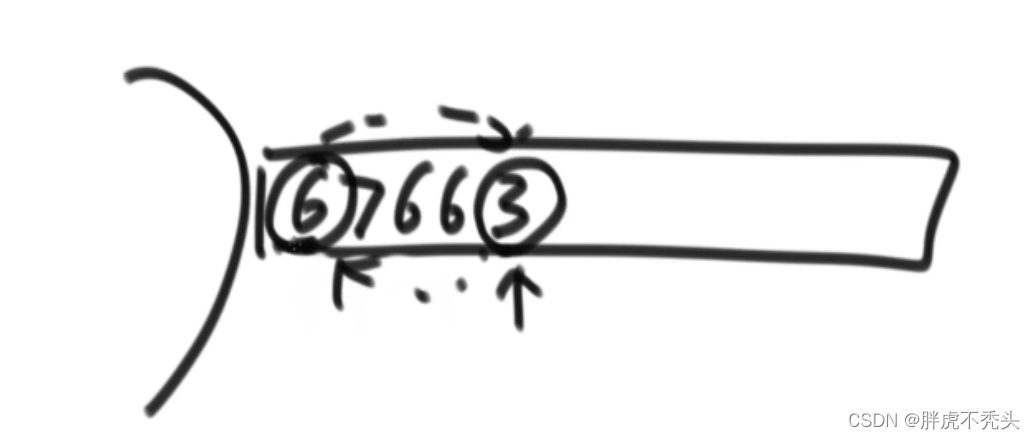
插入排序
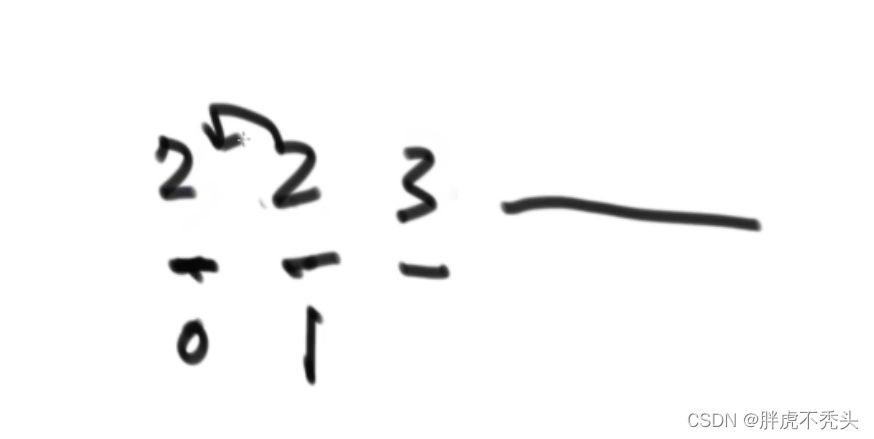
归并排序关键在于merge的时候,要先拷贝左边的数,而用归并解决小和问题的时候,要先拷贝右边的数,则丧失稳定性

目前没有找到时间复杂度0(N*logN),额外空间复杂度0(1),又稳定的排序。
11.2 常见的坑
-
归并排序的额外空间复杂度可以变成0(1),但是非常难,不需要掌握,有兴趣可以搜“归并排序内部缓存法”
-
“原地归并排序”的帖子都是垃圾,会让归并排序的时间复杂度变成O(N~2)
-
快速排序可以做到稳定性问题,但是非常难,不需要掌握,可以搜“01stable sort"
-
所有的改进都不重要,因为目前没有找到时间复杂度0(N*logN),额外空间复杂度0(1),又稳定的排序。
-
有一道题目,是奇数放在数组左边,偶数放在数组右边,还要求原始的相对次序不变,碰到这个问题,可以怼面试官。
11.3 工程上对排序的改进
1)充分利用O(N*IogN)和0(N^2)排序各自的优势 2)稳定性的考虑
在快速排序中,当样本量小于60的时候,插入排序时间复杂度相当,当常数操作复杂度极低,因此可以将2种混合起来。
public class Test { public static void quickSort(int[] arr, int 1, int r) { if(1 ==r){ return; } if (1 >r - 60) {//插入排序 在arr[1..r]插入排序 O(Nへ2)小样本量的时候,跑的快 return; } swap(arr, 1 + (int) (Math.random() * (r - 1 + 1)), r);//快速排序 int[] p = partition(arr, 1, r); quickSort(arr, 1, p[0] - 1); //‹ 区 quickSort(arr, p[1] + 1, r); // > 区 }}大样本调度快选择 O(N*IogN);小样本选择插入,跑得快 0(N^2)
12、链表
12.1 HashSet 和 HashMap
哈希表的简单介绍
-
哈希表在使用层面上可以理解为一种集合结构
-
如果只有key,没有伴随数据value,可以使用HashSet结构(C++中叫UnOrderedSet)
-
如果既有key,又有伴随数据value,可以使用HashMap结构(C++中叫UnOrderedMap)
-
有无伴随数据,是HashMap和HashSet唯一的区别,底层的实际结构是一回事
-
使用哈希表增(put)、删(remove)、改(put)和查(get)的操作,可以认为时间复杂度为0(1),但是常数时间比较大
-
放入哈希表的东西,如果是基础类型,内部按值传递,内存占用就是这个东西的大小
-
放入哈希表的东西,如果不是基础类型,内部按引用传递,内存占用是这个东西内存地址的大小
12.2 有序表
有序表的简单介绍
-
有序表在使用层面上可以理解为一种集合结构
-
如果只有key,没有伴随数据value,可以使用TreeSet结构(C++中叫OrderedSet)
-
如果既有key,又有伴随数据value,可以使用TreeMap结构(C++中叫OrderedMap)
-
有无伴随数据,是TreeSet和TreeMap唯一的区别,底层的实际结构是一回事
-
有序表和哈希表的区别是,有序表把key按照顺序组织起来,而哈希表完全不组织
-
红黑树、AVL树、size-balance-tree和跳表等都属于有序表结构,只是底层具体实现 不同
-
放入有序表的东西,如果是基础类型,内部按值传递,内存占用就是这个东西的大小
-
放入有序表的东西,如果不是基础类型,必须提供比较器,内部按引用传递,内存占 用是这个东西内存地址的大小
-
不管是什么底层具体实现,只要是有序表,都有以下固定的基本功能和固定的时间复 杂度
12.3 面试时链表解题的方法论
-
对于笔试,不用太在乎空间复杂度,一切为时间复杂度
-
对于面试,时间复杂度依然放在第一位,但是一定要找到空间最省的方法
重要技巧:
-
额外数据结构记录(哈希表等)
-
快慢指针
*12.4 关于链表的练习题
12.4.1 判断一个链表是否为回文结构
【题目】给定一个单链表的头节点head,请判断该链表是否为回文结构。 【例子】1->2->1,返回true;1->2->2->1,返回true;15->6->15,返回true;1->2->3,返回false。 【例子】如果链表长度为N,时间复杂度达到O(N),额外空间复杂度达到O(1)。
把链表扔到栈,然后弹出一个比对一个
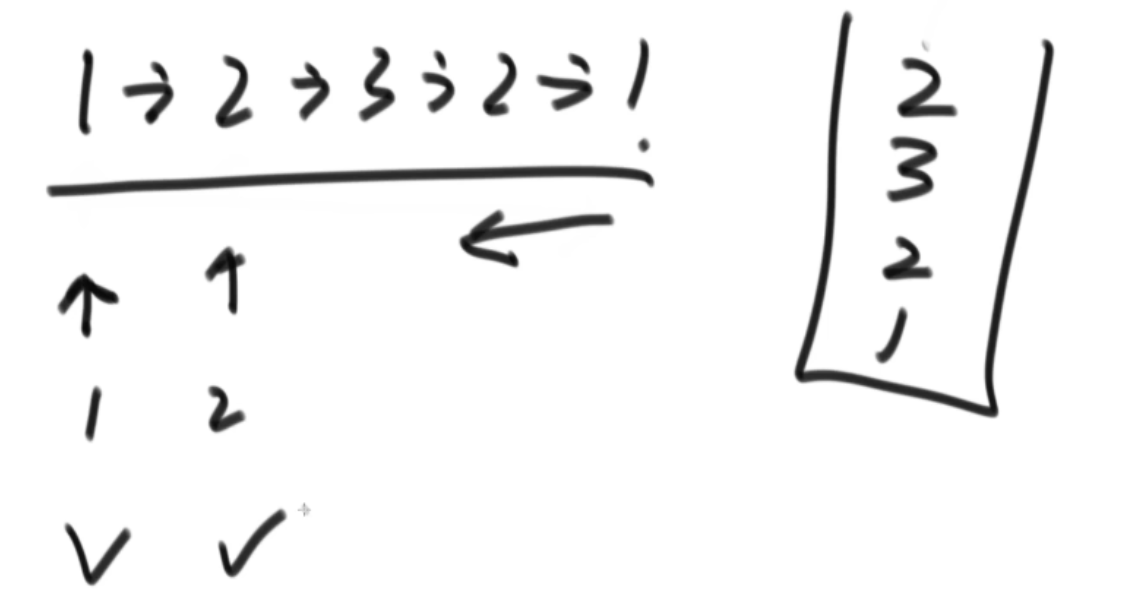
优化算法1:只将链表的右半部分扔到栈中,然后对比(节省了一般的空间复杂度)
优化算法2:使用快慢指针,快指针结束的时候,慢指针走到中点。这个coding要练熟。
如果要使用低空间复杂度,使用改链表的方式,最后再恢复:
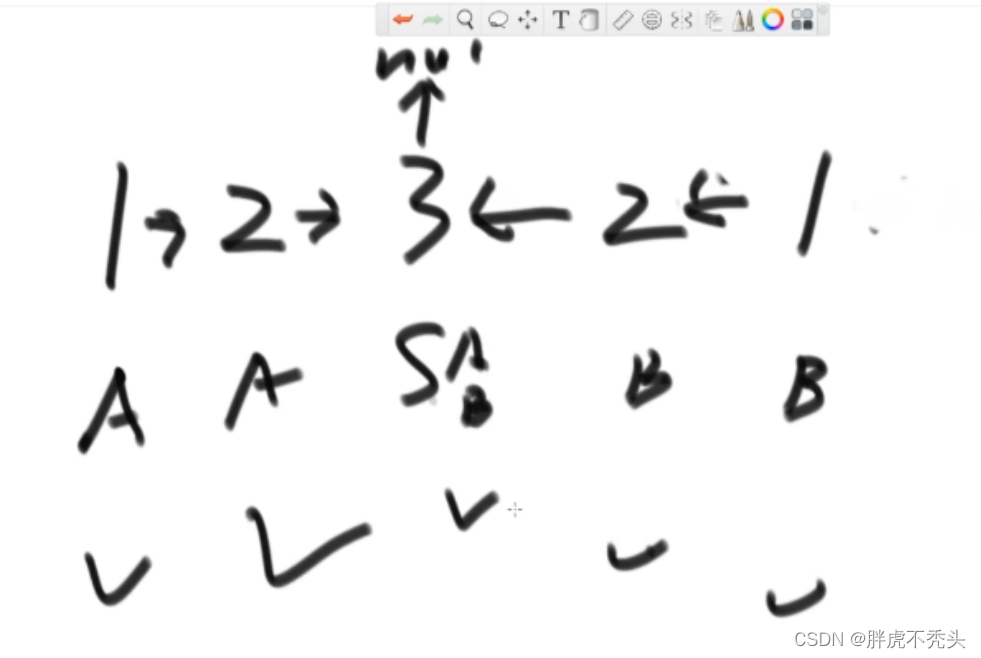
// need O(1) extra space public static boolean isPalindrome3(Node head) { if (head == null || head.next == null) { return true; } Node n1 = head;//慢指针 Node n2 = head;//快指针 //快慢指针找末尾和中点 while (n2.next != null && n2.next.next != null) { // find mid node n1 = n1.next; // n1 -> mid n2 = n2.next.next; // n2 -> end } n2 = n1.next; // n2 -> right part first node n1.next = null; // mid.next -> null Node n3 = null;//用于记录n2原本的下一个node //右半部分逆序 while (n2 != null) { // right part convert n3 = n2.next; // n3 -> save next node,保留未改变的链表 n2.next = n1; // next of right node convert,改变链表指向 //n1,n2两个指针完成改变指向操作后,同时右移,准备下一个元素的链表指向逆序 n1 = n2; // n1 move n2 = n3; // n2 move } n3 = n1; // n3 -> save last node n2 = head;// n2 -> left first node boolean res = true; while (n1 != null && n2 != null) { // check palindrome //每走一步,都验证 if (n1.value != n2.value) { res = false; break; } //n1,n2从中间开始走 n1 = n1.next; // left to mid n2 = n2.next; // right to mid } n1 = n3.next; n3.next = null; //最后将逆序的链表变回来 while (n1 != null) { // recover list n2 = n1.next; n1.next = n3; n3 = n1; n1 = n2; } return res; }12.4.2 将单向链表按某值划分成左边小、中间相等、右边大的形式

笔试:创建node数组,把链表的node烤进去,再做partition,快速排序,即归并的3.0版本。
面试:使用6个变量指针,小于区域的头和尾,等于区域的头和尾,大于区域的头和尾,最后将3个区域连起来的时候,要注意是否有区域为空。
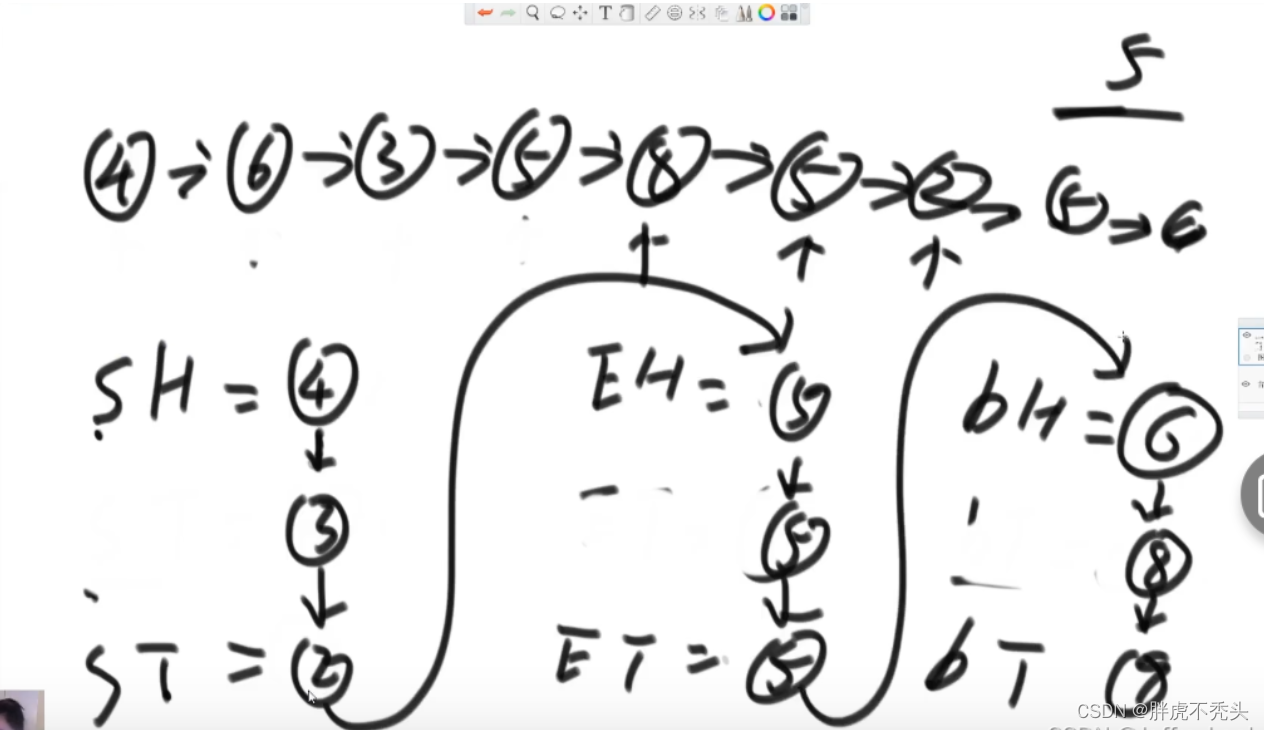
public static Node listPartition2(Node head, int pivot) { Node sH = null; // small head Node sT = null; // small tail Node eH = null; // equal head Node eT = null; // equal tail Node bH = null; // big head Node bT = null; // big tail Node next = null; // save next node // every node distributed to three lists while (head != null) { next = head.next; head.next = null; if (head.value < pivot) { if (sH == null) { sH = head; sT = head; } else { sT.next = head; sT = head; } } else if (head.value == pivot) { if (eH == null) { eH = head; eT = head; } else { eT.next = head; eT = head; } } else { if (bH == null) { bH = head; bT = head; } else { bT.next = head; bT = head; } } head = next; } // small and equal reconnect if (sT != null) { sT.next = eH; eT = eT == null ? sT : eT; } // all reconnect if (eT != null) { eT.next = bH; } return sH != null ? sH : eH != null ? eH : bH; }
12.4.3 复制含有随机指针节点的链表

做法1:第一次遍历旧链表,使用哈希map,key为旧链表,value为新链表,新链表只是单纯地串起来并拷贝int value值,rand没有设置;第二次遍历旧链表,调用key-value,设置rand node。
做法2:第一次遍历旧链表,不用哈希map,在旧map中,插入克隆node,拷贝int value值;第二次遍历链表,一对一对处理,设置rand node;第三次遍历,把旧节点删除。省去了hashmap的空间。