Python每日一练-----全排列(回溯思想)
⛅(day22)
目录
🖍题目:
题目分析:
解题思路:
🌈回溯解法
✏代码注释
🖍题目:
给定一个不含重复数字的数组 nums ,返回其 所有可能的全排列 。你可以 按任意顺序 返回答案。
1 <= nums.length <= 6-10 <= nums[i] <= 10nums中的所有整数 互不相同
🌠示例 1:
输入:nums = [1,2,3]
输出:[[1,2,3],[1,3,2],[2,1,3],[2,3,1],[3,1,2],[3,2,1]]
🌠示例 2:
输入:nums = [0,1]
输出:[[0,1],[1,0]]
🌠示例 3:
输入:nums = [1]
输出:[[1]]
题目分析:
题目要求对给出的数组的数值进行全排列,因为数组中的数字互不相同所以我们解题的时候不必担心交换位置或者是填入数值时出现重复问题。
解题思路:
回溯解法:一种通过探索所有可能的候选解来找出所有的解的算法。如果候选解被确认不是一个解(或者至少不是最后一个解),回溯算法会通过在上一步进行一些变化抛弃该解,即回溯并且再次尝试。简单来说就是不断的探索求解(和递归有所联系),像一颗树,从根部出发,产生众多分支,最后在末梢得到一个分支的解后,在回溯到上一节点开始另一分支的计算。
解题时从节点1出发,到达节点2按顺序计算出结果1,因为没有可以继续进行的分支,所以回溯到节点2,从节点2另一分支开始计算出结果2,因为没又可以继续进行的分支,所以回溯到节点2,节点2的分支已经全部算出,所以又返回节点1,从节点1出发到节点3.以此类推
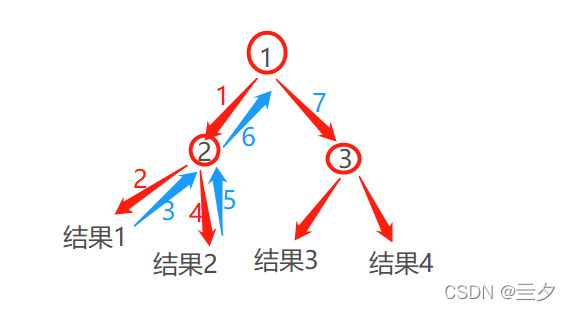
那么全排列和回溯有什么关系呢?
可以看到,对于全排列,如例1,我们可以按照如下的方法计算
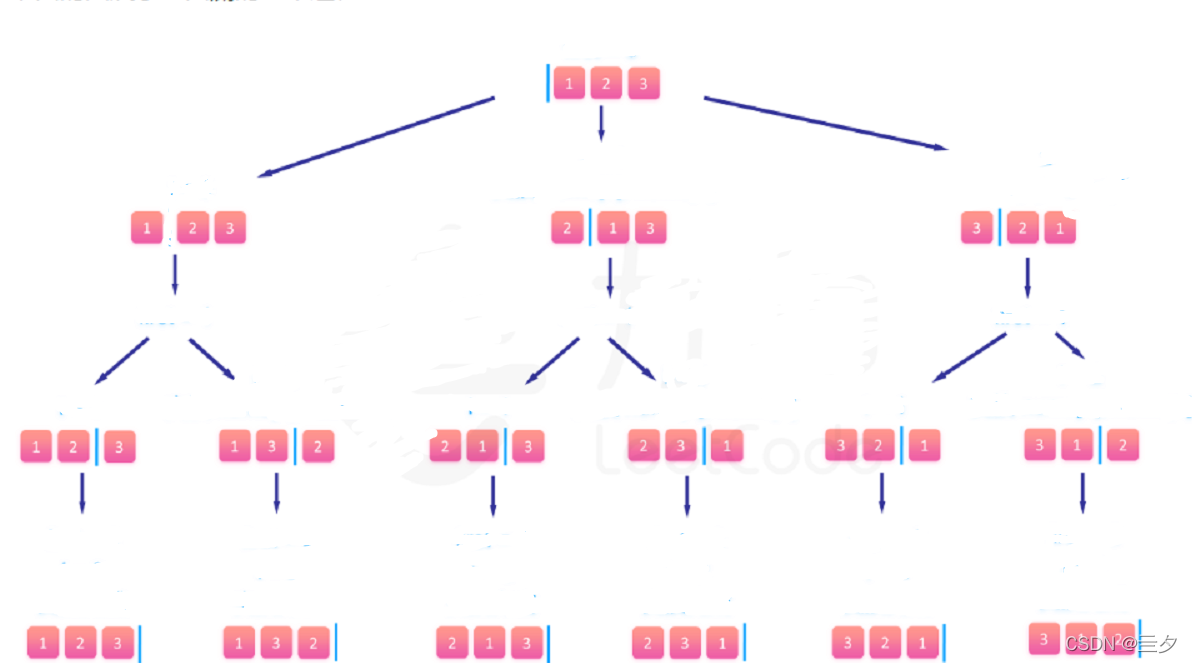
如何实现图中的算法
我们可以采取逐个填入的方法获得不同的排列,例如先填第一个位置,填到第几个位置我们可以使用标记值first记录。填入1时,用一个数组记录已经填过的数字,填第二个位置时先遍历记录数组,如果要填入的数不在记录数组内就可以填入,现在1已经填入第一个位置,那么第二个位置可以填入2或3,因为2和3不在记录数组内。现在第二个位置填入2,同时记录数组记录2已使用过,最后第三个位置想填入3,先遍历记录数组,3不在记录数组,所以第3个位置填入3.
那么为了减少计算的空间复杂度,可不可以不使用记录数组?
这是可以的,换一个思路,我们在位置填入时可以选择的数都是给定数组nums中的数字,那么我们就可以在原数组的基础上使用上述的标记值first将数组nums分割成左右两部分。左边的部分[0, first]是已经填写好的,右边的部分[first+1, n-1](n为数组nums的长度)是未填写好的,包含有未使用过的数值。那么在填入下一个位置时我们可以将first想右移一个位置,接着为了在该位置填入其他值我们交换该位置已填入的值和未填入的值即可。
例如
其实我们上面所说得first向右移一个位置也相当于一个交换,只是交换双方的值都是一样的。如[1 | 2 3]到[1 2 | 3]可以理解为2和2的交换。
简单的交换写法为 a , b = b, a
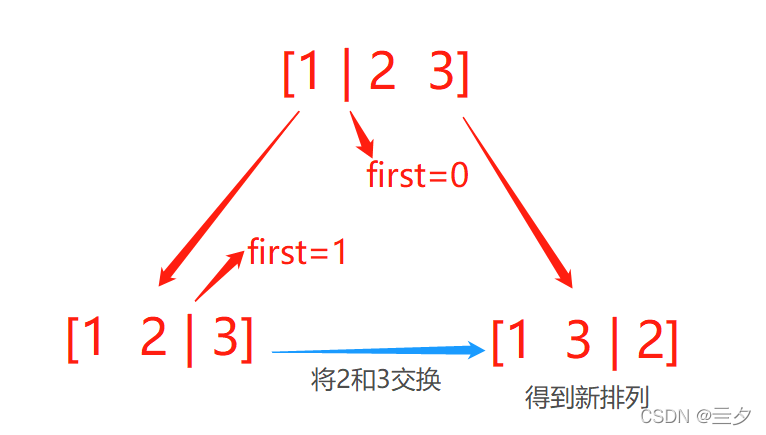
图示
代码实现
🌈回溯解法
def permute(nums): def backtrack(first=0): if first == n: res.append(nums[:]) for i in range(first, n): nums[first], nums[i] = nums[i], nums[first] backtrack(first + 1) nums[first], nums[i] = nums[i], nums[first] n = len(nums) res = [] backtrack() return res✏代码注释
def permute(nums): def backtrack(first=0): # 所有数都填完了 if first == n: res.append(nums[:]) for i in range(first, n): # 动态维护数组 nums[first], nums[i] = nums[i], nums[first] # 交换构成新排列 # 继续递归填下一个数 backtrack(first + 1) # 撤销操作 nums[first], nums[i] = nums[i], nums[first] n = len(nums) res = [] backtrack() return resif语句那一部分为什么使用的是res.append(nums[:])而不是res.append(nums)?
以nums = [1,2,3]为例
使用res.append(nums[:])输出为正确结果
[[1, 2, 3], [1, 3, 2], [2, 1, 3], [2, 3, 1], [3, 2, 1], [3, 1, 2]]
而使用res.append(nums)则输出结果错误
[[1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3], [1, 2, 3]]
如果使用res.append(nums)那么对于撤销操作,撤销操作修改的数组nums将会包括res里的数组,这是因为res直接添加nums后,这个nums数组和后续操作的数组nums是一样的。后续对nums所作的操作都会同步到res中的数组。这是我们就需要复制一个nums的副本,让副本加入res,这样后续对nums数组的操作就不会影响到res数组。
回溯主要体现在了撤销这一步。
可能会有一个疑问,撤销操作是怎么实现的?撤销操作不是只能进行一次吗,超过一次不是需要改变i和first的值才能撤销多次吗,但是在撤销这一操作没看出来在哪里改变i和first的值了。
这里说明撤销操作如何进行。
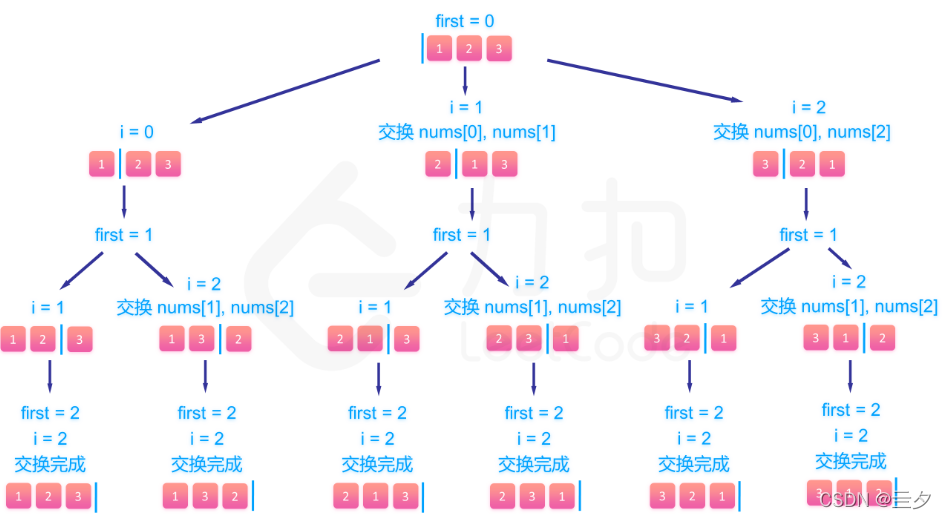
以图中分支为例。
- 开始时i = 0, first = 0. i的取值范围为range(0, 3)。(i还可以取1,2)
- ---------------------------------------------------------
- 接着进行nums[i] = 1与nums[first] = 1的交换。进入a点状态
- 使用递归,调用backtrack(first + 1),进入下一步交换。注意,正在没有递归完整个分支的时候时不会执行撤销操作的
- first + 1 = 1,i = 1,i的取值范围为range(1,3)。(i还可以取2)
- -----------------------------------------------------------
- 接着进行nums[i] = 2与nums[first] = 2的交换。进入b点状态
- 使用递归,调用backtrack(first + 1),进入下一步交换。
- first + 1 = 2,i的取值范围为range(2,3)。(i取完)
- -------------------------------------------------------------
- 接着进行nums[i] = 3与nums[first] = 3的交换。进入c点状态
- 使用递归,调用backtrack(first + 1),进入下一步交换。
- 但是这时候first + 1 = 3 = n最后一个递归结束(c状态结束),撤销操作可以执行(再c状态结束时,此时first = 2)。此时i = 2,first = 2,交换回来后返回到状态b
- 在b状态无分支也结束,此时i = 1,first = 1,进行撤销操作后返回到a状态
- 这是a状态的i还有2可取,所以i = 2,first = 1。(i取完)
- --------------------------------------------------------------
- 接着进行nums[i] = 3与与nums[first] = 2的交换。进入d点状态
- 以此类推
图解


今天就到这,明天见。🚀
❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄end❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄❄