数据库五章其三 ——视图与索引
目录
本人会用几天时间把在学校学到的整个数据库知识全盘托出,如果能看懂并且明白我接下来所写的博文,相信对你数据库提升、对行业软件理解、以后工作有很大帮助。
第三讲:视图与索引
目录
第三讲:视图与索引
引例代码
内容的引入
问题:
针对这种需求,如何设计数据库以便用户很方便的查看所需的数据呢?
设计思路
3.1.1 定义视图
创建视图
创建视图的SQL语句一般格式为:
创建视图注意事项
1.创建单源表视图
2.创建多源表视图
3.创建基于视图的视图
4.创建带表达式的视图
5.创建含统计信息的视图
删除视图
•删除视图的SQL语句的格式为:
DROP VIEW
•删除视图时注意:按照参照的逆序删除。
3.1.2 查询视图
3.1.4 视图的作用
•1.视图能够简化用户的操作。
•2.视图使用户能以多种角度看待同一数据。
•3.视图对重构数据库提供了一定程度的逻辑独立性。
•4. 视图能够对机密数据提供安全保护。
•5.适当的利用视图可以更清晰的表达查询。
3.2 索引
没有索引:逐行扫描(顺序查找)
有索引:快速定位数据行(索引查找)
3.2.1 索引的概念
l索引实质上是一个单独的、物理的数据库结构,它是表中一个或多个列(称为搜索关键字)的值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。
3.2.2 索引的类型
l聚集索引在使用中具有如下特点:
l非聚集索引在使用中具有如下特点:
(1)非聚集索引具有与表的数据完全分离的结构。
3.2.3 索引的优缺点
l索引的主要优点如下:
l索引的主要缺点如下:
3.2.4 设计索引
l一般来说,适合在以下的这些列上创建索引:
l对于以下这些列不适合创建索引:
引例代码
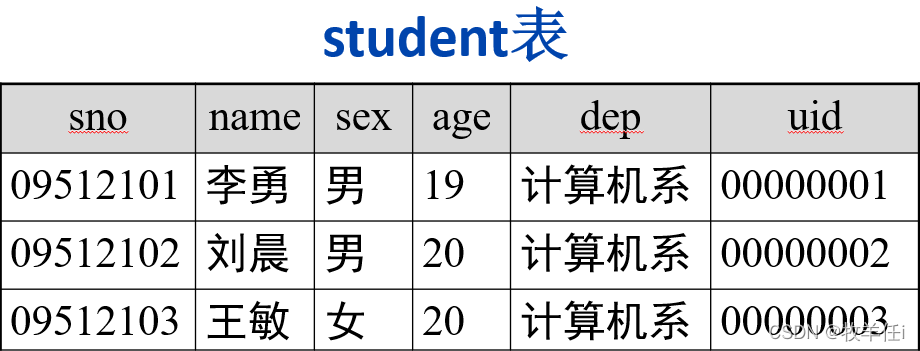
CREATE VIEW StudentView1 AS SELECT * FROM student WHERE sdept='计算机系'内容的引入
对于一个学校,其学生的情况存于数据库的一个或多个表中,而作为学校的不同职能部门教务部和后勤管理部门,它所关心的学生数据的内容是不同的,如:教务部关心学生的成绩信息,后勤管理部门重点关心学生的住宿信息,而且不允许其查看成绩信息。
问题:
针对这种需求,如何设计数据库以便用户很方便的查看所需的数据呢?
设计思路
• 根据不同用户的不同需求,在物理的数据库上定义他们对数据库所要求的数据结构,这种根据用户观点定义的数据结构就是视图。
• 用户只能对他所见到的视图进行操作,不仅可以查看其感兴趣的数据,而且可以屏蔽对其保密的数据。
3.1.1 定义视图
• 用CREATE TABEL语句创建的表叫基本表(Base Table)。
•视图(View)是从一个或多个基本表或视图中导出的表,视图的结构和数据都是建立在对基本表的查询基础上的。
• 视图不是真实存在的表,而是一个虚拟表,数据库中只存储视图的定义,而没有存储视图对应的数据,视图中的数据是从基本表中选取出来的,这些数据并不实际的按视图结构存储在数据库中,而是存储在原来的基本表中。
创建视图
创建视图的SQL语句一般格式为:
CREATE VIEW <视图名> [(视图列名表)]
AS
SELECT 查询子句
[WITH CHECK OPTION]
创建视图注意事项
(1)视图名必须遵循标识符命名规则,且对每类用户视图名必须是唯一的,即对不同用户定义相同的视图,也必须使用不同的名字。
(2) SELECT查询子句的查询内容就是视图的内容。SELECT语句通常不允许含有ORDER BY子句和DISTINCT子句。
SELECT语句中查询的表和视图即新创建的视图所参照的表和视图。
(3)视图列名列表是视图中所包含的列。若使用与基本表中相同的列名,则可以省略。若指定列名列表,则需全部指定,不能只给出一部分。以下情况要求必须指定视图的全部列名:
①由算术表达式、系统内置函数或者常量得到的列;
②多表连接查询时选出的同名列;
③希望视图中的列名与基表中的列名不同的时候。
(4)WITH CHECK OPTION子句表示在视图上执行UPDATE,INSERT或DELETE操作时要保证所修改的行满足视图定义中的谓词条件(即SELECT查询子句中的限定条件,如Where条件),这样可以确保数据修改后,仍可通过视图看到修改的数据。
1.创建单源表视图
l如果一个视图从单个基本表导出的,并且保留了码,这种视图称为单源表视图(行列子集视图)。
【例4.1】创建价格高于30元的图书视图BookView1。
CREATE VIEW BookView1 AS SELECT * FROM Book WHERE price>30【例4.2】创建价格高于30元的图书视图BookView2。并要保证对该视图的修改都要符合价格高于30元这个条件。
CREATE VIEW BookView2 AS SELECT book_id,name,author,publish,price FROM Book WHERE price>30 WITH CHECK OPTION 2.创建多源表视图
l多源表视图是指创建视图时的子查询中用了多个源表。
l多源表视图一般只用于查询,不用于修改数据。
【例4.3】创建R_B_Book视图,查询所有读者借阅图书的读者编号、姓名、图书编号、书名、出版社、价格、借阅日期信息。
CREATE VIEW R_B_Book (读者编号,姓名,图书编号,书名,出版社,价格,借阅日期信息) AS SELECT R.reader_id, R.name, B.book_id, B.name, publish, price, borrowdate FROM Reader as R JOIN Borrow as W ON R.reader_id = W.reader_id JOIN Book as BON B.book_id=W.book_id 3.创建基于视图的视图
l视图可以建立在其它已经创建好的视图上,即创建基于视图的视图。
【例4.4】基于上例中的视图R_B_Book,创建”王旭”的读者借阅的图书书名和出版社信息和借阅日期的视图WXBorrow。
CREATE VIEW WXBorrowAS SELECT 书名, 出版社, 借阅日期 FROM R_B_Book WHERE姓名 =‘王旭’4.创建带表达式的视图
l在定义视图时可以根据实际需要设置一些派生属性列,在这些派生属性列中保存经过计算的值。称它们为虚拟列。带虚拟列的视图也称带表达式的视图。
【例4.5】创建读者信息的视图ReaderInfo,包括读者编号、姓名和年龄,在视图中的列名分别为ID,Name和Age。
CREATE VIEW ReaderInfo (ID, Name, Age)AS SELECT reader_id,name,YEAR(GETDATE()) -YEAR(birthdate) FROM Reader5.创建含统计信息的视图
l还可以用带有集合函数和GROUP BY子句的查询来创建视图,这种视图称为分组视图。
【例4.6】创建每个出版社出版图书的平均价格的视图PerPublish_AVG。
CREATE VIEW PerPublish_AVG(Publish,AVG_Price)AS SELECT publish, AVG(price) FROM Book GROUP BY publish删除视图
•删除视图的SQL语句的格式为:
DROP VIEW <视图名>
•删除视图时注意:按照参照的逆序删除。
如WXBorrow视图是基于R_B_Borrow创建的,因此删除的顺序应该是……?
•【例4.10】删除图书视图BookView1。
DROP VIEW BookView1 3.1.2 查询视图
l视图是一张虚表,可以同基本表一样进行查询,但需要注意查询视图时应使用视图定义时的列名。
【例4.8】基于视图R_B_Book查询借阅《数据库原理》一书的读者编号和姓名
SELECT 读者编号,姓名 FROM R_B_Book WHERE 书名=‘数据库原理’【例4.9】基于视图ReaderInfo查询年龄高于20岁的读者编号和姓名
SELECT id,name FROM ReaderInfo WHERE AGE>=20 3.1.4 视图的作用
•1.视图能够简化用户的操作。
•2.视图使用户能以多种角度看待同一数据。
•3.视图对重构数据库提供了一定程度的逻辑独立性。
•4. 视图能够对机密数据提供安全保护。
•5.适当的利用视图可以更清晰的表达查询。
3.2 索引
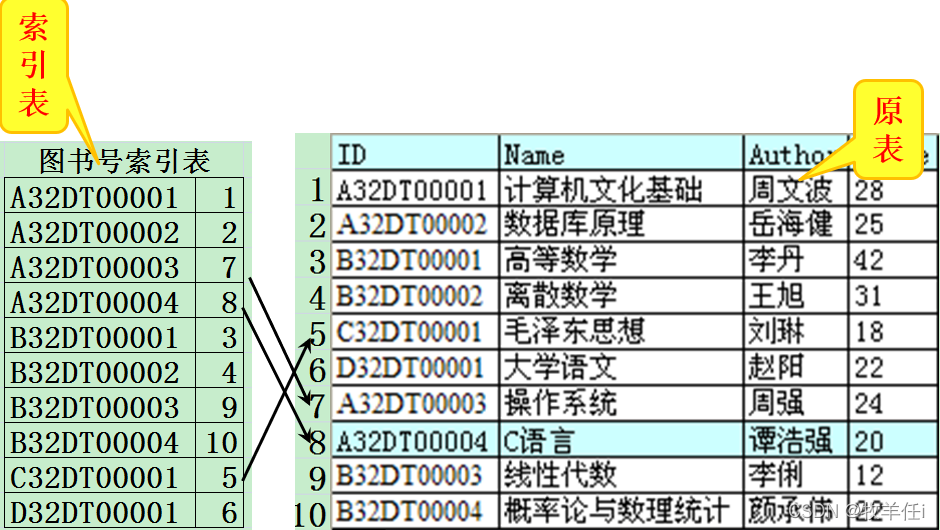
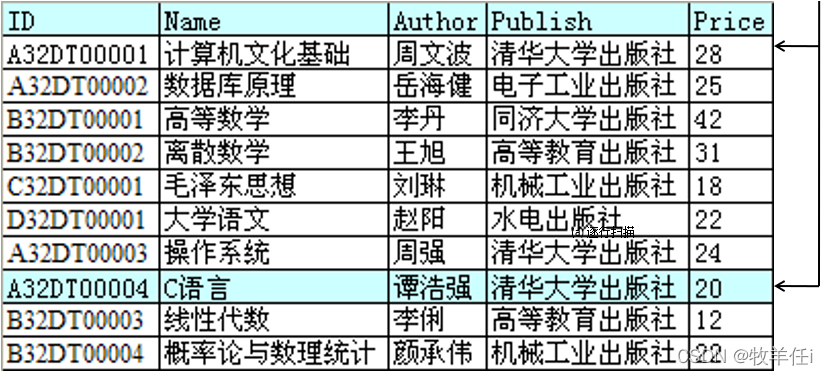
没有索引:逐行扫描(顺序查找)
从如下图书信息表查找“A32DT0004”一书的过程:
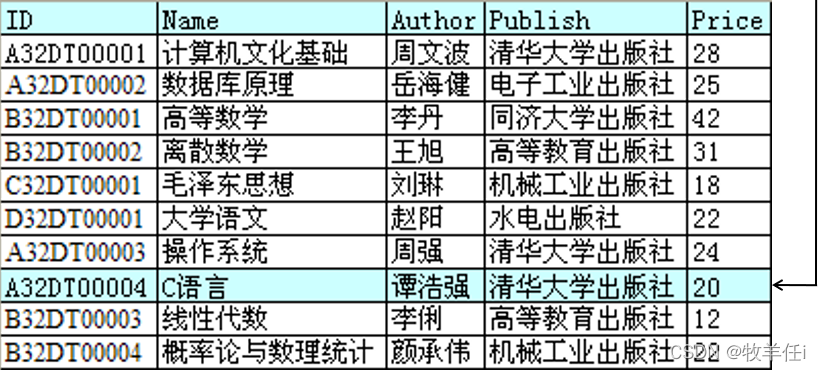
有索引:快速定位数据行(索引查找)
从如下图书信息表查找“A32DT0004”一书的过程:
3.2.1 索引的概念
l索引实质上是一个单独的、物理的数据库结构,它是表中一个或多个列(称为搜索关键字)的值的集合和相应的指向表中物理标识这些值的数据页的逻辑指针清单。